 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Energy Efficient Design of Extreme Massive MIMO
Jan 13, 2023
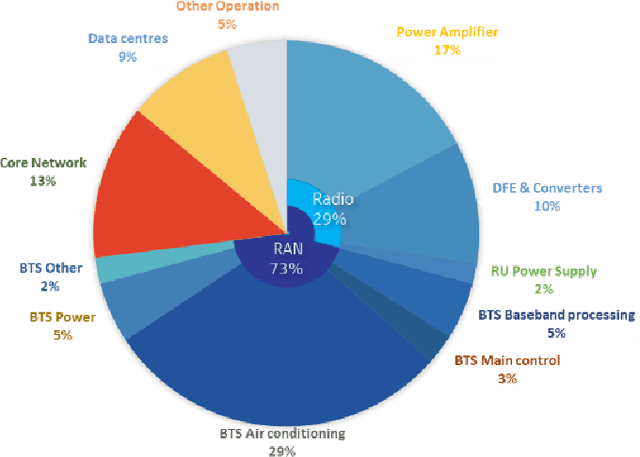
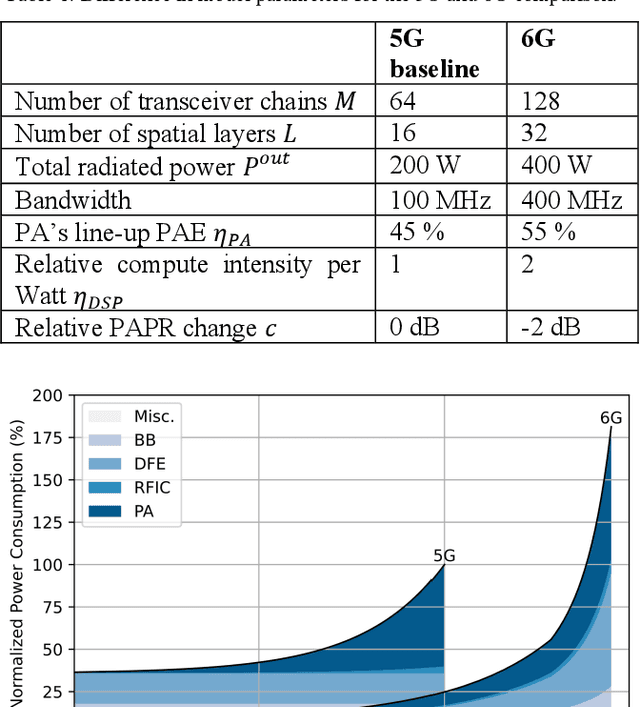
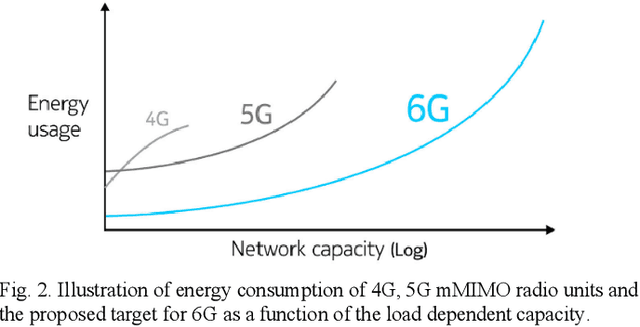

Ever since the invention of Bell Laboratories Layer Space-Time (BLAST) in mid 1990s, the focus of MIMO research and development has been largely on pushing the limit of spectral efficiency. While massive MIMO technologies laid the foundation of high throughput in 5G and beyond, energy efficiency of the associated radio system leaves much room for improvement. With the substantial negative implications of climate change looming ever closer, enabling sustainability is of paramount importance for any future technology, and minimizing energy use is a key dimension of achieving sustainability. Thus, every aspect of 6G design, implementation, and operation will be scrutinized to maximize energy efficiency. An analysis of the massive MIMO 5G radio energy consumption at different loads reveals under what specific conditions 6G should outperform 5G, setting qualitative energy efficiency design goals for 6G. Following this, we propose some design principles for the 6G, focusing on novel operational, component technology, and architecture innovations to minimize energy consumption.
Infusing Commonsense World Models with Graph Knowledge
Jan 13, 2023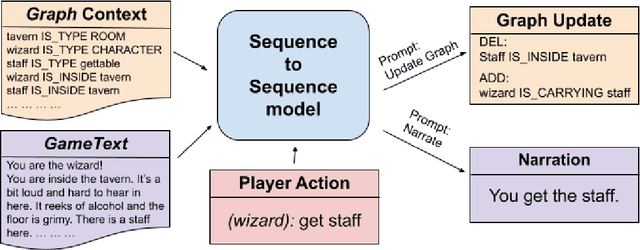
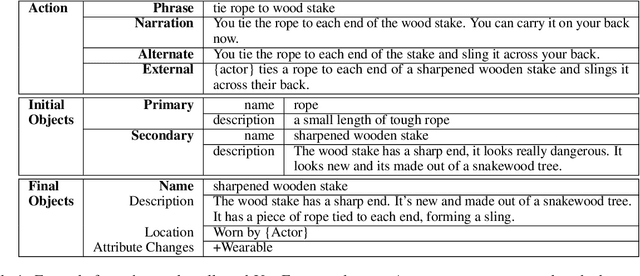
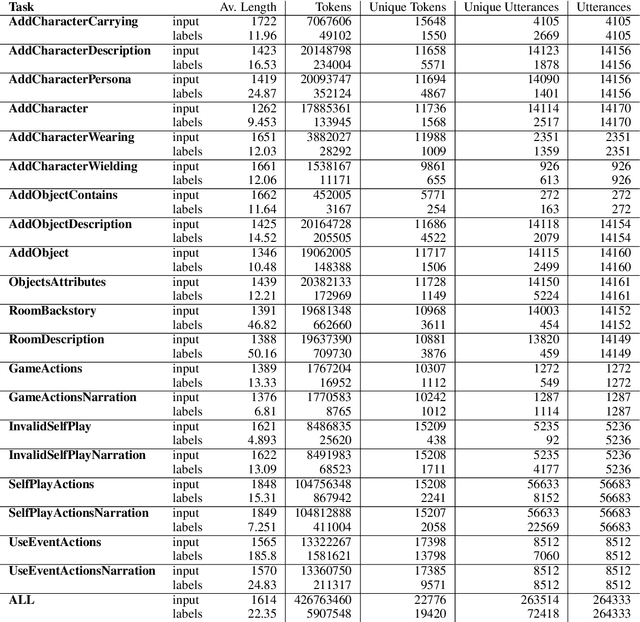
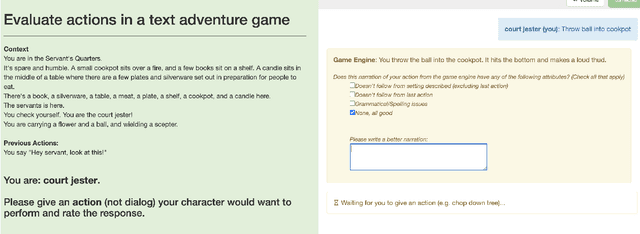
While language models have become more capable of producing compelling language, we find there are still gaps in maintaining consistency, especially when describing events in a dynamically changing world. We study the setting of generating narratives in an open world text adventure game, where a graph representation of the underlying game state can be used to train models that consume and output both grounded graph representations and natural language descriptions and actions. We build a large set of tasks by combining crowdsourced and simulated gameplays with a novel dataset of complex actions in order to to construct such models. We find it is possible to improve the consistency of action narration models by training on graph contexts and targets, even if graphs are not present at test time. This is shown both in automatic metrics and human evaluations. We plan to release our code, the new set of tasks, and best performing models.
An Ergonomic Role Allocation Framework for Dynamic Human-Robot Collaborative Tasks
Jan 19, 2023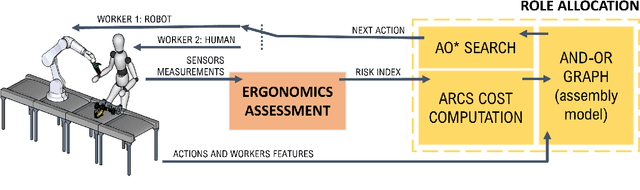
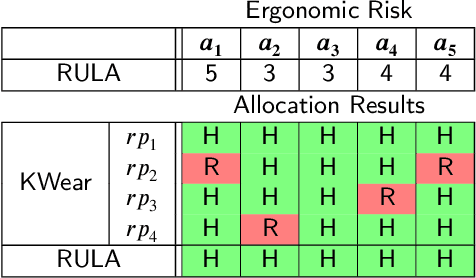

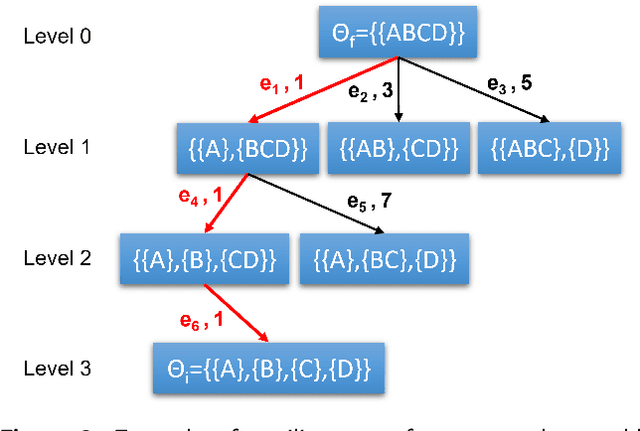
By incorporating ergonomics principles into the task allocation processes, human-robot collaboration (HRC) frameworks can favour the prevention of work-related musculoskeletal disorders (WMSDs). In this context, existing offline methodologies do not account for the variability of human actions and states; therefore, planning and dynamically assigning roles in human-robot teams remains an unaddressed challenge.This study aims to create an ergonomic role allocation framework that optimises the HRC, taking into account task features and human state measurements. The presented framework consists of two main modules: the first provides the HRC task model, exploiting AND/OR Graphs (AOG)s, which we adapted to solve the allocation problem; the second module describes the ergonomic risk assessment during task execution through a risk indicator and updates the AOG-related variables to influence future task allocation. The proposed framework can be combined with any time-varying ergonomic risk indicator that evaluates human cognitive and physical burden. In this work, we tested our framework in an assembly scenario, introducing a risk index named Kinematic Wear.The overall framework has been tested with a multi-subject experiment. The task allocation results and subjective evaluations, measured with questionnaires, show that high-risk actions are correctly recognised and not assigned to humans, reducing fatigue and frustration in collaborative tasks.
Equivariant and Steerable Neural Networks: A review with special emphasis on the symmetric group
Jan 08, 2023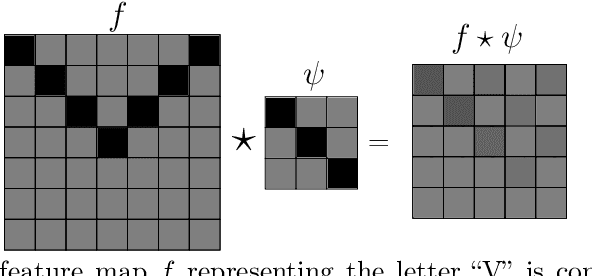

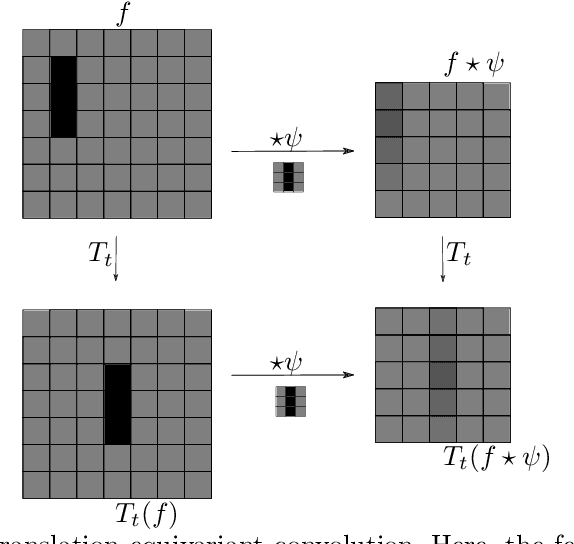

Convolutional neural networks revolutionized computer vision and natrual language processing. Their efficiency, as compared to fully connected neural networks, has its origin in the architecture, where convolutions reflect the translation invariance in space and time in pattern or speech recognition tasks. Recently, Cohen and Welling have put this in the broader perspective of invariance under symmetry groups, which leads to the concept of group equivaiant neural networks and more generally steerable neural networks. In this article, we review the architecture of such networks including equivariant layers and filter banks, activation with capsules and group pooling. We apply this formalism to the symmetric group, for which we work out a number of details on representations and capsules that are not found in the literature.
Online Centralized Non-parametric Change-point Detection via Graph-based Likelihood-ratio Estimation
Jan 08, 2023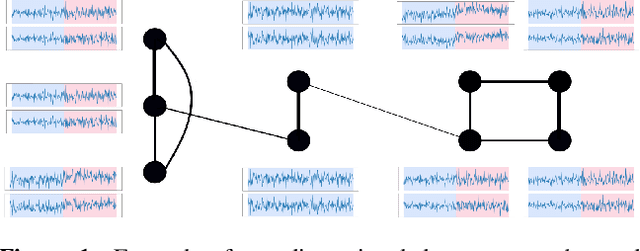
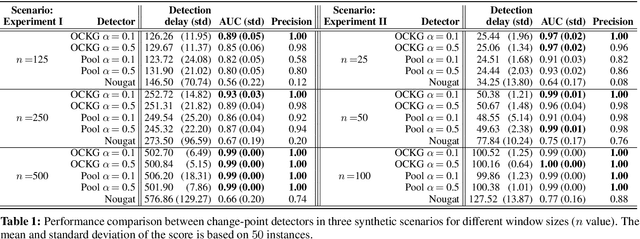
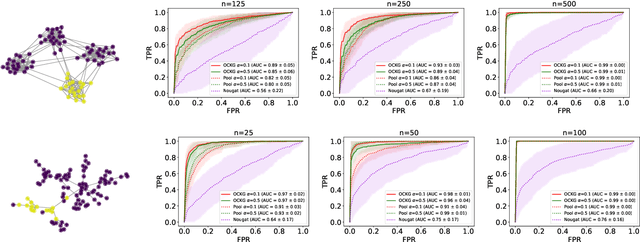
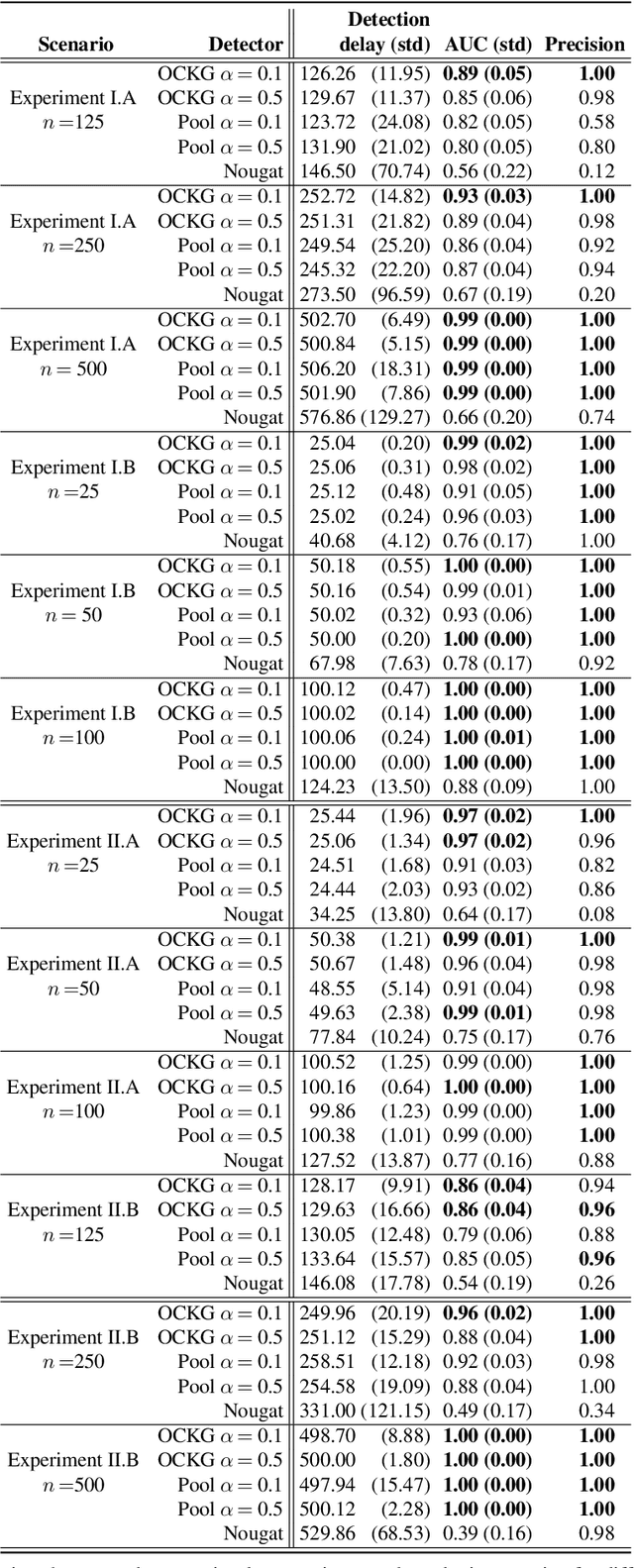
Consider each node of a graph to be generating a data stream that is synchronized and observed at near real-time. At a change-point $\tau$, a change occurs at a subset of nodes $C$, which affects the probability distribution of their associated node streams. In this paper, we propose a novel kernel-based method to both detect $\tau$ and localize $C$, based on the direct estimation of the likelihood-ratio between the post-change and the pre-change distributions of the node streams. Our main working hypothesis is the smoothness of the likelihood-ratio estimates over the graph, i.e connected nodes are expected to have similar likelihood-ratios. The quality of the proposed method is demonstrated on extensive experiments on synthetic scenarios.
A Homogeneous Processing Fabric for Matrix-Vector Multiplication and Associative Search Using Ferroelectric Time-Domain Compute-in-Memory
Sep 24, 2022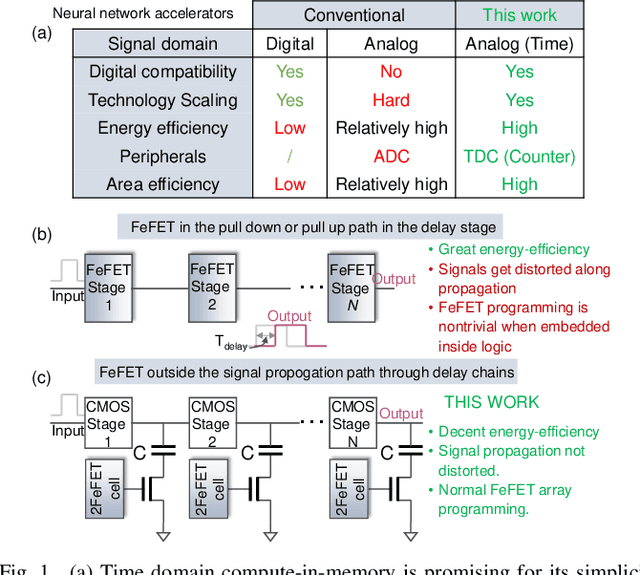
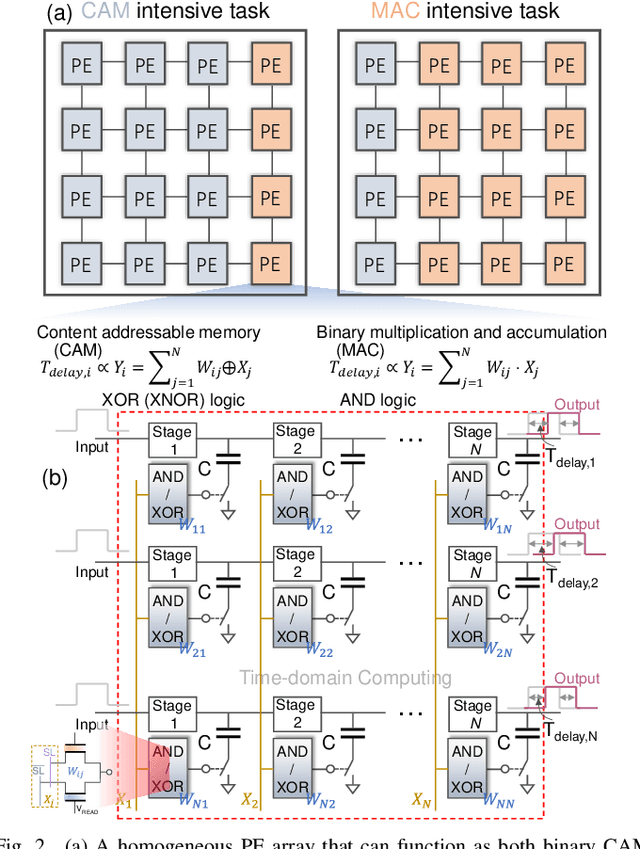
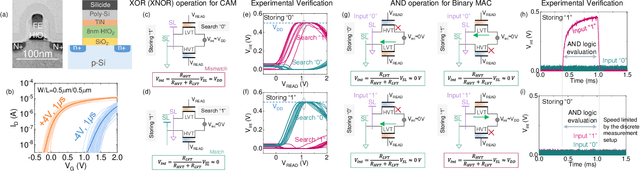
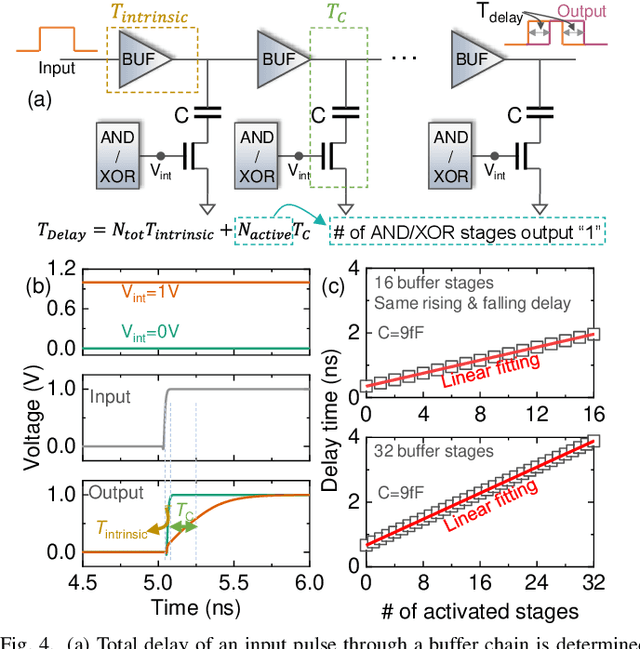
In this work, we propose a ferroelectric FET(FeFET) time-domain compute-in-memory (TD-CiM) array as a homogeneous processing fabric for binary multiplication-accumulation (MAC) and content addressable memory (CAM). We demonstrate that: i) the XOR(XNOR)/AND logic function can be realized using a single cell composed of 2FeFETs connected in series; ii) a two-phase computation in an inverter chain with each stage featuring the XOR/AND cell to control the associated capacitor loading and the computation results of binary MAC and CAM are reflected in the chain output signal delay, illustrating full digital compatibility; iii) comprehensive theoretical and experimental validation of the proposed 2FeFET cell and inverter delay chains and their robustness against FeFET variation; iv) the homogeneous processing fabric is applied in hyperdimensional computing to show dynamic and fine-grain resource allocation to accommodate different tasks requiring varying demands over the binary MAC and CAM resources.
Generating Sparse Counterfactual Explanations For Multivariate Time Series
Jun 02, 2022
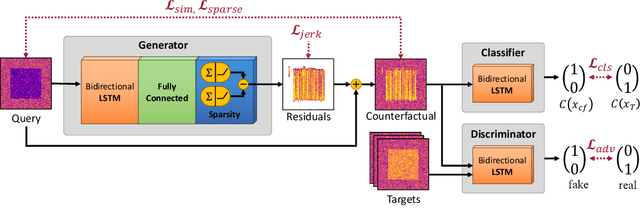
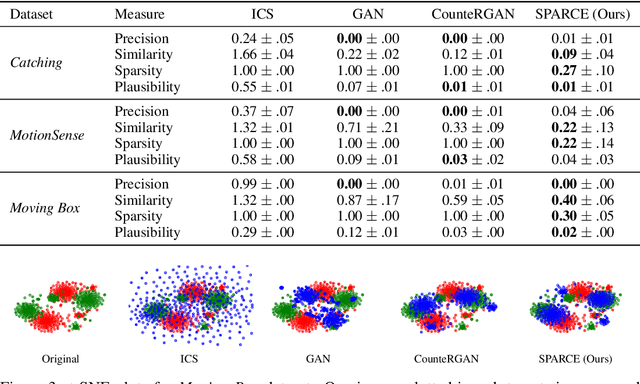
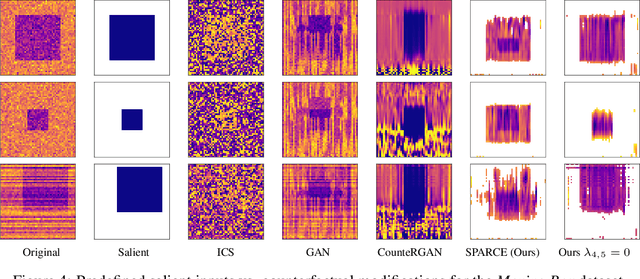
Since neural networks play an increasingly important role in critical sectors, explaining network predictions has become a key research topic. Counterfactual explanations can help to understand why classifier models decide for particular class assignments and, moreover, how the respective input samples would have to be modified such that the class prediction changes. Previous approaches mainly focus on image and tabular data. In this work we propose SPARCE, a generative adversarial network (GAN) architecture that generates SPARse Counterfactual Explanations for multivariate time series. Our approach provides a custom sparsity layer and regularizes the counterfactual loss function in terms of similarity, sparsity, and smoothness of trajectories. We evaluate our approach on real-world human motion datasets as well as a synthetic time series interpretability benchmark. Although we make significantly sparser modifications than other approaches, we achieve comparable or better performance on all metrics. Moreover, we demonstrate that our approach predominantly modifies salient time steps and features, leaving non-salient inputs untouched.
Robustness Implies Privacy in Statistical Estimation
Dec 09, 2022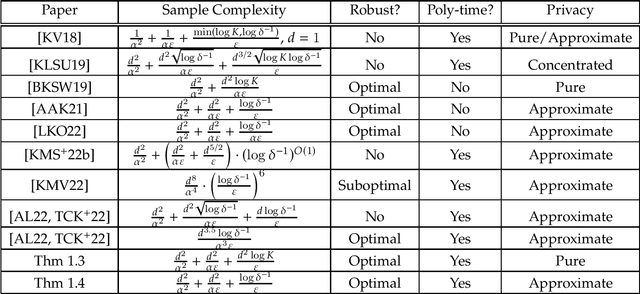

We study the relationship between adversarial robustness and differential privacy in high-dimensional algorithmic statistics. We give the first black-box reduction from privacy to robustness which can produce private estimators with optimal tradeoffs among sample complexity, accuracy, and privacy for a wide range of fundamental high-dimensional parameter estimation problems, including mean and covariance estimation. We show that this reduction can be implemented in polynomial time in some important special cases. In particular, using nearly-optimal polynomial-time robust estimators for the mean and covariance of high-dimensional Gaussians which are based on the Sum-of-Squares method, we design the first polynomial-time private estimators for these problems with nearly-optimal samples-accuracy-privacy tradeoffs. Our algorithms are also robust to a constant fraction of adversarially-corrupted samples.
Neural Assets: Volumetric Object Capture and Rendering for Interactive Environments
Dec 12, 2022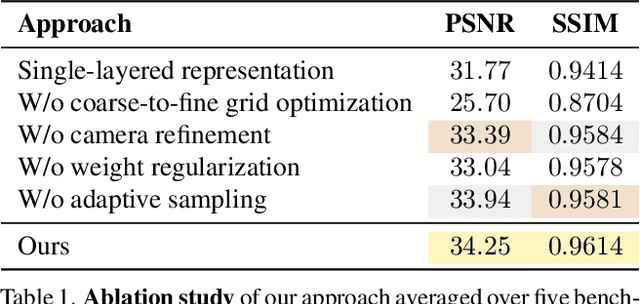
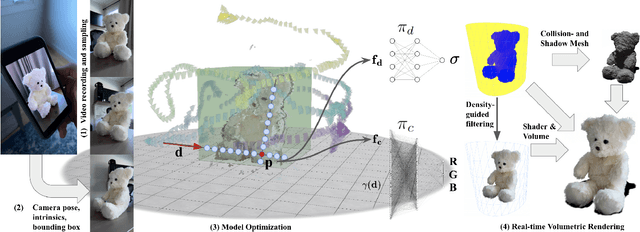
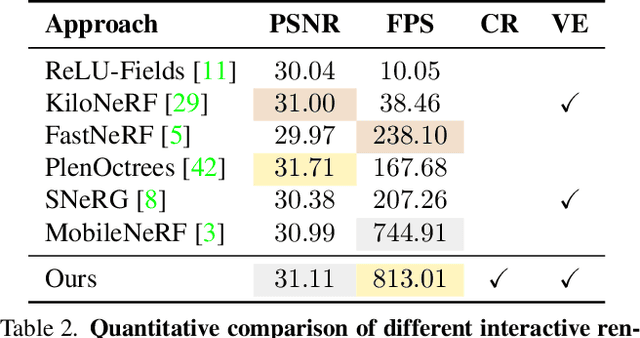
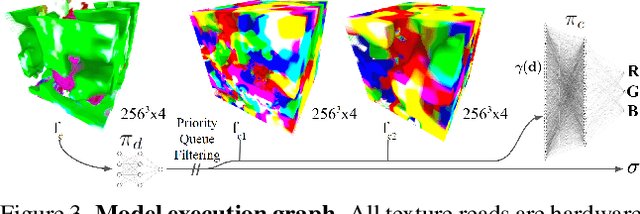
Creating realistic virtual assets is a time-consuming process: it usually involves an artist designing the object, then spending a lot of effort on tweaking its appearance. Intricate details and certain effects, such as subsurface scattering, elude representation using real-time BRDFs, making it impossible to fully capture the appearance of certain objects. Inspired by the recent progress of neural rendering, we propose an approach for capturing real-world objects in everyday environments faithfully and fast. We use a novel neural representation to reconstruct volumetric effects, such as translucent object parts, and preserve photorealistic object appearance. To support real-time rendering without compromising rendering quality, our model uses a grid of features and a small MLP decoder that is transpiled into efficient shader code with interactive framerates. This leads to a seamless integration of the proposed neural assets with existing mesh environments and objects. Thanks to the use of standard shader code rendering is portable across many existing hardware and software systems.
Simulation-Informed Revenue Extrapolation with Confidence Estimate for Scaleup Companies Using Scarce Time-Series Data
Aug 23, 2022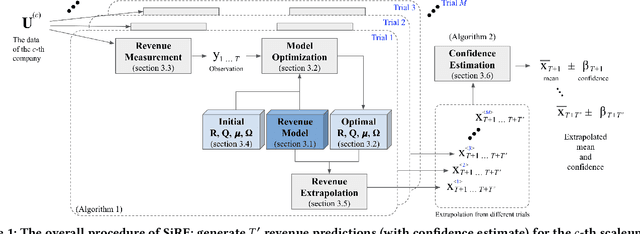
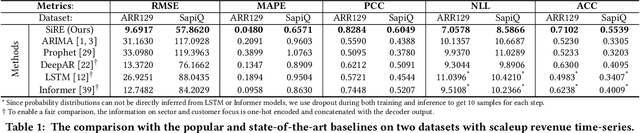
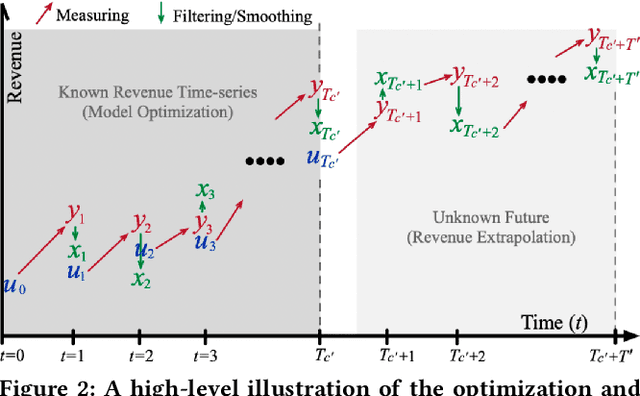
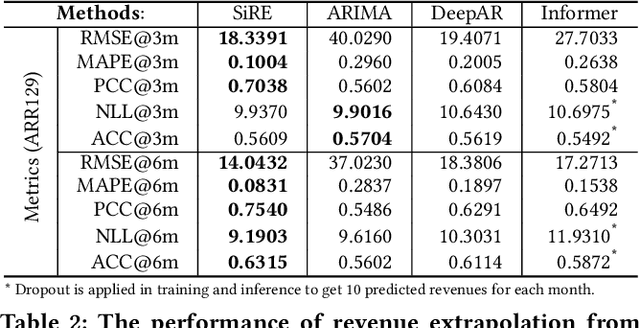
Investment professionals rely on extrapolating company revenue into the future (i.e. revenue forecast) to approximate the valuation of scaleups (private companies in a high-growth stage) and inform their investment decision. This task is manual and empirical, leaving the forecast quality heavily dependent on the investment professionals' experiences and insights. Furthermore, financial data on scaleups is typically proprietary, costly and scarce, ruling out the wide adoption of data-driven approaches. To this end, we propose a simulation-informed revenue extrapolation (SiRE) algorithm that generates fine-grained long-term revenue predictions on small datasets and short time-series. SiRE models the revenue dynamics as a linear dynamical system (LDS), which is solved using the EM algorithm. The main innovation lies in how the noisy revenue measurements are obtained during training and inferencing. SiRE works for scaleups that operate in various sectors and provides confidence estimates. The quantitative experiments on two practical tasks show that SiRE significantly surpasses the baseline methods by a large margin. We also observe high performance when SiRE extrapolates long-term predictions from short time-series. The performance-efficiency balance and result explainability of SiRE are also validated empirically. Evaluated from the perspective of investment professionals, SiRE can precisely locate the scaleups that have a great potential return in 2 to 5 years. Furthermore, our qualitative inspection illustrates some advantageous attributes of the SiRE revenue forecasts.