 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hyperbolic Audio Source Separation
Dec 09, 2022
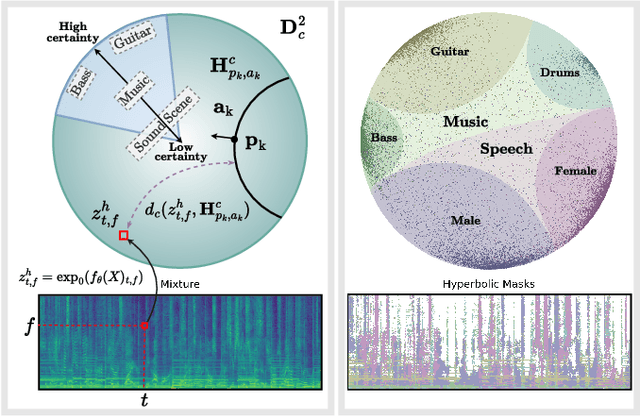
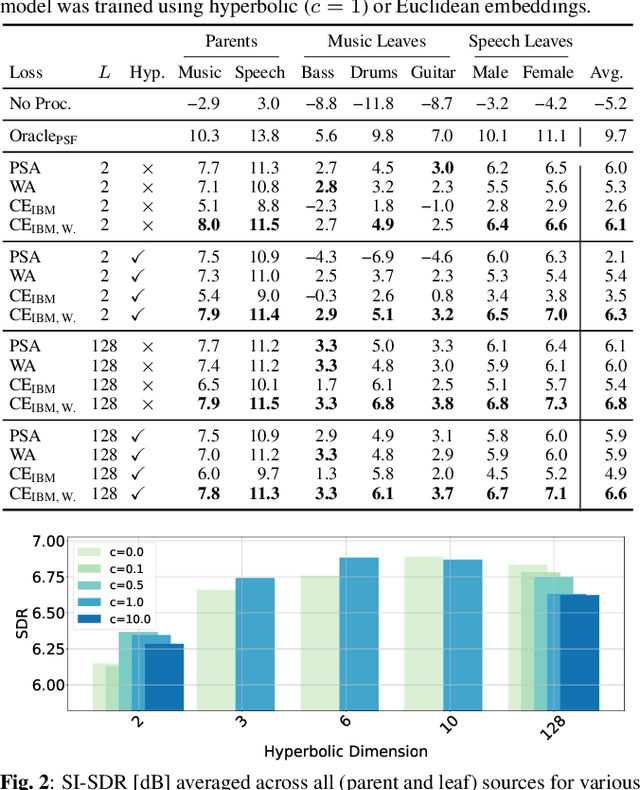
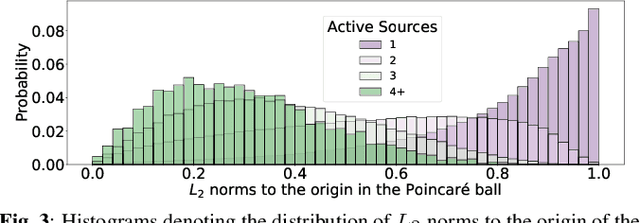
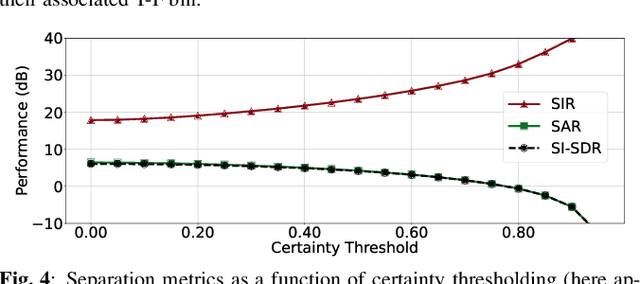
We introduce a framework for audio source separation using embeddings on a hyperbolic manifold that compactly represent the hierarchical relationship between sound sources and time-frequency features. Inspired by recent successes modeling hierarchical relationships in text and images with hyperbolic embeddings, our algorithm obtains a hyperbolic embedding for each time-frequency bin of a mixture signal and estimates masks using hyperbolic softmax layers. On a synthetic dataset containing mixtures of multiple people talking and musical instruments playing, our hyperbolic model performed comparably to a Euclidean baseline in terms of source to distortion ratio, with stronger performance at low embedding dimensions. Furthermore, we find that time-frequency regions containing multiple overlapping sources are embedded towards the center (i.e., the most uncertain region) of the hyperbolic space, and we can use this certainty estimate to efficiently trade-off between artifact introduction and interference reduction when isolating individual sounds.
Multi-scale Attention Flow for Probabilistic Time Series Forecasting
May 16, 2022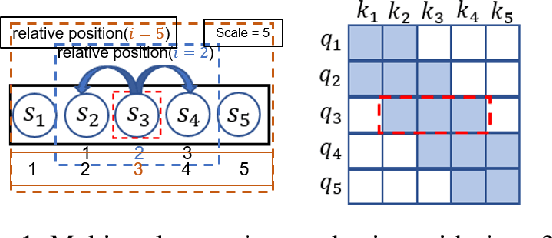
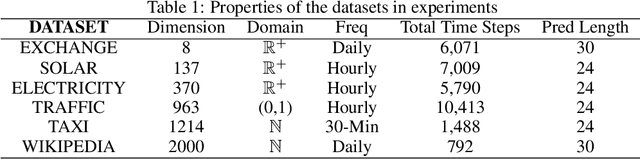
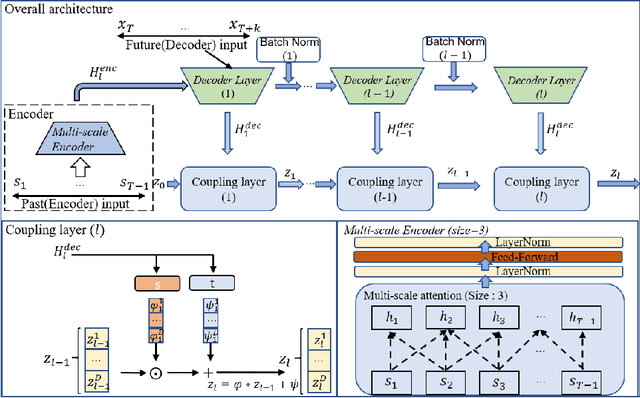
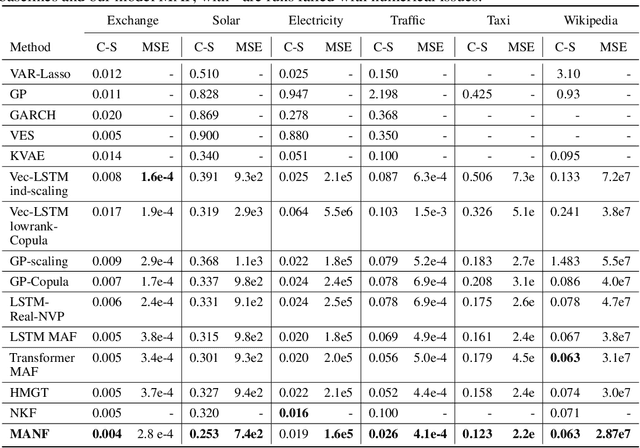
The probability prediction of multivariate time series is a notoriously challenging but practical task. On the one hand, the challenge is how to effectively capture the cross-series correlations between interacting time series, to achieve accurate distribution modeling. On the other hand, we should consider how to capture the contextual information within time series more accurately to model multivariate temporal dynamics of time series. In this work, we proposed a novel non-autoregressive deep learning model, called Multi-scale Attention Normalizing Flow(MANF), where we integrate multi-scale attention and relative position information and the multivariate data distribution is represented by the conditioned normalizing flow. Additionally, compared with autoregressive modeling methods, our model avoids the influence of cumulative error and does not increase the time complexity. Extensive experiments demonstrate that our model achieves state-of-the-art performance on many popular multivariate datasets.
Reinforcement Learning Based Approaches to Adaptive Context Caching in Distributed Context Management Systems
Dec 22, 2022

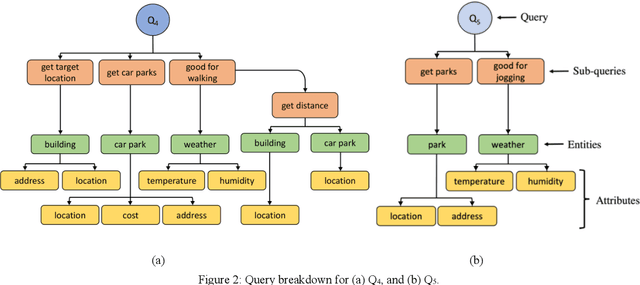

Performance metrics-driven context caching has a profound impact on throughput and response time in distributed context management systems for real-time context queries. This paper proposes a reinforcement learning based approach to adaptively cache context with the objective of minimizing the cost incurred by context management systems in responding to context queries. Our novel algorithms enable context queries and sub-queries to reuse and repurpose cached context in an efficient manner. This approach is distinctive to traditional data caching approaches by three main features. First, we make selective context cache admissions using no prior knowledge of the context, or the context query load. Secondly, we develop and incorporate innovative heuristic models to calculate expected performance of caching an item when making the decisions. Thirdly, our strategy defines a time-aware continuous cache action space. We present two reinforcement learning agents, a value function estimating actor-critic agent and a policy search agent using deep deterministic policy gradient method. The paper also proposes adaptive policies such as eviction and cache memory scaling to complement our objective. Our method is evaluated using a synthetically generated load of context sub-queries and a synthetic data set inspired from real world data and query samples. We further investigate optimal adaptive caching configurations under different settings. This paper presents, compares, and discusses our findings that the proposed selective caching methods reach short- and long-term cost- and performance-efficiency. The paper demonstrates that the proposed methods outperform other modes of context management such as redirector mode, and database mode, and cache all policy by up to 60% in cost efficiency.
Robust Dynamic Radiance Fields
Jan 05, 2023
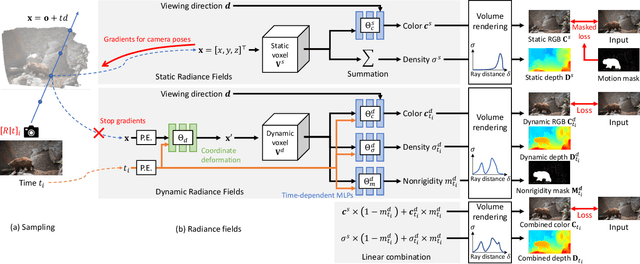
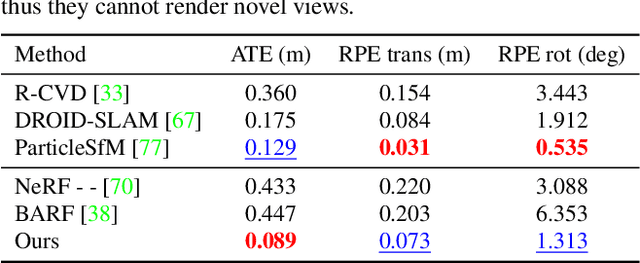
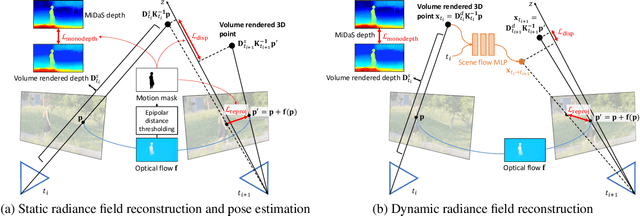
Dynamic radiance field reconstruction methods aim to model the time-varying structure and appearance of a dynamic scene. Existing methods, however, assume that accurate camera poses can be reliably estimated by Structure from Motion (SfM) algorithms. These methods, thus, are unreliable as SfM algorithms often fail or produce erroneous poses on challenging videos with highly dynamic objects, poorly textured surfaces, and rotating camera motion. We address this robustness issue by jointly estimating the static and dynamic radiance fields along with the camera parameters (poses and focal length). We demonstrate the robustness of our approach via extensive quantitative and qualitative experiments. Our results show favorable performance over the state-of-the-art dynamic view synthesis methods.
Multivariate Time Series Anomaly Detection with Few Positive Samples
Jul 02, 2022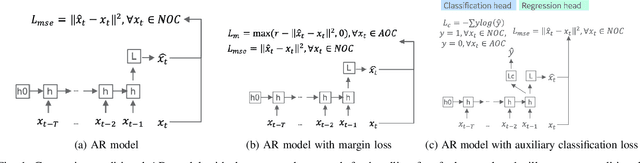
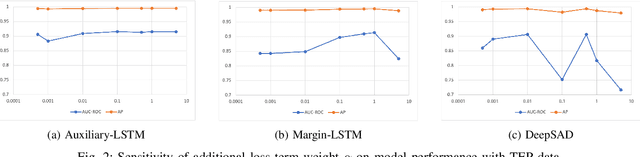
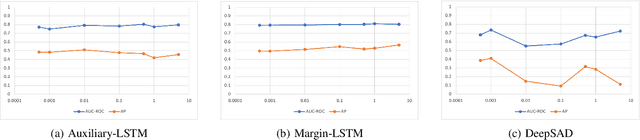
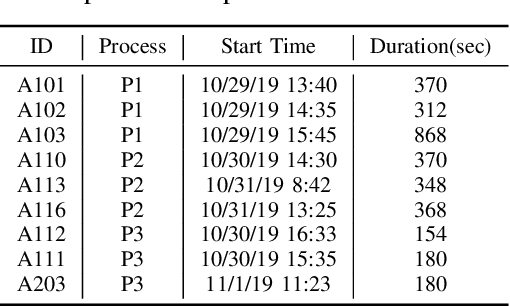
Given the scarcity of anomalies in real-world applications, the majority of literature has been focusing on modeling normality. The learned representations enable anomaly detection as the normality model is trained to capture certain key underlying data regularities under normal circumstances. In practical settings, particularly industrial time series anomaly detection, we often encounter situations where a large amount of normal operation data is available along with a small number of anomaly events collected over time. This practical situation calls for methodologies to leverage these small number of anomaly events to create a better anomaly detector. In this paper, we introduce two methodologies to address the needs of this practical situation and compared them with recently developed state of the art techniques. Our proposed methods anchor on representative learning of normal operation with autoregressive (AR) model along with loss components to encourage representations that separate normal versus few positive examples. We applied the proposed methods to two industrial anomaly detection datasets and demonstrated effective performance in comparison with approaches from literature. Our study also points out additional challenges with adopting such methods in practical applications.
Optimization of Mobile Robotic Relay Operation for Minimal Average Wait Time
Aug 23, 2022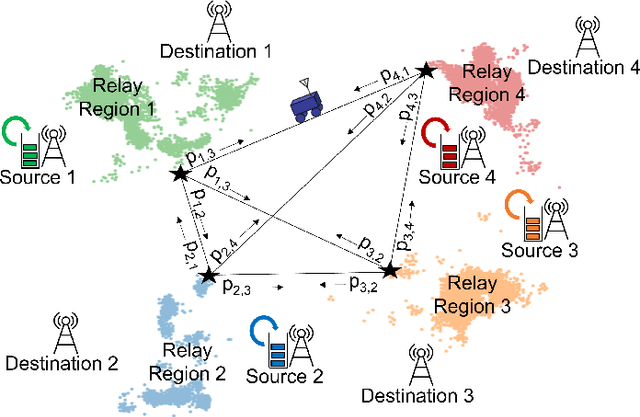

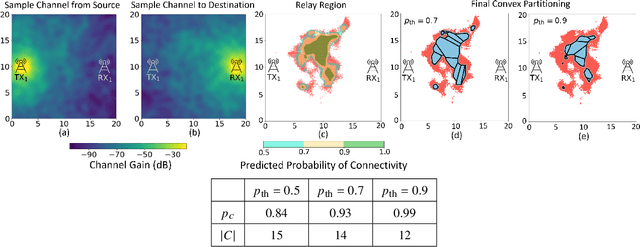
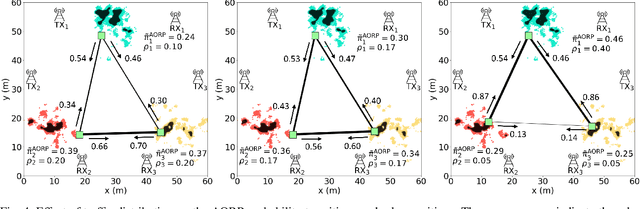
This paper considers trajectory planning for a mobile robot which persistently relays data between pairs of far-away communication nodes. Data accumulates stochastically at each source, and the robot must move to appropriate positions to enable data offload to the corresponding destination. The robot needs to minimize the average time that data waits at a source before being serviced. We are interested in finding optimal robotic routing policies consisting of 1) locations where the robot stops to relay (relay positions) and 2) conditional transition probabilities that determine the sequence in which the pairs are serviced. We first pose this problem as a non-convex problem that optimizes over both relay positions and transition probabilities. To find approximate solutions, we propose a novel algorithm which alternately optimizes relay positions and transition probabilities. For the former, we find efficient convex partitions of the non-convex relay regions, then formulate a mixed-integer second-order cone problem. For the latter, we find optimal transition probabilities via sequential least squares programming. We extensively analyze the proposed approach and mathematically characterize important system properties related to the robot's long-term energy consumption and service rate. Finally, through extensive simulation with real channel parameters, we verify the efficacy of our approach.
InstantAvatar: Learning Avatars from Monocular Video in 60 Seconds
Dec 20, 2022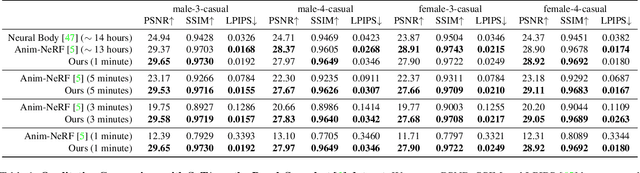
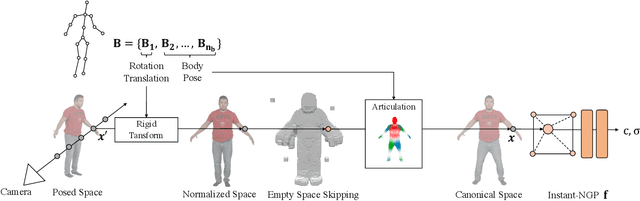
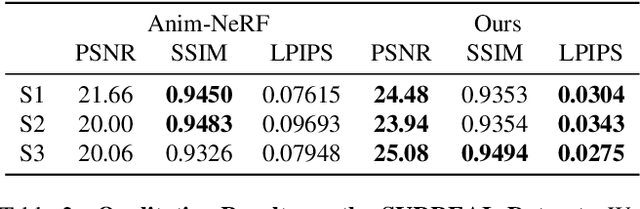
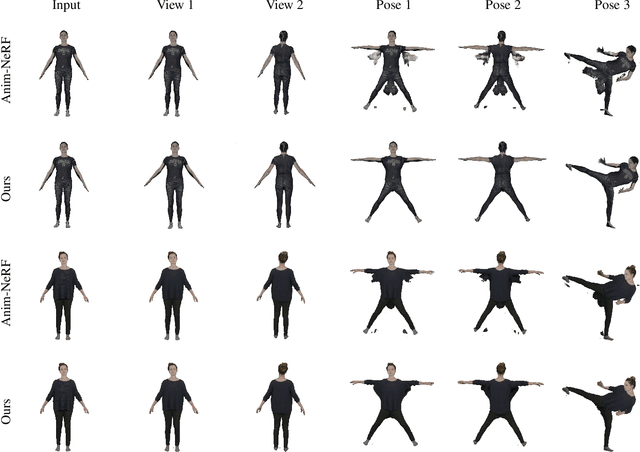
In this paper, we take a significant step towards real-world applicability of monocular neural avatar reconstruction by contributing InstantAvatar, a system that can reconstruct human avatars from a monocular video within seconds, and these avatars can be animated and rendered at an interactive rate. To achieve this efficiency we propose a carefully designed and engineered system, that leverages emerging acceleration structures for neural fields, in combination with an efficient empty space-skipping strategy for dynamic scenes. We also contribute an efficient implementation that we will make available for research purposes. Compared to existing methods, InstantAvatar converges 130x faster and can be trained in minutes instead of hours. It achieves comparable or even better reconstruction quality and novel pose synthesis results. When given the same time budget, our method significantly outperforms SoTA methods. InstantAvatar can yield acceptable visual quality in as little as 10 seconds training time.
CSMPQ:Class Separability Based Mixed-Precision Quantization
Dec 20, 2022
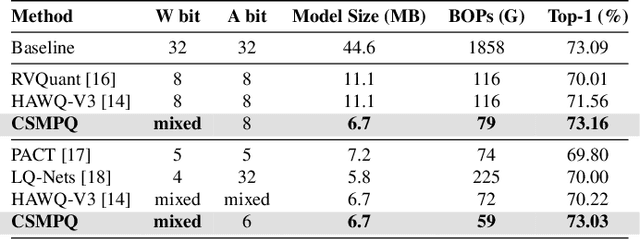
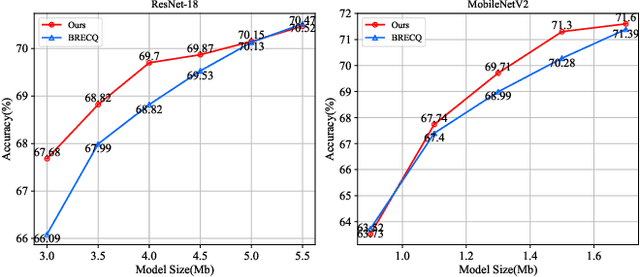
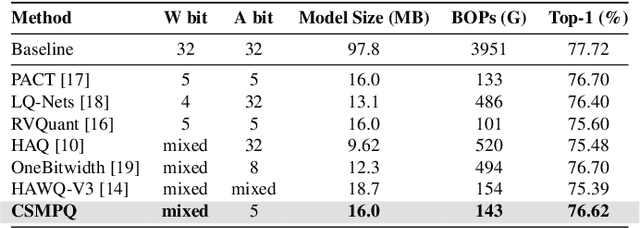
Mixed-precision quantization has received increasing attention for its capability of reducing the computational burden and speeding up the inference time. Existing methods usually focus on the sensitivity of different network layers, which requires a time-consuming search or training process. To this end, a novel mixed-precision quantization method, termed CSMPQ, is proposed. Specifically, the TF-IDF metric that is widely used in natural language processing (NLP) is introduced to measure the class separability of layer-wise feature maps. Furthermore, a linear programming problem is designed to derive the optimal bit configuration for each layer. Without any iterative process, the proposed CSMPQ achieves better compression trade-offs than the state-of-the-art quantization methods. Specifically, CSMPQ achieves 73.03$\%$ Top-1 acc on ResNet-18 with only 59G BOPs for QAT, and 71.30$\%$ top-1 acc with only 1.5Mb on MobileNetV2 for PTQ.
RobustPdM: Designing Robust Predictive Maintenance against Adversarial Attacks
Jan 25, 2023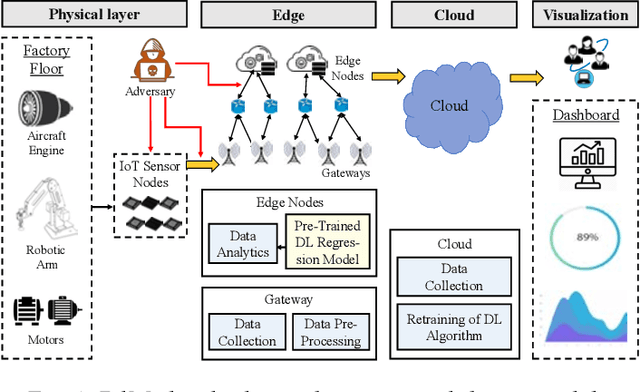

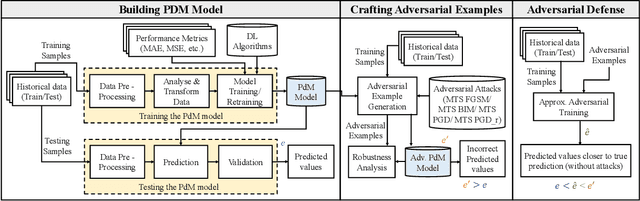
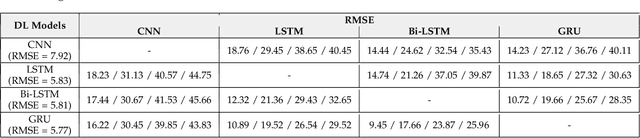
The state-of-the-art predictive maintenance (PdM) techniques have shown great success in reducing maintenance costs and downtime of complicated machines while increasing overall productivity through extensive utilization of Internet-of-Things (IoT) and Deep Learning (DL). Unfortunately, IoT sensors and DL algorithms are both prone to cyber-attacks. For instance, DL algorithms are known for their susceptibility to adversarial examples. Such adversarial attacks are vastly under-explored in the PdM domain. This is because the adversarial attacks in the computer vision domain for classification tasks cannot be directly applied to the PdM domain for multivariate time series (MTS) regression tasks. In this work, we propose an end-to-end methodology to design adversarially robust PdM systems by extensively analyzing the effect of different types of adversarial attacks and proposing a novel adversarial defense technique for DL-enabled PdM models. First, we propose novel MTS Projected Gradient Descent (PGD) and MTS PGD with random restarts (PGD_r) attacks. Then, we evaluate the impact of MTS PGD and PGD_r along with MTS Fast Gradient Sign Method (FGSM) and MTS Basic Iterative Method (BIM) on Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), Convolutional Neural Network (CNN), and Bi-directional LSTM based PdM system. Our results using NASA's turbofan engine dataset show that adversarial attacks can cause a severe defect (up to 11X) in the RUL prediction, outperforming the effectiveness of the state-of-the-art PdM attacks by 3X. Furthermore, we present a novel approximate adversarial training method to defend against adversarial attacks. We observe that approximate adversarial training can significantly improve the robustness of PdM models (up to 54X) and outperforms the state-of-the-art PdM defense methods by offering 3X more robustness.
Forgetful Forests: high performance learning data structures for streaming data under concept drift
Dec 15, 2022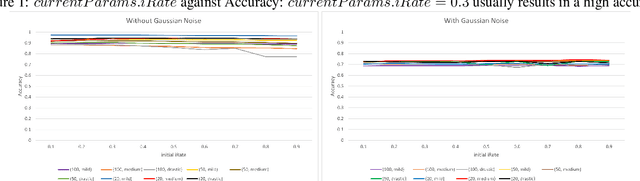
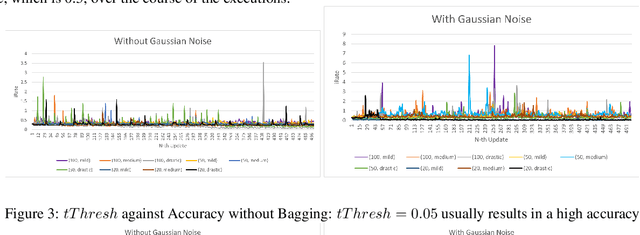
Database research can help machine learning performance in many ways. One way is to design better data structures. This paper combines the use of incremental computation and sequential and probabilistic filtering to enable "forgetful" tree-based learning algorithms to cope with concept drift data (i.e., data whose function from input to classification changes over time). The forgetful algorithms described in this paper achieve high time performance while maintaining high quality predictions on streaming data. Specifically, the algorithms are up to 24 times faster than state-of-the-art incremental algorithms with at most a 2% loss of accuracy, or at least twice faster without any loss of accuracy. This makes such structures suitable for high volume streaming applications.