 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Transferring Multiple Policies to Hotstart Reinforcement Learning in an Air Compressor Management Problem
Jan 30, 2023
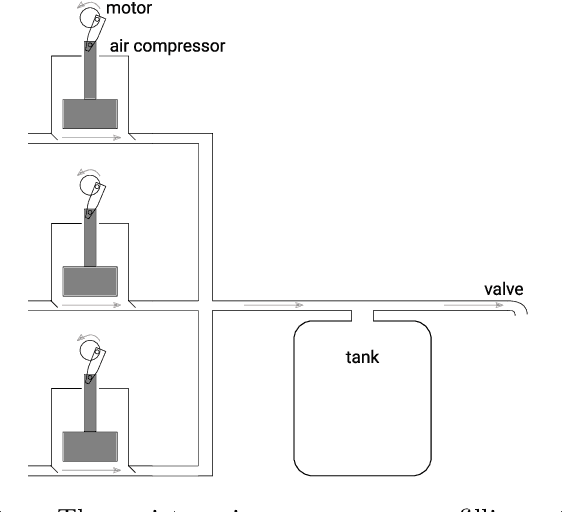
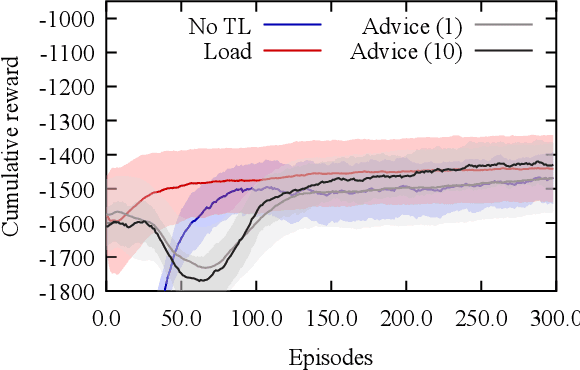
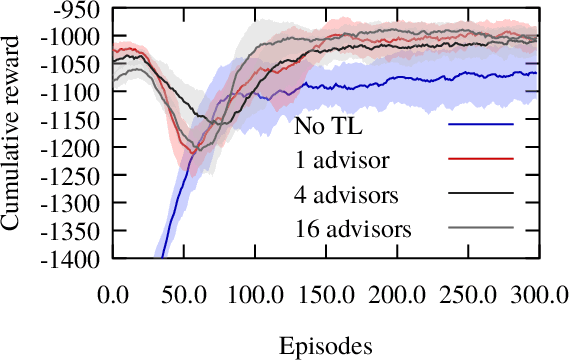
Many instances of similar or almost-identical industrial machines or tools are often deployed at once, or in quick succession. For instance, a particular model of air compressor may be installed at hundreds of customers. Because these tools perform distinct but highly similar tasks, it is interesting to be able to quickly produce a high-quality controller for machine $N+1$ given the controllers already produced for machines $1..N$. This is even more important when the controllers are learned through Reinforcement Learning, as training takes time, energy and other resources. In this paper, we apply Policy Intersection, a Policy Shaping method, to help a Reinforcement Learning agent learn to solve a new variant of a compressors control problem faster, by transferring knowledge from several previously learned controllers. We show that our approach outperforms loading an old controller, and significantly improves performance in the long run.
Modelling the performance of delivery vehicles across urban micro-regions to accelerate the transition to cargo-bike logistics
Jan 30, 2023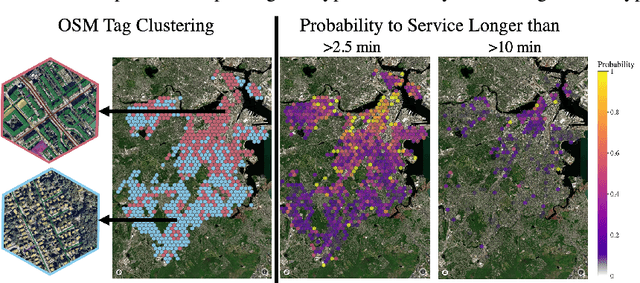
Light goods vehicles (LGV) used extensively in the last mile of delivery are one of the leading polluters in cities. Cargo-bike logistics has been put forward as a high impact candidate for replacing LGVs, with experts estimating over half of urban van deliveries being replaceable by cargo bikes, due to their faster speeds, shorter parking times and more efficient routes across cities. By modelling the relative delivery performance of different vehicle types across urban micro-regions, machine learning can help operators evaluate the business and environmental impact of adding cargo-bikes to their fleets. In this paper, we introduce two datasets, and present initial progress in modelling urban delivery service time (e.g. cruising for parking, unloading, walking). Using Uber's H3 index to divide the cities into hexagonal cells, and aggregating OpenStreetMap tags for each cell, we show that urban context is a critical predictor of delivery performance.
Beyond Uniform Smoothness: A Stopped Analysis of Adaptive SGD
Feb 13, 2023This work considers the problem of finding a first-order stationary point of a non-convex function with potentially unbounded smoothness constant using a stochastic gradient oracle. We focus on the class of $(L_0,L_1)$-smooth functions proposed by Zhang et al. (ICLR'20). Empirical evidence suggests that these functions more closely captures practical machine learning problems as compared to the pervasive $L_0$-smoothness. This class is rich enough to include highly non-smooth functions, such as $\exp(L_1 x)$ which is $(0,\mathcal{O}(L_1))$-smooth. Despite the richness, an emerging line of works achieves the $\widetilde{\mathcal{O}}(\frac{1}{\sqrt{T}})$ rate of convergence when the noise of the stochastic gradients is deterministically and uniformly bounded. This noise restriction is not required in the $L_0$-smooth setting, and in many practical settings is either not satisfied, or results in weaker convergence rates with respect to the noise scaling of the convergence rate. We develop a technique that allows us to prove $\mathcal{O}(\frac{\mathrm{poly}\log(T)}{\sqrt{T}})$ convergence rates for $(L_0,L_1)$-smooth functions without assuming uniform bounds on the noise support. The key innovation behind our results is a carefully constructed stopping time $\tau$ which is simultaneously "large" on average, yet also allows us to treat the adaptive step sizes before $\tau$ as (roughly) independent of the gradients. For general $(L_0,L_1)$-smooth functions, our analysis requires the mild restriction that the multiplicative noise parameter $\sigma_1 < 1$. For a broad subclass of $(L_0,L_1)$-smooth functions, our convergence rate continues to hold when $\sigma_1 \geq 1$. By contrast, we prove that many algorithms analyzed by prior works on $(L_0,L_1)$-smooth optimization diverge with constant probability even for smooth and strongly-convex functions when $\sigma_1 > 1$.
A Domain Decomposition-Based CNN-DNN Architecture for Model Parallel Training Applied to Image Recognition Problems
Feb 13, 2023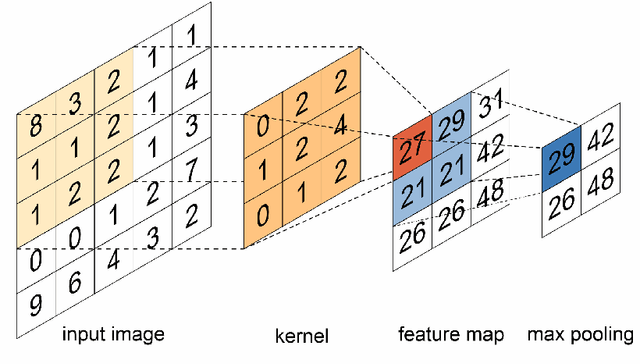
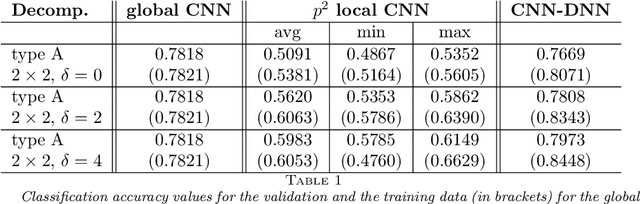
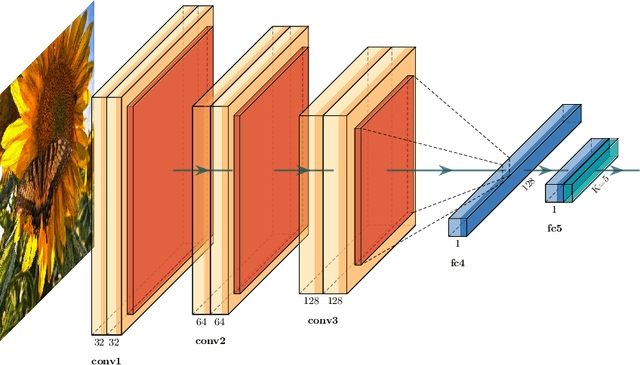
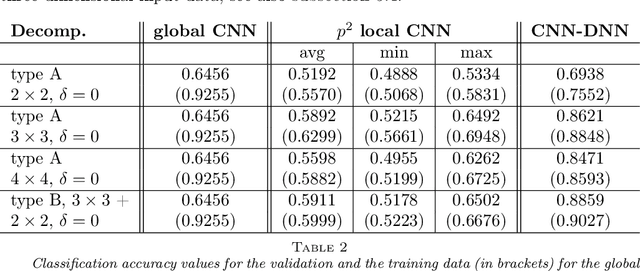
Deep neural networks (DNNs) and, in particular, convolutional neural networks (CNNs) have brought significant advances in a wide range of modern computer application problems. However, the increasing availability of large amounts of datasets as well as the increasing available computational power of modern computers lead to a steady growth in the complexity and size of DNN and CNN models, and thus, to longer training times. Hence, various methods and attempts have been developed to accelerate and parallelize the training of complex network architectures. In this work, a novel CNN-DNN architecture is proposed that naturally supports a model parallel training strategy and that is loosely inspired by two-level domain decomposition methods (DDM). First, local CNN models, that is, subnetworks, are defined that operate on overlapping or nonoverlapping parts of the input data, for example, sub-images. The subnetworks can be trained completely in parallel. Each subnetwork outputs a local decision for the given machine learning problem which is exclusively based on the respective local input data. Subsequently, an additional DNN model is trained which evaluates the local decisions of the local subnetworks and generates a final, global decision. With respect to the analogy to DDM, the DNN can be interpreted as a coarse problem and hence, the new approach can be interpreted as a two-level domain decomposition. In this paper, solely image classification problems using CNNs are considered. Experimental results for different 2D image classification problems are provided as well as a face recognition problem, and a classification problem for 3D computer tomography (CT) scans. The results show that the proposed approach can significantly accelerate the required training time compared to the global model and, additionally, can also help to improve the accuracy of the underlying classification problem.
GFM: Building Geospatial Foundation Models via Continual Pretraining
Feb 09, 2023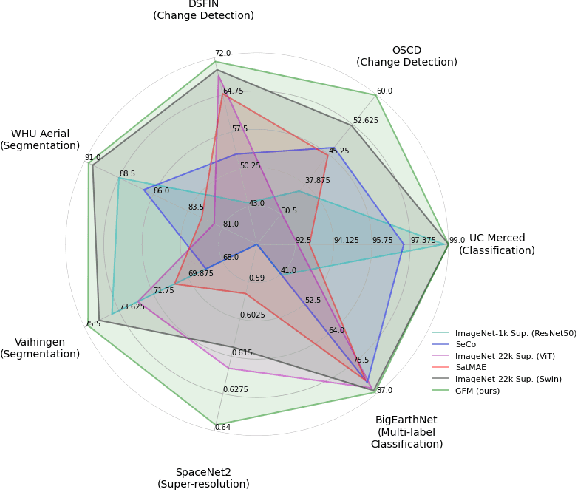
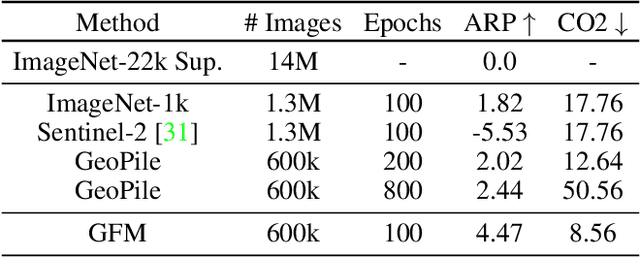

Geospatial technologies are becoming increasingly essential in our world for a large range of tasks, such as earth monitoring and natural disaster response. To help improve the applicability and performance of deep learning models on these geospatial tasks, various works have pursued the idea of a geospatial foundation model, i.e., training networks from scratch on a large corpus of remote sensing imagery. However, this approach often requires a significant amount of data and training time to achieve suitable performance, especially when employing large state-of-the-art transformer models. In light of these challenges, we investigate a sustainable approach to building geospatial foundation models. In our investigations, we discover two important factors in the process. First, we find that the selection of pretraining data matters, even within the geospatial domain. We therefore gather a concise yet effective dataset for pretraining. Second, we find that available pretrained models on diverse datasets like ImageNet-22k should not be ignored when building geospatial foundation models, as their representations are still surprisingly effective. Rather, by leveraging their representations, we can build strong models for geospatial applications in a sustainable manner. To this end, we formulate a multi-objective continual pretraining approach for training sustainable geospatial foundation models. We experiment on a wide variety of downstream datasets and tasks, achieving strong performance across the board in comparison to ImageNet baselines and state-of-the-art geospatial pretrained models.
Scaling Self-Supervised End-to-End Driving with Multi-View Attention Learning
Feb 09, 2023
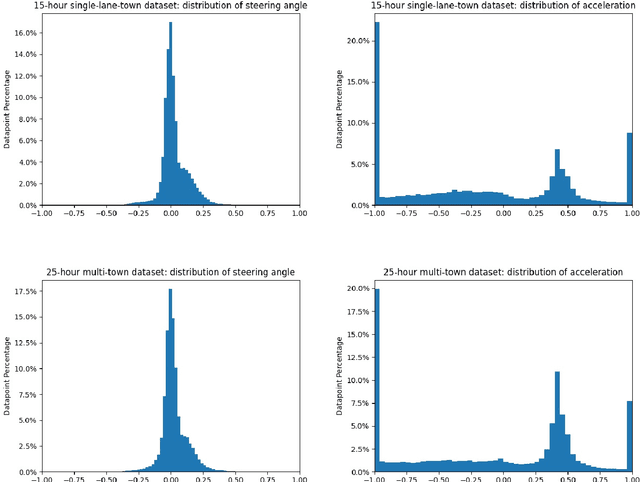
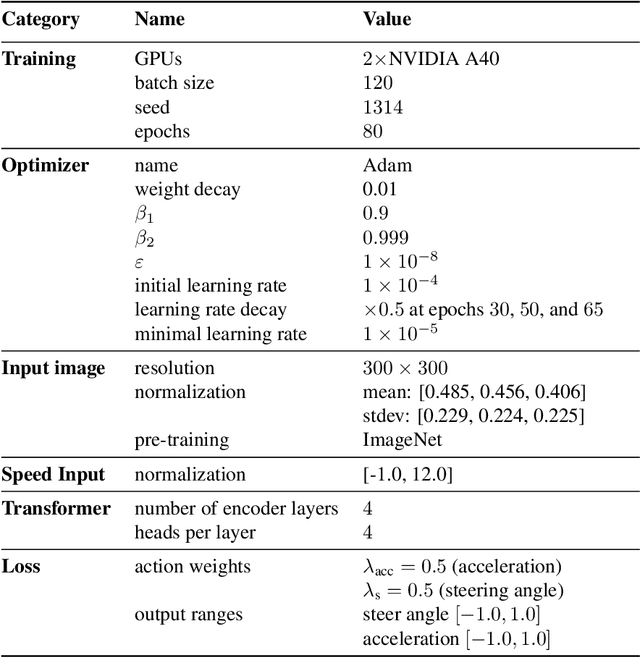

On end-to-end driving, a large amount of expert driving demonstrations is used to train an agent that mimics the expert by predicting its control actions. This process is self-supervised on vehicle signals (e.g., steering angle, acceleration) and does not require extra costly supervision (human labeling). Yet, the improvement of existing self-supervised end-to-end driving models has mostly given room to modular end-to-end models where labeling data intensive format such as semantic segmentation are required during training time. However, we argue that the latest self-supervised end-to-end models were developed in sub-optimal conditions with low-resolution images and no attention mechanisms. Further, those models are confined with limited field of view and far from the human visual cognition which can quickly attend far-apart scene features, a trait that provides an useful inductive bias. In this context, we present a new end-to-end model, trained by self-supervised imitation learning, leveraging a large field of view and a self-attention mechanism. These settings are more contributing to the agent's understanding of the driving scene, which brings a better imitation of human drivers. With only self-supervised training data, our model yields almost expert performance in CARLA's Nocrash metrics and could be rival to the SOTA models requiring large amounts of human labeled data. To facilitate further research, our code will be released.
NLP-based Decision Support System for Examination of Eligibility Criteria from Securities Prospectuses at the German Central Bank
Feb 09, 2023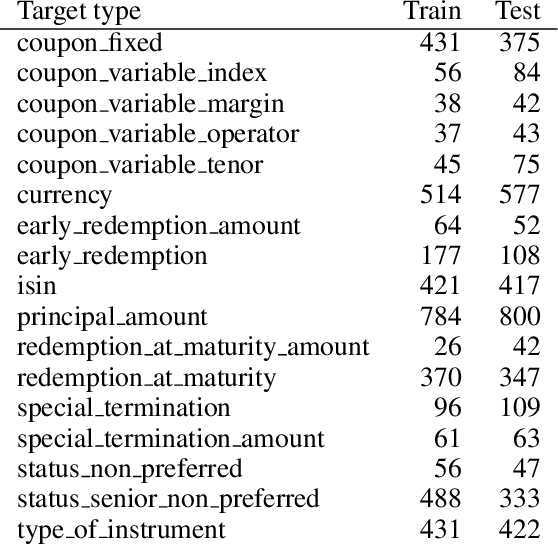
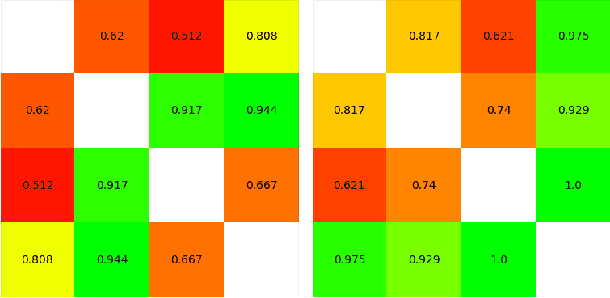
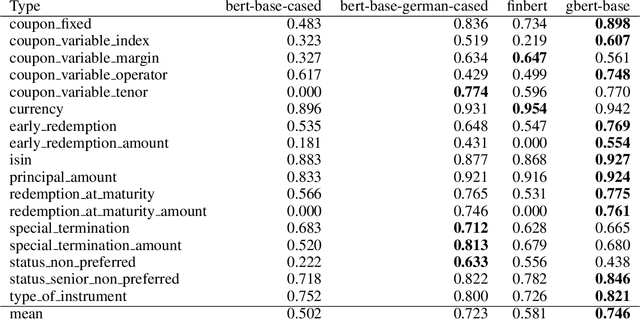
As part of its digitization initiative, the German Central Bank (Deutsche Bundesbank) wants to examine the extent to which natural Language Processing (NLP) can be used to make independent decisions upon the eligibility criteria of securities prospectuses. Every month, the Directorate General Markets at the German Central Bank receives hundreds of scanned prospectuses in PDF format, which must be manually processed to decide upon their eligibility. We found that this tedious and time-consuming process can be (semi-)automated by employing modern NLP model architectures, which learn the linguistic feature representation in text to identify the present eligible and ineligible criteria. The proposed Decision Support System provides decisions of document-level eligibility criteria accompanied by human-understandable explanations of the decisions. The aim of this project is to model the described use case and to evaluate the extent to which current research results from the field of NLP can be applied to this problem. After creating a heterogeneous domain-specific dataset containing annotations of eligible and non-eligible mentions of relevant criteria, we were able to successfully build, train and deploy a semi-automatic decider model. This model is based on transformer-based language models and decision trees, which integrate the established rule-based parts of the decision processes. Results suggest that it is possible to efficiently model the problem and automate decision making to more than 90% for many of the considered eligibility criteria.
Chance-Constrained Trajectory Optimization for High-DOF Robots in Uncertain Environments
Jan 31, 2023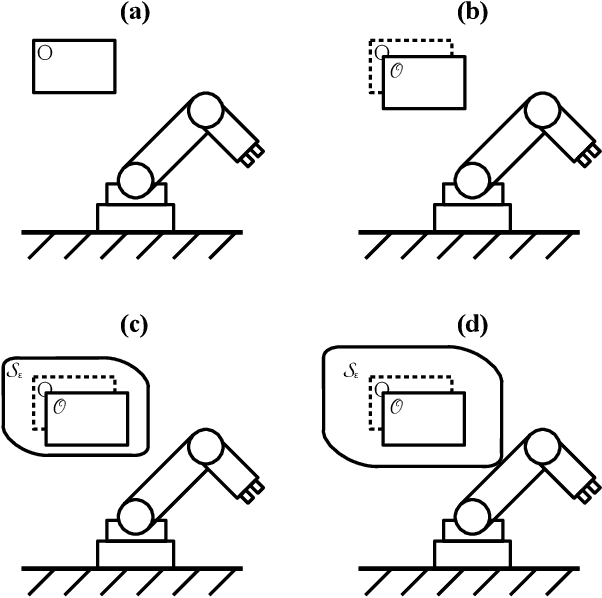



Many practical applications of robotics require systems that can operate safely despite uncertainty. In the context of motion planning, two types of uncertainty are particularly important when planning safe robot trajectories. The first is environmental uncertainty -- uncertainty in the locations of nearby obstacles, stemming from sensor noise or (in the case of obstacles' future locations) prediction error. The second class of uncertainty is uncertainty in the robots own state, typically caused by tracking or estimation error. To achieve high levels of safety, it is necessary for robots to consider both of these sources of uncertainty. In this paper, we propose a risk-bounded trajectory optimization algorithm, known as Sequential Convex Optimization with Risk Optimization (SCORA), to solve chance-constrained motion planning problems despite both environmental uncertainty and tracking error. Through experiments in simulation, we demonstrate that SCORA significantly outperforms state-of-the-art risk-aware motion planners both in planning time and in the safety of the resulting trajectories.
Dynamic Storyboard Generation in an Engine-based Virtual Environment for Video Production
Jan 31, 2023

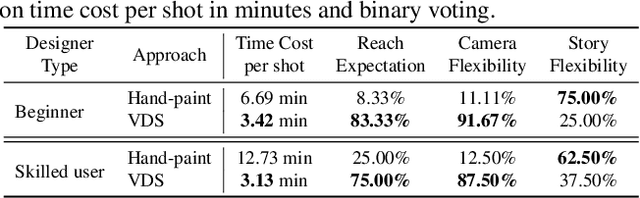
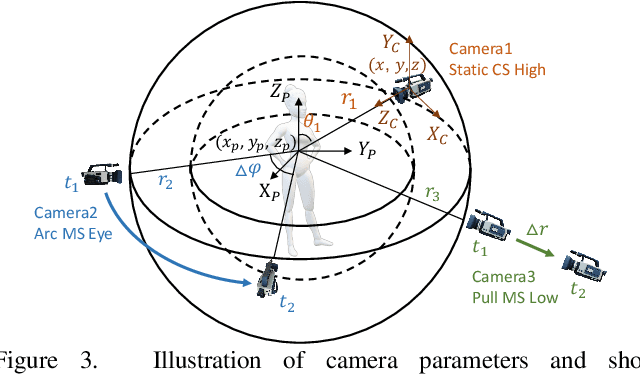
Amateurs working on mini-films and short-form videos usually spend lots of time and effort on the multi-round complicated process of setting and adjusting scenes, plots, and cameras to deliver satisfying video shots. We present Virtual Dynamic Storyboard (VDS) to allow users storyboarding shots in virtual environments, where the filming staff can easily test the settings of shots before the actual filming. VDS runs on a "propose-simulate-discriminate" mode: Given a formatted story script and a camera script as input, it generates several character animation and camera movement proposals following predefined story and cinematic rules to allow an off-the-shelf simulation engine to render videos. To pick up the top-quality dynamic storyboard from the candidates, we equip it with a shot ranking discriminator based on shot quality criteria learned from professional manual-created data. VDS is comprehensively validated via extensive experiments and user studies, demonstrating its efficiency, effectiveness, and great potential in assisting amateur video production.
Sequential Strategic Screening
Jan 31, 2023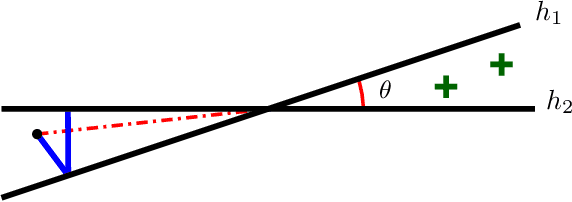
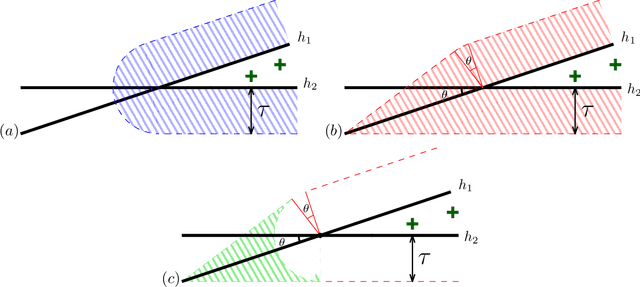
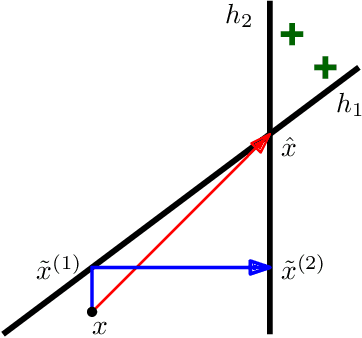
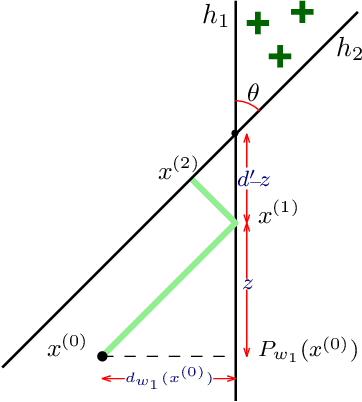
We initiate the study of strategic behavior in screening processes with multiple classifiers. We focus on two contrasting settings: a conjunctive setting in which an individual must satisfy all classifiers simultaneously, and a sequential setting in which an individual to succeed must satisfy classifiers one at a time. In other words, we introduce the combination of strategic classification with screening processes. We show that sequential screening pipelines exhibit new and surprising behavior where individuals can exploit the sequential ordering of the tests to zig-zag between classifiers without having to simultaneously satisfy all of them. We demonstrate an individual can obtain a positive outcome using a limited manipulation budget even when far from the intersection of the positive regions of every classifier. Finally, we consider a learner whose goal is to design a sequential screening process that is robust to such manipulations, and provide a construction for the learner that optimizes a natural objective.