 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Implementing Energy-aware Data-driven Intelligence for Smart Health Applications on Mobile Platforms
Feb 01, 2023
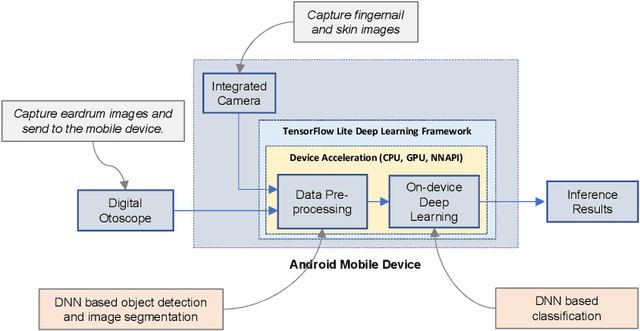
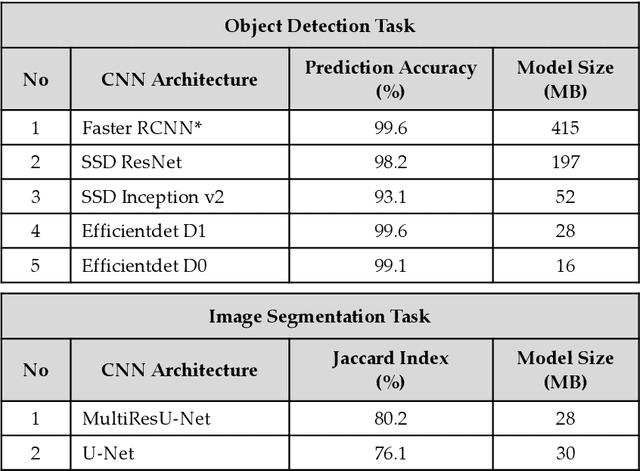
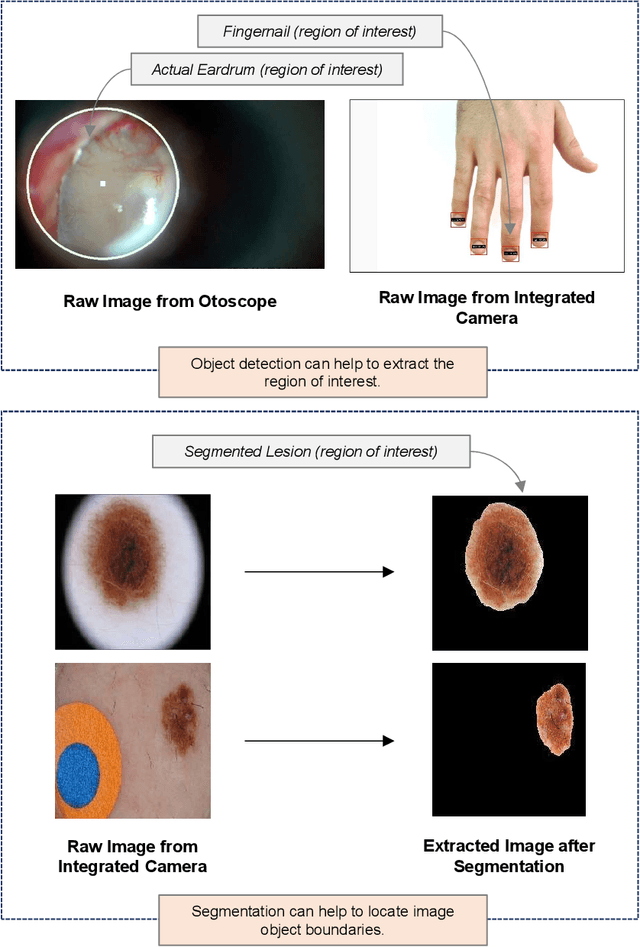
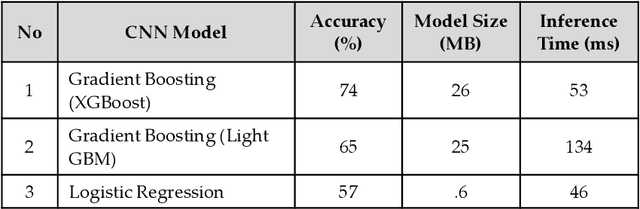
Recent breakthrough technological progressions of powerful mobile computing resources such as low-cost mobile GPUs along with cutting-edge, open-source software architectures have enabled high-performance deep learning on mobile platforms. These advancements have revolutionized the capabilities of today's mobile applications in different dimensions to perform data-driven intelligence locally, particularly for smart health applications. Unlike traditional machine learning (ML) architectures, modern on-device deep learning frameworks are proficient in utilizing computing resources in mobile platforms seamlessly, in terms of producing highly accurate results in less inference time. However, on the flip side, energy resources in a mobile device are typically limited. Hence, whenever a complex Deep Neural Network (DNN) architecture is fed into the on-device deep learning framework, while it achieves high prediction accuracy (and performance), it also urges huge energy demands during the runtime. Therefore, managing these resources efficiently within the spectrum of performance and energy efficiency is the newest challenge for any mobile application featuring data-driven intelligence beyond experimental evaluations. In this paper, first, we provide a timely review of recent advancements in on-device deep learning while empirically evaluating the performance metrics of current state-of-the-art ML architectures and conventional ML approaches with the emphasis given on energy characteristics by deploying them on a smart health application. With that, we are introducing a new framework through an energy-aware, adaptive model comprehension and realization (EAMCR) approach that can be utilized to make more robust and efficient inference decisions based on the available computing/energy resources in the mobile device during the runtime.
Exploiting High Performance Spiking Neural Networks with Efficient Spiking Patterns
Jan 29, 2023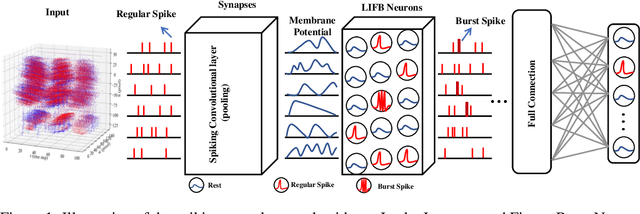
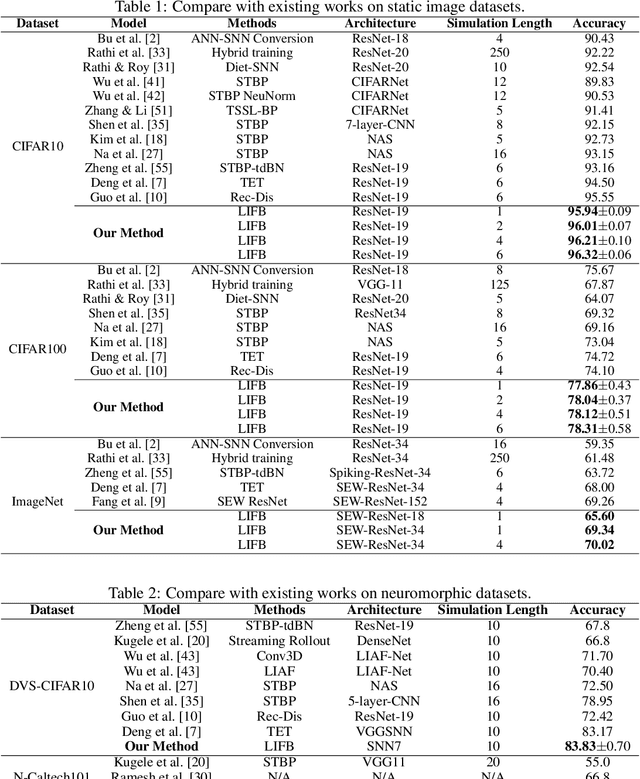
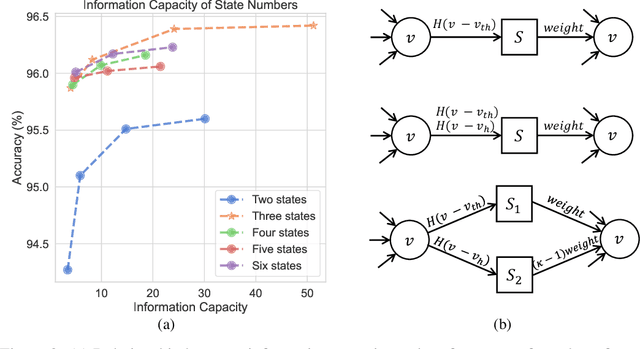
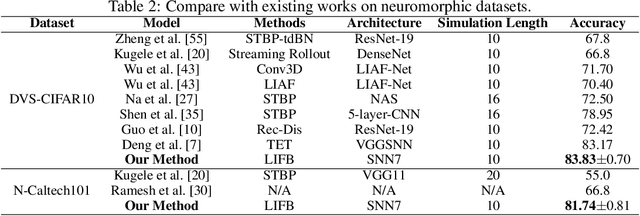
Spiking Neural Networks (SNNs) use discrete spike sequences to transmit information, which significantly mimics the information transmission of the brain. Although this binarized form of representation dramatically enhances the energy efficiency and robustness of SNNs, it also leaves a large gap between the performance of SNNs and Artificial Neural Networks based on real values. There are many different spike patterns in the brain, and the dynamic synergy of these spike patterns greatly enriches the representation capability. Inspired by spike patterns in biological neurons, this paper introduces the dynamic Burst pattern and designs the Leaky Integrate and Fire or Burst (LIFB) neuron that can make a trade-off between short-time performance and dynamic temporal performance from the perspective of network information capacity. LIFB neuron exhibits three modes, resting, Regular spike, and Burst spike. The burst density of the neuron can be adaptively adjusted, which significantly enriches the characterization capability. We also propose a decoupling method that can losslessly decouple LIFB neurons into equivalent LIF neurons, which demonstrates that LIFB neurons can be efficiently implemented on neuromorphic hardware. We conducted experiments on the static datasets CIFAR10, CIFAR100, and ImageNet, which showed that we greatly improved the performance of the SNNs while significantly reducing the network latency. We also conducted experiments on neuromorphic datasets DVS-CIFAR10 and NCALTECH101 and showed that we achieved state-of-the-art with a small network structure.
Deconfounding Duration Bias in Watch-time Prediction for Video Recommendation
Jun 13, 2022

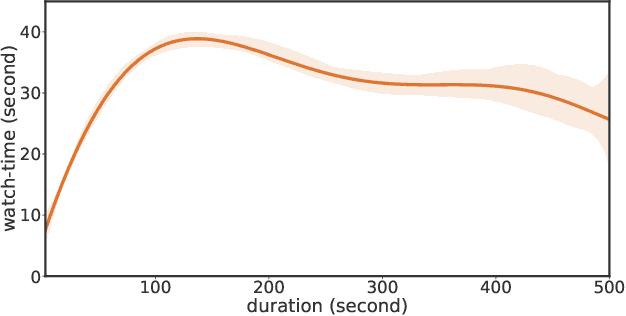
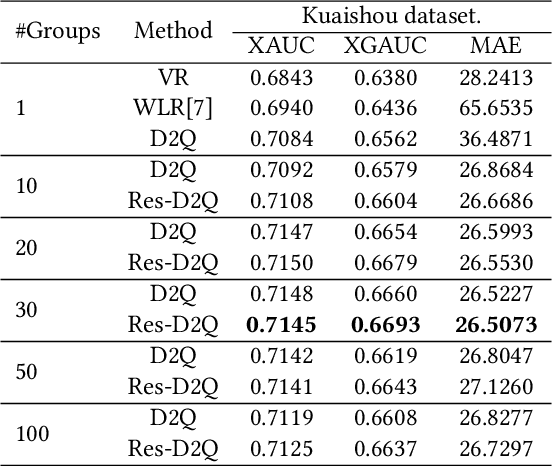
Watch-time prediction remains to be a key factor in reinforcing user engagement via video recommendations. It has become increasingly important given the ever-growing popularity of online videos. However, prediction of watch time not only depends on the match between the user and the video but is often mislead by the duration of the video itself. With the goal of improving watch time, recommendation is always biased towards videos with long duration. Models trained on this imbalanced data face the risk of bias amplification, which misguides platforms to over-recommend videos with long duration but overlook the underlying user interests. This paper presents the first work to study duration bias in watch-time prediction for video recommendation. We employ a causal graph illuminating that duration is a confounding factor that concurrently affects video exposure and watch-time prediction -- the first effect on video causes the bias issue and should be eliminated, while the second effect on watch time originates from video intrinsic characteristics and should be preserved. To remove the undesired bias but leverage the natural effect, we propose a Duration Deconfounded Quantile-based (D2Q) watch-time prediction framework, which allows for scalability to perform on industry production systems. Through extensive offline evaluation and live experiments, we showcase the effectiveness of this duration-deconfounding framework by significantly outperforming the state-of-the-art baselines. We have fully launched our approach on Kuaishou App, which has substantially improved real-time video consumption due to more accurate watch-time predictions.
Codebook Based Two-Time Scale Resource Allocation Design for IRS-Assisted eMBB-URLLC Systems
Aug 07, 2022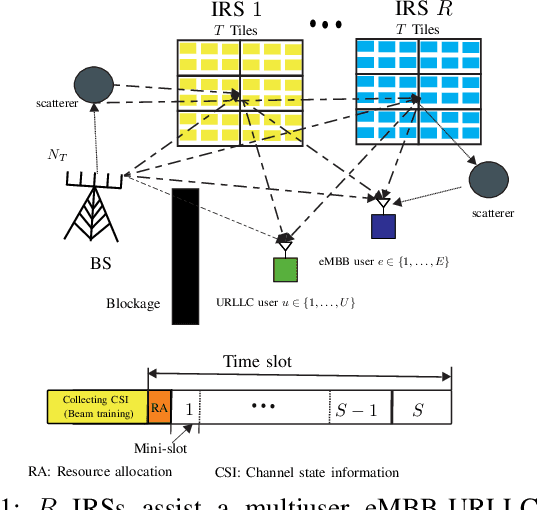
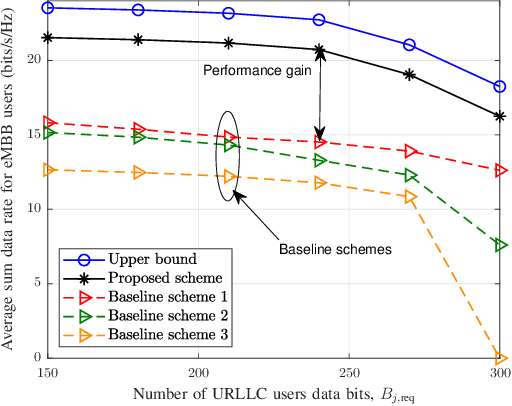
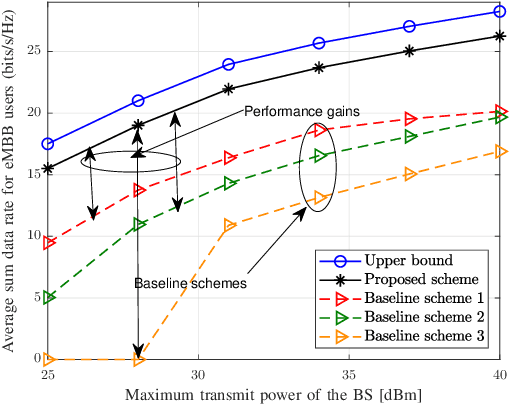
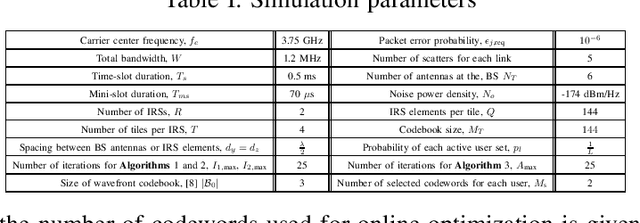
This paper investigates the resource allocation algorithm design for wireless systems assisted by large intelligent reflecting surfaces (IRSs) with coexisting enhanced mobile broadband (eMBB) and ultra reliable low-latency communication (URLLC) users. We consider a two-time scale resource allocation scheme, whereby the base station's precoders are optimized in each mini-slot to adapt to newly arriving URLLC traffic, whereas the IRS phase shifts are reconfigured only in each time slot to avoid excessive base station-IRS signaling. To facilitate efficient resource allocation design for large IRSs, we employ a codebook-based optimization framework, where the IRS is divided into several tiles and the phase-shift elements of each tile are selected from a pre-defined codebook. The resource allocation algorithm design is formulated as an optimization problem for the maximization of the average sum data rate of the eMBB users over a time slot while guaranteeing the quality-of-service (QoS) of each URLLC user in each mini-slot. An iterative algorithm based on alternating optimization (AO) is proposed to find a high-quality suboptimal solution. As a case study, the proposed algorithm is applied in an industrial indoor environment modelled via the Quadriga channel simulator. Our simulation results show that the proposed algorithm design enables the coexistence of eMBB and URLLC users and yields large performance gains compared to three baseline schemes. Furthermore, our simulation results reveal that the proposed two-time scale resource allocation design incurs only a small performance loss compared to the case when the IRSs are optimized in each mini-slot.
Geometric path augmentation for inference of sparsely observed stochastic nonlinear systems
Jan 19, 2023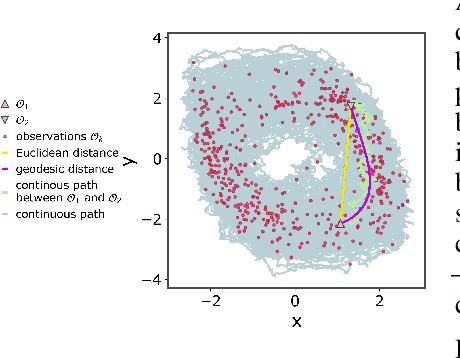
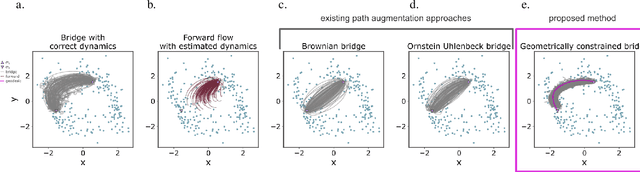
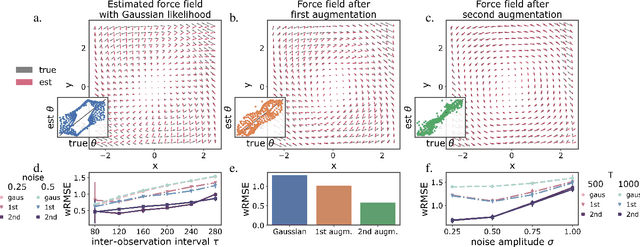
Stochastic evolution equations describing the dynamics of systems under the influence of both deterministic and stochastic forces are prevalent in all fields of science. Yet, identifying these systems from sparse-in-time observations remains still a challenging endeavour. Existing approaches focus either on the temporal structure of the observations by relying on conditional expectations, discarding thereby information ingrained in the geometry of the system's invariant density; or employ geometric approximations of the invariant density, which are nevertheless restricted to systems with conservative forces. Here we propose a method that reconciles these two paradigms. We introduce a new data-driven path augmentation scheme that takes the local observation geometry into account. By employing non-parametric inference on the augmented paths, we can efficiently identify the deterministic driving forces of the underlying system for systems observed at low sampling rates.
Warning: Humans Cannot Reliably Detect Speech Deepfakes
Jan 19, 2023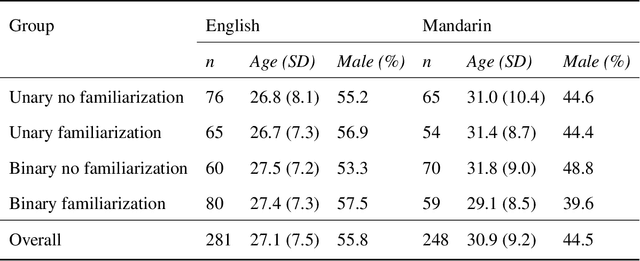
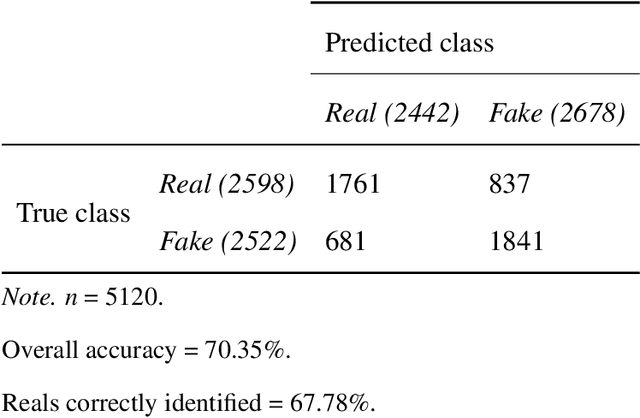
Speech deepfakes are artificial voices generated by machine learning models. Previous literature has highlighted deepfakes as one of the biggest threats to security arising from progress in AI due to their potential for misuse. However, studies investigating human detection capabilities are limited. We presented genuine and deepfake audio to $n$ = 529 individuals and asked them to identify the deepfakes. We ran our experiments in English and Mandarin to understand if language affects detection performance and decision-making rationale. Detection capability is unreliable. Listeners only correctly spotted the deepfakes 73% of the time, and there was no difference in detectability between the two languages. Increasing listener awareness by providing examples of speech deepfakes only improves results slightly. The difficulty of detecting speech deepfakes confirms their potential for misuse and signals that defenses against this threat are needed.
Correlation Clustering Algorithm for Dynamic Complete Signed Graphs: An Index-based Approach
Jan 01, 2023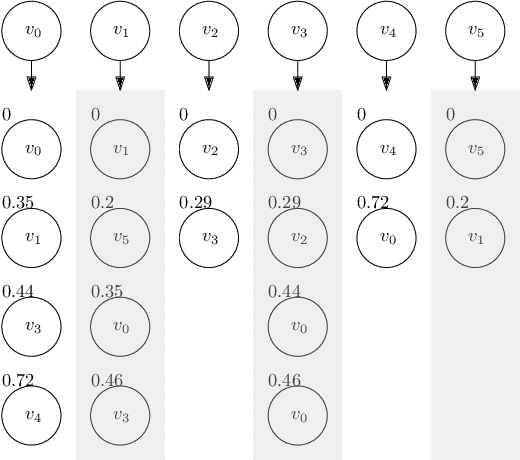
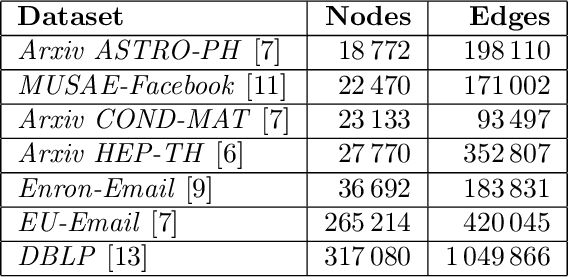
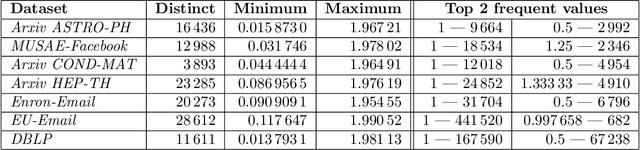
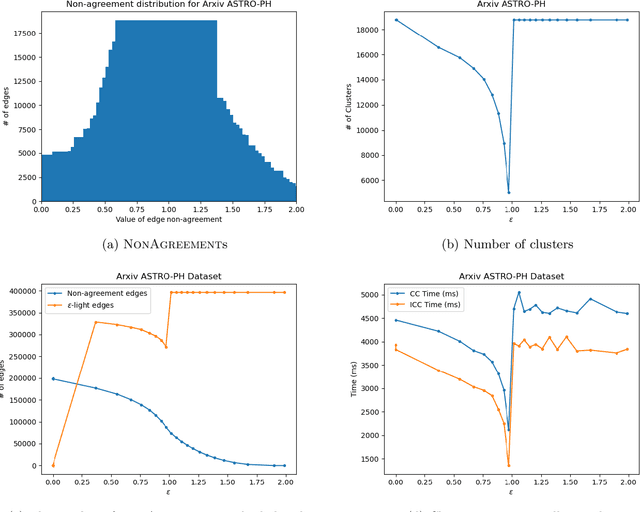
In this paper, we reduce the complexity of approximating the correlation clustering problem from $O(m\times\left( 2+ \alpha (G) \right)+n)$ to $O(m+n)$ for any given value of $\varepsilon$ for a complete signed graph with $n$ vertices and $m$ positive edges where $\alpha(G)$ is the arboricity of the graph. Our approach gives the same output as the original algorithm and makes it possible to implement the algorithm in a full dynamic setting where edge sign flipping and vertex addition/removal are allowed. Constructing this index costs $O(m)$ memory and $O(m\times\alpha(G))$ time. We also studied the structural properties of the non-agreement measure used in the approximation algorithm. The theoretical results are accompanied by a full set of experiments concerning seven real-world graphs. These results shows superiority of our index-based algorithm to the non-index one by a decrease of %34 in time on average.
Training a Deep Q-Learning Agent Inside a Generic Constraint Programming Solver
Jan 05, 2023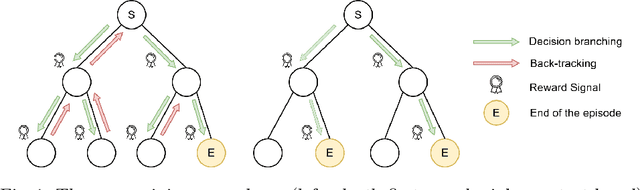
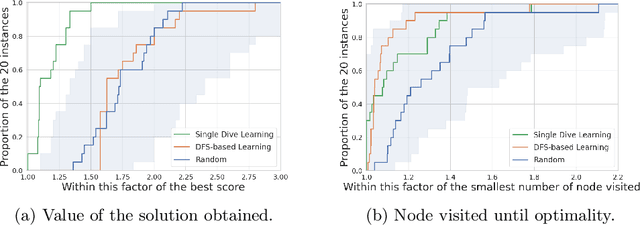
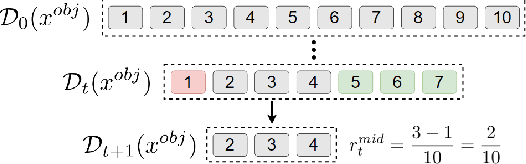
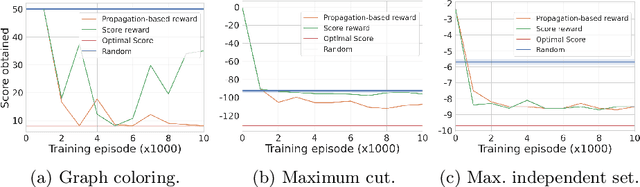
Constraint programming is known for being an efficient approach for solving combinatorial problems. Important design choices in a solver are the branching heuristics, which are designed to lead the search to the best solutions in a minimum amount of time. However, developing these heuristics is a time-consuming process that requires problem-specific expertise. This observation has motivated many efforts to use machine learning to automatically learn efficient heuristics without expert intervention. To the best of our knowledge, it is still an open research question. Although several generic variable-selection heuristics are available in the literature, the options for a generic value-selection heuristic are more scarce. In this paper, we propose to tackle this issue by introducing a generic learning procedure that can be used to obtain a value-selection heuristic inside a constraint programming solver. This has been achieved thanks to the combination of a deep Q-learning algorithm, a tailored reward signal, and a heterogeneous graph neural network architecture. Experiments on graph coloring, maximum independent set, and maximum cut problems show that our framework is able to find better solutions close to optimality without requiring a large amounts of backtracks while being generic.
OTFS-SCMA: A Downlink NOMA Scheme for Massive Connectivity in High Mobility Channels
Jan 03, 2023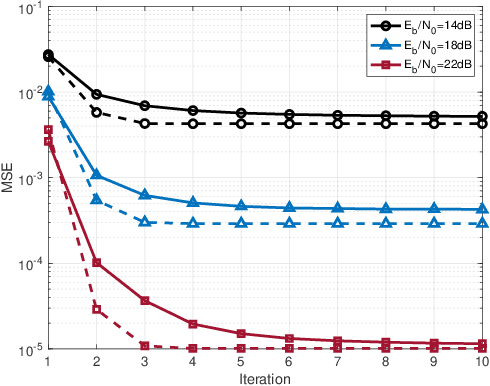
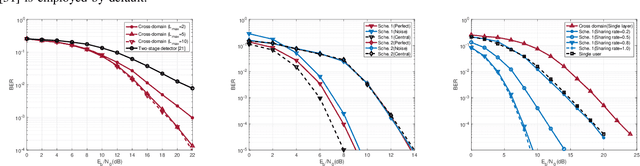
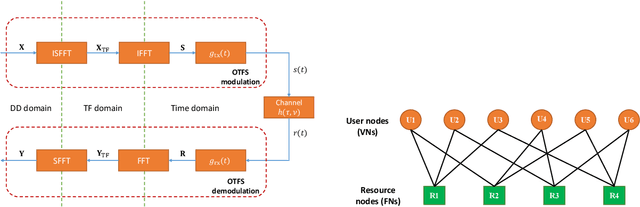
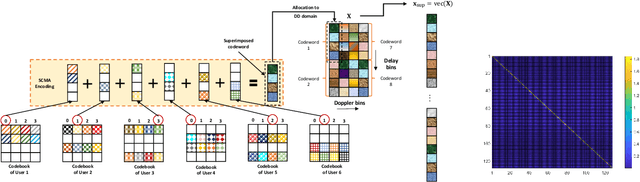
This paper studies a downlink system that combines orthogonal-time-frequency-space (OTFS) modulation and sparse code multiple access (SCMA) to support massive connectivity in high-mobility environments. We propose a cross-domain receiver for the considered OTFS-SCMA system which efficiently carries out OTFS symbol estimation and SCMA decoding in a joint manner. This is done by iteratively passing the extrinsic information between the time domain and the delay-Doppler (DD) domain via the corresponding unitary transformation to ensure the principal orthogonality of errors from each domain. We show that the proposed OTFS-SCMA detection algorithm exists at a fixed point in the state evolution when it converges. To further enhance the error performance of the proposed OTFS-SCMA system, we investigate the cooperation between downlink users to exploit the diversity gains and develop a distributed cooperative detection (DCD) algorithm with the aid of belief consensus. Our numerical results demonstrate the effectiveness and convergence of the proposed algorithm and show an increased spectral efficiency compared to the conventional OTFS transmission.
Neural Abstractions
Jan 27, 2023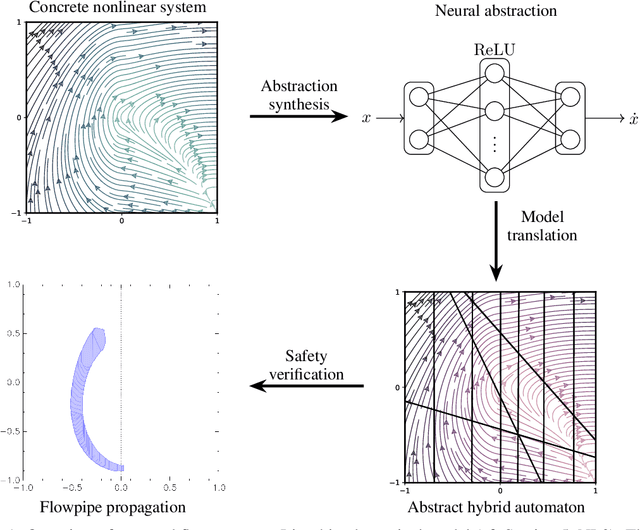
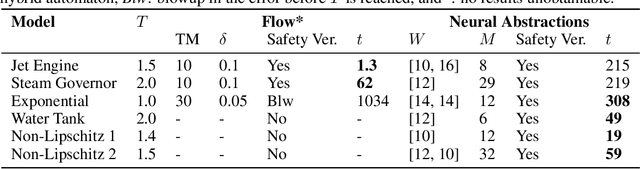
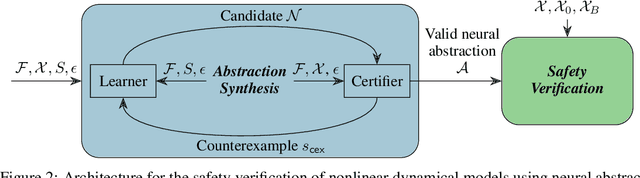
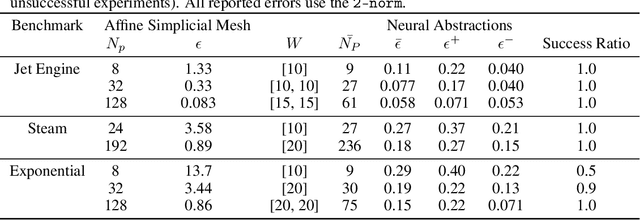
We present a novel method for the safety verification of nonlinear dynamical models that uses neural networks to represent abstractions of their dynamics. Neural networks have extensively been used before as approximators; in this work, we make a step further and use them for the first time as abstractions. For a given dynamical model, our method synthesises a neural network that overapproximates its dynamics by ensuring an arbitrarily tight, formally certified bound on the approximation error. For this purpose, we employ a counterexample-guided inductive synthesis procedure. We show that this produces a neural ODE with non-deterministic disturbances that constitutes a formal abstraction of the concrete model under analysis. This guarantees a fundamental property: if the abstract model is safe, i.e., free from any initialised trajectory that reaches an undesirable state, then the concrete model is also safe. By using neural ODEs with ReLU activation functions as abstractions, we cast the safety verification problem for nonlinear dynamical models into that of hybrid automata with affine dynamics, which we verify using SpaceEx. We demonstrate that our approach performs comparably to the mature tool Flow* on existing benchmark nonlinear models. We additionally demonstrate and that it is effective on models that do not exhibit local Lipschitz continuity, which are out of reach to the existing technologies.