 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Observability-aware online multi-lidar extrinsic calibration
Dec 19, 2022
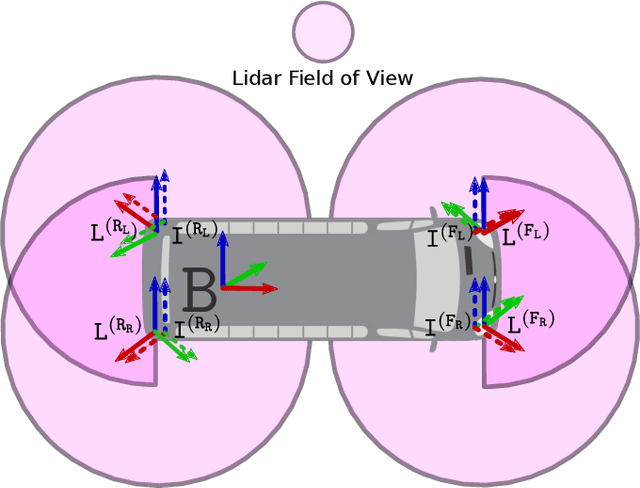

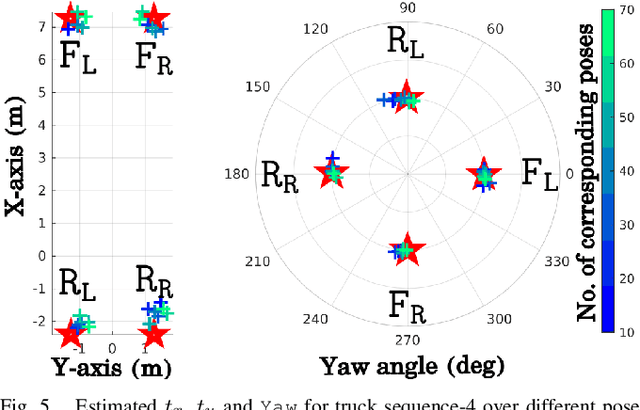

Accurate and robust extrinsic calibration is necessary for deploying autonomous systems which need multiple sensors for perception. In this paper, we present a robust system for real-time extrinsic calibration of multiple lidars in vehicle base frame without the need for any fiducial markers or features. We base our approach on matching absolute GNSS and estimated lidar poses in real-time. Comparing rotation components allows us to improve the robustness of the solution than traditional least-square approach comparing translation components only. Additionally, instead of comparing all corresponding poses, we select poses comprising maximum mutual information based on our novel observability criteria. This allows us to identify a subset of the poses helpful for real-time calibration. We also provide stopping criteria for ensuring calibration completion. To validate our approach extensive tests were carried out on data collected using Scania test vehicles (7 sequences for a total of ~ 6.5 Km). The results presented in this paper show that our approach is able to accurately determine the extrinsic calibration for various combinations of sensor setups.
Real-Time Video Deblurring via Lightweight Motion Compensation
Jun 08, 2022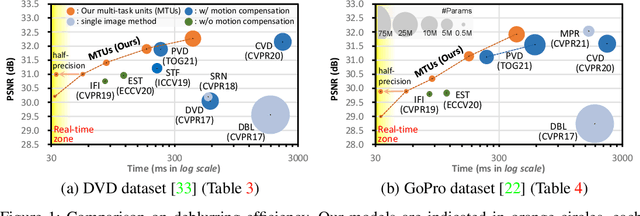

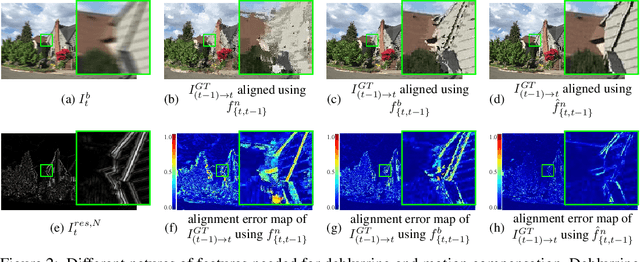
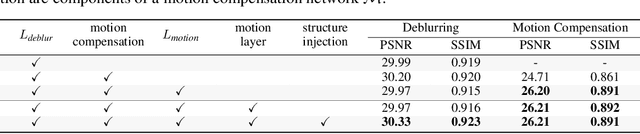
While motion compensation greatly improves video deblurring quality, separately performing motion compensation and video deblurring demands huge computational overhead. This paper proposes a real-time video deblurring framework consisting of a lightweight multi-task unit that supports both video deblurring and motion compensation in an efficient way. The multi-task unit is specifically designed to handle large portions of the two tasks using a single shared network, and consists of a multi-task detail network and simple networks for deblurring and motion compensation. The multi-task unit minimizes the cost of incorporating motion compensation into video deblurring and enables real-time deblurring. Moreover, by stacking multiple multi-task units, our framework provides flexible control between the cost and deblurring quality. We experimentally validate the state-of-the-art deblurring quality of our approach, which runs at a much faster speed compared to previous methods, and show practical real-time performance (30.99dB@30fps measured in the DVD dataset).
Earthformer: Exploring Space-Time Transformers for Earth System Forecasting
Jul 12, 2022
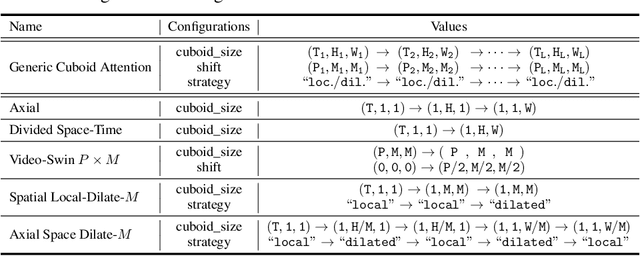
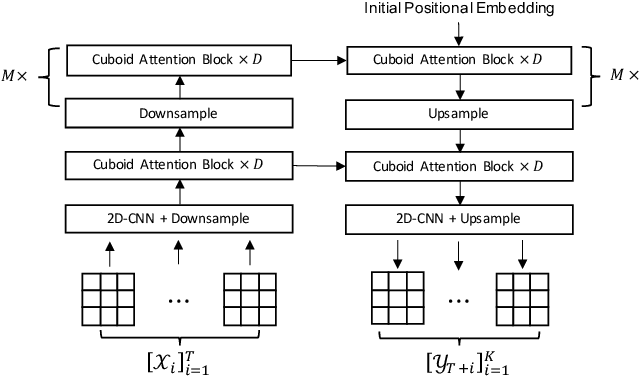
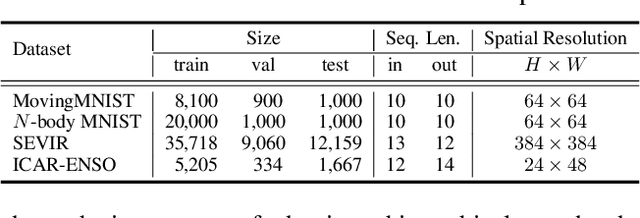
Conventionally, Earth system (e.g., weather and climate) forecasting relies on numerical simulation with complex physical models and are hence both expensive in computation and demanding on domain expertise. With the explosive growth of the spatiotemporal Earth observation data in the past decade, data-driven models that apply Deep Learning (DL) are demonstrating impressive potential for various Earth system forecasting tasks. The Transformer as an emerging DL architecture, despite its broad success in other domains, has limited adoption in this area. In this paper, we propose Earthformer, a space-time Transformer for Earth system forecasting. Earthformer is based on a generic, flexible and efficient space-time attention block, named Cuboid Attention. The idea is to decompose the data into cuboids and apply cuboid-level self-attention in parallel. These cuboids are further connected with a collection of global vectors. We conduct experiments on the MovingMNIST dataset and a newly proposed chaotic N-body MNIST dataset to verify the effectiveness of cuboid attention and figure out the best design of Earthformer. Experiments on two real-world benchmarks about precipitation nowcasting and El Nino/Southern Oscillation (ENSO) forecasting show Earthformer achieves state-of-the-art performance.
Location-aware green energy availability forecasting for multiple time frames in smart buildings: The case of Estonia
Oct 04, 2022
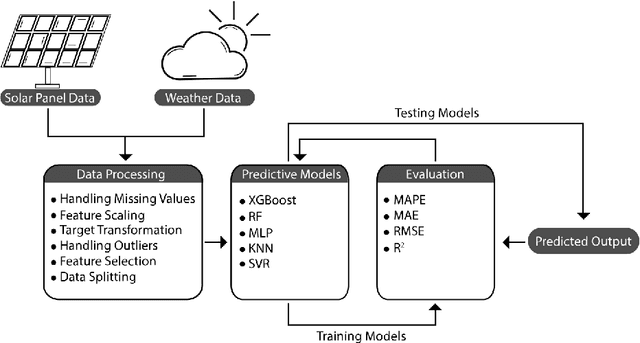
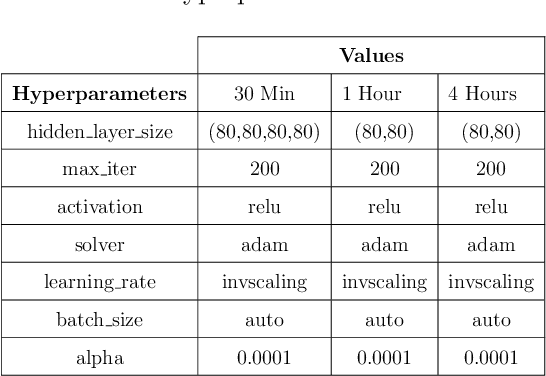
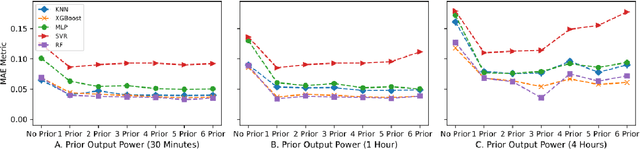
Renewable Energies (RE) have gained more attention in recent years since they offer clean and sustainable energy. One of the major sustainable development goals (SDG-7) set by the United Nations (UN) is to achieve affordable and clean energy for everyone. Among the world's all renewable resources, solar energy is considered as the most abundant and can certainly fulfill the target of SDGs. Solar energy is converted into electrical energy through Photovoltaic (PV) panels with no greenhouse gas emissions. However, power generated by PV panels is highly dependent on solar radiation received at a particular location over a given time period. Therefore, it is challenging to forecast the amount of PV output power. Predicting the output power of PV systems is essential since several public or private institutes generate such green energy, and need to maintain the balance between demand and supply. This research aims to forecast PV system output power based on weather and derived features using different machine learning models. The objective is to obtain the best-fitting model to precisely predict output power by inspecting the data. Moreover, different performance metrics are used to compare and evaluate the accuracy under different machine learning models such as random forest, XGBoost, KNN, etc.
Towards Understanding How Self-training Tolerates Data Backdoor Poisoning
Jan 20, 2023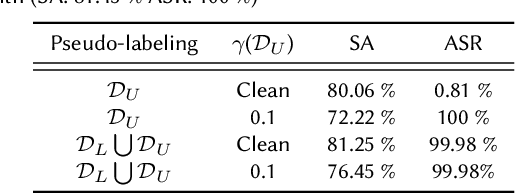
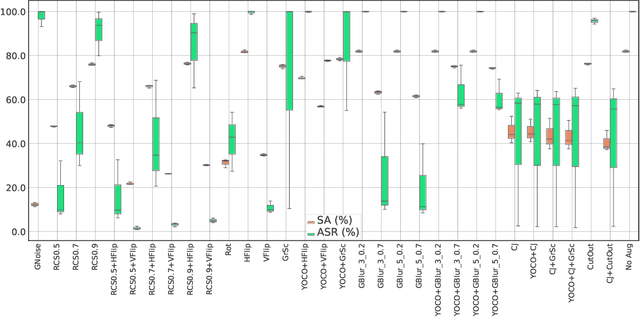
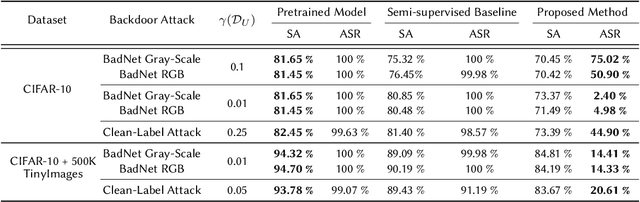
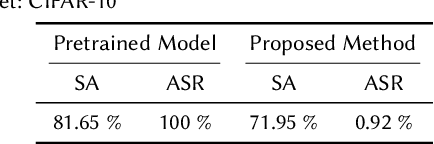
Recent studies on backdoor attacks in model training have shown that polluting a small portion of training data is sufficient to produce incorrect manipulated predictions on poisoned test-time data while maintaining high clean accuracy in downstream tasks. The stealthiness of backdoor attacks has imposed tremendous defense challenges in today's machine learning paradigm. In this paper, we explore the potential of self-training via additional unlabeled data for mitigating backdoor attacks. We begin by making a pilot study to show that vanilla self-training is not effective in backdoor mitigation. Spurred by that, we propose to defend the backdoor attacks by leveraging strong but proper data augmentations in the self-training pseudo-labeling stage. We find that the new self-training regime help in defending against backdoor attacks to a great extent. Its effectiveness is demonstrated through experiments for different backdoor triggers on CIFAR-10 and a combination of CIFAR-10 with an additional unlabeled 500K TinyImages dataset. Finally, we explore the direction of combining self-supervised representation learning with self-training for further improvement in backdoor defense.
Feature Relevance Analysis to Explain Concept Drift -- A Case Study in Human Activity Recognition
Jan 20, 2023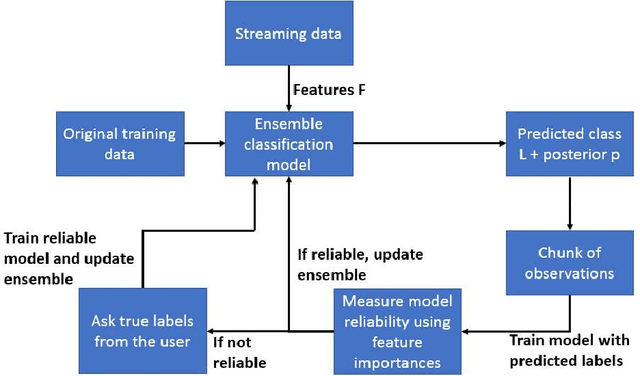
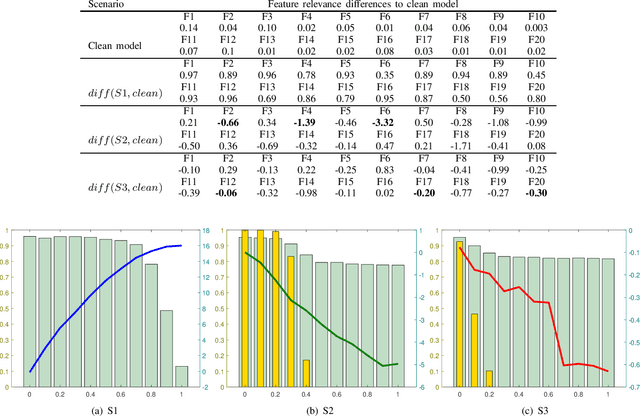
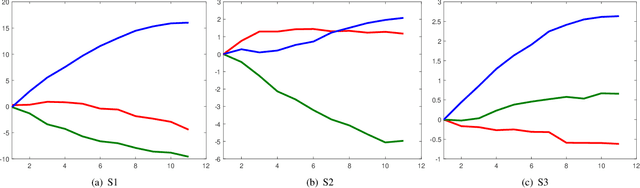

This article studies how to detect and explain concept drift. Human activity recognition is used as a case study together with a online batch learning situation where the quality of the labels used in the model updating process starts to decrease. Drift detection is based on identifying a set of features having the largest relevance difference between the drifting model and a model that is known to be accurate and monitoring how the relevance of these features changes over time. As a main result of this article, it is shown that feature relevance analysis cannot only be used to detect the concept drift but also to explain the reason for the drift when a limited number of typical reasons for the concept drift are predefined. To explain the reason for the concept drift, it is studied how these predefined reasons effect to feature relevance. In fact, it is shown that each of these has an unique effect to features relevance and these can be used to explain the reason for concept drift.
Traffic Prediction in Cellular Networks using Graph Neural Networks
Jan 30, 2023
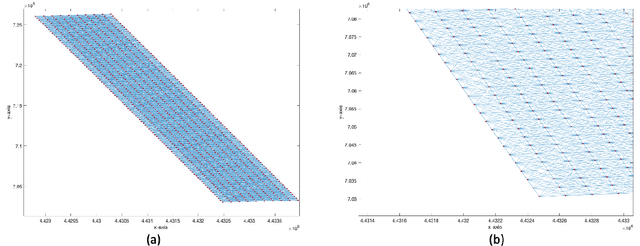
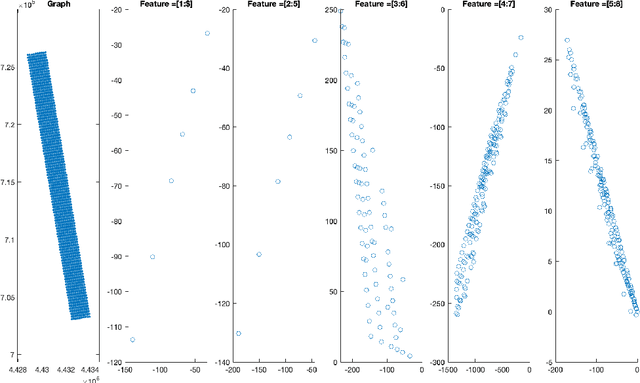
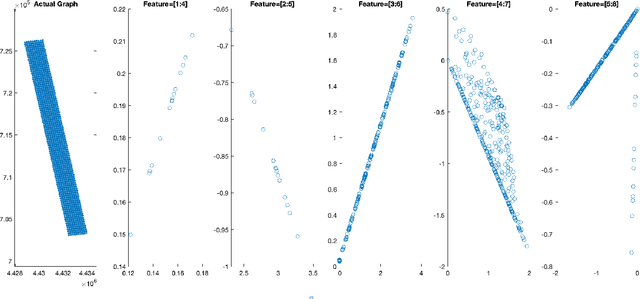
Cellular networks are ubiquitous entities that provide major means of communication all over the world. One major challenge in cellular networks is a dynamic change in the number of users and their usage of telecommunication service which results in overloading at certain base stations. One class of solution to deal with this overloading issue is the deployment of drones that can act as temporary base stations and offload the traffic from the overloaded base station. There are two main challenges in the development of this solution. Firstly, the drone is expected to be present around the base station where an overload would occur in the future thus requiring a prediction of traffic overload. Secondly, drones are highly constrained in their resources and can only fly for a few minutes. If the affected base station is really far, drones can never reach there. This requires the initial placement of drones in sectors where overloading can occur thus again requiring a traffic forecast but at a different spatial scale. It must be noted that the spatial extent of the region that the problem poses and the extremely limited power resources available to the drone pose a great challenge that is hard to overcome without deploying the drones in strategic positions to reduce the time to fly to the required high-demand zone. Moreover, since drone fly at a finite speed, it is important that a predictive solution that can forecast traffic surges is adopted so that drones are available to offload the overload before it actually happens. Both these goals require analysis and forecast of cellular network traffic which is the main goal of this project
Continuous-Time Modeling of Counterfactual Outcomes Using Neural Controlled Differential Equations
Jun 16, 2022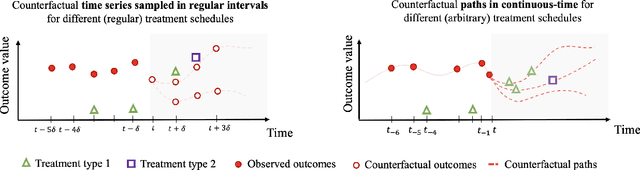

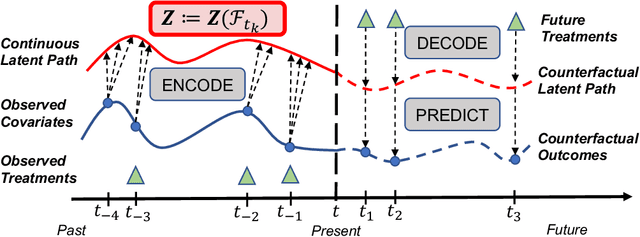
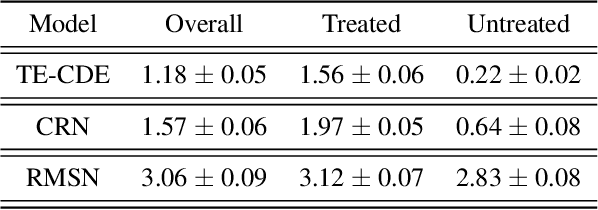
Estimating counterfactual outcomes over time has the potential to unlock personalized healthcare by assisting decision-makers to answer ''what-iF'' questions. Existing causal inference approaches typically consider regular, discrete-time intervals between observations and treatment decisions and hence are unable to naturally model irregularly sampled data, which is the common setting in practice. To handle arbitrary observation patterns, we interpret the data as samples from an underlying continuous-time process and propose to model its latent trajectory explicitly using the mathematics of controlled differential equations. This leads to a new approach, the Treatment Effect Neural Controlled Differential Equation (TE-CDE), that allows the potential outcomes to be evaluated at any time point. In addition, adversarial training is used to adjust for time-dependent confounding which is critical in longitudinal settings and is an added challenge not encountered in conventional time-series. To assess solutions to this problem, we propose a controllable simulation environment based on a model of tumor growth for a range of scenarios with irregular sampling reflective of a variety of clinical scenarios. TE-CDE consistently outperforms existing approaches in all simulated scenarios with irregular sampling.
Time Gated Convolutional Neural Networks for Crop Classification
Jun 20, 2022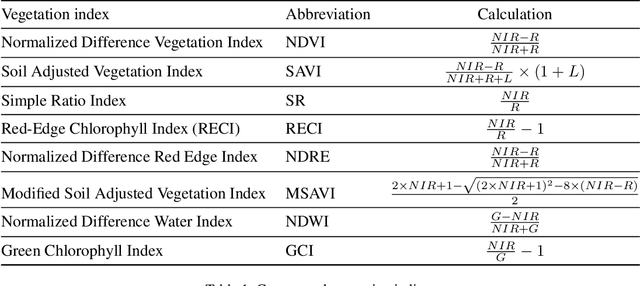
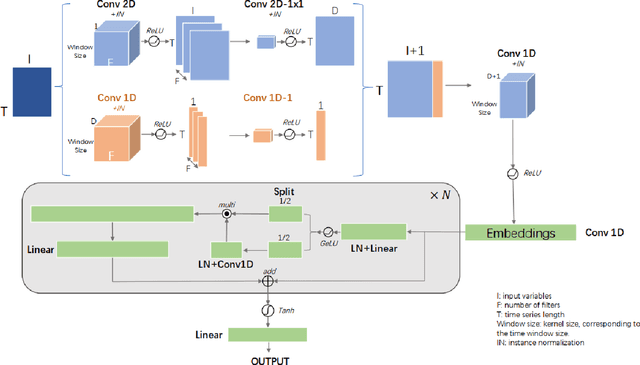
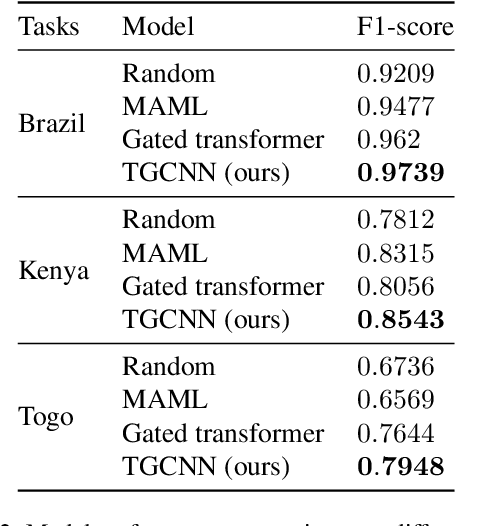
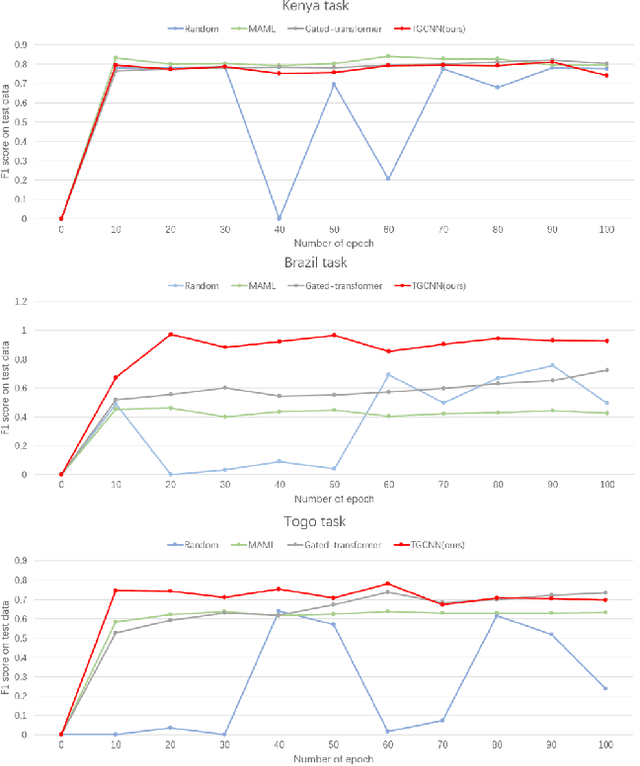
This paper presented a state-of-the-art framework, Time Gated Convolutional Neural Network (TGCNN) that takes advantage of temporal information and gating mechanisms for the crop classification problem. Besides, several vegetation indices were constructed to expand dimensions of input data to take advantage of spectral information. Both spatial (channel-wise) and temporal (step-wise) correlation are considered in TGCNN. Specifically, our preliminary analysis indicates that step-wise information is of greater importance in this data set. Lastly, the gating mechanism helps capture high-order relationship. Our TGCNN solution achieves $0.973$ F1 score, $0.977$ AUC ROC and $0.948$ IoU, respectively. In addition, it outperforms three other benchmarks in different local tasks (Kenya, Brazil and Togo). Overall, our experiments demonstrate that TGCNN is advantageous in this earth observation time series classification task.
A general framework for multi-step ahead adaptive conformal heteroscedastic time series forecasting
Jul 28, 2022
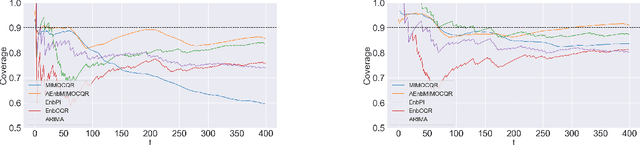

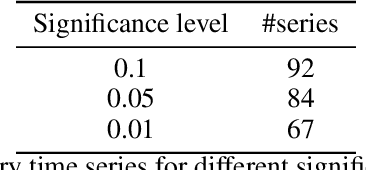
The exponential growth of machine learning (ML) has prompted a great deal of interest in quantifying the uncertainty of each prediction for a user-defined level of confidence. Reliable uncertainty quantification is crucial and is a step towards increased trust in AI results. It becomes especially important in high-stakes decision-making, where the true output must be within the confidence set with high probability. Conformal prediction (CP) is a distribution-free uncertainty quantification framework that works for any black-box model and yields prediction intervals (PIs) that are valid under the mild assumption of exchangeability. CP-type methods are gaining popularity due to being easy to implement and computationally cheap; however, the exchangeability assumption immediately excludes time series forecasting. Although recent papers tackle covariate shift, this is not enough for the general time series forecasting problem of producing H-step ahead valid PIs. To attain such a goal, we propose a new method called AEnbMIMOCQR (Adaptive ensemble batch multiinput multi-output conformalized quantile regression), which produces asymptotic valid PIs and is appropriate for heteroscedastic time series. We compare the proposed method against state-of-the-art competitive methods in the NN5 forecasting competition dataset. All the code and data to reproduce the experiments are made available