 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On Dynamic Regret and Constraint Violations in Constrained Online Convex Optimization
Jan 24, 2023
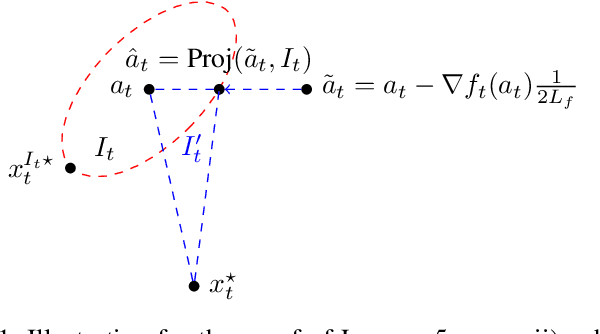
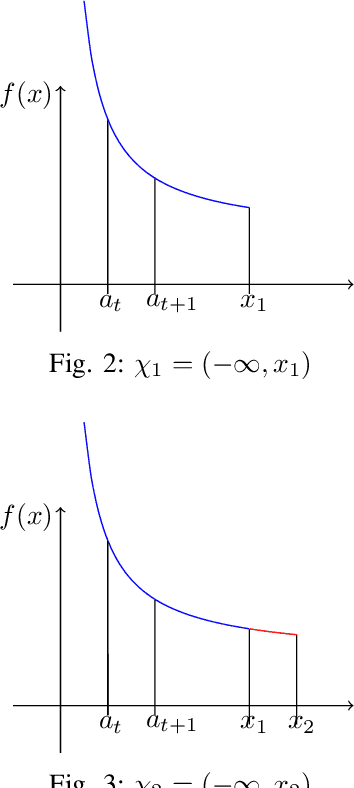
A constrained version of the online convex optimization (OCO) problem is considered. With slotted time, for each slot, first an action is chosen. Subsequently the loss function and the constraint violation penalty evaluated at the chosen action point is revealed. For each slot, both the loss function as well as the function defining the constraint set is assumed to be smooth and strongly convex. In addition, once an action is chosen, local information about a feasible set within a small neighborhood of the current action is also revealed. An algorithm is allowed to compute at most one gradient at its point of choice given the described feedback to choose the next action. The goal of an algorithm is to simultaneously minimize the dynamic regret (loss incurred compared to the oracle's loss) and the constraint violation penalty (penalty accrued compared to the oracle's penalty). We propose an algorithm that follows projected gradient descent over a suitably chosen set around the current action. We show that both the dynamic regret and the constraint violation is order-wise bounded by the {\it path-length}, the sum of the distances between the consecutive optimal actions. Moreover, we show that the derived bounds are the best possible.
Implementation of the Critical Wave Groups Method with Computational Fluid Dynamics and Neural Networks
Jan 24, 2023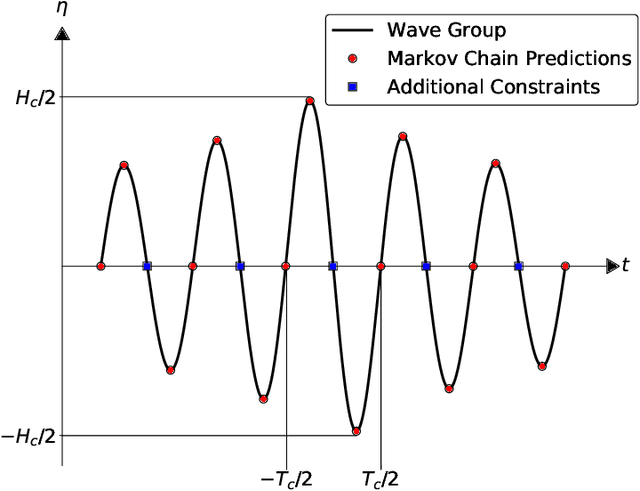

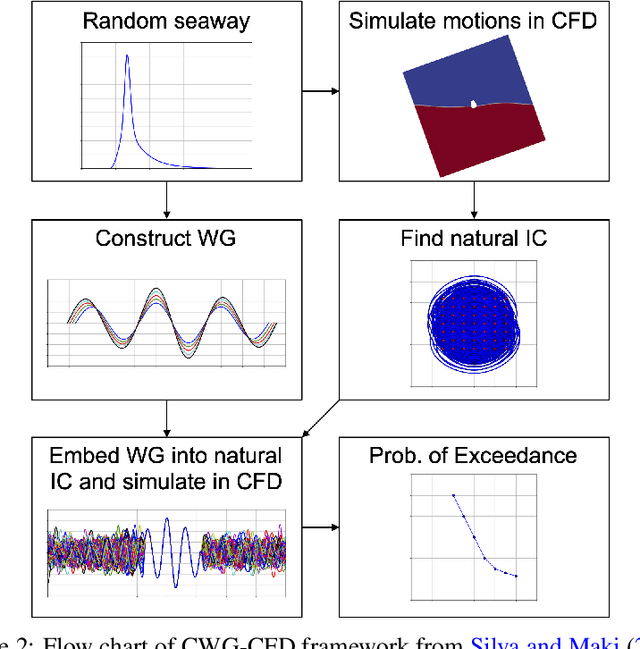

Accurate and efficient prediction of extreme ship responses continues to be a challenging problem in ship hydrodynamics. Probabilistic frameworks in conjunction with computationally efficient numerical hydrodynamic tools have been developed that allow researchers and designers to better understand extremes. However, the ability of these hydrodynamic tools to represent the physics quantitatively during extreme events is limited. Previous research successfully implemented the critical wave groups (CWG) probabilistic method with computational fluid dynamics (CFD). Although the CWG method allows for less simulation time than a Monte Carlo approach, the large quantity of simulations required is cost prohibitive. The objective of the present paper is to reduce the computational cost of implementing CWG with CFD, through the construction of long short-term memory (LSTM) neural networks. After training the models with a limited quantity of simulations, the models can provide a larger quantity of predictions to calculate the probability. The new framework is demonstrated with a 2-D midship section of the Office of Naval Research Tumblehome (ONRT) hull in Sea State 7 and beam seas at zero speed. The new framework is able to produce predictions that are representative of a purely CFD-driven CWG framework, with two orders of magnitude of computational cost savings.
Probabilistic Bilevel Coreset Selection
Jan 24, 2023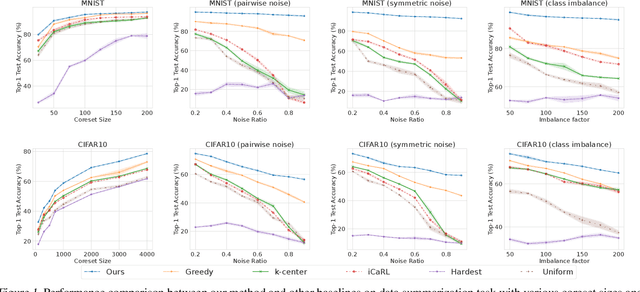
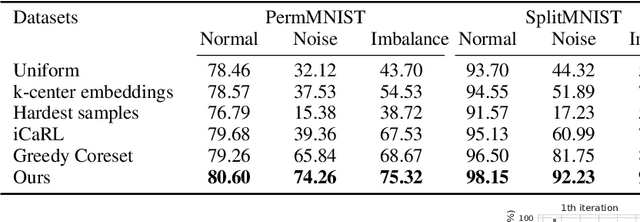
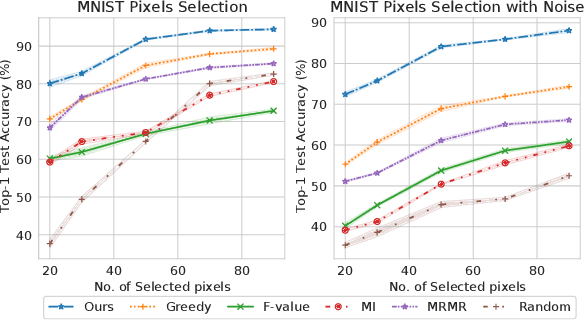
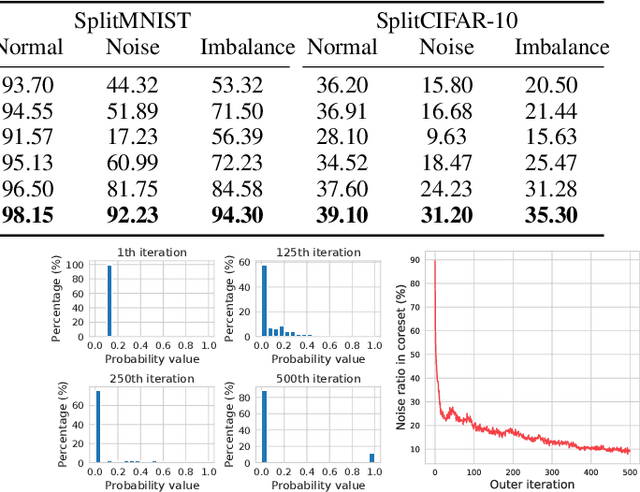
The goal of coreset selection in supervised learning is to produce a weighted subset of data, so that training only on the subset achieves similar performance as training on the entire dataset. Existing methods achieved promising results in resource-constrained scenarios such as continual learning and streaming. However, most of the existing algorithms are limited to traditional machine learning models. A few algorithms that can handle large models adopt greedy search approaches due to the difficulty in solving the discrete subset selection problem, which is computationally costly when coreset becomes larger and often produces suboptimal results. In this work, for the first time we propose a continuous probabilistic bilevel formulation of coreset selection by learning a probablistic weight for each training sample. The overall objective is posed as a bilevel optimization problem, where 1) the inner loop samples coresets and train the model to convergence and 2) the outer loop updates the sample probability progressively according to the model's performance. Importantly, we develop an efficient solver to the bilevel optimization problem via unbiased policy gradient without trouble of implicit differentiation. We provide the convergence property of our training procedure and demonstrate the superiority of our algorithm against various coreset selection methods in various tasks, especially in more challenging label-noise and class-imbalance scenarios.
Traffic Prediction in Cellular Networks using Graph Neural Networks
Jan 30, 2023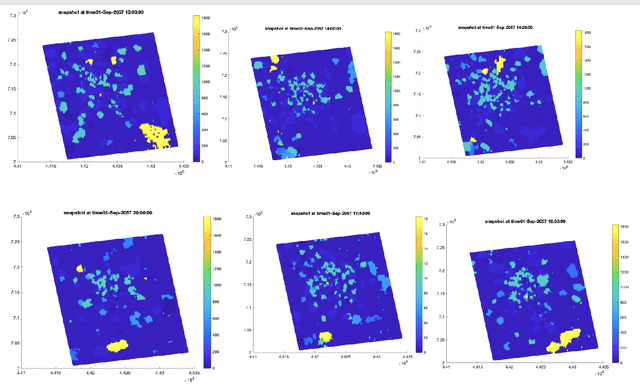
Cellular networks are ubiquitous entities that provide major means of communication all over the world. One major challenge in cellular networks is a dynamic change in the number of users and their usage of telecommunication service which results in overloading at certain base stations. One class of solution to deal with this overloading issue is the deployment of drones that can act as temporary base stations and offload the traffic from the overloaded base station. There are two main challenges in the development of this solution. Firstly, the drone is expected to be present around the base station where an overload would occur in the future thus requiring a prediction of traffic overload. Secondly, drones are highly constrained in their resources and can only fly for a few minutes. If the affected base station is really far, drones can never reach there. This requires the initial placement of drones in sectors where overloading can occur thus again requiring a traffic forecast but at a different spatial scale. It must be noted that the spatial extent of the region that the problem poses and the extremely limited power resources available to the drone pose a great challenge that is hard to overcome without deploying the drones in strategic positions to reduce the time to fly to the required high-demand zone. Moreover, since drone fly at a finite speed, it is important that a predictive solution that can forecast traffic surges is adopted so that drones are available to offload the overload before it actually happens. Both these goals require analysis and forecast of cellular network traffic which is the main goal of this project
Robust Knowledge Adaptation for Federated Unsupervised Person ReID
Jan 18, 2023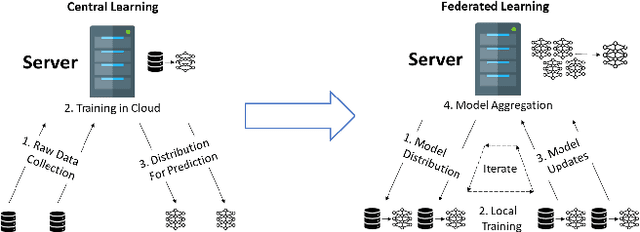
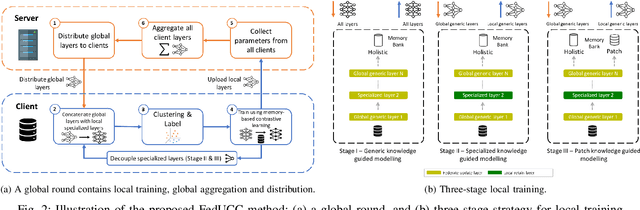

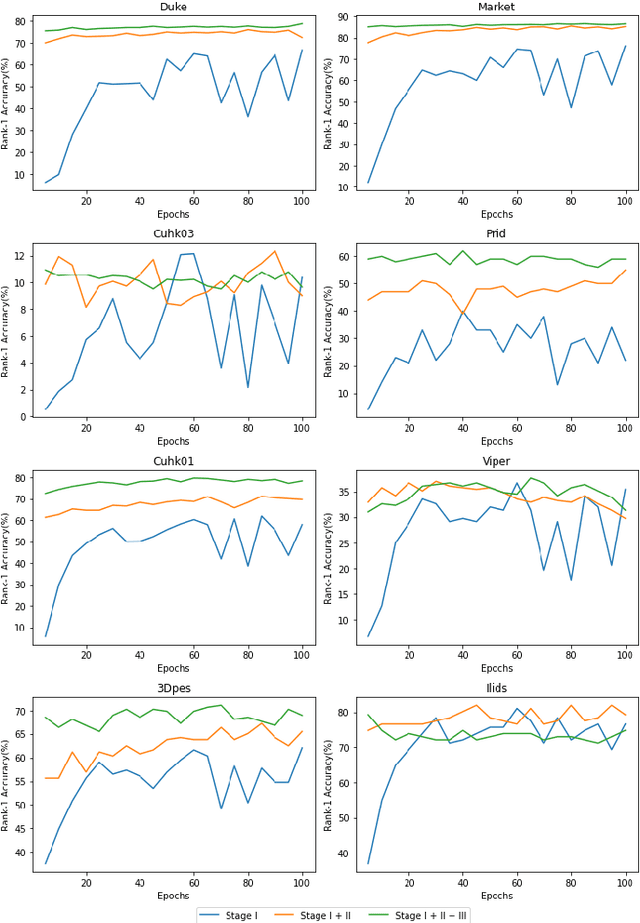
Person Re-identification (ReID) has been extensively studied in recent years due to the increasing demand in public security. However, collecting and dealing with sensitive personal data raises privacy concerns. Therefore, federated learning has been explored for Person ReID, which aims to share minimal sensitive data between different parties (clients). However, existing federated learning based person ReID methods generally rely on laborious and time-consuming data annotations and it is difficult to guarantee cross-domain consistency. Thus, in this work, a federated unsupervised cluster-contrastive (FedUCC) learning method is proposed for Person ReID. FedUCC introduces a three-stage modelling strategy following a coarse-to-fine manner. In detail, generic knowledge, specialized knowledge and patch knowledge are discovered using a deep neural network. This enables the sharing of mutual knowledge among clients while retaining local domain-specific knowledge based on the kinds of network layers and their parameters. Comprehensive experiments on 8 public benchmark datasets demonstrate the state-of-the-art performance of our proposed method.
A Sublinear-Time Quantum Algorithm for Approximating Partition Functions
Jul 18, 2022

We present a novel quantum algorithm for estimating Gibbs partition functions in sublinear time with respect to the logarithm of the size of the state space. This is the first speed-up of this type to be obtained over the seminal nearly-linear time algorithm of \v{S}tefankovi\v{c}, Vempala and Vigoda [JACM, 2009]. Our result also preserves the quadratic speed-up in precision and spectral gap achieved in previous work by exploiting the properties of quantum Markov chains. As an application, we obtain new polynomial improvements over the best-known algorithms for computing the partition function of the Ising model, and counting the number of $k$-colorings, matchings or independent sets of a graph. Our approach relies on developing new variants of the quantum phase and amplitude estimation algorithms that return nearly unbiased estimates with low variance and without destroying their initial quantum state. We extend these subroutines into a nearly unbiased quantum mean estimator that reduces the variance quadratically faster than the classical empirical mean. No such estimator was known to exist prior to our work. These properties, which are of general interest, lead to better convergence guarantees within the paradigm of simulated annealing for computing partition functions.
Using the profile of publishers to predict barriers across news articles
Jan 13, 2023


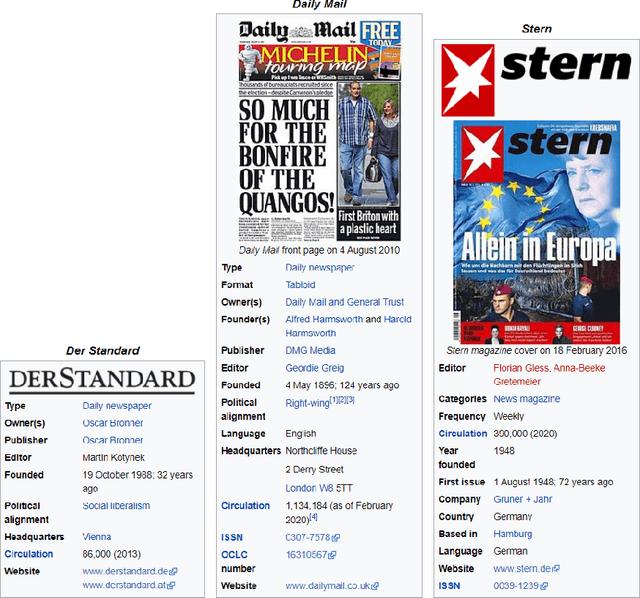
Detection of news propagation barriers, being economical, cultural, political, time zonal, or geographical, is still an open research issue. We present an approach to barrier detection in news spreading by utilizing Wikipedia-concepts and metadata associated with each barrier. Solving this problem can not only convey the information about the coverage of an event but it can also show whether an event has been able to cross a specific barrier or not. Experimental results on IPoNews dataset (dataset for information spreading over the news) reveals that simple classification models are able to detect barriers with high accuracy. We believe that our approach can serve to provide useful insights which pave the way for the future development of a system for predicting information spreading barriers over the news.
Almost Surely $\sqrt{T}$ Regret Bound for Adaptive LQR
Jan 13, 2023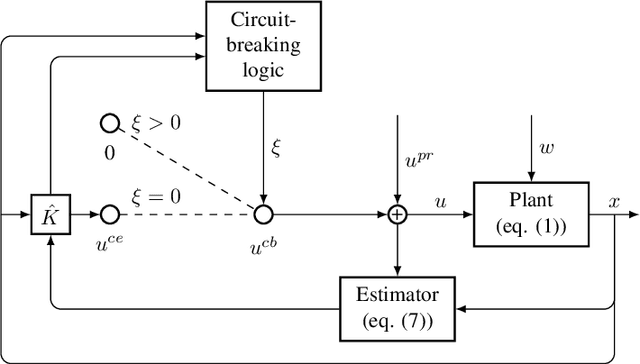
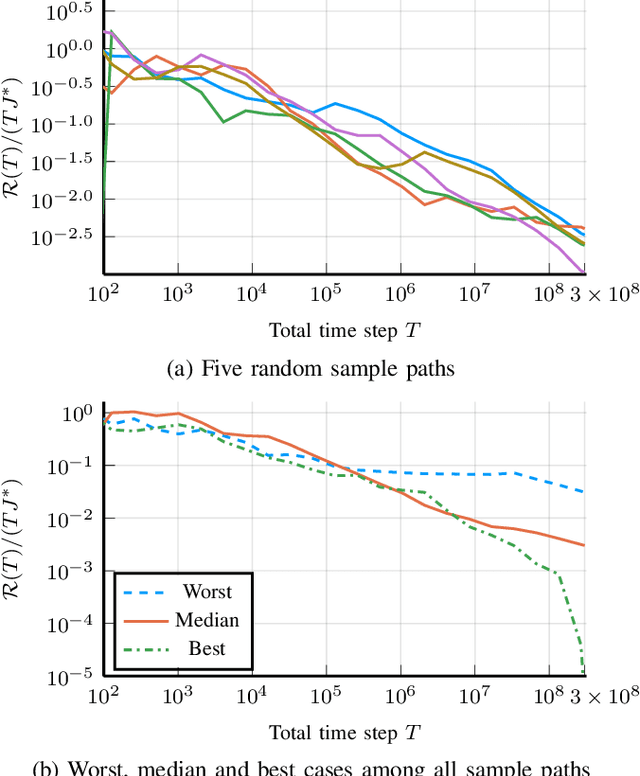
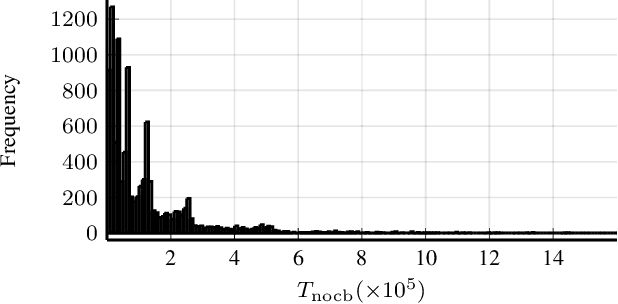

The Linear-Quadratic Regulation (LQR) problem with unknown system parameters has been widely studied, but it has remained unclear whether $\tilde{ \mathcal{O}}(\sqrt{T})$ regret, which is the best known dependence on time, can be achieved almost surely. In this paper, we propose an adaptive LQR controller with almost surely $\tilde{ \mathcal{O}}(\sqrt{T})$ regret upper bound. The controller features a circuit-breaking mechanism, which circumvents potential safety breach and guarantees the convergence of the system parameter estimate, but is shown to be triggered only finitely often and hence has negligible effect on the asymptotic performance of the controller. The proposed controller is also validated via simulation on Tennessee Eastman Process~(TEP), a commonly used industrial process example.
Prompting Neural Machine Translation with Translation Memories
Jan 13, 2023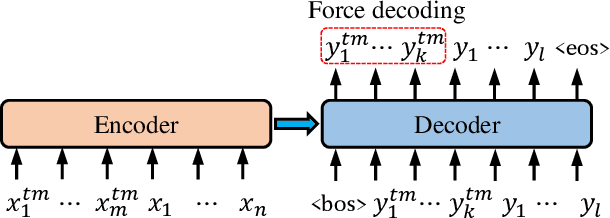

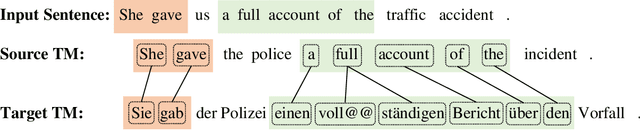
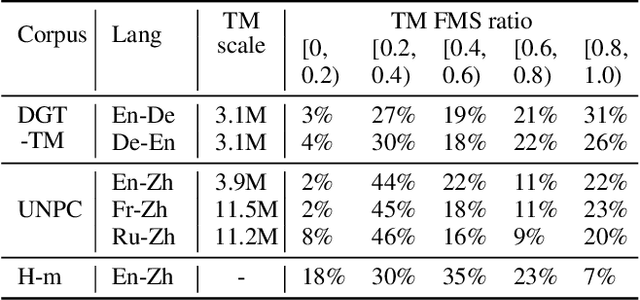
Improving machine translation (MT) systems with translation memories (TMs) is of great interest to practitioners in the MT community. However, previous approaches require either a significant update of the model architecture and/or additional training efforts to make the models well-behaved when TMs are taken as additional input. In this paper, we present a simple but effective method to introduce TMs into neural machine translation (NMT) systems. Specifically, we treat TMs as prompts to the NMT model at test time, but leave the training process unchanged. The result is a slight update of an existing NMT system, which can be implemented in a few hours by anyone who is familiar with NMT. Experimental results on several datasets demonstrate that our system significantly outperforms strong baselines.
Towards Understanding How Self-training Tolerates Data Backdoor Poisoning
Jan 20, 2023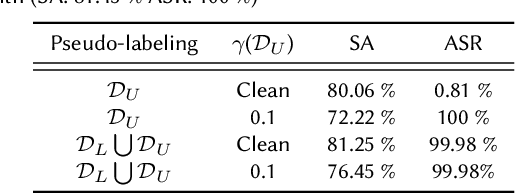
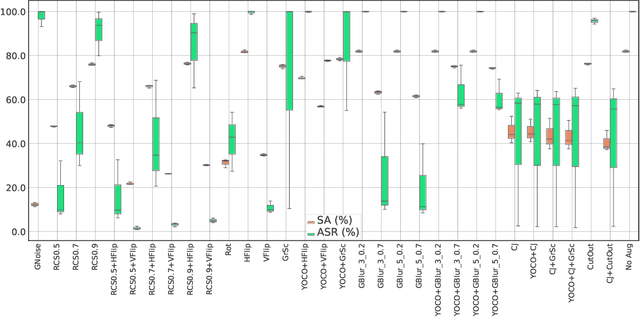
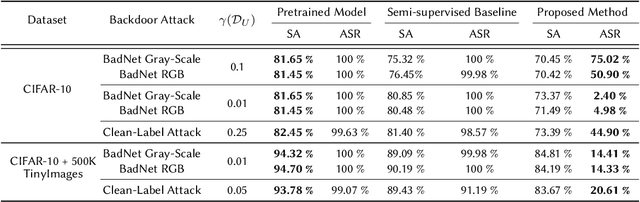
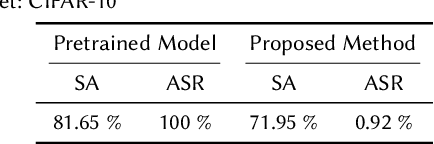
Recent studies on backdoor attacks in model training have shown that polluting a small portion of training data is sufficient to produce incorrect manipulated predictions on poisoned test-time data while maintaining high clean accuracy in downstream tasks. The stealthiness of backdoor attacks has imposed tremendous defense challenges in today's machine learning paradigm. In this paper, we explore the potential of self-training via additional unlabeled data for mitigating backdoor attacks. We begin by making a pilot study to show that vanilla self-training is not effective in backdoor mitigation. Spurred by that, we propose to defend the backdoor attacks by leveraging strong but proper data augmentations in the self-training pseudo-labeling stage. We find that the new self-training regime help in defending against backdoor attacks to a great extent. Its effectiveness is demonstrated through experiments for different backdoor triggers on CIFAR-10 and a combination of CIFAR-10 with an additional unlabeled 500K TinyImages dataset. Finally, we explore the direction of combining self-supervised representation learning with self-training for further improvement in backdoor defense.