 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CAS: A General Algorithm for Online Selective Conformal Prediction with FCR Control
Mar 12, 2024
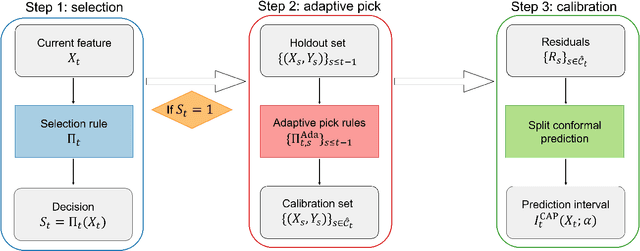
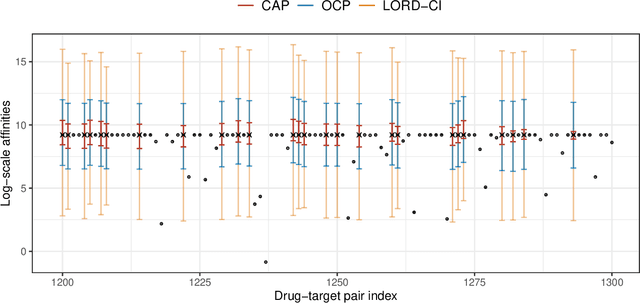
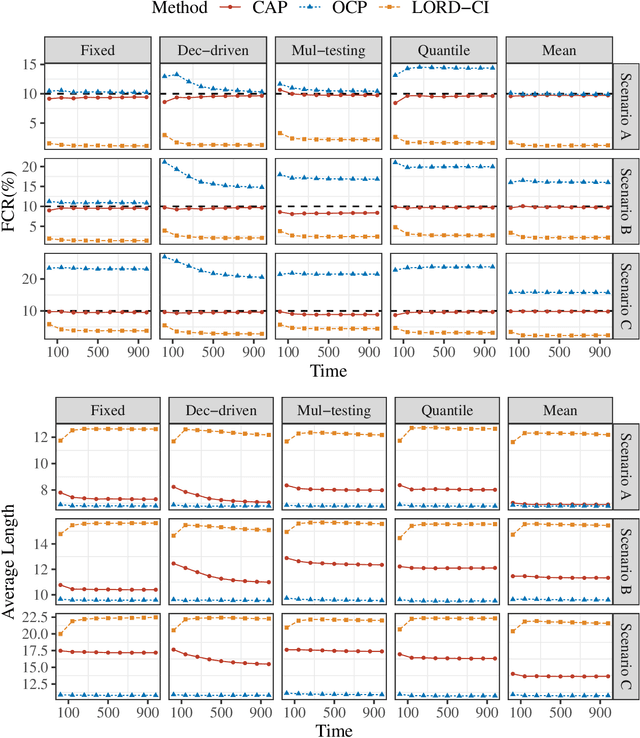
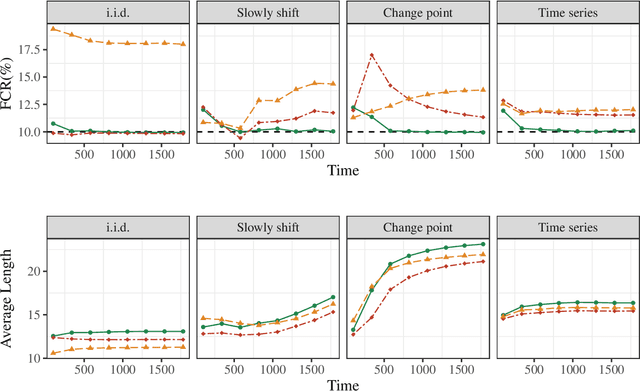
We study the problem of post-selection predictive inference in an online fashion. To avoid devoting resources to unimportant units, a preliminary selection of the current individual before reporting its prediction interval is common and meaningful in online predictive tasks. Since the online selection causes a temporal multiplicity in the selected prediction intervals, it is important to control the real-time false coverage-statement rate (FCR) to measure the averaged miscoverage error. We develop a general framework named CAS (Calibration after Adaptive Selection) that can wrap around any prediction model and online selection rule to output post-selection prediction intervals. If the current individual is selected, we first perform an adaptive selection on historical data to construct a calibration set, then output a conformal prediction interval for the unobserved label. We provide tractable constructions for the calibration set for popular online selection rules. We proved that CAS can achieve an exact selection-conditional coverage guarantee in the finite-sample and distribution-free regimes. For the decision-driven selection rule, including most online multiple-testing procedures, CAS can exactly control the real-time FCR below the target level without any distributional assumptions. For the online selection with symmetric thresholds, we establish the error bound for the control gap of FCR under mild distributional assumptions. To account for the distribution shift in online data, we also embed CAS into some recent dynamic conformal prediction methods and examine the long-run FCR control. Numerical results on both synthetic and real data corroborate that CAS can effectively control FCR around the target level and yield more narrowed prediction intervals over existing baselines across various settings.
Radar Rainbow Beams For Wideband mmWave Communication: Beam Training And Tracking
Mar 14, 2024We propose a novel integrated sensing and communication (ISAC) system that leverages sensing to assist communication, ensuring fast initial access, seamless user tracking, and uninterrupted communication for millimeter wave (mmWave) wideband systems. True-time-delayers (TTDs) are utilized to generate frequency-dependent radar rainbow beams by controlling the beam squint effect. These beams cover users across the entire angular space simultaneously for fast beam training using just one orthogonal frequency-division multiplexing (OFDM) symbol. Three detection and estimation schemes are proposed based on radar rainbow beams for estimation of the users' angles, distances, and velocities, which are then exploited for communication beamformer design. The first proposed scheme utilizes a single-antenna radar receiver and one set of rainbow beams, but may cause a Doppler ambiguity. To tackle this limitation, two additional schemes are introduced, utilizing two sets of rainbow beams and a multi-antenna receiver, respectively. Furthermore, the proposed detection and estimation schemes are extended to realize user tracking by choosing different subsets of OFDM subcarriers. This approach eliminates the need to switch phase shifters and TTDs, which are typically necessary in existing tracking technologies, thereby reducing the demands on the control circurity. Simulation results reveal the effectiveness of the proposed rainbow beam-based training and tracking methods for mobile users. Notably, the scheme employing a multi-antenna radar receiver can accurately estimate the channel parameters and can support communication rates comparable to those achieved with perfect channel information.
Learning Algorithms for Verification of Markov Decision Processes
Mar 14, 2024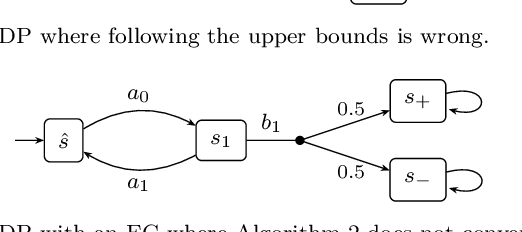
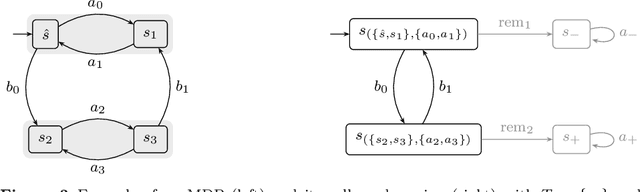

We present a general framework for applying learning algorithms and heuristical guidance to the verification of Markov decision processes (MDPs), based on the ideas of Br\'azdil, T. et al. (2014). Verification of Markov Decision Processes Using Learning Algorithms. The primary goal of the techniques presented in that work is to improve performance by avoiding an exhaustive exploration of the state space, guided by heuristics. This approach is significantly extended in this work. Several details of the base theory are refined and errors are fixed. Section 1.3 provides an overview of all differences. The presented framework focuses on probabilistic reachability, which is a core problem in verification, and is instantiated in two distinct scenarios. The first assumes that full knowledge of the MDP is available, in particular precise transition probabilities. It performs a heuristic-driven partial exploration of the model, yielding precise lower and upper bounds on the required probability. The second tackles the case where we may only sample the MDP without knowing the exact transition dynamics. Here, we obtain probabilistic guarantees, again in terms of both the lower and upper bounds, which provides efficient stopping criteria for the approximation. In particular, the latter is an extension of statistical model-checking (SMC) for unbounded properties in MDPs. In contrast to other related approaches, we do not restrict our attention to time-bounded (finite-horizon) or discounted properties, nor assume any particular structural properties of the MDP.
Keyformer: KV Cache Reduction through Key Tokens Selection for Efficient Generative Inference
Mar 14, 2024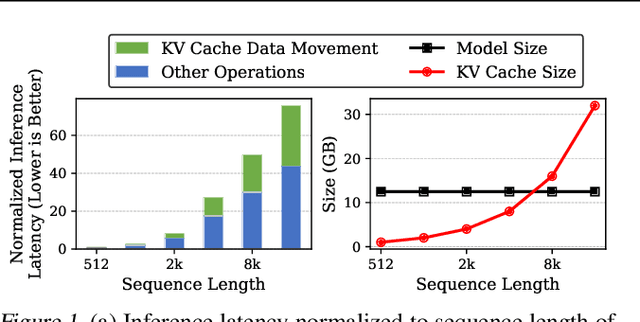

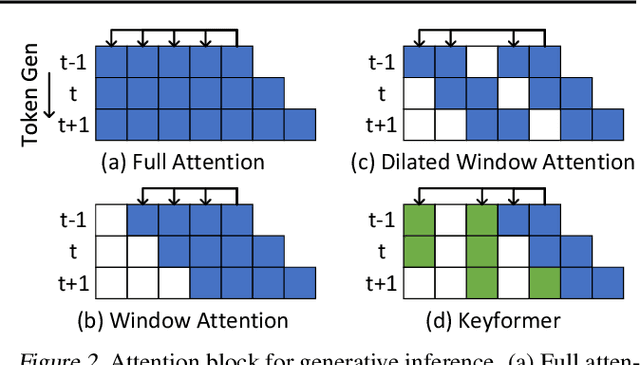
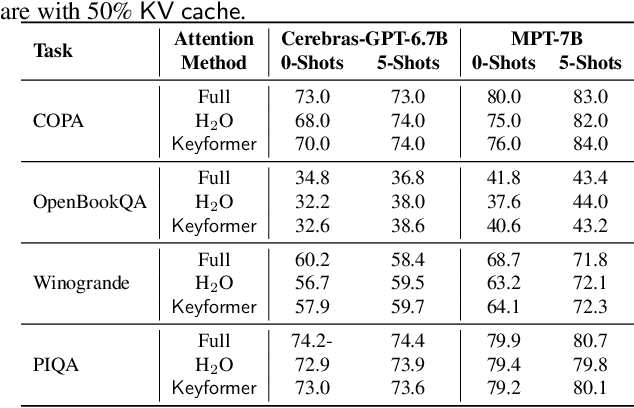
Transformers have emerged as the underpinning architecture for Large Language Models (LLMs). In generative language models, the inference process involves two primary phases: prompt processing and token generation. Token generation, which constitutes the majority of the computational workload, primarily entails vector-matrix multiplications and interactions with the Key-Value (KV) Cache. This phase is constrained by memory bandwidth due to the overhead of transferring weights and KV cache values from the memory system to the computing units. This memory bottleneck becomes particularly pronounced in applications that require long-context and extensive text generation, both of which are increasingly crucial for LLMs. This paper introduces "Keyformer", an innovative inference-time approach, to mitigate the challenges associated with KV cache size and memory bandwidth utilization. Keyformer leverages the observation that approximately 90% of the attention weight in generative inference focuses on a specific subset of tokens, referred to as "key" tokens. Keyformer retains only the key tokens in the KV cache by identifying these crucial tokens using a novel score function. This approach effectively reduces both the KV cache size and memory bandwidth usage without compromising model accuracy. We evaluate Keyformer's performance across three foundational models: GPT-J, Cerebras-GPT, and MPT, which employ various positional embedding algorithms. Our assessment encompasses a variety of tasks, with a particular emphasis on summarization and conversation tasks involving extended contexts. Keyformer's reduction of KV cache reduces inference latency by 2.1x and improves token generation throughput by 2.4x, while preserving the model's accuracy.
* A collaborative effort by d-matrix and the University of British Columbia
DiTMoS: Delving into Diverse Tiny-Model Selection on Microcontrollers
Mar 14, 2024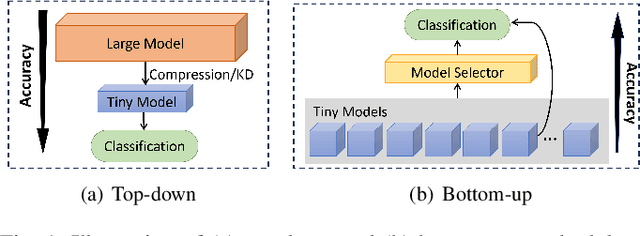
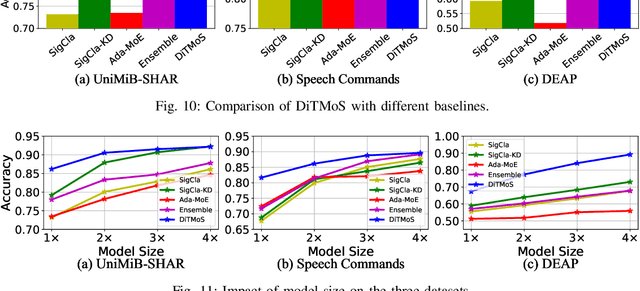
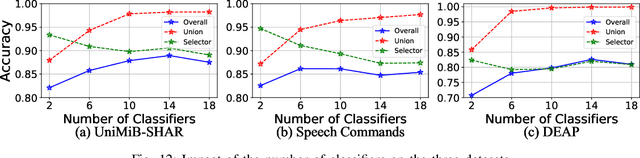
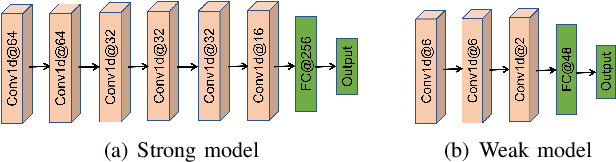
Enabling efficient and accurate deep neural network (DNN) inference on microcontrollers is non-trivial due to the constrained on-chip resources. Current methodologies primarily focus on compressing larger models yet at the expense of model accuracy. In this paper, we rethink the problem from the inverse perspective by constructing small/weak models directly and improving their accuracy. Thus, we introduce DiTMoS, a novel DNN training and inference framework with a selector-classifiers architecture, where the selector routes each input sample to the appropriate classifier for classification. DiTMoS is grounded on a key insight: a composition of weak models can exhibit high diversity and the union of them can significantly boost the accuracy upper bound. To approach the upper bound, DiTMoS introduces three strategies including diverse training data splitting to increase the classifiers' diversity, adversarial selector-classifiers training to ensure synergistic interactions thereby maximizing their complementarity, and heterogeneous feature aggregation to improve the capacity of classifiers. We further propose a network slicing technique to alleviate the extra memory overhead incurred by feature aggregation. We deploy DiTMoS on the Neucleo STM32F767ZI board and evaluate it based on three time-series datasets for human activity recognition, keywords spotting, and emotion recognition, respectively. The experiment results manifest that: (a) DiTMoS achieves up to 13.4% accuracy improvement compared to the best baseline; (b) network slicing almost completely eliminates the memory overhead incurred by feature aggregation with a marginal increase of latency.
The Virtues of Laziness: Multi-Query Kinodynamic Motion Planning with Lazy Methods
Mar 12, 2024
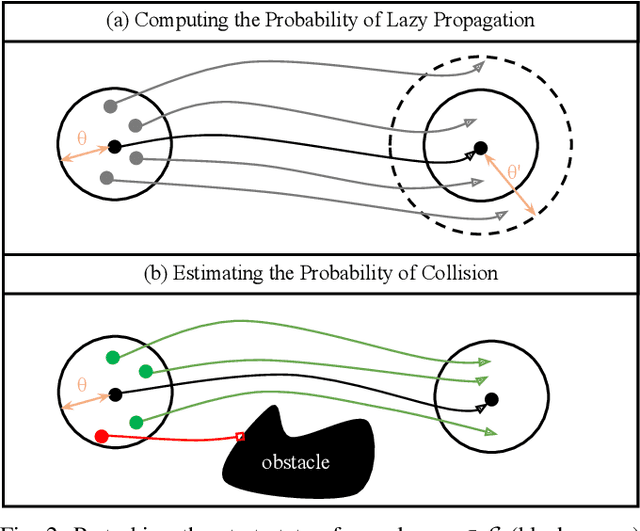
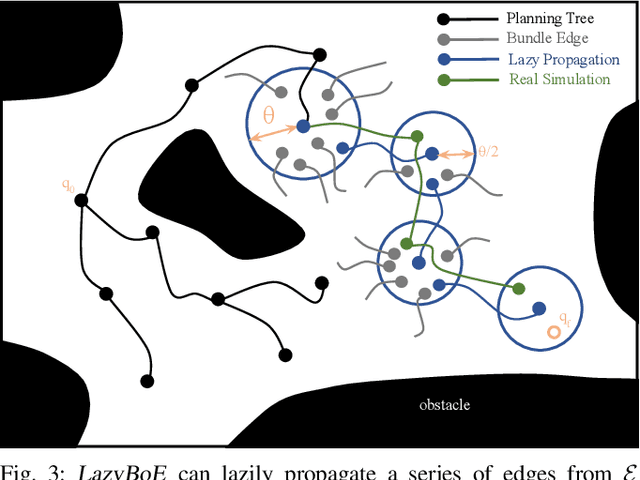
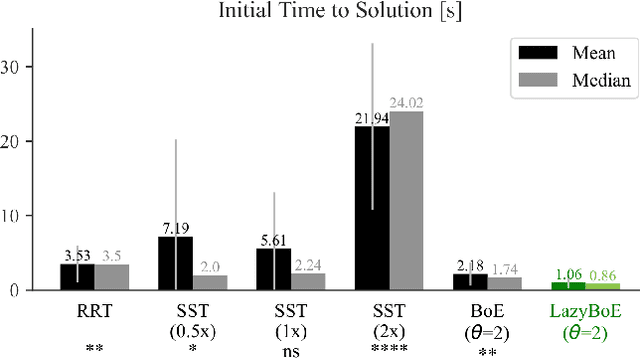
In this work, we introduce LazyBoE, a multi-query method for kinodynamic motion planning with forward propagation. This algorithm allows for the simultaneous exploration of a robot's state and control spaces, thereby enabling a wider suite of dynamic tasks in real-world applications. Our contributions are three-fold: i) a method for discretizing the state and control spaces to amortize planning times across multiple queries; ii) lazy approaches to collision checking and propagation of control sequences that decrease the cost of physics-based simulation; and iii) LazyBoE, a robust kinodynamic planner that leverages these two contributions to produce dynamically-feasible trajectories. The proposed framework not only reduces planning time but also increases success rate in comparison to previous approaches.
Adaptive Gain Scheduling using Reinforcement Learning for Quadcopter Control
Mar 12, 2024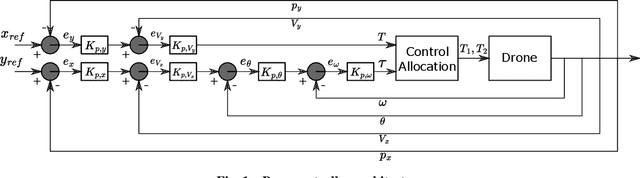
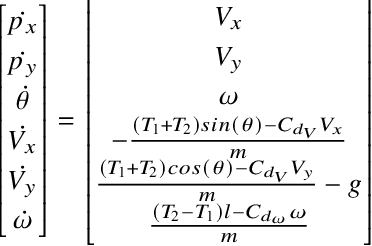

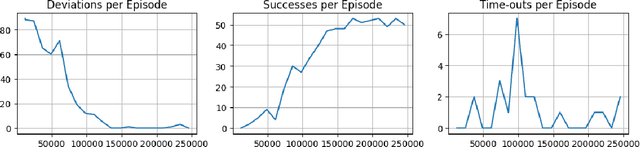
The paper presents a technique using reinforcement learning (RL) to adapt the control gains of a quadcopter controller. Specifically, we employed Proximal Policy Optimization (PPO) to train a policy which adapts the gains of a cascaded feedback controller in-flight. The primary goal of this controller is to minimize tracking error while following a specified trajectory. The paper's key objective is to analyze the effectiveness of the adaptive gain policy and compare it to the performance of a static gain control algorithm, where the Integral Squared Error and Integral Time Squared Error are used as metrics. The results show that the adaptive gain scheme achieves over 40$\%$ decrease in tracking error as compared to the static gain controller.
AI-Assisted Causal Pathway Diagram for Human-Centered Design
Mar 12, 2024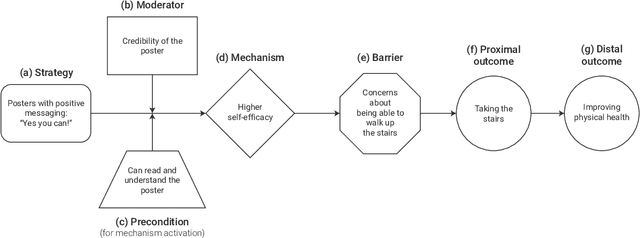
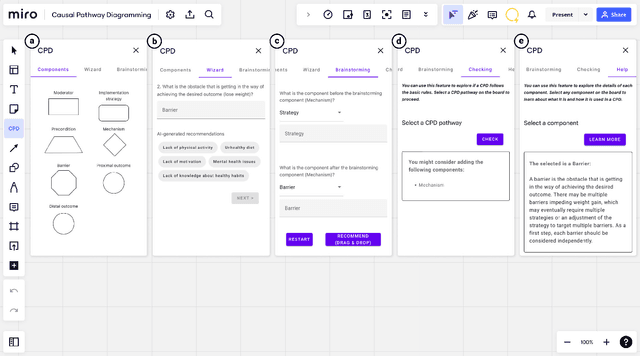

This paper explores the integration of causal pathway diagrams (CPD) into human-centered design (HCD), investigating how these diagrams can enhance the early stages of the design process. A dedicated CPD plugin for the online collaborative whiteboard platform Miro was developed to streamline diagram creation and offer real-time AI-driven guidance. Through a user study with designers (N=20), we found that CPD's branching and its emphasis on causal connections supported both divergent and convergent processes during design. CPD can also facilitate communication among stakeholders. Additionally, we found our plugin significantly reduces designers' cognitive workload and increases their creativity during brainstorming, highlighting the implications of AI-assisted tools in supporting creative work and evidence-based designs.
Contact-Implicit Model Predictive Control for Dexterous In-hand Manipulation: A Long-Horizon and Robust Approach
Mar 11, 2024Dexterous in-hand manipulation is an essential skill of production and life. Nevertheless, the highly stiff and mutable features of contacts cause limitations to real-time contact discovery and inference, which degrades the performance of model-based methods. Inspired by recent advancements in contact-rich locomotion and manipulation, this paper proposes a novel model-based approach to control dexterous in-hand manipulation and overcome the current limitations. The proposed approach has the attractive feature, which allows the robot to robustly execute long-horizon in-hand manipulation without pre-defined contact sequences or separated planning procedures. Specifically, we design a contact-implicit model predictive controller at high-level to generate real-time contact plans, which are executed by the low-level tracking controller. Compared with other model-based methods, such a long-horizon feature enables replanning and robust execution of contact-rich motions to achieve large-displacement in-hand tasks more efficiently; Compared with existing learning-based methods, the proposed approach achieves the dexterity and also generalizes to different objects without any pre-training. Detailed simulations and ablation studies demonstrate the efficiency and effectiveness of our method. It runs at 20Hz on the 23-degree-of-freedom long-horizon in-hand object rotation task.
Temporal-Mapping Photography for Event Cameras
Mar 11, 2024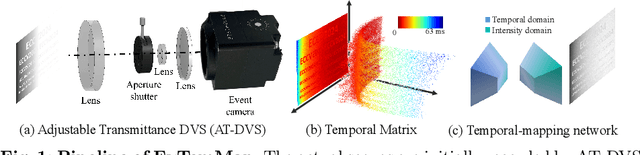

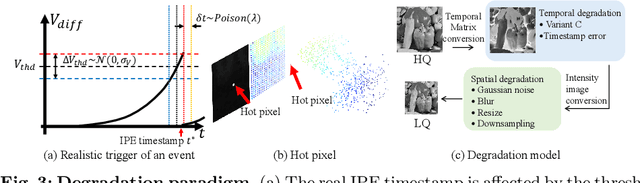
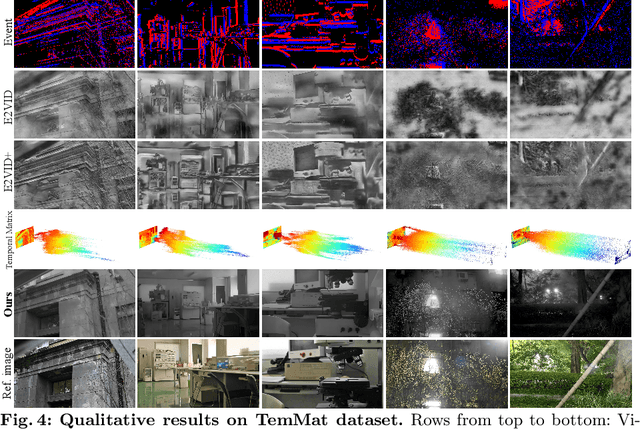
Event cameras, or Dynamic Vision Sensors (DVS) are novel neuromorphic sensors that capture brightness changes as a continuous stream of ``events'' rather than traditional intensity frames. Converting sparse events to dense intensity frames faithfully has long been an ill-posed problem. Previous methods have primarily focused on converting events to video in dynamic scenes or with a moving camera. In this paper, for the first time, we realize events to dense intensity image conversion using a stationary event camera in static scenes. Different from traditional methods that mainly rely on event integration, the proposed Event-Based Temporal Mapping Photography (EvTemMap) measures the time of event emitting for each pixel. Then, the resulting Temporal Matrix is converted to an intensity frame with a temporal mapping neural network. At the hardware level, the proposed EvTemMap is implemented by combining a transmittance adjustment device with a DVS, named Adjustable Transmittance Dynamic Vision Sensor. Additionally, we collected TemMat dataset under various conditions including low-light and high dynamic range scenes. The experimental results showcase the high dynamic range, fine-grained details, and high-grayscale-resolution of the proposed EvTemMap, as well as the enhanced performance on downstream computer vision tasks compared to other methods. The code and TemMat dataset will be made publicly available.