 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hierarchical Graph Neural Networks for Causal Discovery and Root Cause Localization
Feb 03, 2023
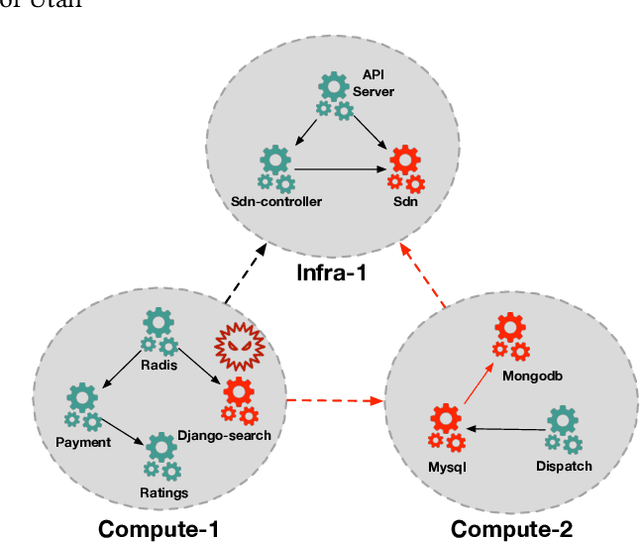
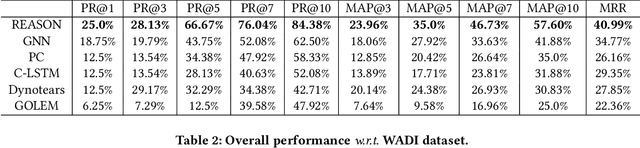
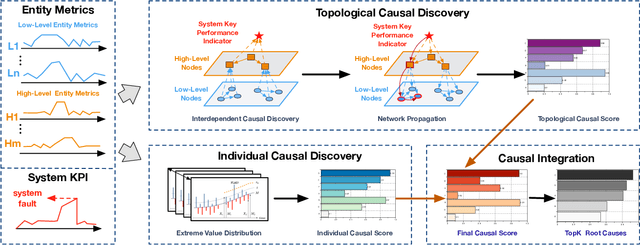
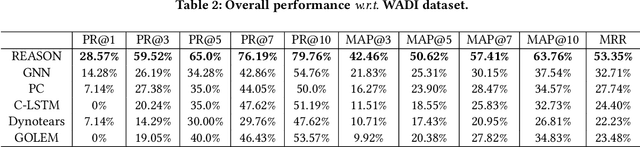
In this paper, we propose REASON, a novel framework that enables the automatic discovery of both intra-level (i.e., within-network) and inter-level (i.e., across-network) causal relationships for root cause localization. REASON consists of Topological Causal Discovery and Individual Causal Discovery. The Topological Causal Discovery component aims to model the fault propagation in order to trace back to the root causes. To achieve this, we propose novel hierarchical graph neural networks to construct interdependent causal networks by modeling both intra-level and inter-level non-linear causal relations. Based on the learned interdependent causal networks, we then leverage random walks with restarts to model the network propagation of a system fault. The Individual Causal Discovery component focuses on capturing abrupt change patterns of a single system entity. This component examines the temporal patterns of each entity's metric data (i.e., time series), and estimates its likelihood of being a root cause based on the Extreme Value theory. Combining the topological and individual causal scores, the top K system entities are identified as root causes. Extensive experiments on three real-world datasets with case studies demonstrate the effectiveness and superiority of the proposed framework.
Real-Time Massive MIMO Channel Prediction: A Combination of Deep Learning and NeuralProphet
Aug 11, 2022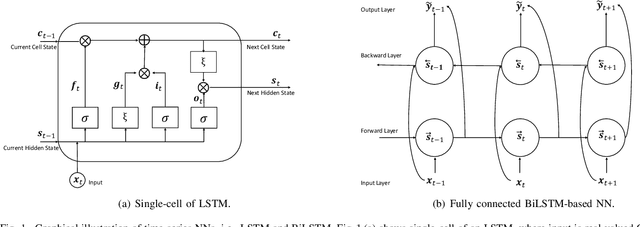
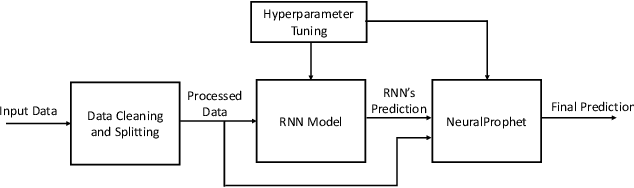
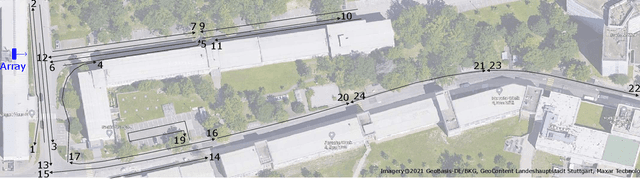
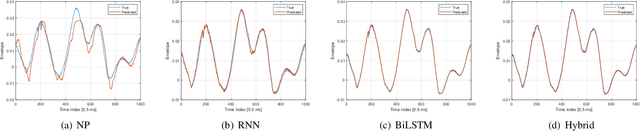
Channel state information (CSI) is of pivotal importance as it enables wireless systems to adapt transmission parameters more accurately, thus improving the system's overall performance. However, it becomes challenging to acquire accurate CSI in a highly dynamic environment, mainly due to multi-path fading. Inaccurate CSI can deteriorate the performance, particularly of a massive multiple-input multiple-output (mMIMO) system. This paper adapts machine learning (ML) for CSI prediction. Specifically, we exploit time-series models of deep learning (DL) such as recurrent neural network (RNN) and Bidirectional long-short term memory (BiLSTM). Further, we use NeuralProphet (NP), a recently introduced time-series model, composed of statistical components, e.g., auto-regression (AR) and Fourier terms, for CSI prediction. Inspired by statistical models, we also develop a novel hybrid framework comprising RNN and NP to achieve better prediction accuracy. The proposed channel predictors (CPs) performance is evaluated on a real-time dataset recorded at the Nokia Bell-Labs campus in Stuttgart, Germany. Numerical results show that DL brings performance gain when used with statistical models and showcases robustness.
Privacy Risk for anisotropic Langevin dynamics using relative entropy bounds
Feb 01, 2023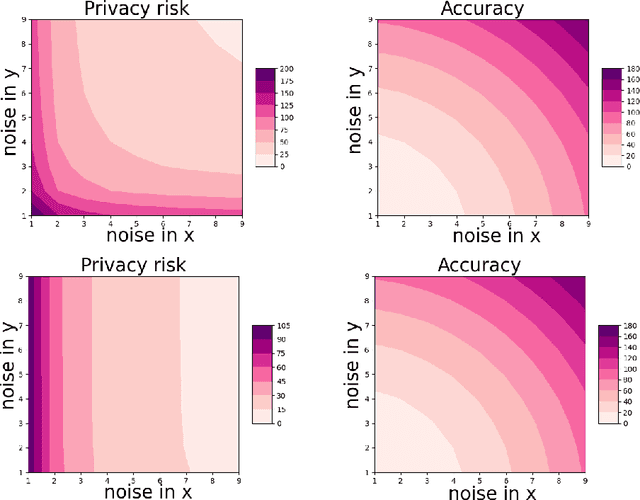
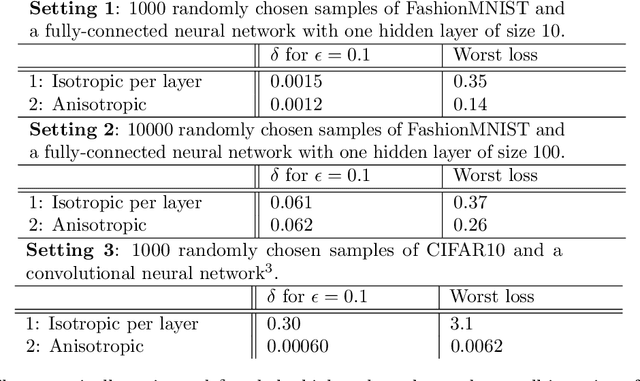
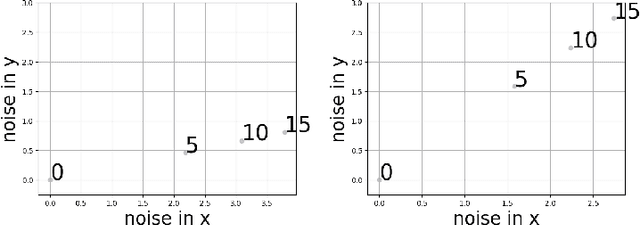
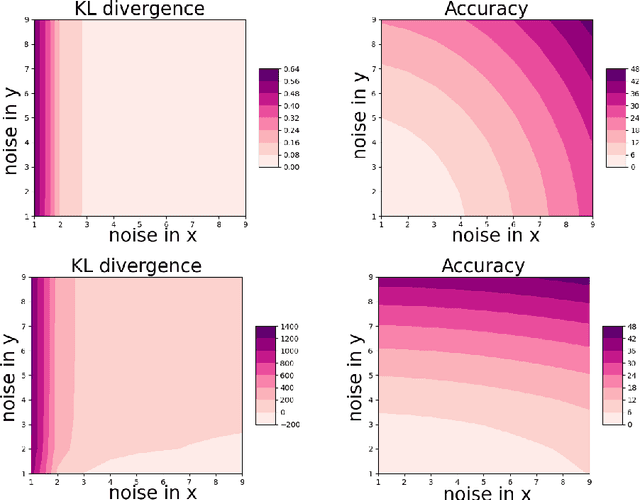
The privacy preserving properties of Langevin dynamics with additive isotropic noise have been extensively studied. However, the isotropic noise assumption is very restrictive: (a) when adding noise to existing learning algorithms to preserve privacy and maintain the best possible accuracy one should take into account the relative magnitude of the outputs and their correlations; (b) popular algorithms such as stochastic gradient descent (and their continuous time limits) appear to possess anisotropic covariance properties. To study the privacy risks for the anisotropic noise case, one requires general results on the relative entropy between the laws of two Stochastic Differential Equations with different drifts and diffusion coefficients. Our main contribution is to establish such a bound using stability estimates for solutions to the Fokker-Planck equations via functional inequalities. With additional assumptions, the relative entropy bound implies an $(\epsilon,\delta)$-differential privacy bound. We discuss the practical implications of our bound related to privacy risk in different contexts.Finally, the benefits of anisotropic noise are illustrated using numerical results on optimising a quadratic loss or calibrating a neural network.
Filtering Context Mitigates Scarcity and Selection Bias in Political Ideology Prediction
Feb 01, 2023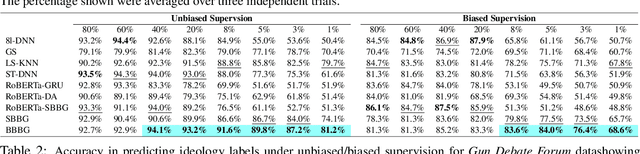
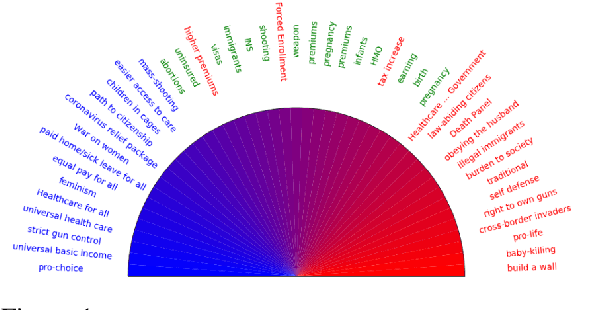

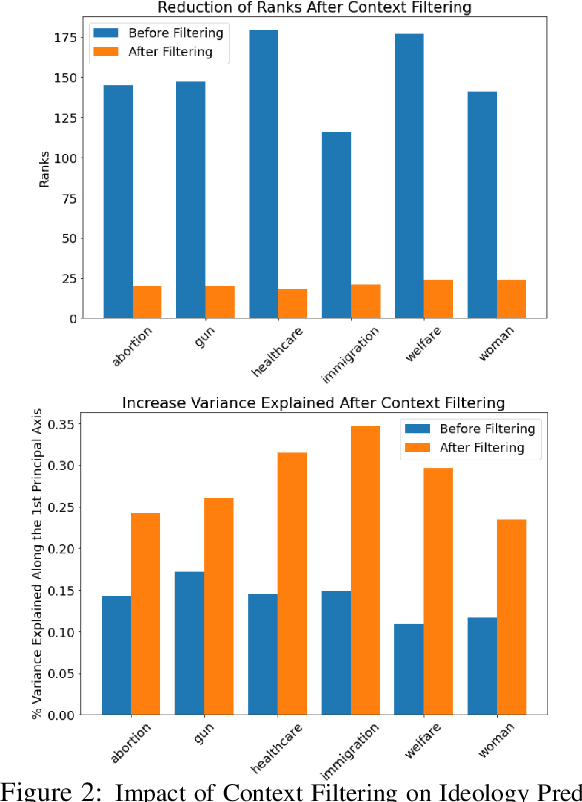
We propose a novel supervised learning approach for political ideology prediction (PIP) that is capable of predicting out-of-distribution inputs. This problem is motivated by the fact that manual data-labeling is expensive, while self-reported labels are often scarce and exhibit significant selection bias. We propose a novel statistical model that decomposes the document embeddings into a linear superposition of two vectors; a latent neutral \emph{context} vector independent of ideology, and a latent \emph{position} vector aligned with ideology. We train an end-to-end model that has intermediate contextual and positional vectors as outputs. At deployment time, our model predicts labels for input documents by exclusively leveraging the predicted positional vectors. On two benchmark datasets we show that our model is capable of outputting predictions even when trained with as little as 5\% biased data, and is significantly more accurate than the state-of-the-art. Through crowd-sourcing we validate the neutrality of contextual vectors, and show that context filtering results in ideological concentration, allowing for prediction on out-of-distribution examples.
Attention-LSTM for Multivariate Traffic State Prediction on Rural Roads
Jan 06, 2023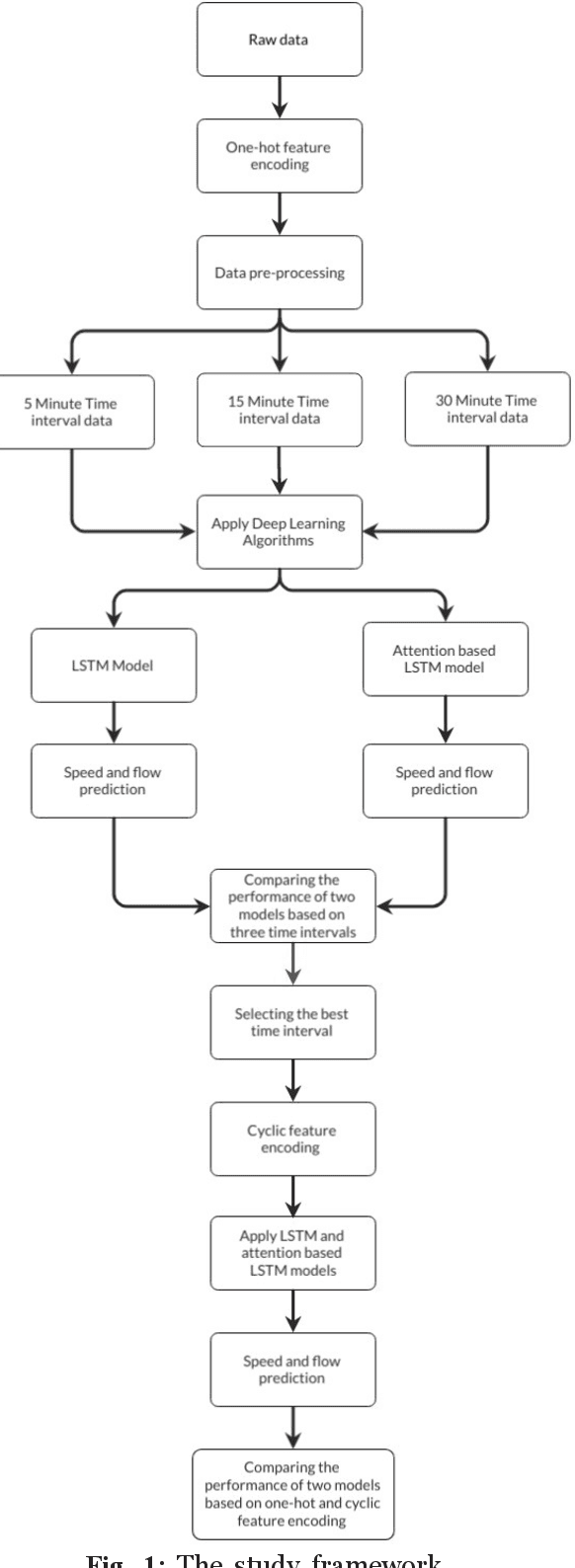
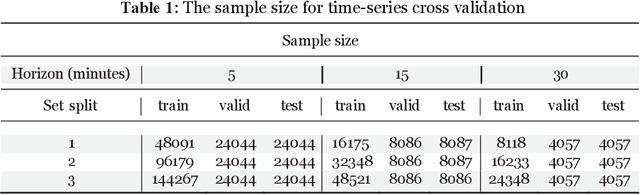
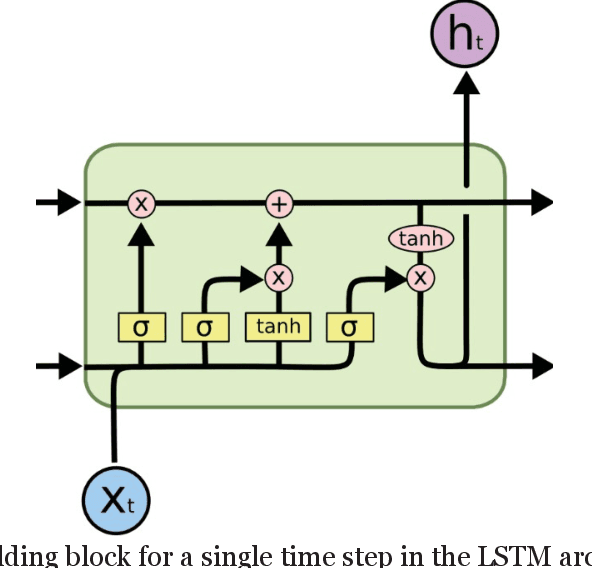
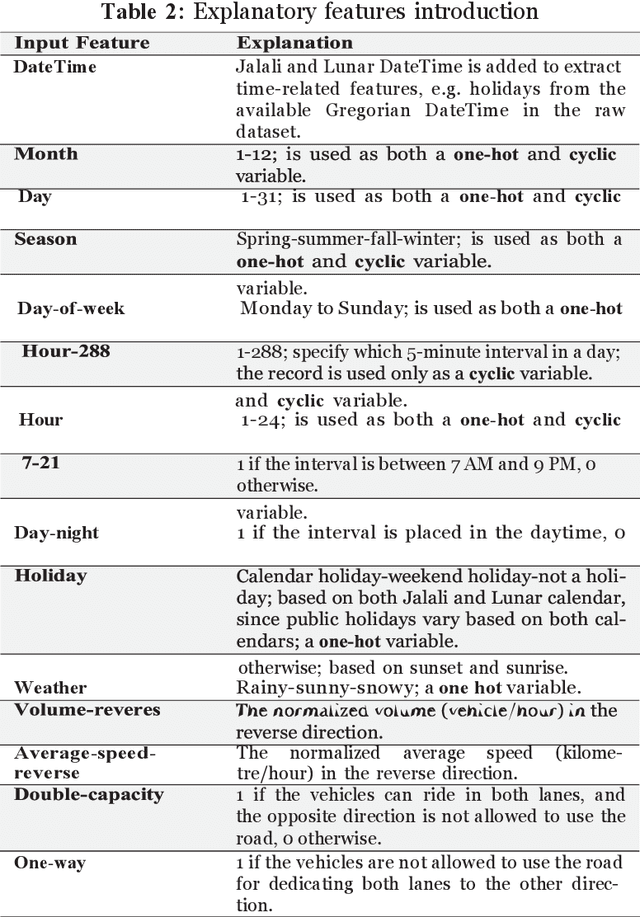
Accurate traffic volume and speed prediction have a wide range of applications in transportation. It can result in useful and timely information for both travellers and transportation decision-makers. In this study, an Attention based Long Sort-Term Memory model (A-LSTM) is proposed to simultaneously predict traffic volume and speed in a critical rural road segmentation which connects Tehran to Chalus, the most tourist destination city in Iran. Moreover, this study compares the results of the A-LSTM model with the Long Short-Term Memory (LSTM) model. Both models show acceptable performance in predicting speed and flow. However, the A-LSTM model outperforms the LSTM in 5 and 15-minute intervals. In contrast, there is no meaningful difference between the two models for the 30-minute time interval. By comparing the performance of the models based on different time horizons, the 15-minute horizon model outperforms the others by reaching the lowest Mean Square Error (MSE) loss of 0.0032, followed by the 30 and 5-minutes horizons with 0.004 and 0.0051, respectively. In addition, this study compares the results of the models based on two transformations of temporal categorical input variables, one-hot or cyclic, for the 15-minute time interval. The results demonstrate that both LSTM and A-LSTM with cyclic feature encoding outperform those with one-hot feature encoding.
An Image captioning algorithm based on the Hybrid Deep Learning Technique (CNN+GRU)
Jan 06, 2023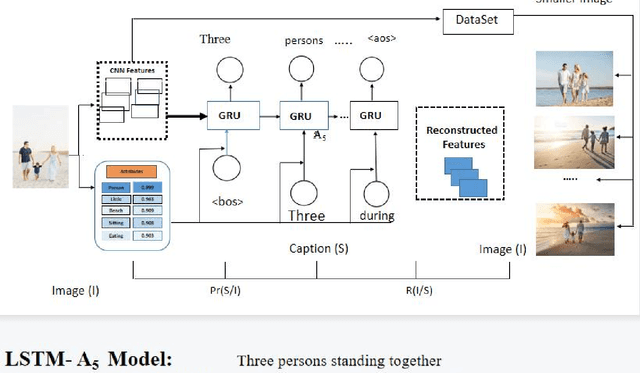
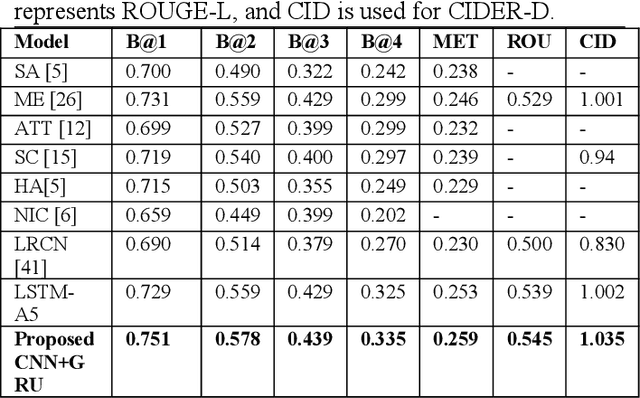
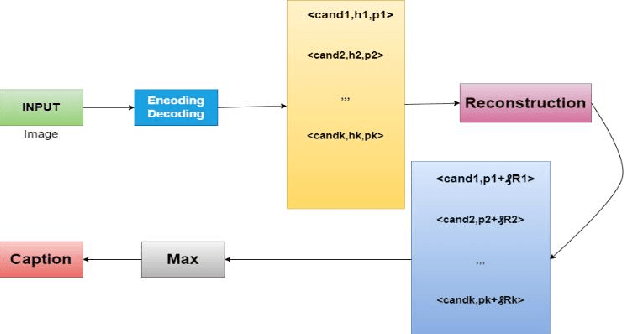
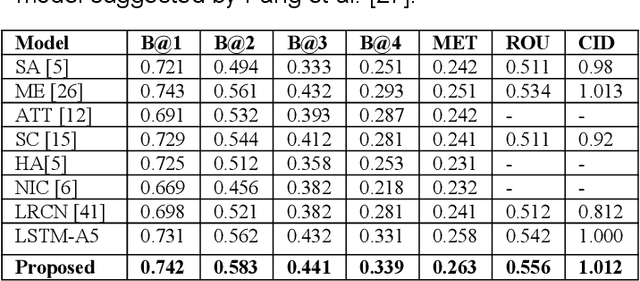
Image captioning by the encoder-decoder framework has shown tremendous advancement in the last decade where CNN is mainly used as encoder and LSTM is used as a decoder. Despite such an impressive achievement in terms of accuracy in simple images, it lacks in terms of time complexity and space complexity efficiency. In addition to this, in case of complex images with a lot of information and objects, the performance of this CNN-LSTM pair downgraded exponentially due to the lack of semantic understanding of the scenes presented in the images. Thus, to take these issues into consideration, we present CNN-GRU encoder decode framework for caption-to-image reconstructor to handle the semantic context into consideration as well as the time complexity. By taking the hidden states of the decoder into consideration, the input image and its similar semantic representations is reconstructed and reconstruction scores from a semantic reconstructor are used in conjunction with likelihood during model training to assess the quality of the generated caption. As a result, the decoder receives improved semantic information, enhancing the caption production process. During model testing, combining the reconstruction score and the log-likelihood is also feasible to choose the most appropriate caption. The suggested model outperforms the state-of-the-art LSTM-A5 model for picture captioning in terms of time complexity and accuracy.
Photonics-enabled wavelet-like transform via nonlinear optical frequency sweeping and stimulated Brillouin scattering-based frequency-to-time mapping
Aug 19, 2022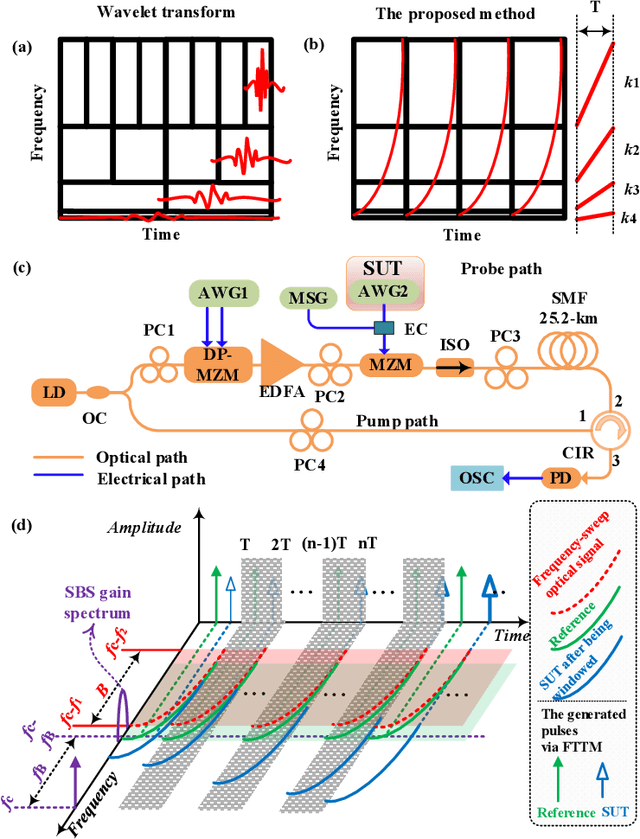
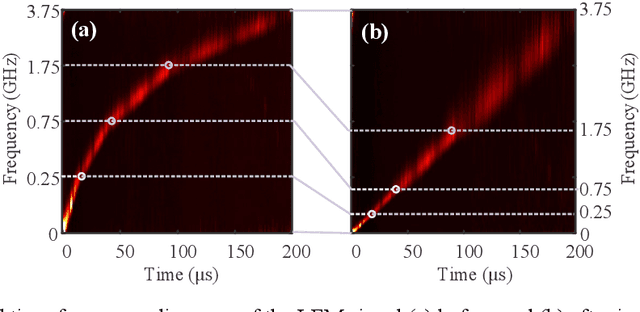
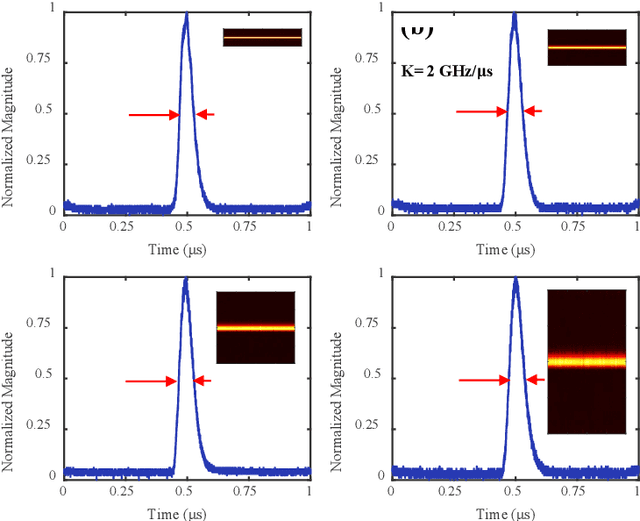
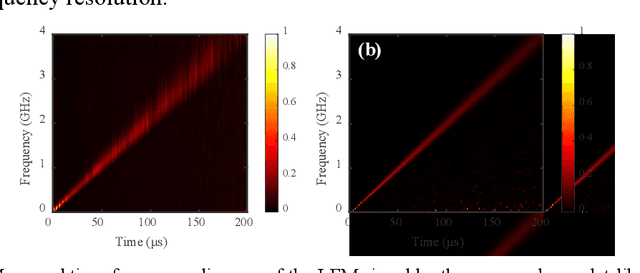
A photonics-enabled wavelet-like transform system, characterized by multi-resolution time-frequency analysis, is proposed based on a typical stimulated Brillouin scattering (SBS) pump-probe setup using an optical nonlinear frequency-sweep signal. In the pump path, a continuous-wave optical signal is injected into an SBS medium to generate an SBS gain. In the probe path, a periodic nonlinear frequency-sweep optical signal with a time-varying chirp rate is generated, which is then modulated at a Mach-Zehnder modulator (MZM) by the electrical signal under test (SUT). The optical signal from the MZM is selectively amplified by the SBS gain and converted back to the electrical domain using a low-speed photodetector, implementing the periodic SBS-based frequency-to-time mapping (FTTM). The frequency-domain information corresponding to different periods is mapped to the time domain via the FTTM in the form of low-speed electrical pulses, which is then spliced to analyze the time-frequency relationship of the SUT in real-time. The time-varying chirp rate in each sweep period makes the signals with different frequencies have different frequency resolutions in the FTTM process, which is very similar to the characteristics of the wavelet transform, so we call it wavelet-like transform. An experiment is carried out. Multi-resolution time-frequency analysis of a variety of RF signals is carried out in a 4-GHz bandwidth limited only by the equipment.
HAL3D: Hierarchical Active Learning for Fine-Grained 3D Part Labeling
Jan 25, 2023
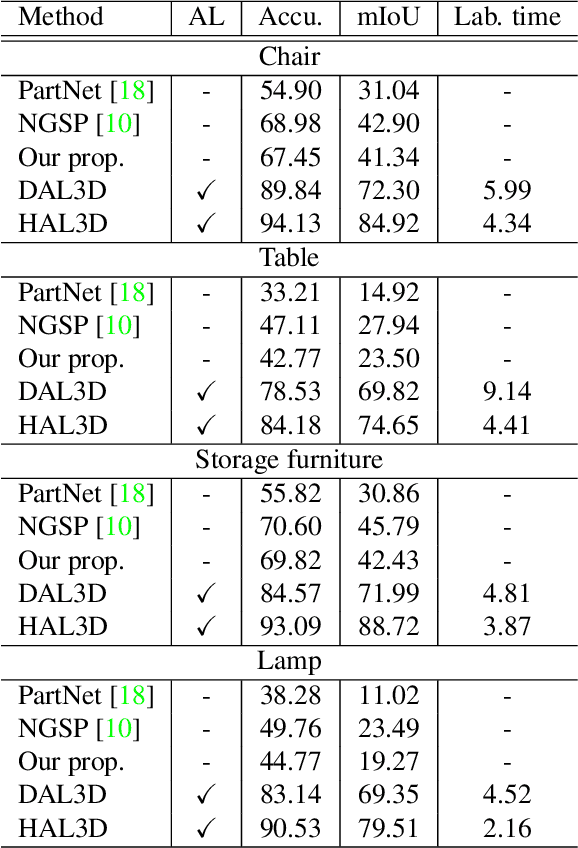
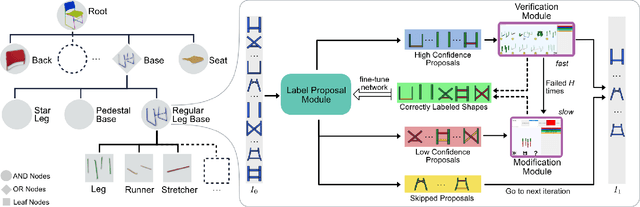
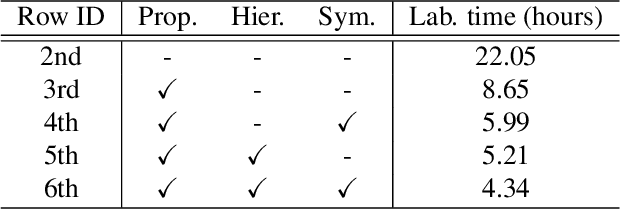
We present the first active learning tool for fine-grained 3D part labeling, a problem which challenges even the most advanced deep learning (DL) methods due to the significant structural variations among the small and intricate parts. For the same reason, the necessary data annotation effort is tremendous, motivating approaches to minimize human involvement. Our labeling tool iteratively verifies or modifies part labels predicted by a deep neural network, with human feedback continually improving the network prediction. To effectively reduce human efforts, we develop two novel features in our tool, hierarchical and symmetry-aware active labeling. Our human-in-the-loop approach, coined HAL3D, achieves 100% accuracy (barring human errors) on any test set with pre-defined hierarchical part labels, with 80% time-saving over manual effort.
Time-series Transformer Generative Adversarial Networks
May 23, 2022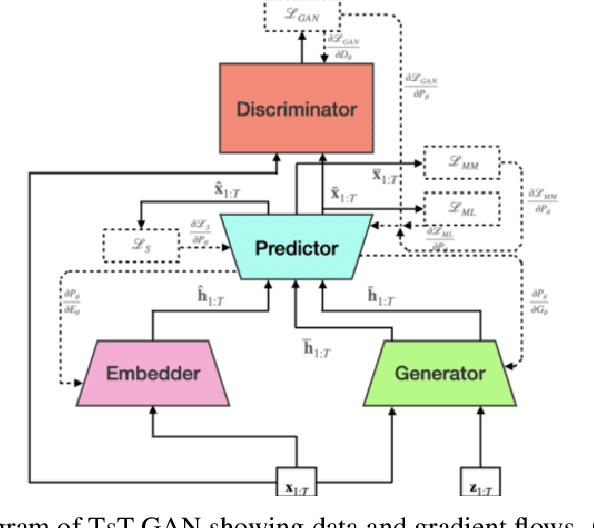
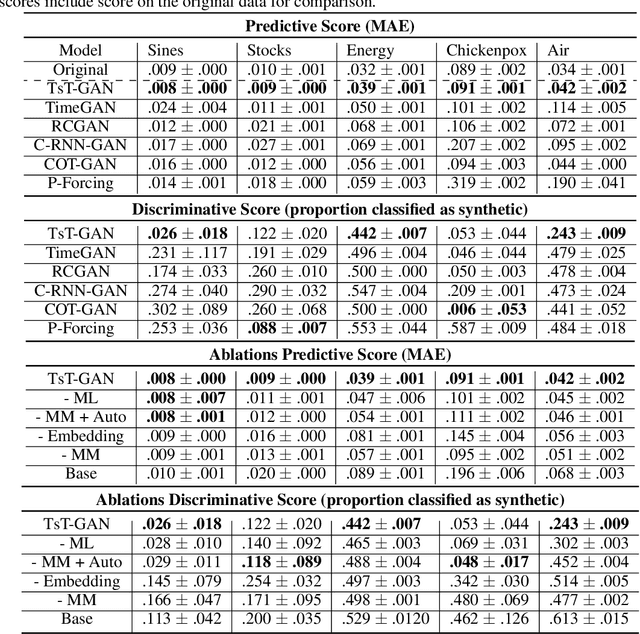
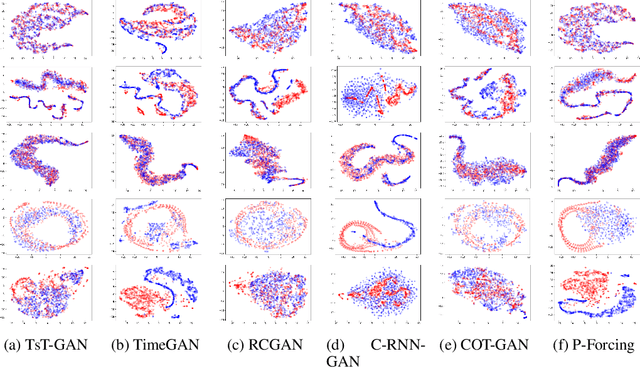
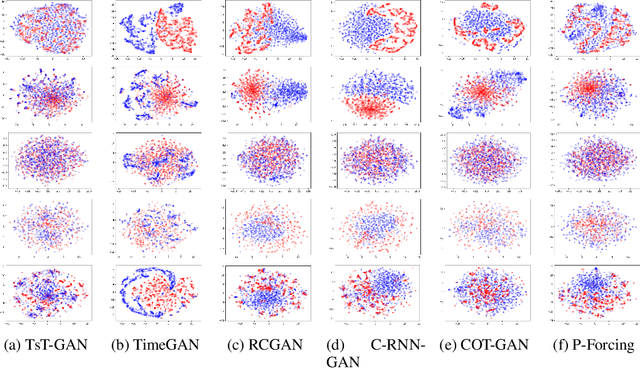
Many real-world tasks are plagued by limitations on data: in some instances very little data is available and in others, data is protected by privacy enforcing regulations (e.g. GDPR). We consider limitations posed specifically on time-series data and present a model that can generate synthetic time-series which can be used in place of real data. A model that generates synthetic time-series data has two objectives: 1) to capture the stepwise conditional distribution of real sequences, and 2) to faithfully model the joint distribution of entire real sequences. Autoregressive models trained via maximum likelihood estimation can be used in a system where previous predictions are fed back in and used to predict future ones; in such models, errors can accrue over time. Furthermore, a plausible initial value is required making MLE based models not really generative. Many downstream tasks learn to model conditional distributions of the time-series, hence, synthetic data drawn from a generative model must satisfy 1) in addition to performing 2). We present TsT-GAN, a framework that capitalises on the Transformer architecture to satisfy the desiderata and compare its performance against five state-of-the-art models on five datasets and show that TsT-GAN achieves higher predictive performance on all datasets.
System Design for an Integrated Lifelong Reinforcement Learning Agent for Real-Time Strategy Games
Dec 08, 2022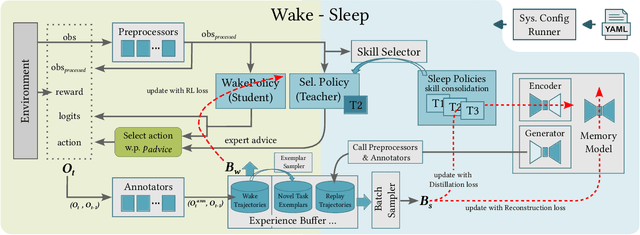
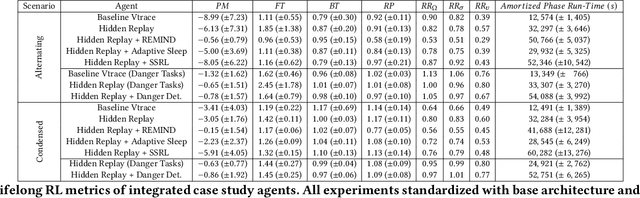
As Artificial and Robotic Systems are increasingly deployed and relied upon for real-world applications, it is important that they exhibit the ability to continually learn and adapt in dynamically-changing environments, becoming Lifelong Learning Machines. Continual/lifelong learning (LL) involves minimizing catastrophic forgetting of old tasks while maximizing a model's capability to learn new tasks. This paper addresses the challenging lifelong reinforcement learning (L2RL) setting. Pushing the state-of-the-art forward in L2RL and making L2RL useful for practical applications requires more than developing individual L2RL algorithms; it requires making progress at the systems-level, especially research into the non-trivial problem of how to integrate multiple L2RL algorithms into a common framework. In this paper, we introduce the Lifelong Reinforcement Learning Components Framework (L2RLCF), which standardizes L2RL systems and assimilates different continual learning components (each addressing different aspects of the lifelong learning problem) into a unified system. As an instantiation of L2RLCF, we develop a standard API allowing easy integration of novel lifelong learning components. We describe a case study that demonstrates how multiple independently-developed LL components can be integrated into a single realized system. We also introduce an evaluation environment in order to measure the effect of combining various system components. Our evaluation environment employs different LL scenarios (sequences of tasks) consisting of Starcraft-2 minigames and allows for the fair, comprehensive, and quantitative comparison of different combinations of components within a challenging common evaluation environment.