 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Long Short-Term Preference Modeling for Continuous-Time Sequential Recommendation
Aug 01, 2022
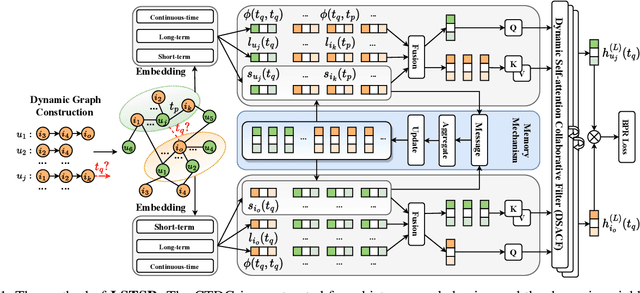

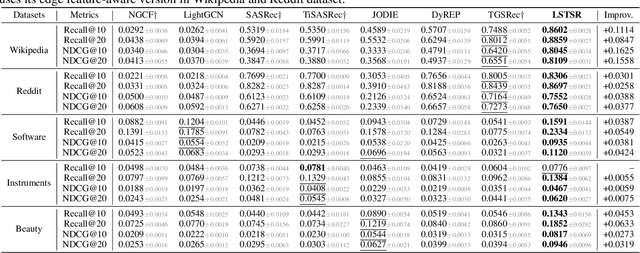
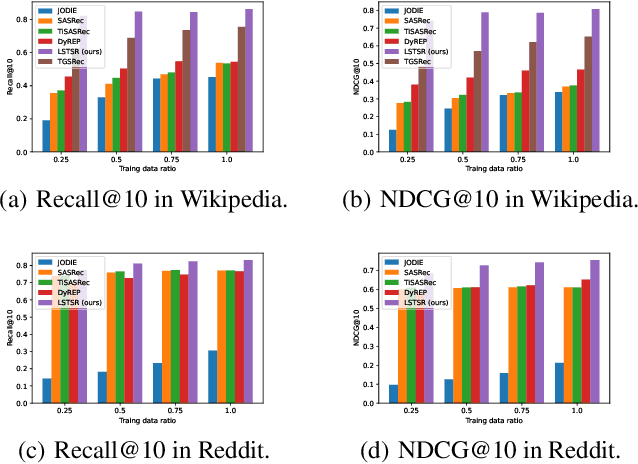
Modeling the evolution of user preference is essential in recommender systems. Recently, dynamic graph-based methods have been studied and achieved SOTA for recommendation, majority of which focus on user's stable long-term preference. However, in real-world scenario, user's short-term preference evolves over time dynamically. Although there exists sequential methods that attempt to capture it, how to model the evolution of short-term preference with dynamic graph-based methods has not been well-addressed yet. In particular: 1) existing methods do not explicitly encode and capture the evolution of short-term preference as sequential methods do; 2) simply using last few interactions is not enough for modeling the changing trend. In this paper, we propose Long Short-Term Preference Modeling for Continuous-Time Sequential Recommendation (LSTSR) to capture the evolution of short-term preference under dynamic graph. Specifically, we explicitly encode short-term preference and optimize it via memory mechanism, which has three key operations: Message, Aggregate and Update. Our memory mechanism can not only store one-hop information, but also trigger with new interactions online. Extensive experiments conducted on five public datasets show that LSTSR consistently outperforms many state-of-the-art recommendation methods across various lines.
Robust Continual Test-time Adaptation: Instance-aware BN and Prediction-balanced Memory
Aug 10, 2022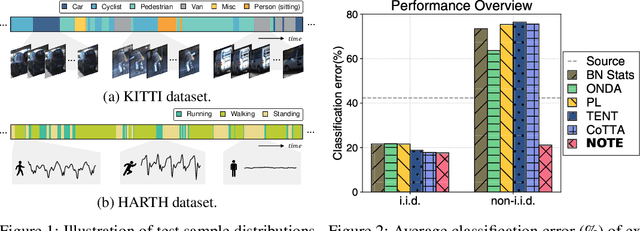
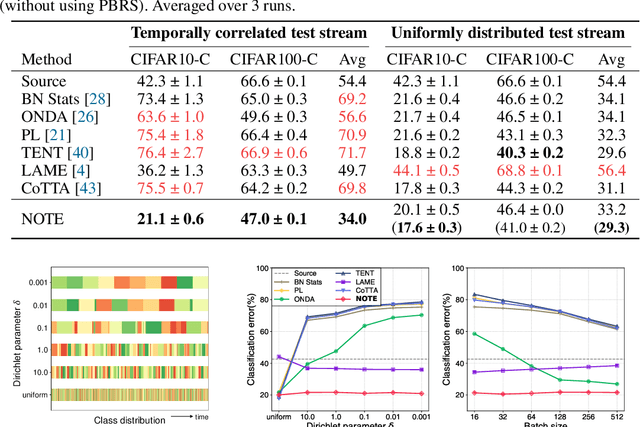
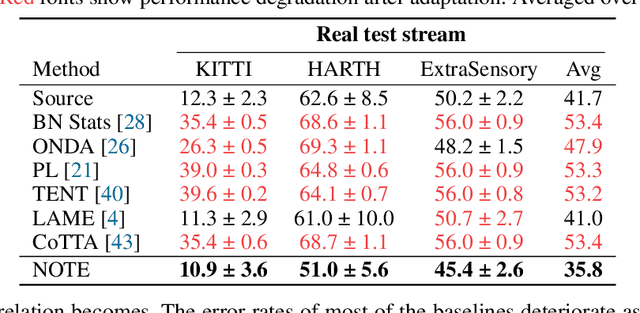
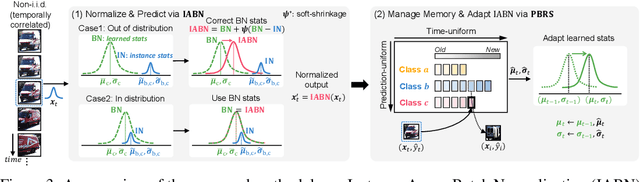
Test-time adaptation (TTA) is an emerging paradigm that addresses distributional shifts between training and testing phases without additional data acquisition or labeling cost; only unlabeled test data streams are used for continual model adaptation. Previous TTA schemes assume that the test samples are independent and identically distributed (i.i.d.), even though they are often temporally correlated (non-i.i.d.) in application scenarios, e.g., autonomous driving. We discover that most existing TTA methods fail dramatically under such scenarios. Motivated by this, we present a new test-time adaptation scheme that is robust against non-i.i.d. test data streams. Our novelty is mainly two-fold: (a) Instance-Aware Batch Normalization (IABN) that corrects normalization for out-of-distribution samples, and (b) Prediction-balanced Reservoir Sampling (PBRS) that simulates i.i.d. data stream from non-i.i.d. stream in a class-balanced manner. Our evaluation with various datasets, including real-world non-i.i.d. streams, demonstrates that the proposed robust TTA not only outperforms state-of-the-art TTA algorithms in the non-i.i.d. setting, but also achieves comparable performance to those algorithms under the i.i.d. assumption.
Augmented Bilinear Network for Incremental Multi-Stock Time-Series Classification
Jul 23, 2022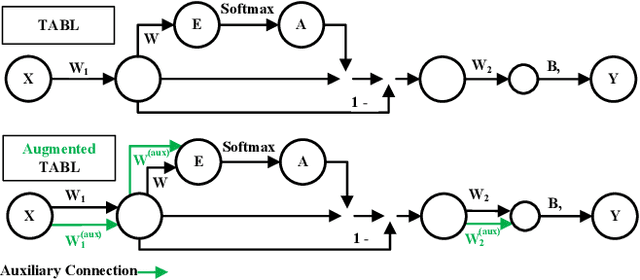
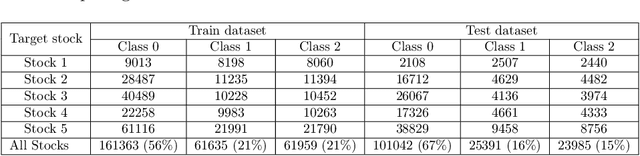
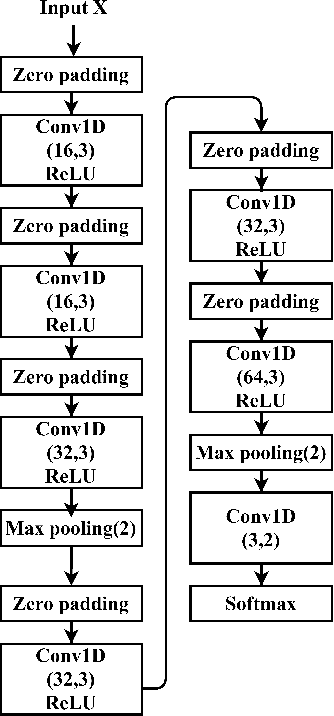
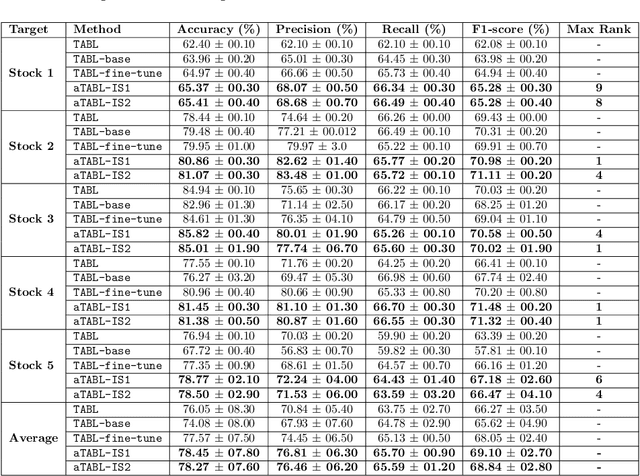
Deep Learning models have become dominant in tackling financial time-series analysis problems, overturning conventional machine learning and statistical methods. Most often, a model trained for one market or security cannot be directly applied to another market or security due to differences inherent in the market conditions. In addition, as the market evolves through time, it is necessary to update the existing models or train new ones when new data is made available. This scenario, which is inherent in most financial forecasting applications, naturally raises the following research question: How to efficiently adapt a pre-trained model to a new set of data while retaining performance on the old data, especially when the old data is not accessible? In this paper, we propose a method to efficiently retain the knowledge available in a neural network pre-trained on a set of securities and adapt it to achieve high performance in new ones. In our method, the prior knowledge encoded in a pre-trained neural network is maintained by keeping existing connections fixed, and this knowledge is adjusted for the new securities by a set of augmented connections, which are optimized using the new data. The auxiliary connections are constrained to be of low rank. This not only allows us to rapidly optimize for the new task but also reduces the storage and run-time complexity during the deployment phase. The efficiency of our approach is empirically validated in the stock mid-price movement prediction problem using a large-scale limit order book dataset. Experimental results show that our approach enhances prediction performance as well as reduces the overall number of network parameters.
Don't Play Favorites: Minority Guidance for Diffusion Models
Jan 29, 2023
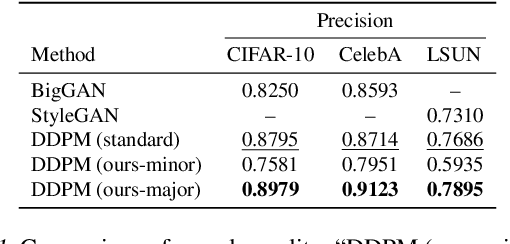
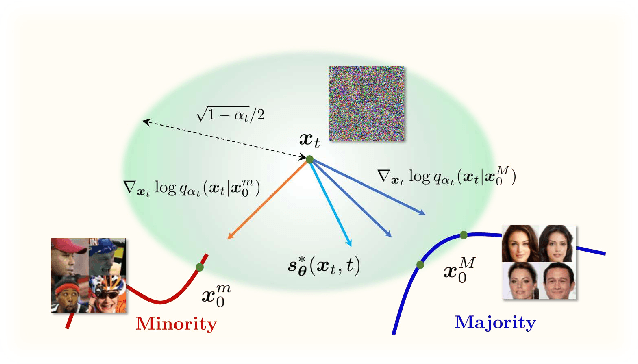
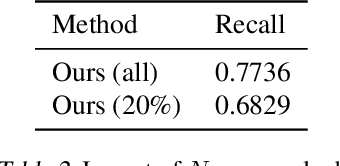
We explore the problem of generating minority samples using diffusion models. The minority samples are instances that lie on low-density regions of a data manifold. Generating sufficient numbers of such minority instances is important, since they often contain some unique attributes of the data. However, the conventional generation process of the diffusion models mostly yields majority samples (that lie on high-density regions of the manifold) due to their high likelihoods, making themselves highly ineffective and time-consuming for the task. In this work, we present a novel framework that can make the generation process of the diffusion models focus on the minority samples. We first provide a new insight on the majority-focused nature of the diffusion models: they denoise in favor of the majority samples. The observation motivates us to introduce a metric that describes the uniqueness of a given sample. To address the inherent preference of the diffusion models w.r.t. the majority samples, we further develop minority guidance, a sampling technique that can guide the generation process toward regions with desired likelihood levels. Experiments on benchmark real datasets demonstrate that our minority guidance can greatly improve the capability of generating the low-likelihood minority samples over existing generative frameworks including the standard diffusion sampler.
Generating Novel, Designable, and Diverse Protein Structures by Equivariantly Diffusing Oriented Residue Clouds
Jan 29, 2023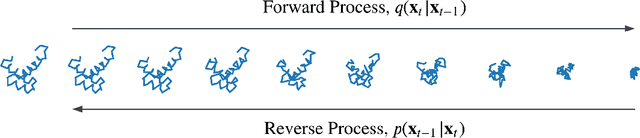
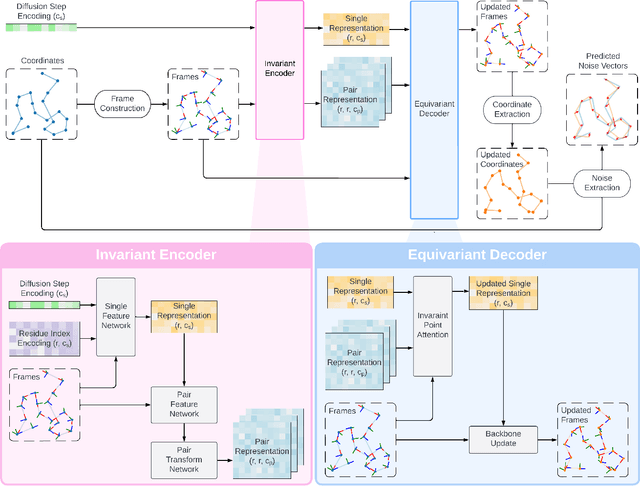
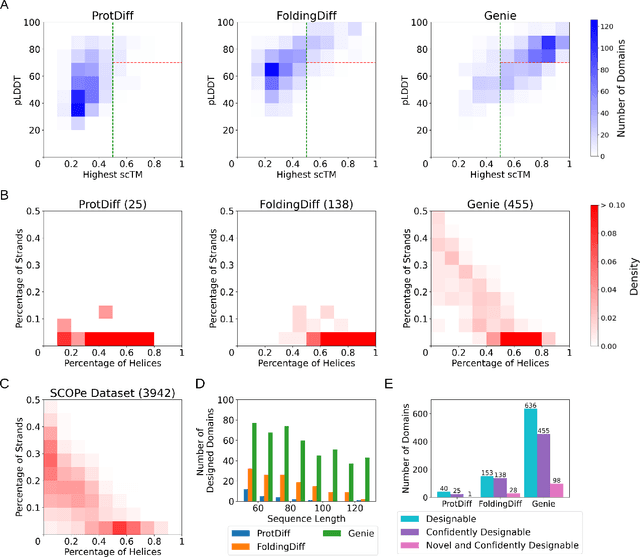
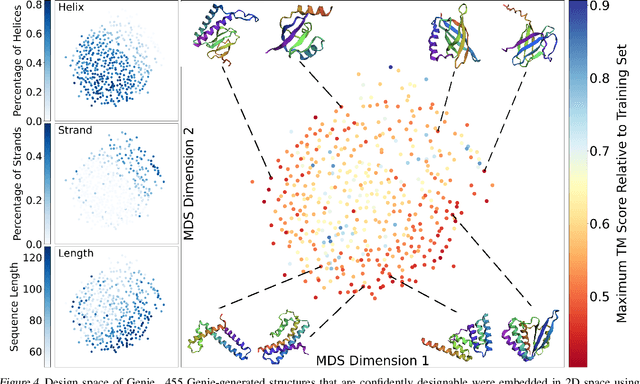
Proteins power a vast array of functional processes in living cells. The capability to create new proteins with designed structures and functions would thus enable the engineering of cellular behavior and development of protein-based therapeutics and materials. Structure-based protein design aims to find structures that are designable (can be realized by a protein sequence), novel (have dissimilar geometry from natural proteins), and diverse (span a wide range of geometries). While advances in protein structure prediction have made it possible to predict structures of novel protein sequences, the combinatorially large space of sequences and structures limits the practicality of search-based methods. Generative models provide a compelling alternative, by implicitly learning the low-dimensional structure of complex data distributions. Here, we leverage recent advances in denoising diffusion probabilistic models and equivariant neural networks to develop Genie, a generative model of protein structures that performs discrete-time diffusion using a cloud of oriented reference frames in 3D space. Through in silico evaluations, we demonstrate that Genie generates protein backbones that are more designable, novel, and diverse than existing models. This indicates that Genie is capturing key aspects of the distribution of protein structure space and facilitates protein design with high success rates.
Learning to Control and Coordinate Hybrid Traffic Through Robot Vehicles at Complex and Unsignalized Intersections
Jan 12, 2023
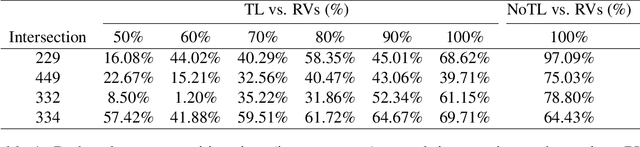
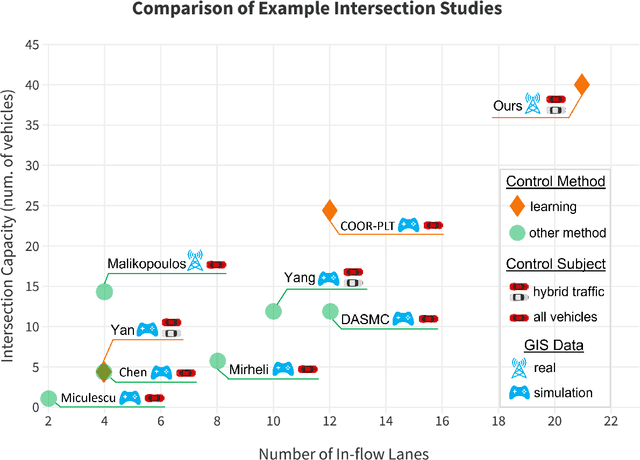
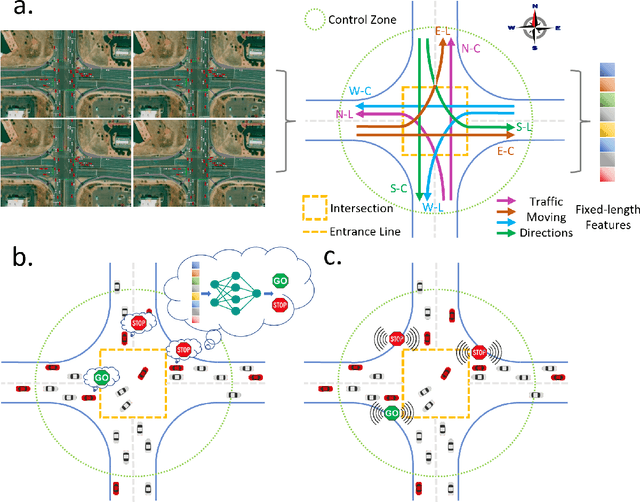
Intersections are essential road infrastructures for traffic in modern metropolises; however, they can also be the bottleneck of traffic flows due to traffic incidents or the absence of traffic coordination mechanisms such as traffic lights. Thus, various control and coordination mechanisms that are beyond traditional control methods have been proposed to improve the efficiency of intersection traffic. Amongst these methods, the control of foreseeable hybrid traffic that consists of human-driven vehicles (HVs) and robot vehicles (RVs) has recently emerged. We propose a decentralized reinforcement learning approach for the control and coordination of hybrid traffic at real-world, complex intersections--a topic that has not been previously explored. Comprehensive experiments are conducted to show the effectiveness of our approach. In particular, we show that using 5% RVs, we can prevent congestion formation inside the intersection under the actual traffic demand of 700 vehicles per hour. In contrast, without RVs, congestion starts to develop when the traffic demand reaches as low as 200 vehicles per hour. Further performance gains (reduced waiting time of vehicles at the intersection) are obtained as the RV penetration rate increases. When there exist more than 50% RVs in traffic, our method starts to outperform traffic signals on the average waiting time of all vehicles at the intersection. Our method is also robust against both blackout events and sudden RV percentage drops, and enjoys excellent generalizablility, which is illustrated by its successful deployment in two unseen intersections.
ImMesh: An Immediate LiDAR Localization and Meshing Framework
Jan 12, 2023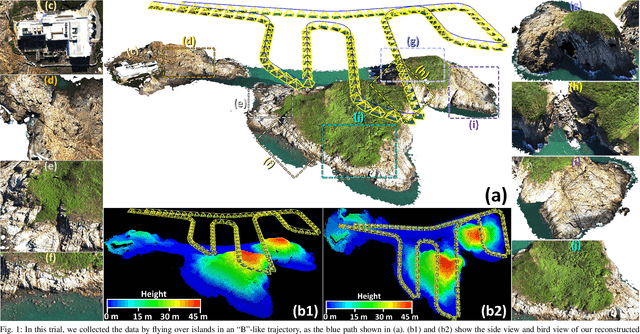
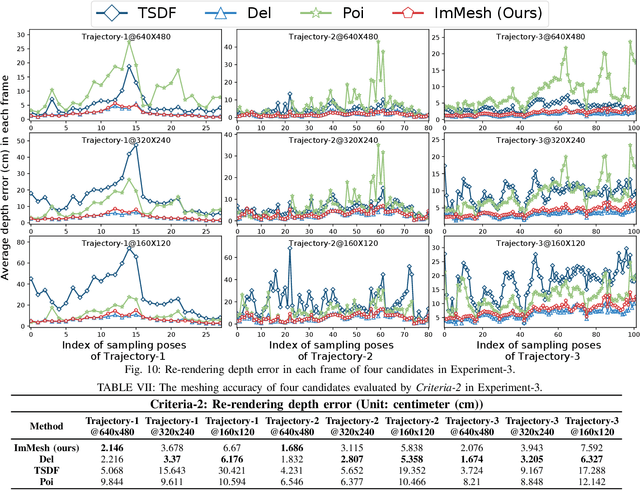
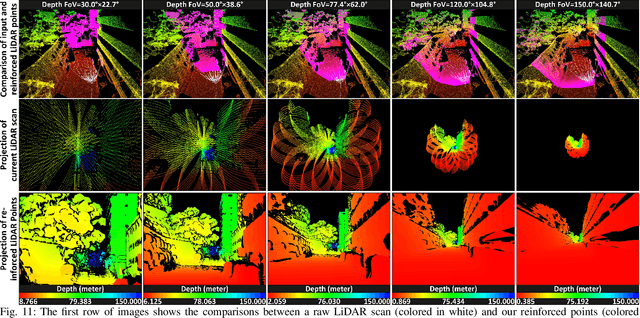

In this paper, we propose a novel LiDAR(-inertial) odometry and mapping framework to achieve the goal of simultaneous localization and meshing in real-time. This proposed framework termed ImMesh comprises four tightly-coupled modules: receiver, localization, meshing, and broadcaster. The localization module utilizes the prepossessed sensor data from the receiver, estimates the sensor pose online by registering LiDAR scans to maps, and dynamically grows the map. Then, our meshing module takes the registered LiDAR scan for incrementally reconstructing the triangle mesh on the fly. Finally, the real-time odometry, map, and mesh are published via our broadcaster. The key contribution of this work is the meshing module, which represents a scene by an efficient hierarchical voxels structure, performs fast finding of voxels observed by new scans, and reconstructs triangle facets in each voxel in an incremental manner. This voxel-wise meshing operation is delicately designed for the purpose of efficiency; it first performs a dimension reduction by projecting 3D points to a 2D local plane contained in the voxel, and then executes the meshing operation with pull, commit and push steps for incremental reconstruction of triangle facets. To the best of our knowledge, this is the first work in literature that can reconstruct online the triangle mesh of large-scale scenes, just relying on a standard CPU without GPU acceleration. To share our findings and make contributions to the community, we make our code publicly available on our GitHub: https://github.com/hku-mars/ImMesh.
FUSION: Fully Unsupervised Test-Time Stain Adaptation via Fused Normalization Statistics
Aug 30, 2022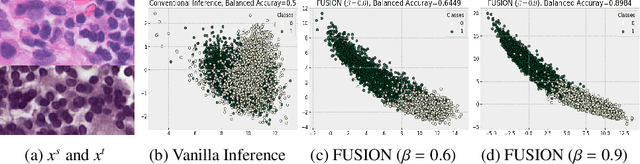
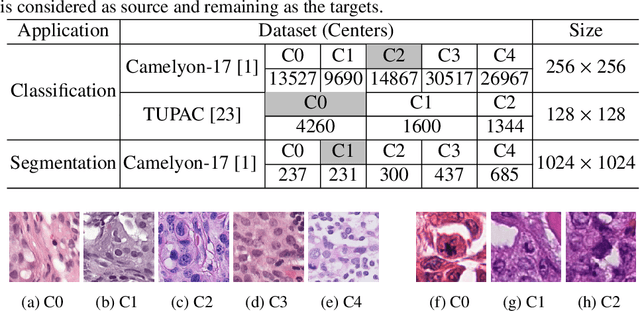
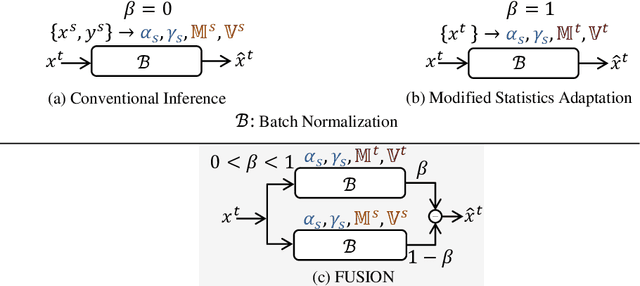
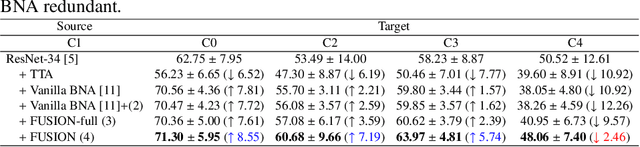
Staining reveals the micro structure of the aspirate while creating histopathology slides. Stain variation, defined as a chromatic difference between the source and the target, is caused by varying characteristics during staining, resulting in a distribution shift and poor performance on the target. The goal of stain normalization is to match the target's chromatic distribution to that of the source. However, stain normalisation causes the underlying morphology to distort, resulting in an incorrect diagnosis. We propose FUSION, a new method for promoting stain-adaption by adjusting the model to the target in an unsupervised test-time scenario, eliminating the necessity for significant labelling at the target end. FUSION works by altering the target's batch normalization statistics and fusing them with source statistics using a weighting factor. The algorithm reduces to one of two extremes based on the weighting factor. Despite the lack of training or supervision, FUSION surpasses existing equivalent algorithms for classification and dense predictions (segmentation), as demonstrated by comprehensive experiments on two public datasets.
MEMO : Accelerating Transformers with Memoization on Big Memory Systems
Jan 23, 2023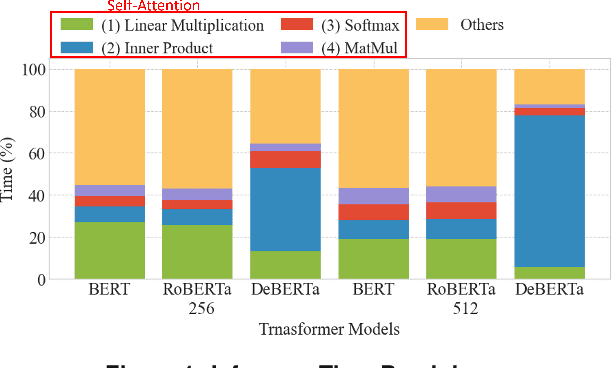

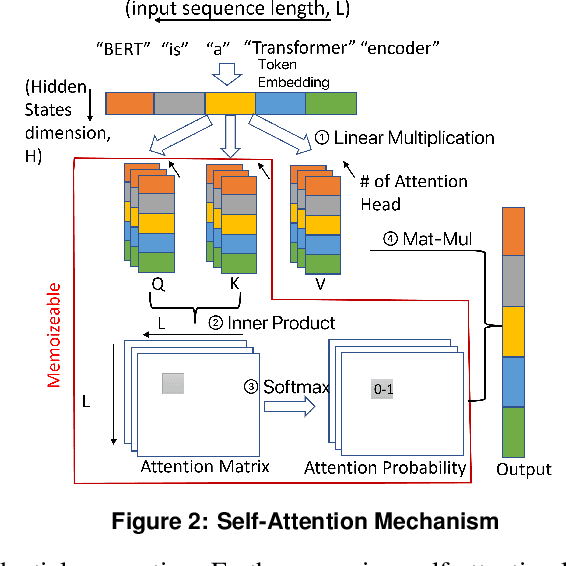
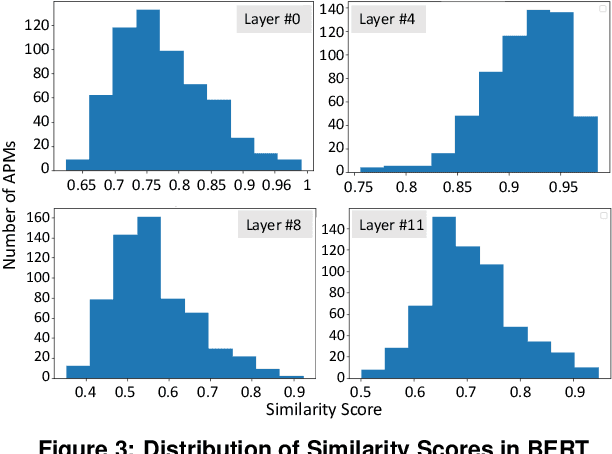
Transformers gain popularity because of their superior prediction accuracy and inference throughput. However, the transformer is computation-intensive, causing a long inference time. The existing work to accelerate transformer inferences has limitations because of the changes to transformer architectures or the need for specialized hardware. In this paper, we identify the opportunities of using memoization to accelerate the attention mechanism in transformers without the above limitation. Built upon a unique observation that there is a rich similarity in attention computation across inference sequences, we build an attention database upon the emerging big memory system. We introduce the embedding technique to find semantically similar inputs to identify computation similarity. We also introduce a series of techniques such as memory mapping and selective memoization to avoid memory copy and unnecessary overhead. We enable 21% performance improvement on average (up to 68%) with the TB-scale attention database and with ignorable loss in inference accuracy.
Federated Sufficient Dimension Reduction Through High-Dimensional Sparse Sliced Inverse Regression
Jan 23, 2023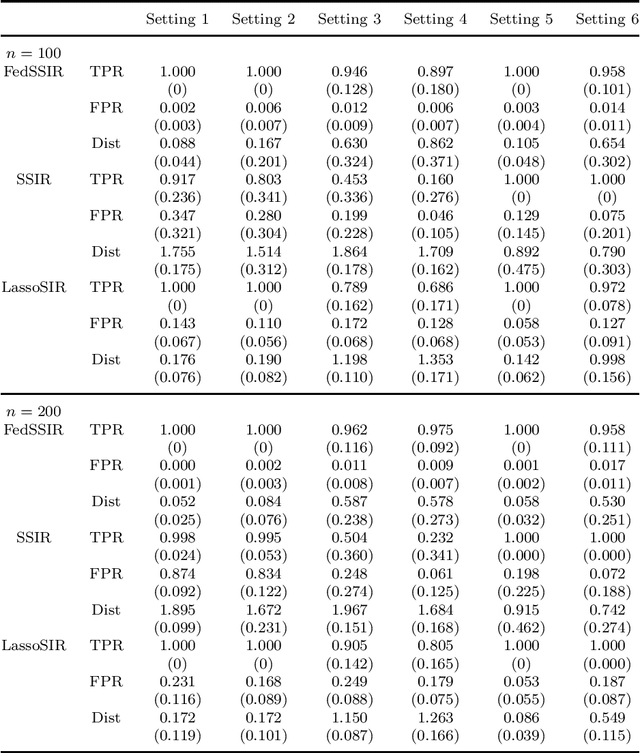
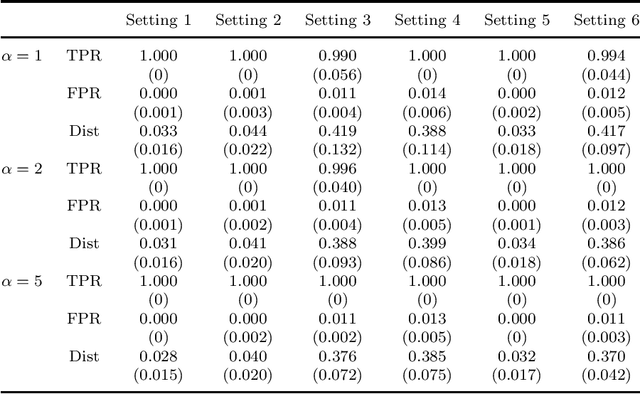
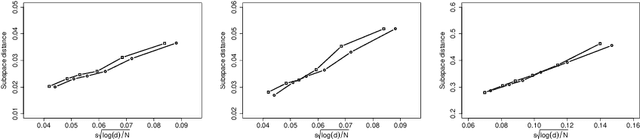
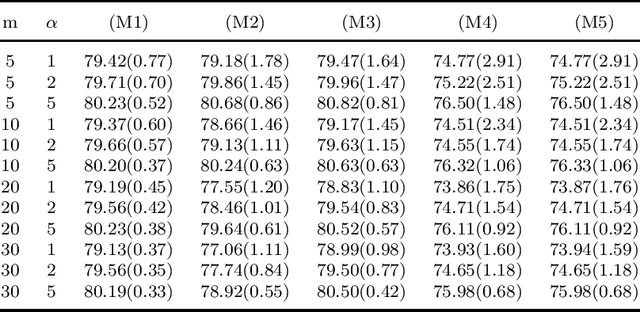
Federated learning has become a popular tool in the big data era nowadays. It trains a centralized model based on data from different clients while keeping data decentralized. In this paper, we propose a federated sparse sliced inverse regression algorithm for the first time. Our method can simultaneously estimate the central dimension reduction subspace and perform variable selection in a federated setting. We transform this federated high-dimensional sparse sliced inverse regression problem into a convex optimization problem by constructing the covariance matrix safely and losslessly. We then use a linearized alternating direction method of multipliers algorithm to estimate the central subspace. We also give approaches of Bayesian information criterion and hold-out validation to ascertain the dimension of the central subspace and the hyper-parameter of the algorithm. We establish an upper bound of the statistical error rate of our estimator under the heterogeneous setting. We demonstrate the effectiveness of our method through simulations and real world applications.