 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Silent Killer: Optimizing Backdoor Trigger Yields a Stealthy and Powerful Data Poisoning Attack
Jan 05, 2023
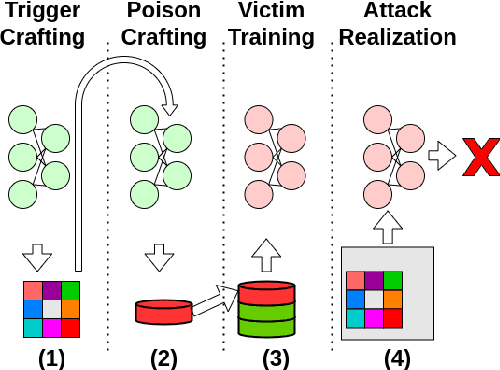
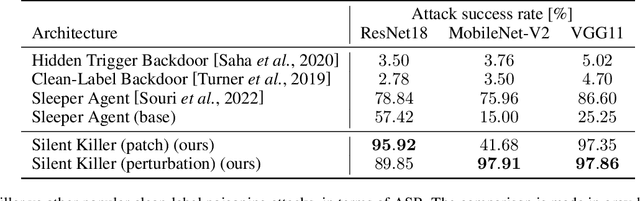


We propose a stealthy and powerful backdoor attack on neural networks based on data poisoning (DP). In contrast to previous attacks, both the poison and the trigger in our method are stealthy. We are able to change the model's classification of samples from a source class to a target class chosen by the attacker. We do so by using a small number of poisoned training samples with nearly imperceptible perturbations, without changing their labels. At inference time, we use a stealthy perturbation added to the attacked samples as a trigger. This perturbation is crafted as a universal adversarial perturbation (UAP), and the poison is crafted using gradient alignment coupled to this trigger. Our method is highly efficient in crafting time compared to previous methods and requires only a trained surrogate model without additional retraining. Our attack achieves state-of-the-art results in terms of attack success rate while maintaining high accuracy on clean samples.
Device JNEEG to convert Jetson Nano to brain-Computer interfaces. Short report
Jan 23, 2023
Artificial intelligence has made significant advances in recent years and this has had an impact on the field of neuroscience. As a result, different architectures have been implemented to extract features from EEG signals in real time. However, the use of such architectures requires a lot of computing power. As a result, EEG devices typically act only as transmitters of EEG data, with the actual data processing taking place in a third-party device. That's expensive and not compact. In this paper, we present a shield that allows a single-board computer, the Jetson Nano from Nvidia, to be converted into a brain-computer interface and, most importantly, the Jetson Nano's capabilities allow machine learning tools to be used directly on the data collection device. Here we present the test results of the developed device. https://github.com/HackerBCI/EEG-with-JetsonNano
Balance is Essence: Accelerating Sparse Training via Adaptive Gradient Correction
Jan 09, 2023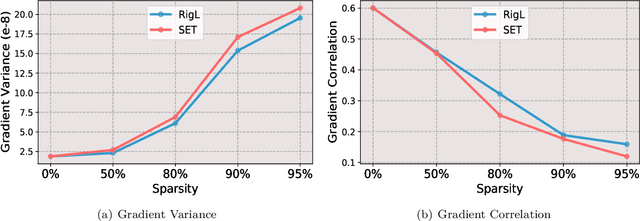
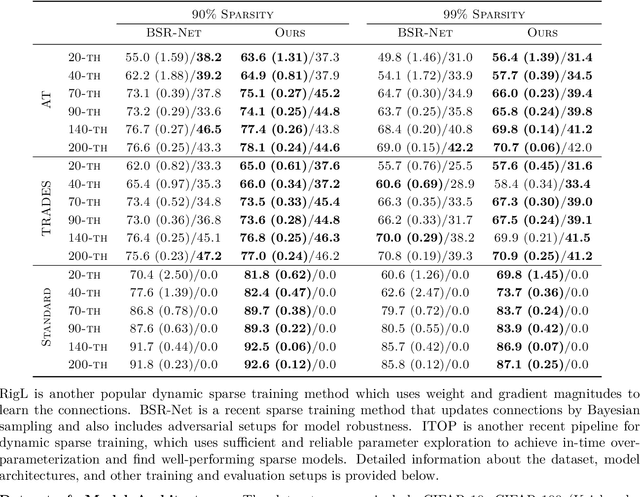
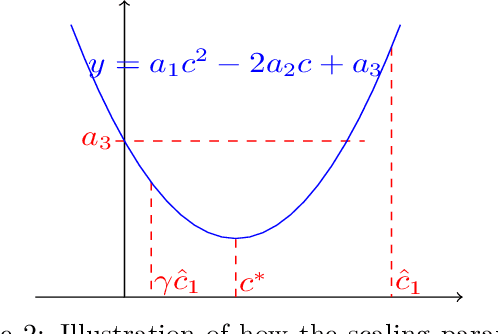
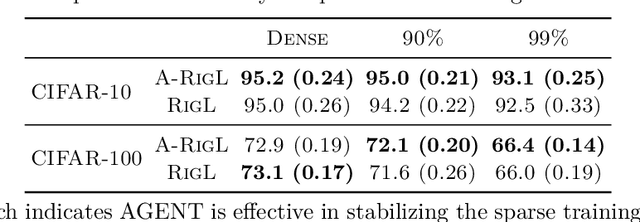
Despite impressive performance on a wide variety of tasks, deep neural networks require significant memory and computation costs, prohibiting their application in resource-constrained scenarios. Sparse training is one of the most common techniques to reduce these costs, however, the sparsity constraints add difficulty to the optimization, resulting in an increase in training time and instability. In this work, we aim to overcome this problem and achieve space-time co-efficiency. To accelerate and stabilize the convergence of sparse training, we analyze the gradient changes and develop an adaptive gradient correction method. Specifically, we approximate the correlation between the current and previous gradients, which is used to balance the two gradients to obtain a corrected gradient. Our method can be used with most popular sparse training pipelines under both standard and adversarial setups. Theoretically, we prove that our method can accelerate the convergence rate of sparse training. Extensive experiments on multiple datasets, model architectures, and sparsities demonstrate that our method outperforms leading sparse training methods by up to \textbf{5.0\%} in accuracy given the same number of training epochs, and reduces the number of training epochs by up to \textbf{52.1\%} to achieve the same accuracy.
Latent Autoregressive Source Separation
Jan 09, 2023

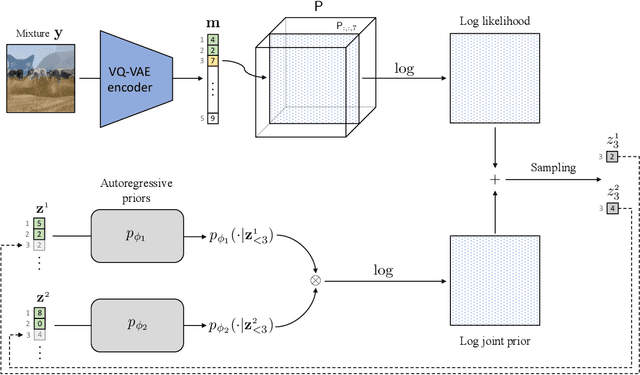
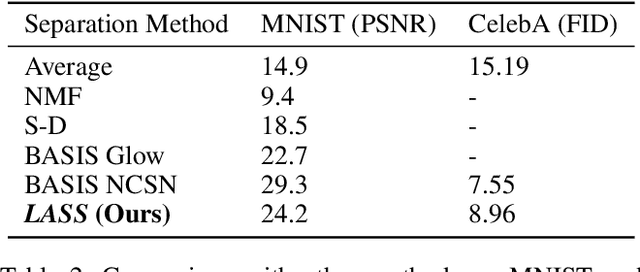
Autoregressive models have achieved impressive results over a wide range of domains in terms of generation quality and downstream task performance. In the continuous domain, a key factor behind this success is the usage of quantized latent spaces (e.g., obtained via VQ-VAE autoencoders), which allow for dimensionality reduction and faster inference times. However, using existing pre-trained models to perform new non-trivial tasks is difficult since it requires additional fine-tuning or extensive training to elicit prompting. This paper introduces LASS as a way to perform vector-quantized Latent Autoregressive Source Separation (i.e., de-mixing an input signal into its constituent sources) without requiring additional gradient-based optimization or modifications of existing models. Our separation method relies on the Bayesian formulation in which the autoregressive models are the priors, and a discrete (non-parametric) likelihood function is constructed by performing frequency counts over latent sums of addend tokens. We test our method on images and audio with several sampling strategies (e.g., ancestral, beam search) showing competitive results with existing approaches in terms of separation quality while offering at the same time significant speedups in terms of inference time and scalability to higher dimensional data.
FRAME: Fast and Robust Autonomous 3D point cloud Map-merging for Egocentric multi-robot exploration
Jan 24, 2023
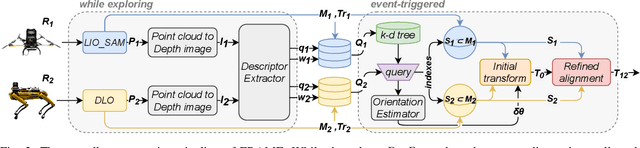
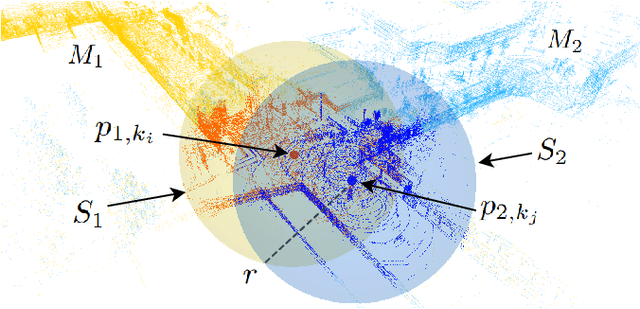
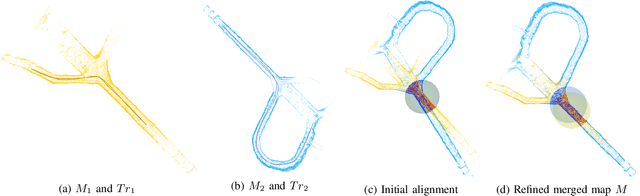
This article presents a 3D point cloud map-merging framework for egocentric heterogeneous multi-robot exploration, based on overlap detection and alignment, that is independent of a manual initial guess or prior knowledge of the robots' poses. The novel proposed solution utilizes state-of-the-art place recognition learned descriptors, that through the framework's main pipeline, offer a fast and robust region overlap estimation, hence eliminating the need for the time-consuming global feature extraction and feature matching process that is typically used in 3D map integration. The region overlap estimation provides a homogeneous rigid transform that is applied as an initial condition in the point cloud registration algorithm Fast-GICP, which provides the final and refined alignment. The efficacy of the proposed framework is experimentally evaluated based on multiple field multi-robot exploration missions in underground environments, where both ground and aerial robots are deployed, with different sensor configurations.
Semi-Automated Construction of Food Composition Knowledge Base
Jan 24, 2023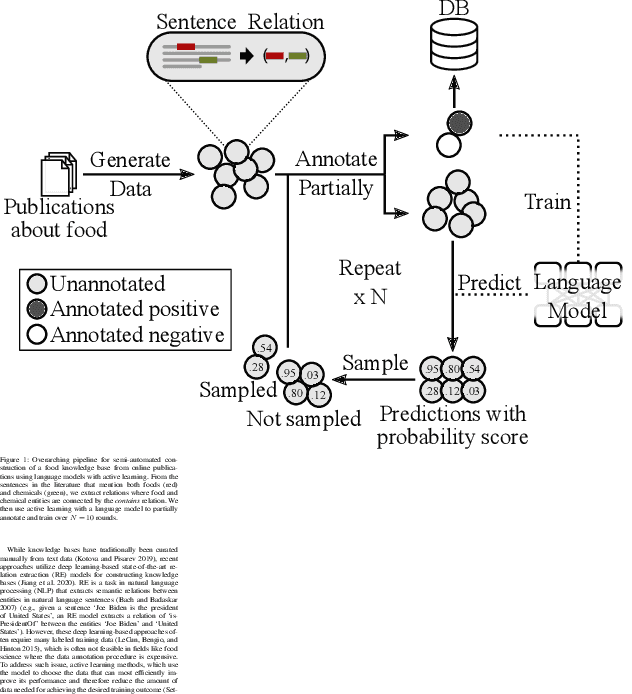
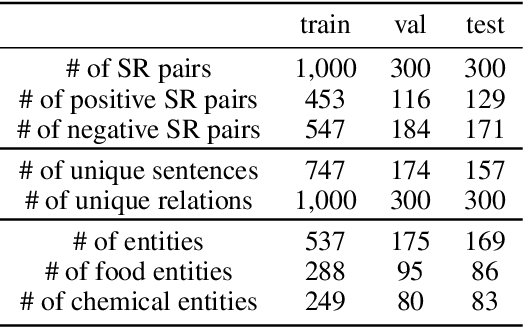
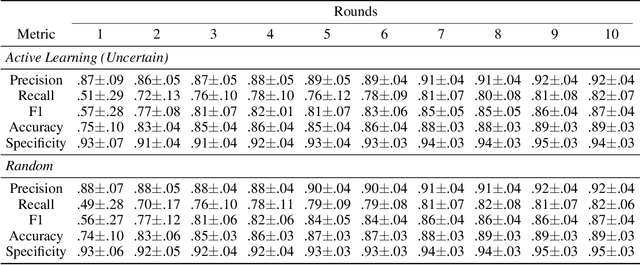
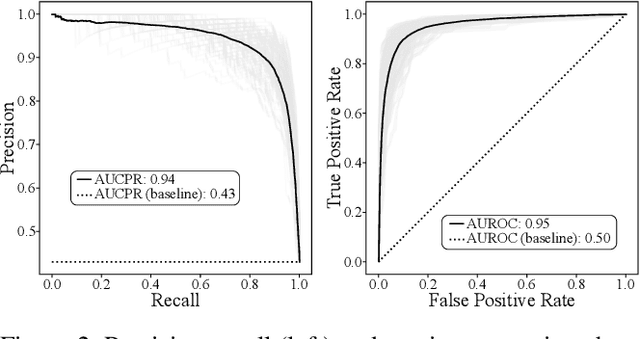
A food composition knowledge base, which stores the essential phyto-, micro-, and macro-nutrients of foods is useful for both research and industrial applications. Although many existing knowledge bases attempt to curate such information, they are often limited by time-consuming manual curation processes. Outside of the food science domain, natural language processing methods that utilize pre-trained language models have recently shown promising results for extracting knowledge from unstructured text. In this work, we propose a semi-automated framework for constructing a knowledge base of food composition from the scientific literature available online. To this end, we utilize a pre-trained BioBERT language model in an active learning setup that allows the optimal use of limited training data. Our work demonstrates how human-in-the-loop models are a step toward AI-assisted food systems that scale well to the ever-increasing big data.
When Source-Free Domain Adaptation Meets Learning with Noisy Labels
Jan 31, 2023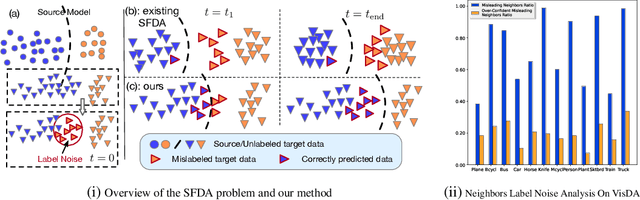
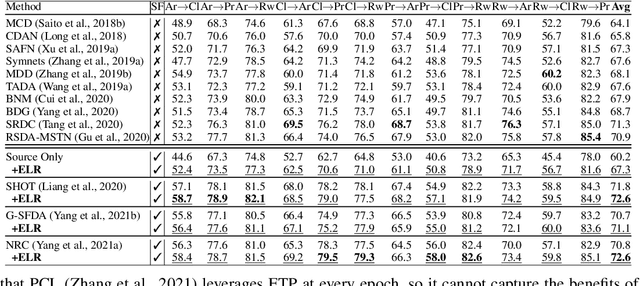
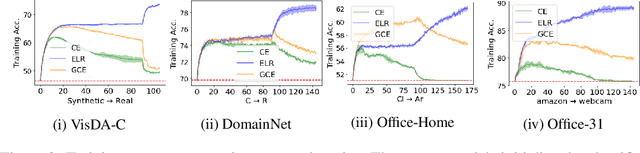
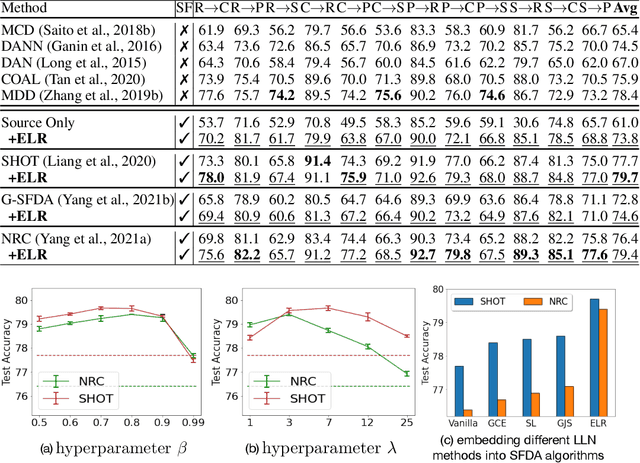
Recent state-of-the-art source-free domain adaptation (SFDA) methods have focused on learning meaningful cluster structures in the feature space, which have succeeded in adapting the knowledge from source domain to unlabeled target domain without accessing the private source data. However, existing methods rely on the pseudo-labels generated by source models that can be noisy due to domain shift. In this paper, we study SFDA from the perspective of learning with label noise (LLN). Unlike the label noise in the conventional LLN scenario, we prove that the label noise in SFDA follows a different distribution assumption. We also prove that such a difference makes existing LLN methods that rely on their distribution assumptions unable to address the label noise in SFDA. Empirical evidence suggests that only marginal improvements are achieved when applying the existing LLN methods to solve the SFDA problem. On the other hand, although there exists a fundamental difference between the label noise in the two scenarios, we demonstrate theoretically that the early-time training phenomenon (ETP), which has been previously observed in conventional label noise settings, can also be observed in the SFDA problem. Extensive experiments demonstrate significant improvements to existing SFDA algorithms by leveraging ETP to address the label noise in SFDA.
What Makes Good Examples for Visual In-Context Learning?
Jan 31, 2023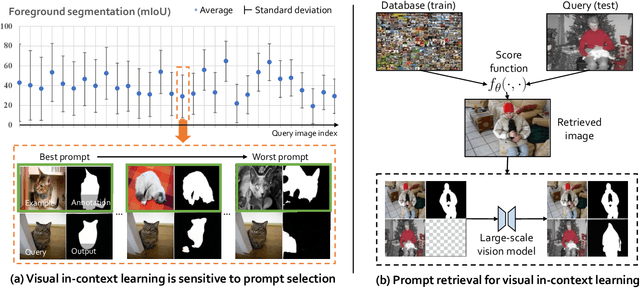

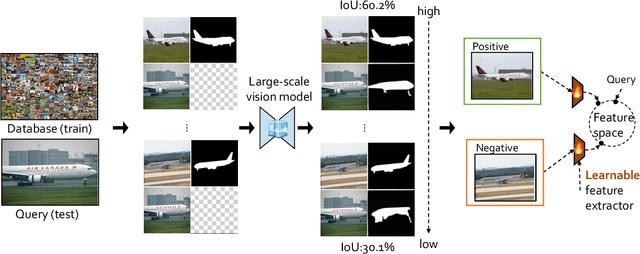
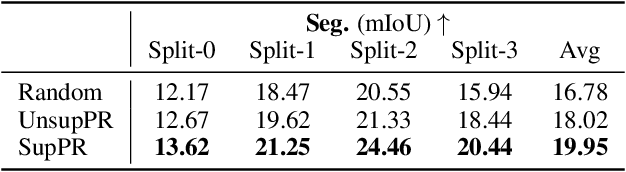
Large-scale models trained on broad data have recently become the mainstream architecture in computer vision due to their strong generalization performance. In this paper, the main focus is on an emergent ability in large vision models, known as in-context learning, which allows inference on unseen tasks by conditioning on in-context examples (a.k.a.~prompt) without updating the model parameters. This concept has been well-known in natural language processing but has only been studied very recently for large vision models. We for the first time provide a comprehensive investigation on the impact of in-context examples in computer vision, and find that the performance is highly sensitive to the choice of in-context examples. To overcome the problem, we propose a prompt retrieval framework to automate the selection of in-context examples. Specifically, we present (1) an unsupervised prompt retrieval method based on nearest example search using an off-the-shelf model, and (2) a supervised prompt retrieval method, which trains a neural network to choose examples that directly maximize in-context learning performance. The results demonstrate that our methods can bring non-trivial improvements to visual in-context learning in comparison to the commonly-used random selection.
Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models
Jan 31, 2023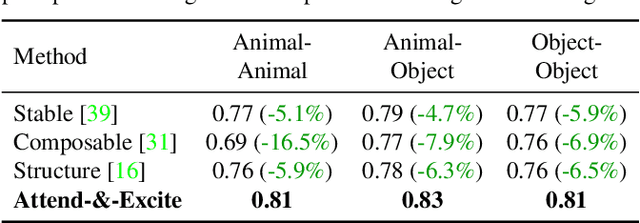

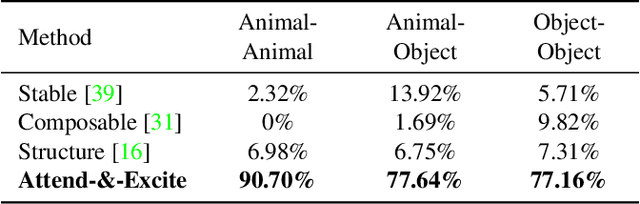
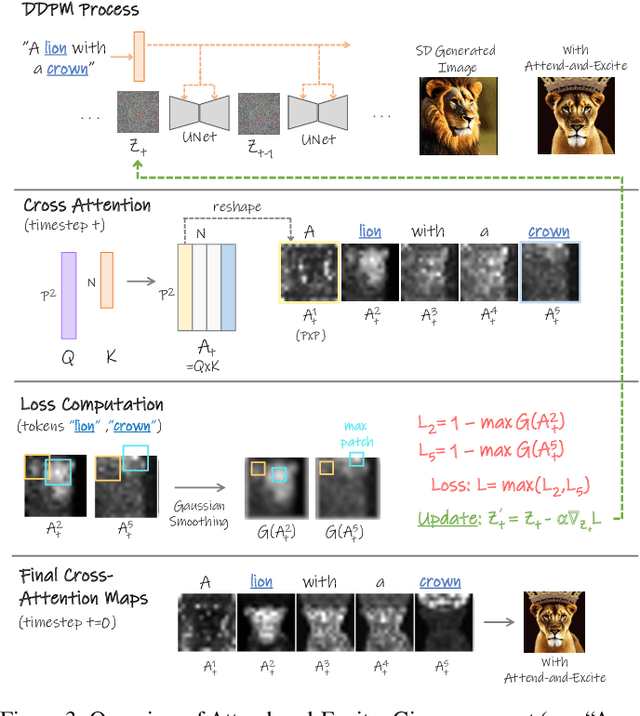
Recent text-to-image generative models have demonstrated an unparalleled ability to generate diverse and creative imagery guided by a target text prompt. While revolutionary, current state-of-the-art diffusion models may still fail in generating images that fully convey the semantics in the given text prompt. We analyze the publicly available Stable Diffusion model and assess the existence of catastrophic neglect, where the model fails to generate one or more of the subjects from the input prompt. Moreover, we find that in some cases the model also fails to correctly bind attributes (e.g., colors) to their corresponding subjects. To help mitigate these failure cases, we introduce the concept of Generative Semantic Nursing (GSN), where we seek to intervene in the generative process on the fly during inference time to improve the faithfulness of the generated images. Using an attention-based formulation of GSN, dubbed Attend-and-Excite, we guide the model to refine the cross-attention units to attend to all subject tokens in the text prompt and strengthen - or excite - their activations, encouraging the model to generate all subjects described in the text prompt. We compare our approach to alternative approaches and demonstrate that it conveys the desired concepts more faithfully across a range of text prompts.
Evaluating Temporal Observation-Based Causal Discovery Techniques Applied to Road Driver Behaviour
Jan 31, 2023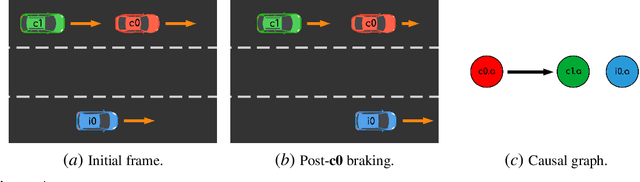
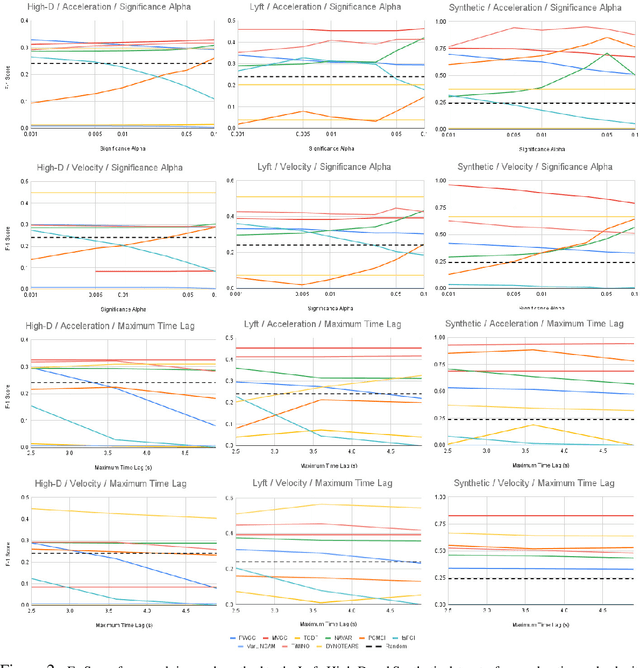
Autonomous robots are required to reason about the behaviour of dynamic agents in their environment. To this end, many approaches assume that causal models describing the interactions of agents are given a priori. However, in many application domains such models do not exist or cannot be engineered. Hence, the learning (or discovery) of high-level causal structures from low-level, temporal observations is a key problem in AI and robotics. However, the application of causal discovery methods to scenarios involving autonomous agents remains in the early stages of research. While a number of methods exist for performing causal discovery on time series data, these usually rely upon assumptions such as sufficiency and stationarity which cannot be guaranteed in interagent behavioural interactions in the real world. In this paper we are applying contemporary observation-based temporal causal discovery techniques to real world and synthetic driving scenarios from multiple datasets. Our evaluation demonstrates and highlights the limitations of state of the art approaches by comparing and contrasting the performance between real and synthetically generated data. Finally, based on our analysis, we discuss open issues related to causal discovery on autonomous robotics scenarios and propose future research directions for overcoming current limitations in the field.