 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Coincident Learning for Unsupervised Anomaly Detection
Jan 26, 2023
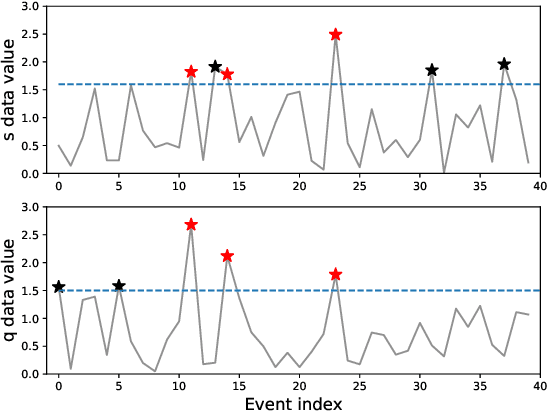

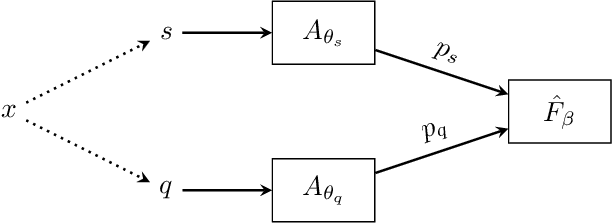
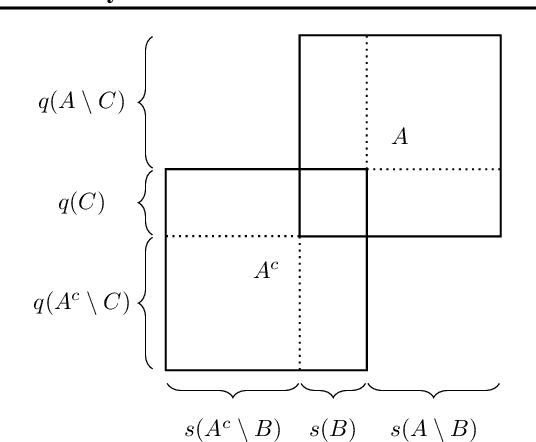
Anomaly detection is an important task for complex systems (e.g., industrial facilities, manufacturing, large-scale science experiments), where failures in a sub-system can lead to low yield, faulty products, or even damage to components. While complex systems often have a wealth of data, labeled anomalies are typically rare (or even nonexistent) and expensive to acquire. In this paper, we introduce a new method, called CoAD, for training anomaly detection models on unlabeled data, based on the expectation that anomalous behavior in one sub-system will produce coincident anomalies in downstream sub-systems and products. Given data split into two streams $s$ and $q$ (i.e., subsystem diagnostics and final product quality), we define an unsupervised metric, $\hat{F}_\beta$, out of analogy to the supervised classification $F_\beta$ statistic, which quantifies the performance of the independent anomaly detection algorithms on s and q based on their coincidence rate. We demonstrate our method in four cases: a synthetic time-series data set, a synthetic imaging data set generated from MNIST, a metal milling data set, and a data set taken from a particle accelerator.
Merging satellite and gauge-measured precipitation using LightGBM with an emphasis on extreme quantiles
Feb 02, 2023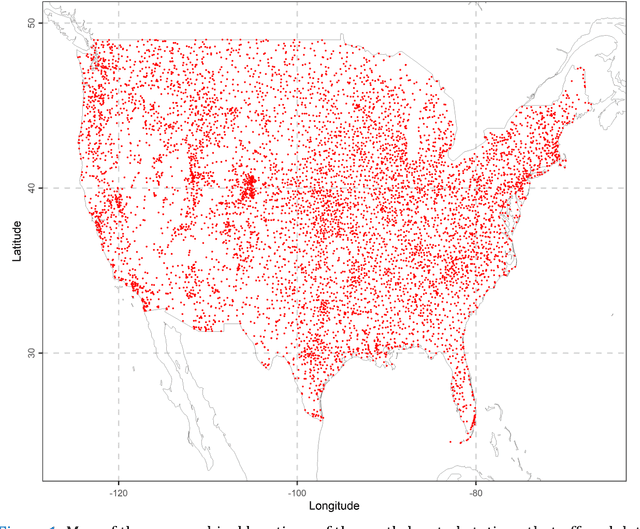
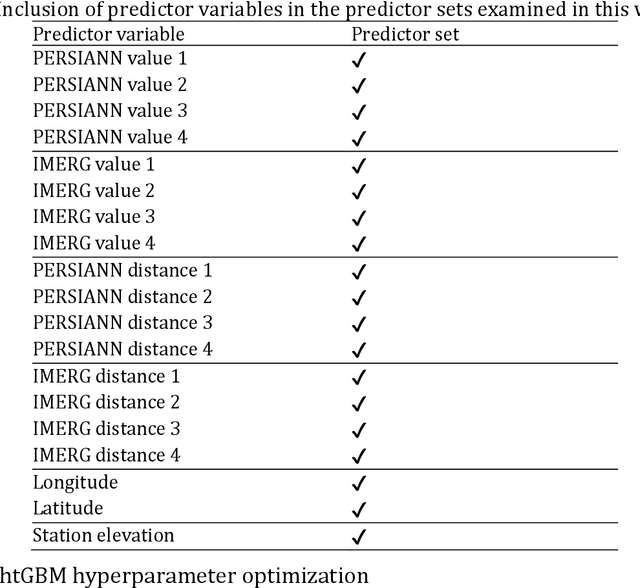

Knowing the actual precipitation in space and time is critical in hydrological modelling applications, yet the spatial coverage with rain gauge stations is limited due to economic constraints. Gridded satellite precipitation datasets offer an alternative option for estimating the actual precipitation by covering uniformly large areas, albeit related estimates are not accurate. To improve precipitation estimates, machine learning is applied to merge rain gauge-based measurements and gridded satellite precipitation products. In this context, observed precipitation plays the role of the dependent variable, while satellite data play the role of predictor variables. Random forests is the dominant machine learning algorithm in relevant applications. In those spatial predictions settings, point predictions (mostly the mean or the median of the conditional distribution) of the dependent variable are issued. Here we propose, issuing probabilistic spatial predictions of precipitation using Light Gradient Boosting Machine (LightGBM). LightGBM is a boosting algorithm, highlighted by prize-winning entries in prediction and forecasting competitions. To assess LightGBM, we contribute a large-scale application that includes merging daily precipitation measurements in contiguous US with PERSIANN and GPM-IMERG satellite precipitation data. We focus on extreme quantiles of the probability distribution of the dependent variable, where LightGBM outperforms quantile regression forests (QRF, a variant of random forests) in terms of quantile score. LightGBM and QRF show similar performance when predicting functionals at the centre of the conditional probability distribution, including the conditional median. Our study offers understanding of probabilistic predictions in spatial settings using machine learning.
IKOL: Inverse kinematics optimization layer for 3D human pose and shape estimation via Gauss-Newton differentiation
Feb 02, 2023
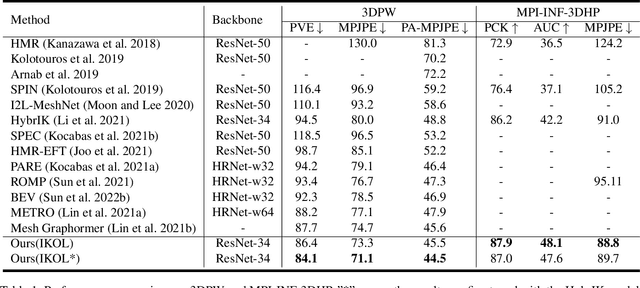
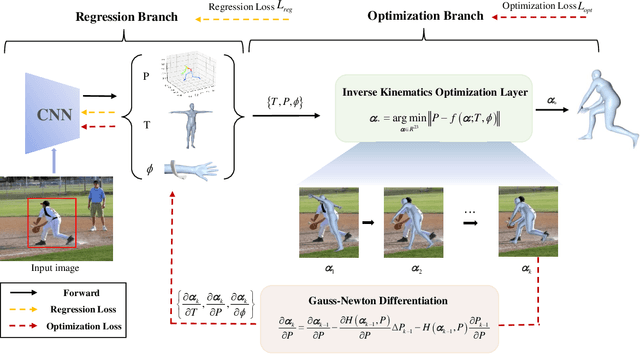
This paper presents an inverse kinematic optimization layer (IKOL) for 3D human pose and shape estimation that leverages the strength of both optimization- and regression-based methods within an end-to-end framework. IKOL involves a nonconvex optimization that establishes an implicit mapping from an image's 3D keypoints and body shapes to the relative body-part rotations. The 3D keypoints and the body shapes are the inputs and the relative body-part rotations are the solutions. However, this procedure is implicit and hard to make differentiable. So, to overcome this issue, we designed a Gauss-Newton differentiation (GN-Diff) procedure to differentiate IKOL. GN-Diff iteratively linearizes the nonconvex objective function to obtain Gauss-Newton directions with closed form solutions. Then, an automatic differentiation procedure is directly applied to generate a Jacobian matrix for end-to-end training. Notably, the GN-Diff procedure works fast because it does not rely on a time-consuming implicit differentiation procedure. The twist rotation and shape parameters are learned from the neural networks and, as a result, IKOL has a much lower computational overhead than most existing optimization-based methods. Additionally, compared to existing regression-based methods, IKOL provides a more accurate mesh-image correspondence. This is because it iteratively reduces the distance between the keypoints and also enhances the reliability of the pose structures. Extensive experiments demonstrate the superiority of our proposed framework over a wide range of 3D human pose and shape estimation methods.
LesionAid: Vision Transformers-based Skin Lesion Generation and Classification
Feb 02, 2023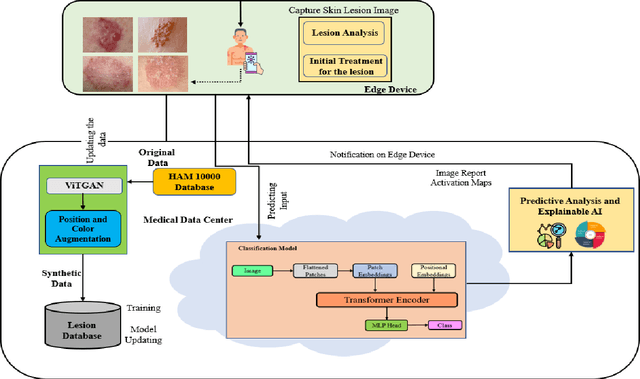
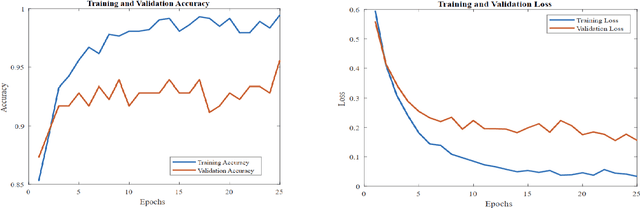
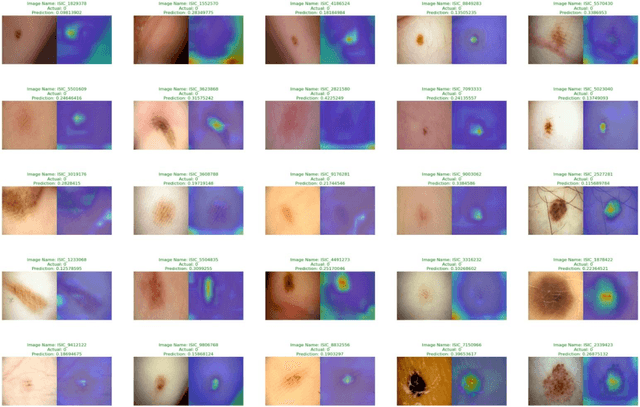
Skin cancer is one of the most prevalent forms of human cancer. It is recognized mainly visually, beginning with clinical screening and continuing with the dermoscopic examination, histological assessment, and specimen collection. Deep convolutional neural networks (CNNs) perform highly segregated and potentially universal tasks against a classified finegrained object. This research proposes a novel multi-class prediction framework that classifies skin lesions based on ViT and ViTGAN. Vision transformers-based GANs (Generative Adversarial Networks) are utilized to tackle the class imbalance. The framework consists of four main phases: ViTGANs, Image processing, and explainable AI. Phase 1 consists of generating synthetic images to balance all the classes in the dataset. Phase 2 consists of applying different data augmentation techniques and morphological operations to increase the size of the data. Phases 3 & 4 involve developing a ViT model for edge computing systems that can identify patterns and categorize skin lesions from the user's skin visible in the image. In phase 3, after classifying the lesions into the desired class with ViT, we will use explainable AI (XAI) that leads to more explainable results (using activation maps, etc.) while ensuring high predictive accuracy. Real-time images of skin diseases can capture by a doctor or a patient using the camera of a mobile application to perform an early examination and determine the cause of the skin lesion. The whole framework is compared with the existing frameworks for skin lesion detection.
A Comprehensive Study of Real-Time Object Detection Networks Across Multiple Domains: A Survey
Aug 23, 2022
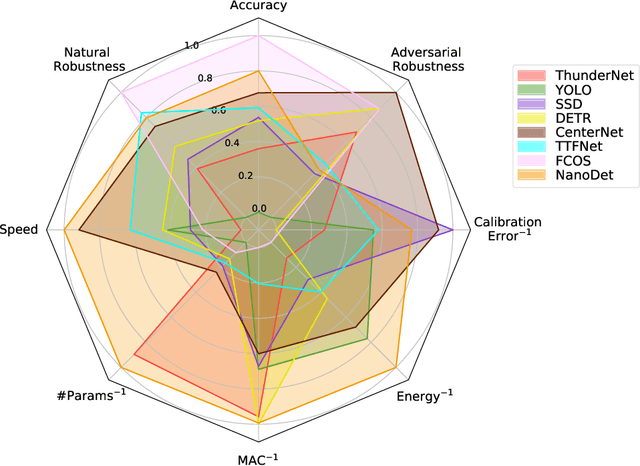
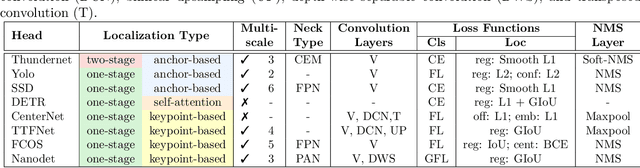
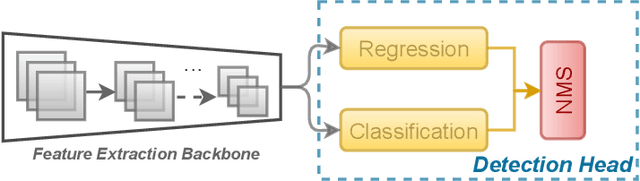
Deep neural network based object detectors are continuously evolving and are used in a multitude of applications, each having its own set of requirements. While safety-critical applications need high accuracy and reliability, low-latency tasks need resource and energy-efficient networks. Real-time detectors, which are a necessity in high-impact real-world applications, are continuously proposed, but they overemphasize the improvements in accuracy and speed while other capabilities such as versatility, robustness, resource and energy efficiency are omitted. A reference benchmark for existing networks does not exist, nor does a standard evaluation guideline for designing new networks, which results in ambiguous and inconsistent comparisons. We, thus, conduct a comprehensive study on multiple real-time detectors (anchor-, keypoint-, and transformer-based) on a wide range of datasets and report results on an extensive set of metrics. We also study the impact of variables such as image size, anchor dimensions, confidence thresholds, and architecture layers on the overall performance. We analyze the robustness of detection networks against distribution shifts, natural corruptions, and adversarial attacks. Also, we provide a calibration analysis to gauge the reliability of the predictions. Finally, to highlight the real-world impact, we conduct two unique case studies, on autonomous driving and healthcare applications. To further gauge the capability of networks in critical real-time applications, we report the performance after deploying the detection networks on edge devices. Our extensive empirical study can act as a guideline for the industrial community to make an informed choice on the existing networks. We also hope to inspire the research community towards a new direction in the design and evaluation of networks that focuses on a bigger and holistic overview for a far-reaching impact.
* Published in Transactions on Machine Learning Research (TMLR) with Survey Certification
LSDM: Long-Short Diffeomorphic Motion for Weakly-Supervised Ultrasound Landmark Tracking
Jan 11, 2023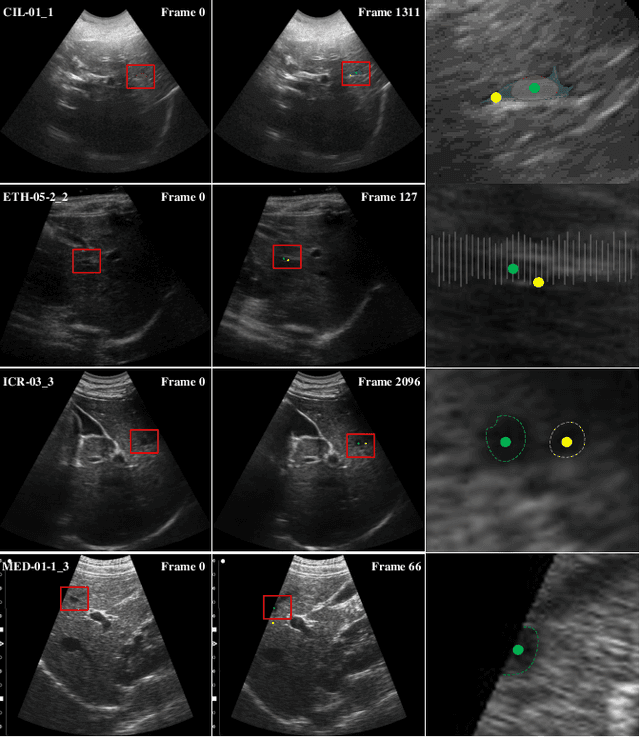
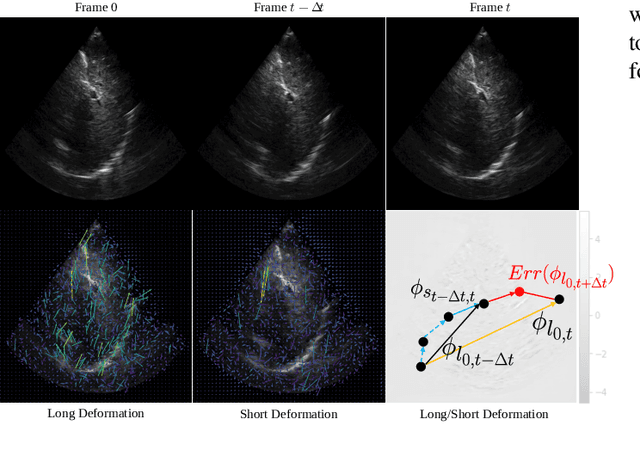
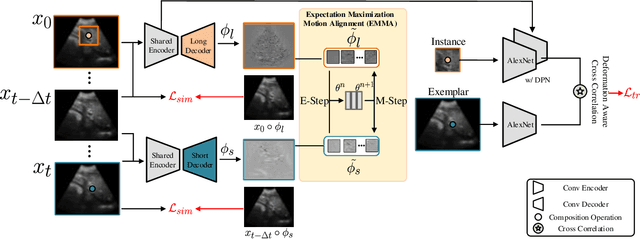
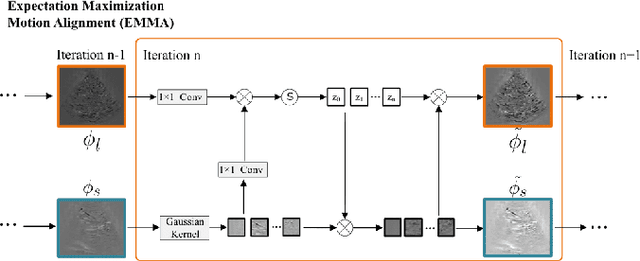
Accurate tracking of an anatomical landmark over time has been of high interests for disease assessment such as minimally invasive surgery and tumor radiation therapy. Ultrasound imaging is a promising modality benefiting from low-cost and real-time acquisition. However, generating a precise landmark tracklet is very challenging, as attempts can be easily distorted by different interference such as landmark deformation, visual ambiguity and partial observation. In this paper, we propose a long-short diffeomorphic motion network, which is a multi-task framework with a learnable deformation prior to search for the plausible deformation of landmark. Specifically, we design a novel diffeomorphism representation in both long and short temporal domains for delineating motion margins and reducing long-term cumulative tracking errors. To further mitigate local anatomical ambiguity, we propose an expectation maximisation motion alignment module to iteratively optimize both long and short deformation, aligning to the same directional and spatial representation. The proposed multi-task system can be trained in a weakly-supervised manner, which only requires few landmark annotations for tracking and zero annotation for long-short deformation learning. We conduct extensive experiments on two ultrasound landmark tracking datasets. Experimental results show that our proposed method can achieve better or competitive landmark tracking performance compared with other state-of-the-art tracking methods, with a strong generalization capability across different scanner types and different ultrasound modalities.
Codebook Based Two-Time Scale Resource Allocation Design for IRS-Assisted eMBB-URLLC Systems
Aug 07, 2022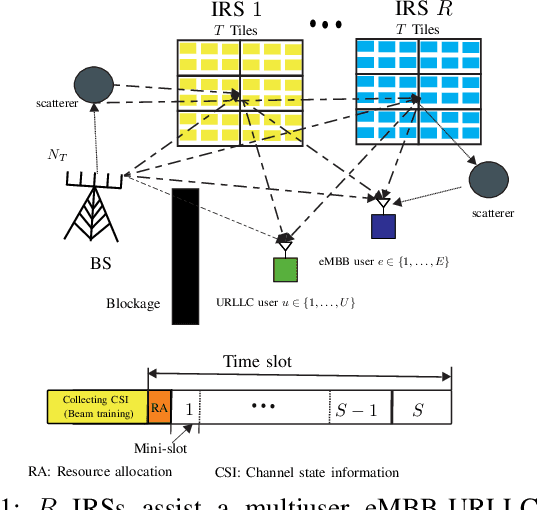
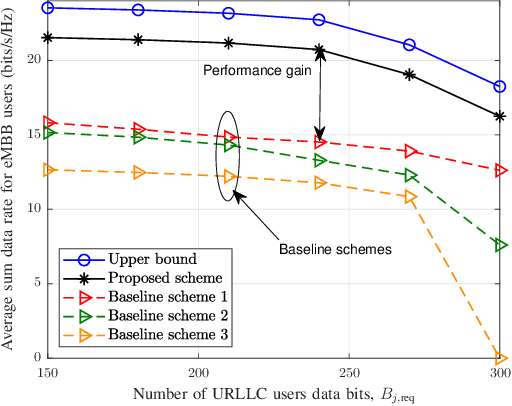
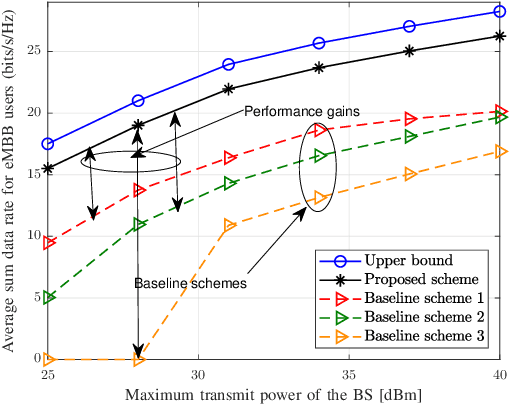
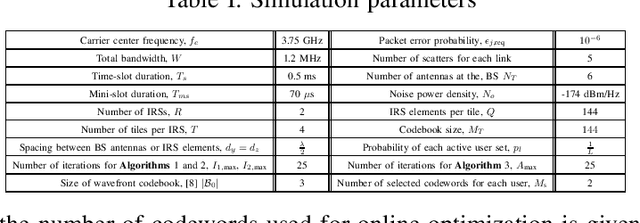
This paper investigates the resource allocation algorithm design for wireless systems assisted by large intelligent reflecting surfaces (IRSs) with coexisting enhanced mobile broadband (eMBB) and ultra reliable low-latency communication (URLLC) users. We consider a two-time scale resource allocation scheme, whereby the base station's precoders are optimized in each mini-slot to adapt to newly arriving URLLC traffic, whereas the IRS phase shifts are reconfigured only in each time slot to avoid excessive base station-IRS signaling. To facilitate efficient resource allocation design for large IRSs, we employ a codebook-based optimization framework, where the IRS is divided into several tiles and the phase-shift elements of each tile are selected from a pre-defined codebook. The resource allocation algorithm design is formulated as an optimization problem for the maximization of the average sum data rate of the eMBB users over a time slot while guaranteeing the quality-of-service (QoS) of each URLLC user in each mini-slot. An iterative algorithm based on alternating optimization (AO) is proposed to find a high-quality suboptimal solution. As a case study, the proposed algorithm is applied in an industrial indoor environment modelled via the Quadriga channel simulator. Our simulation results show that the proposed algorithm design enables the coexistence of eMBB and URLLC users and yields large performance gains compared to three baseline schemes. Furthermore, our simulation results reveal that the proposed two-time scale resource allocation design incurs only a small performance loss compared to the case when the IRSs are optimized in each mini-slot.
Development of a Self-Calibrated Motion Capture System by Nonlinear Trilateration of Multiple Kinects v2
Dec 25, 2022



In this paper, a Kinect-based distributed and real-time motion capture system is developed. A trigonometric method is applied to calculate the relative position of Kinect v2 sensors with a calibration wand and register the sensors' positions automatically. By combining results from multiple sensors with a nonlinear least square method, the accuracy of the motion capture is optimized. Moreover, to exclude inaccurate results from sensors, a computational geometry is applied in the occlusion approach, which discovers occluded joint data. The synchronization approach is based on an NTP protocol that synchronizes the time between the clocks of a server and clients dynamically, ensuring that the proposed system is a real-time system. Experiments for validating the proposed system are conducted from the perspective of calibration, occlusion, accuracy, and efficiency. Furthermore, to demonstrate the practical performance of our system, a comparison of previously developed motion capture systems (the linear trilateration approach and the geometric trilateration approach) with the benchmark OptiTrack system is conducted, therein showing that the accuracy of our proposed system is $38.3\%$ and 24.1% better than the two aforementioned trilateration systems, respectively.
An ensemble-based framework for mispronunciation detection of Arabic phonemes
Jan 03, 2023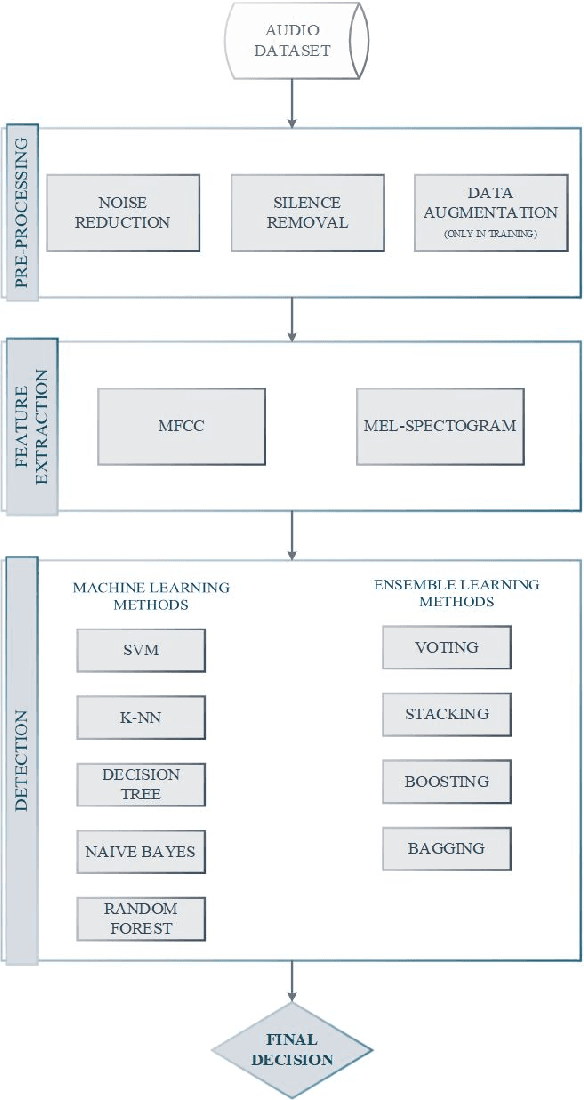
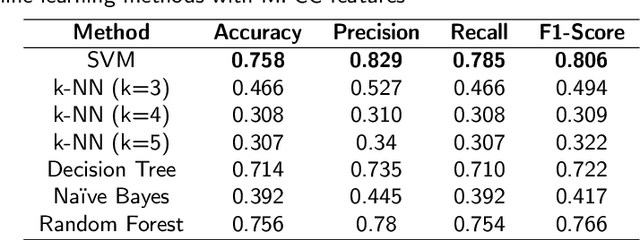
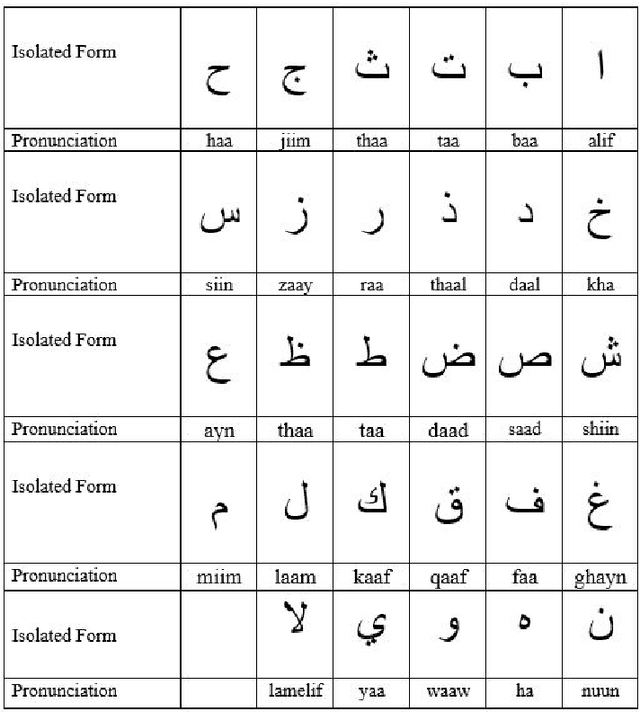
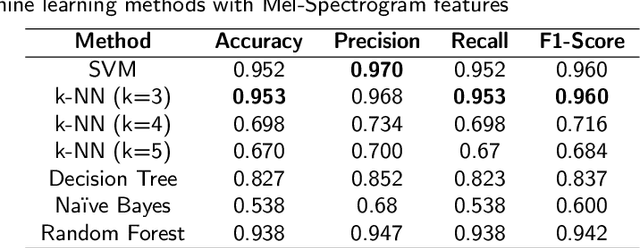
Determination of mispronunciations and ensuring feedback to users are maintained by computer-assisted language learning (CALL) systems. In this work, we introduce an ensemble model that defines the mispronunciation of Arabic phonemes and assists learning of Arabic, effectively. To the best of our knowledge, this is the very first attempt to determine the mispronunciations of Arabic phonemes employing ensemble learning techniques and conventional machine learning models, comprehensively. In order to observe the effect of feature extraction techniques, mel-frequency cepstrum coefficients (MFCC), and Mel spectrogram are blended with each learning algorithm. To show the success of proposed model, 29 letters in the Arabic phonemes, 8 of which are hafiz, are voiced by a total of 11 different person. The amount of data set has been enhanced employing the methods of adding noise, time shifting, time stretching, pitch shifting. Extensive experiment results demonstrate that the utilization of voting classifier as an ensemble algorithm with Mel spectrogram feature extraction technique exhibits remarkable classification result with 95.9% of accuracy.
Through-life Monitoring of Resource-constrained Systems and Fleets
Jan 03, 2023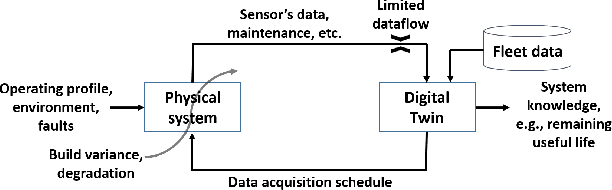
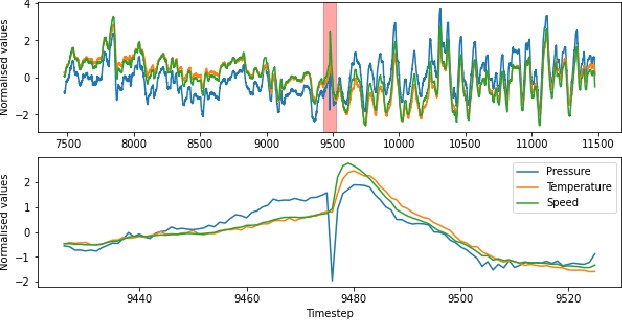
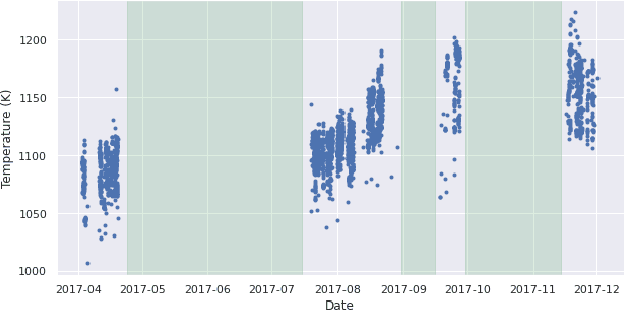
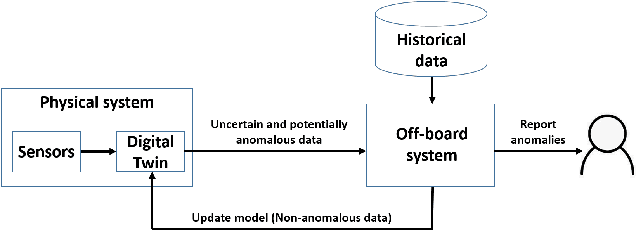
A Digital Twin (DT) is a simulation of a physical system that provides information to make decisions that add economic, social or commercial value. The behaviour of a physical system changes over time, a DT must therefore be continually updated with data from the physical systems to reflect its changing behaviour. For resource-constrained systems, updating a DT is non-trivial because of challenges such as on-board learning and the off-board data transfer. This paper presents a framework for updating data-driven DTs of resource-constrained systems geared towards system health monitoring. The proposed solution consists of: (1) an on-board system running a light-weight DT allowing the prioritisation and parsimonious transfer of data generated by the physical system; and (2) off-board robust updating of the DT and detection of anomalous behaviours. Two case studies are considered using a production gas turbine engine system to demonstrate the digital representation accuracy for real-world, time-varying physical systems.