 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LOSDD: Leave-Out Support Vector Data Description for Outlier Detection
Dec 27, 2022
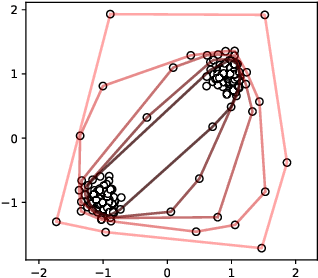
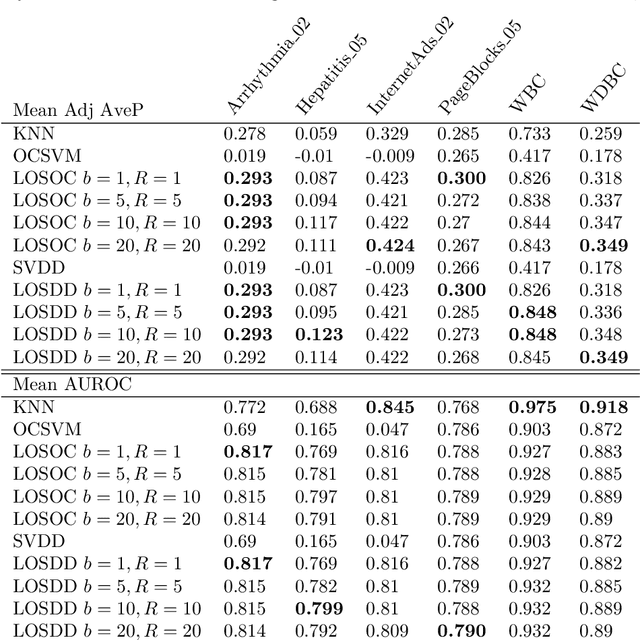
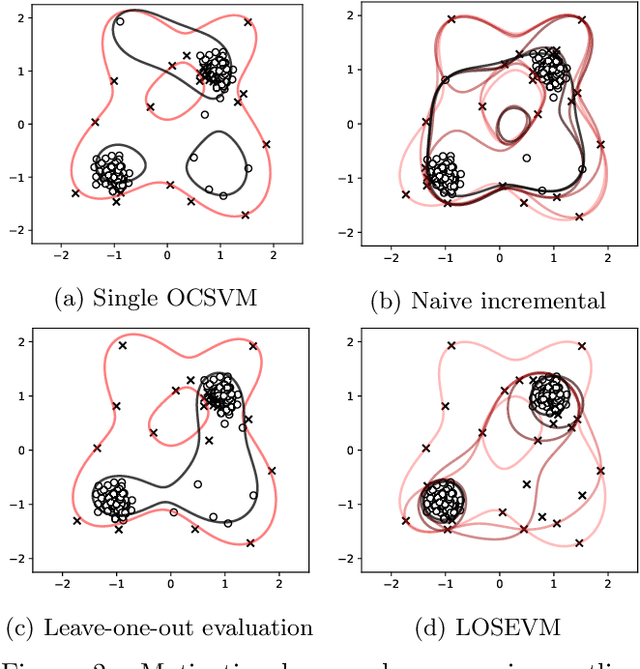
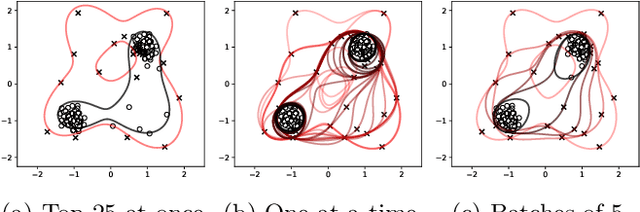
Support Vector Machines have been successfully used for one-class classification (OCSVM, SVDD) when trained on clean data, but they work much worse on dirty data: outliers present in the training data tend to become support vectors, and are hence considered "normal". In this article, we improve the effectiveness to detect outliers in dirty training data with a leave-out strategy: by temporarily omitting one candidate at a time, this point can be judged using the remaining data only. We show that this is more effective at scoring the outlierness of points than using the slack term of existing SVM-based approaches. Identified outliers can then be removed from the data, such that outliers hidden by other outliers can be identified, to reduce the problem of masking. Naively, this approach would require training N individual SVMs (and training $O(N^2)$ SVMs when iteratively removing the worst outliers one at a time), which is prohibitively expensive. We will discuss that only support vectors need to be considered in each step and that by reusing SVM parameters and weights, this incremental retraining can be accelerated substantially. By removing candidates in batches, we can further improve the processing time, although it obviously remains more costly than training a single SVM.
Moment-based Kalman Filter: Nonlinear Kalman Filtering with Exact Moment Propagation
Jan 22, 2023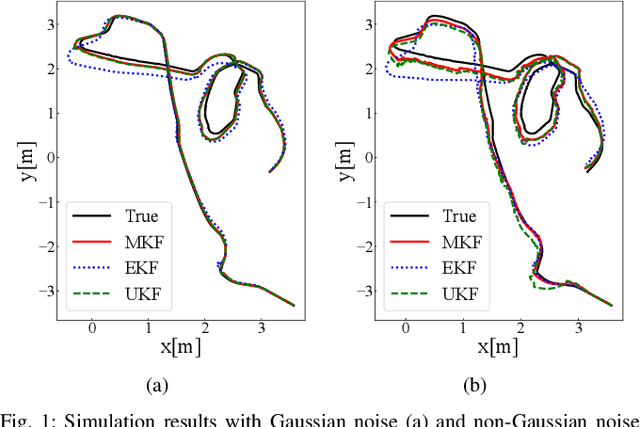
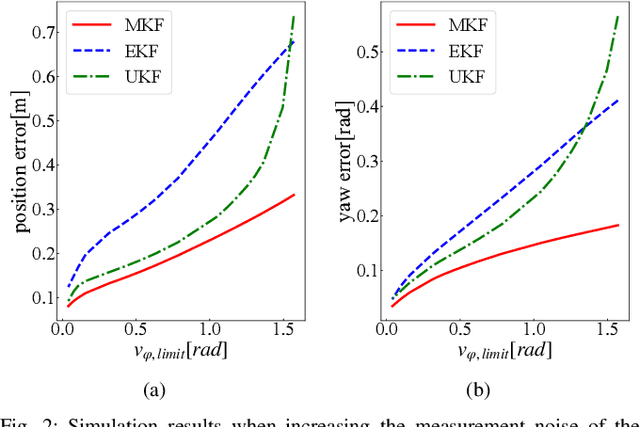
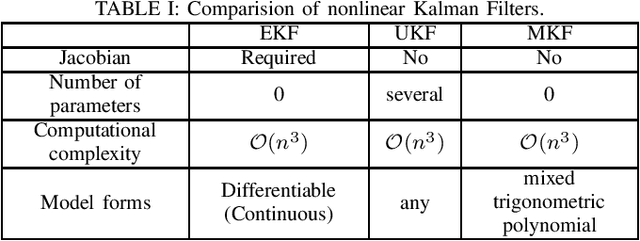
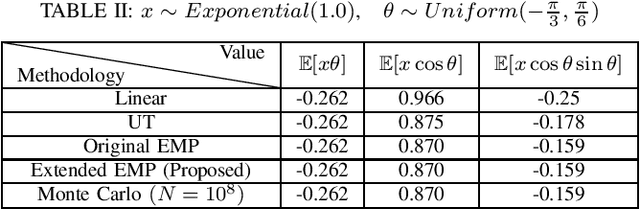
This paper develops a new nonlinear filter, called Moment-based Kalman Filter (MKF), using the exact moment propagation method. Existing state estimation methods use linearization techniques or sampling points to compute approximate values of moments. However, moment propagation of probability distributions of random variables through nonlinear process and measurement models play a key role in the development of state estimation and directly affects their performance. The proposed moment propagation procedure can compute exact moments for non-Gaussian as well as non-independent Gaussian random variables. Thus, MKF can propagate exact moments of uncertain state variables up to any desired order. MKF is derivative-free and does not require tuning parameters. Moreover, MKF has the same computation time complexity as the extended or unscented Kalman filters, i.e., EKF and UKF. The experimental evaluations show that MKF is the preferred filter in comparison to EKF and UKF and outperforms both filters in non-Gaussian noise regimes.
IMPORTANT-Net: Integrated MRI Multi-Parameter Reinforcement Fusion Generator with Attention Network for Synthesizing Absent Data
Feb 03, 2023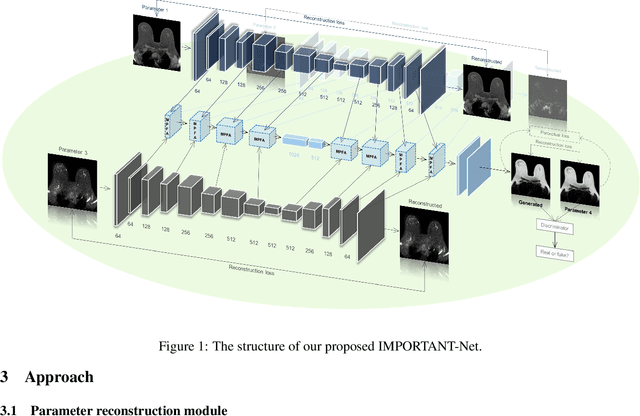
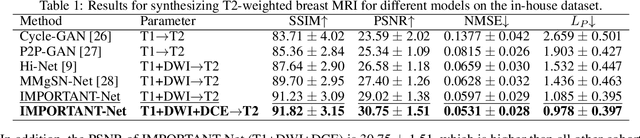
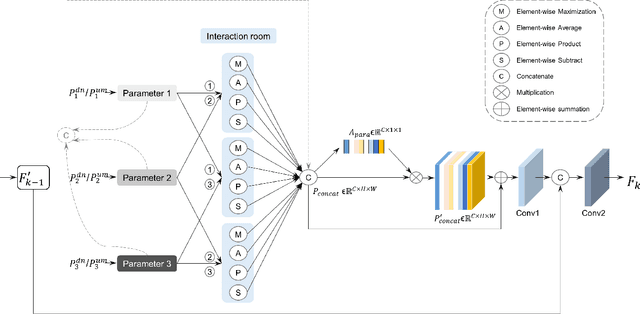
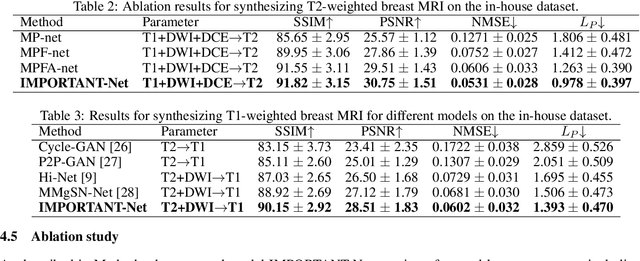
Magnetic resonance imaging (MRI) is highly sensitive for lesion detection in the breasts. Sequences obtained with different settings can capture the specific characteristics of lesions. Such multi-parameter MRI information has been shown to improve radiologist performance in lesion classification, as well as improving the performance of artificial intelligence models in various tasks. However, obtaining multi-parameter MRI makes the examination costly in both financial and time perspectives, and there may be safety concerns for special populations, thus making acquisition of the full spectrum of MRI sequences less durable. In this study, different than naive input fusion or feature concatenation from existing MRI parameters, a novel $\textbf{I}$ntegrated MRI $\textbf{M}$ulti-$\textbf{P}$arameter reinf$\textbf{O}$rcement fusion generato$\textbf{R}$ wi$\textbf{T}$h $\textbf{A}$tte$\textbf{NT}$ion Network (IMPORTANT-Net) is developed to generate missing parameters. First, the parameter reconstruction module is used to encode and restore the existing MRI parameters to obtain the corresponding latent representation information at any scale level. Then the multi-parameter fusion with attention module enables the interaction of the encoded information from different parameters through a set of algorithmic strategies, and applies different weights to the information through the attention mechanism after information fusion to obtain refined representation information. Finally, a reinforcement fusion scheme embedded in a $V^{-}$-shape generation module is used to combine the hierarchical representations to generate the missing MRI parameter. Results showed that our IMPORTANT-Net is capable of generating missing MRI parameters and outperforms comparable state-of-the-art networks. Our code is available at https://github.com/Netherlands-Cancer-Institute/MRI_IMPORTANT_NET.
Clustered Embedding Learning for Recommender Systems
Feb 03, 2023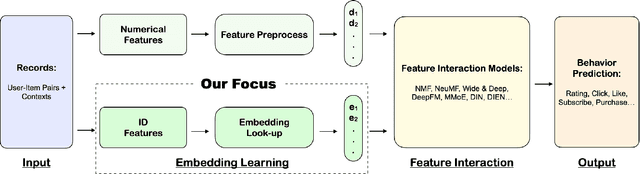
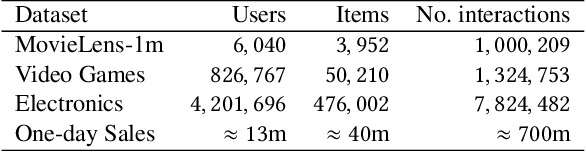
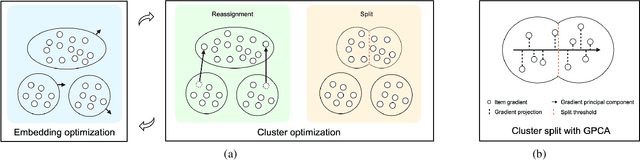
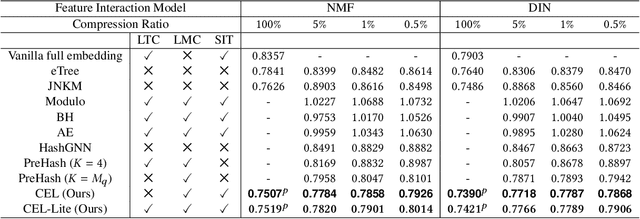
In recent years, recommender systems have advanced rapidly, where embedding learning for users and items plays a critical role. A standard method learns a unique embedding vector for each user and item. However, such a method has two important limitations in real-world applications: 1) it is hard to learn embeddings that generalize well for users and items with rare interactions on their own; and 2) it may incur unbearably high memory costs when the number of users and items scales up. Existing approaches either can only address one of the limitations or have flawed overall performances. In this paper, we propose Clustered Embedding Learning (CEL) as an integrated solution to these two problems. CEL is a plug-and-play embedding learning framework that can be combined with any differentiable feature interaction model. It is capable of achieving improved performance, especially for cold users and items, with reduced memory cost. CEL enables automatic and dynamic clustering of users and items in a top-down fashion, where clustered entities jointly learn a shared embedding. The accelerated version of CEL has an optimal time complexity, which supports efficient online updates. Theoretically, we prove the identifiability and the existence of a unique optimal number of clusters for CEL in the context of nonnegative matrix factorization. Empirically, we validate the effectiveness of CEL on three public datasets and one business dataset, showing its consistently superior performance against current state-of-the-art methods. In particular, when incorporating CEL into the business model, it brings an improvement of $+0.6\%$ in AUC, which translates into a significant revenue gain; meanwhile, the size of the embedding table gets $2650$ times smaller.
HDFormer: High-order Directed Transformer for 3D Human Pose Estimation
Feb 03, 2023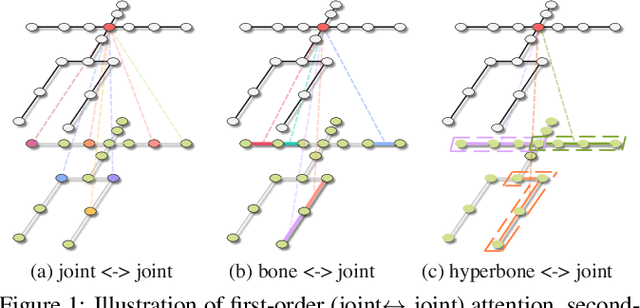
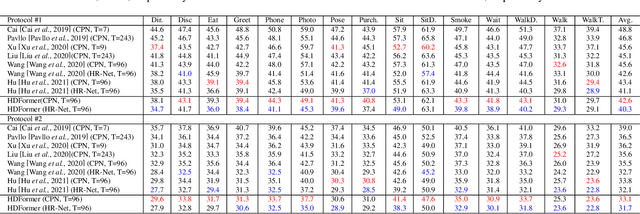
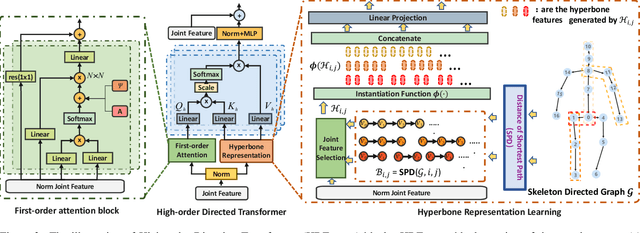
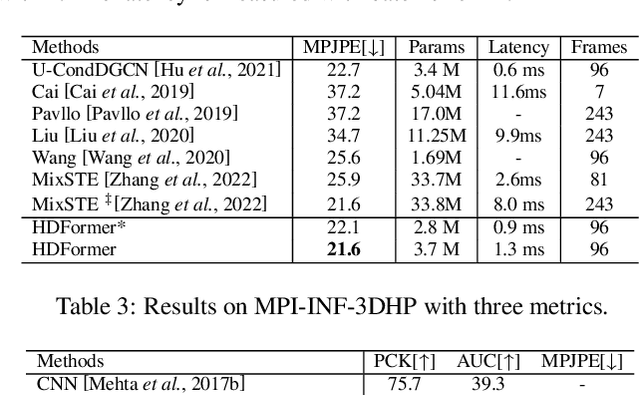
Human pose estimation is a complicated structured data sequence modeling task. Most existing methods only consider the pair-wise interaction of human body joints in model learning. Unfortunately, this causes 3D pose estimation to fail in difficult cases such as $\textit{joints overlapping}$, and pose $\textit{fast-changing}$, as pair-wise relations cannot exploit fine-grained human body priors in pose estimation. To this end, we revamped the 3D pose estimation framework with a $\textit{High-order}$ $\textit{Directed}$ $\textit{Transformer}$ (HDFormer), which coherently exploits the high-order bones and joints relevances to boost the performance of pose estimation. Specifically, HDFormer adopts both self-attention and high-order attention schemes to build up a multi-order attention module to perform the information flow interaction including the first-order $"\textit{joint$\leftrightarrow$joint}"$, second-order $"\textit{bone$\leftrightarrow$joint}"$ as well as high-order $"\textit{hyperbone$\leftrightarrow$joint}"$ relationships (hyperbone is defined as a joint set), compensating the hard cases prediction in fast-changing and heavy occlusion scenarios. Moreover, modernized CNN techniques are applied to upgrade the transformer-based architecture to speed up the HDFormer, achieving a favorable trade-off between effectiveness and efficiency. We compare our model with other SOTA models on the datasets Human3.6M and MPI-INF-3DHP. The results demonstrate that the proposed HDFormer achieves superior performance with only $\textbf{1/10}$ parameters and much lower computational cost compared to the current SOTAs. Moreover, HDFormer can be applied to various types of real-world applications, enabling real-time and accurate 3D pose estimation. The source code is in https://github.com/hyer/HDFormer.
Continuous-time Analysis for Variational Inequalities: An Overview and Desiderata
Jul 14, 2022Algorithms that solve zero-sum games, multi-objective agent objectives, or, more generally, variational inequality (VI) problems are notoriously unstable on general problems. Owing to the increasing need for solving such problems in machine learning, this instability has been highlighted in recent years as a significant research challenge. In this paper, we provide an overview of recent progress in the use of continuous-time perspectives in the analysis and design of methods targeting the broad VI problem class. Our presentation draws parallels between single-objective problems and multi-objective problems, highlighting the challenges of the latter. We also formulate various desiderata for algorithms that apply to general VIs and we argue that achieving these desiderata may profit from an understanding of the associated continuous-time dynamics.
Neural Dynamic Focused Topic Model
Jan 26, 2023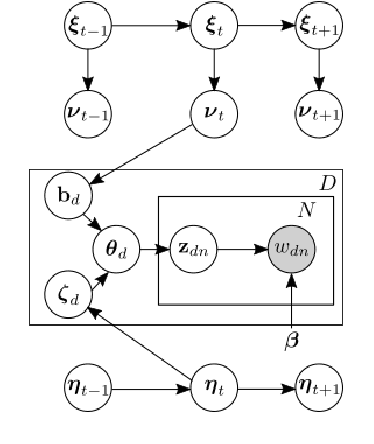
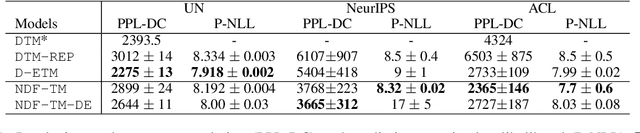

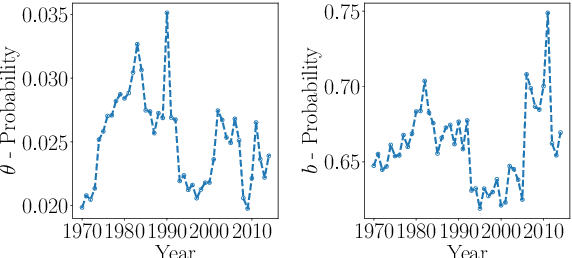
Topic models and all their variants analyse text by learning meaningful representations through word co-occurrences. As pointed out by Williamson et al. (2010), such models implicitly assume that the probability of a topic to be active and its proportion within each document are positively correlated. This correlation can be strongly detrimental in the case of documents created over time, simply because recent documents are likely better described by new and hence rare topics. In this work we leverage recent advances in neural variational inference and present an alternative neural approach to the dynamic Focused Topic Model. Indeed, we develop a neural model for topic evolution which exploits sequences of Bernoulli random variables in order to track the appearances of topics, thereby decoupling their activities from their proportions. We evaluate our model on three different datasets (the UN general debates, the collection of NeurIPS papers, and the ACL Anthology dataset) and show that it (i) outperforms state-of-the-art topic models in generalization tasks and (ii) performs comparably to them on prediction tasks, while employing roughly the same number of parameters, and converging about two times faster. Source code to reproduce our experiments is available online.
Neuromorphic spintronics accelerated by an unconventional data-driven Thiele equation approach
Jan 26, 2023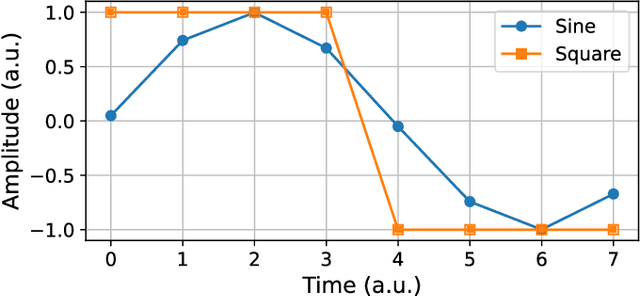
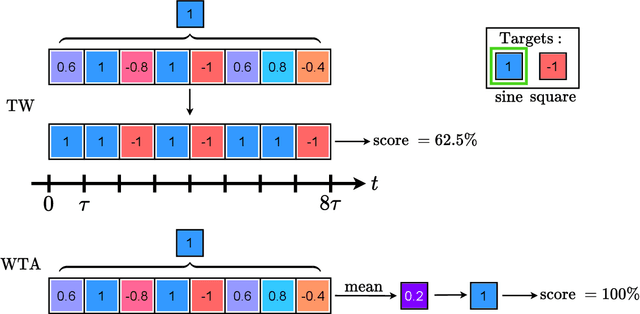
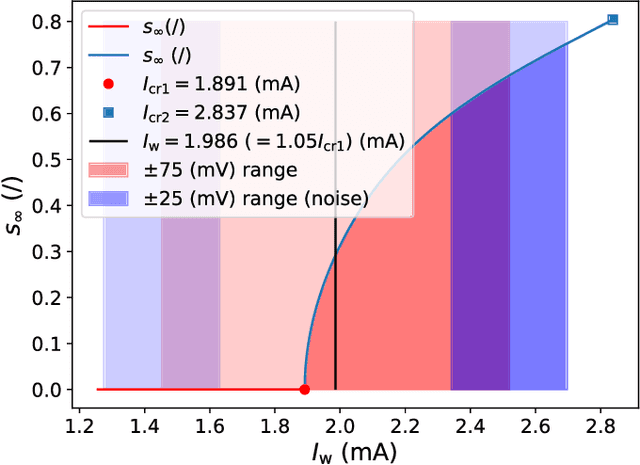
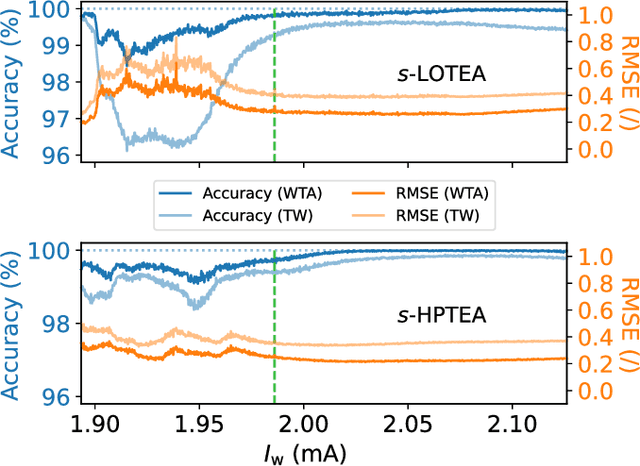
A hardware neural network based on a single spin-torque vortex nano-oscillator is designed using time-multiplexing. The behavior of the spin-torque vortex nano-oscillator is simulated with an improved ultra-fast and quantitative model based on the Thiele equation approach. Different mathematical and numerical adaptations are brought to the model in order to increase the accuracy and the speed of the simulations. A benchmark task of waveform classification is designed to assess the performance of the neural network in the framework of reservoir computing and compare two different versions of the model. The obtained results allow to conclude on the ability of the system to effectively classify sine and square signals with high accuracy and low root-mean-square error, reflecting high confidence cognition. Given the high throughput of the simulations, two innovative parametric studies on the dc bias current intensity and the level of noise in the system are performed to demonstrate the value of our models. The efficiency of our system is also tested during speech recognition and shows the agreement between these models and the corresponding experimental measurements.
Minerva: A File-Based Ransomware Detector
Jan 26, 2023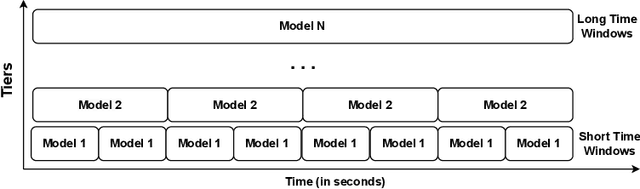
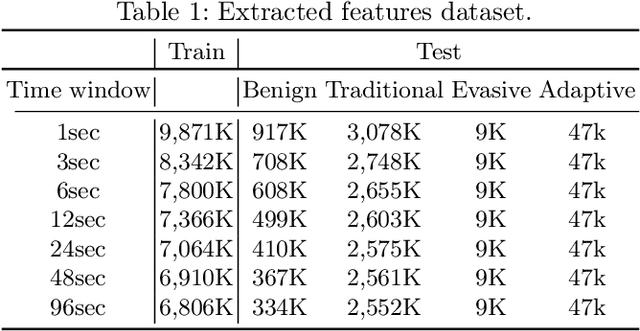
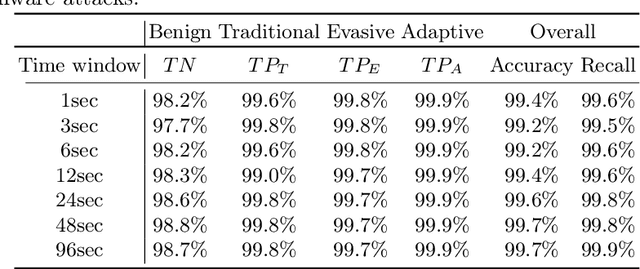
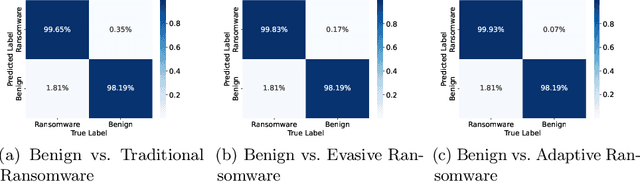
Ransomware is a rapidly evolving type of malware designed to encrypt user files on a device, making them inaccessible in order to exact a ransom. Ransomware attacks resulted in billions of dollars in damages in recent years and are expected to cause hundreds of billions more in the next decade. With current state-of-the-art process-based detectors being heavily susceptible to evasion attacks, no comprehensive solution to this problem is available today. This paper presents Minerva, a new approach to ransomware detection. Unlike current methods focused on identifying ransomware based on process-level behavioral modeling, Minerva detects ransomware by building behavioral profiles of files based on all the operations they receive in a time window. Minerva addresses some of the critical challenges associated with process-based approaches, specifically their vulnerability to complex evasion attacks. Our evaluation of Minerva demonstrates its effectiveness in detecting ransomware attacks, including those that are able to bypass existing defenses. Our results show that Minerva identifies ransomware activity with an average accuracy of 99.45% and an average recall of 99.66%, with 99.97% of ransomware detected within 1 second.
Trajectory-Aware Eligibility Traces for Off-Policy Reinforcement Learning
Jan 26, 2023

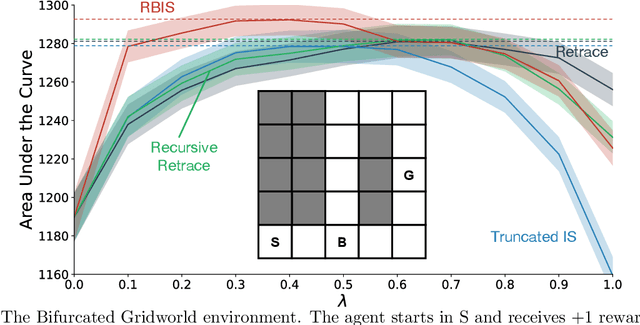
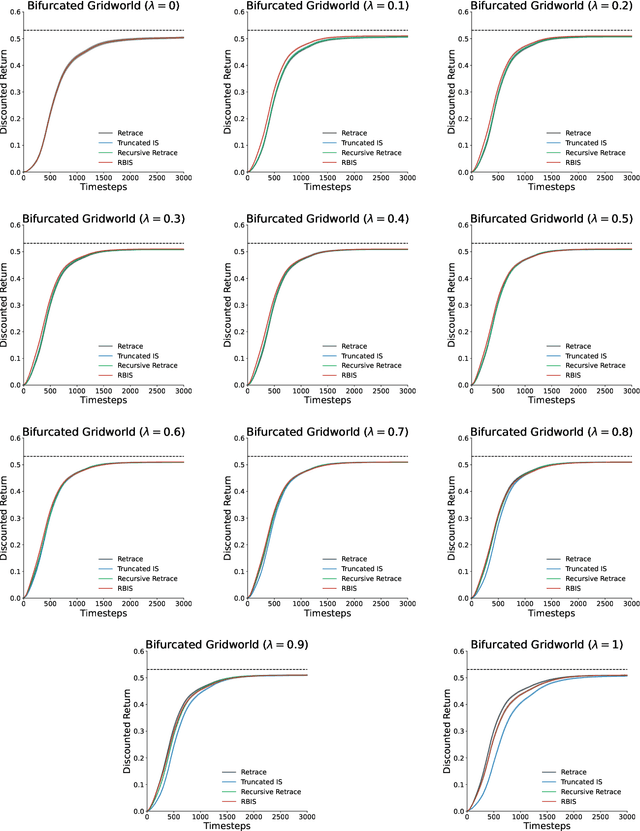
Off-policy learning from multistep returns is crucial for sample-efficient reinforcement learning, but counteracting off-policy bias without exacerbating variance is challenging. Classically, off-policy bias is corrected in a per-decision manner: past temporal-difference errors are re-weighted by the instantaneous Importance Sampling (IS) ratio after each action via eligibility traces. Many off-policy algorithms rely on this mechanism, along with differing protocols for cutting the IS ratios to combat the variance of the IS estimator. Unfortunately, once a trace has been fully cut, the effect cannot be reversed. This has led to the development of credit-assignment strategies that account for multiple past experiences at a time. These trajectory-aware methods have not been extensively analyzed, and their theoretical justification remains uncertain. In this paper, we propose a multistep operator that can express both per-decision and trajectory-aware methods. We prove convergence conditions for our operator in the tabular setting, establishing the first guarantees for several existing methods as well as many new ones. Finally, we introduce Recency-Bounded Importance Sampling (RBIS), which leverages trajectory awareness to perform robustly across $\lambda$-values in an off-policy control task.