 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Conversational Recommender System via Contextual and Time-Aware Modeling with Less Domain-Specific Knowledge
Sep 23, 2022
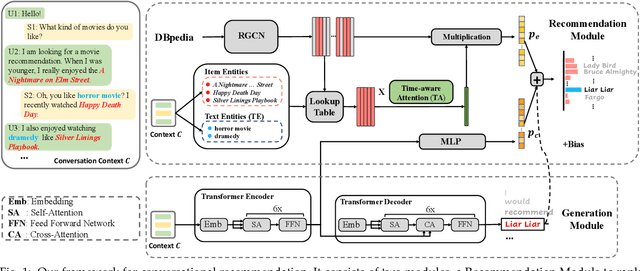
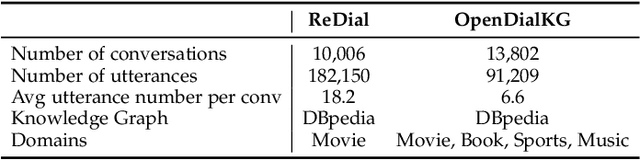
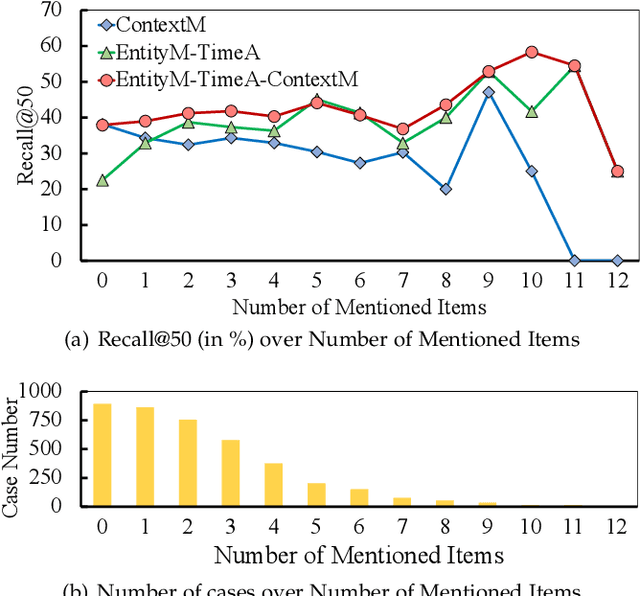
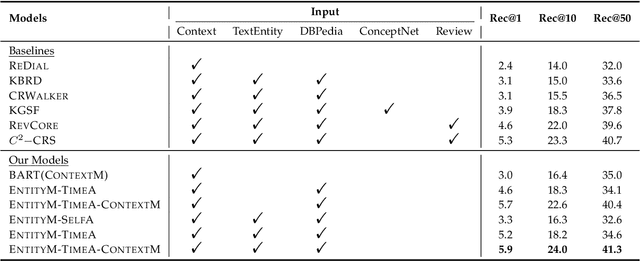
Conversational Recommender Systems (CRS) has become an emerging research topic seeking to perform recommendations through interactive conversations, which generally consist of generation and recommendation modules. Prior work on CRS tends to incorporate more external and domain-specific knowledge like item reviews to enhance performance. Despite the fact that the collection and annotation of the external domain-specific information needs much human effort and degenerates the generalizability, too much extra knowledge introduces more difficulty to balance among them. Therefore, we propose to fully discover and extract internal knowledge from the context. We capture both entity-level and contextual-level representations to jointly model user preferences for the recommendation, where a time-aware attention is designed to emphasize the recently appeared items in entity-level representations. We further use the pre-trained BART to initialize the generation module to alleviate the data scarcity and enhance the context modeling. In addition to conducting experiments on a popular dataset (ReDial), we also include a multi-domain dataset (OpenDialKG) to show the effectiveness of our model. Experiments on both datasets show that our model achieves better performance on most evaluation metrics with less external knowledge and generalizes well to other domains. Additional analyses on the recommendation and generation tasks demonstrate the effectiveness of our model in different scenarios.
Deep Learning for Short-Latency Epileptic Seizure Detection with Probabilistic Classification
Jan 04, 2023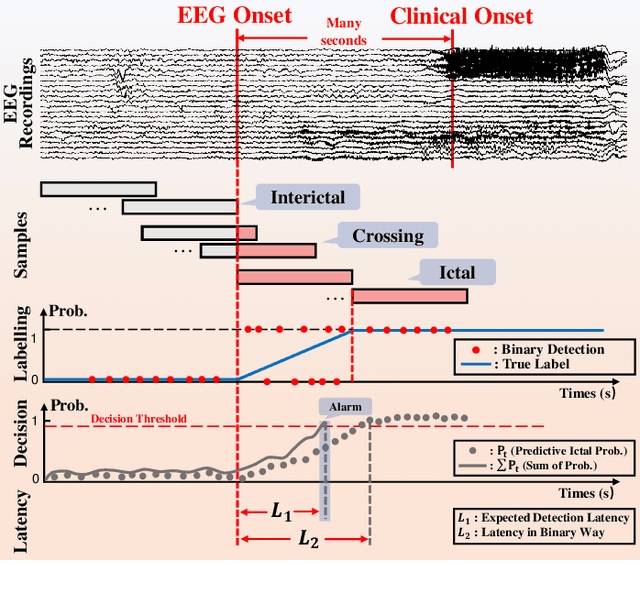
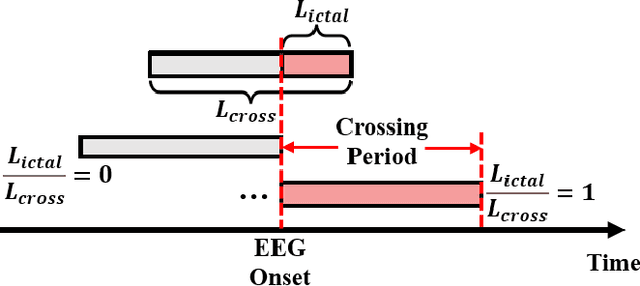
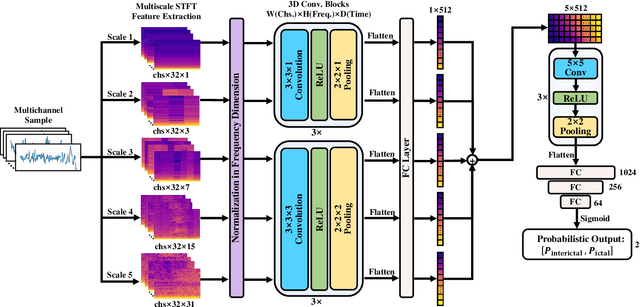
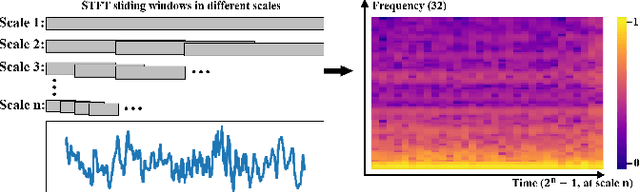
In this manuscript, we propose a novel deep learning (DL)-based framework intended for obtaining short latency in real-time electroencephalogram-based epileptic seizure detection using multiscale 3D convolutional neural networks. We pioneer converting seizure detection task from traditional binary classification of samples from ictal and interictal periods to probabilistic classification of samples from interictal, ictal, and crossing periods. We introduce a crossing period from seizure-oriented EEG recording and propose a labelling rule using soft-label for samples from the crossing period to build a probabilistic classification task. A novel multiscale short-time Fourier transform feature extraction method and 3D convolution neural network architecture are proposed to accurately capture predictive probabilities of samples. Furthermore, we also propose rectified weighting strategy to enhance predictive probabilities, and accumulative decision-making rule to achieve short detection latency. We implement leave-one-seizure-out cross validation on two prevalent datasets -- CHB-MIT scalp EEG dataset and SWEC-ETHZ intracranial EEG dataset. Eventually, the proposed algorithm achieved 94 out of 99 seizures detected during the crossing period, averaged 14.84% rectified predictive ictal probability (RPIP) errors of crossing samples, 2.3 s detection latency, 0.32/h false detection rate on CHB-MIT dataset, meanwhile 84 out of 89 detected seizures, 16.17% RPIP errors, 4.7 s detection latency, and 0.75/h FDR are achieved on SWEC-ETHZ dataset. The obtained detection latencies are at least 50% faster than state-of-the-art results reported in previous studies.
SuperScaler: Supporting Flexible DNN Parallelization via a Unified Abstraction
Jan 21, 2023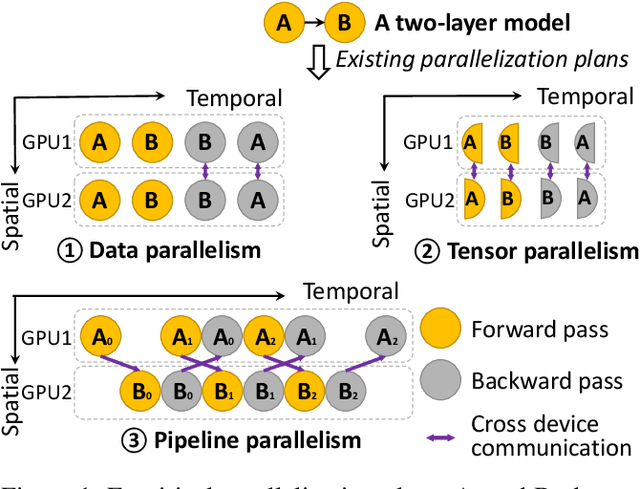



With the growing model size, deep neural networks (DNN) are increasingly trained over massive GPU accelerators, which demands a proper parallelization plan that transforms a DNN model into fine-grained tasks and then schedules them to GPUs for execution. Due to the large search space, the contemporary parallelization plan generators often rely on empirical rules that couple transformation and scheduling, and fall short in exploring more flexible schedules that yield better memory usage and compute efficiency. This tension can be exacerbated by the emerging models with increasing complexity in their structure and model size. SuperScaler is a system that facilitates the design and generation of highly flexible parallelization plans. It formulates the plan design and generation into three sequential phases explicitly: model transformation, space-time scheduling, and data dependency preserving. Such a principled approach decouples multiple seemingly intertwined factors and enables the composition of highly flexible parallelization plans. As a result, SuperScaler can not only generate empirical parallelization plans, but also construct new plans that achieve up to 3.5X speedup compared to state-of-the-art solutions like DeepSpeed, Megatron and Alpa, for emerging DNN models like Swin-Transformer and AlphaFold2, as well as well-optimized models like GPT-3.
Collective Privacy Recovery: Data-sharing Coordination via Decentralized Artificial Intelligence
Jan 15, 2023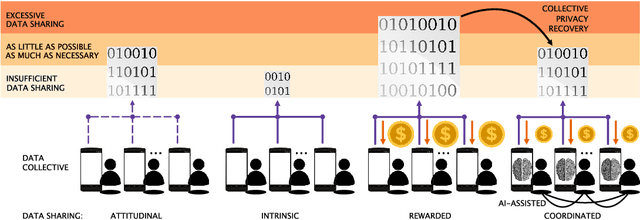
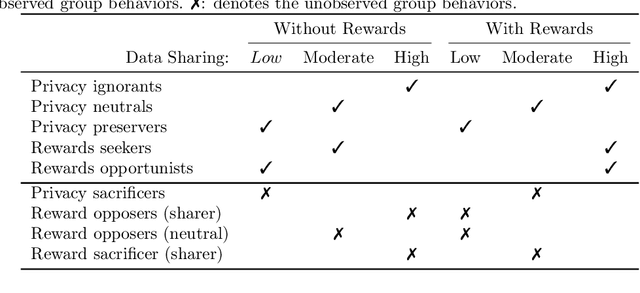


Collective privacy loss becomes a colossal problem, an emergency for personal freedoms and democracy. But, are we prepared to handle personal data as scarce resource and collectively share data under the doctrine: as little as possible, as much as necessary? We hypothesize a significant privacy recovery if a population of individuals, the data collective, coordinates to share minimum data for running online services with the required quality. Here we show how to automate and scale-up complex collective arrangements for privacy recovery using decentralized artificial intelligence. For this, we compare for first time attitudinal, intrinsic, rewarded and coordinated data sharing in a rigorous living-lab experiment of high realism involving >27,000 data-sharing choices. Using causal inference and cluster analysis, we differentiate criteria predicting privacy and five key data-sharing behaviors. Strikingly, data-sharing coordination proves to be a win-win for all: remarkable privacy recovery for people with evident costs reduction for service providers.
MTGFlow: Unsupervised Multivariate Time Series Anomaly Detection via Dynamic Graph and Entity-aware Normalizing Flow
Aug 03, 2022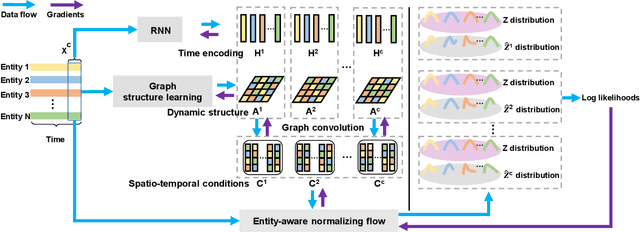

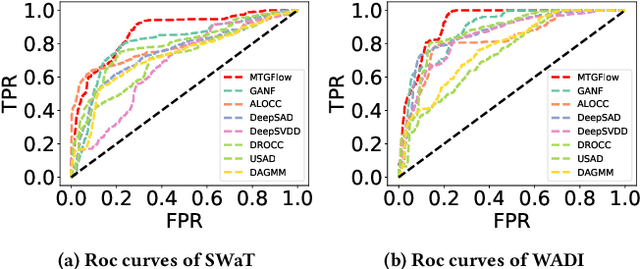

Multivariate time series anomaly detection has been extensively studied under the semi-supervised setting, where a training dataset with all normal instances is required. However, preparing such a dataset is very laborious since each single data instance should be fully guaranteed to be normal. It is, therefore, desired to explore multivariate time series anomaly detection methods based on the dataset without any label knowledge. In this paper, we propose MTGFlow, an unsupervised anomaly detection approach for Multivariate Time series anomaly detection via dynamic Graph and entity-aware normalizing Flow, leaning only on a widely accepted hypothesis that abnormal instances exhibit sparse densities than the normal. However, the complex interdependencies among entities and the diverse inherent characteristics of each entity pose significant challenges on the density estimation, let alone to detect anomalies based on the estimated possibility distribution. To tackle these problems, we propose to learn the mutual and dynamic relations among entities via a graph structure learning model, which helps to model accurate distribution of multivariate time series. Moreover, taking account of distinct characteristics of the individual entities, an entity-aware normalizing flow is developed to describe each entity into a parameterized normal distribution, thereby producing fine-grained density estimation. Incorporating these two strategies, MTGFlowachieves superior anomaly detection performance. Experiments on the real-world datasets are conducted, demonstrating that MTGFlow outperforms the state-of-the-art (SOTA) by 5.0% and 1.6% AUROC for SWaT and WADI datasets respectively. Also, through the anomaly scores contributed by individual entities, MTGFlow can provide explanation information for the detection results.
Look, Listen, and Attack: Backdoor Attacks Against Video Action Recognition
Jan 19, 2023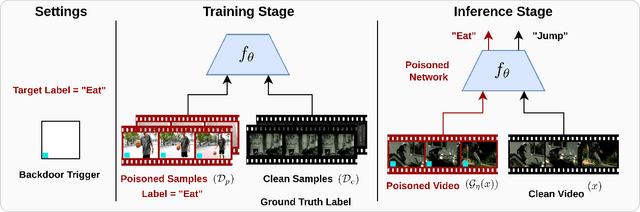
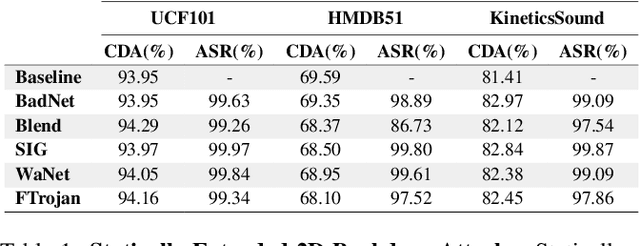

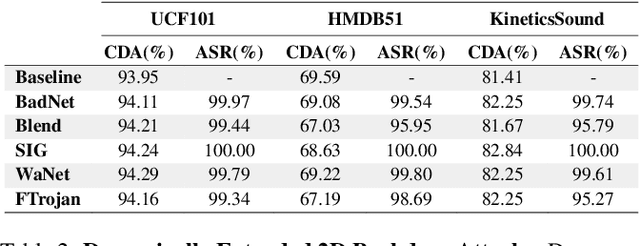
Deep neural networks (DNNs) are vulnerable to a class of attacks called "backdoor attacks", which create an association between a backdoor trigger and a target label the attacker is interested in exploiting. A backdoored DNN performs well on clean test images, yet persistently predicts an attacker-defined label for any sample in the presence of the backdoor trigger. Although backdoor attacks have been extensively studied in the image domain, there are very few works that explore such attacks in the video domain, and they tend to conclude that image backdoor attacks are less effective in the video domain. In this work, we revisit the traditional backdoor threat model and incorporate additional video-related aspects to that model. We show that poisoned-label image backdoor attacks could be extended temporally in two ways, statically and dynamically, leading to highly effective attacks in the video domain. In addition, we explore natural video backdoors to highlight the seriousness of this vulnerability in the video domain. And, for the first time, we study multi-modal (audiovisual) backdoor attacks against video action recognition models, where we show that attacking a single modality is enough for achieving a high attack success rate.
From English to More Languages: Parameter-Efficient Model Reprogramming for Cross-Lingual Speech Recognition
Jan 19, 2023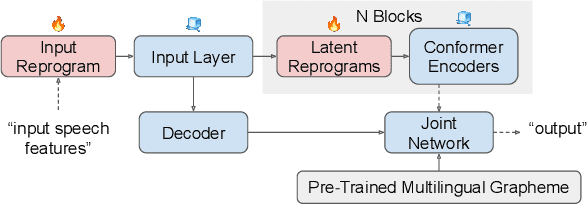

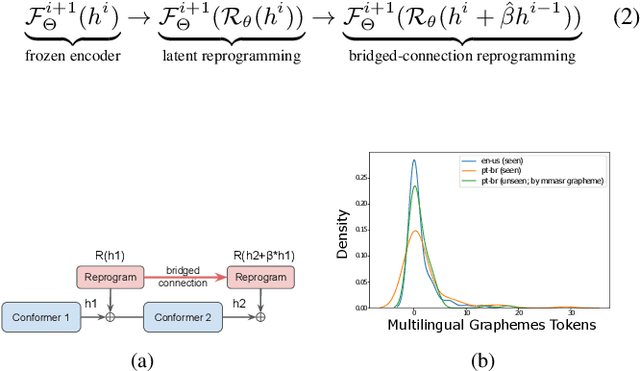
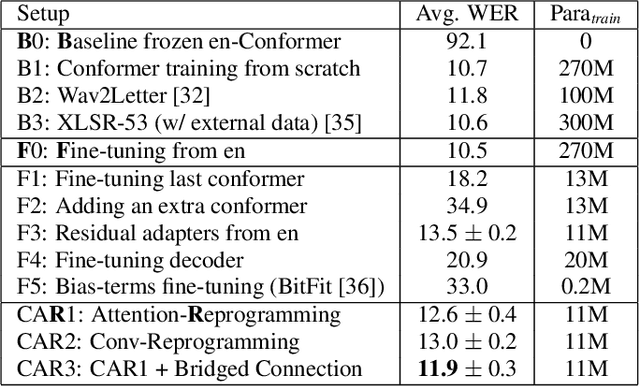
In this work, we propose a new parameter-efficient learning framework based on neural model reprogramming for cross-lingual speech recognition, which can \textbf{re-purpose} well-trained English automatic speech recognition (ASR) models to recognize the other languages. We design different auxiliary neural architectures focusing on learnable pre-trained feature enhancement that, for the first time, empowers model reprogramming on ASR. Specifically, we investigate how to select trainable components (i.e., encoder) of a conformer-based RNN-Transducer, as a frozen pre-trained backbone. Experiments on a seven-language multilingual LibriSpeech speech (MLS) task show that model reprogramming only requires 4.2% (11M out of 270M) to 6.8% (45M out of 660M) of its original trainable parameters from a full ASR model to perform competitive results in a range of 11.9% to 8.1% WER averaged across different languages. In addition, we discover different setups to make large-scale pre-trained ASR succeed in both monolingual and multilingual speech recognition. Our methods outperform existing ASR tuning architectures and their extension with self-supervised losses (e.g., w2v-bert) in terms of lower WER and better training efficiency.
Estimating Remaining Lifespan from the Face
Jan 19, 2023
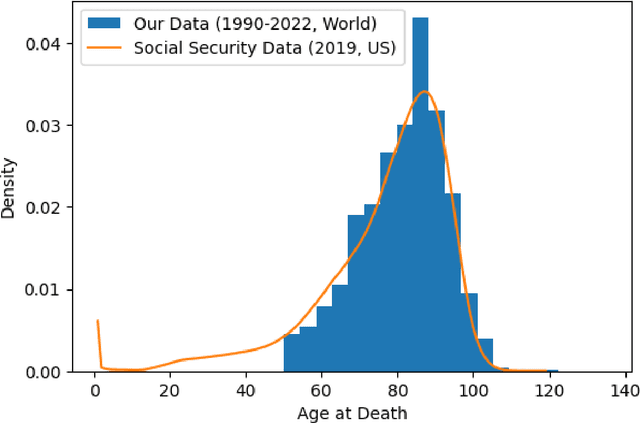

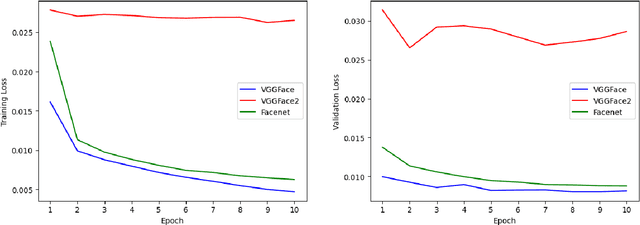
The face is a rich source of information that can be utilized to infer a person's biological age, sex, phenotype, genetic defects, and health status. All of these factors are relevant for predicting an individual's remaining lifespan. In this study, we collected a dataset of over 24,000 images (from Wikidata/Wikipedia) of individuals who died of natural causes, along with the number of years between when the image was taken and when the person passed away. We made this dataset publicly available. We fine-tuned multiple Convolutional Neural Network (CNN) models on this data, at best achieving a mean absolute error of 8.3 years in the validation data using VGGFace. However, the model's performance diminishes when the person was younger at the time of the image. To demonstrate the potential applications of our remaining lifespan model, we present examples of using it to estimate the average loss of life (in years) due to the COVID-19 pandemic and to predict the increase in life expectancy that might result from a health intervention such as weight loss. Additionally, we discuss the ethical considerations associated with such models.
Interval Reachability of Nonlinear Dynamical Systems with Neural Network Controllers
Jan 19, 2023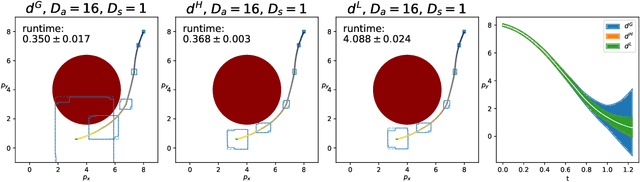
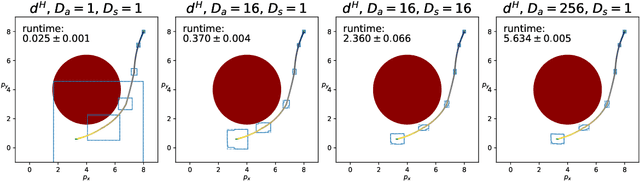
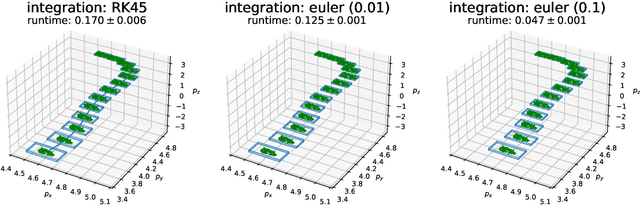
This paper proposes a computationally efficient framework, based on interval analysis, for rigorous verification of nonlinear continuous-time dynamical systems with neural network controllers. Given a neural network, we use an existing verification algorithm to construct inclusion functions for its input-output behavior. Inspired by mixed monotone theory, we embed the closed-loop dynamics into a larger system using an inclusion function of the neural network and a decomposition function of the open-loop system. This embedding provides a scalable approach for safety analysis of the neural control loop while preserving the nonlinear structure of the system. We show that one can efficiently compute hyper-rectangular over-approximations of the reachable sets using a single trajectory of the embedding system. We design an algorithm to leverage this computational advantage through partitioning strategies, improving our reachable set estimates while balancing its runtime with tunable parameters. We demonstrate the performance of this algorithm through two case studies. First, we demonstrate this method's strength in complex nonlinear environments. Then, we show that our approach matches the performance of the state-of-the art verification algorithm for linear discretized systems.
Blind as a bat: audible echolocation on small robots
Jan 19, 2023
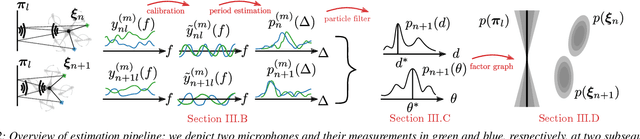
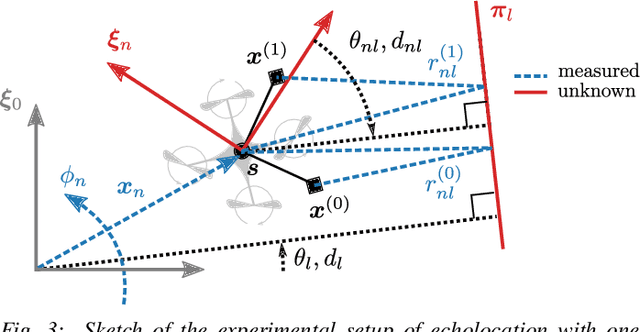
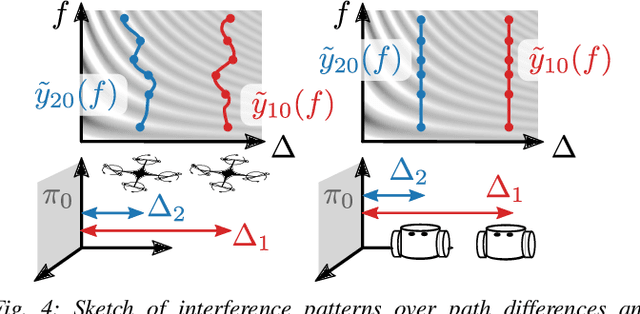
For safe and efficient operation, mobile robots need to perceive their environment, and in particular, perform tasks such as obstacle detection, localization, and mapping. Although robots are often equipped with microphones and speakers, the audio modality is rarely used for these tasks. Compared to the localization of sound sources, for which many practical solutions exist, algorithms for active echolocation are less developed and often rely on hardware requirements that are out of reach for small robots. We propose an end-to-end pipeline for sound-based localization and mapping that is targeted at, but not limited to, robots equipped with only simple buzzers and low-end microphones. The method is model-based, runs in real time, and requires no prior calibration or training. We successfully test the algorithm on the e-puck robot with its integrated audio hardware, and on the Crazyflie drone, for which we design a reproducible audio extension deck. We achieve centimeter-level wall localization on both platforms when the robots are static during the measurement process. Even in the more challenging setting of a flying drone, we can successfully localize walls, which we demonstrate in a proof-of-concept multi-wall localization and mapping demo.