 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploitation and exploration in text evolution. Quantifying planning and translation flows during writing
Feb 08, 2023
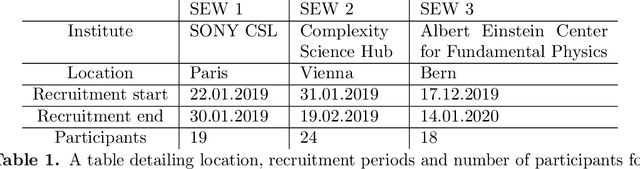
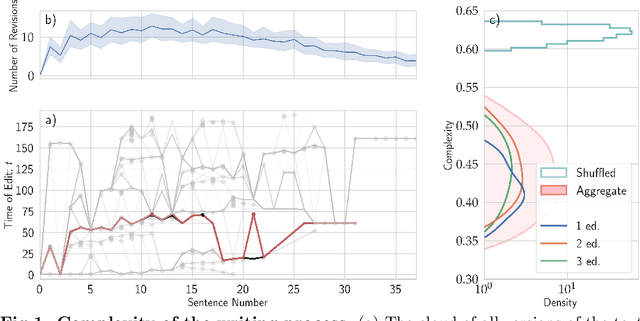
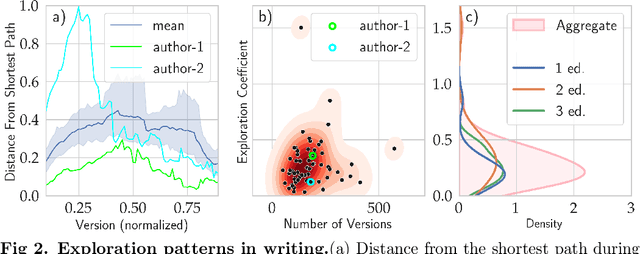
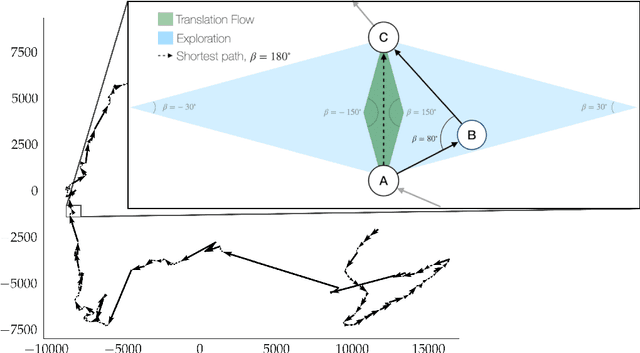
Writing is a complex process at the center of much of modern human activity. Despite it appears to be a linear process, writing conceals many highly non-linear processes. Previous research has focused on three phases of writing: planning, translation and transcription, and revision. While research has shown these are non-linear, they are often treated linearly when measured. Here, we introduce measures to detect and quantify subcycles of planning (exploration) and translation (exploitation) during the writing process. We apply these to a novel dataset that recorded the creation of a text in all its phases, from early attempts to the finishing touches on a final version. This dataset comes from a series of writing workshops in which, through innovative versioning software, we were able to record all the steps in the construction of a text. More than 60 junior researchers in science wrote a scientific essay intended for a general readership. We recorded each essay as a writing cloud, defined as a complex topological structure capturing the history of the essay itself. Through this unique dataset of writing clouds, we expose a representation of the writing process that quantifies its complexity and the writer's efforts throughout the draft and through time. Interestingly, this representation highlights the phases of "translation flow", where authors improve existing ideas, and exploration, where creative deviations appear as the writer returns to the planning phase. These turning points between translation and exploration become rarer as the writing process progresses and the author approaches the final version. Our results and the new measures introduced have the potential to foster the discussion about the non-linear nature of writing and support the development of tools that can support more creative and impactful writing processes.
Explainable AI for clinical and remote health applications: a survey on tabular and time series data
Sep 14, 2022
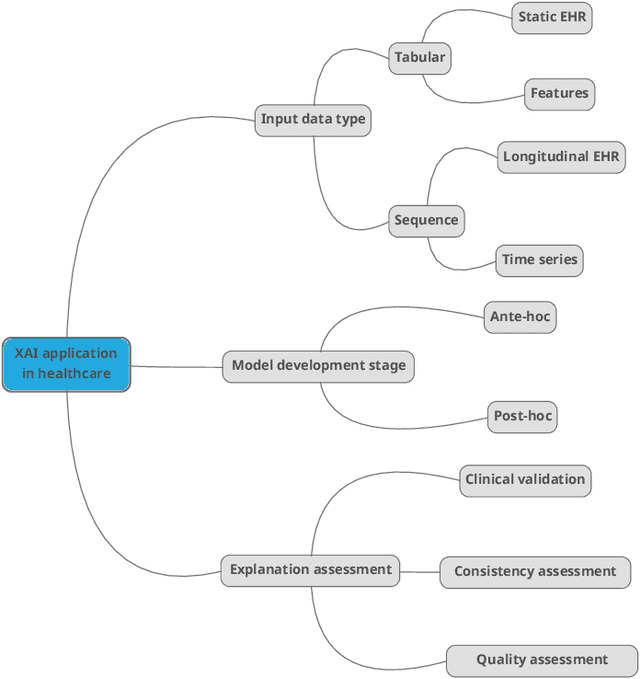


Nowadays Artificial Intelligence (AI) has become a fundamental component of healthcare applications, both clinical and remote, but the best performing AI systems are often too complex to be self-explaining. Explainable AI (XAI) techniques are defined to unveil the reasoning behind the system's predictions and decisions, and they become even more critical when dealing with sensitive and personal health data. It is worth noting that XAI has not gathered the same attention across different research areas and data types, especially in healthcare. In particular, many clinical and remote health applications are based on tabular and time series data, respectively, and XAI is not commonly analysed on these data types, while computer vision and Natural Language Processing (NLP) are the reference applications. To provide an overview of XAI methods that are most suitable for tabular and time series data in the healthcare domain, this paper provides a review of the literature in the last 5 years, illustrating the type of generated explanations and the efforts provided to evaluate their relevance and quality. Specifically, we identify clinical validation, consistency assessment, objective and standardised quality evaluation, and human-centered quality assessment as key features to ensure effective explanations for the end users. Finally, we highlight the main research challenges in the field as well as the limitations of existing XAI methods.
PROFHIT: Probabilistic Robust Forecasting for Hierarchical Time-series
Jun 20, 2022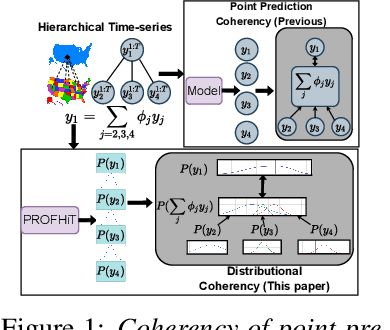
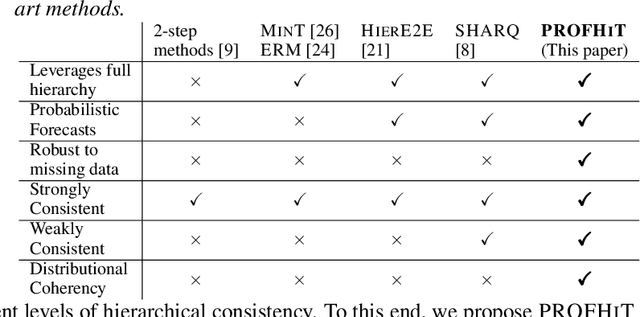
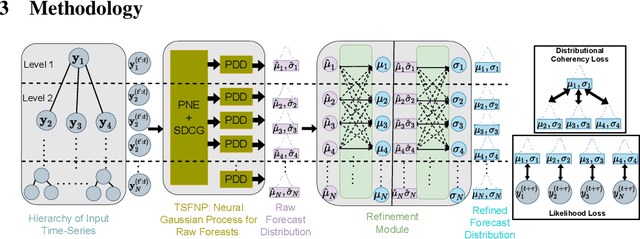
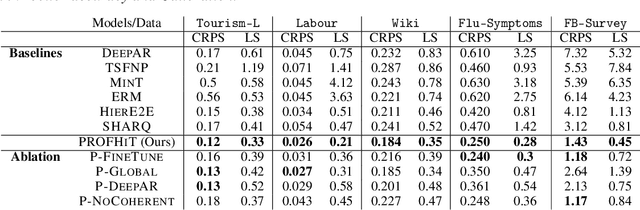
Probabilistic hierarchical time-series forecasting is an important variant of time-series forecasting, where the goal is to model and forecast multivariate time-series that have underlying hierarchical relations. Most methods focus on point predictions and do not provide well-calibrated probabilistic forecasts distributions. Recent state-of-art probabilistic forecasting methods also impose hierarchical relations on point predictions and samples of distribution which does not account for coherency of forecast distributions. Previous works also silently assume that datasets are always consistent with given hierarchical relations and do not adapt to real-world datasets that show deviation from this assumption. We close both these gaps and propose PROFHIT, which is a fully probabilistic hierarchical forecasting model that jointly models forecast distribution of entire hierarchy. PROFHIT uses a flexible probabilistic Bayesian approach and introduces a novel Distributional Coherency regularization to learn from hierarchical relations for entire forecast distribution that enables robust and calibrated forecasts as well as adapt to datasets of varying hierarchical consistency. On evaluating PROFHIT over wide range of datasets, we observed 41-88% better performance in accuracy and calibration. Due to modeling the coherency over full distribution, we observed that PROFHIT can robustly provide reliable forecasts even if up to 10% of input time-series data is missing where other methods' performance severely degrade by over 70%.
Calibrated Data-Dependent Constraints with Exact Satisfaction Guarantees
Jan 15, 2023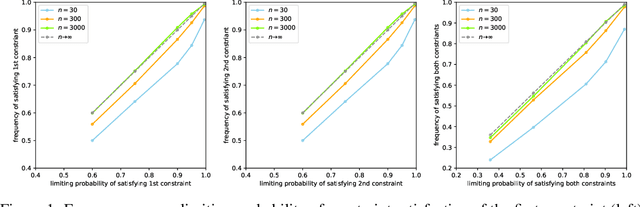
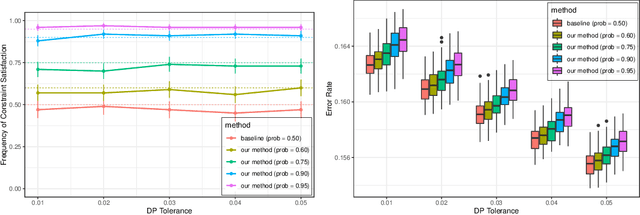
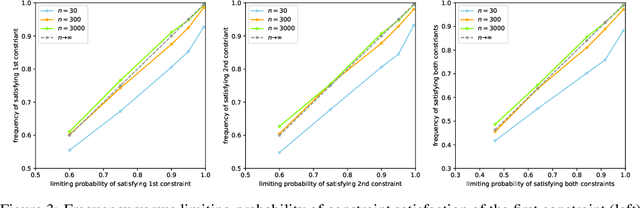
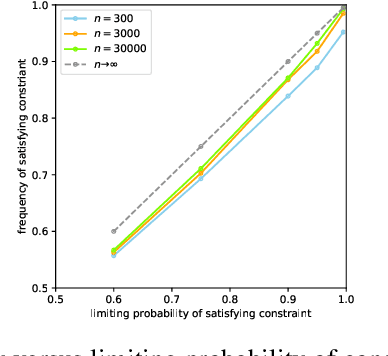
We consider the task of training machine learning models with data-dependent constraints. Such constraints often arise as empirical versions of expected value constraints that enforce fairness or stability goals. We reformulate data-dependent constraints so that they are calibrated: enforcing the reformulated constraints guarantees that their expected value counterparts are satisfied with a user-prescribed probability. The resulting optimization problem is amendable to standard stochastic optimization algorithms, and we demonstrate the efficacy of our method on a fairness-sensitive classification task where we wish to guarantee the classifier's fairness (at test time).
Space-time tradeoffs of lenses and optics via higher category theory
Sep 19, 2022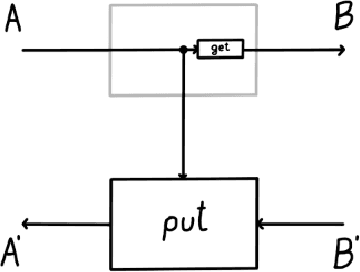
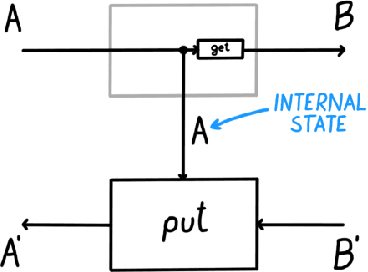
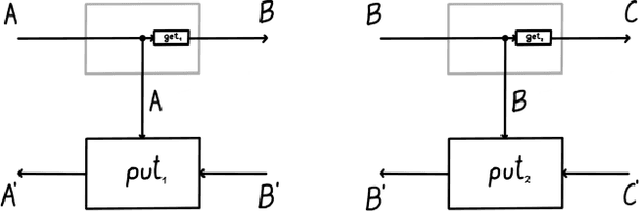
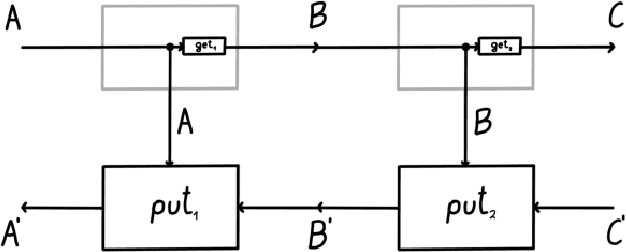
Optics and lenses are abstract categorical gadgets that model systems with bidirectional data flow. In this paper we observe that the denotational definition of optics - identifying two optics as equivalent by observing their behaviour from the outside - is not suitable for operational, software oriented approaches where optics are not merely observed, but built with their internal setups in mind. We identify operational differences between denotationally isomorphic categories of cartesian optics and lenses: their different composition rule and corresponding space-time tradeoffs, positioning them at two opposite ends of a spectrum. With these motivations we lift the existing categorical constructions and their relationships to the 2-categorical level, showing that the relevant operational concerns become visible. We define the 2-category $\textbf{2-Optic}(\mathcal{C})$ whose 2-cells explicitly track optics' internal configuration. We show that the 1-category $\textbf{Optic}(\mathcal{C})$ arises by locally quotienting out the connected components of this 2-category. We show that the embedding of lenses into cartesian optics gets weakened from a functor to an oplax functor whose oplaxator now detects the different composition rule. We determine the difficulties in showing this functor forms a part of an adjunction in any of the standard 2-categories. We establish a conjecture that the well-known isomorphism between cartesian lenses and optics arises out of the lax 2-adjunction between their double-categorical counterparts. In addition to presenting new research, this paper is also meant to be an accessible introduction to the topic.
TF-Net: Deep Learning Empowered Tiny Feature Network for Night-time UAV Detection
Nov 29, 2022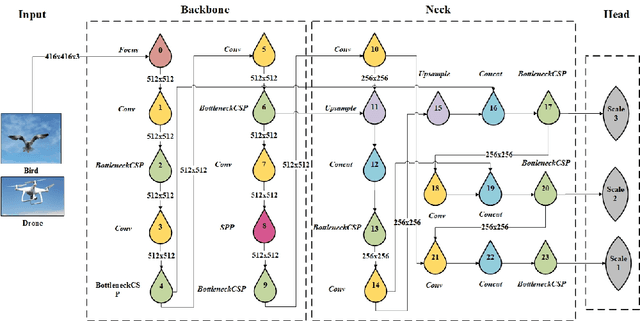

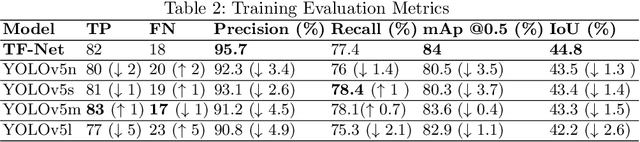
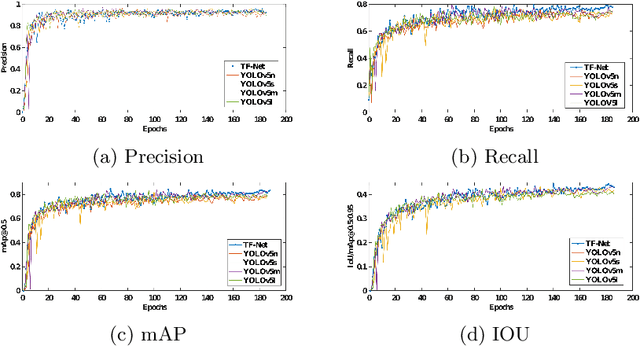
Technological advancements have normalized the usage of unmanned aerial vehicles (UAVs) in every sector, spanning from military to commercial but they also pose serious security concerns due to their enhanced functionalities and easy access to private and highly secured areas. Several instances related to UAVs have raised security concerns, leading to UAV detection research studies. Visual techniques are widely adopted for UAV detection, but they perform poorly at night, in complex backgrounds, and in adverse weather conditions. Therefore, a robust night vision-based drone detection system is required to that could efficiently tackle this problem. Infrared cameras are increasingly used for nighttime surveillance due to their wide applications in night vision equipment. This paper uses a deep learning-based TinyFeatureNet (TF-Net), which is an improved version of YOLOv5s, to accurately detect UAVs during the night using infrared (IR) images. In the proposed TF-Net, we introduce architectural changes in the neck and backbone of the YOLOv5s. We also simulated four different YOLOv5 models (s,m,n,l) and proposed TF-Net for a fair comparison. The results showed better performance for the proposed TF-Net in terms of precision, IoU, GFLOPS, model size, and FPS compared to the YOLOv5s. TF-Net yielded the best results with 95.7\% precision, 84\% mAp, and 44.8\% $IoU$.
Frequency-Domain Detection for Molecular Communications
Jan 03, 2023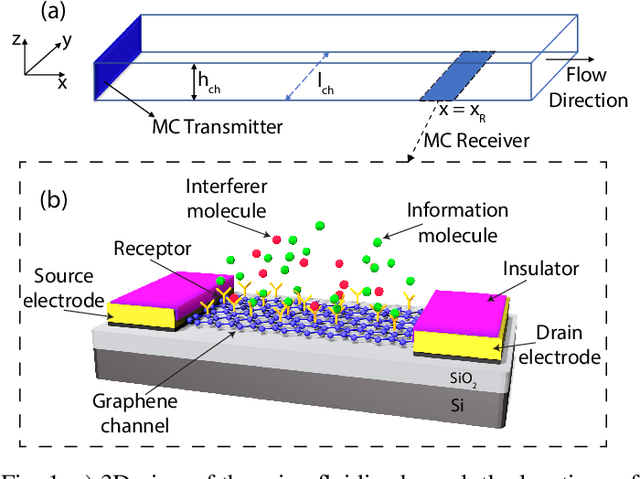
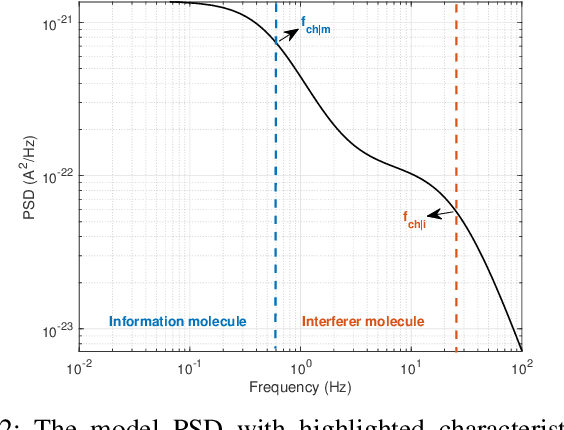
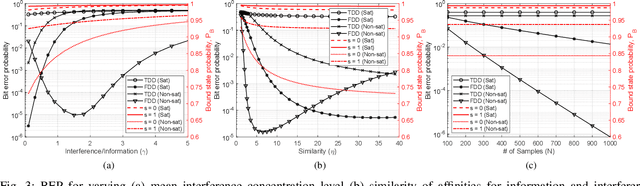
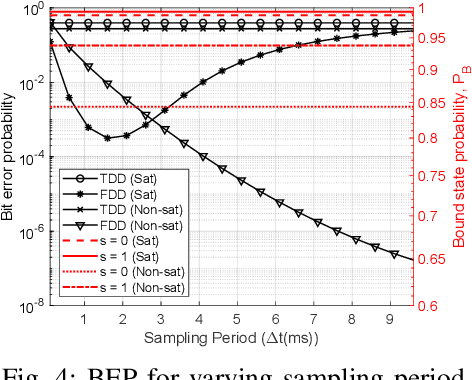
Molecular Communications (MC) is a bio-inspired communication paradigm which uses molecules as information carriers, thereby requiring unconventional transmitter/receiver architectures and modulation/detection techniques. Practical MC receivers (MC-Rxs) can be implemented based on field-effect transistor biosensor (bioFET) architectures, where surface receptors reversibly react with ligands, whose concentration encodes the information. The time-varying concentration of ligand-bound receptors is then translated into electrical signals via field-effect, which is used to decode the transmitted information. However, ligand-receptor interactions do not provide an ideal molecular selectivity, as similar types of ligands, i.e., interferers, co-existing in the MC channel can interact with the same type of receptors, resulting in cross-talk. Overcoming this molecular cross-talk with time-domain samples of the Rx's electrical output is not always attainable, especially when Rx has no knowledge of the interferer statistics or it operates near saturation. In this study, we propose a frequency-domain detection (FDD) technique for bioFET-based MC-Rxs, which exploits the difference in binding reaction rates of different types of ligands, reflected to the noise spectrum of the ligand-receptor binding fluctuations. We analytically derive the bit error probability (BEP) of the FDD technique, and demonstrate its effectiveness in decoding transmitted concentration signals under stochastic molecular interference, in comparison to a widely-used time-domain detection (TDD) technique. The proposed FDD method can be applied to any biosensor-based MC-Rxs, which employ receptor molecules as the channel-Rx interface.
Game Theoretic Decision Making by Actively Learning Human Intentions Applied on Autonomous Driving
Jan 22, 2023
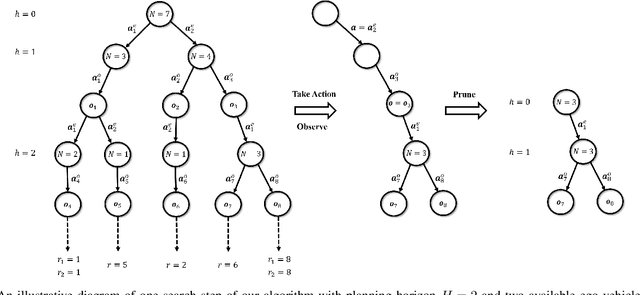
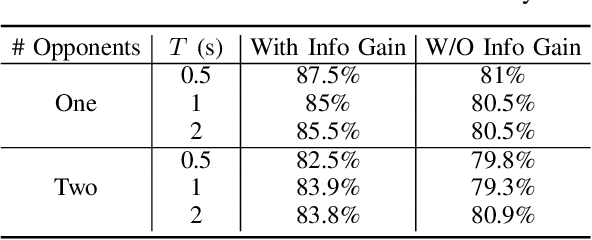
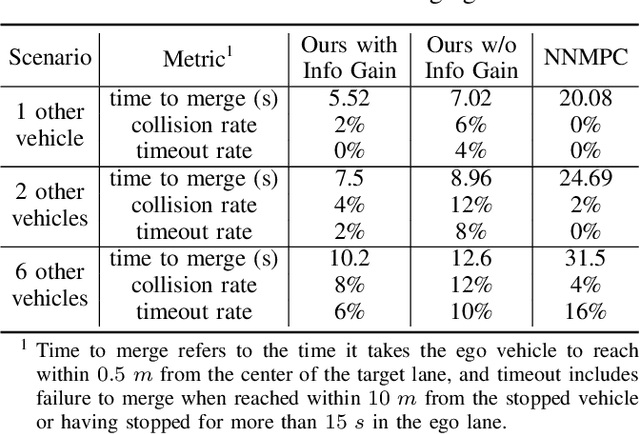
The ability to estimate human intentions and interact with human drivers intelligently is crucial for autonomous vehicles to successfully achieve their objectives. In this paper, we propose a game theoretic planning algorithm that models human opponents with an iterative reasoning framework and estimates human latent cognitive states through probabilistic inference and active learning. By modeling the interaction as a partially observable Markov decision process with adaptive state and action spaces, our algorithm is able to accomplish real-time lane changing tasks in a realistic driving simulator. We compare our algorithm's lane changing performance in dense traffic with a state-of-the-art autonomous lane changing algorithm to show the advantage of iterative reasoning and active learning in terms of avoiding overly conservative behaviors and achieving the driving objective successfully.
Prompt Federated Learning for Weather Forecasting: Toward Foundation Models on Meteorological Data
Jan 22, 2023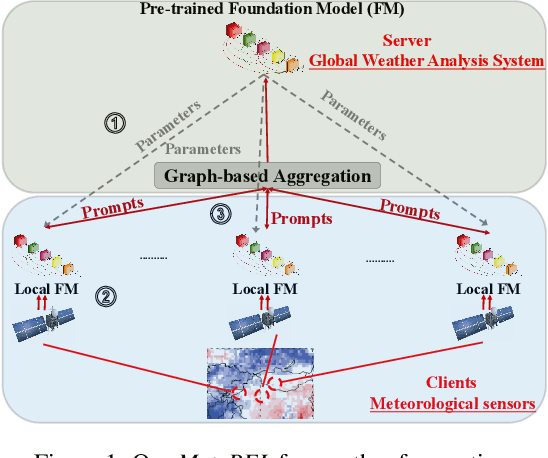
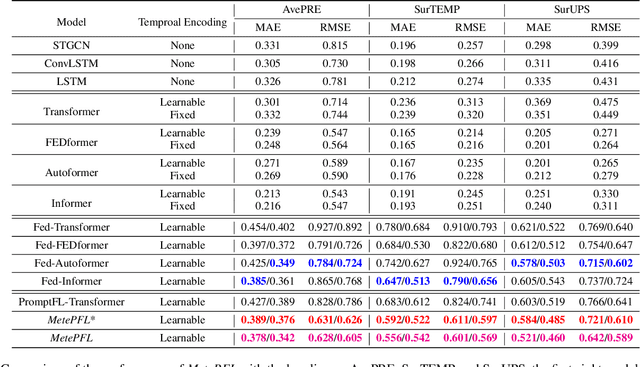
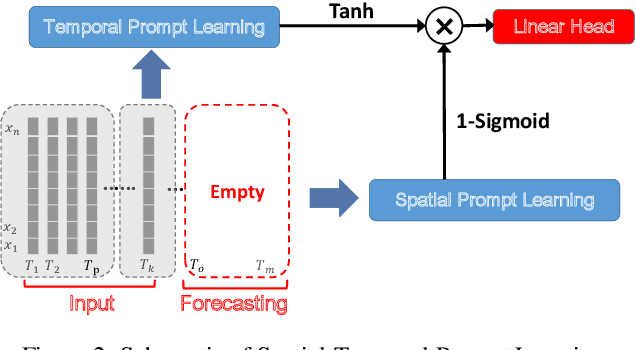
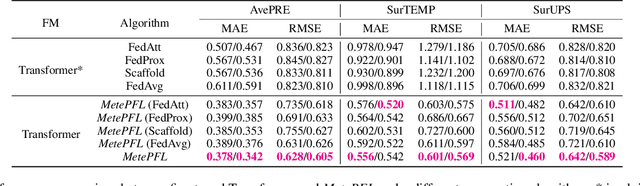
To tackle the global climate challenge, it urgently needs to develop a collaborative platform for comprehensive weather forecasting on large-scale meteorological data. Despite urgency, heterogeneous meteorological sensors across countries and regions, inevitably causing multivariate heterogeneity and data exposure, become the main barrier. This paper develops a foundation model across regions capable of understanding complex meteorological data and providing weather forecasting. To relieve the data exposure concern across regions, a novel federated learning approach has been proposed to collaboratively learn a brand-new spatio-temporal Transformer-based foundation model across participants with heterogeneous meteorological data. Moreover, a novel prompt learning mechanism has been adopted to satisfy low-resourced sensors' communication and computational constraints. The effectiveness of the proposed method has been demonstrated on classical weather forecasting tasks using three meteorological datasets with multivariate time series.
SA-NET.v2: Real-time vehicle detection from oblique UAV images with use of uncertainty estimation in deep meta-learning
Aug 04, 2022
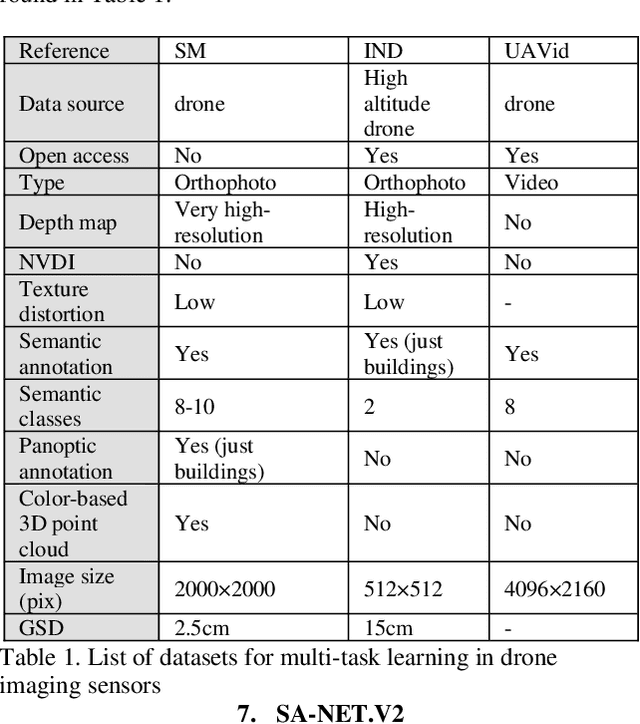
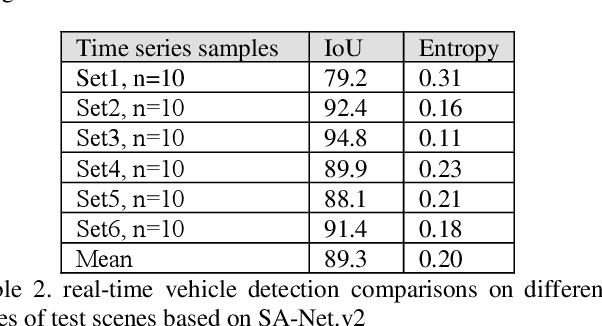

In recent years, unmanned aerial vehicle (UAV) imaging is a suitable solution for real-time monitoring different vehicles on the urban scale. Real-time vehicle detection with the use of uncertainty estimation in deep meta-learning for the portable platforms (e.g., UAV) potentially improves video understanding in real-world applications with a small training dataset, while many vehicle monitoring approaches appear to understand single-time detection with a big training dataset. The purpose of real-time vehicle detection from oblique UAV images is to locate the vehicle on the time series UAV images by using semantic segmentation. Real-time vehicle detection is more difficult due to the variety of depth and scale vehicles in oblique view UAV images. Motivated by these facts, in this manuscript, we consider the problem of real-time vehicle detection for oblique UAV images based on a small training dataset and deep meta-learning. The proposed architecture, called SA-Net.v2, is a developed method based on the SA-CNN for real-time vehicle detection by reformulating the squeeze-and-attention mechanism. The SA-Net.v2 is composed of two components, including the squeeze-and-attention function that extracts the high-level feature based on a small training dataset, and the gated CNN. For the real-time vehicle detection scenario, we test our model on the UAVid dataset. UAVid is a time series oblique UAV images dataset consisting of 30 video sequences. We examine the proposed method's applicability for stand real-time vehicle detection in urban environments using time series UAV images. The experiments show that the SA-Net.v2 achieves promising performance in time series oblique UAV images.