 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Coincident Learning for Unsupervised Anomaly Detection
Jan 26, 2023
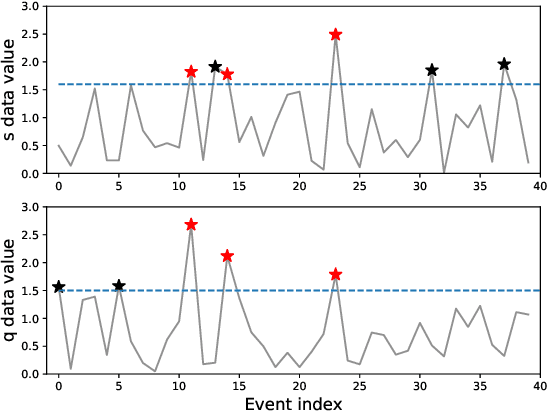

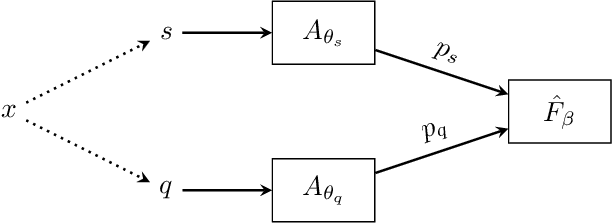
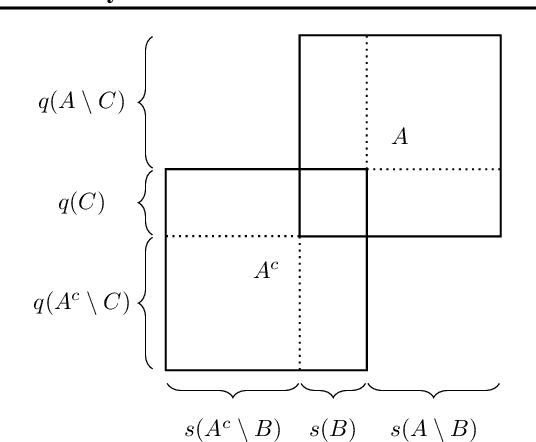
Anomaly detection is an important task for complex systems (e.g., industrial facilities, manufacturing, large-scale science experiments), where failures in a sub-system can lead to low yield, faulty products, or even damage to components. While complex systems often have a wealth of data, labeled anomalies are typically rare (or even nonexistent) and expensive to acquire. In this paper, we introduce a new method, called CoAD, for training anomaly detection models on unlabeled data, based on the expectation that anomalous behavior in one sub-system will produce coincident anomalies in downstream sub-systems and products. Given data split into two streams $s$ and $q$ (i.e., subsystem diagnostics and final product quality), we define an unsupervised metric, $\hat{F}_\beta$, out of analogy to the supervised classification $F_\beta$ statistic, which quantifies the performance of the independent anomaly detection algorithms on s and q based on their coincidence rate. We demonstrate our method in four cases: a synthetic time-series data set, a synthetic imaging data set generated from MNIST, a metal milling data set, and a data set taken from a particle accelerator.
Merging satellite and gauge-measured precipitation using LightGBM with an emphasis on extreme quantiles
Feb 02, 2023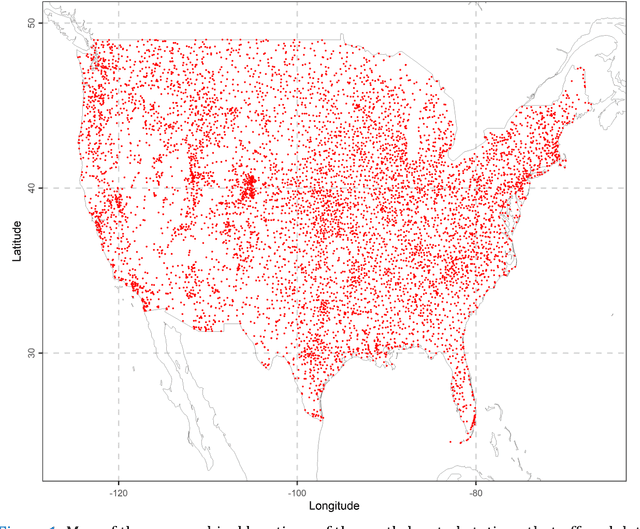
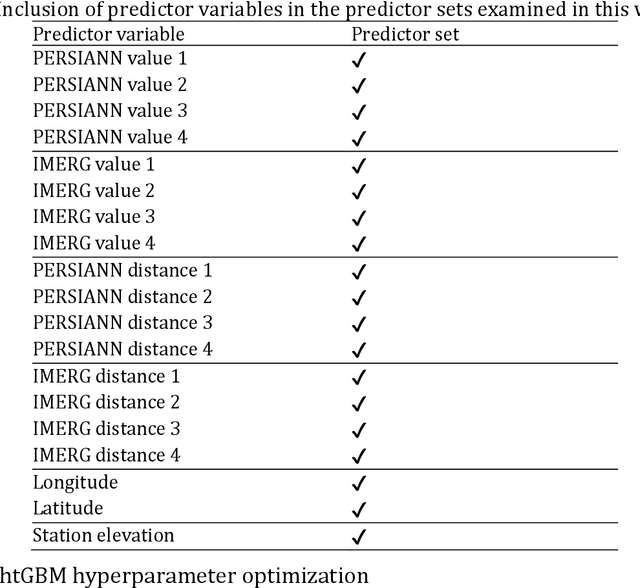

Knowing the actual precipitation in space and time is critical in hydrological modelling applications, yet the spatial coverage with rain gauge stations is limited due to economic constraints. Gridded satellite precipitation datasets offer an alternative option for estimating the actual precipitation by covering uniformly large areas, albeit related estimates are not accurate. To improve precipitation estimates, machine learning is applied to merge rain gauge-based measurements and gridded satellite precipitation products. In this context, observed precipitation plays the role of the dependent variable, while satellite data play the role of predictor variables. Random forests is the dominant machine learning algorithm in relevant applications. In those spatial predictions settings, point predictions (mostly the mean or the median of the conditional distribution) of the dependent variable are issued. Here we propose, issuing probabilistic spatial predictions of precipitation using Light Gradient Boosting Machine (LightGBM). LightGBM is a boosting algorithm, highlighted by prize-winning entries in prediction and forecasting competitions. To assess LightGBM, we contribute a large-scale application that includes merging daily precipitation measurements in contiguous US with PERSIANN and GPM-IMERG satellite precipitation data. We focus on extreme quantiles of the probability distribution of the dependent variable, where LightGBM outperforms quantile regression forests (QRF, a variant of random forests) in terms of quantile score. LightGBM and QRF show similar performance when predicting functionals at the centre of the conditional probability distribution, including the conditional median. Our study offers understanding of probabilistic predictions in spatial settings using machine learning.
IKOL: Inverse kinematics optimization layer for 3D human pose and shape estimation via Gauss-Newton differentiation
Feb 02, 2023
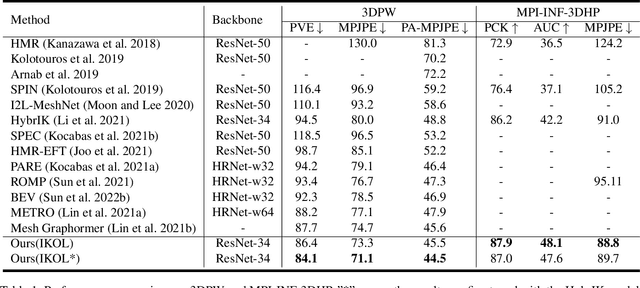
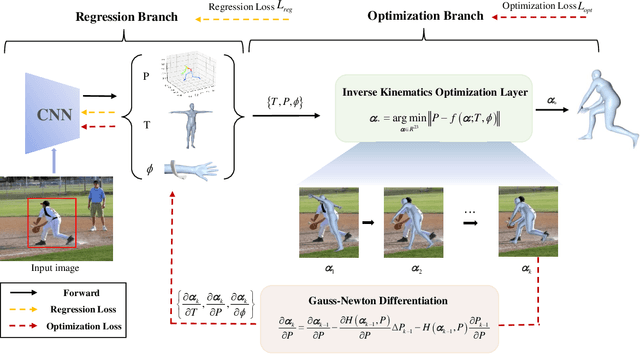
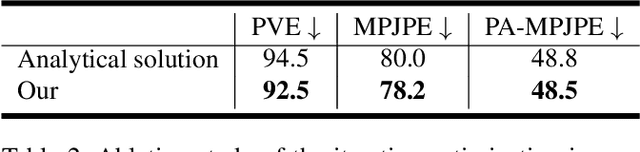
This paper presents an inverse kinematic optimization layer (IKOL) for 3D human pose and shape estimation that leverages the strength of both optimization- and regression-based methods within an end-to-end framework. IKOL involves a nonconvex optimization that establishes an implicit mapping from an image's 3D keypoints and body shapes to the relative body-part rotations. The 3D keypoints and the body shapes are the inputs and the relative body-part rotations are the solutions. However, this procedure is implicit and hard to make differentiable. So, to overcome this issue, we designed a Gauss-Newton differentiation (GN-Diff) procedure to differentiate IKOL. GN-Diff iteratively linearizes the nonconvex objective function to obtain Gauss-Newton directions with closed form solutions. Then, an automatic differentiation procedure is directly applied to generate a Jacobian matrix for end-to-end training. Notably, the GN-Diff procedure works fast because it does not rely on a time-consuming implicit differentiation procedure. The twist rotation and shape parameters are learned from the neural networks and, as a result, IKOL has a much lower computational overhead than most existing optimization-based methods. Additionally, compared to existing regression-based methods, IKOL provides a more accurate mesh-image correspondence. This is because it iteratively reduces the distance between the keypoints and also enhances the reliability of the pose structures. Extensive experiments demonstrate the superiority of our proposed framework over a wide range of 3D human pose and shape estimation methods.
LesionAid: Vision Transformers-based Skin Lesion Generation and Classification
Feb 02, 2023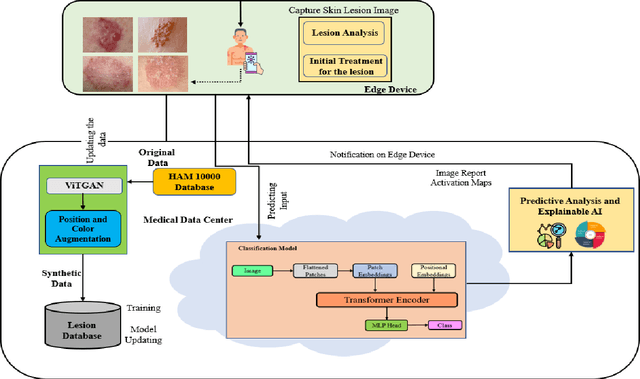
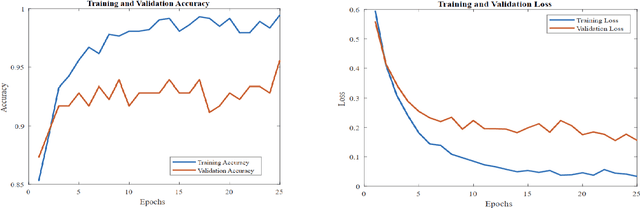
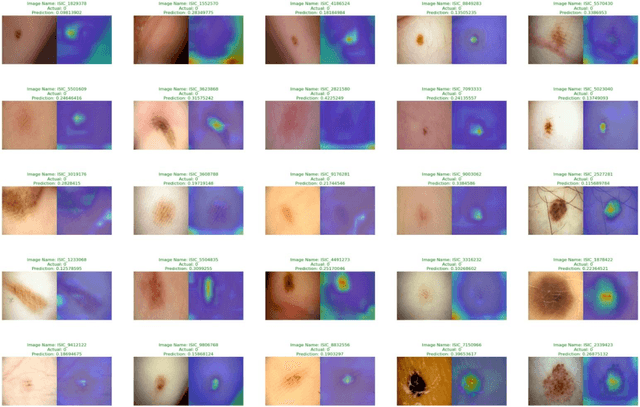
Skin cancer is one of the most prevalent forms of human cancer. It is recognized mainly visually, beginning with clinical screening and continuing with the dermoscopic examination, histological assessment, and specimen collection. Deep convolutional neural networks (CNNs) perform highly segregated and potentially universal tasks against a classified finegrained object. This research proposes a novel multi-class prediction framework that classifies skin lesions based on ViT and ViTGAN. Vision transformers-based GANs (Generative Adversarial Networks) are utilized to tackle the class imbalance. The framework consists of four main phases: ViTGANs, Image processing, and explainable AI. Phase 1 consists of generating synthetic images to balance all the classes in the dataset. Phase 2 consists of applying different data augmentation techniques and morphological operations to increase the size of the data. Phases 3 & 4 involve developing a ViT model for edge computing systems that can identify patterns and categorize skin lesions from the user's skin visible in the image. In phase 3, after classifying the lesions into the desired class with ViT, we will use explainable AI (XAI) that leads to more explainable results (using activation maps, etc.) while ensuring high predictive accuracy. Real-time images of skin diseases can capture by a doctor or a patient using the camera of a mobile application to perform an early examination and determine the cause of the skin lesion. The whole framework is compared with the existing frameworks for skin lesion detection.
Continual Mean Estimation Under User-Level Privacy
Dec 20, 2022We consider the problem of continually releasing an estimate of the population mean of a stream of samples that is user-level differentially private (DP). At each time instant, a user contributes a sample, and the users can arrive in arbitrary order. Until now these requirements of continual release and user-level privacy were considered in isolation. But, in practice, both these requirements come together as the users often contribute data repeatedly and multiple queries are made. We provide an algorithm that outputs a mean estimate at every time instant $t$ such that the overall release is user-level $\varepsilon$-DP and has the following error guarantee: Denoting by $M_t$ the maximum number of samples contributed by a user, as long as $\tilde{\Omega}(1/\varepsilon)$ users have $M_t/2$ samples each, the error at time $t$ is $\tilde{O}(1/\sqrt{t}+\sqrt{M}_t/t\varepsilon)$. This is a universal error guarantee which is valid for all arrival patterns of the users. Furthermore, it (almost) matches the existing lower bounds for the single-release setting at all time instants when users have contributed equal number of samples.
LSDM: Long-Short Diffeomorphic Motion for Weakly-Supervised Ultrasound Landmark Tracking
Jan 11, 2023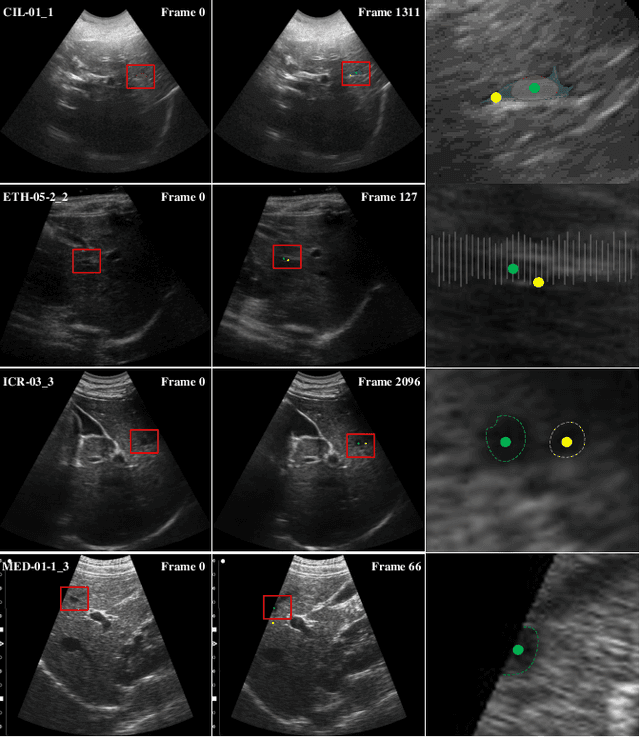
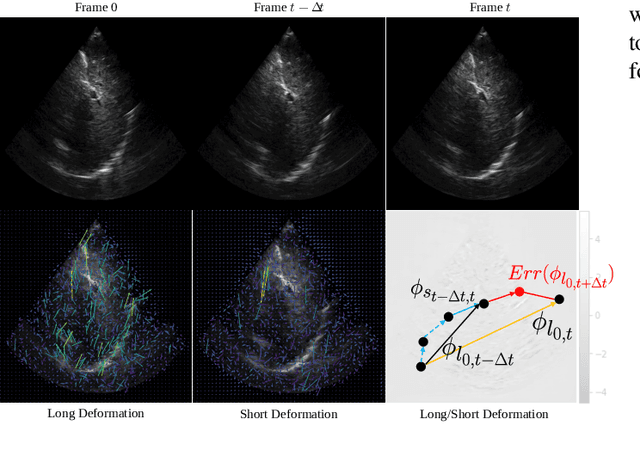
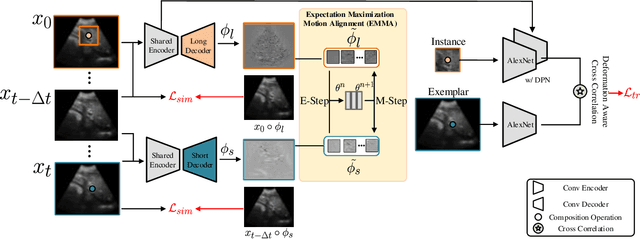
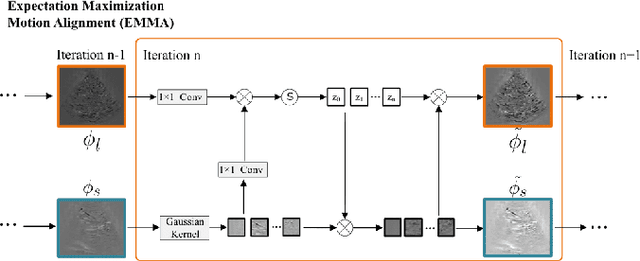
Accurate tracking of an anatomical landmark over time has been of high interests for disease assessment such as minimally invasive surgery and tumor radiation therapy. Ultrasound imaging is a promising modality benefiting from low-cost and real-time acquisition. However, generating a precise landmark tracklet is very challenging, as attempts can be easily distorted by different interference such as landmark deformation, visual ambiguity and partial observation. In this paper, we propose a long-short diffeomorphic motion network, which is a multi-task framework with a learnable deformation prior to search for the plausible deformation of landmark. Specifically, we design a novel diffeomorphism representation in both long and short temporal domains for delineating motion margins and reducing long-term cumulative tracking errors. To further mitigate local anatomical ambiguity, we propose an expectation maximisation motion alignment module to iteratively optimize both long and short deformation, aligning to the same directional and spatial representation. The proposed multi-task system can be trained in a weakly-supervised manner, which only requires few landmark annotations for tracking and zero annotation for long-short deformation learning. We conduct extensive experiments on two ultrasound landmark tracking datasets. Experimental results show that our proposed method can achieve better or competitive landmark tracking performance compared with other state-of-the-art tracking methods, with a strong generalization capability across different scanner types and different ultrasound modalities.
Deconfounding Duration Bias in Watch-time Prediction for Video Recommendation
Jun 13, 2022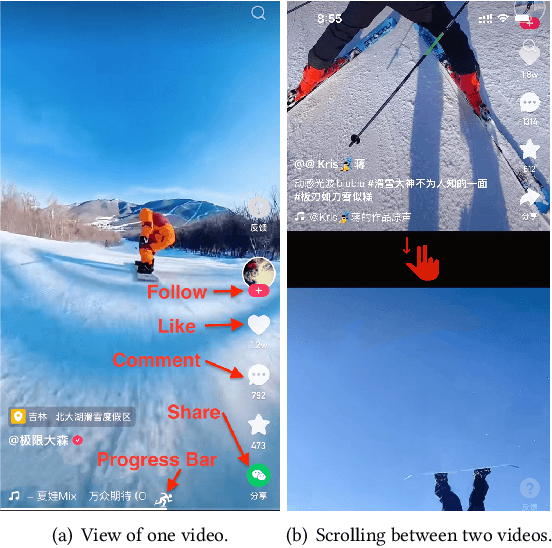

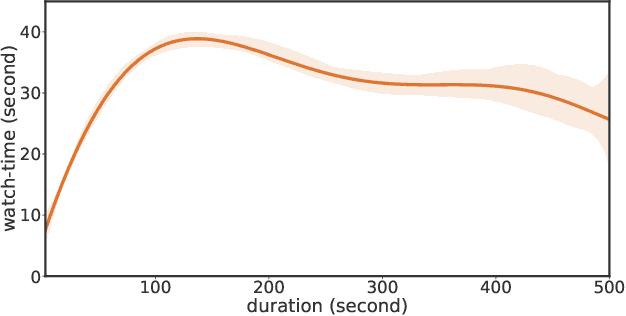
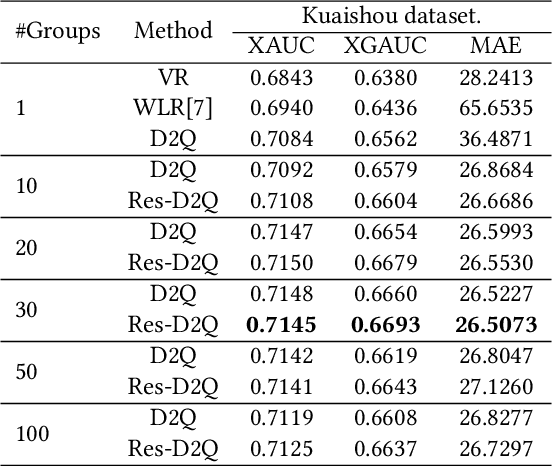
Watch-time prediction remains to be a key factor in reinforcing user engagement via video recommendations. It has become increasingly important given the ever-growing popularity of online videos. However, prediction of watch time not only depends on the match between the user and the video but is often mislead by the duration of the video itself. With the goal of improving watch time, recommendation is always biased towards videos with long duration. Models trained on this imbalanced data face the risk of bias amplification, which misguides platforms to over-recommend videos with long duration but overlook the underlying user interests. This paper presents the first work to study duration bias in watch-time prediction for video recommendation. We employ a causal graph illuminating that duration is a confounding factor that concurrently affects video exposure and watch-time prediction -- the first effect on video causes the bias issue and should be eliminated, while the second effect on watch time originates from video intrinsic characteristics and should be preserved. To remove the undesired bias but leverage the natural effect, we propose a Duration Deconfounded Quantile-based (D2Q) watch-time prediction framework, which allows for scalability to perform on industry production systems. Through extensive offline evaluation and live experiments, we showcase the effectiveness of this duration-deconfounding framework by significantly outperforming the state-of-the-art baselines. We have fully launched our approach on Kuaishou App, which has substantially improved real-time video consumption due to more accurate watch-time predictions.
Compiler-Aware Neural Architecture Search for On-Mobile Real-time Super-Resolution
Jul 25, 2022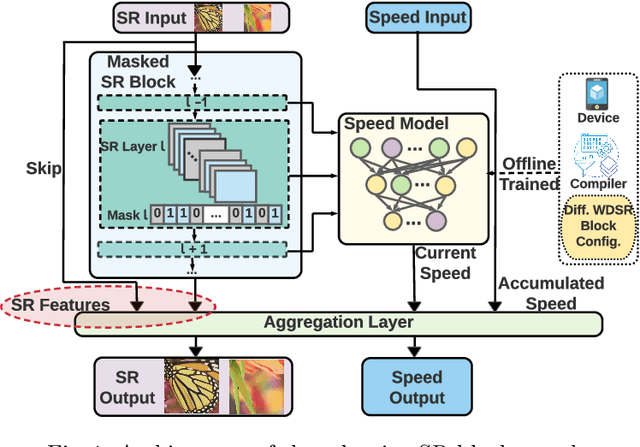
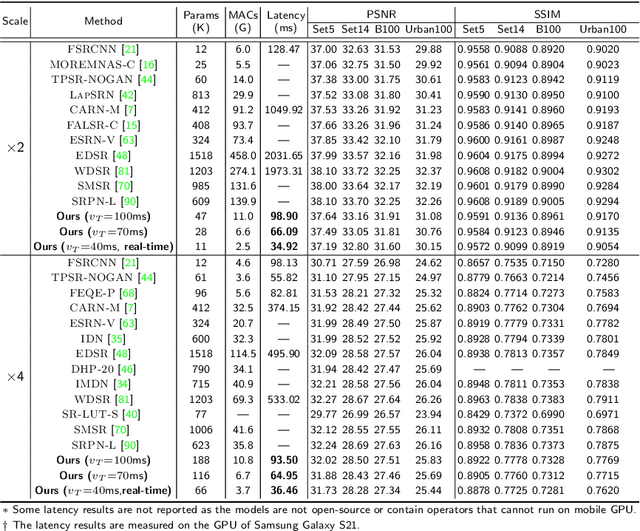
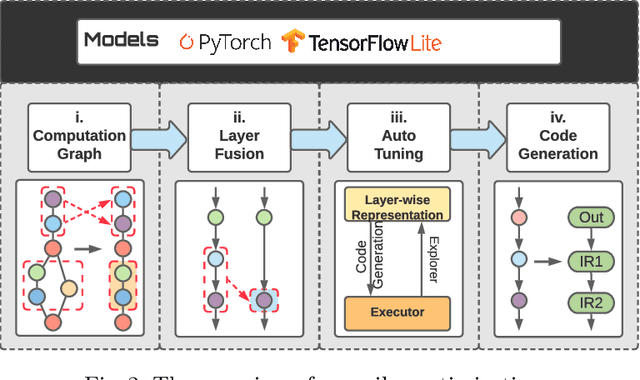
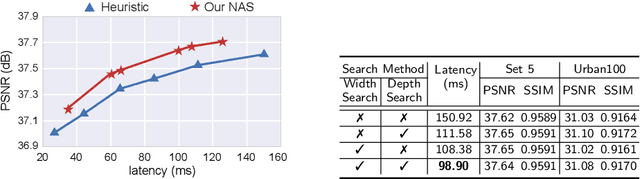
Deep learning-based super-resolution (SR) has gained tremendous popularity in recent years because of its high image quality performance and wide application scenarios. However, prior methods typically suffer from large amounts of computations and huge power consumption, causing difficulties for real-time inference, especially on resource-limited platforms such as mobile devices. To mitigate this, we propose a compiler-aware SR neural architecture search (NAS) framework that conducts depth search and per-layer width search with adaptive SR blocks. The inference speed is directly taken into the optimization along with the SR loss to derive SR models with high image quality while satisfying the real-time inference requirement. Instead of measuring the speed on mobile devices at each iteration during the search process, a speed model incorporated with compiler optimizations is leveraged to predict the inference latency of the SR block with various width configurations for faster convergence. With the proposed framework, we achieve real-time SR inference for implementing 720p resolution with competitive SR performance (in terms of PSNR and SSIM) on GPU/DSP of mobile platforms (Samsung Galaxy S21).
Development of a Self-Calibrated Motion Capture System by Nonlinear Trilateration of Multiple Kinects v2
Dec 25, 2022



In this paper, a Kinect-based distributed and real-time motion capture system is developed. A trigonometric method is applied to calculate the relative position of Kinect v2 sensors with a calibration wand and register the sensors' positions automatically. By combining results from multiple sensors with a nonlinear least square method, the accuracy of the motion capture is optimized. Moreover, to exclude inaccurate results from sensors, a computational geometry is applied in the occlusion approach, which discovers occluded joint data. The synchronization approach is based on an NTP protocol that synchronizes the time between the clocks of a server and clients dynamically, ensuring that the proposed system is a real-time system. Experiments for validating the proposed system are conducted from the perspective of calibration, occlusion, accuracy, and efficiency. Furthermore, to demonstrate the practical performance of our system, a comparison of previously developed motion capture systems (the linear trilateration approach and the geometric trilateration approach) with the benchmark OptiTrack system is conducted, therein showing that the accuracy of our proposed system is $38.3\%$ and 24.1% better than the two aforementioned trilateration systems, respectively.
NP-Match: Towards a New Probabilistic Model for Semi-Supervised Learning
Jan 31, 2023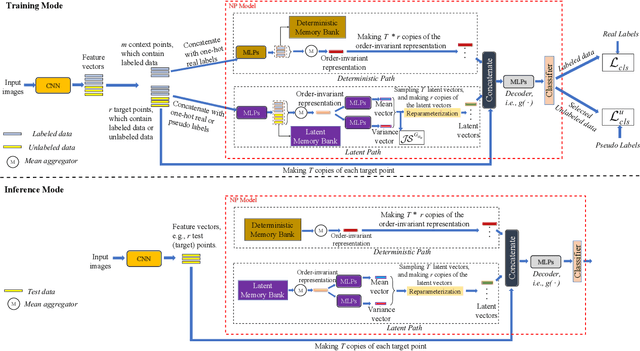
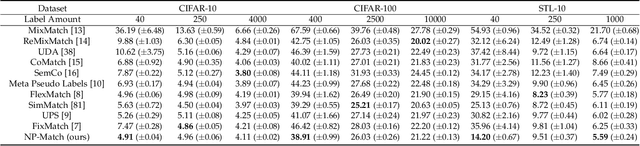
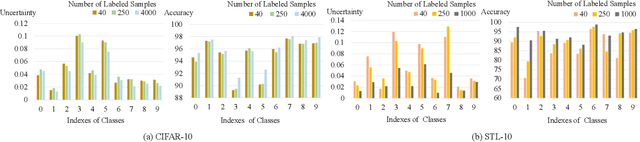
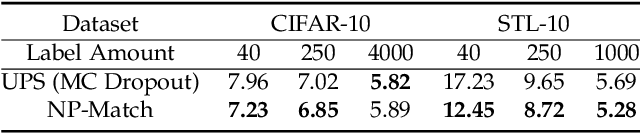
Semi-supervised learning (SSL) has been widely explored in recent years, and it is an effective way of leveraging unlabeled data to reduce the reliance on labeled data. In this work, we adjust neural processes (NPs) to the semi-supervised image classification task, resulting in a new method named NP-Match. NP-Match is suited to this task for two reasons. Firstly, NP-Match implicitly compares data points when making predictions, and as a result, the prediction of each unlabeled data point is affected by the labeled data points that are similar to it, which improves the quality of pseudo-labels. Secondly, NP-Match is able to estimate uncertainty that can be used as a tool for selecting unlabeled samples with reliable pseudo-labels. Compared with uncertainty-based SSL methods implemented with Monte-Carlo (MC) dropout, NP-Match estimates uncertainty with much less computational overhead, which can save time at both the training and the testing phases. We conducted extensive experiments on five public datasets under three semi-supervised image classification settings, namely, the standard semi-supervised image classification, the imbalanced semi-supervised image classification, and the multi-label semi-supervised image classification, and NP-Match outperforms state-of-the-art (SOTA) approaches or achieves competitive results on them, which shows the effectiveness of NP-Match and its potential for SSL. The codes are at https://github.com/Jianf-Wang/NP-Match