 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Recovering Surveillance Video Using RF Cues
Dec 27, 2022
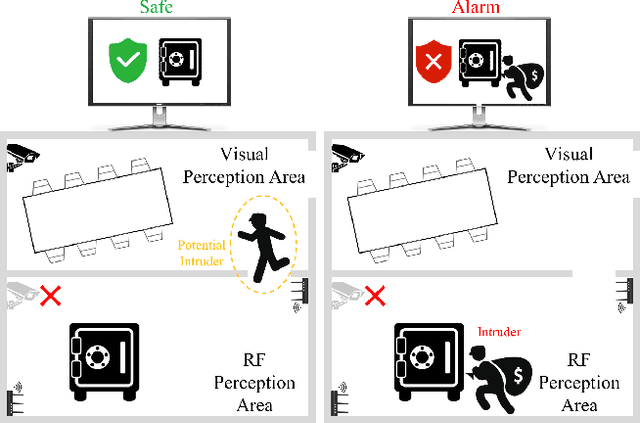
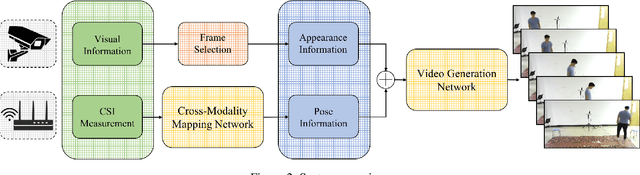
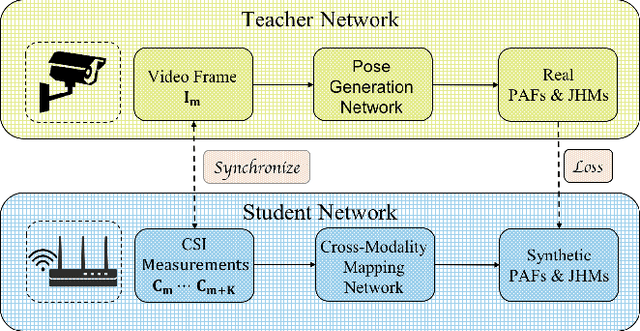

Video capture is the most extensively utilized human perception source due to its intuitively understandable nature. A desired video capture often requires multiple environmental conditions such as ample ambient-light, unobstructed space, and proper camera angle. In contrast, wireless measurements are more ubiquitous and have fewer environmental constraints. In this paper, we propose CSI2Video, a novel cross-modal method that leverages only WiFi signals from commercial devices and a source of human identity information to recover fine-grained surveillance video in a real-time manner. Specifically, two tailored deep neural networks are designed to conduct cross-modal mapping and video generation tasks respectively. We make use of an auto-encoder-based structure to extract pose features from WiFi frames. Afterward, both extracted pose features and identity information are merged to generate synthetic surveillance video. Our solution generates realistic surveillance videos without any expensive wireless equipment and has ubiquitous, cheap, and real-time characteristics.
Two-stream Multi-dimensional Convolutional Network for Real-time Violence Detection
Nov 08, 2022
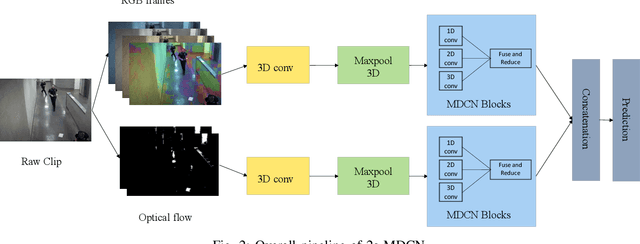
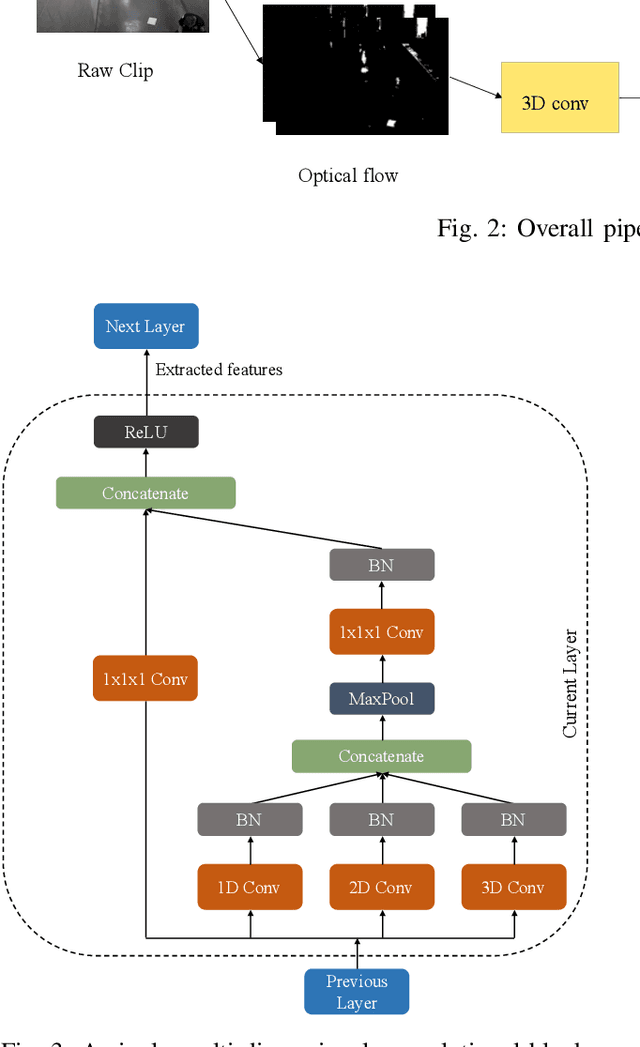
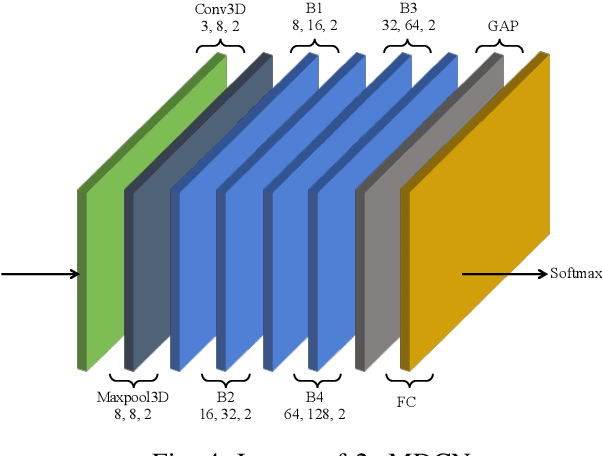
The increasing number of surveillance cameras and security concerns have made automatic violent activity detection from surveillance footage an active area for research. Modern deep learning methods have achieved good accuracy in violence detection and proved to be successful because of their applicability in intelligent surveillance systems. However, the models are computationally expensive and large in size because of their inefficient methods for feature extraction. This work presents a novel architecture for violence detection called Two-stream Multi-dimensional Convolutional Network (2s-MDCN), which uses RGB frames and optical flow to detect violence. Our proposed method extracts temporal and spatial information independently by 1D, 2D, and 3D convolutions. Despite combining multi-dimensional convolutional networks, our models are lightweight and efficient due to reduced channel capacity, yet they learn to extract meaningful spatial and temporal information. Additionally, combining RGB frames and optical flow yields 2.2% more accuracy than a single RGB stream. Regardless of having less complexity, our models obtained state-of-the-art accuracy of 89.7% on the largest violence detection benchmark dataset.
Dynamics-informed deconvolutional neural networks for super-resolution identification of regime changes in epidemiological time series
Sep 16, 2022Inferring the timing and amplitude of perturbations in epidemiological systems from their stochastically spread low-resolution outcomes is as relevant as challenging. It is a requirement for current approaches to overcome the need to know the details of the perturbations to proceed with the analyses. However, the general problem of connecting epidemiological curves with the underlying incidence lacks the highly effective methodology present in other inverse problems, such as super-resolution and dehazing from computer vision. Here, we develop an unsupervised physics-informed convolutional neural network approach in reverse to connect death records with incidence that allows the identification of regime changes at single-day resolution. Applied to COVID-19 data with proper regularization and model-selection criteria, the approach can identify the implementation and removal of lockdowns and other nonpharmaceutical interventions with 0.93-day accuracy over the time span of a year.
FastML Science Benchmarks: Accelerating Real-Time Scientific Edge Machine Learning
Jul 16, 2022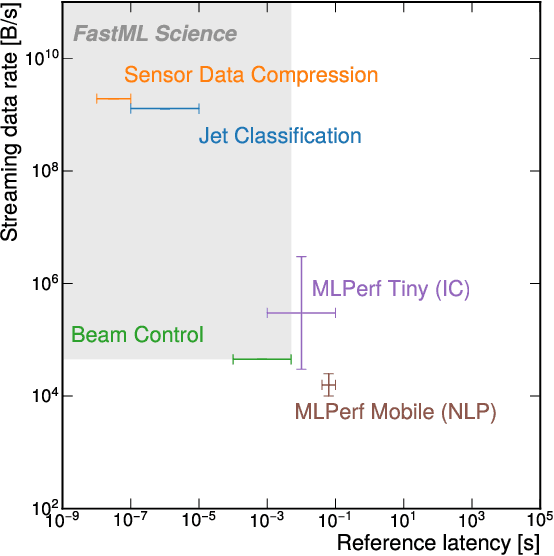

Applications of machine learning (ML) are growing by the day for many unique and challenging scientific applications. However, a crucial challenge facing these applications is their need for ultra low-latency and on-detector ML capabilities. Given the slowdown in Moore's law and Dennard scaling, coupled with the rapid advances in scientific instrumentation that is resulting in growing data rates, there is a need for ultra-fast ML at the extreme edge. Fast ML at the edge is essential for reducing and filtering scientific data in real-time to accelerate science experimentation and enable more profound insights. To accelerate real-time scientific edge ML hardware and software solutions, we need well-constrained benchmark tasks with enough specifications to be generically applicable and accessible. These benchmarks can guide the design of future edge ML hardware for scientific applications capable of meeting the nanosecond and microsecond level latency requirements. To this end, we present an initial set of scientific ML benchmarks, covering a variety of ML and embedded system techniques.
On the Challenges of using Reinforcement Learning in Precision Drug Dosing: Delay and Prolongedness of Action Effects
Jan 02, 2023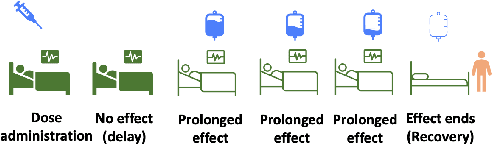

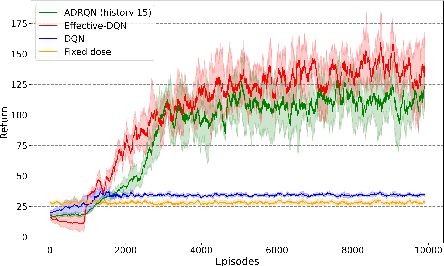
Drug dosing is an important application of AI, which can be formulated as a Reinforcement Learning (RL) problem. In this paper, we identify two major challenges of using RL for drug dosing: delayed and prolonged effects of administering medications, which break the Markov assumption of the RL framework. We focus on prolongedness and define PAE-POMDP (Prolonged Action Effect-Partially Observable Markov Decision Process), a subclass of POMDPs in which the Markov assumption does not hold specifically due to prolonged effects of actions. Motivated by the pharmacology literature, we propose a simple and effective approach to converting drug dosing PAE-POMDPs into MDPs, enabling the use of the existing RL algorithms to solve such problems. We validate the proposed approach on a toy task, and a challenging glucose control task, for which we devise a clinically-inspired reward function. Our results demonstrate that: (1) the proposed method to restore the Markov assumption leads to significant improvements over a vanilla baseline; (2) the approach is competitive with recurrent policies which may inherently capture the prolonged effect of actions; (3) it is remarkably more time and memory efficient than the recurrent baseline and hence more suitable for real-time dosing control systems; and (4) it exhibits favorable qualitative behavior in our policy analysis.
FPGA Implementation of Multi-Layer Machine Learning Equalizer with On-Chip Training
Dec 07, 2022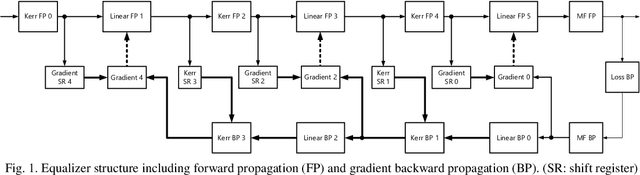
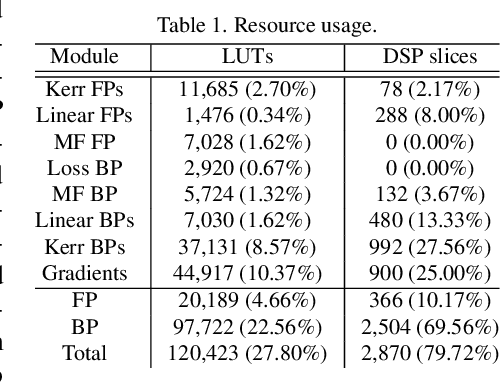

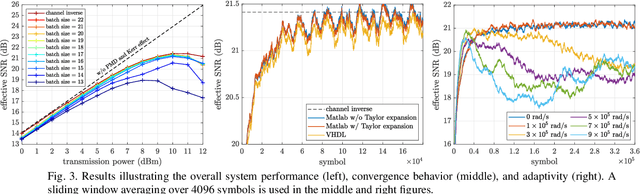
We design and implement an adaptive machine learning equalizer that alternates multiple linear and nonlinear computational layers on an FPGA. On-chip training via gradient backpropagation is shown to allow for real-time adaptation to time-varying channel impairments.
Multimodal Wildland Fire Smoke Detection
Dec 29, 2022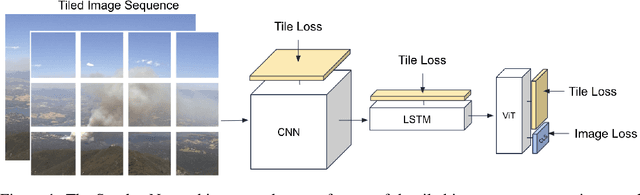
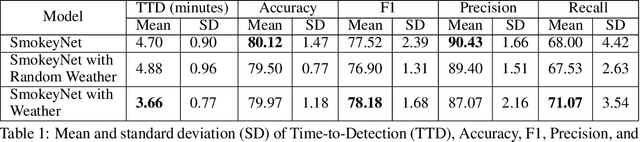
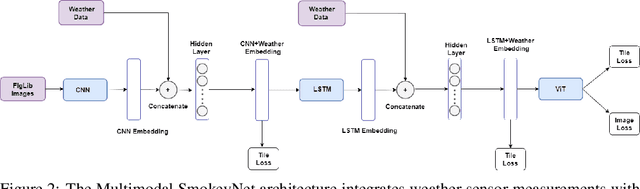
Research has shown that climate change creates warmer temperatures and drier conditions, leading to longer wildfire seasons and increased wildfire risks in the United States. These factors have in turn led to increases in the frequency, extent, and severity of wildfires in recent years. Given the danger posed by wildland fires to people, property, wildlife, and the environment, there is an urgency to provide tools for effective wildfire management. Early detection of wildfires is essential to minimizing potentially catastrophic destruction. In this paper, we present our work on integrating multiple data sources in SmokeyNet, a deep learning model using spatio-temporal information to detect smoke from wildland fires. Camera image data is integrated with weather sensor measurements and processed by SmokeyNet to create a multimodal wildland fire smoke detection system. We present our results comparing performance in terms of both accuracy and time-to-detection for multimodal data vs. a single data source. With a time-to-detection of only a few minutes, SmokeyNet can serve as an automated early notification system, providing a useful tool in the fight against destructive wildfires.
SMILE: Robust Network Localization via Sparse and Low-Rank Matrix Decomposition
Jan 26, 2023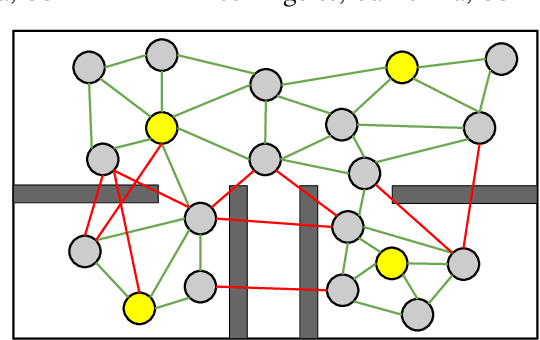

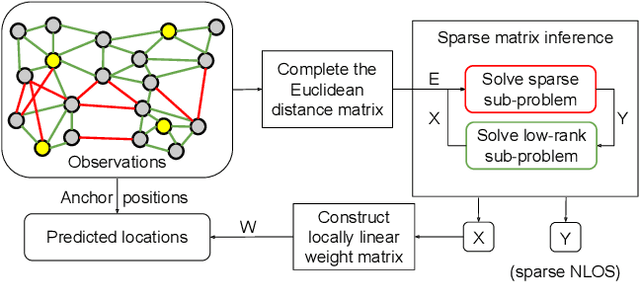
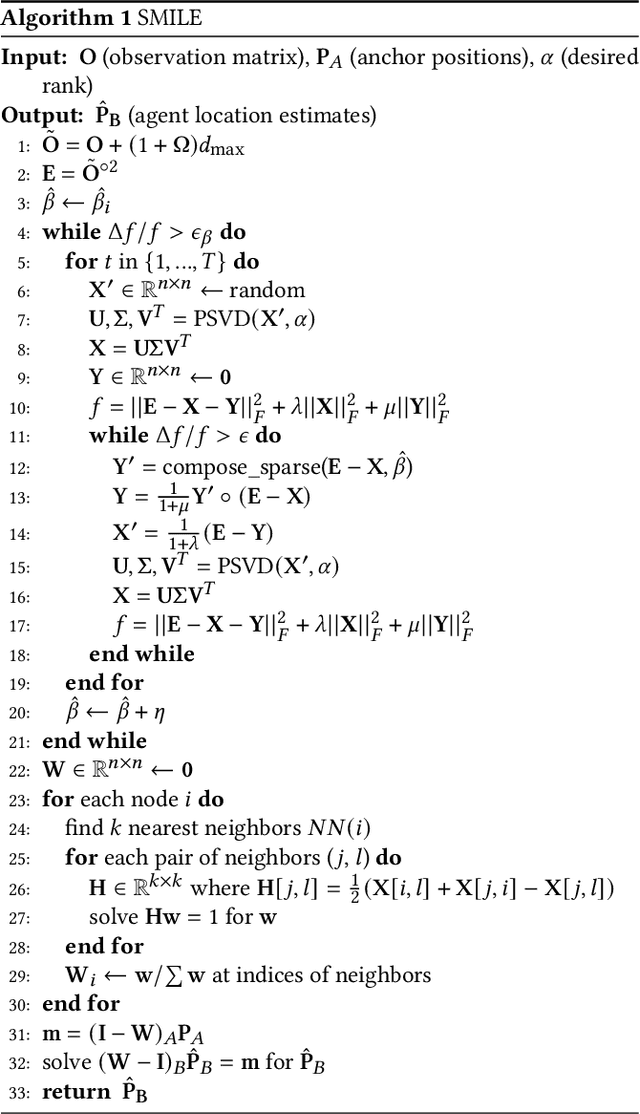
Motivated by collaborative localization in robotic sensor networks, we consider the problem of large-scale network localization where location estimates are derived from inter-node radio signals. Well-established methods for network localization commonly assume that all radio links are line-of-sight and subject to Gaussian noise. However, the presence of obstacles which cause non-line-of-sight attenuation present distinct challenges. To enable robust network localization, we present Sparse Matrix Inference and Linear Embedding (SMILE), a novel approach which draws on both the well-known Locally Linear Embedding (LLE) algorithm and recent advances in sparse plus low-rank matrix decomposition. We demonstrate that our approach is robust to noisy signal propagation, severe attenuation due to non-line-of-sight, and missing pairwise measurements. Our experiments include simulated large-scale networks, an 11-node sensor network, and an 18-node network of mobile robots and static anchor radios in a GPS-denied limestone mine. Our findings indicate that SMILE outperforms classical multidimensional scaling (MDS) which ignores the effect of non-line of sight (NLOS), as well as outperforming state-of-the-art robust network localization algorithms that do account for NLOS attenuation including a graph convolutional network-based approach. We demonstrate that this improved accuracy is not at the cost of complexity, as SMILE sees reduced computation time for very large networks which is important for position estimation updates in a dynamic setting, e.g for mobile robots.
Understanding Finetuning for Factual Knowledge Extraction from Language Models
Jan 26, 2023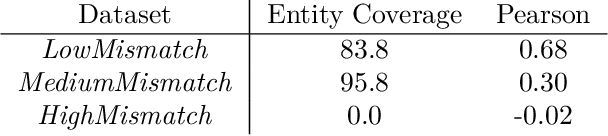

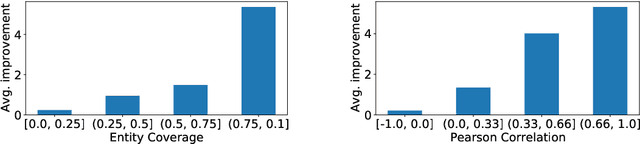

Language models (LMs) pretrained on large corpora of text from the web have been observed to contain large amounts of various types of knowledge about the world. This observation has led to a new and exciting paradigm in knowledge graph construction where, instead of manual curation or text mining, one extracts knowledge from the parameters of an LM. Recently, it has been shown that finetuning LMs on a set of factual knowledge makes them produce better answers to queries from a different set, thus making finetuned LMs a good candidate for knowledge extraction and, consequently, knowledge graph construction. In this paper, we analyze finetuned LMs for factual knowledge extraction. We show that along with its previously known positive effects, finetuning also leads to a (potentially harmful) phenomenon which we call Frequency Shock, where at the test time the model over-predicts rare entities that appear in the training set and under-predicts common entities that do not appear in the training set enough times. We show that Frequency Shock leads to a degradation in the predictions of the model and beyond a point, the harm from Frequency Shock can even outweigh the positive effects of finetuning, making finetuning harmful overall. We then consider two solutions to remedy the identified negative effect: 1- model mixing and 2- mixture finetuning with the LM's pre-training task. The two solutions combined lead to significant improvements compared to vanilla finetuning.
The Functional Wiener Filter
Dec 31, 2022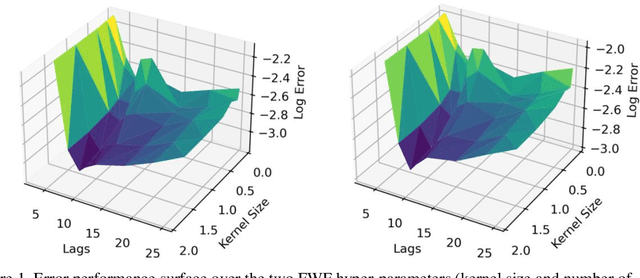
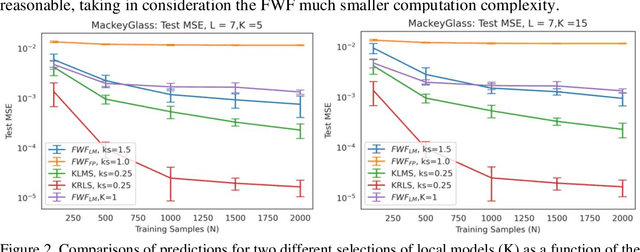
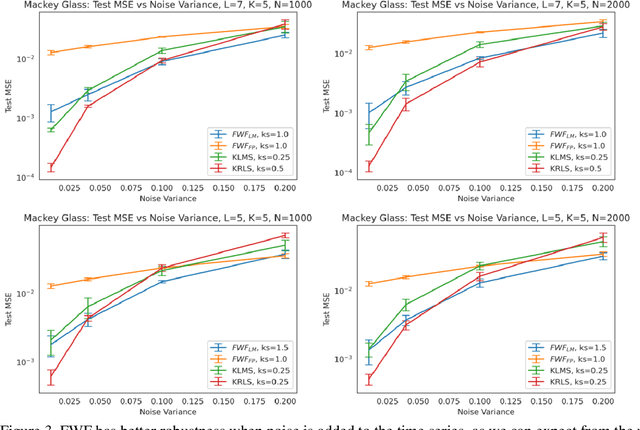
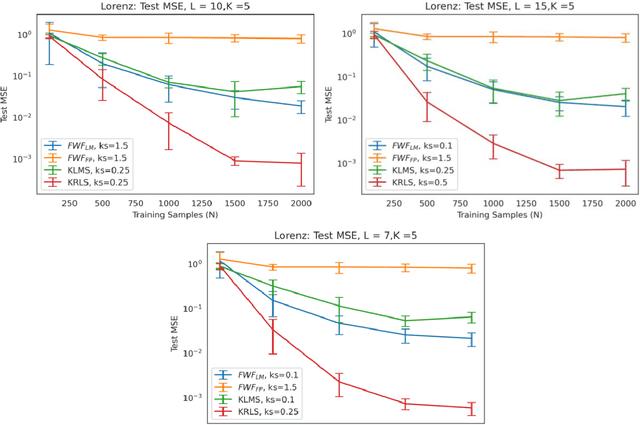
This paper presents a close form solution in Reproducing Kernel Hilbert Space (RKHS) for the famed Wiener filter, which we called the functional Wiener filter(FWF). Instead of using the Wiener-Hopf factorization theory, here we define a new lagged RKHS that embeds signal statistics based on the correntropy function. In essence, we extend Parzen$'$s work on the autocorrelation function RKHS to nonlinear functional spaces. The FWF derivation is also quite different from kernel adaptive filtering (KAF) algorithms, which utilize a search approach. The analytic FWF solution is derived in the Gaussian kernel RKHS with a constant computational complexity similar to the Wiener solution, and never composes nor employs the error as in conventional optimal modeling. Because of the lack of congruence between the Gaussian RKHS and the space of time series, we compare performance of two pre-imaging algorithms: a fixed-point optimization (FWFFP) that finds and approximate solution in the RKHS, and a local model implementation named FWFLM. The experimental results show that the FWF performance is on par with the KAF for time series modeling, and it requires far less computation.