 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Passively Addressed Morphing Surface (PARMS) Based on Machine Learning
Jan 30, 2023
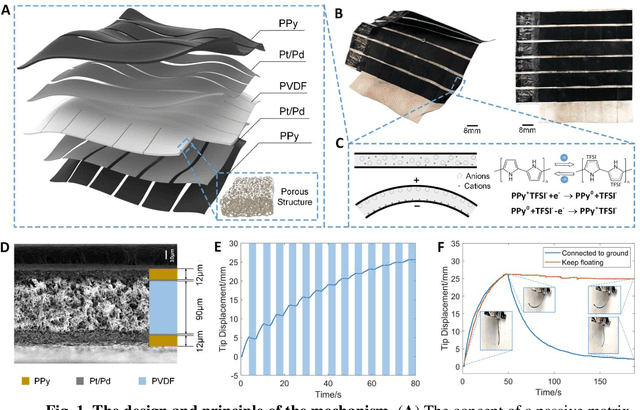


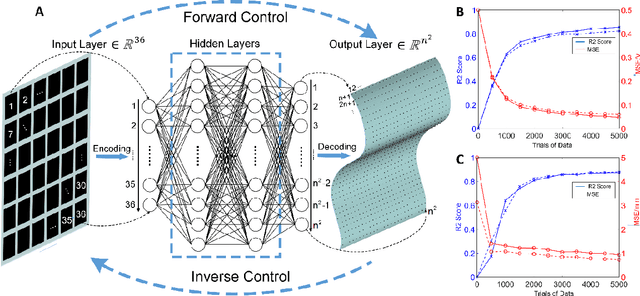
Reconfigurable morphing surfaces provide new opportunities for advanced human-machine interfaces and bio-inspired robotics. Morphing into arbitrary surfaces on demand requires a device with a sufficiently large number of actuators and an inverse control strategy that can calculate the actuator stimulation necessary to achieve a target surface. The programmability of a morphing surface can be improved by increasing the number of independent actuators, but this increases the complexity of the control system. Thus, developing compact and efficient control interfaces and control algorithms is a crucial knowledge gap for the adoption of morphing surfaces in broad applications. In this work, we describe a passively addressed robotic morphing surface (PARMS) composed of matrix-arranged ionic actuators. To reduce the complexity of the physical control interface, we introduce passive matrix addressing. Matrix addressing allows the control of independent actuators using only 2N control inputs, which is significantly lower than control inputs required for traditional direct addressing. Our control algorithm is based on machine learning using finite element simulations as the training data. This machine learning approach allows both forward and inverse control with high precision in real time. Inverse control demonstrations show that the PARMS can dynamically morph into arbitrary pre-defined surfaces on demand. These innovations in actuator matrix control may enable future implementation of PARMS in wearables, haptics, and augmented reality/virtual reality (AR/VR).
Long Short-Term Memory Neural Network for Temperature Prediction in Laser Powder Bed Additive Manufacturing
Jan 30, 2023In context of laser powder bed fusion (L-PBF), it is known that the properties of the final fabricated product highly depend on the temperature distribution and its gradient over the manufacturing plate. In this paper, we propose a novel means to predict the temperature gradient distributions during the printing process by making use of neural networks. This is realized by employing heat maps produced by an optimized printing protocol simulation and used for training a specifically tailored recurrent neural network in terms of a long short-term memory architecture. The aim of this is to avoid extreme and inhomogeneous temperature distribution that may occur across the plate in the course of the printing process. In order to train the neural network, we adopt a well-engineered simulation and unsupervised learning framework. To maintain a minimized average thermal gradient across the plate, a cost function is introduced as the core criteria, which is inspired and optimized by considering the well-known traveling salesman problem (TSP). As time evolves the unsupervised printing process governed by TSP produces a history of temperature heat maps that maintain minimized average thermal gradient. All in one, we propose an intelligent printing tool that provides control over the substantial printing process components for L-PBF, i.e.\ optimal nozzle trajectory deployment as well as online temperature prediction for controlling printing quality.
PCV: A Point Cloud-Based Network Verifier
Jan 30, 2023
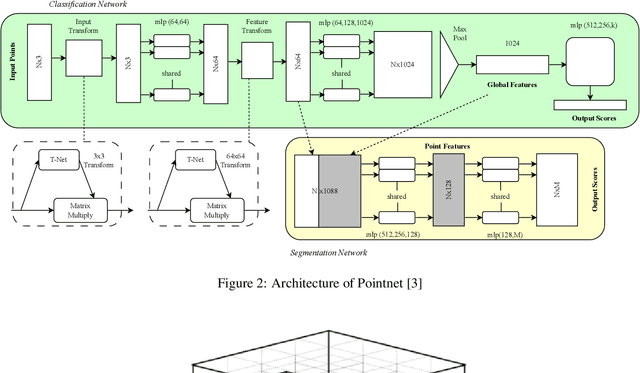
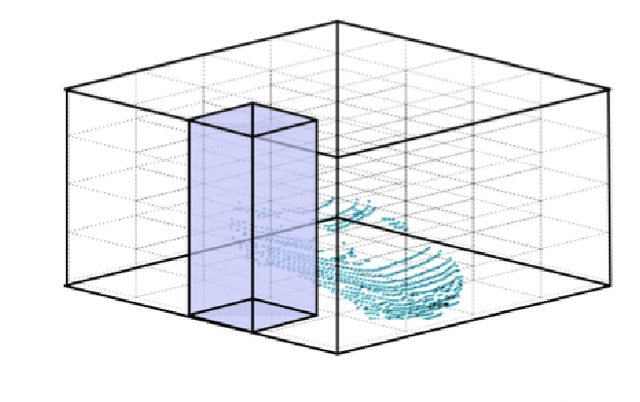
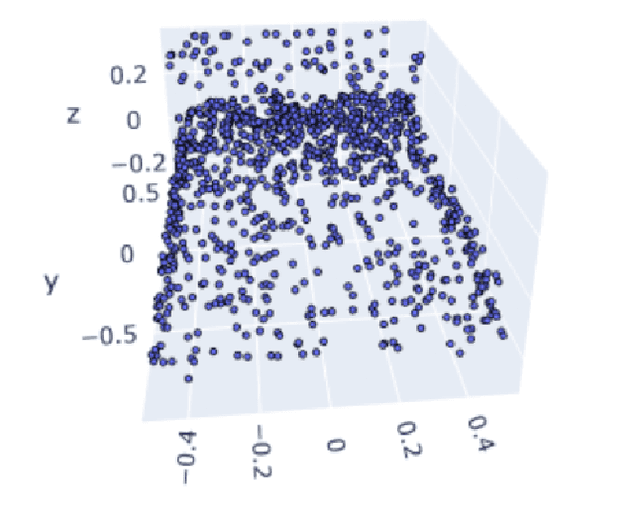
3D vision with real-time LiDAR-based point cloud data became a vital part of autonomous system research, especially perception and prediction modules use for object classification, segmentation, and detection. Despite their success, point cloud-based network models are vulnerable to multiple adversarial attacks, where the certain factor of changes in the validation set causes significant performance drop in well-trained networks. Most of the existing verifiers work perfectly on 2D convolution. Due to complex architecture, dimension of hyper-parameter, and 3D convolution, no verifiers can perform the basic layer-wise verification. It is difficult to conclude the robustness of a 3D vision model without performing the verification. Because there will be always corner cases and adversarial input that can compromise the model's effectiveness. In this project, we describe a point cloud-based network verifier that successfully deals state of the art 3D classifier PointNet verifies the robustness by generating adversarial inputs. We have used extracted properties from the trained PointNet and changed certain factors for perturbation input. We calculate the impact on model accuracy versus property factor and can test PointNet network's robustness against a small collection of perturbing input states resulting from adversarial attacks like the suggested hybrid reverse signed attack. The experimental results reveal that the resilience property of PointNet is affected by our hybrid reverse signed perturbation strategy
Efficient and Effective Methods for Mixed Precision Neural Network Quantization for Faster, Energy-efficient Inference
Jan 30, 2023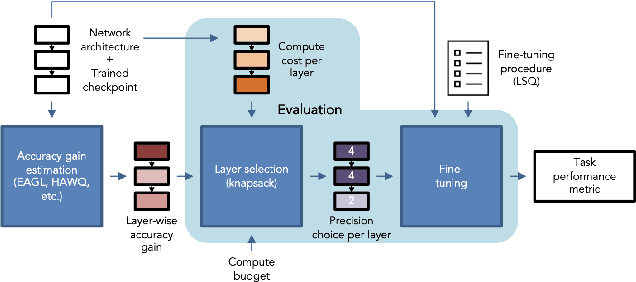
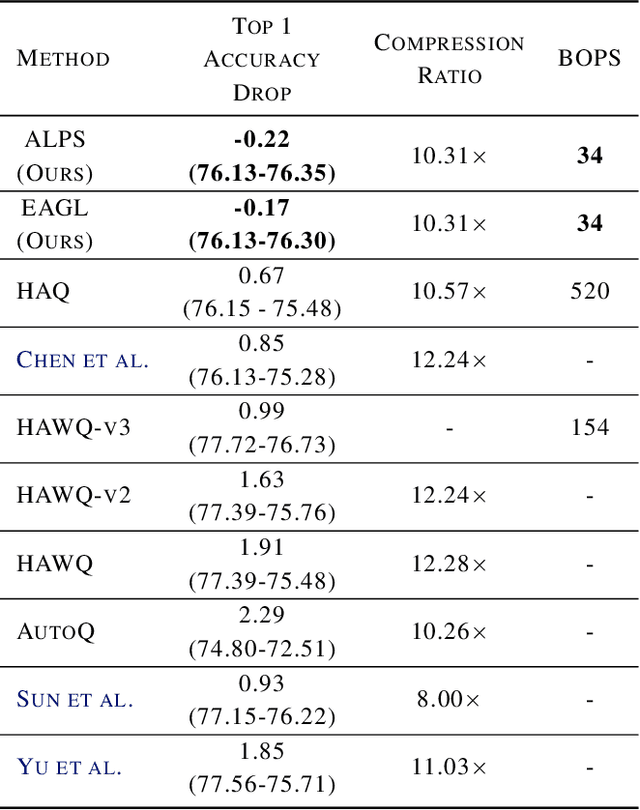
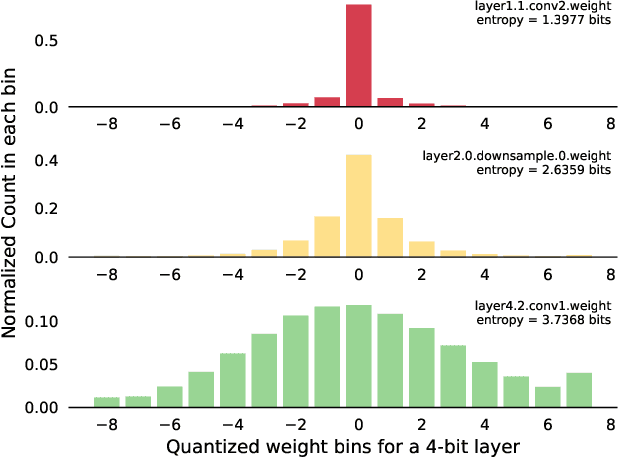

For effective and efficient deep neural network inference, it is desirable to achieve state-of-the-art accuracy with the simplest networks requiring the least computation, memory, and power. Quantizing networks to lower precision is a powerful technique for simplifying networks. It is generally desirable to quantize as aggressively as possible without incurring significant accuracy degradation. As each layer of a network may have different sensitivity to quantization, mixed precision quantization methods selectively tune the precision of individual layers of a network to achieve a minimum drop in task performance (e.g., accuracy). To estimate the impact of layer precision choice on task performance two methods are introduced: i) Entropy Approximation Guided Layer selection (EAGL) is fast and uses the entropy of the weight distribution, and ii) Accuracy-aware Layer Precision Selection (ALPS) is straightforward and relies on single epoch fine-tuning after layer precision reduction. Using EAGL and ALPS for layer precision selection, full-precision accuracy is recovered with a mix of 4-bit and 2-bit layers for ResNet-50 and ResNet-101 classification networks, demonstrating improved performance across the entire accuracy-throughput frontier, and equivalent performance for the PSPNet segmentation network in our own commensurate comparison over leading mixed precision layer selection techniques, while requiring orders of magnitude less compute time to reach a solution.
Channel Measurement for Holographic MIMO: Benefits and Challenges of Spatial Oversampling
Jan 13, 2023
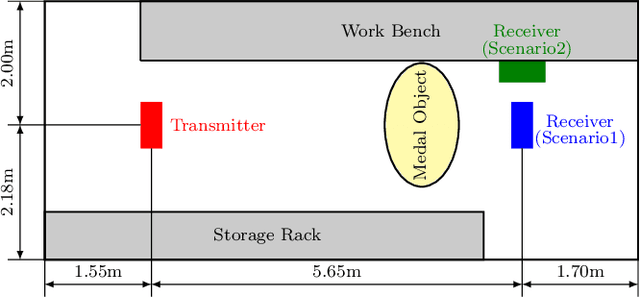
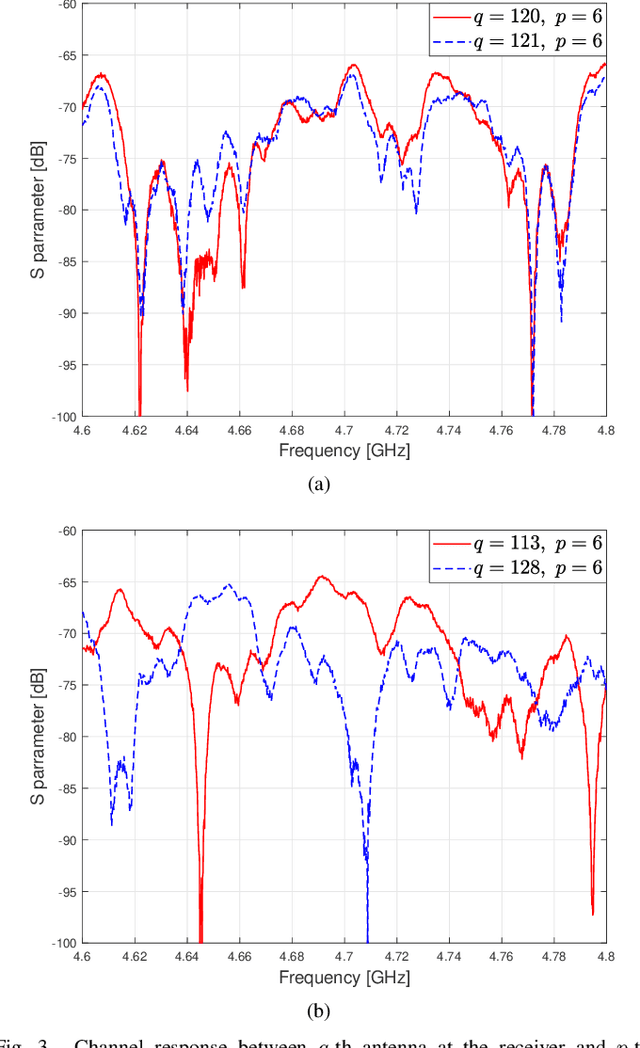
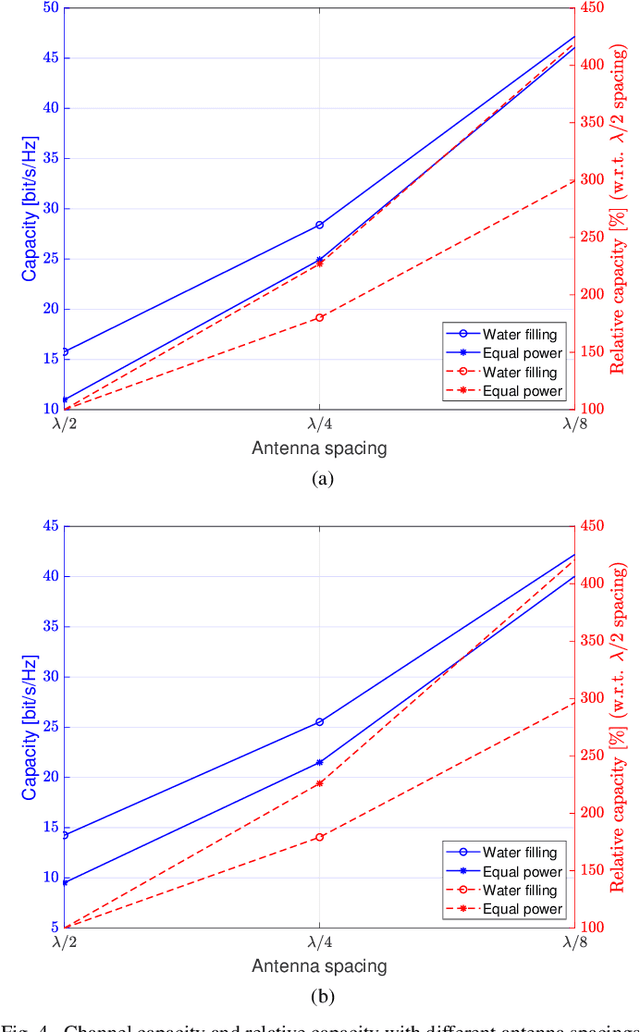
In this paper, the channel of an indoor holographic multiple-input multiple-output (MIMO) system is measured. It is demonstrated through experiments for the first time that the spatial oversampling of holographic MIMO systems is able to increase the capacity of a wireless communication system significantly. However, the antenna efficiency is the most crucial challenge preventing us from getting the capacity improvement. An extended EM-compliant channel model is also proposed for holographic MIMO systems, which is able to take the non-isotropic characteristics of the propagation environment, the antenna pattern distortion, the antenna efficiency, and the polarization characteristics into consideration.
Surrogate-assisted Multi-objective Neural Architecture Search for Real-time Semantic Segmentation
Aug 14, 2022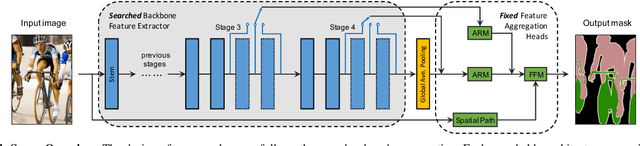
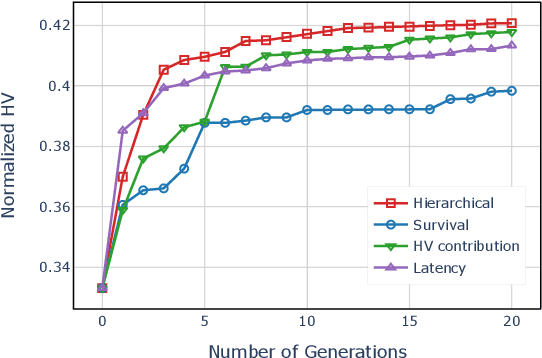
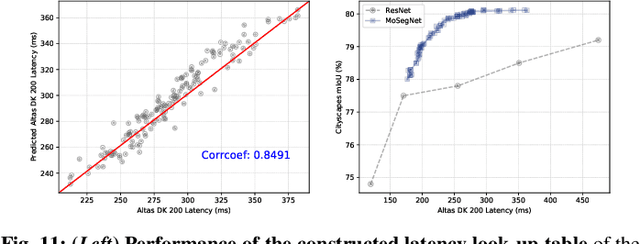
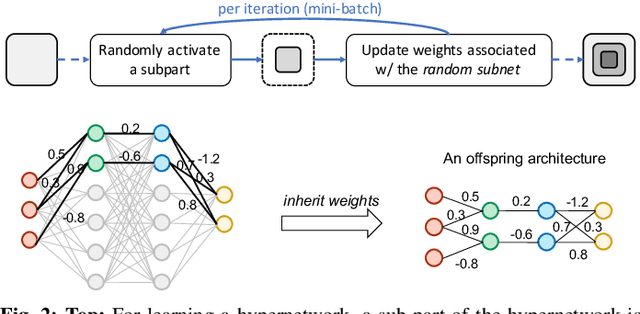
The architectural advancements in deep neural networks have led to remarkable leap-forwards across a broad array of computer vision tasks. Instead of relying on human expertise, neural architecture search (NAS) has emerged as a promising avenue toward automating the design of architectures. While recent achievements in image classification have suggested opportunities, the promises of NAS have yet to be thoroughly assessed on more challenging tasks of semantic segmentation. The main challenges of applying NAS to semantic segmentation arise from two aspects: (i) high-resolution images to be processed; (ii) additional requirement of real-time inference speed (i.e., real-time semantic segmentation) for applications such as autonomous driving. To meet such challenges, we propose a surrogate-assisted multi-objective method in this paper. Through a series of customized prediction models, our method effectively transforms the original NAS task into an ordinary multi-objective optimization problem. Followed by a hierarchical pre-screening criterion for in-fill selection, our method progressively achieves a set of efficient architectures trading-off between segmentation accuracy and inference speed. Empirical evaluations on three benchmark datasets together with an application using Huawei Atlas 200 DK suggest that our method can identify architectures significantly outperforming existing state-of-the-art architectures designed both manually by human experts and automatically by other NAS methods.
LOSDD: Leave-Out Support Vector Data Description for Outlier Detection
Dec 27, 2022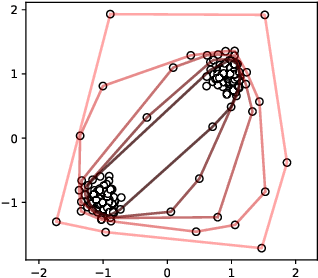
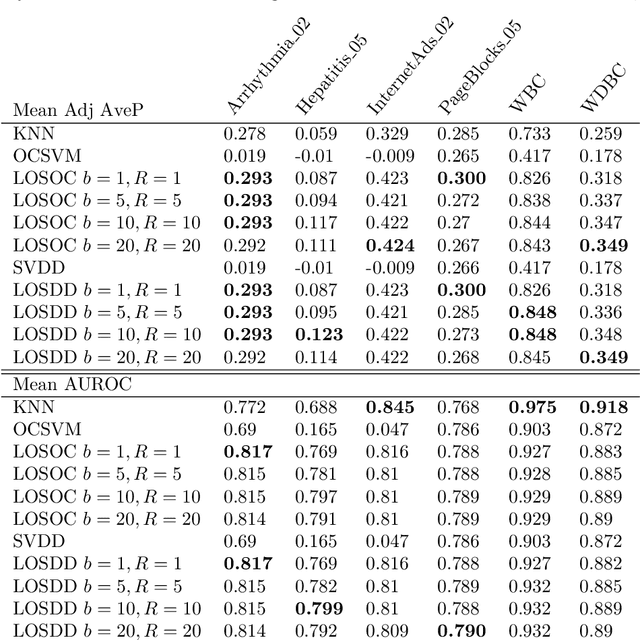
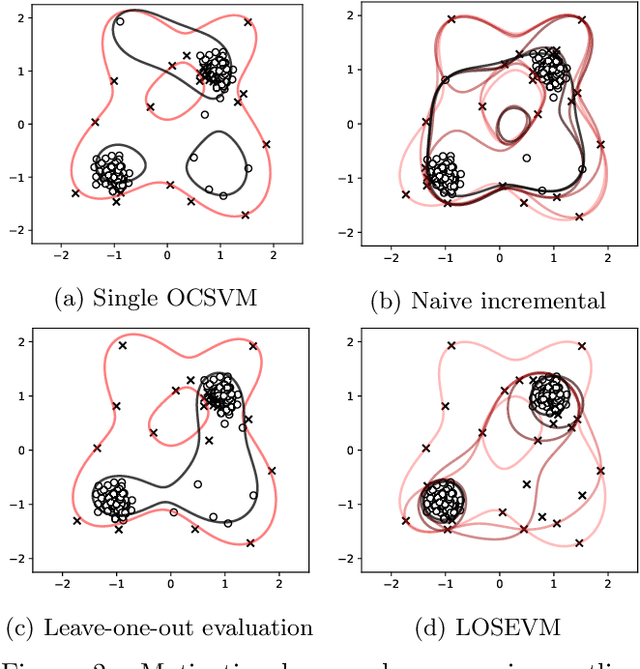
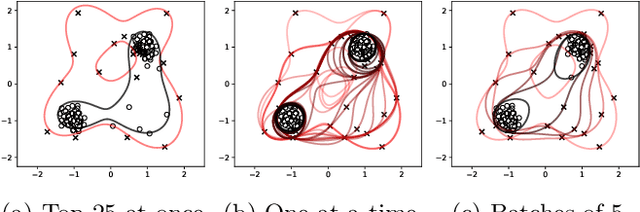
Support Vector Machines have been successfully used for one-class classification (OCSVM, SVDD) when trained on clean data, but they work much worse on dirty data: outliers present in the training data tend to become support vectors, and are hence considered "normal". In this article, we improve the effectiveness to detect outliers in dirty training data with a leave-out strategy: by temporarily omitting one candidate at a time, this point can be judged using the remaining data only. We show that this is more effective at scoring the outlierness of points than using the slack term of existing SVM-based approaches. Identified outliers can then be removed from the data, such that outliers hidden by other outliers can be identified, to reduce the problem of masking. Naively, this approach would require training N individual SVMs (and training $O(N^2)$ SVMs when iteratively removing the worst outliers one at a time), which is prohibitively expensive. We will discuss that only support vectors need to be considered in each step and that by reusing SVM parameters and weights, this incremental retraining can be accelerated substantially. By removing candidates in batches, we can further improve the processing time, although it obviously remains more costly than training a single SVM.
A Large-scale Film Style Dataset for Learning Multi-frequency Driven Film Enhancement
Jan 21, 2023
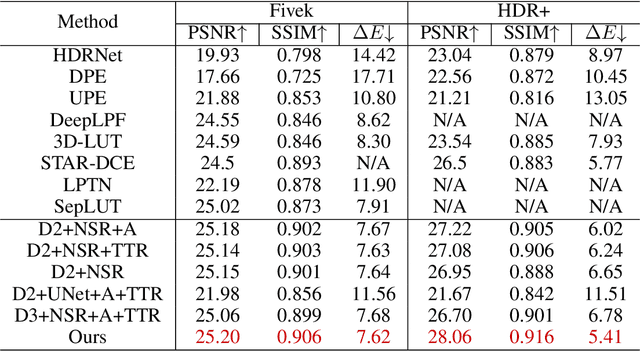

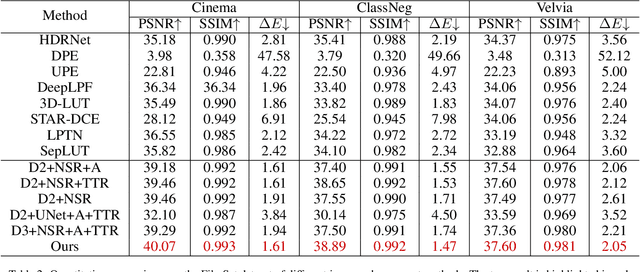
Film, a classic image style, is culturally significant to the whole photographic industry since it marks the birth of photography. However, film photography is time-consuming and expensive, necessitating a more efficient method for collecting film-style photographs. Numerous datasets that have emerged in the field of image enhancement so far are not film-specific. In order to facilitate film-based image stylization research, we construct FilmSet, a large-scale and high-quality film style dataset. Our dataset includes three different film types and more than 5000 in-the-wild high resolution images. Inspired by the features of FilmSet images, we propose a novel framework called FilmNet based on Laplacian Pyramid for stylizing images across frequency bands and achieving film style outcomes. Experiments reveal that the performance of our model is superior than state-of-the-art techniques. Our dataset and code will be made publicly available.
NeuralPassthrough: Learned Real-Time View Synthesis for VR
Jul 05, 2022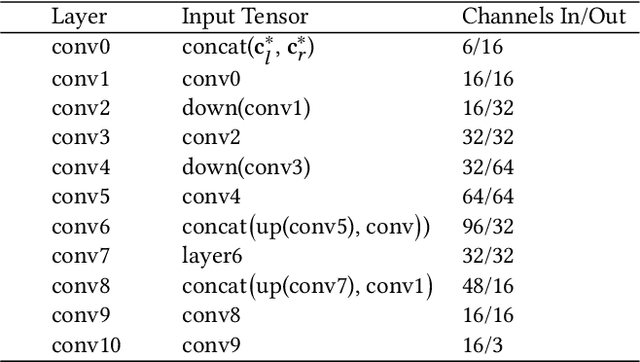

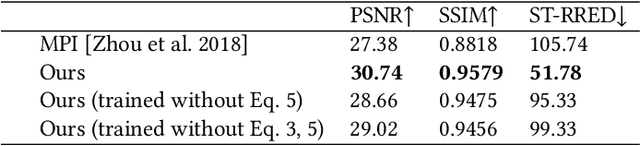
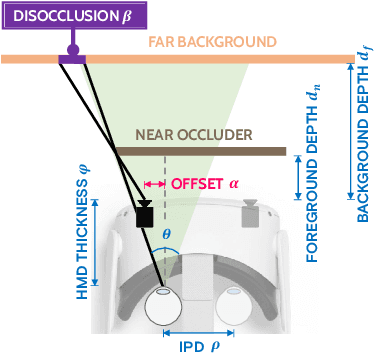
Virtual reality (VR) headsets provide an immersive, stereoscopic visual experience, but at the cost of blocking users from directly observing their physical environment. Passthrough techniques are intended to address this limitation by leveraging outward-facing cameras to reconstruct the images that would otherwise be seen by the user without the headset. This is inherently a real-time view synthesis challenge, since passthrough cameras cannot be physically co-located with the eyes. Existing passthrough techniques suffer from distracting reconstruction artifacts, largely due to the lack of accurate depth information (especially for near-field and disoccluded objects), and also exhibit limited image quality (e.g., being low resolution and monochromatic). In this paper, we propose the first learned passthrough method and assess its performance using a custom VR headset that contains a stereo pair of RGB cameras. Through both simulations and experiments, we demonstrate that our learned passthrough method delivers superior image quality compared to state-of-the-art methods, while meeting strict VR requirements for real-time, perspective-correct stereoscopic view synthesis over a wide field of view for desktop-connected headsets.
MQRetNN: Multi-Horizon Time Series Forecasting with Retrieval Augmentation
Jul 21, 2022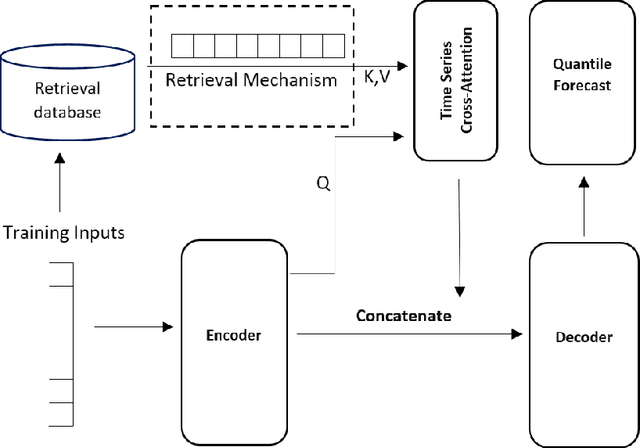
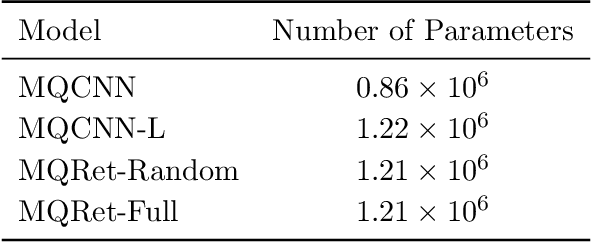
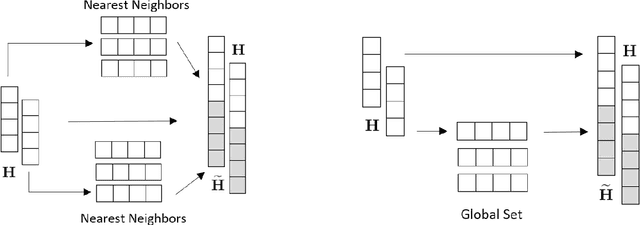
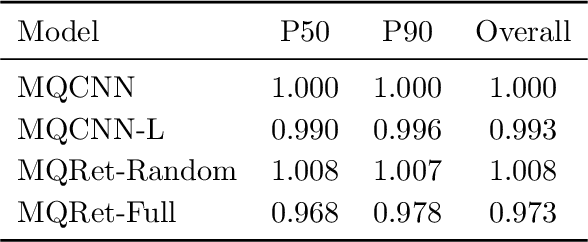
Multi-horizon probabilistic time series forecasting has wide applicability to real-world tasks such as demand forecasting. Recent work in neural time-series forecasting mainly focus on the use of Seq2Seq architectures. For example, MQTransformer - an improvement of MQCNN - has shown the state-of-the-art performance in probabilistic demand forecasting. In this paper, we consider incorporating cross-entity information to enhance model performance by adding a cross-entity attention mechanism along with a retrieval mechanism to select which entities to attend over. We demonstrate how our new neural architecture, MQRetNN, leverages the encoded contexts from a pretrained baseline model on the entire population to improve forecasting accuracy. Using MQCNN as the baseline model (due to computational constraints, we do not use MQTransformer), we first show on a small demand forecasting dataset that it is possible to achieve ~3% improvement in test loss by adding a cross-entity attention mechanism where each entity attends to all others in the population. We then evaluate the model with our proposed retrieval methods - as a means of approximating an attention over a large population - on a large-scale demand forecasting application with over 2 million products and observe ~1% performance gain over the MQCNN baseline.