 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Heckerthoughts
Feb 13, 2023


In 1987, Eric Horvitz, Greg Cooper, and I visited I.J. Good at his university. We wanted to see him was not because he worked with Alan Turing to help win WWII by decoding encrypted messages from the Germans, although that certainly intrigued us. Rather, we wanted to see him because we had just finished reading his book "Good Thinking," which summarized his life's work in Probability and its Applications. We were graduate students at Stanford working in AI, and amazed that his thinking was so similar to ours, having worked decades before us and coming from such a seemingly different perspective not involving AI. This story is a fitting introduction this manuscript. Now having years to look back on my work, to boil it down to its essence, and to better appreciate its significance (if any) in the evolution of AI and ML, I realized it was time to put my work in perspective, providing a roadmap to any who would like to explore it. After I had this realization, it occurred to me that this is what I.J. Good did in his book. This manuscript is for those who want to understand basic concepts central to ML and AI and to learn about early applications of these concepts. Ironically, after I finished writing this manuscript, I realized that a lot of the concepts that I included are missing in modern courses on ML. I hope this work will help to make up for these omissions. The presentation gets somewhat technical in parts, but I've tried to keep the math to the bare minimum. In addition to the technical presentations, I include stories about how the ideas came to be and the effects they have had. When I was a student in physics, I was given dry texts to read. In class, however, several of my physics professors would tell stories around the work. Those stories fascinated me and really made the theory stick. So here, I do my best to present both the ideas and the stories behind them.
Meta-Learning over Time for Destination Prediction Tasks
Jun 29, 2022
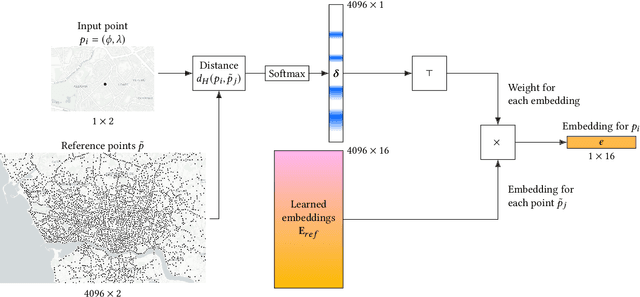

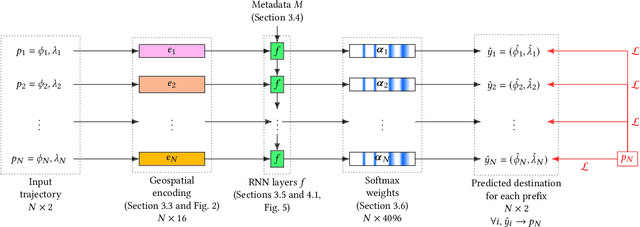
A need to understand and predict vehicles' behavior underlies both public and private goals in the transportation domain, including urban planning and management, ride-sharing services, and intelligent transportation systems. Individuals' preferences and intended destinations vary throughout the day, week, and year: for example, bars are most popular in the evenings, and beaches are most popular in the summer. Despite this principle, we note that recent studies on a popular benchmark dataset from Porto, Portugal have found, at best, only marginal improvements in predictive performance from incorporating temporal information. We propose an approach based on hypernetworks, a variant of meta-learning ("learning to learn") in which a neural network learns to change its own weights in response to an input. In our case, the weights responsible for destination prediction vary with the metadata, in particular the time, of the input trajectory. The time-conditioned weights notably improve the model's error relative to ablation studies and comparable prior work, and we confirm our hypothesis that knowledge of time should improve prediction of a vehicle's intended destination.
SwinCross: Cross-modal Swin Transformer for Head-and-Neck Tumor Segmentation in PET/CT Images
Feb 08, 2023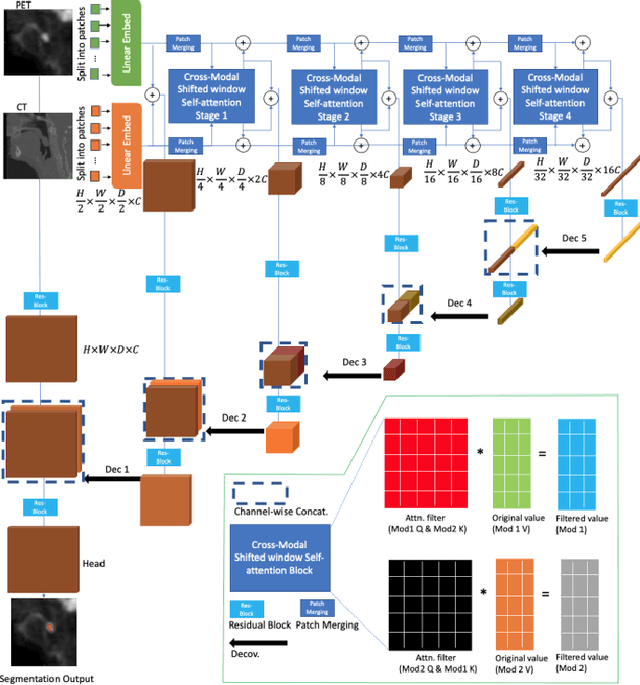
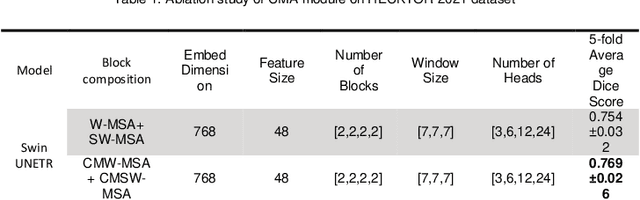
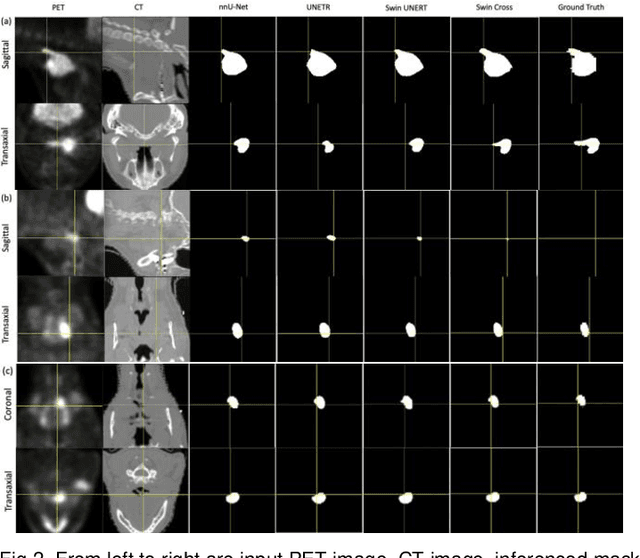
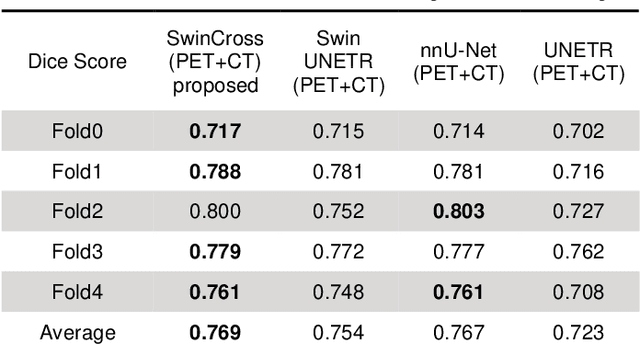
Radiotherapy (RT) combined with cetuximab is the standard treatment for patients with inoperable head and neck cancers. Segmentation of head and neck (H&N) tumors is a prerequisite for radiotherapy planning but a time-consuming process. In recent years, deep convolutional neural networks have become the de facto standard for automated image segmentation. However, due to the expensive computational cost associated with enlarging the field of view in DCNNs, their ability to model long-range dependency is still limited, and this can result in sub-optimal segmentation performance for objects with background context spanning over long distances. On the other hand, Transformer models have demonstrated excellent capabilities in capturing such long-range information in several semantic segmentation tasks performed on medical images. Inspired by the recent success of Vision Transformers and advances in multi-modal image analysis, we propose a novel segmentation model, debuted, Cross-Modal Swin Transformer (SwinCross), with cross-modal attention (CMA) module to incorporate cross-modal feature extraction at multiple resolutions.To validate the effectiveness of the proposed method, we performed experiments on the HECKTOR 2021 challenge dataset and compared it with the nnU-Net (the backbone of the top-5 methods in HECKTOR 2021) and other state-of-the-art transformer-based methods such as UNETR, and Swin UNETR. The proposed method is experimentally shown to outperform these comparing methods thanks to the ability of the CMA module to capture better inter-modality complimentary feature representations between PET and CT, for the task of head-and-neck tumor segmentation.
TranSOP: Transformer-based Multimodal Classification for Stroke Treatment Outcome Prediction
Jan 25, 2023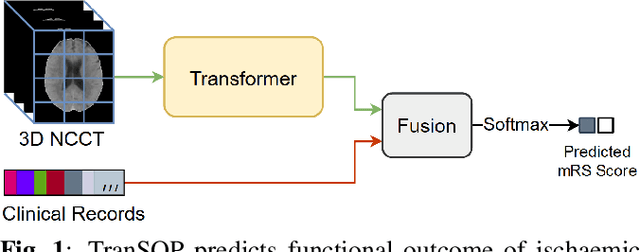
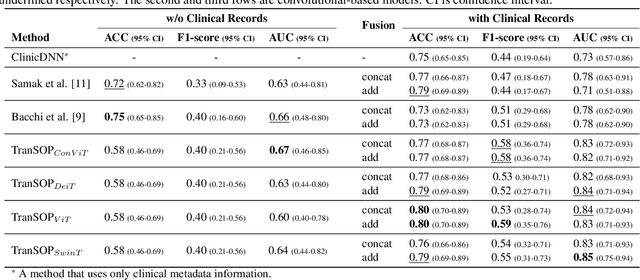
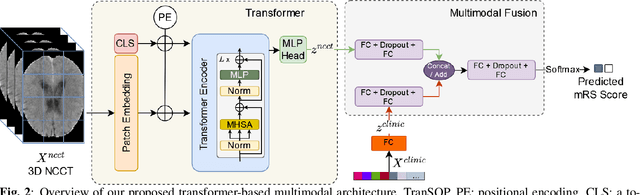
Acute ischaemic stroke, caused by an interruption in blood flow to brain tissue, is a leading cause of disability and mortality worldwide. The selection of patients for the most optimal ischaemic stroke treatment is a crucial step for a successful outcome, as the effect of treatment highly depends on the time to treatment. We propose a transformer-based multimodal network (TranSOP) for a classification approach that employs clinical metadata and imaging information, acquired on hospital admission, to predict the functional outcome of stroke treatment based on the modified Rankin Scale (mRS). This includes a fusion module to efficiently combine 3D non-contrast computed tomography (NCCT) features and clinical information. In comparative experiments using unimodal and multimodal data on the MRCLEAN dataset, we achieve a state-of-the-art AUC score of 0.85.
CIPER: Combining Invariant and Equivariant Representations Using Contrastive and Predictive Learning
Feb 05, 2023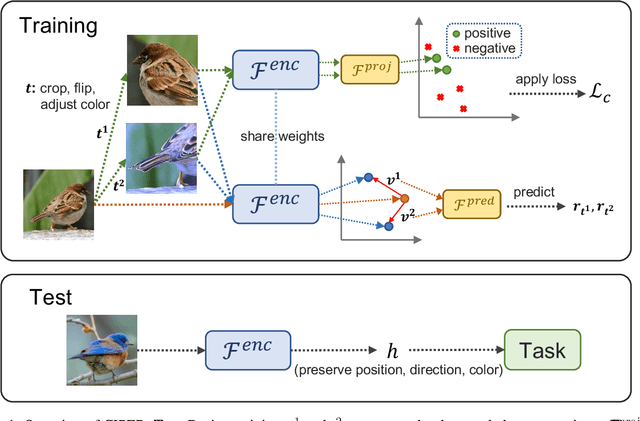


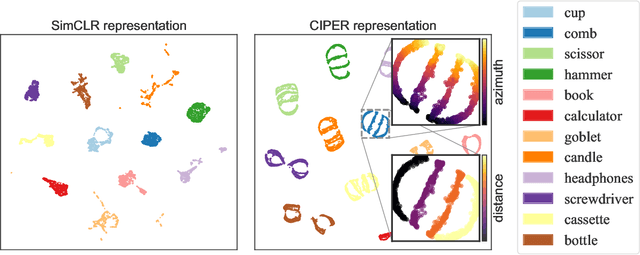
Self-supervised representation learning (SSRL) methods have shown great success in computer vision. In recent studies, augmentation-based contrastive learning methods have been proposed for learning representations that are invariant or equivariant to pre-defined data augmentation operations. However, invariant or equivariant features favor only specific downstream tasks depending on the augmentations chosen. They may result in poor performance when a downstream task requires the counterpart of those features (e.g., when the task is to recognize hand-written digits while the model learns to be invariant to in-plane image rotations rendering it incapable of distinguishing "9" from "6"). This work introduces Contrastive Invariant and Predictive Equivariant Representation learning (CIPER). CIPER comprises both invariant and equivariant learning objectives using one shared encoder and two different output heads on top of the encoder. One output head is a projection head with a state-of-the-art contrastive objective to encourage invariance to augmentations. The other is a prediction head estimating the augmentation parameters, capturing equivariant features. Both heads are discarded after training and only the encoder is used for downstream tasks. We evaluate our method on static image tasks and time-augmented image datasets. Our results show that CIPER outperforms a baseline contrastive method on various tasks, especially when the downstream task requires the encoding of augmentation-related information.
Using Intermediate Forward Iterates for Intermediate Generator Optimization
Feb 05, 2023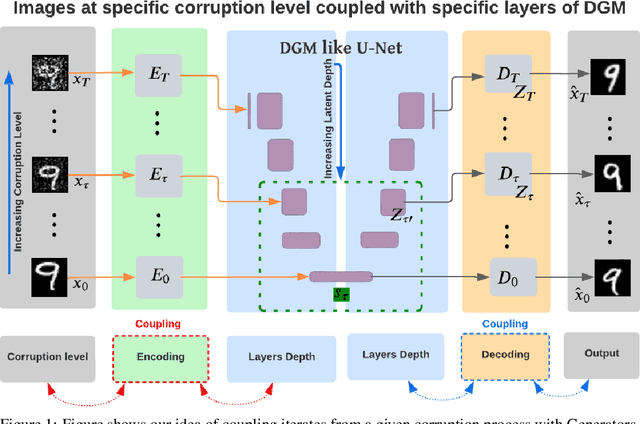
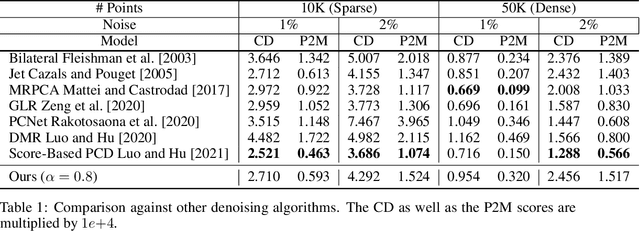
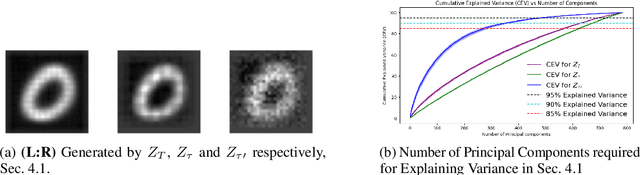

Score-based models have recently been introduced as a richer framework to model distributions in high dimensions and are generally more suitable for generative tasks. In score-based models, a generative task is formulated using a parametric model (such as a neural network) to directly learn the gradient of such high dimensional distributions, instead of the density functions themselves, as is done traditionally. From the mathematical point of view, such gradient information can be utilized in reverse by stochastic sampling to generate diverse samples. However, from a computational perspective, existing score-based models can be efficiently trained only if the forward or the corruption process can be computed in closed form. By using the relationship between the process and layers in a feed-forward network, we derive a backpropagation-based procedure which we call Intermediate Generator Optimization to utilize intermediate iterates of the process with negligible computational overhead. The main advantage of IGO is that it can be incorporated into any standard autoencoder pipeline for the generative task. We analyze the sample complexity properties of IGO to solve downstream tasks like Generative PCA. We show applications of the IGO on two dense predictive tasks viz., image extrapolation, and point cloud denoising. Our experiments indicate that obtaining an ensemble of generators for various time points is possible using first-order methods.
Spatio-Temporal Point Process for Multiple Object Tracking
Feb 05, 2023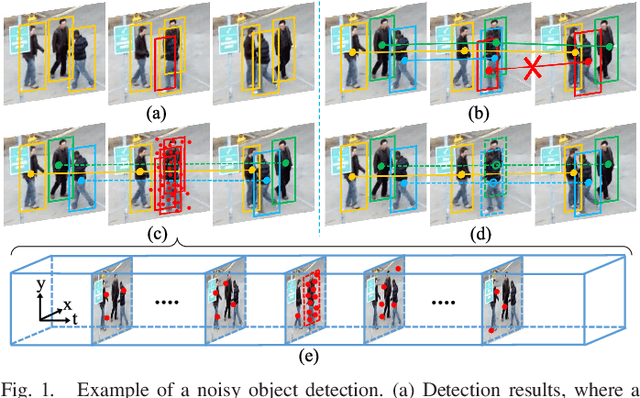
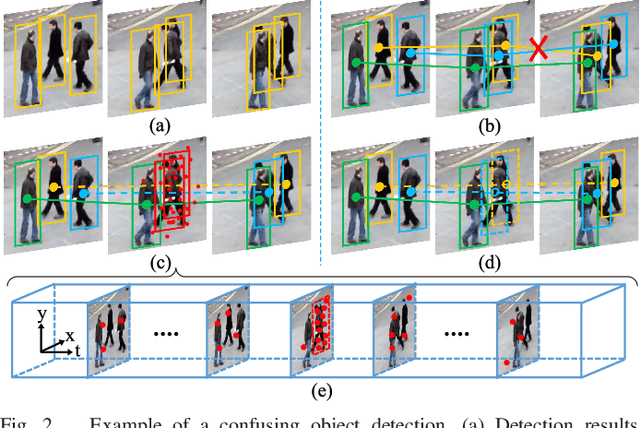
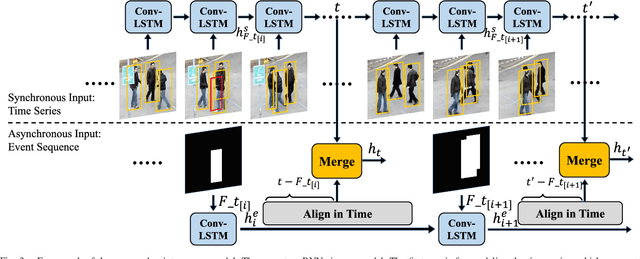
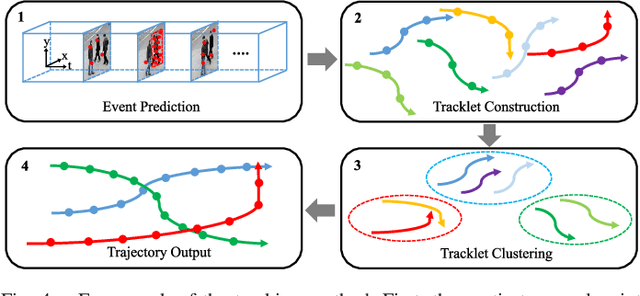
Multiple Object Tracking (MOT) focuses on modeling the relationship of detected objects among consecutive frames and merge them into different trajectories. MOT remains a challenging task as noisy and confusing detection results often hinder the final performance. Furthermore, most existing research are focusing on improving detection algorithms and association strategies. As such, we propose a novel framework that can effectively predict and mask-out the noisy and confusing detection results before associating the objects into trajectories. In particular, we formulate such "bad" detection results as a sequence of events and adopt the spatio-temporal point process}to model such events. Traditionally, the occurrence rate in a point process is characterized by an explicitly defined intensity function, which depends on the prior knowledge of some specific tasks. Thus, designing a proper model is expensive and time-consuming, with also limited ability to generalize well. To tackle this problem, we adopt the convolutional recurrent neural network (conv-RNN) to instantiate the point process, where its intensity function is automatically modeled by the training data. Furthermore, we show that our method captures both temporal and spatial evolution, which is essential in modeling events for MOT. Experimental results demonstrate notable improvements in addressing noisy and confusing detection results in MOT datasets. An improved state-of-the-art performance is achieved by incorporating our baseline MOT algorithm with the spatio-temporal point process model.
Using Kaldi for Automatic Speech Recognition of Conversational Austrian German
Jan 16, 2023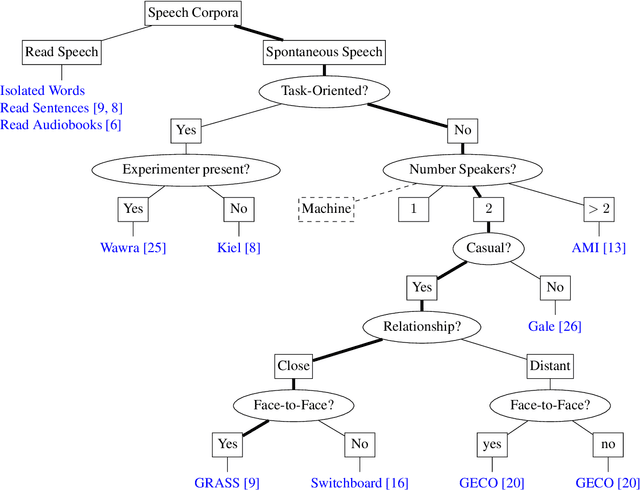

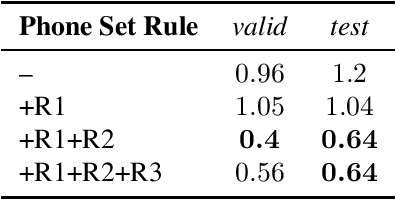
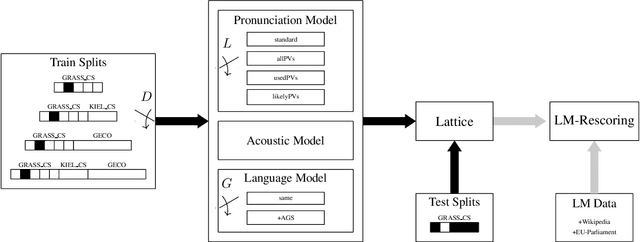
As dialogue systems are becoming more and more interactional and social, also the accurate automatic speech recognition (ASR) of conversational speech is of increasing importance. This shifts the focus from short, spontaneous, task-oriented dialogues to the much higher complexity of casual face-to-face conversations. However, the collection and annotation of such conversations is a time-consuming process and data is sparse for this specific speaking style. This paper presents ASR experiments with read and conversational Austrian German as target. In order to deal with having only limited resources available for conversational German and, at the same time, with a large variation among speakers with respect to pronunciation characteristics, we improve a Kaldi-based ASR system by incorporating a (large) knowledge-based pronunciation lexicon, while exploring different data-based methods to restrict the number of pronunciation variants for each lexical entry. We achieve best WER of 0.4% on Austrian German read speech and best average WER of 48.5% on conversational speech. We find that by using our best pronunciation lexicon a similarly high performance can be achieved than by increasing the size of the data used for the language model by approx. 360% to 760%. Our findings indicate that for low-resource scenarios -- despite the general trend in speech technology towards using data-based methods only -- knowledge-based approaches are a successful, efficient method.
Real-Time Monitoring of User Stress, Heart Rate and Heart Rate Variability on Mobile Devices
Oct 04, 2022
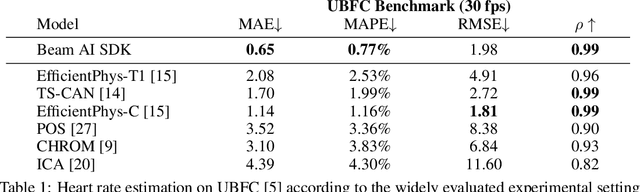
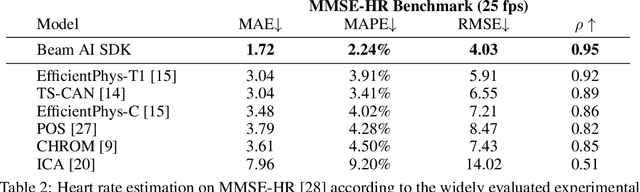
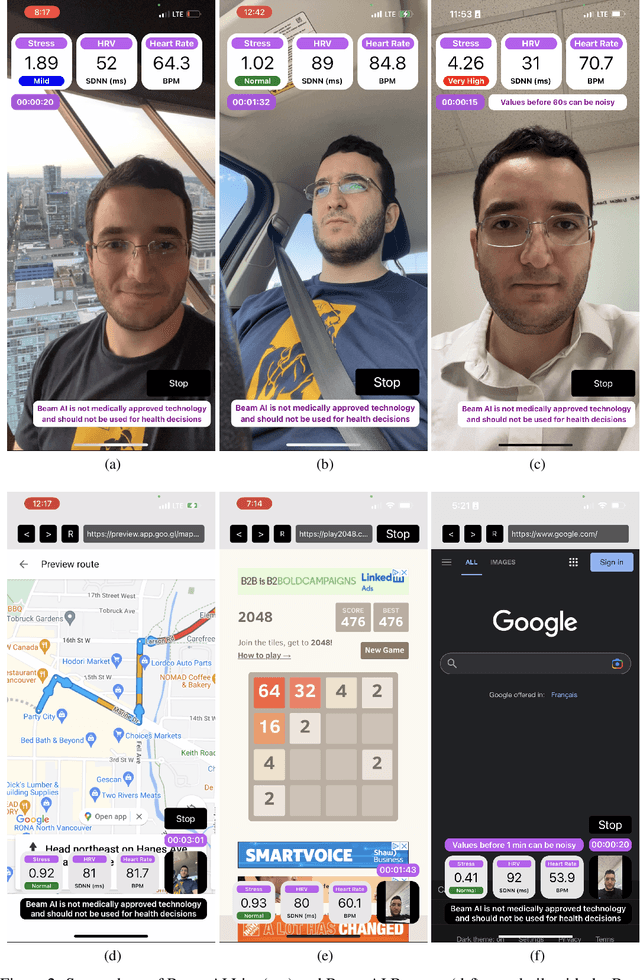
Stress is considered to be the epidemic of the 21st-century. Yet, mobile apps cannot directly evaluate the impact of their content and services on user stress. We introduce the Beam AI SDK to address this issue. Using our SDK, apps can monitor user stress through the selfie camera in real-time. Our technology extracts the user's pulse wave by analyzing subtle color variations across the skin regions of the user's face. The user's pulse wave is then used to determine stress (according to the Baevsky Stress Index), heart rate, and heart rate variability. We evaluate our technology on the UBFC dataset, the MMSE-HR dataset, and Beam AI's internal data. Our technology achieves 99.2%, 97.8% and 98.5% accuracy for heart rate estimation on each benchmark respectively, a nearly twice lower error rate than competing methods. We further demonstrate an average Pearson correlation of 0.801 in determining stress and heart rate variability, thus producing commercially useful readings to derive content decisions in apps. Our SDK is available for use at www.beamhealth.ai.
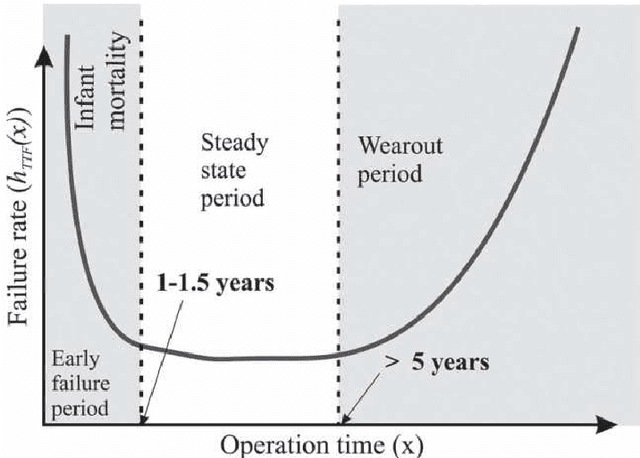
Durability and Availability of Erasure-Coded Storage Systems with Concurrent Maintenance
Jan 22, 2023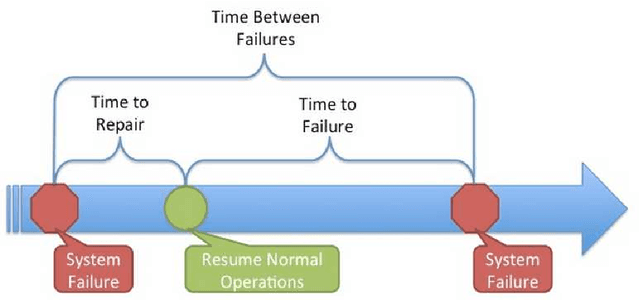

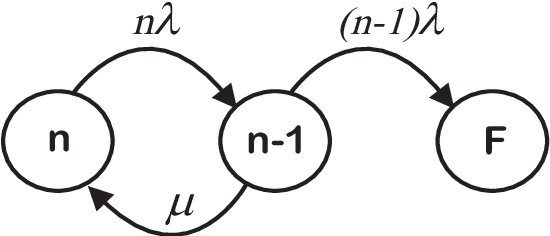
This initial version of this document was written back in 2014 for the sole purpose of providing fundamentals of reliability theory as well as to identify the theoretical types of machinery for the prediction of durability/availability of erasure-coded storage systems. Since the definition of a "system" is too broad, we specifically focus on warm/cold storage systems where the data is stored in a distributed fashion across different storage units with or without continuous operation. The contents of this document are dedicated to a review of fundamentals, a few major improved stochastic models, and several contributions of my work relevant to the field. One of the contributions of this document is the introduction of the most general form of Markov models for the estimation of mean time to failure. This work was partially later published in IEEE Transactions on Reliability. Very good approximations for the closed-form solutions for this general model are also investigated. Various storage configurations under different policies are compared using such advanced models. Later in a subsequent chapter, we have also considered multi-dimensional Markov models to address detached drive-medium combinations such as those found in optical disk and tape storage systems. It is not hard to anticipate such a system structure would most likely be part of future DNA storage libraries. This work is partially published in Elsevier Reliability and System Safety. Topics that include simulation modelings for more accurate estimations are included towards the end of the document by noting the deficiencies of the simplified canonical as well as more complex Markov models, due mainly to the stationary and static nature of Markovinity. Throughout the document, we shall focus on concurrently maintained systems although the discussions will only slightly change for the systems repaired one device at a time.