 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Forecasting formation of a Tropical Cyclone Using Reanalysis Data
Dec 10, 2022
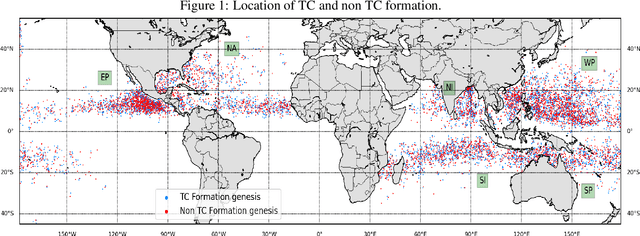
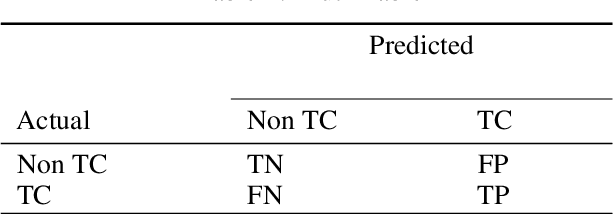
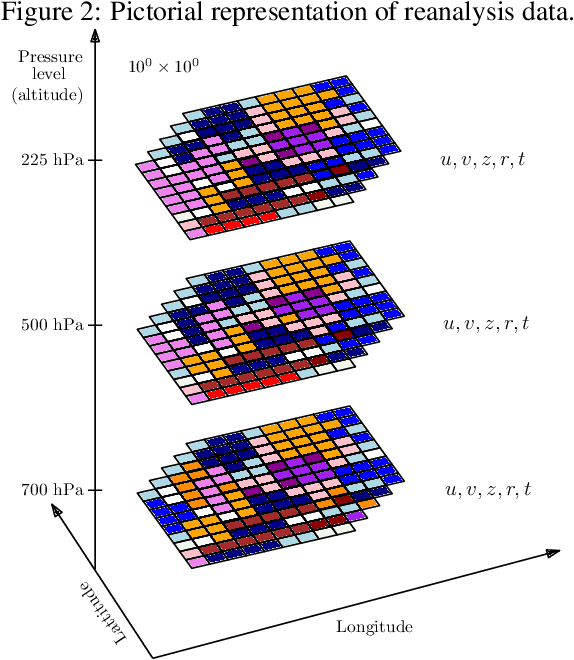
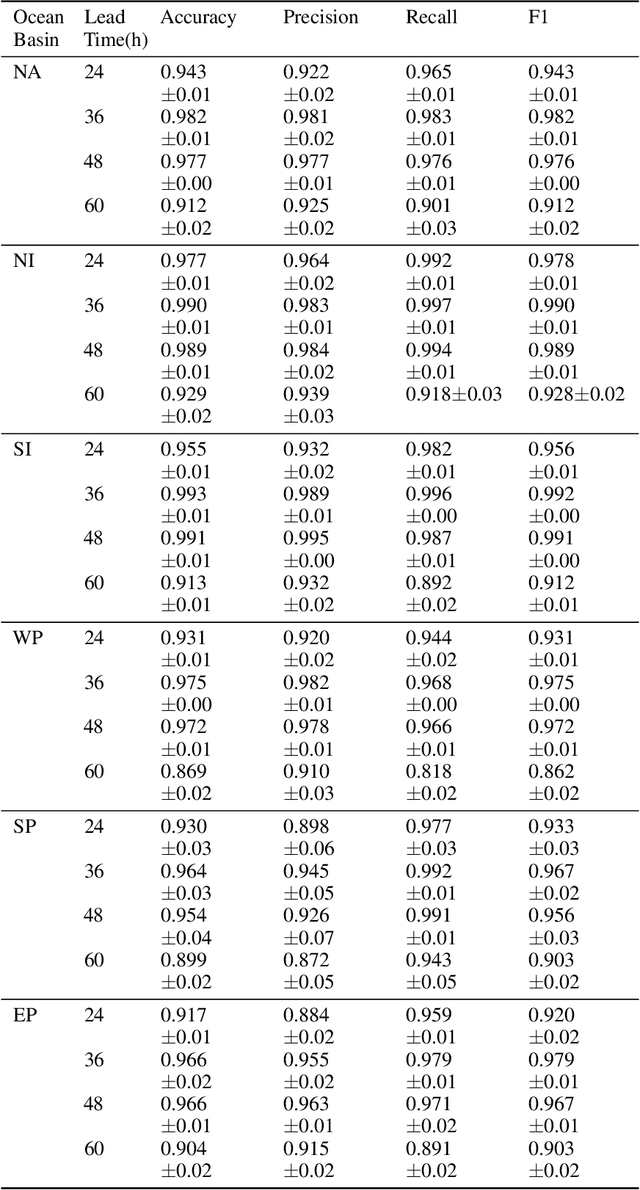
The tropical cyclone formation process is one of the most complex natural phenomena which is governed by various atmospheric, oceanographic, and geographic factors that varies with time and space. Despite several years of research, accurately predicting tropical cyclone formation remains a challenging task. While the existing numerical models have inherent limitations, the machine learning models fail to capture the spatial and temporal dimensions of the causal factors behind TC formation. In this study, a deep learning model has been proposed that can forecast the formation of a tropical cyclone with a lead time of up to 60 hours with high accuracy. The model uses the high-resolution reanalysis data ERA5 (ECMWF reanalysis 5th generation), and best track data IBTrACS (International Best Track Archive for Climate Stewardship) to forecast tropical cyclone formation in six ocean basins of the world. For 60 hours lead time the models achieve an accuracy in the range of 86.9% - 92.9% across the six ocean basins. The model takes about 5-15 minutes of training time depending on the ocean basin, and the amount of data used and can predict within seconds, thereby making it suitable for real-life usage.
LETS-GZSL: A Latent Embedding Model for Time Series Generalized Zero Shot Learning
Jul 25, 2022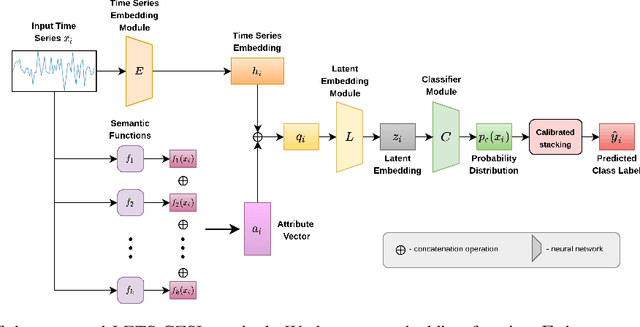
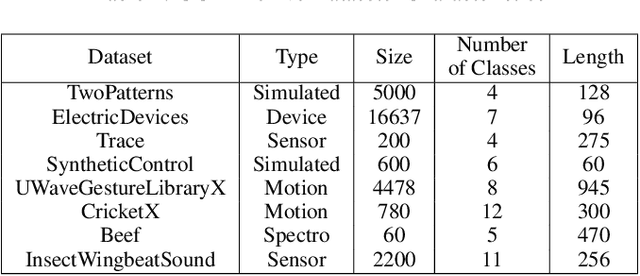
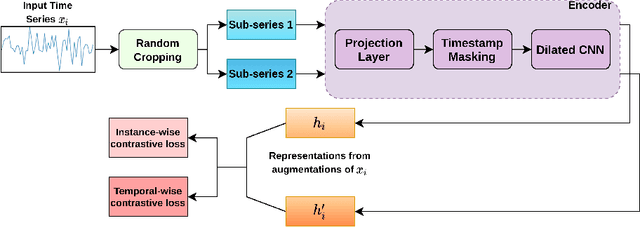
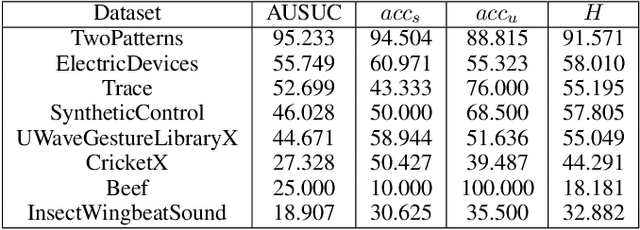
One of the recent developments in deep learning is generalized zero-shot learning (GZSL), which aims to recognize objects from both seen and unseen classes, when only the labeled examples from seen classes are provided. Over the past couple of years, GZSL has picked up traction and several models have been proposed to solve this problem. Whereas an extensive amount of research on GZSL has been carried out in fields such as computer vision and natural language processing, no such research has been carried out to deal with time series data. GZSL is used for applications such as detecting abnormalities from ECG and EEG data and identifying unseen classes from sensor, spectrograph and other devices' data. In this regard, we propose a Latent Embedding for Time Series - GZSL (LETS-GZSL) model that can solve the problem of GZSL for time series classification (TSC). We utilize an embedding-based approach and combine it with attribute vectors to predict the final class labels. We report our results on the widely popular UCR archive datasets. Our framework is able to achieve a harmonic mean value of at least 55% on most of the datasets except when the number of unseen classes is greater than 3 or the amount of data is very low (less than 100 training examples).
LiteLSTM Architecture Based on Weights Sharing for Recurrent Neural Networks
Jan 12, 2023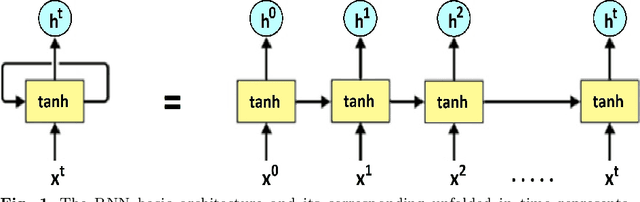

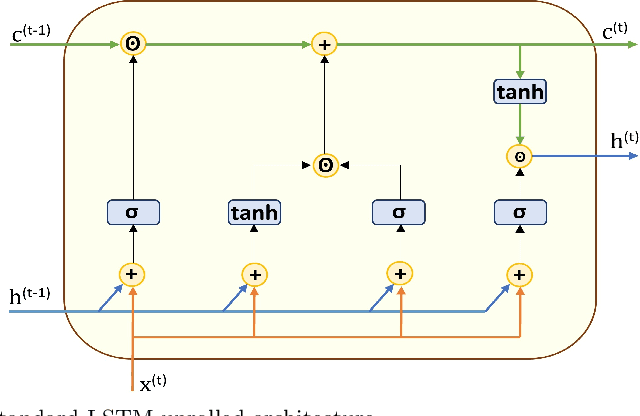
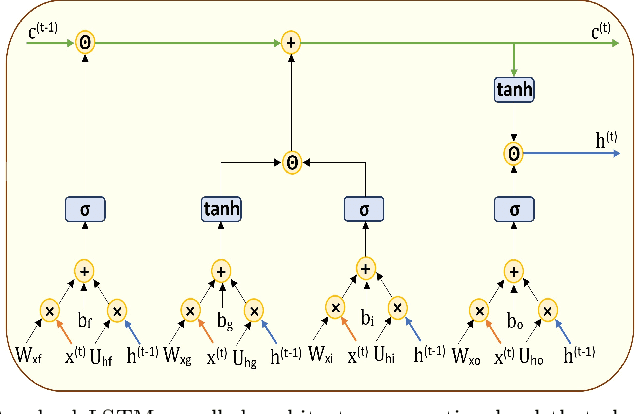
Long short-term memory (LSTM) is one of the robust recurrent neural network architectures for learning sequential data. However, it requires considerable computational power to learn and implement both software and hardware aspects. This paper proposed a novel LiteLSTM architecture based on reducing the LSTM computation components via the weights sharing concept to reduce the overall architecture computation cost and maintain the architecture performance. The proposed LiteLSTM can be significant for processing large data where time-consuming is crucial while hardware resources are limited, such as the security of IoT devices and medical data processing. The proposed model was evaluated and tested empirically on three different datasets from the computer vision, cybersecurity, speech emotion recognition domains. The proposed LiteLSTM has comparable accuracy to the other state-of-the-art recurrent architecture while using a smaller computation budget.
Towards Open World NeRF-Based SLAM
Jan 08, 2023

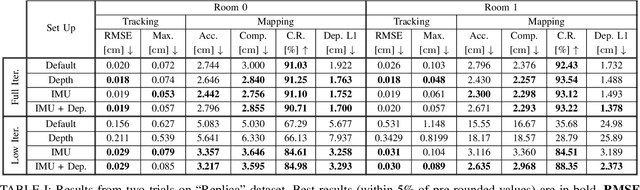
Neural Radiance Fields (NeRFs) have taken the machine vision and robotics perception communities by storm and are starting to be applied in robotics applications. NeRFs offer versatility and robustness in map representations for Simultaneous Localization and Mapping. However, computational difficulties of multilayer perceptrons (MLP) have lead to reductions in robustness in the state-of-the-art of NeRF-based SLAM algorithms in order to meet real-time requirements. In this report, we seek to improve accuracy and robustness of NICE-SLAM, a recent NeRF-based SLAM algorithm, by accounting for depth measurement uncertainty and using IMU measurements. Additionally, extend this algorithm by providing a model that can represent backgrounds that are too distant to be modeled by NeRF.
Bidirectional Propagation for Cross-Modal 3D Object Detection
Jan 22, 2023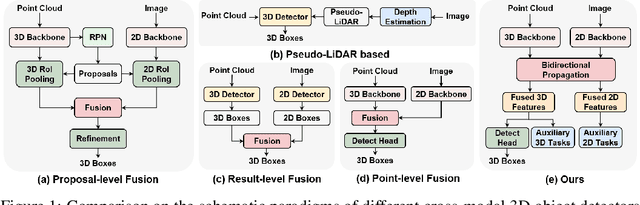
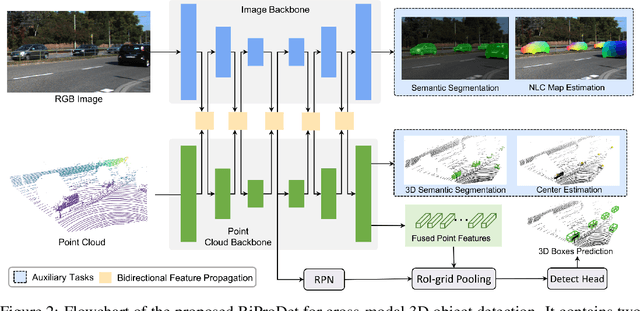
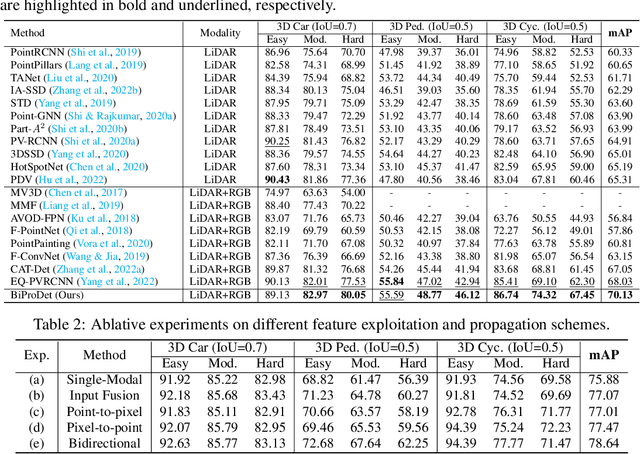
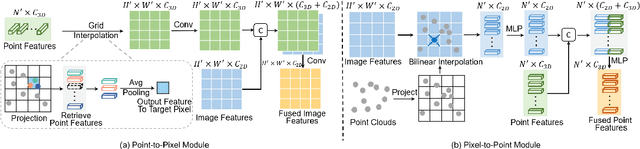
Recent works have revealed the superiority of feature-level fusion for cross-modal 3D object detection, where fine-grained feature propagation from 2D image pixels to 3D LiDAR points has been widely adopted for performance improvement. Still, the potential of heterogeneous feature propagation between 2D and 3D domains has not been fully explored. In this paper, in contrast to existing pixel-to-point feature propagation, we investigate an opposite point-to-pixel direction, allowing point-wise features to flow inversely into the 2D image branch. Thus, when jointly optimizing the 2D and 3D streams, the gradients back-propagated from the 2D image branch can boost the representation ability of the 3D backbone network working on LiDAR point clouds. Then, combining pixel-to-point and point-to-pixel information flow mechanisms, we construct an bidirectional feature propagation framework, dubbed BiProDet. In addition to the architectural design, we also propose normalized local coordinates map estimation, a new 2D auxiliary task for the training of the 2D image branch, which facilitates learning local spatial-aware features from the image modality and implicitly enhances the overall 3D detection performance. Extensive experiments and ablation studies validate the effectiveness of our method. Notably, we rank $\mathbf{1^{\mathrm{st}}}$ on the highly competitive KITTI benchmark on the cyclist class by the time of submission. The source code is available at https://github.com/Eaphan/BiProDet.
An Efficient Semi-Automated Scheme for Infrastructure LiDAR Annotation
Jan 25, 2023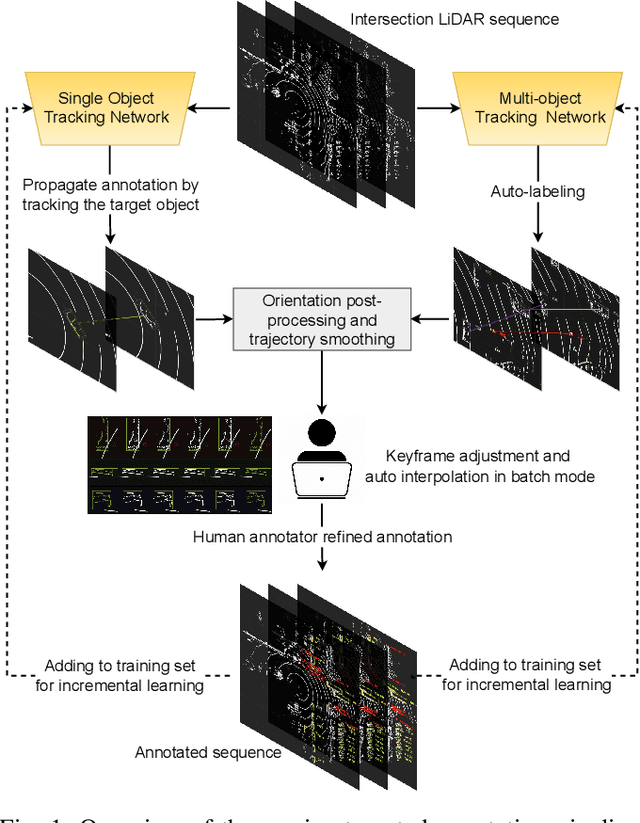


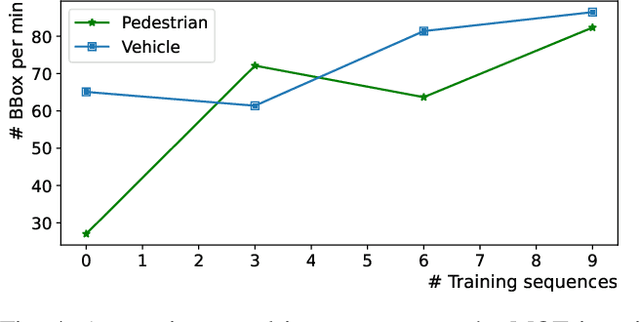
Most existing perception systems rely on sensory data acquired from cameras, which perform poorly in low light and adverse weather conditions. To resolve this limitation, we have witnessed advanced LiDAR sensors become popular in perception tasks in autonomous driving applications. Nevertheless, their usage in traffic monitoring systems is less ubiquitous. We identify two significant obstacles in cost-effectively and efficiently developing such a LiDAR-based traffic monitoring system: (i) public LiDAR datasets are insufficient for supporting perception tasks in infrastructure systems, and (ii) 3D annotations on LiDAR point clouds are time-consuming and expensive. To fill this gap, we present an efficient semi-automated annotation tool that automatically annotates LiDAR sequences with tracking algorithms while offering a fully annotated infrastructure LiDAR dataset -- FLORIDA (Florida LiDAR-based Object Recognition and Intelligent Data Annotation) -- which will be made publicly available. Our advanced annotation tool seamlessly integrates multi-object tracking (MOT), single-object tracking (SOT), and suitable trajectory post-processing techniques. Specifically, we introduce a human-in-the-loop schema in which annotators recursively fix and refine annotations imperfectly predicted by our tool and incrementally add them to the training dataset to obtain better SOT and MOT models. By repeating the process, we significantly increase the overall annotation speed by three to four times and obtain better qualitative annotations than a state-of-the-art annotation tool. The human annotation experiments verify the effectiveness of our annotation tool. In addition, we provide detailed statistics and object detection evaluation results for our dataset in serving as a benchmark for perception tasks at traffic intersections.
Ngram-LSTM Open Rate Prediction Model (NLORP) and Error_accuracy@C metric: Simple effective, and easy to implement approach to predict open rates for marketing email
Jan 25, 2023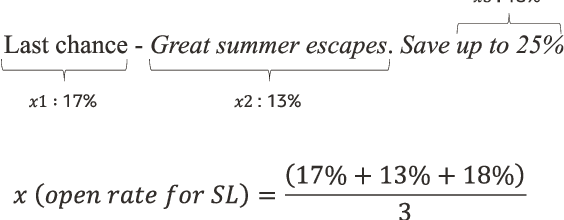
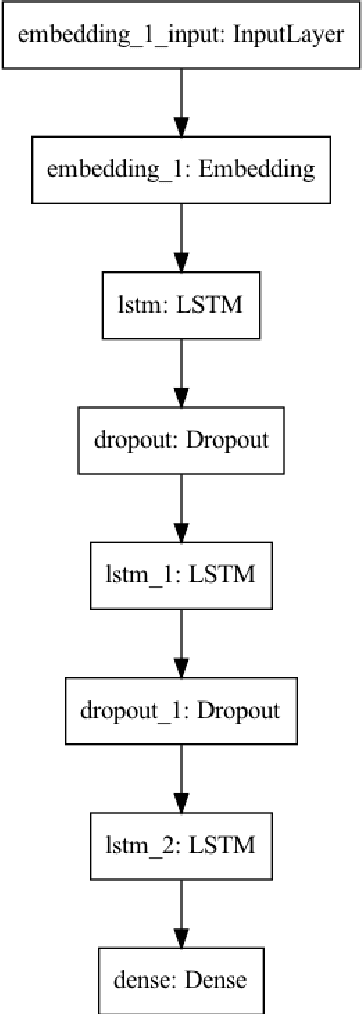
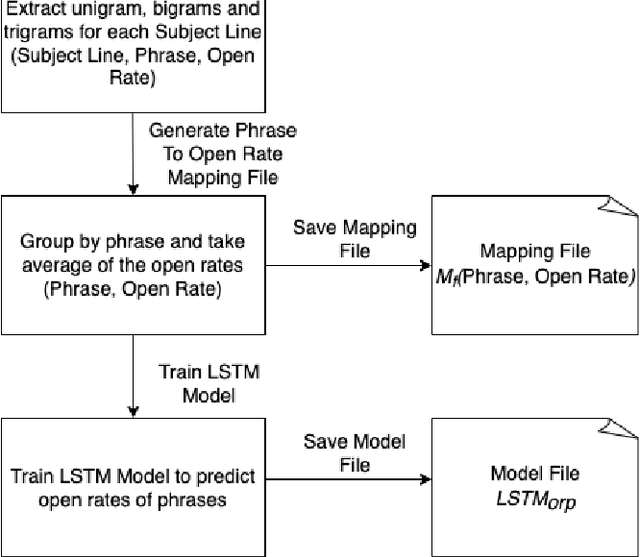
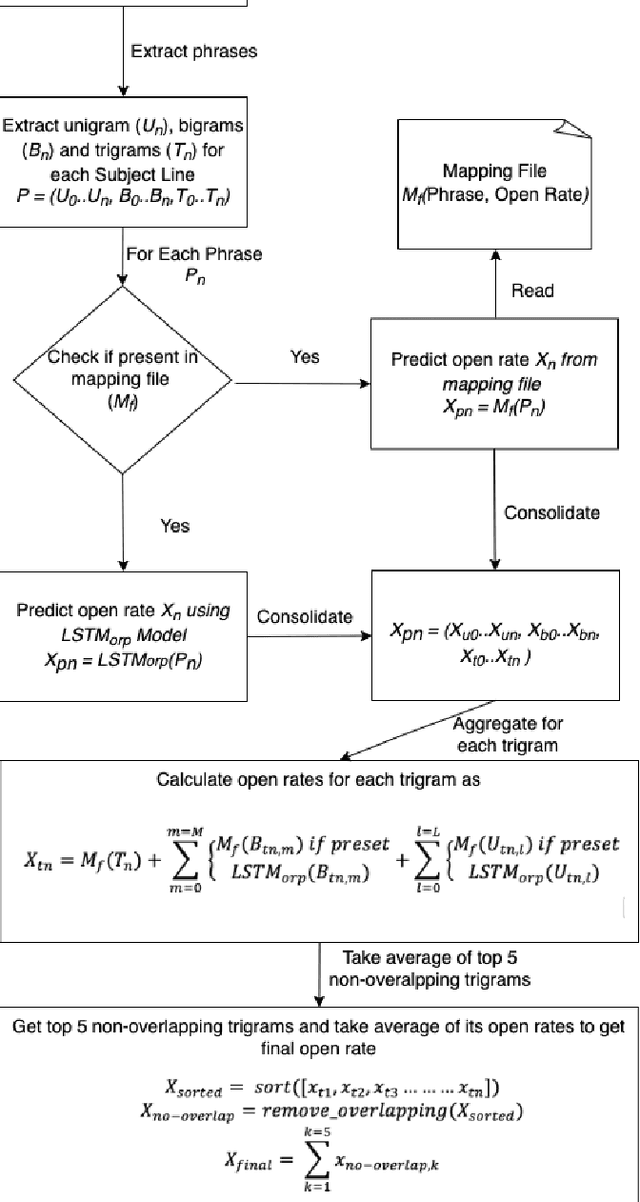
Our generation has seen an exponential increase in digital tools adoption. One of the unique areas where digital tools have made an exponential foray is in the sphere of digital marketing, where goods and services have been extensively promoted through the use of digital advertisements. Following this growth, multiple companies have leveraged multiple apps and channels to display their brand identities to a significantly larger user base. This has resulted in products, worth billions of dollars to be sold online. Emails and push notifications have become critical channels to publish advertisement content, to proactively engage with their contacts. Several marketing tools provide a user interface for marketers to design Email and Push messages for digital marketing campaigns. Marketers are also given a predicted open rate for the entered subject line. For enabling marketers generate targeted subject lines, multiple machine learning techniques have been used in the recent past. In particular, deep learning techniques that have established good effectiveness and efficiency. However, these techniques require a sizable amount of labelled training data in order to get good results. The creation of such datasets, particularly those with subject lines that have a specific theme, is a challenging and time-consuming task. In this paper, we propose a novel Ngram and LSTM-based modeling approach (NLORPM) to predict open rates of entered subject lines that is easier to implement, has low prediction latency, and performs extremely well for sparse data. To assess the performance of this model, we also devise a new metric called 'Error_accuracy@C' which is simple to grasp and fully comprehensible to marketers.
POSET-RL: Phase ordering for Optimizing Size and Execution Time using Reinforcement Learning
Jul 27, 2022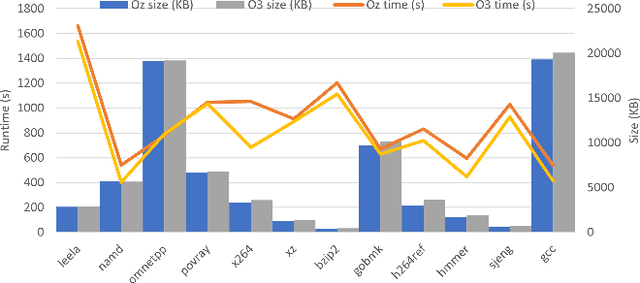
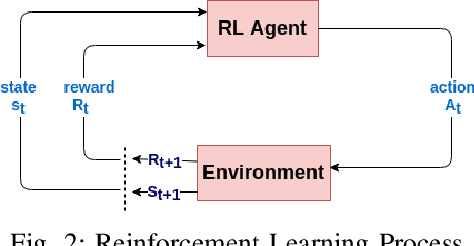
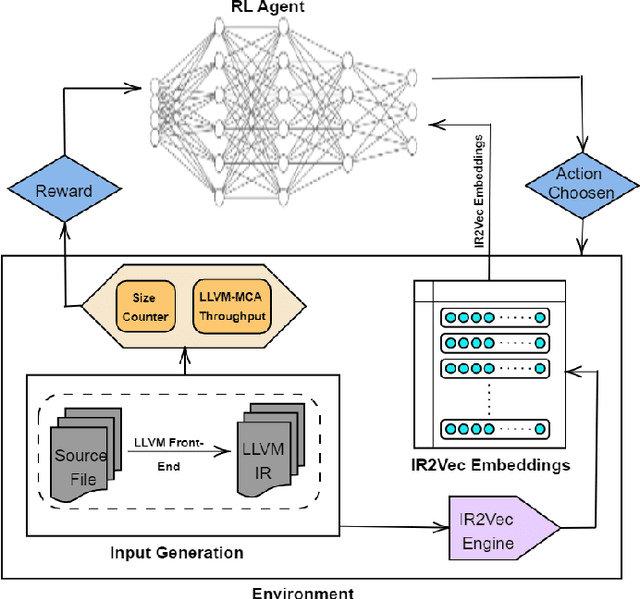
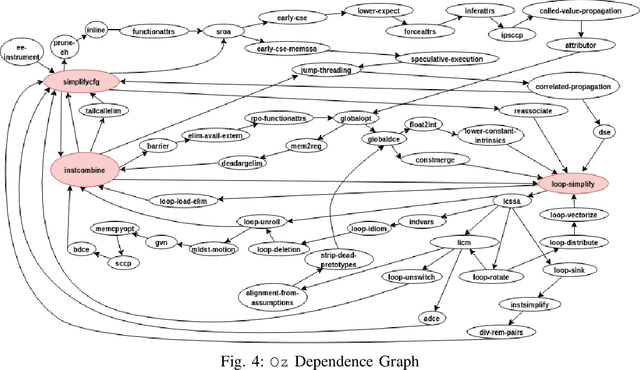
The ever increasing memory requirements of several applications has led to increased demands which might not be met by embedded devices. Constraining the usage of memory in such cases is of paramount importance. It is important that such code size improvements should not have a negative impact on the runtime. Improving the execution time while optimizing for code size is a non-trivial but a significant task. The ordering of standard optimization sequences in modern compilers is fixed, and are heuristically created by the compiler domain experts based on their expertise. However, this ordering is sub-optimal, and does not generalize well across all the cases. We present a reinforcement learning based solution to the phase ordering problem, where the ordering improves both the execution time and code size. We propose two different approaches to model the sequences: one by manual ordering, and other based on a graph called Oz Dependence Graph (ODG). Our approach uses minimal data as training set, and is integrated with LLVM. We show results on x86 and AArch64 architectures on the benchmarks from SPEC-CPU 2006, SPEC-CPU 2017 and MiBench. We observe that the proposed model based on ODG outperforms the current Oz sequence both in terms of size and execution time by 6.19% and 11.99% in SPEC 2017 benchmarks, on an average.
Model-based Transfer Learning for Automatic Optical Inspection based on domain discrepancy
Jan 14, 2023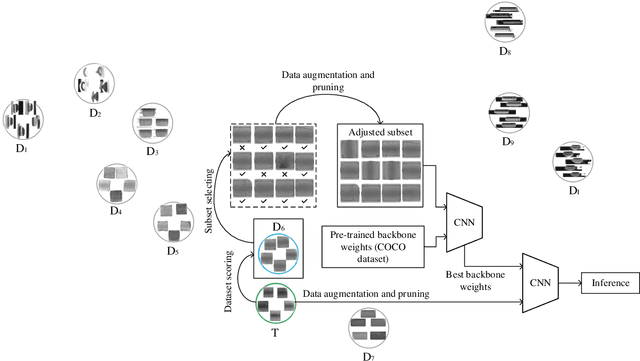

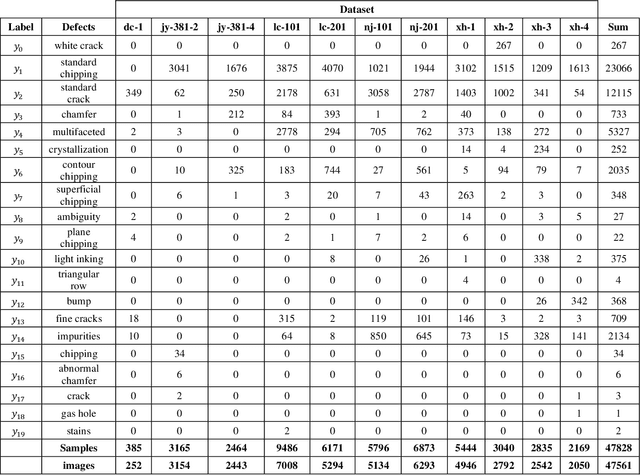
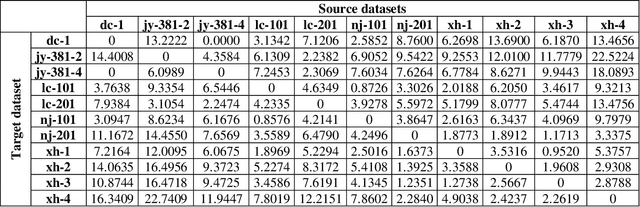
Transfer learning is a promising method for AOI applications since it can significantly shorten sample collection time and improve efficiency in today's smart manufacturing. However, related research enhanced the network models by applying TL without considering the domain similarity among datasets, the data long-tailedness of a source dataset, and mainly used linear transformations to mitigate the lack of samples. This research applies model-based TL via domain similarity to improve the overall performance and data augmentation in both target and source domains to enrich the data quality and reduce the imbalance. Given a group of source datasets from similar industrial processes, we define which group is the most related to the target through the domain discrepancy score and the number of samples each has. Then, we transfer the chosen pre-trained backbone weights to train and fine-tune the target network. Our research suggests increases in the F1 score and the PR curve up to 20% compared with TL using benchmark datasets.
* This is a fix of the published paper "Relational-based transfer learning for automatic optical inspection based on domain discrepancy"
Learning Trajectory-Conditioned Relations to Predict Pedestrian Crossing Behavior
Jan 14, 2023
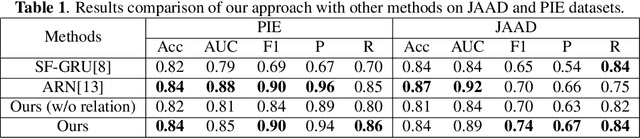
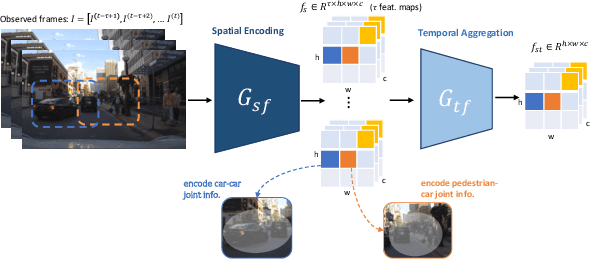
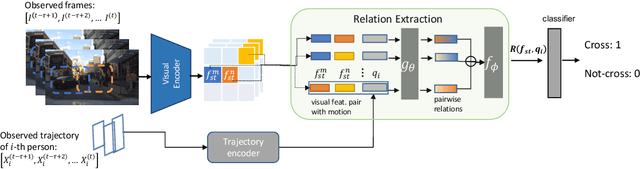
In smart transportation, intelligent systems avoid potential collisions by predicting the intent of traffic agents, especially pedestrians. Pedestrian intent, defined as future action, e.g., start crossing, can be dependent on traffic surroundings. In this paper, we develop a framework to incorporate such dependency given observed pedestrian trajectory and scene frames. Our framework first encodes regional joint information between a pedestrian and surroundings over time into feature-map vectors. The global relation representations are then extracted from pairwise feature-map vectors to estimate intent with past trajectory condition. We evaluate our approach on two public datasets and compare against two state-of-the-art approaches. The experimental results demonstrate that our method helps to inform potential risks during crossing events with 0.04 improvement in F1-score on JAAD dataset and 0.01 improvement in recall on PIE dataset. Furthermore, we conduct ablation experiments to confirm the contribution of the relation extraction in our framework.