 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reduced Deep Convolutional Activation Features (R-DeCAF) in Histopathology Images to Improve the Classification Performance for Breast Cancer Diagnosis
Jan 05, 2023
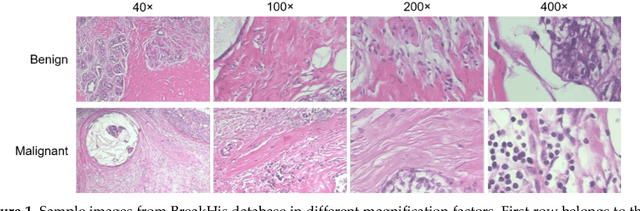
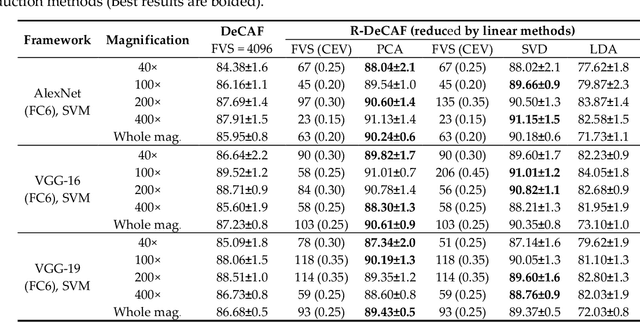
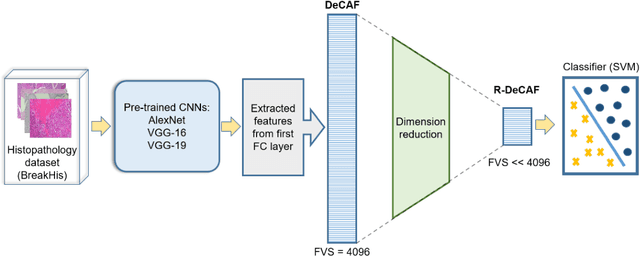
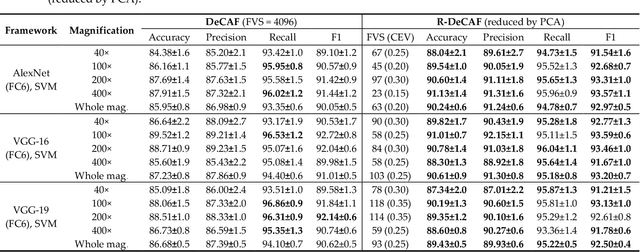
Breast cancer is the second most common cancer among women worldwide. Diagnosis of breast cancer by the pathologists is a time-consuming procedure and subjective. Computer aided diagnosis frameworks are utilized to relieve pathologist workload by classifying the data automatically, in which deep convolutional neural networks (CNNs) are effective solutions. The features extracted from activation layer of pre-trained CNNs are called deep convolutional activation features (DeCAF). In this paper, we have analyzed that all DeCAF features are not necessarily led to a higher accuracy in the classification task and dimension reduction plays an important role. Therefore, different dimension reduction methods are applied to achieve an effective combination of features by capturing the essence of DeCAF features. To this purpose, we have proposed reduced deep convolutional activation features (R-DeCAF). In this framework, pre-trained CNNs such as AlexNet, VGG-16 and VGG-19 are utilized in transfer learning mode as feature extractors. DeCAF features are extracted from the first fully connected layer of the mentioned CNNs and support vector machine has been used for binary classification. Among linear and nonlinear dimensionality reduction algorithms, linear approaches such as principal component analysis (PCA) represent a better combination among deep features and lead to a higher accuracy in the classification task using small number of features considering specific amount of cumulative explained variance (CEV) of features. The proposed method is validated using experimental BreakHis dataset. Comprehensive results show improvement in the classification accuracy up to 4.3% with less computational time. Best achieved accuracy is 91.13% for 400x data with feature vector size (FVS) of 23 and CEV equals to 0.15 using pre-trained AlexNet as feature extractor and PCA as feature reduction algorithm.
Two-Timescale Stochastic Approximation for Bilevel Optimisation Problems in Continuous-Time Models
Jun 14, 2022We analyse the asymptotic properties of a continuous-time, two-timescale stochastic approximation algorithm designed for stochastic bilevel optimisation problems in continuous-time models. We obtain the weak convergence rate of this algorithm in the form of a central limit theorem. We also demonstrate how this algorithm can be applied to several continuous-time bilevel optimisation problems.
Real-Time Face Recognition System
Apr 19, 2022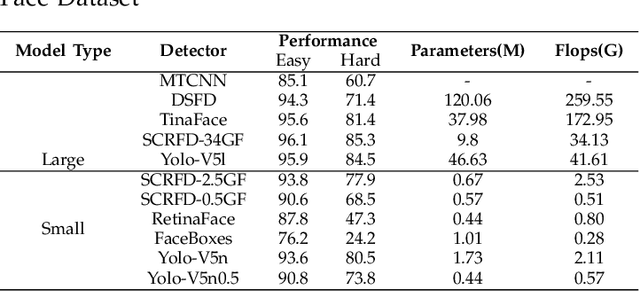
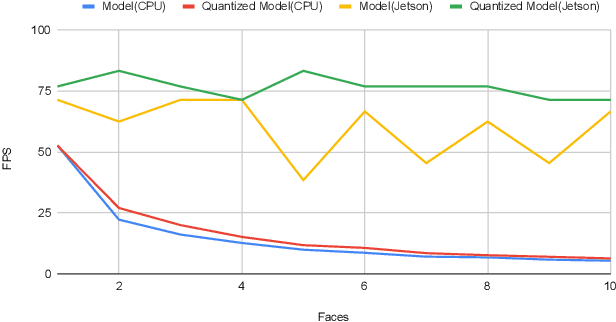
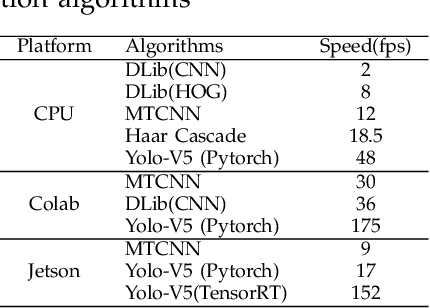
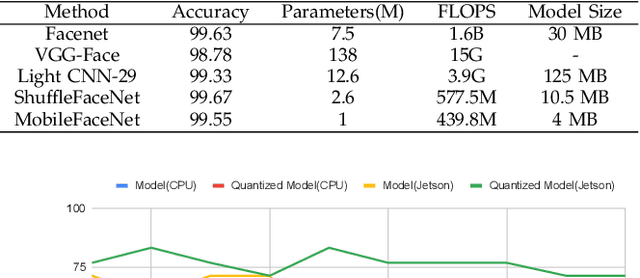
Over the past few decades, interest in algorithms for face recognition has been growing rapidly and has even surpassed human-level performance. Despite their accomplishments, their practical integration with a real-time performance-hungry system is not feasible due to high computational costs. So in this paper, we explore the recent, fast, and accurate face recognition system that can be easily integrated with real-time devices, and tested the algorithms on robot hardware platforms to confirm their robustness and speed.
* Poster
RobustPdM: Designing Robust Predictive Maintenance against Adversarial Attacks
Jan 25, 2023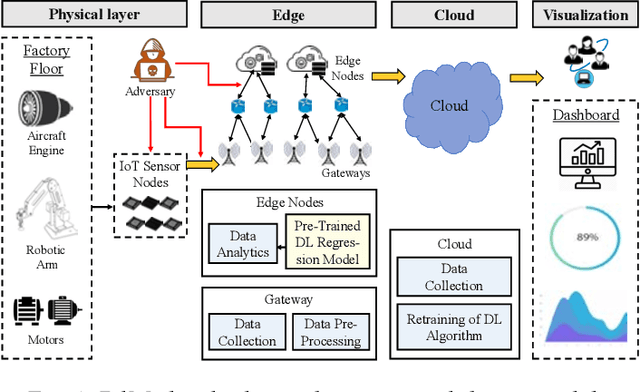

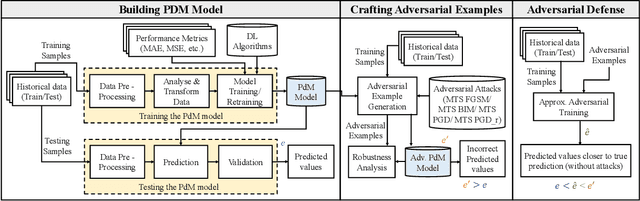
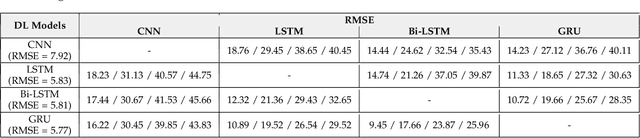
The state-of-the-art predictive maintenance (PdM) techniques have shown great success in reducing maintenance costs and downtime of complicated machines while increasing overall productivity through extensive utilization of Internet-of-Things (IoT) and Deep Learning (DL). Unfortunately, IoT sensors and DL algorithms are both prone to cyber-attacks. For instance, DL algorithms are known for their susceptibility to adversarial examples. Such adversarial attacks are vastly under-explored in the PdM domain. This is because the adversarial attacks in the computer vision domain for classification tasks cannot be directly applied to the PdM domain for multivariate time series (MTS) regression tasks. In this work, we propose an end-to-end methodology to design adversarially robust PdM systems by extensively analyzing the effect of different types of adversarial attacks and proposing a novel adversarial defense technique for DL-enabled PdM models. First, we propose novel MTS Projected Gradient Descent (PGD) and MTS PGD with random restarts (PGD_r) attacks. Then, we evaluate the impact of MTS PGD and PGD_r along with MTS Fast Gradient Sign Method (FGSM) and MTS Basic Iterative Method (BIM) on Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), Convolutional Neural Network (CNN), and Bi-directional LSTM based PdM system. Our results using NASA's turbofan engine dataset show that adversarial attacks can cause a severe defect (up to 11X) in the RUL prediction, outperforming the effectiveness of the state-of-the-art PdM attacks by 3X. Furthermore, we present a novel approximate adversarial training method to defend against adversarial attacks. We observe that approximate adversarial training can significantly improve the robustness of PdM models (up to 54X) and outperforms the state-of-the-art PdM defense methods by offering 3X more robustness.
Robust Dynamic Radiance Fields
Jan 05, 2023
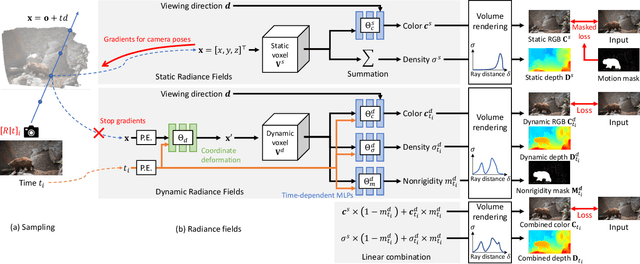
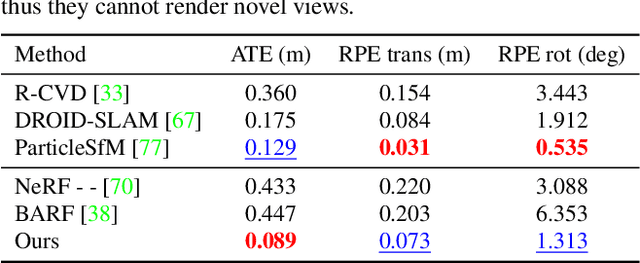
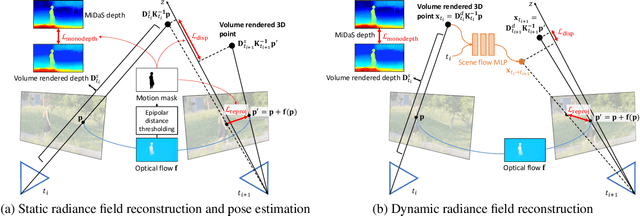
Dynamic radiance field reconstruction methods aim to model the time-varying structure and appearance of a dynamic scene. Existing methods, however, assume that accurate camera poses can be reliably estimated by Structure from Motion (SfM) algorithms. These methods, thus, are unreliable as SfM algorithms often fail or produce erroneous poses on challenging videos with highly dynamic objects, poorly textured surfaces, and rotating camera motion. We address this robustness issue by jointly estimating the static and dynamic radiance fields along with the camera parameters (poses and focal length). We demonstrate the robustness of our approach via extensive quantitative and qualitative experiments. Our results show favorable performance over the state-of-the-art dynamic view synthesis methods.
Reinforcement Learning Based Approaches to Adaptive Context Caching in Distributed Context Management Systems
Dec 22, 2022

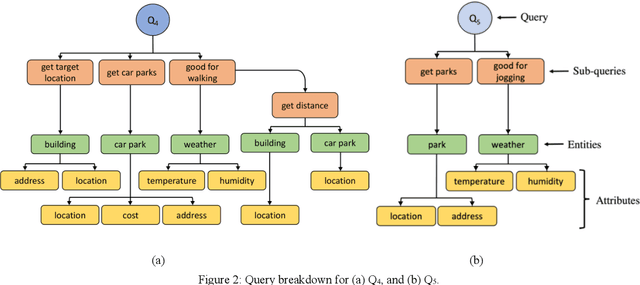

Performance metrics-driven context caching has a profound impact on throughput and response time in distributed context management systems for real-time context queries. This paper proposes a reinforcement learning based approach to adaptively cache context with the objective of minimizing the cost incurred by context management systems in responding to context queries. Our novel algorithms enable context queries and sub-queries to reuse and repurpose cached context in an efficient manner. This approach is distinctive to traditional data caching approaches by three main features. First, we make selective context cache admissions using no prior knowledge of the context, or the context query load. Secondly, we develop and incorporate innovative heuristic models to calculate expected performance of caching an item when making the decisions. Thirdly, our strategy defines a time-aware continuous cache action space. We present two reinforcement learning agents, a value function estimating actor-critic agent and a policy search agent using deep deterministic policy gradient method. The paper also proposes adaptive policies such as eviction and cache memory scaling to complement our objective. Our method is evaluated using a synthetically generated load of context sub-queries and a synthetic data set inspired from real world data and query samples. We further investigate optimal adaptive caching configurations under different settings. This paper presents, compares, and discusses our findings that the proposed selective caching methods reach short- and long-term cost- and performance-efficiency. The paper demonstrates that the proposed methods outperform other modes of context management such as redirector mode, and database mode, and cache all policy by up to 60% in cost efficiency.
Robust Projection based Anomaly Extraction (RPE) in Univariate Time-Series
May 31, 2022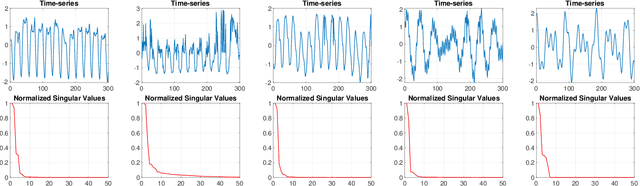

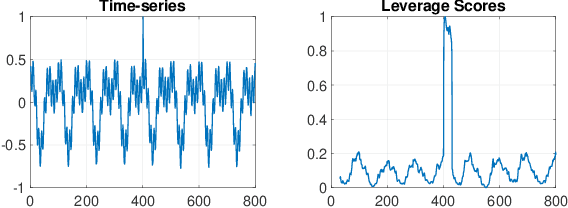

This paper presents a novel, closed-form, and data/computation efficient online anomaly detection algorithm for time-series data. The proposed method, dubbed RPE, is a window-based method and in sharp contrast to the existing window-based methods, it is robust to the presence of anomalies in its window and it can distinguish the anomalies in time-stamp level. RPE leverages the linear structure of the trajectory matrix of the time-series and employs a robust projection step which makes the algorithm able to handle the presence of multiple arbitrarily large anomalies in its window. A closed-form/non-iterative algorithm for the robust projection step is provided and it is proved that it can identify the corrupted time-stamps. RPE is a great candidate for the applications where a large training data is not available which is the common scenario in the area of time-series. An extensive set of numerical experiments show that RPE can outperform the existing approaches with a notable margin.
Tacchi: A Pluggable and Low Computational Cost Elastomer Deformation Simulator for Optical Tactile Sensors
Jan 19, 2023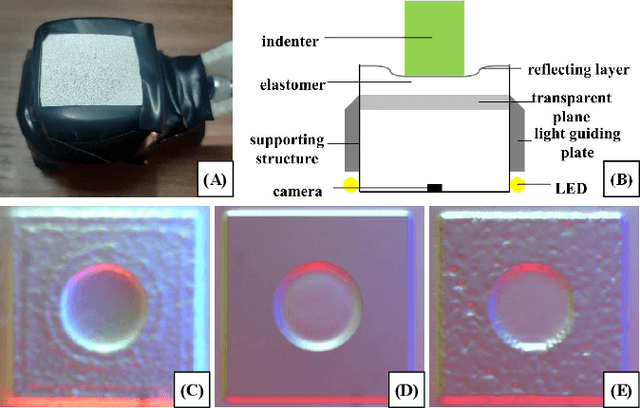
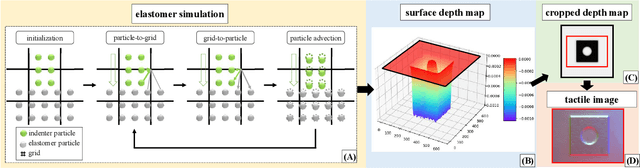
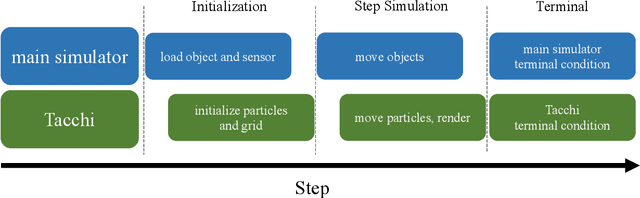

Simulation is widely applied in robotics research to save time and resources. There have been several works to simulate optical tactile sensors that leverage either a smoothing method or Finite Element Method (FEM). However, elastomer deformation physics is not considered in the former method, whereas the latter requires a massive amount of computational resources like a computer cluster. In this work, we propose a pluggable and low computational cost simulator using the Taichi programming language for simulating optical tactile sensors, named as Tacchi . It reconstructs elastomer deformation using particles, which allows deformed elastomer surfaces to be rendered into tactile images and reveals contact information without suffering from high computational costs. Tacchi facilitates creating realistic tactile images in simulation, e.g., ones that capture wear-and-tear defects on object surfaces. In addition, the proposed Tacchi can be integrated with robotics simulators for a robot system simulation. Experiment results showed that Tacchi can produce images with better similarity to real images and achieved higher Sim2Real accuracy compared to the existing methods. Moreover, it can be connected with MuJoCo and Gazebo with only the requirement of 1G memory space in GPU compared to a computer cluster applied for FEM. With Tacchi, physical robot simulation with optical tactile sensors becomes possible. All the materials in this paper are available at https://github.com/zixichen007115/Tacchi .
Advanced Scaling Methods for VNF deployment with Reinforcement Learning
Jan 19, 2023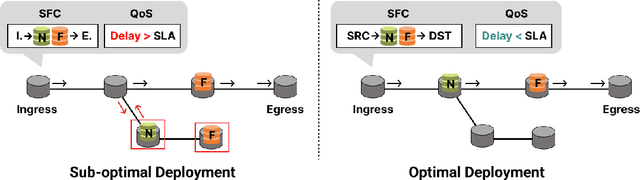
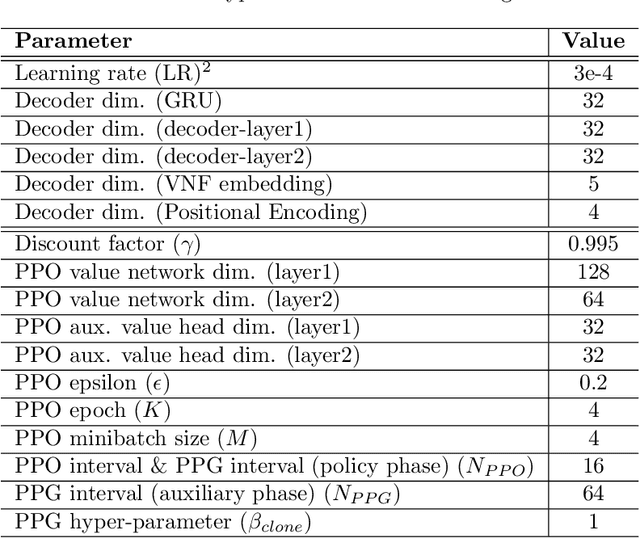
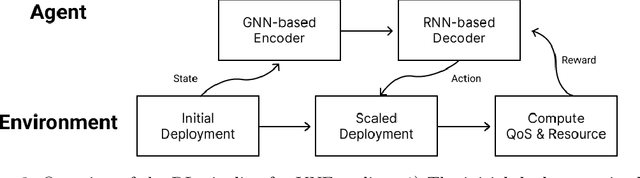
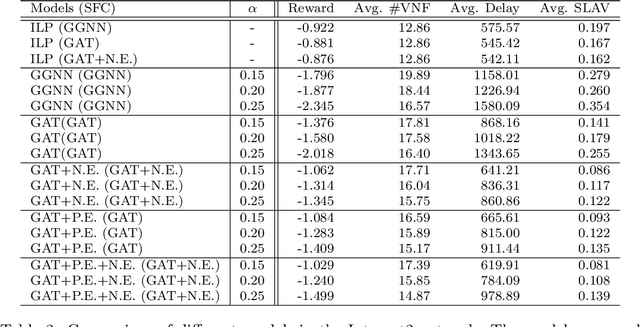
Network function virtualization (NFV) and software-defined network (SDN) have become emerging network paradigms, allowing virtualized network function (VNF) deployment at a low cost. Even though VNF deployment can be flexible, it is still challenging to optimize VNF deployment due to its high complexity. Several studies have approached the task as dynamic programming, e.g., integer linear programming (ILP). However, optimizing VNF deployment for highly complex networks remains a challenge. Alternatively, reinforcement learning (RL) based approaches have been proposed to optimize this task, especially to employ a scaling action-based method which can deploy VNFs within less computational time. However, the model architecture can be improved further to generalize to the different networking settings. In this paper, we propose an enhanced model which can be adapted to more general network settings. We adopt the improved GNN architecture and a few techniques to obtain a better node representation for the VNF deployment task. Furthermore, we apply a recently proposed RL method, phasic policy gradient (PPG), to leverage the shared representation of the service function chain (SFC) generation model from the value function. We evaluate the proposed method in various scenarios, achieving a better QoS with minimum resource utilization compared to the previous methods. Finally, as a qualitative evaluation, we analyze our proposed encoder's representation for the nodes, which shows a more disentangled representation.
The role of noise in denoising models for anomaly detection in medical images
Jan 19, 2023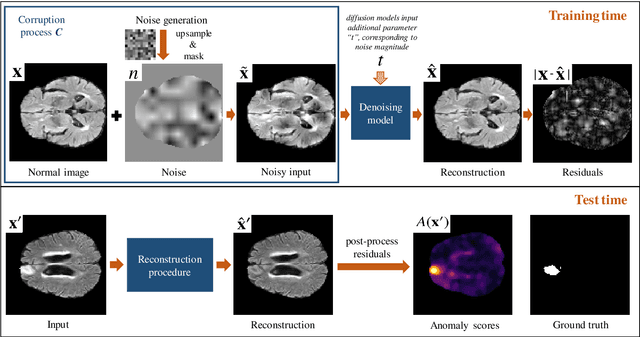


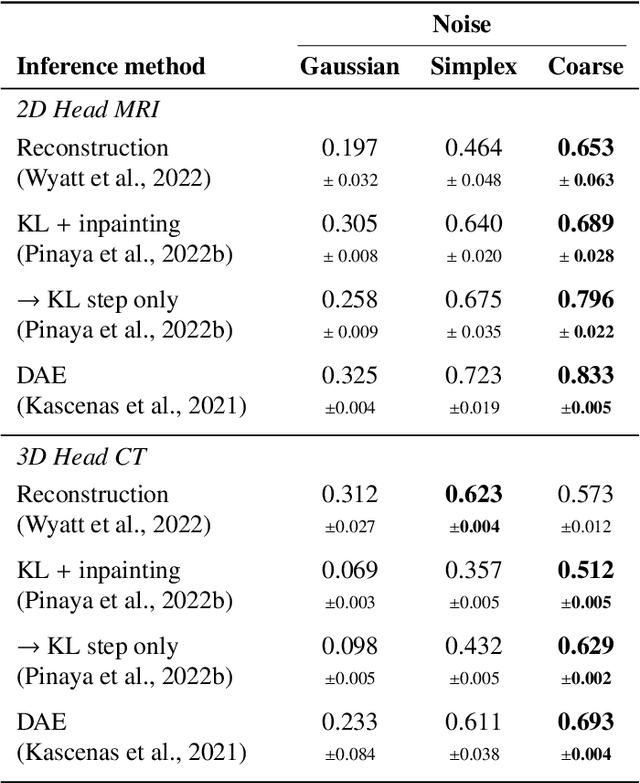
Pathological brain lesions exhibit diverse appearance in brain images, in terms of intensity, texture, shape, size, and location. Comprehensive sets of data and annotations are difficult to acquire. Therefore, unsupervised anomaly detection approaches have been proposed using only normal data for training, with the aim of detecting outlier anomalous voxels at test time. Denoising methods, for instance classical denoising autoencoders (DAEs) and more recently emerging diffusion models, are a promising approach, however naive application of pixelwise noise leads to poor anomaly detection performance. We show that optimization of the spatial resolution and magnitude of the noise improves the performance of different model training regimes, with similar noise parameter adjustments giving good performance for both DAEs and diffusion models. Visual inspection of the reconstructions suggests that the training noise influences the trade-off between the extent of the detail that is reconstructed and the extent of erasure of anomalies, both of which contribute to better anomaly detection performance. We validate our findings on two real-world datasets (tumor detection in brain MRI and hemorrhage/ischemia/tumor detection in brain CT), showing good detection on diverse anomaly appearances. Overall, we find that a DAE trained with coarse noise is a fast and simple method that gives state-of-the-art accuracy. Diffusion models applied to anomaly detection are as yet in their infancy and provide a promising avenue for further research.