 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Imitation Learning-Based Online Time-Optimal Control with Multiple-Waypoint Constraints for Quadrotors
Feb 18, 2024
Over the past decade, there has been a remarkable surge in utilizing quadrotors for various purposes due to their simple structure and aggressive maneuverability, such as search and rescue, delivery and autonomous drone racing, etc. One of the key challenges preventing quadrotors from being widely used in these scenarios is online waypoint-constrained time-optimal trajectory generation and control technique. This letter proposes an imitation learning-based online solution to efficiently navigate the quadrotor through multiple waypoints with time-optimal performance. The neural networks (WN&CNets) are trained to learn the control law from the dataset generated by the time-consuming CPC algorithm and then deployed to generate the optimal control commands online to guide the quadrotors. To address the challenge of limited training data and the hover maneuver at the final waypoint, we propose a transition phase strategy that utilizes polynomials to help the quadrotor 'jump over' the stop-and-go maneuver when switching waypoints. Our method is demonstrated in both simulation and real-world experiments, achieving a maximum speed of 7 m/s while navigating through 7 waypoints in a confined space of 6.0 m * 4.0 m * 2.0 m. The results show that with a slight loss in optimality, the WN&CNets significantly reduce the processing time and enable online optimal control for multiple-waypoint-constrained flight tasks.
Only the Curve Shape Matters: Training Foundation Models for Zero-Shot Multivariate Time Series Forecasting through Next Curve Shape Prediction
Feb 19, 2024We present General Time Transformer (GTT), an encoder-only style foundation model for zero-shot multivariate time series forecasting. GTT is pretrained on a large dataset of 200M high-quality time series samples spanning diverse domains. In our proposed framework, the task of multivariate time series forecasting is formulated as a channel-wise next curve shape prediction problem, where each time series sample is represented as a sequence of non-overlapping curve shapes with a unified numerical magnitude. GTT is trained to predict the next curve shape based on a window of past curve shapes in a channel-wise manner. Experimental results demonstrate that GTT exhibits superior zero-shot multivariate forecasting capabilities on unseen time series datasets, even surpassing state-of-the-art supervised baselines. Additionally, we investigate the impact of varying GTT model parameters and training dataset scales, observing that the scaling law also holds in the context of zero-shot multivariate time series forecasting.
Competitive Facility Location under Random Utilities and Routing Constraints
Mar 09, 2024
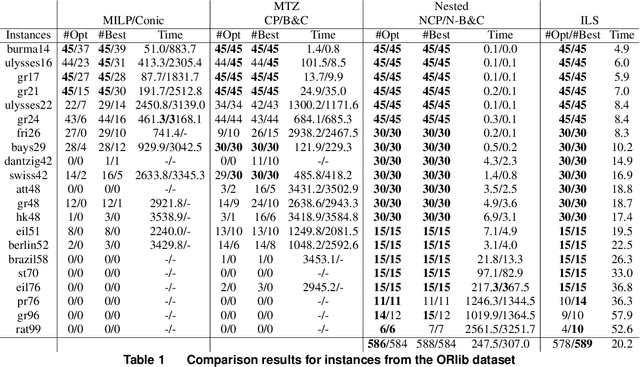
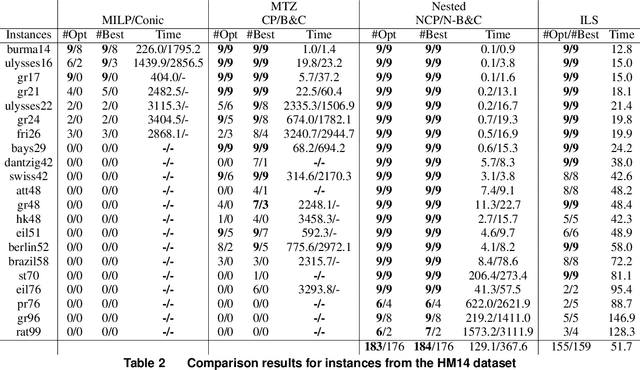
In this paper, we study a facility location problem within a competitive market context, where customer demand is predicted by a random utility choice model. Unlike prior research, which primarily focuses on simple constraints such as a cardinality constraint on the number of selected locations, we introduce routing constraints that necessitate the selection of locations in a manner that guarantees the existence of a tour visiting all chosen locations while adhering to a specified tour length upper bound. Such routing constraints find crucial applications in various real-world scenarios. The problem at hand features a non-linear objective function, resulting from the utilization of random utilities, together with complex routing constraints, making it computationally challenging. To tackle this problem, we explore three types of valid cuts, namely, outer-approximation and submodular cuts to handle the nonlinear objective function, as well as sub-tour elimination cuts to address the complex routing constraints. These lead to the development of two exact solution methods: a nested cutting plane and nested branch-and-cut algorithms, where these valid cuts are iteratively added to a master problem through two nested loops. We also prove that our nested cutting plane method always converges to optimality after a finite number of iterations. Furthermore, we develop a local search-based metaheuristic tailored for solving large-scale instances and show its pros and cons compared to exact methods. Extensive experiments are conducted on problem instances of varying sizes, demonstrating that our approach excels in terms of solution quality and computation time when compared to other baseline approaches.
Towards Optimizing Human-Centric Objectives in AI-Assisted Decision-Making With Offline Reinforcement Learning
Mar 09, 2024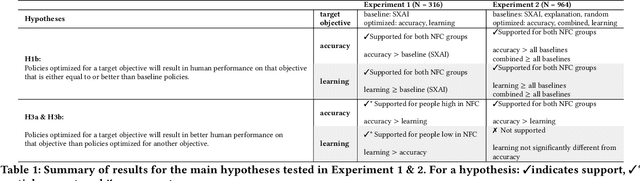
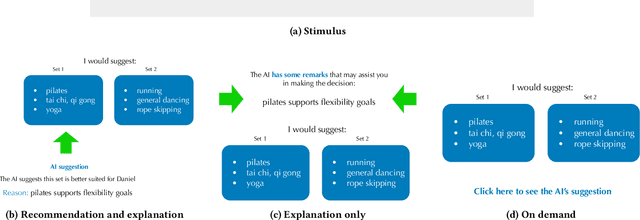
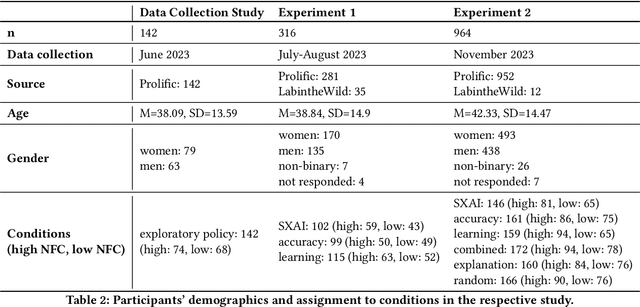
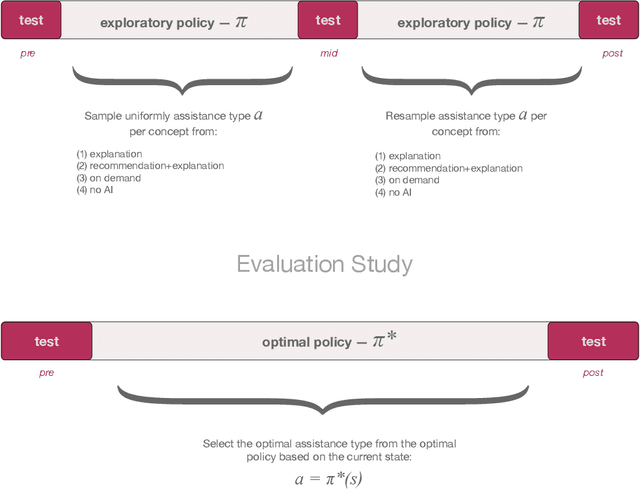
As AI assistance is increasingly infused into decision-making processes, we may seek to optimize human-centric objectives beyond decision accuracy, such as skill improvement or task enjoyment of individuals interacting with these systems. With this aspiration in mind, we propose offline reinforcement learning (RL) as a general approach for modeling human-AI decision-making to optimize such human-centric objectives. Our approach seeks to optimize different objectives by adaptively providing decision support to humans -- the right type of assistance, to the right person, at the right time. We instantiate our approach with two objectives: human-AI accuracy on the decision-making task and human learning about the task, and learn policies that optimize these two objectives from previous human-AI interaction data. We compare the optimized policies against various baselines in AI-assisted decision-making. Across two experiments (N = 316 and N = 964), our results consistently demonstrate that people interacting with policies optimized for accuracy achieve significantly better accuracy -- and even human-AI complementarity -- compared to those interacting with any other type of AI support. Our results further indicate that human learning is more difficult to optimize than accuracy, with participants who interacted with learning-optimized policies showing significant learning improvement only at times. Our research (1) demonstrates offline RL to be a promising approach to model dynamics of human-AI decision-making, leading to policies that may optimize various human-centric objectives and provide novel insights about the AI-assisted decision-making space, and (2) emphasizes the importance of considering human-centric objectives beyond decision accuracy in AI-assisted decision-making, while also opening up the novel research challenge of optimizing such objectives.
Finding Waldo: Towards Efficient Exploration of NeRF Scene Spaces
Mar 08, 2024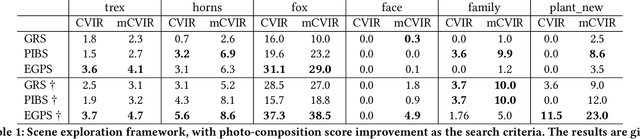

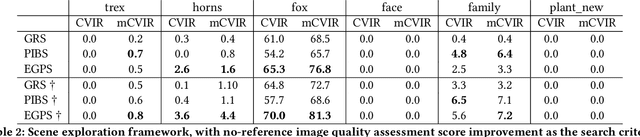

Neural Radiance Fields (NeRF) have quickly become the primary approach for 3D reconstruction and novel view synthesis in recent years due to their remarkable performance. Despite the huge interest in NeRF methods, a practical use case of NeRFs has largely been ignored; the exploration of the scene space modelled by a NeRF. In this paper, for the first time in the literature, we propose and formally define the scene exploration framework as the efficient discovery of NeRF model inputs (i.e. coordinates and viewing angles), using which one can render novel views that adhere to user-selected criteria. To remedy the lack of approaches addressing scene exploration, we first propose two baseline methods called Guided-Random Search (GRS) and Pose Interpolation-based Search (PIBS). We then cast scene exploration as an optimization problem, and propose the criteria-agnostic Evolution-Guided Pose Search (EGPS) for efficient exploration. We test all three approaches with various criteria (e.g. saliency maximization, image quality maximization, photo-composition quality improvement) and show that our EGPS performs more favourably than other baselines. We finally highlight key points and limitations, and outline directions for future research in scene exploration.
MamMIL: Multiple Instance Learning for Whole Slide Images with State Space Models
Mar 08, 2024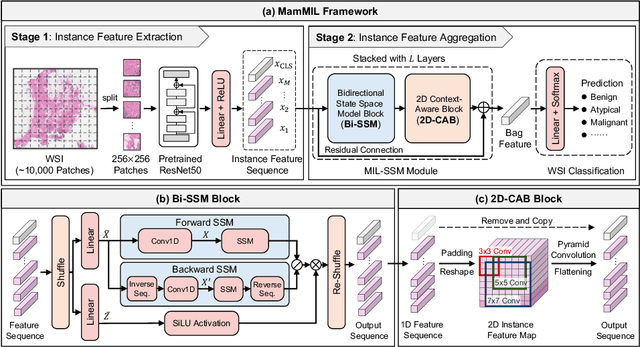
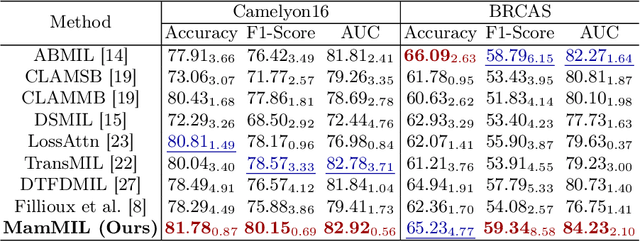
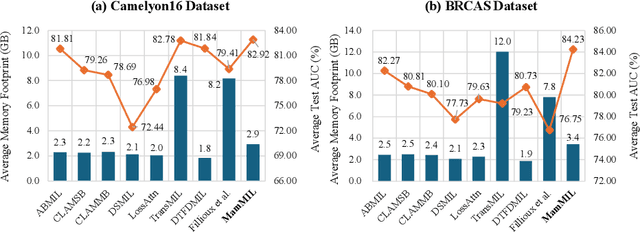
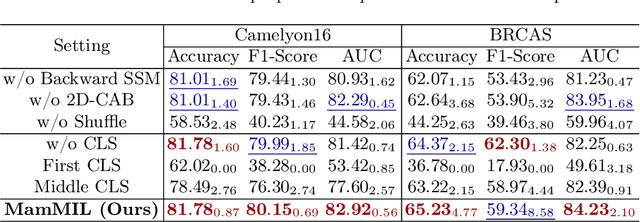
Recently, pathological diagnosis, the gold standard for cancer diagnosis, has achieved superior performance by combining the Transformer with the multiple instance learning (MIL) framework using whole slide images (WSIs). However, the giga-pixel nature of WSIs poses a great challenge for the quadratic-complexity self-attention mechanism in Transformer to be applied in MIL. Existing studies usually use linear attention to improve computing efficiency but inevitably bring performance bottlenecks. To tackle this challenge, we propose a MamMIL framework for WSI classification by cooperating the selective structured state space model (i.e., Mamba) with MIL for the first time, enabling the modeling of instance dependencies while maintaining linear complexity. Specifically, to solve the problem that Mamba can only conduct unidirectional one-dimensional (1D) sequence modeling, we innovatively introduce a bidirectional state space model and a 2D context-aware block to enable MamMIL to learn the bidirectional instance dependencies with 2D spatial relationships. Experiments on two datasets show that MamMIL can achieve advanced classification performance with smaller memory footprints than the state-of-the-art MIL frameworks based on the Transformer. The code will be open-sourced if accepted.
Prepared for the Worst: A Learning-Based Adversarial Attack for Resilience Analysis of the ICP Algorithm
Mar 08, 2024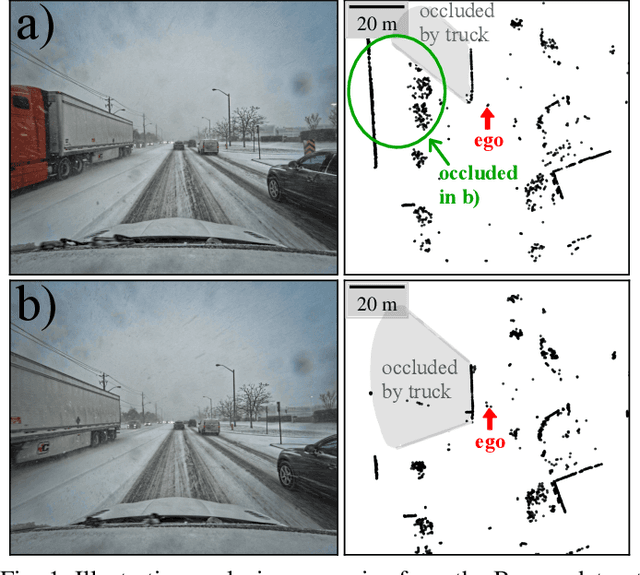
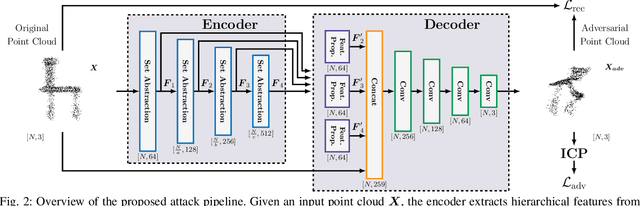
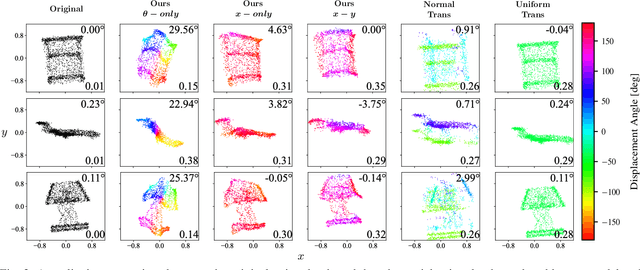
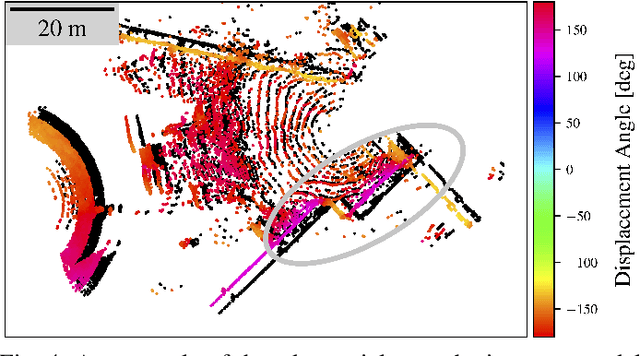
This paper presents a novel method to assess the resilience of the Iterative Closest Point (ICP) algorithm via deep-learning-based attacks on lidar point clouds. For safety-critical applications such as autonomous navigation, ensuring the resilience of algorithms prior to deployments is of utmost importance. The ICP algorithm has become the standard for lidar-based localization. However, the pose estimate it produces can be greatly affected by corruption in the measurements. Corruption can arise from a variety of scenarios such as occlusions, adverse weather, or mechanical issues in the sensor. Unfortunately, the complex and iterative nature of ICP makes assessing its resilience to corruption challenging. While there have been efforts to create challenging datasets and develop simulations to evaluate the resilience of ICP empirically, our method focuses on finding the maximum possible ICP pose error using perturbation-based adversarial attacks. The proposed attack induces significant pose errors on ICP and outperforms baselines more than 88% of the time across a wide range of scenarios. As an example application, we demonstrate that our attack can be used to identify areas on a map where ICP is particularly vulnerable to corruption in the measurements.
Eliciting Better Multilingual Structured Reasoning from LLMs through Code
Mar 05, 2024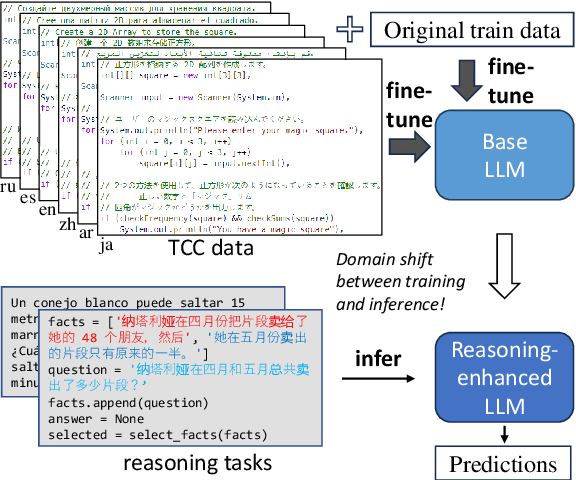
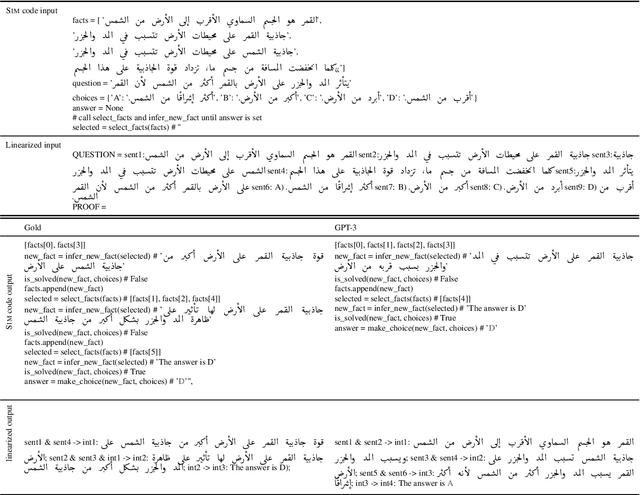
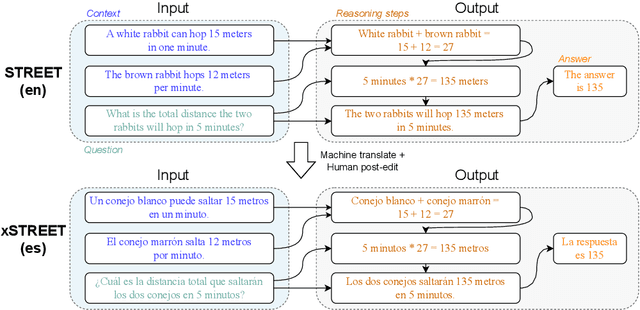
Development of large language models (LLM) have shown progress on reasoning, though studies have been limited to English or simple reasoning tasks. We thus introduce a multilingual structured reasoning and explanation dataset, termed xSTREET, that covers four tasks across six languages. xSTREET exposes a gap in base LLM performance between English and non-English reasoning tasks. We then propose two methods to remedy this gap, building on the insight that LLMs trained on code are better reasoners. First, at training time, we augment a code dataset with multi-lingual comments using machine translation while keeping program code as-is. Second, at inference time, we bridge the gap between training and inference by employing a prompt structure that incorporates step-by-step code primitives to derive new facts and find a solution. Our methods show improved multilingual performance on xSTREET, most notably on the scientific commonsense reasoning subtask. Furthermore, the models show no regression on non-reasoning tasks, thus showing our techniques maintain general-purpose abilities.
A Novel Theoretical Framework for Exponential Smoothing
Mar 07, 2024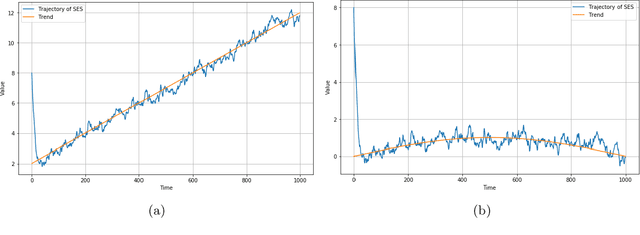
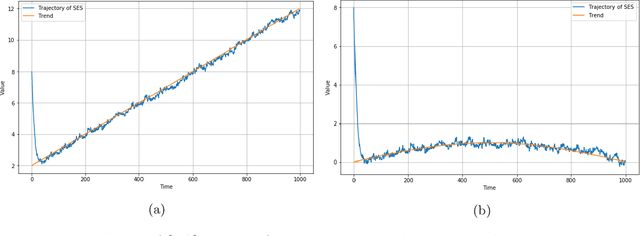
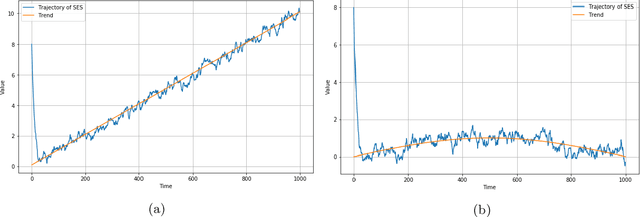
Simple Exponential Smoothing is a classical technique used for smoothing time series data by assigning exponentially decreasing weights to past observations through a recursive equation; it is sometimes presented as a rule of thumb procedure. We introduce a novel theoretical perspective where the recursive equation that defines simple exponential smoothing occurs naturally as a stochastic gradient ascent scheme to optimize a sequence of Gaussian log-likelihood functions. Under this lens of analysis, our main theorem shows that -- in a general setting -- simple exponential smoothing converges to a neighborhood of the trend of a trend-stationary stochastic process. This offers a novel theoretical assurance that the exponential smoothing procedure yields reliable estimators of the underlying trend shedding light on long-standing observations in the literature regarding the robustness of simple exponential smoothing.
Improvements & Evaluations on the MLCommons CloudMask Benchmark
Mar 07, 2024
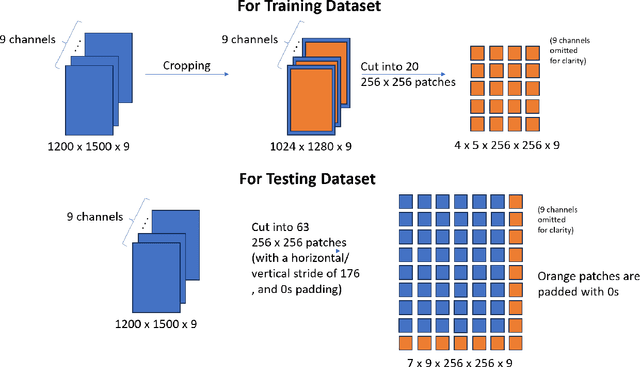
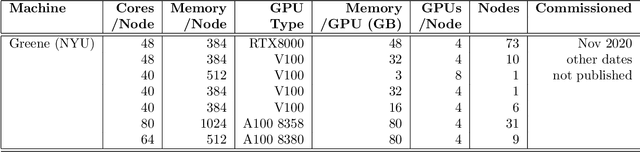
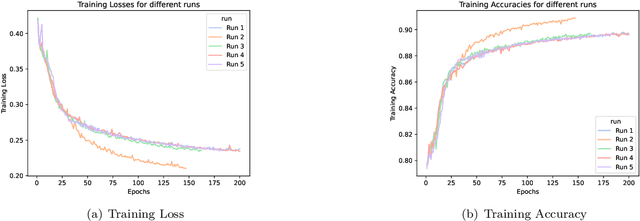
In this paper, we report the performance benchmarking results of deep learning models on MLCommons' Science cloud-masking benchmark using a high-performance computing cluster at New York University (NYU): NYU Greene. MLCommons is a consortium that develops and maintains several scientific benchmarks that can benefit from developments in AI. We provide a description of the cloud-masking benchmark task, updated code, and the best model for this benchmark when using our selected hyperparameter settings. Our benchmarking results include the highest accuracy achieved on the NYU system as well as the average time taken for both training and inference on the benchmark across several runs/seeds. Our code can be found on GitHub. MLCommons team has been kept informed about our progress and may use the developed code for their future work.