 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Blind estimation of room acoustic parameters from speech signals based on extended model of room impulse response
Dec 26, 2022

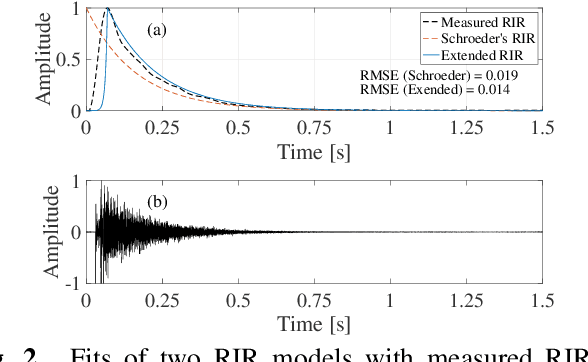
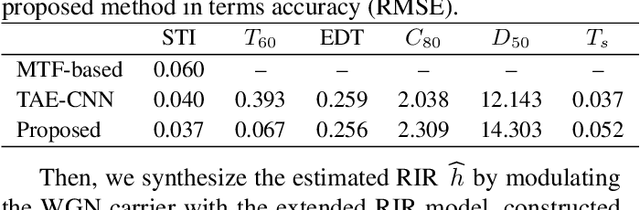
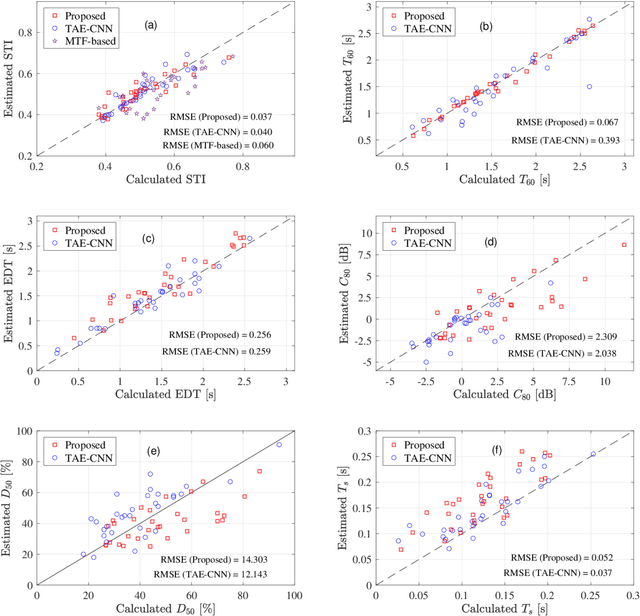
The speech transmission index (STI) and room acoustic parameters (RAPs), which are derived from a room impulse response (RIR), such as reverberation time and early decay time, are essential to assess speech transmission and to predict the listening difficulty in a sound field. Since it is difficult to measure RIR in daily occupied spaces, simultaneous blind estimation of STI and RAPs must be resolved as it is an imperative and challenging issue. This paper proposes a deterministic method for blindly estimating STI and five RAPs on the basis of an RIR stochastic model that approximates an unknown RIR. The proposed method formulates a temporal power envelope of a reverberant speech signal to obtain the optimal parameters for the RIR model. Simulations were conducted to evaluate STI and RAPs from observed reverberant speech signals. The root-mean-square errors between the estimated and ground-truth results were used to comparatively evaluate the proposed method with the previous method. The results showed that the proposed method can estimate STI and RAPs effectively without any training.
Simple Yet Surprisingly Effective Training Strategies for LSTMs in Sensor-Based Human Activity Recognition
Dec 23, 2022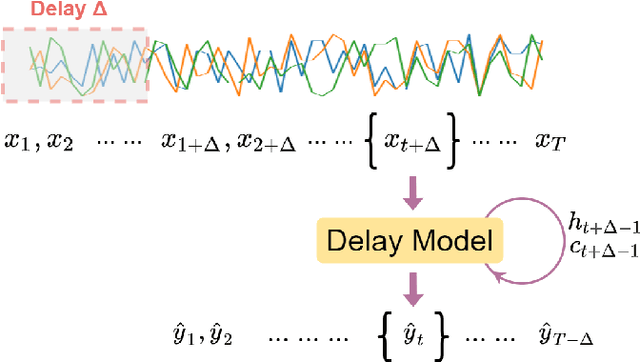
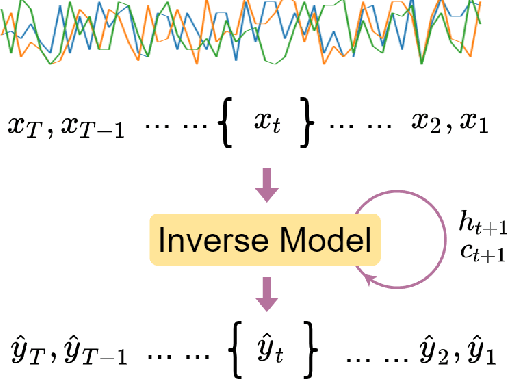
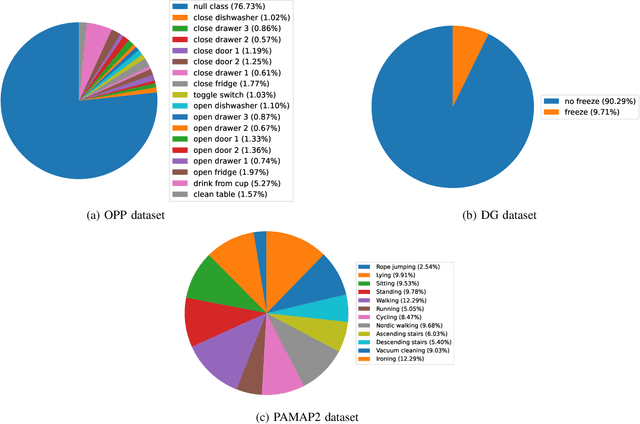
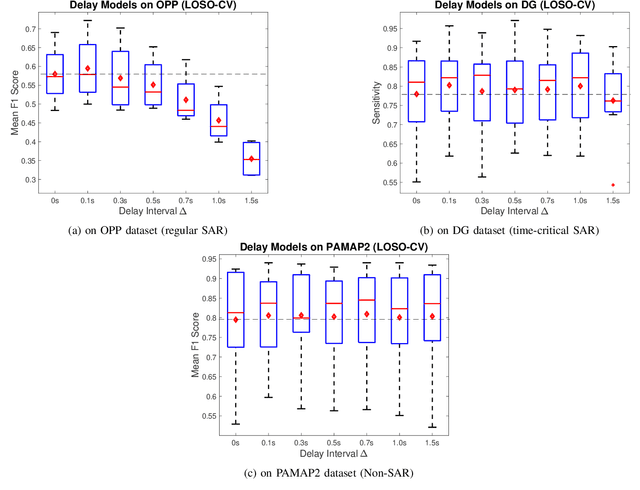
Human Activity Recognition (HAR) is one of the core research areas in mobile and wearable computing. With the application of deep learning (DL) techniques such as CNN, recognizing periodic or static activities (e.g, walking, lying, cycling, etc.) has become a well studied problem. What remains a major challenge though is the sporadic activity recognition (SAR) problem, where activities of interest tend to be non periodic, and occur less frequently when compared with the often large amount of irrelevant background activities. Recent works suggested that sequential DL models (such as LSTMs) have great potential for modeling nonperiodic behaviours, and in this paper we studied some LSTM training strategies for SAR. Specifically, we proposed two simple yet effective LSTM variants, namely delay model and inverse model, for two SAR scenarios (with and without time critical requirement). For time critical SAR, the delay model can effectively exploit predefined delay intervals (within tolerance) in form of contextual information for improved performance. For regular SAR task, the second proposed, inverse model can learn patterns from the time series in an inverse manner, which can be complementary to the forward model (i.e.,LSTM), and combining both can boost the performance. These two LSTM variants are very practical, and they can be deemed as training strategies without alteration of the LSTM fundamentals. We also studied some additional LSTM training strategies, which can further improve the accuracy. We evaluated our models on two SAR and one non-SAR datasets, and the promising results demonstrated the effectiveness of our approaches in HAR applications.
Data Distillation: A Survey
Jan 11, 2023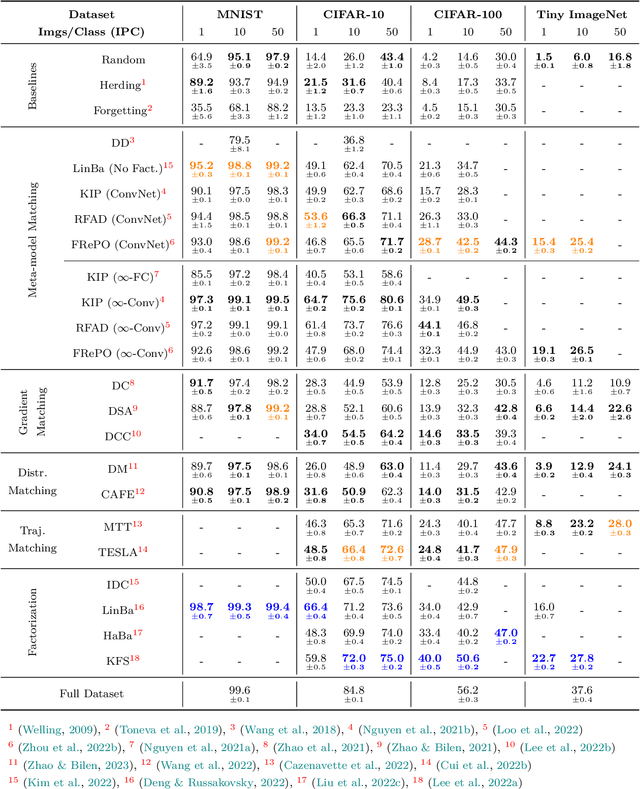
The popularity of deep learning has led to the curation of a vast number of massive and multifarious datasets. Despite having close-to-human performance on individual tasks, training parameter-hungry models on large datasets poses multi-faceted problems such as (a) high model-training time; (b) slow research iteration; and (c) poor eco-sustainability. As an alternative, data distillation approaches aim to synthesize terse data summaries, which can serve as effective drop-in replacements of the original dataset for scenarios like model training, inference, architecture search, etc. In this survey, we present a formal framework for data distillation, along with providing a detailed taxonomy of existing approaches. Additionally, we cover data distillation approaches for different data modalities, namely images, graphs, and user-item interactions (recommender systems), while also identifying current challenges and future research directions.
POSET-RL: Phase ordering for Optimizing Size and Execution Time using Reinforcement Learning
Jul 27, 2022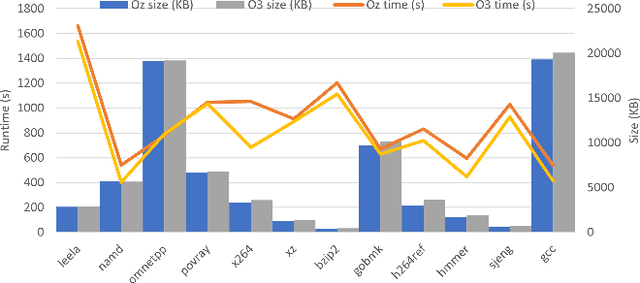
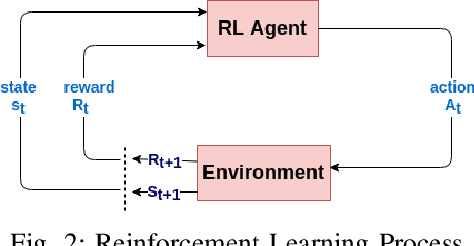
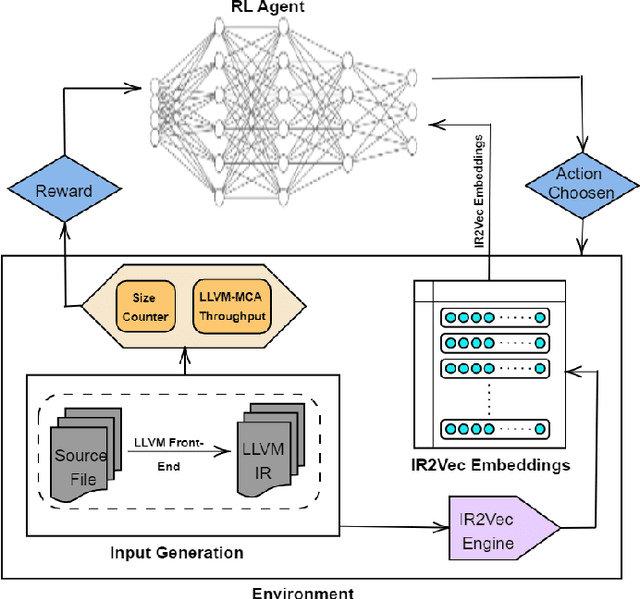
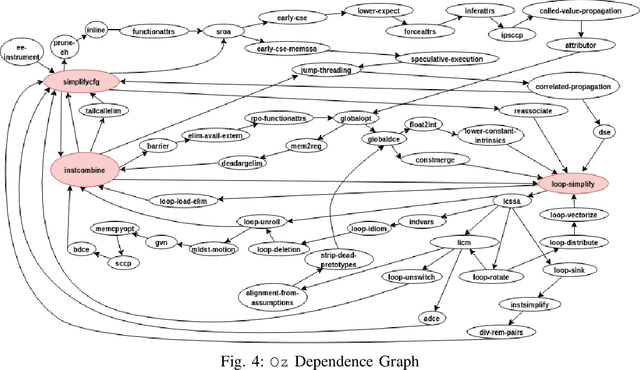
The ever increasing memory requirements of several applications has led to increased demands which might not be met by embedded devices. Constraining the usage of memory in such cases is of paramount importance. It is important that such code size improvements should not have a negative impact on the runtime. Improving the execution time while optimizing for code size is a non-trivial but a significant task. The ordering of standard optimization sequences in modern compilers is fixed, and are heuristically created by the compiler domain experts based on their expertise. However, this ordering is sub-optimal, and does not generalize well across all the cases. We present a reinforcement learning based solution to the phase ordering problem, where the ordering improves both the execution time and code size. We propose two different approaches to model the sequences: one by manual ordering, and other based on a graph called Oz Dependence Graph (ODG). Our approach uses minimal data as training set, and is integrated with LLVM. We show results on x86 and AArch64 architectures on the benchmarks from SPEC-CPU 2006, SPEC-CPU 2017 and MiBench. We observe that the proposed model based on ODG outperforms the current Oz sequence both in terms of size and execution time by 6.19% and 11.99% in SPEC 2017 benchmarks, on an average.
Self-Supervised Video Forensics by Audio-Visual Anomaly Detection
Jan 04, 2023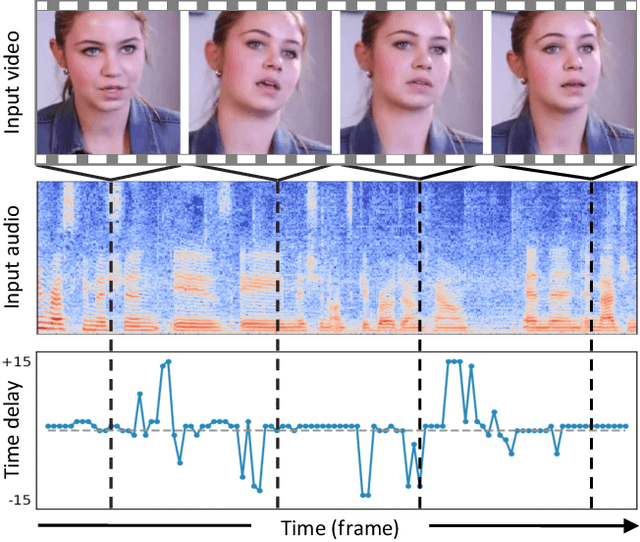
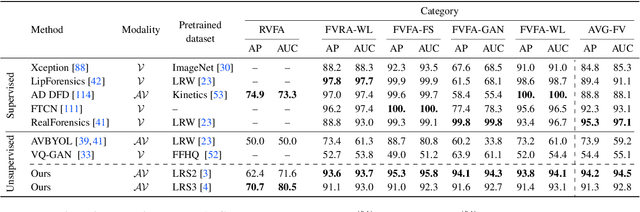
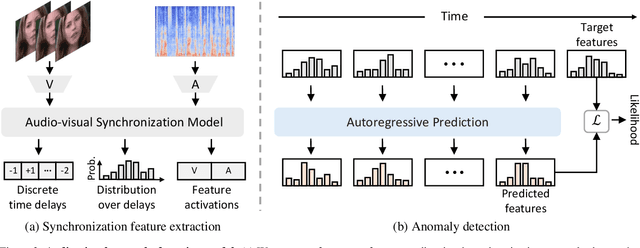
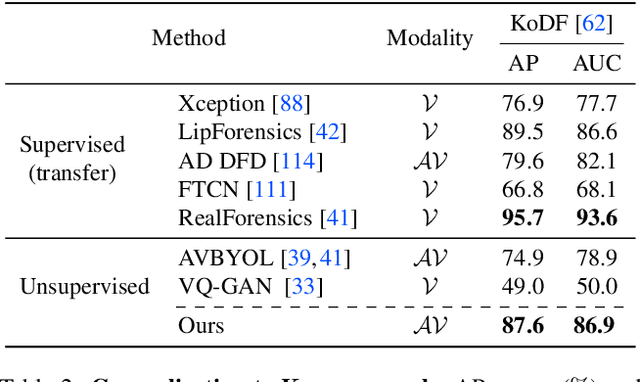
Manipulated videos often contain subtle inconsistencies between their visual and audio signals. We propose a video forensics method, based on anomaly detection, that can identify these inconsistencies, and that can be trained solely using real, unlabeled data. We train an autoregressive model to generate sequences of audio-visual features, using feature sets that capture the temporal synchronization between video frames and sound. At test time, we then flag videos that the model assigns low probability. Despite being trained entirely on real videos, our model obtains strong performance on the task of detecting manipulated speech videos. Project site: https://cfeng16.github.io/audio-visual-forensics
Forecasting the 2016-2017 Central Apennines Earthquake Sequence with a Neural Point Process
Jan 24, 2023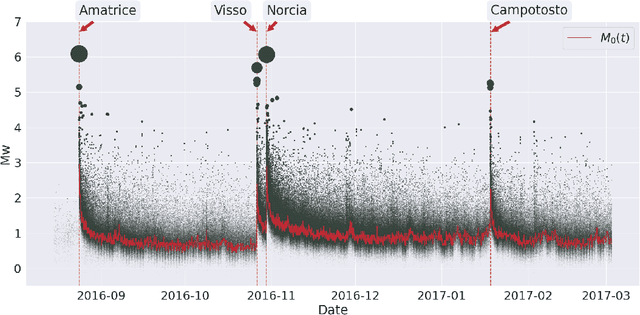
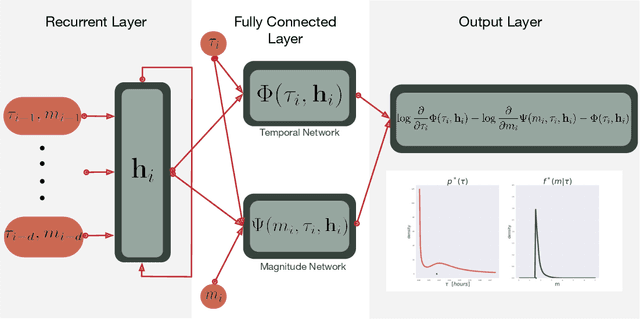
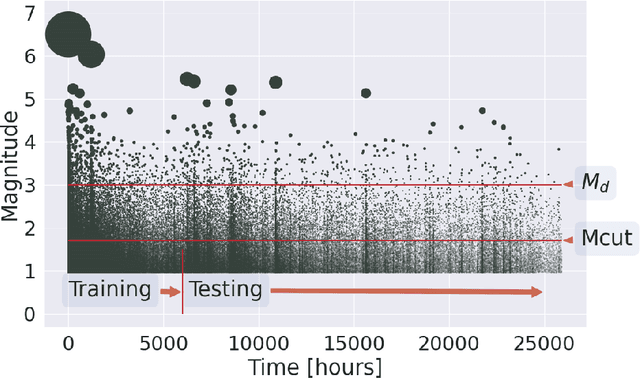
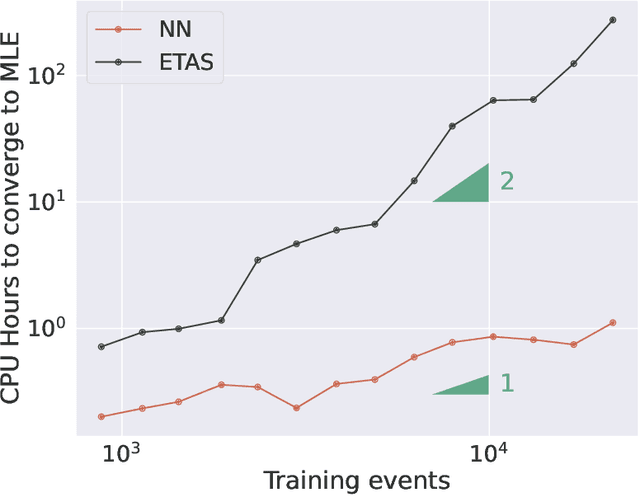
Point processes have been dominant in modeling the evolution of seismicity for decades, with the Epidemic Type Aftershock Sequence (ETAS) model being most popular. Recent advances in machine learning have constructed highly flexible point process models using neural networks to improve upon existing parametric models. We investigate whether these flexible point process models can be applied to short-term seismicity forecasting by extending an existing temporal neural model to the magnitude domain and we show how this model can forecast earthquakes above a target magnitude threshold. We first demonstrate that the neural model can fit synthetic ETAS data, however, requiring less computational time because it is not dependent on the full history of the sequence. By artificially emulating short-term aftershock incompleteness in the synthetic dataset, we find that the neural model outperforms ETAS. Using a new enhanced catalog from the 2016-2017 Central Apennines earthquake sequence, we investigate the predictive skill of ETAS and the neural model with respect to the lowest input magnitude. Constructing multiple forecasting experiments using the Visso, Norcia and Campotosto earthquakes to partition training and testing data, we target M3+ events. We find both models perform similarly at previously explored thresholds (e.g., above M3), but lowering the threshold to M1.2 reduces the performance of ETAS unlike the neural model. We argue that some of these gains are due to the neural model's ability to handle incomplete data. The robustness to missing data and speed to train the neural model present it as an encouraging competitor in earthquake forecasting.
Simultaneous Spatial and Temporal Assignment for Fast UAV Trajectory Optimization using Bilevel Optimization
Dec 01, 2022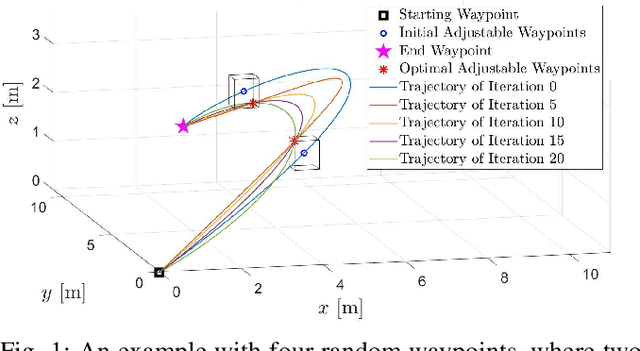
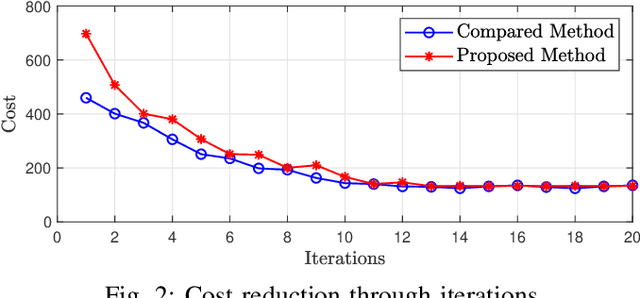
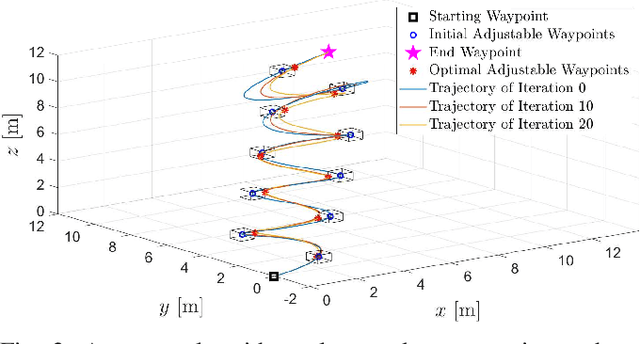
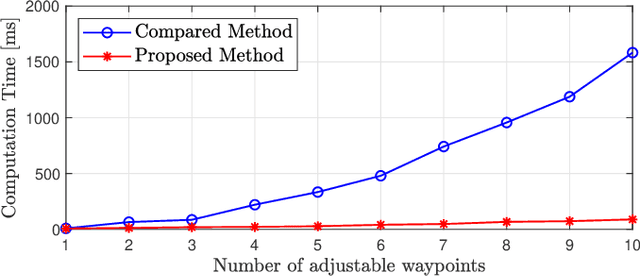
In this paper, we propose a framework for fast trajectory planning for unmanned aerial vehicles (UAVs). Our framework is reformulated from an existing bilevel optimization, in which the lower-level problem solves for the optimal trajectory with a fixed time allocation, whereas the upper-level problem updates the time allocation using analytical gradients. The lower-level problem incorporates the safety-set constraints (in the form of inequality constraints) and is cast as a convex quadratic program (QP). Our formulation modifies the lower-level QP by excluding the inequality constraints for the safety sets, which significantly reduces the computation time. The safety-set constraints are moved to the upper-level problem, where the feasible waypoints are updated together with the time allocation using analytical gradients enabled by the OptNet. We validate our approach in simulations, where our method's computation time scales linearly with respect to the number of safety sets, in contrast to the state-of-the-art that scales exponentially.
Forecasting Soil Moisture Using Domain Inspired Temporal Graph Convolution Neural Networks To Guide Sustainable Crop Management
Dec 12, 2022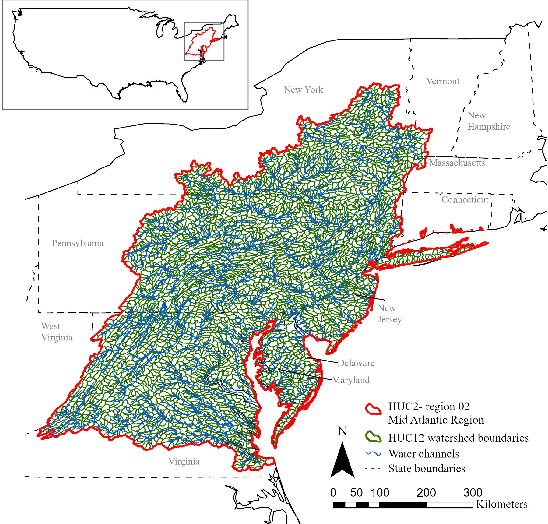
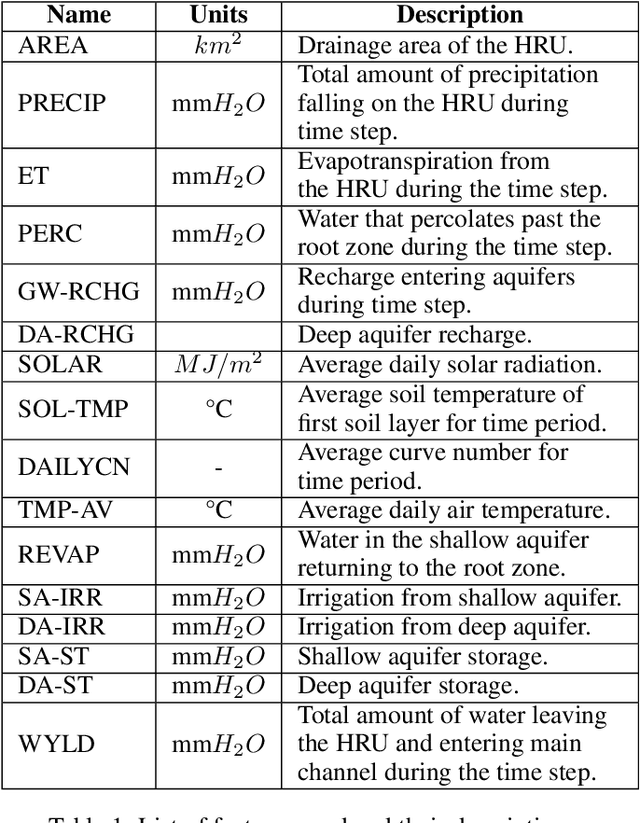
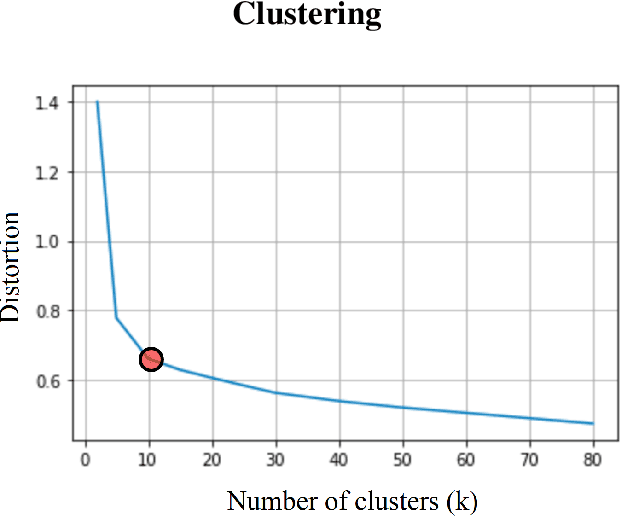
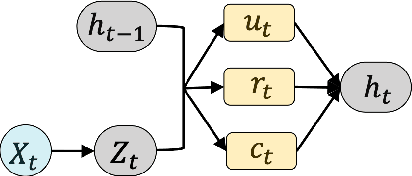
Climate change, population growth, and water scarcity present unprecedented challenges for agriculture. This project aims to forecast soil moisture using domain knowledge and machine learning for crop management decisions that enable sustainable farming. Traditional methods for predicting hydrological response features require significant computational time and expertise. Recent work has implemented machine learning models as a tool for forecasting hydrological response features, but these models neglect a crucial component of traditional hydrological modeling that spatially close units can have vastly different hydrological responses. In traditional hydrological modeling, units with similar hydrological properties are grouped together and share model parameters regardless of their spatial proximity. Inspired by this domain knowledge, we have constructed a novel domain-inspired temporal graph convolution neural network. Our approach involves clustering units based on time-varying hydrological properties, constructing graph topologies for each cluster, and forecasting soil moisture using graph convolutions and a gated recurrent neural network. We have trained, validated, and tested our method on field-scale time series data consisting of approximately 99,000 hydrological response units spanning 40 years in a case study in northeastern United States. Comparison with existing models illustrates the effectiveness of using domain-inspired clustering with time series graph neural networks. The framework is being deployed as part of a pro bono social impact program. The trained models are being deployed on small-holding farms in central Texas.
Elly: A Real-Time Failure Recovery and Data Collection System for Robotic Manipulation
Aug 25, 2022
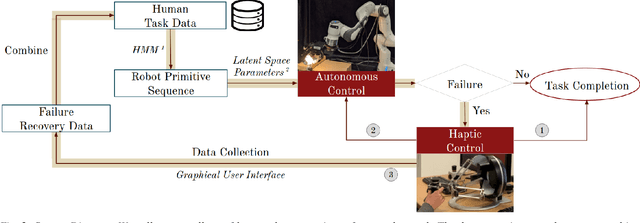
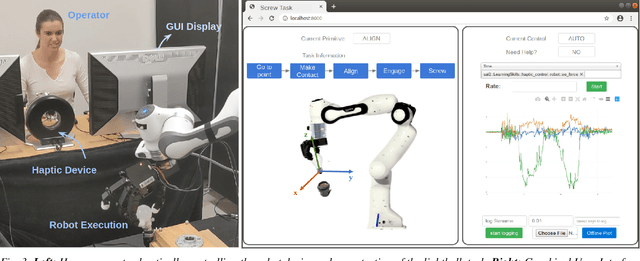

Even the most robust autonomous behaviors can fail. The goal of this research is to both recover and collect data from failures, during autonomous task execution, so they can be prevented in the future. We propose haptic intervention for real-time failure recovery and data collection. Elly is a system that allows for seamless transitions between autonomous robot behaviors and human intervention while collecting sensory information from the human's recovery strategy. The system and our design choices were experimentally validated on a single arm task -- installing a lightbulb in a socket -- and a bimanual task -- screwing a cap on a bottle -- using two 7-DOF manipulators equipped 4-finger grippers. In these examples, Elly achieved over 80% task completion during a total of 40 runs.
Temporal Concept Drift and Alignment: An empirical approach to comparing Knowledge Organization Systems over time
Aug 16, 2022

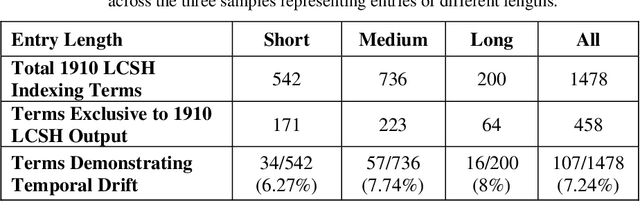
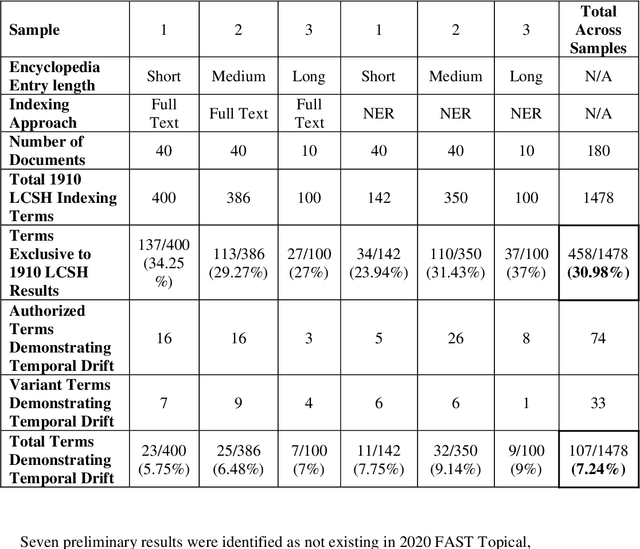
This research explores temporal concept drift and temporal alignment in knowledge organization systems (KOS). A comparative analysis is pursued using the 1910 Library of Congress Subject Headings, 2020 FAST Topical, and automatic indexing. The use case involves a sample of 90 nineteenth-century Encyclopedia Britannica entries. The entries were indexed using two approaches: 1) full-text indexing; 2) Named Entity Recognition was performed upon the entries with Stanza, Stanford's NLP toolkit, and entities were automatically indexed with the Helping Interdisciplinary Vocabulary application (HIVE), using both 1910 LCSH and FAST Topical. The analysis focused on three goals: 1) identifying results that were exclusive to the 1910 LCSH output; 2) identifying terms in the exclusive set that have been deprecated from the contemporary LCSH, demonstrating temporal concept drift; and 3) exploring the historical significance of these deprecated terms. Results confirm that historical vocabularies can be used to generate anachronistic subject headings representing conceptual drift across time in KOS and historical resources. A methodological contribution is made demonstrating how to study changes in KOS over time and improve the contextualization of historical humanities resources.