 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Clustering Survival Machines with Interpretable Expert Distributions
Jan 27, 2023
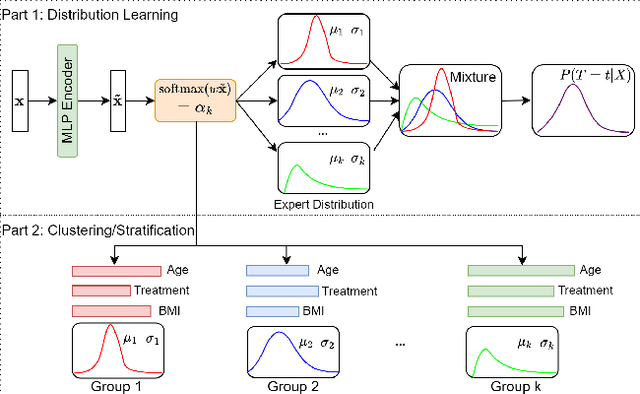
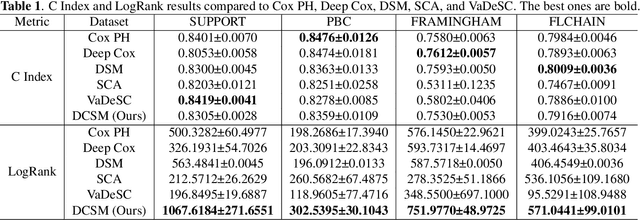
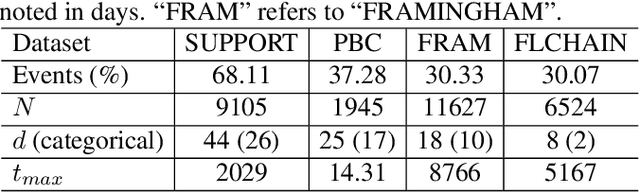
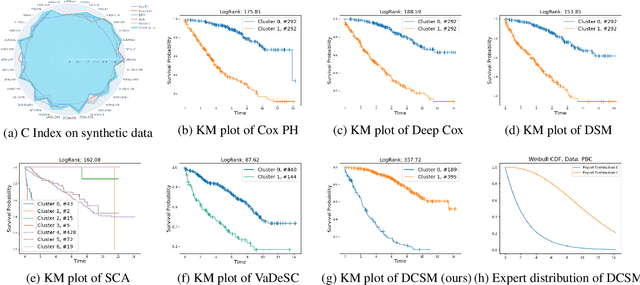
Conventional survival analysis methods are typically ineffective to characterize heterogeneity in the population while such information can be used to assist predictive modeling. In this study, we propose a hybrid survival analysis method, referred to as deep clustering survival machines, that combines the discriminative and generative mechanisms. Similar to the mixture models, we assume that the timing information of survival data is generatively described by a mixture of certain numbers of parametric distributions, i.e., expert distributions. We learn weights of the expert distributions for individual instances according to their features discriminatively such that each instance's survival information can be characterized by a weighted combination of the learned constant expert distributions. This method also facilitates interpretable subgrouping/clustering of all instances according to their associated expert distributions. Extensive experiments on both real and synthetic datasets have demonstrated that the method is capable of obtaining promising clustering results and competitive time-to-event predicting performance.
Solving Constrained Reinforcement Learning through Augmented State and Reward Penalties
Jan 27, 2023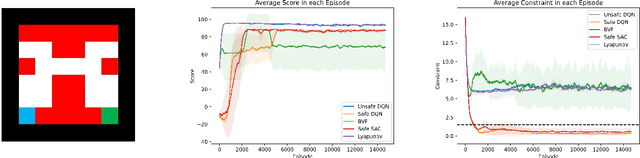
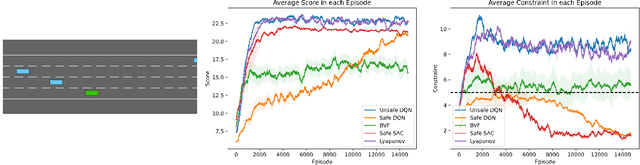
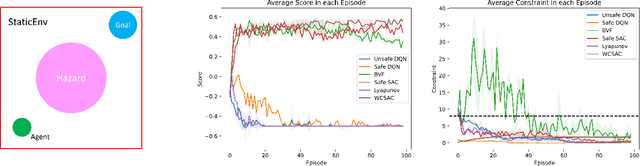
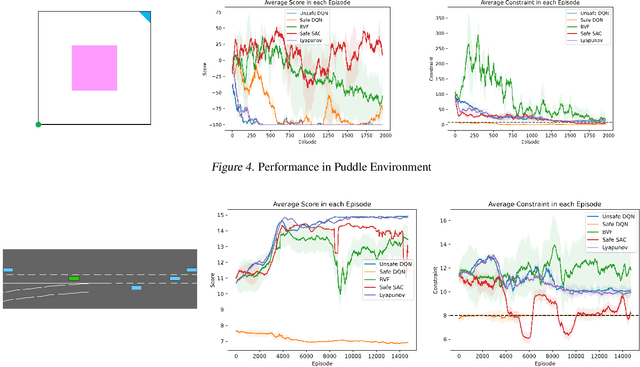
Constrained Reinforcement Learning has been employed to enforce safety constraints on policy through the use of expected cost constraints. The key challenge is in handling expected cost accumulated using the policy and not just in a single step. Existing methods have developed innovative ways of converting this cost constraint over entire policy to constraints over local decisions (at each time step). While such approaches have provided good solutions with regards to objective, they can either be overly aggressive or conservative with respect to costs. This is owing to use of estimates for "future" or "backward" costs in local cost constraints. To that end, we provide an equivalent unconstrained formulation to constrained RL that has an augmented state space and reward penalties. This intuitive formulation is general and has interesting theoretical properties. More importantly, this provides a new paradigm for solving constrained RL problems effectively. As we show in our experimental results, we are able to outperform leading approaches on multiple benchmark problems from literature.
Fast Region of Interest Proposals on Maritime UAVs
Jan 27, 2023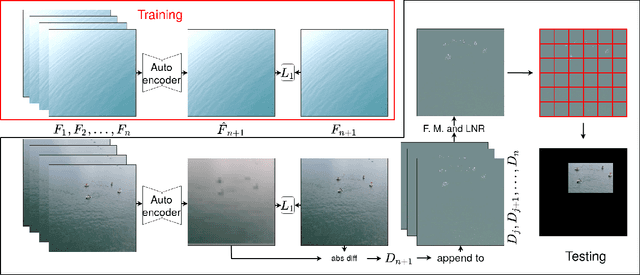

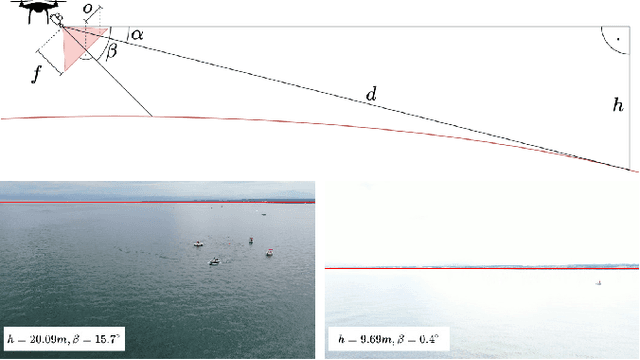
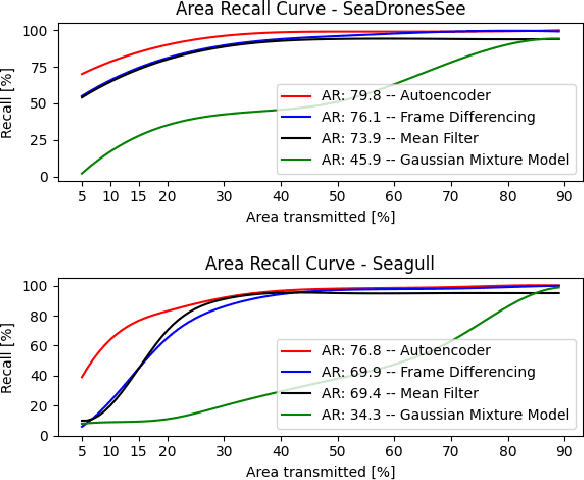
Unmanned aerial vehicles assist in maritime search and rescue missions by flying over large search areas to autonomously search for objects or people. Reliably detecting objects of interest requires fast models to employ on embedded hardware. Moreover, with increasing distance to the ground station only part of the video data can be transmitted. In this work, we consider the problem of finding meaningful region of interest proposals in a video stream on an embedded GPU. Current object or anomaly detectors are not suitable due to their slow speed, especially on limited hardware and for large image resolutions. Lastly, objects of interest, such as pieces of wreckage, are often not known a priori. Therefore, we propose an end-to-end future frame prediction model running in real-time on embedded GPUs to generate region proposals. We analyze its performance on large-scale maritime data sets and demonstrate its benefits over traditional and modern methods.
A critical look at deep neural network for dynamic system modeling
Jan 27, 2023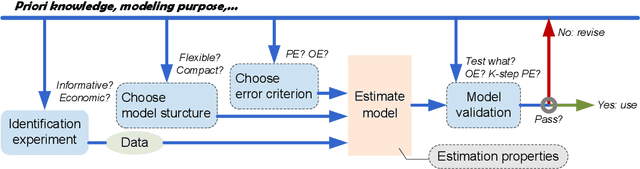
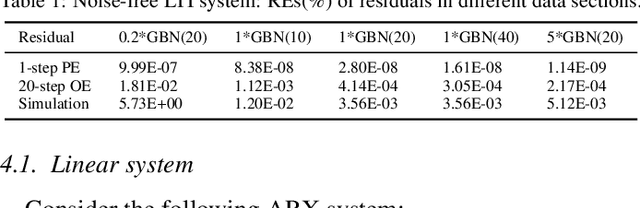
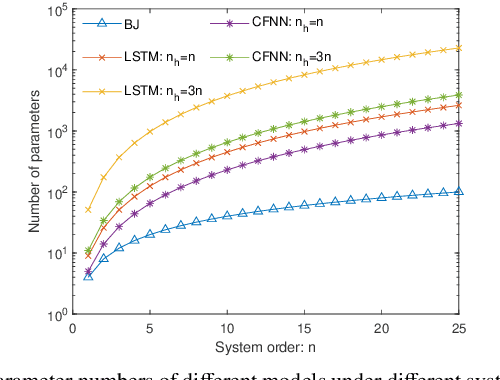
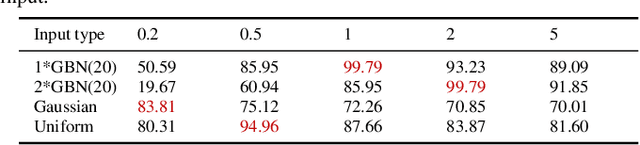
Neural network models become increasingly popular as dynamic modeling tools in the control community. They have many appealing features including nonlinear structures, being able to approximate any functions. While most researchers hold optimistic attitudes towards such models, this paper questions the capability of (deep) neural networks for the modeling of dynamic systems using input-output data. For the identification of linear time-invariant (LTI) dynamic systems, two representative neural network models, Long Short-Term Memory (LSTM) and Cascade Foward Neural Network (CFNN) are compared to the standard Prediction Error Method (PEM) of system identification. In the comparison, four essential aspects of system identification are considered, then several possible defects and neglected issues of neural network based modeling are pointed out. Detailed simulation studies are performed to verify these defects: for the LTI system, both LSTM and CFNN fail to deliver consistent models even in noise-free cases; and they give worse results than PEM in noisy cases.
PECAN: A Deterministic Certified Defense Against Backdoor Attacks
Jan 27, 2023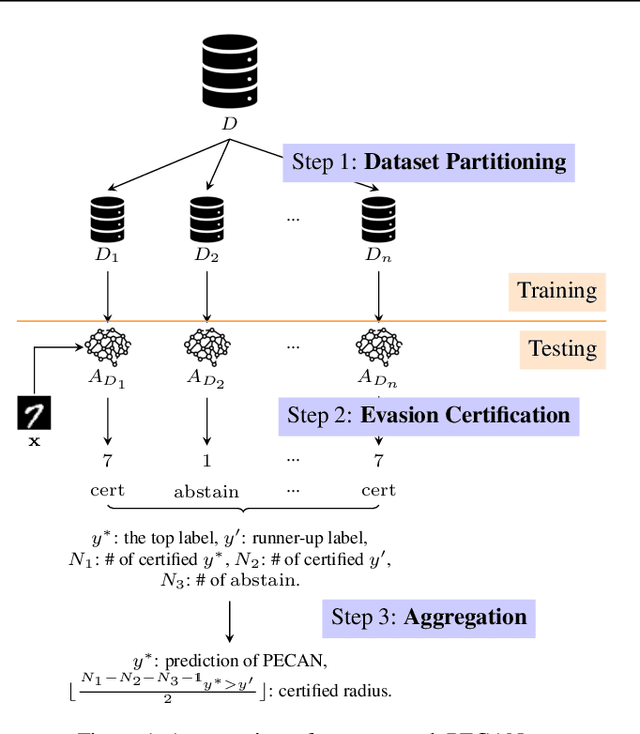
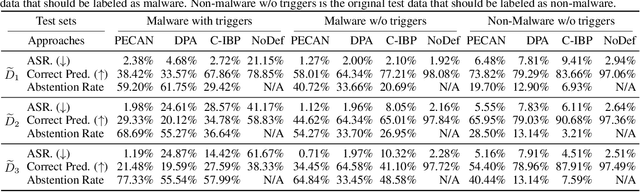
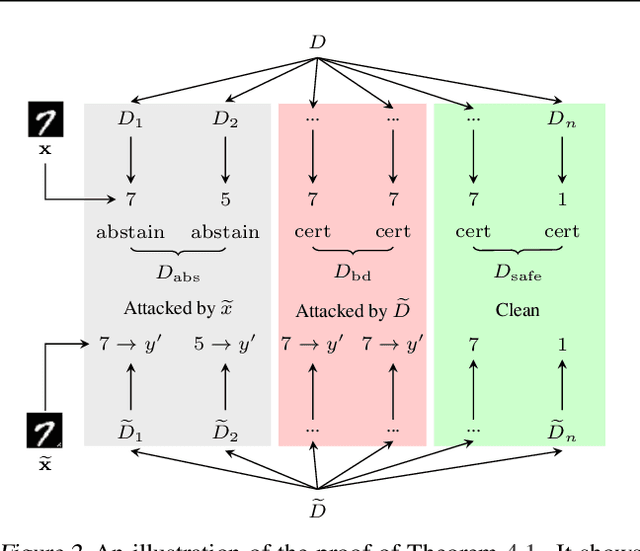
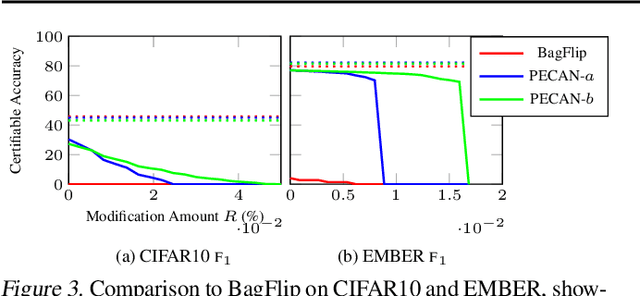
Neural networks are vulnerable to backdoor poisoning attacks, where the attackers maliciously poison the training set and insert triggers into the test input to change the prediction of the victim model. Existing defenses for backdoor attacks either provide no formal guarantees or come with expensive-to-compute and ineffective probabilistic guarantees. We present PECAN, an efficient and certified approach for defending against backdoor attacks. The key insight powering PECAN is to apply off-the-shelf test-time evasion certification techniques on a set of neural networks trained on disjoint partitions of the data. We evaluate PECAN on image classification and malware detection datasets. Our results demonstrate that PECAN can (1) significantly outperform the state-of-the-art certified backdoor defense, both in defense strength and efficiency, and (2) on real back-door attacks, PECAN can reduce attack success rate by order of magnitude when compared to a range of baselines from the literature.
Practical Frequency-Hopping MIMO Joint Radar Communications: Design and Experiment
Jan 27, 2023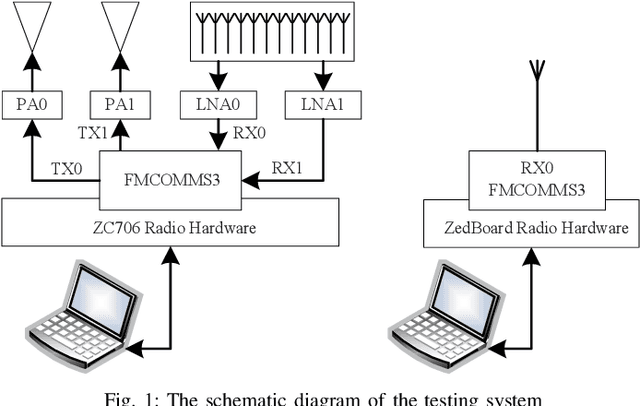
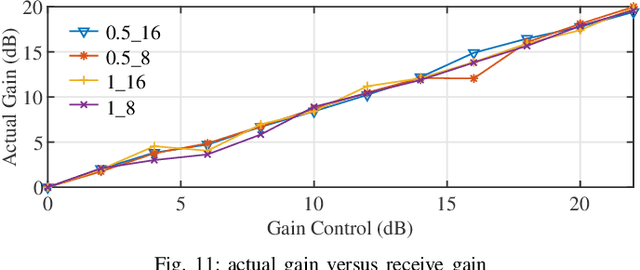
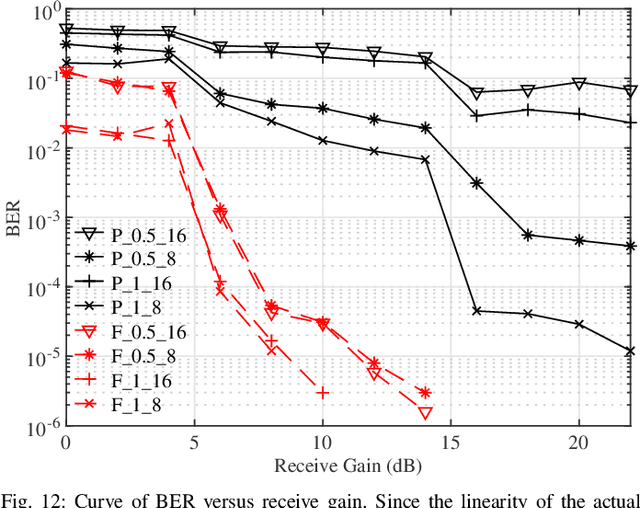
Joint radar and communications (JRC) can realize two radio frequency (RF) functions using one set of resources, greatly saving hardware, energy and spectrum for wireless systems needing both functions. Frequency-hopping (FH) MIMO radar is a popular candidate for JRC, as the achieved communication symbol rate can greatly exceed radar pulse repetition frequency. However, practical transceiver imperfections can fail many existing theoretical designs. In this work, we unveil for the first time the non-trivial impact of hardware imperfections on FH-MIMO JRC and analytically model the impact. We also design new waveforms and, accordingly, develop a low-complexity algorithm to jointly estimate the hardware imperfections of unsynchronized receiver. Moreover, employing low-cost software-defined radios and commercial off-the-shelf (COTS) products, we build the first FH-MIMO JRC experiment platform with radar and communications simultaneously validated over the air. Corroborated by simulation and experiment results, the proposed designs achieves high performances for both radar and communications.
Transfer Learning and Class Decomposition for Detecting the Cognitive Decline of Alzheimer Disease
Jan 31, 2023

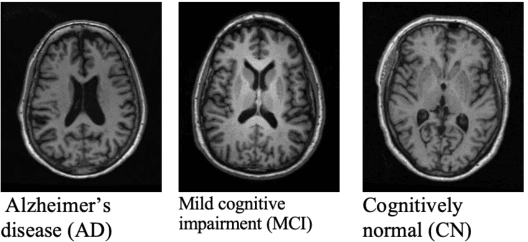
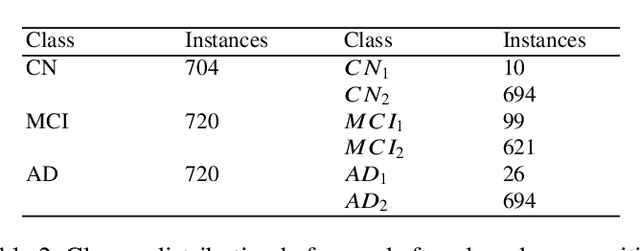
Early diagnosis of Alzheimer's disease (AD) is essential in preventing the disease's progression. Therefore, detecting AD from neuroimaging data such as structural magnetic resonance imaging (sMRI) has been a topic of intense investigation in recent years. Deep learning has gained considerable attention in Alzheimer's detection. However, training a convolutional neural network from scratch is challenging since it demands more computational time and a significant amount of annotated data. By transferring knowledge learned from other image recognition tasks to medical image classification, transfer learning can provide a promising and effective solution. Irregularities in the dataset distribution present another difficulty. Class decomposition can tackle this issue by simplifying learning a dataset's class boundaries. Motivated by these approaches, this paper proposes a transfer learning method using class decomposition to detect Alzheimer's disease from sMRI images. We use two ImageNet-trained architectures: VGG19 and ResNet50, and an entropy-based technique to determine the most informative images. The proposed model achieved state-of-the-art performance in the Alzheimer's disease (AD) vs mild cognitive impairment (MCI) vs cognitively normal (CN) classification task with a 3\% increase in accuracy from what is reported in the literature.
Improved Algorithms for Multi-period Multi-class Packing Problems with~Bandit~Feedback
Jan 31, 2023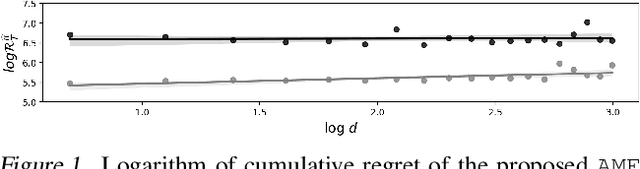
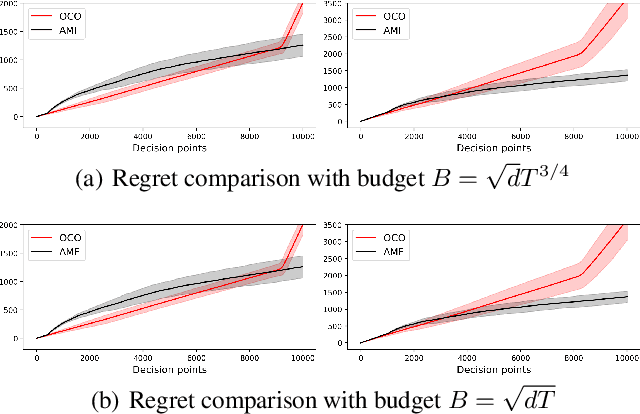
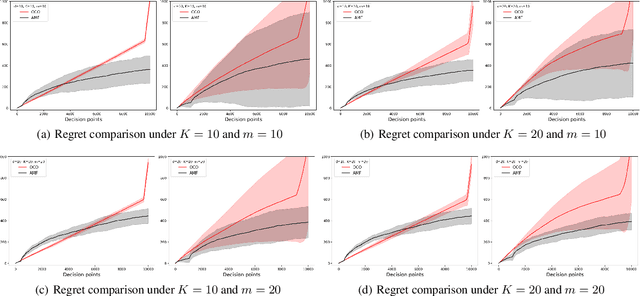
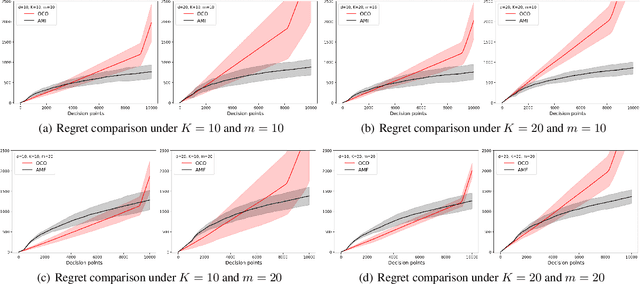
We consider the linear contextual multi-class multi-period packing problem~(LMMP) where the goal is to pack items such that the total vector of consumption is below a given budget vector and the total value is as large as possible. We consider the setting where the reward and the consumption vector associated with each action is a class-dependent linear function of the context, and the decision-maker receives bandit feedback. LMMP includes linear contextual bandits with knapsacks and online revenue management as special cases. We establish a new more efficient estimator which guarantees a faster convergence rate, and consequently, a lower regret in such problems. We propose a bandit policy that is a closed-form function of said estimated parameters. When the contexts are non-degenerate, the regret of the proposed policy is sublinear in the context dimension, the number of classes, and the time horizon~$T$ when the budget grows at least as $\sqrt{T}$. We also resolve an open problem posed in Agrawal & Devanur (2016), and extend the result to a multi-class setting. Our numerical experiments clearly demonstrate that the performance of our policy is superior to other benchmarks in the literature.
Dynamic Scheduled Sampling with Imitation Loss for Neural Text Generation
Jan 31, 2023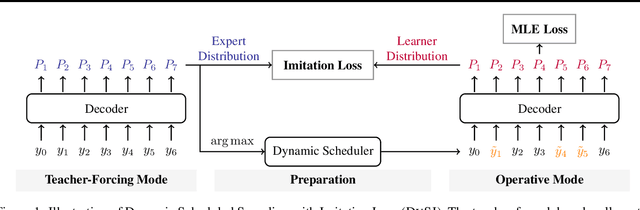
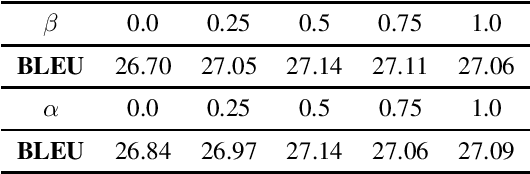
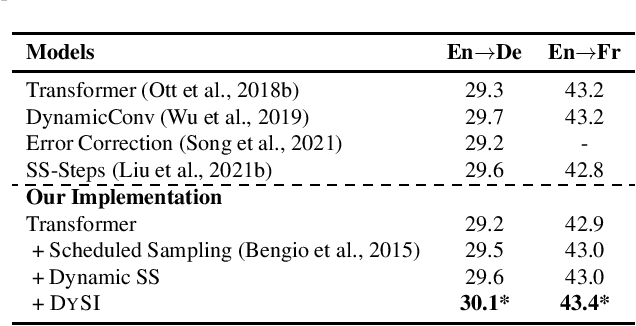
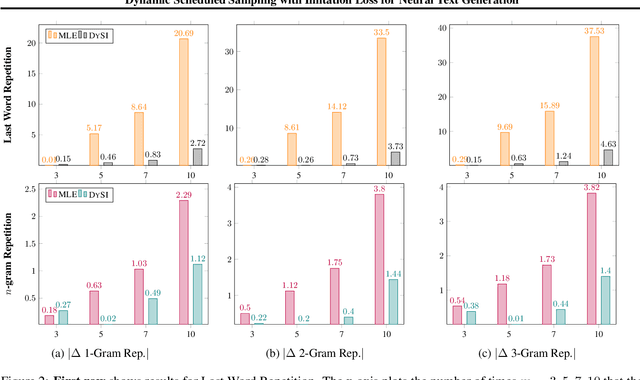
State-of-the-art neural text generation models are typically trained to maximize the likelihood of each token in the ground-truth sequence conditioned on the previous target tokens. However, during inference, the model needs to make a prediction conditioned on the tokens generated by itself. This train-test discrepancy is referred to as exposure bias. Scheduled sampling is a curriculum learning strategy that gradually exposes the model to its own predictions during training to mitigate this bias. Most of the proposed approaches design a scheduler based on training steps, which generally requires careful tuning depending on the training setup. In this work, we introduce Dynamic Scheduled Sampling with Imitation Loss (DySI), which maintains the schedule based solely on the training time accuracy, while enhancing the curriculum learning by introducing an imitation loss, which attempts to make the behavior of the decoder indistinguishable from the behavior of a teacher-forced decoder. DySI is universally applicable across training setups with minimal tuning. Extensive experiments and analysis show that DySI not only achieves notable improvements on standard machine translation benchmarks, but also significantly improves the robustness of other text generation models.
Learning, Fast and Slow: A Goal-Directed Memory-Based Approach for Dynamic Environments
Jan 31, 2023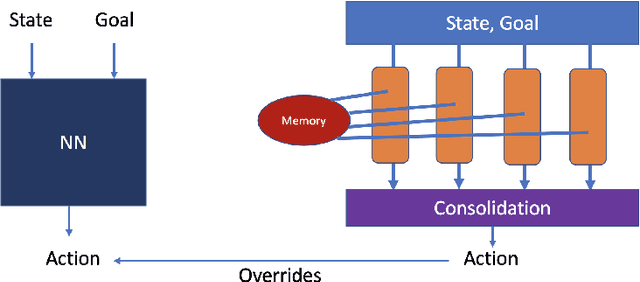
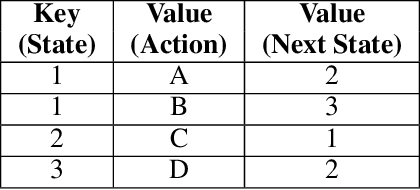
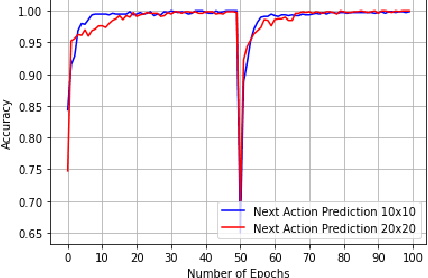
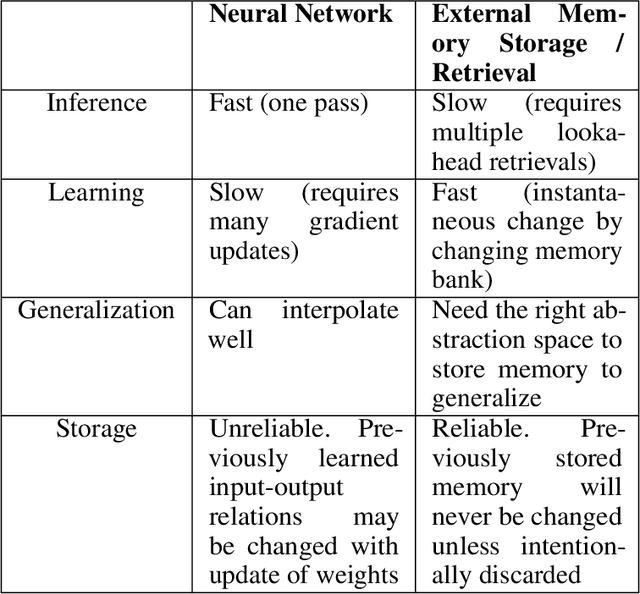
Model-based next state prediction and state value prediction are slow to converge. To address these challenges, we do the following: i) Instead of a neural network, we do model-based planning using a parallel memory retrieval system (which we term the slow mechanism); ii) Instead of learning state values, we guide the agent's actions using goal-directed exploration, by using a neural network to choose the next action given the current state and the goal state (which we term the fast mechanism). The goal-directed exploration is trained online using hippocampal replay of visited states and future imagined states every single time step, leading to fast and efficient training. Empirical studies show that our proposed method has a 92% solve rate across 100 episodes in a dynamically changing grid world, significantly outperforming state-of-the-art actor critic mechanisms such as PPO (54%), TRPO (50%) and A2C (24%). Ablation studies demonstrate that both mechanisms are crucial. We posit that the future of Reinforcement Learning (RL) will be to model goals and sub-goals for various tasks, and plan it out in a goal-directed memory-based approach.