 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Performance-Preserving Event Log Sampling for Predictive Monitoring
Jan 18, 2023
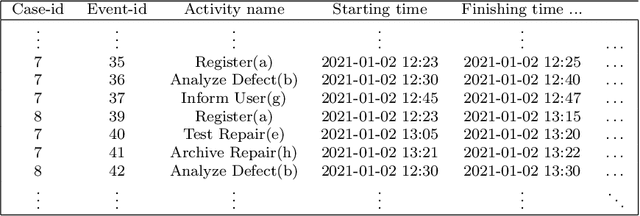

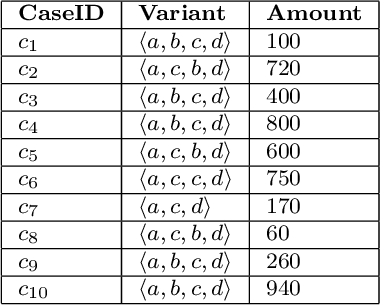

Predictive process monitoring is a subfield of process mining that aims to estimate case or event features for running process instances. Such predictions are of significant interest to the process stakeholders. However, most of the state-of-the-art methods for predictive monitoring require the training of complex machine learning models, which is often inefficient. Moreover, most of these methods require a hyper-parameter optimization that requires several repetitions of the training process which is not feasible in many real-life applications. In this paper, we propose an instance selection procedure that allows sampling training process instances for prediction models. We show that our instance selection procedure allows for a significant increase of training speed for next activity and remaining time prediction methods while maintaining reliable levels of prediction accuracy.
Reslicing Ultrasound Images for Data Augmentation and Vessel Reconstruction
Jan 18, 2023

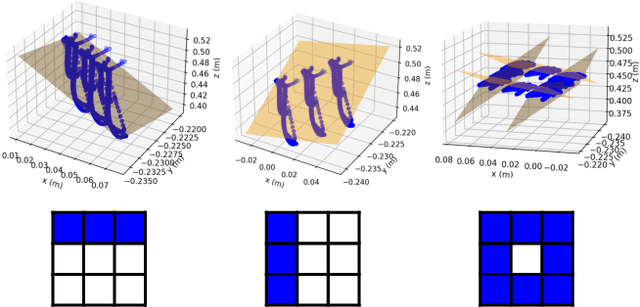
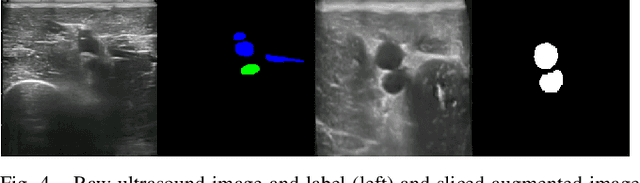
Robot-guided catheter insertion has the potential to deliver urgent medical care in situations where medical personnel are unavailable. However, this technique requires accurate and reliable segmentation of anatomical landmarks in the body. For the ultrasound imaging modality, obtaining large amounts of training data for a segmentation model is time-consuming and expensive. This paper introduces RESUS (RESlicing of UltraSound Images), a weak supervision data augmentation technique for ultrasound images based on slicing reconstructed 3D volumes from tracked 2D images. This technique allows us to generate views which cannot be easily obtained in vivo due to physical constraints of ultrasound imaging, and use these augmented ultrasound images to train a semantic segmentation model. We demonstrate that RESUS achieves statistically significant improvement over training with non-augmented images and highlight qualitative improvements through vessel reconstruction.
Compression of GPS Trajectories using Autoencoders
Jan 18, 2023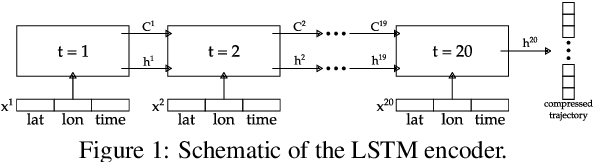
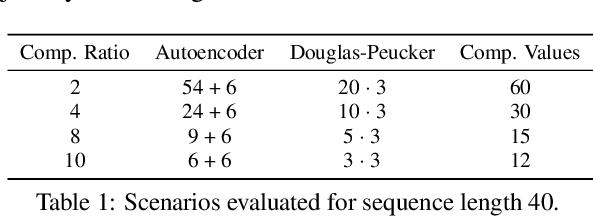
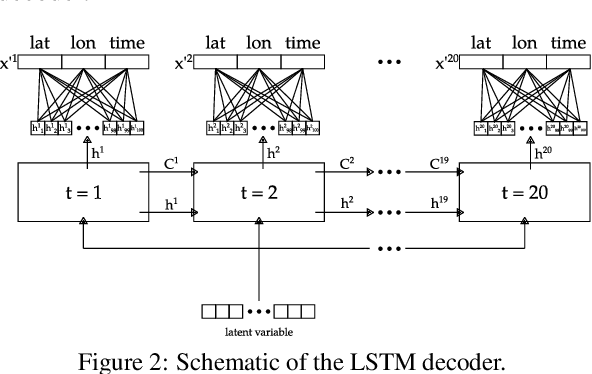
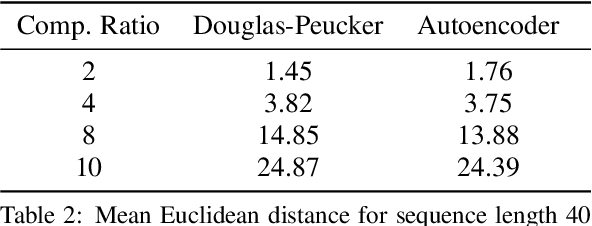
The ubiquitous availability of mobile devices capable of location tracking led to a significant rise in the collection of GPS data. Several compression methods have been developed in order to reduce the amount of storage needed while keeping the important information. In this paper, we present an lstm-autoencoder based approach in order to compress and reconstruct GPS trajectories, which is evaluated on both a gaming and real-world dataset. We consider various compression ratios and trajectory lengths. The performance is compared to other trajectory compression algorithms, i.e., Douglas-Peucker. Overall, the results indicate that our approach outperforms Douglas-Peucker significantly in terms of the discrete Fr\'echet distance and dynamic time warping. Furthermore, by reconstructing every point lossy, the proposed methodology offers multiple advantages over traditional methods.
Correlation Clustering Algorithm for Dynamic Complete Signed Graphs: An Index-based Approach
Jan 01, 2023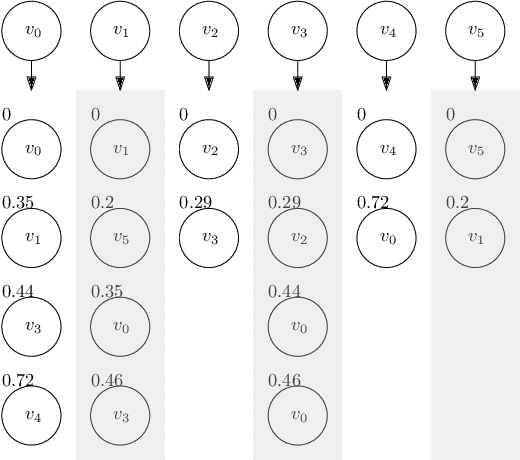
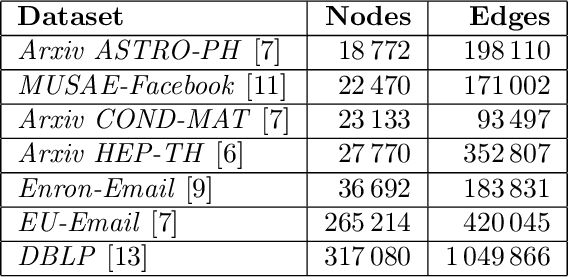
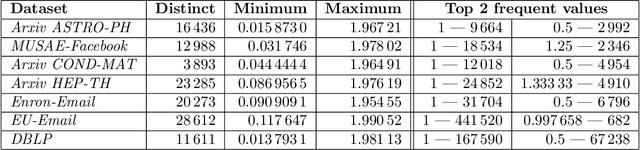
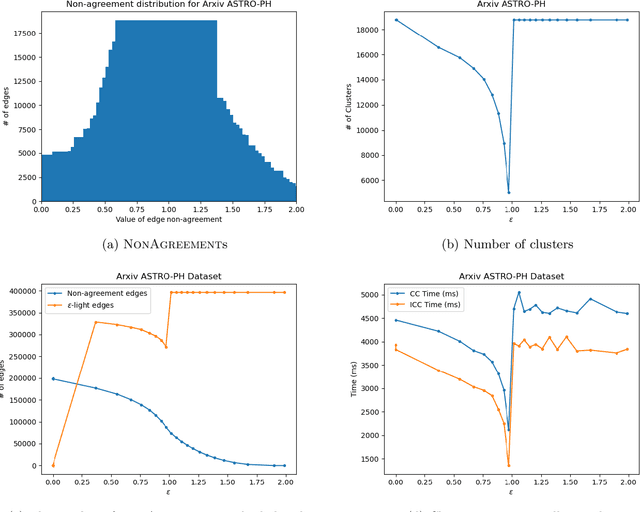
In this paper, we reduce the complexity of approximating the correlation clustering problem from $O(m\times\left( 2+ \alpha (G) \right)+n)$ to $O(m+n)$ for any given value of $\varepsilon$ for a complete signed graph with $n$ vertices and $m$ positive edges where $\alpha(G)$ is the arboricity of the graph. Our approach gives the same output as the original algorithm and makes it possible to implement the algorithm in a full dynamic setting where edge sign flipping and vertex addition/removal are allowed. Constructing this index costs $O(m)$ memory and $O(m\times\alpha(G))$ time. We also studied the structural properties of the non-agreement measure used in the approximation algorithm. The theoretical results are accompanied by a full set of experiments concerning seven real-world graphs. These results shows superiority of our index-based algorithm to the non-index one by a decrease of %34 in time on average.
OTFS-SCMA: A Downlink NOMA Scheme for Massive Connectivity in High Mobility Channels
Jan 03, 2023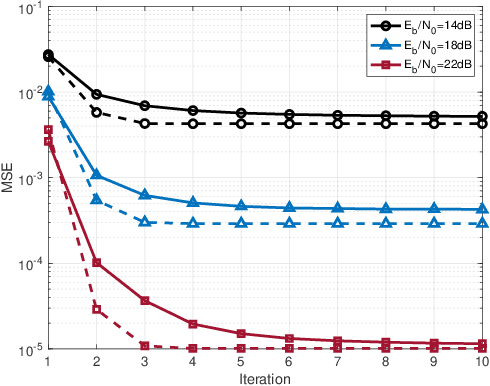
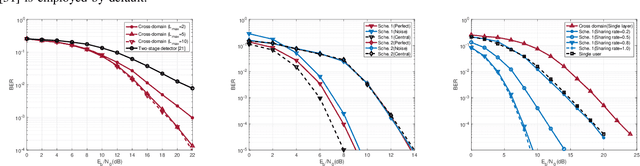
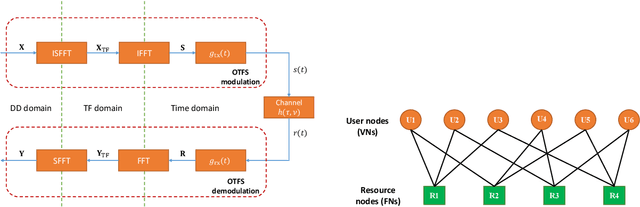
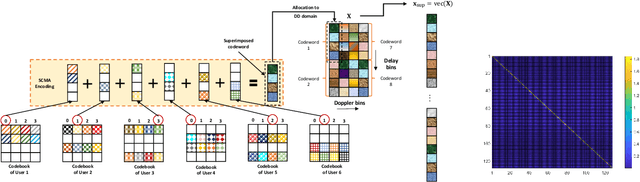
This paper studies a downlink system that combines orthogonal-time-frequency-space (OTFS) modulation and sparse code multiple access (SCMA) to support massive connectivity in high-mobility environments. We propose a cross-domain receiver for the considered OTFS-SCMA system which efficiently carries out OTFS symbol estimation and SCMA decoding in a joint manner. This is done by iteratively passing the extrinsic information between the time domain and the delay-Doppler (DD) domain via the corresponding unitary transformation to ensure the principal orthogonality of errors from each domain. We show that the proposed OTFS-SCMA detection algorithm exists at a fixed point in the state evolution when it converges. To further enhance the error performance of the proposed OTFS-SCMA system, we investigate the cooperation between downlink users to exploit the diversity gains and develop a distributed cooperative detection (DCD) algorithm with the aid of belief consensus. Our numerical results demonstrate the effectiveness and convergence of the proposed algorithm and show an increased spectral efficiency compared to the conventional OTFS transmission.
Training a Deep Q-Learning Agent Inside a Generic Constraint Programming Solver
Jan 05, 2023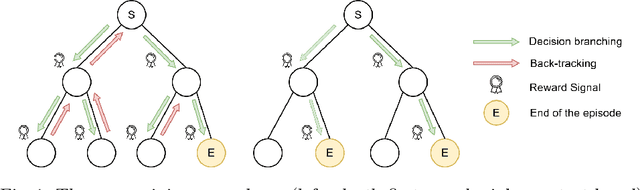
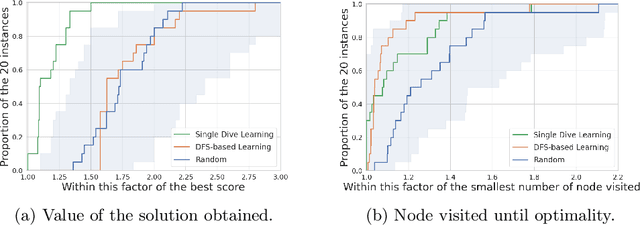
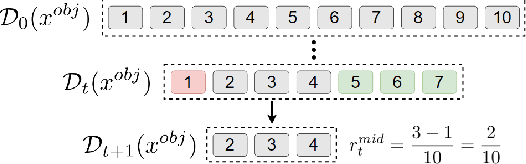
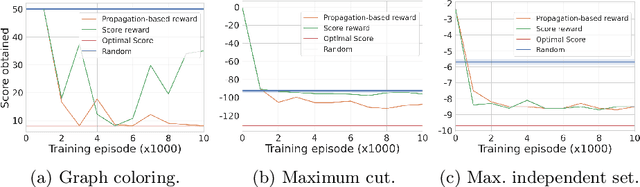
Constraint programming is known for being an efficient approach for solving combinatorial problems. Important design choices in a solver are the branching heuristics, which are designed to lead the search to the best solutions in a minimum amount of time. However, developing these heuristics is a time-consuming process that requires problem-specific expertise. This observation has motivated many efforts to use machine learning to automatically learn efficient heuristics without expert intervention. To the best of our knowledge, it is still an open research question. Although several generic variable-selection heuristics are available in the literature, the options for a generic value-selection heuristic are more scarce. In this paper, we propose to tackle this issue by introducing a generic learning procedure that can be used to obtain a value-selection heuristic inside a constraint programming solver. This has been achieved thanks to the combination of a deep Q-learning algorithm, a tailored reward signal, and a heterogeneous graph neural network architecture. Experiments on graph coloring, maximum independent set, and maximum cut problems show that our framework is able to find better solutions close to optimality without requiring a large amounts of backtracks while being generic.
Geometric path augmentation for inference of sparsely observed stochastic nonlinear systems
Jan 19, 2023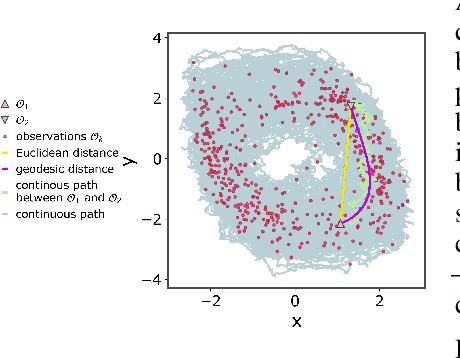
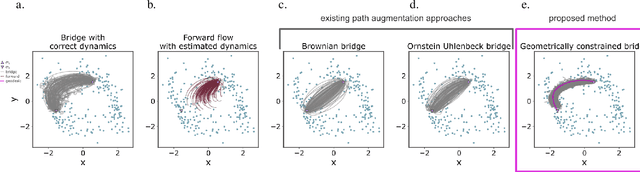
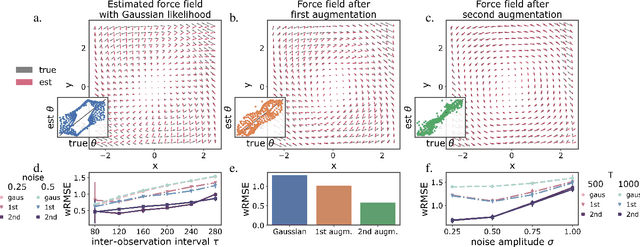
Stochastic evolution equations describing the dynamics of systems under the influence of both deterministic and stochastic forces are prevalent in all fields of science. Yet, identifying these systems from sparse-in-time observations remains still a challenging endeavour. Existing approaches focus either on the temporal structure of the observations by relying on conditional expectations, discarding thereby information ingrained in the geometry of the system's invariant density; or employ geometric approximations of the invariant density, which are nevertheless restricted to systems with conservative forces. Here we propose a method that reconciles these two paradigms. We introduce a new data-driven path augmentation scheme that takes the local observation geometry into account. By employing non-parametric inference on the augmented paths, we can efficiently identify the deterministic driving forces of the underlying system for systems observed at low sampling rates.
Warning: Humans Cannot Reliably Detect Speech Deepfakes
Jan 19, 2023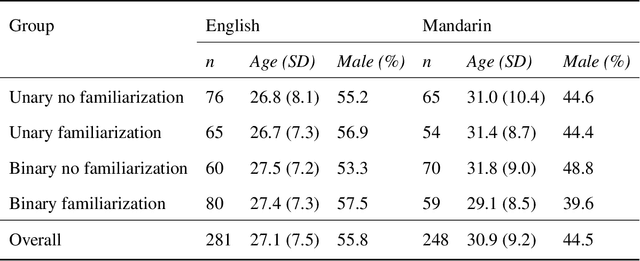
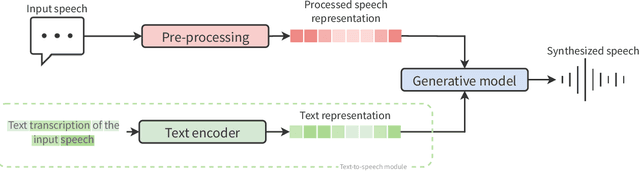
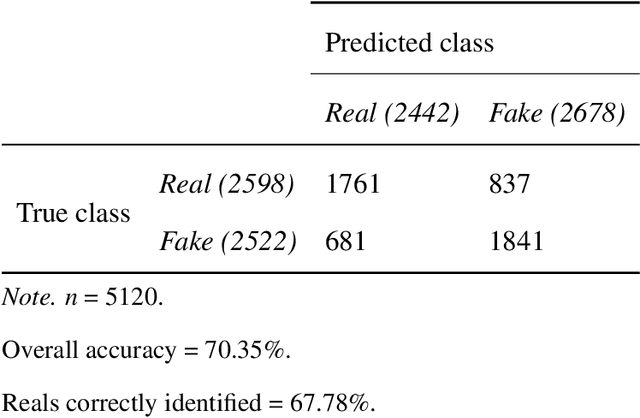
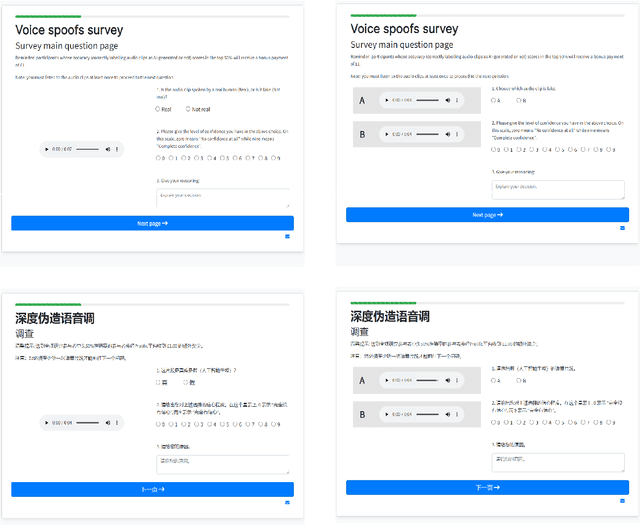
Speech deepfakes are artificial voices generated by machine learning models. Previous literature has highlighted deepfakes as one of the biggest threats to security arising from progress in AI due to their potential for misuse. However, studies investigating human detection capabilities are limited. We presented genuine and deepfake audio to $n$ = 529 individuals and asked them to identify the deepfakes. We ran our experiments in English and Mandarin to understand if language affects detection performance and decision-making rationale. Detection capability is unreliable. Listeners only correctly spotted the deepfakes 73% of the time, and there was no difference in detectability between the two languages. Increasing listener awareness by providing examples of speech deepfakes only improves results slightly. The difficulty of detecting speech deepfakes confirms their potential for misuse and signals that defenses against this threat are needed.
Exploration with Model Uncertainty at Extreme Scale in Real-Time Bidding
Aug 03, 2022In this work, we present a scalable and efficient system for exploring the supply landscape in real-time bidding. The system directs exploration based on the predictive uncertainty of models used for click-through rate prediction and works in a high-throughput, low-latency environment. Through online A/B testing, we demonstrate that exploration with model uncertainty has a positive impact on model performance and business KPIs.
Exploiting High Performance Spiking Neural Networks with Efficient Spiking Patterns
Jan 29, 2023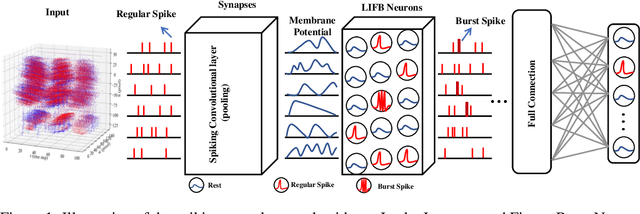
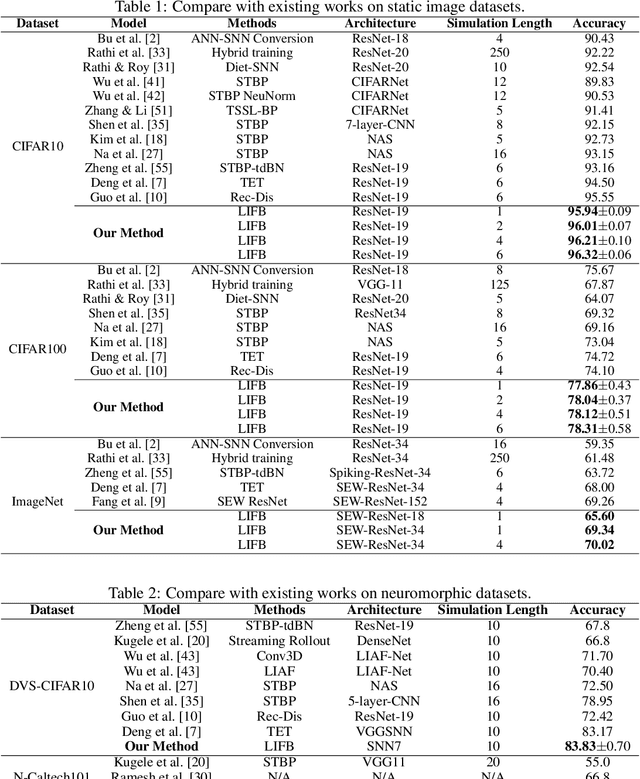
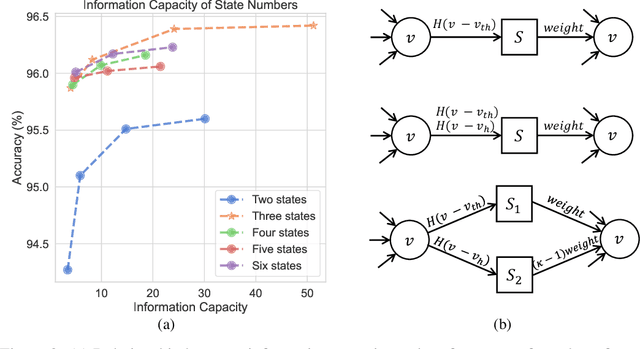
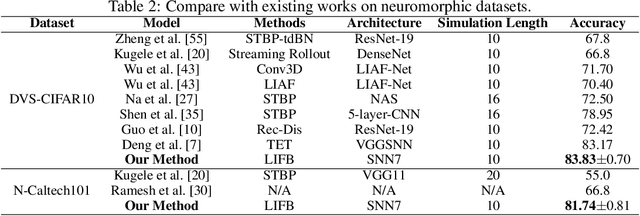
Spiking Neural Networks (SNNs) use discrete spike sequences to transmit information, which significantly mimics the information transmission of the brain. Although this binarized form of representation dramatically enhances the energy efficiency and robustness of SNNs, it also leaves a large gap between the performance of SNNs and Artificial Neural Networks based on real values. There are many different spike patterns in the brain, and the dynamic synergy of these spike patterns greatly enriches the representation capability. Inspired by spike patterns in biological neurons, this paper introduces the dynamic Burst pattern and designs the Leaky Integrate and Fire or Burst (LIFB) neuron that can make a trade-off between short-time performance and dynamic temporal performance from the perspective of network information capacity. LIFB neuron exhibits three modes, resting, Regular spike, and Burst spike. The burst density of the neuron can be adaptively adjusted, which significantly enriches the characterization capability. We also propose a decoupling method that can losslessly decouple LIFB neurons into equivalent LIF neurons, which demonstrates that LIFB neurons can be efficiently implemented on neuromorphic hardware. We conducted experiments on the static datasets CIFAR10, CIFAR100, and ImageNet, which showed that we greatly improved the performance of the SNNs while significantly reducing the network latency. We also conducted experiments on neuromorphic datasets DVS-CIFAR10 and NCALTECH101 and showed that we achieved state-of-the-art with a small network structure.