 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bio-inspired Autonomous Exploration Policies with CNN-based Object Detection on Nano-drones
Feb 01, 2023


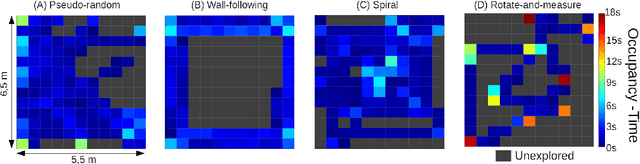

Nano-sized drones, with palm-sized form factor, are gaining relevance in the Internet-of-Things ecosystem. Achieving a high degree of autonomy for complex multi-objective missions (e.g., safe flight, exploration, object detection) is extremely challenging for the onboard chip-set due to tight size, payload (<10g), and power envelope constraints, which strictly limit both memory and computation. Our work addresses this complex problem by combining bio-inspired navigation policies, which rely on time-of-flight distance sensor data, with a vision-based convolutional neural network (CNN) for object detection. Our field-proven nano-drone is equipped with two microcontroller units (MCUs), a single-core ARM Cortex-M4 (STM32) for safe navigation and exploration policies, and a parallel ultra-low power octa-core RISC-V (GAP8) for onboard CNN inference, with a power envelope of just 134mW, including image sensors and external memories. The object detection task achieves a mean average precision of 50% (at 1.6 frame/s) on an in-field collected dataset. We compare four bio-inspired exploration policies and identify a pseudo-random policy to achieve the highest coverage area of 83% in a ~36m^2 unknown room in a 3 minutes flight. By combining the detection CNN and the exploration policy, we show an average detection rate of 90% on six target objects in a never-seen-before environment.
Unsupervised Entity Alignment for Temporal Knowledge Graphs
Feb 01, 2023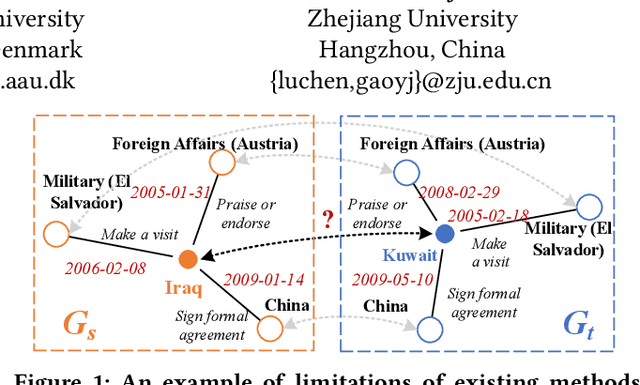
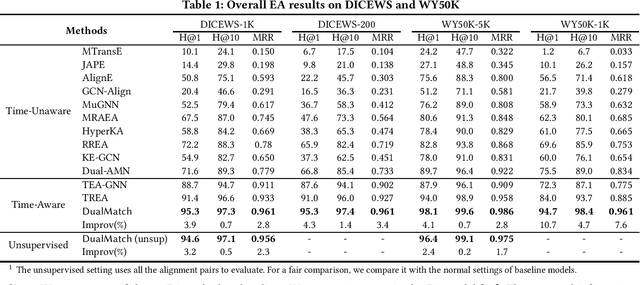
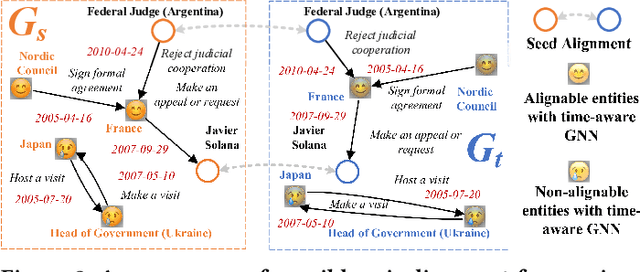
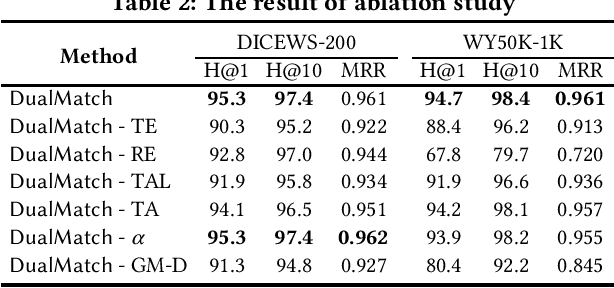
Entity alignment (EA) is a fundamental data integration task that identifies equivalent entities between different knowledge graphs (KGs). Temporal Knowledge graphs (TKGs) extend traditional knowledge graphs by introducing timestamps, which have received increasing attention. State-of-the-art time-aware EA studies have suggested that the temporal information of TKGs facilitates the performance of EA. However, existing studies have not thoroughly exploited the advantages of temporal information in TKGs. Also, they perform EA by pre-aligning entity pairs, which can be labor-intensive and thus inefficient. In this paper, we present DualMatch which effectively fuses the relational and temporal information for EA. DualMatch transfers EA on TKGs into a weighted graph matching problem. More specifically, DualMatch is equipped with an unsupervised method, which achieves EA without necessitating seed alignment. DualMatch has two steps: (i) encoding temporal and relational information into embeddings separately using a novel label-free encoder, Dual-Encoder; and (ii) fusing both information and transforming it into alignment using a novel graph-matching-based decoder, GM-Decoder. DualMatch is able to perform EA on TKGs with or without supervision, due to its capability of effectively capturing temporal information. Extensive experiments on three real-world TKG datasets offer the insight that DualMatch outperforms the state-of-the-art methods in terms of H@1 by 2.4% - 10.7% and MRR by 1.7% - 7.6%, respectively.
Private Federated Submodel Learning via Private Set Union
Jan 18, 2023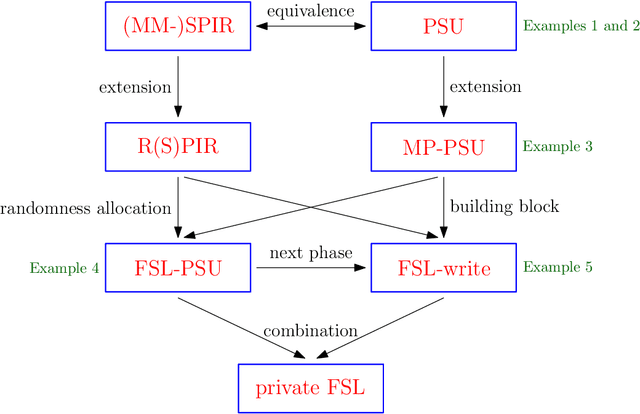
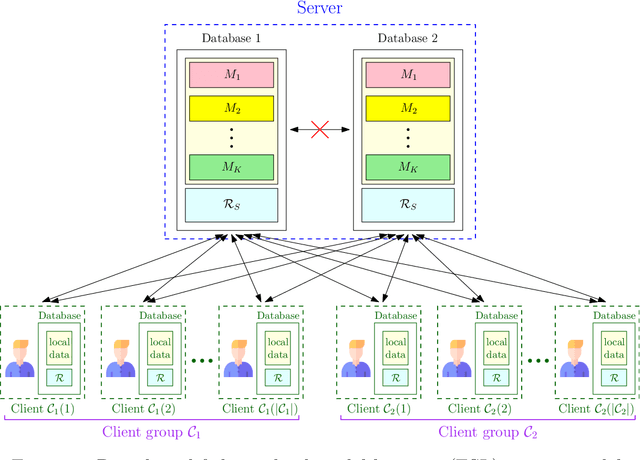
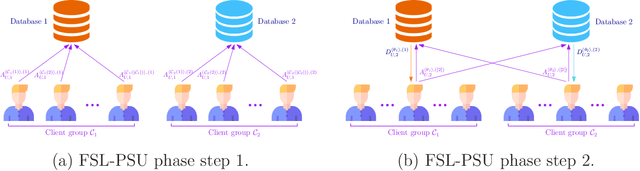
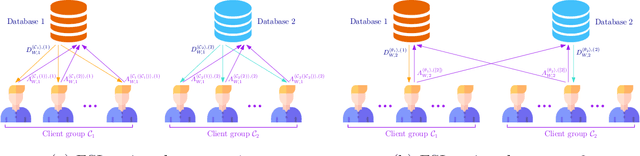
We consider the federated submodel learning (FSL) problem and propose an approach where clients are able to update the central model information theoretically privately. Our approach is based on private set union (PSU), which is further based on multi-message symmetric private information retrieval (MM-SPIR). The server has two non-colluding databases which keep the model in a replicated manner. With our scheme, the server does not get to learn anything further than the subset of submodels updated by the clients: the server does not get to know which client updated which submodel(s), or anything about the local client data. In comparison to the state-of-the-art private FSL schemes of Jia-Jafar and Vithana-Ulukus, our scheme does not require noisy storage of the model at the databases; and in comparison to the secure aggregation scheme of Zhao-Sun, our scheme does not require pre-distribution of client-side common randomness, instead, our scheme creates the required client-side common randomness via random SPIR and one-time pads. The protocol starts with a common randomness generation (CRG) phase where the two databases establish common randomness at the client-side using RSPIR and one-time pads (this phase is called FSL-CRG). Next, the clients utilize the established client-side common randomness to have the server determine privately the union of indices of submodels to be updated collectively by the clients (this phase is called FSL-PSU). Then, the two databases broadcast the current versions of the submodels in the set union to clients. The clients update the submodels based on their local training data. Finally, the clients use a variation of FSL-PSU to write the updates back to the databases privately (this phase is called FSL-write). Our proposed private FSL scheme is robust against client drop-outs, client late-arrivals, and database drop-outs.
Using Detection, Tracking and Prediction in Visual SLAM to Achieve Real-time Semantic Mapping of Dynamic Scenarios
Oct 10, 2022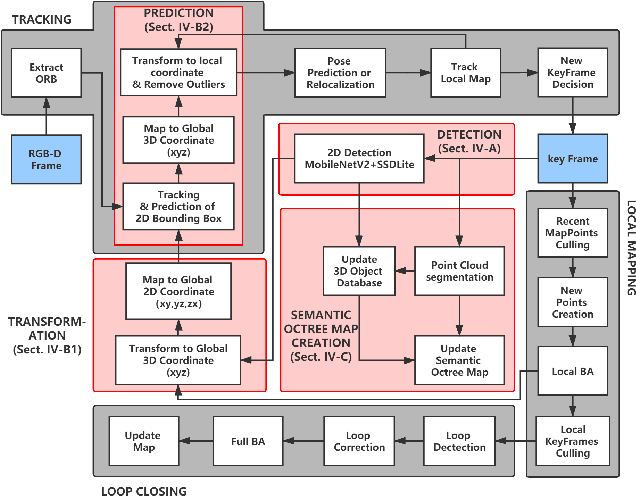
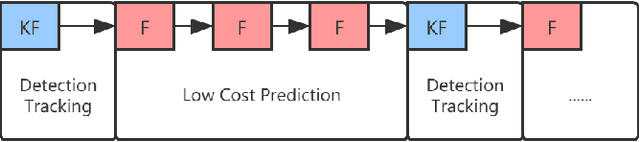
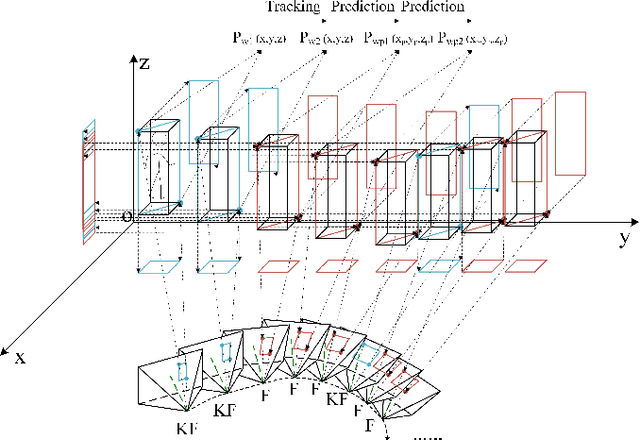

In this paper, we propose a lightweight system, RDS-SLAM, based on ORB-SLAM2, which can accurately estimate poses and build semantic maps at object level for dynamic scenarios in real time using only one commonly used Intel Core i7 CPU. In RDS-SLAM, three major improvements, as well as major architectural modifications, are proposed to overcome the limitations of ORB-SLAM2. Firstly, it adopts a lightweight object detection neural network in key frames. Secondly, an efficient tracking and prediction mechanism is embedded into the system to remove the feature points belonging to movable objects in all incoming frames. Thirdly, a semantic octree map is built by probabilistic fusion of detection and tracking results, which enables a robot to maintain a semantic description at object level for potential interactions in dynamic scenarios. We evaluate RDS-SLAM in TUM RGB-D dataset, and experimental results show that RDS-SLAM can run with 30.3 ms per frame in dynamic scenarios using only an Intel Core i7 CPU, and achieves comparable accuracy compared with the state-of-the-art SLAM systems which heavily rely on both Intel Core i7 CPUs and powerful GPUs.
LitAR: Visually Coherent Lighting for Mobile Augmented Reality
Jan 15, 2023
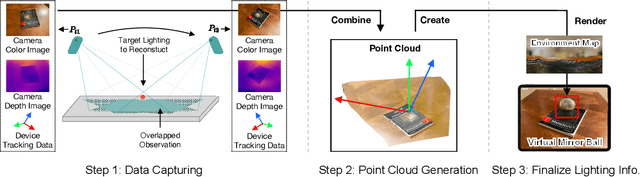

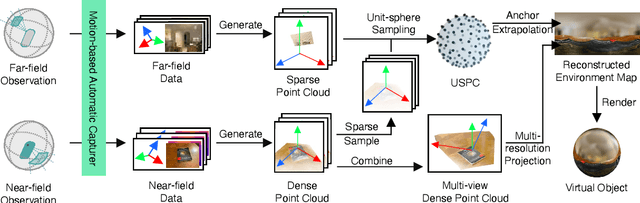
An accurate understanding of omnidirectional environment lighting is crucial for high-quality virtual object rendering in mobile augmented reality (AR). In particular, to support reflective rendering, existing methods have leveraged deep learning models to estimate or have used physical light probes to capture physical lighting, typically represented in the form of an environment map. However, these methods often fail to provide visually coherent details or require additional setups. For example, the commercial framework ARKit uses a convolutional neural network that can generate realistic environment maps; however the corresponding reflective rendering might not match the physical environments. In this work, we present the design and implementation of a lighting reconstruction framework called LitAR that enables realistic and visually-coherent rendering. LitAR addresses several challenges of supporting lighting information for mobile AR. First, to address the spatial variance problem, LitAR uses two-field lighting reconstruction to divide the lighting reconstruction task into the spatial variance-aware near-field reconstruction and the directional-aware far-field reconstruction. The corresponding environment map allows reflective rendering with correct color tones. Second, LitAR uses two noise-tolerant data capturing policies to ensure data quality, namely guided bootstrapped movement and motion-based automatic capturing. Third, to handle the mismatch between the mobile computation capability and the high computation requirement of lighting reconstruction, LitAR employs two novel real-time environment map rendering techniques called multi-resolution projection and anchor extrapolation. These two techniques effectively remove the need of time-consuming mesh reconstruction while maintaining visual quality.
Tracking Passengers and Baggage Items using Multiple Overhead Cameras at Security Checkpoints
Dec 31, 2022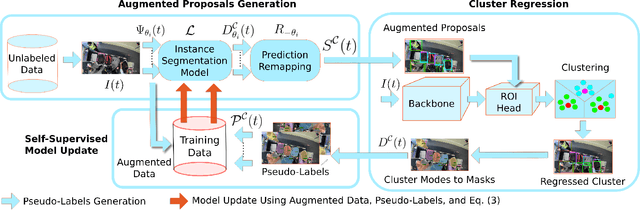


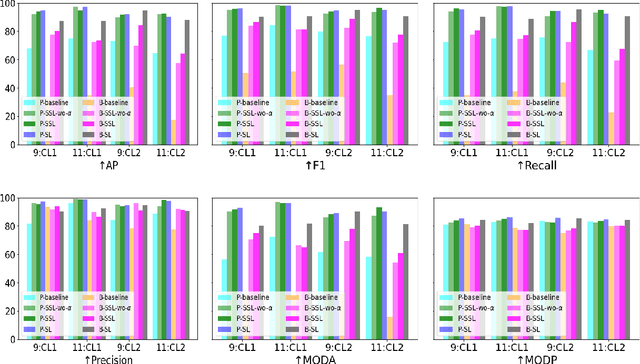
We introduce a novel framework to track multiple objects in overhead camera videos for airport checkpoint security scenarios where targets correspond to passengers and their baggage items. We propose a Self-Supervised Learning (SSL) technique to provide the model information about instance segmentation uncertainty from overhead images. Our SSL approach improves object detection by employing a test-time data augmentation and a regression-based, rotation-invariant pseudo-label refinement technique. Our pseudo-label generation method provides multiple geometrically-transformed images as inputs to a Convolutional Neural Network (CNN), regresses the augmented detections generated by the network to reduce localization errors, and then clusters them using the mean-shift algorithm. The self-supervised detector model is used in a single-camera tracking algorithm to generate temporal identifiers for the targets. Our method also incorporates a multi-view trajectory association mechanism to maintain consistent temporal identifiers as passengers travel across camera views. An evaluation of detection, tracking, and association performances on videos obtained from multiple overhead cameras in a realistic airport checkpoint environment demonstrates the effectiveness of the proposed approach. Our results show that self-supervision improves object detection accuracy by up to $42\%$ without increasing the inference time of the model. Our multi-camera association method achieves up to $89\%$ multi-object tracking accuracy with an average computation time of less than $15$ ms.
* 12 pages, 12 figures. arXiv admin note: text overlap with arXiv:2007.07924
TD-BPQBC: A 1.8μW 5.5mm3 ADC-less Neural Implant SoC utilizing 13.2pJ/Sample Time-domain Bi-phasic Quasi-static Brain Communication
Sep 24, 2022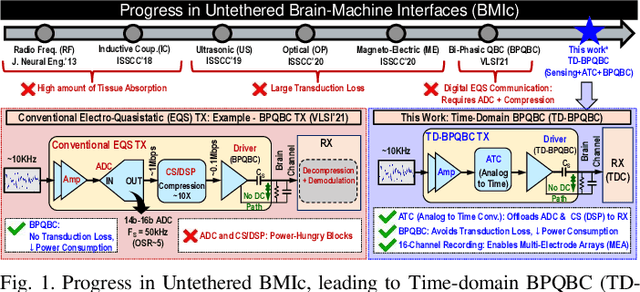
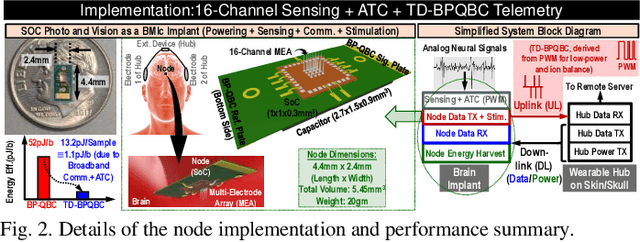
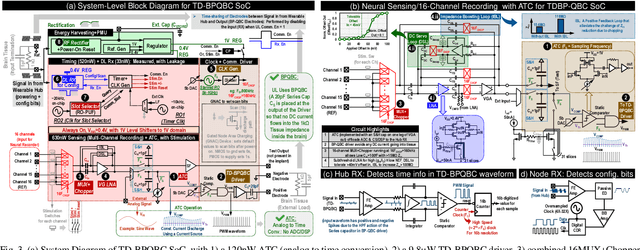

Untethered miniaturized wireless neural sensor nodes with data transmission and energy harvesting capabilities call for circuit and system-level innovations to enable ultra-low energy deep implants for brain-machine interfaces. Realizing that the energy and size constraints of a neural implant motivate highly asymmetric system design (a small, low-power sensor and transmitter at the implant, with a relatively higher power receiver at a body-worn hub), we present Time-Domain Bi-Phasic Quasi-static Brain Communication (TD- BPQBC), offloading the burden of analog to digital conversion (ADC) and digital signal processing (DSP) to the receiver. The input analog signal is converted to time-domain pulse-width modulated (PWM) waveforms, and transmitted using the recently developed BPQBC method for reducing communication power in implants. The overall SoC consumes only 1.8{\mu}W power while sensing and communicating at 800kSps. The transmitter energy efficiency is only 1.1pJ/b, which is >30X better than the state-of-the-art, enabling a fully-electrical, energy-harvested, and connected in-brain sensor/stimulator node.
Huber-Robust Confidence Sequences
Jan 23, 2023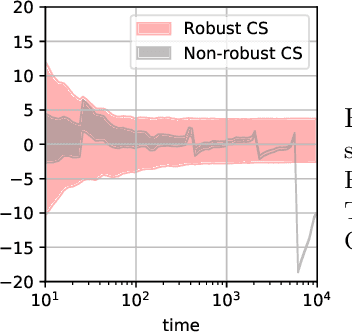
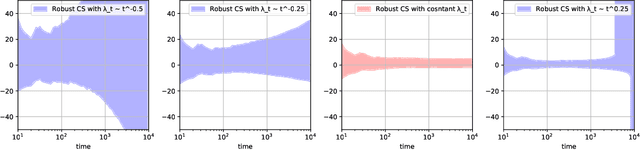
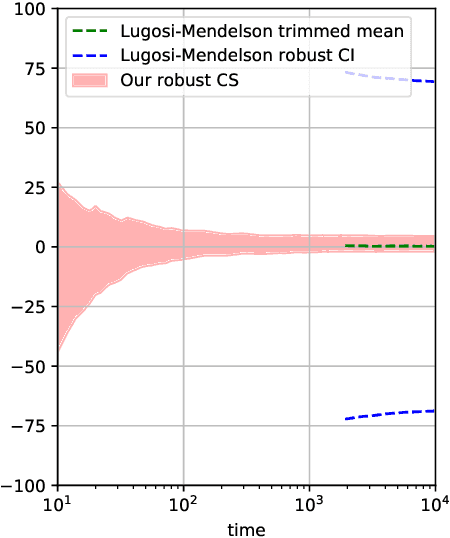
Confidence sequences are confidence intervals that can be sequentially tracked, and are valid at arbitrary data-dependent stopping times. This paper presents confidence sequences for a univariate mean of an unknown distribution with a known upper bound on the p-th central moment (p > 1), but allowing for (at most) {\epsilon} fraction of arbitrary distribution corruption, as in Huber's contamination model. We do this by designing new robust exponential supermartingales, and show that the resulting confidence sequences attain the optimal width achieved in the nonsequential setting. Perhaps surprisingly, the constant margin between our sequential result and the lower bound is smaller than even fixed-time robust confidence intervals based on the trimmed mean, for example. Since confidence sequences are a common tool used within A/B/n testing and bandits, these results open the door to sequential experimentation that is robust to outliers and adversarial corruptions.
Long-tail Detection with Effective Class-Margins
Jan 23, 2023Large-scale object detection and instance segmentation face a severe data imbalance. The finer-grained object classes become, the less frequent they appear in our datasets. However, at test-time, we expect a detector that performs well for all classes and not just the most frequent ones. In this paper, we provide a theoretical understanding of the long-trail detection problem. We show how the commonly used mean average precision evaluation metric on an unknown test set is bound by a margin-based binary classification error on a long-tailed object detection training set. We optimize margin-based binary classification error with a novel surrogate objective called \textbf{Effective Class-Margin Loss} (ECM). The ECM loss is simple, theoretically well-motivated, and outperforms other heuristic counterparts on LVIS v1 benchmark over a wide range of architecture and detectors. Code is available at \url{https://github.com/janghyuncho/ECM-Loss}.
Adaptive Computation with Elastic Input Sequence
Jan 30, 2023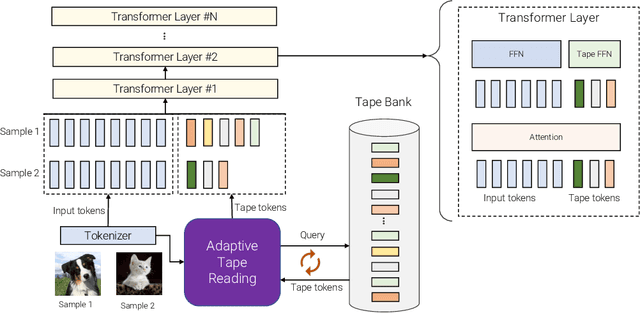
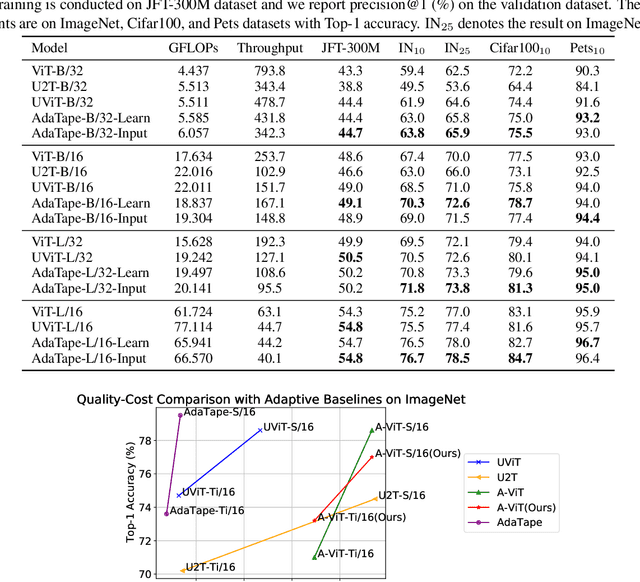
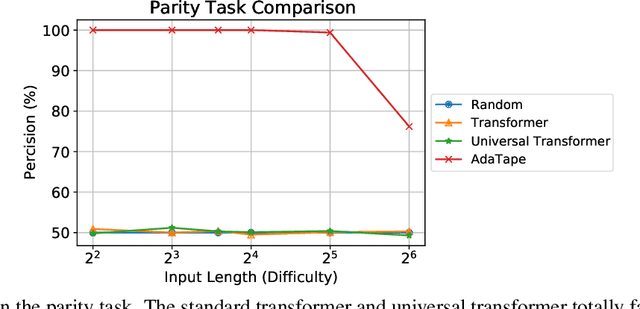
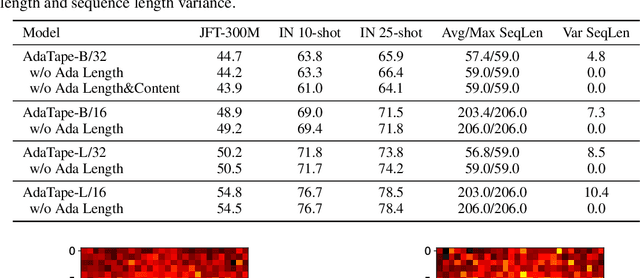
When solving a problem, human beings have the adaptive ability in terms of the type of information they use, the procedure they take, and the amount of time they spend approaching and solving the problem. However, most standard neural networks have the same function type and fixed computation budget on different samples regardless of their nature and difficulty. Adaptivity is a powerful paradigm as it not only imbues practitioners with flexibility pertaining to the downstream usage of these models but can also serve as a powerful inductive bias for solving certain challenging classes of problems. In this work, we propose a new strategy, AdaTape, that enables dynamic computation in neural networks via adaptive tape tokens. AdaTape employs an elastic input sequence by equipping an existing architecture with a dynamic read-and-write tape. Specifically, we adaptively generate input sequences using tape tokens obtained from a tape bank that can either be trainable or generated from input data. We analyze the challenges and requirements to obtain dynamic sequence content and length, and propose the Adaptive Tape Reader (ATR) algorithm to achieve both objectives. Via extensive experiments on image recognition tasks, we show that AdaTape can achieve better performance while maintaining the computational cost.