 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explicit Box Detection Unifies End-to-End Multi-Person Pose Estimation
Feb 03, 2023


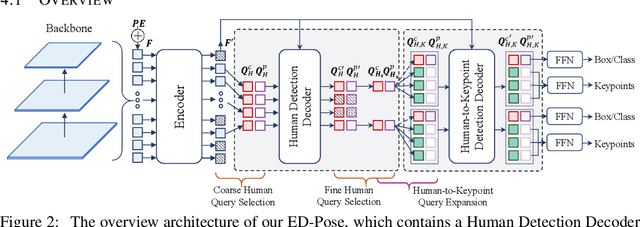
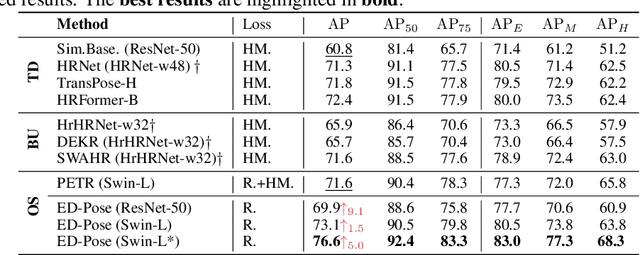
This paper presents a novel end-to-end framework with Explicit box Detection for multi-person Pose estimation, called ED-Pose, where it unifies the contextual learning between human-level (global) and keypoint-level (local) information. Different from previous one-stage methods, ED-Pose re-considers this task as two explicit box detection processes with a unified representation and regression supervision. First, we introduce a human detection decoder from encoded tokens to extract global features. It can provide a good initialization for the latter keypoint detection, making the training process converge fast. Second, to bring in contextual information near keypoints, we regard pose estimation as a keypoint box detection problem to learn both box positions and contents for each keypoint. A human-to-keypoint detection decoder adopts an interactive learning strategy between human and keypoint features to further enhance global and local feature aggregation. In general, ED-Pose is conceptually simple without post-processing and dense heatmap supervision. It demonstrates its effectiveness and efficiency compared with both two-stage and one-stage methods. Notably, explicit box detection boosts the pose estimation performance by 4.5 AP on COCO and 9.9 AP on CrowdPose. For the first time, as a fully end-to-end framework with a L1 regression loss, ED-Pose surpasses heatmap-based Top-down methods under the same backbone by 1.2 AP on COCO and achieves the state-of-the-art with 76.6 AP on CrowdPose without bells and whistles. Code is available at https://github.com/IDEA-Research/ED-Pose.
DeepAstroUDA: Semi-Supervised Universal Domain Adaptation for Cross-Survey Galaxy Morphology Classification and Anomaly Detection
Feb 03, 2023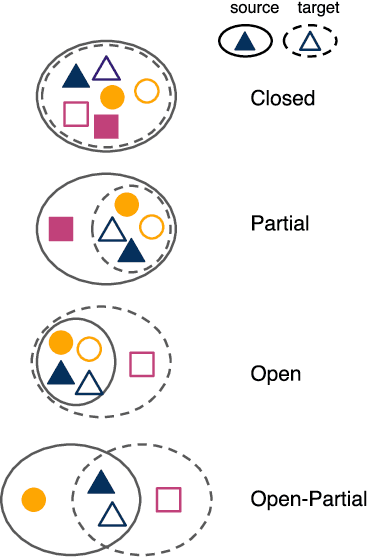
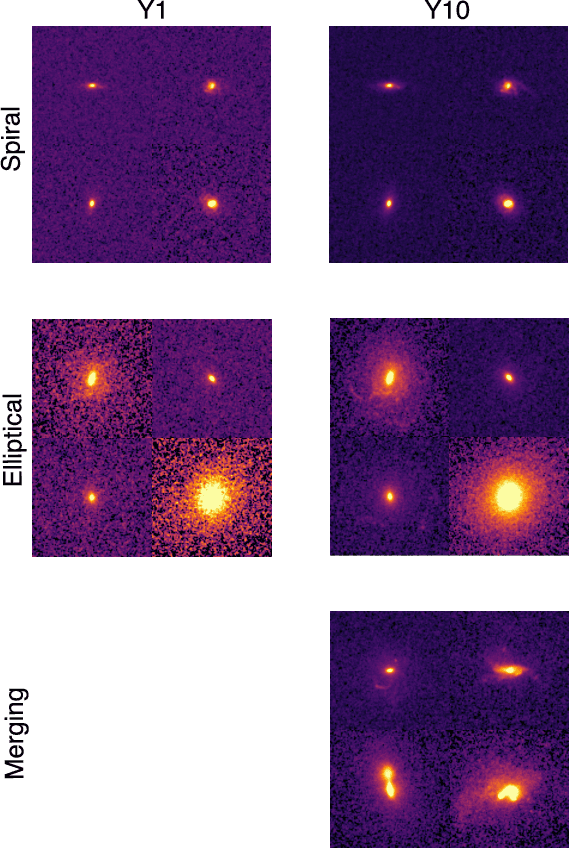
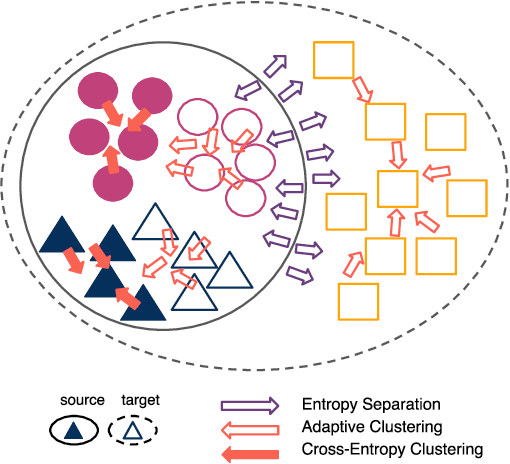
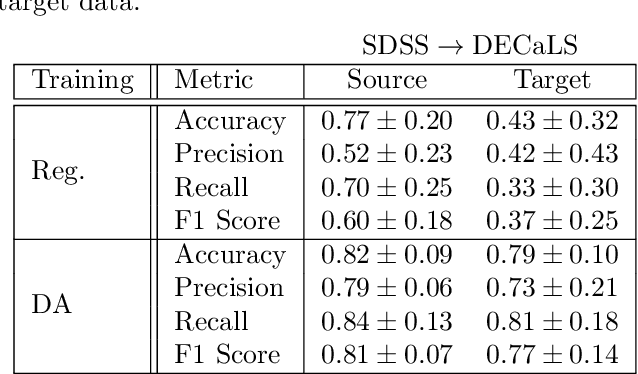
Artificial intelligence methods show great promise in increasing the quality and speed of work with large astronomical datasets, but the high complexity of these methods leads to the extraction of dataset-specific, non-robust features. Therefore, such methods do not generalize well across multiple datasets. We present a universal domain adaptation method, \textit{DeepAstroUDA}, as an approach to overcome this challenge. This algorithm performs semi-supervised domain adaptation and can be applied to datasets with different data distributions and class overlaps. Non-overlapping classes can be present in any of the two datasets (the labeled source domain, or the unlabeled target domain), and the method can even be used in the presence of unknown classes. We apply our method to three examples of galaxy morphology classification tasks of different complexities ($3$-class and $10$-class problems), with anomaly detection: 1) datasets created after different numbers of observing years from a single survey (LSST mock data of $1$ and $10$ years of observations); 2) data from different surveys (SDSS and DECaLS); and 3) data from observing fields with different depths within one survey (wide field and Stripe 82 deep field of SDSS). For the first time, we demonstrate the successful use of domain adaptation between very discrepant observational datasets. \textit{DeepAstroUDA} is capable of bridging the gap between two astronomical surveys, increasing classification accuracy in both domains (up to $40\%$ on the unlabeled data), and making model performance consistent across datasets. Furthermore, our method also performs well as an anomaly detection algorithm and successfully clusters unknown class samples even in the unlabeled target dataset.
VR-LENS: Super Learning-based Cybersickness Detection and Explainable AI-Guided Deployment in Virtual Reality
Feb 03, 2023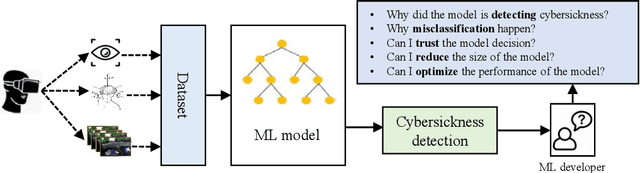

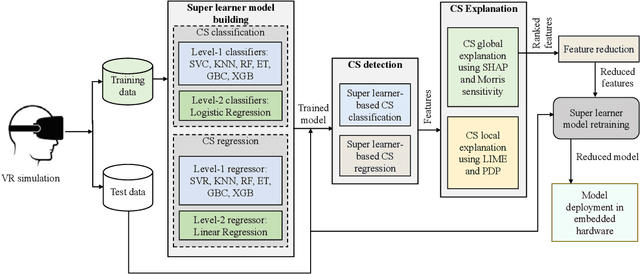

A plethora of recent research has proposed several automated methods based on machine learning (ML) and deep learning (DL) to detect cybersickness in Virtual reality (VR). However, these detection methods are perceived as computationally intensive and black-box methods. Thus, those techniques are neither trustworthy nor practical for deploying on standalone VR head-mounted displays (HMDs). This work presents an explainable artificial intelligence (XAI)-based framework VR-LENS for developing cybersickness detection ML models, explaining them, reducing their size, and deploying them in a Qualcomm Snapdragon 750G processor-based Samsung A52 device. Specifically, we first develop a novel super learning-based ensemble ML model for cybersickness detection. Next, we employ a post-hoc explanation method, such as SHapley Additive exPlanations (SHAP), Morris Sensitivity Analysis (MSA), Local Interpretable Model-Agnostic Explanations (LIME), and Partial Dependence Plot (PDP) to explain the expected results and identify the most dominant features. The super learner cybersickness model is then retrained using the identified dominant features. Our proposed method identified eye tracking, player position, and galvanic skin/heart rate response as the most dominant features for the integrated sensor, gameplay, and bio-physiological datasets. We also show that the proposed XAI-guided feature reduction significantly reduces the model training and inference time by 1.91X and 2.15X while maintaining baseline accuracy. For instance, using the integrated sensor dataset, our reduced super learner model outperforms the state-of-the-art works by classifying cybersickness into 4 classes (none, low, medium, and high) with an accuracy of 96% and regressing (FMS 1-10) with a Root Mean Square Error (RMSE) of 0.03.
GRU-TV: Time- and velocity-aware GRU for patient representation on multivariate clinical time-series data
May 04, 2022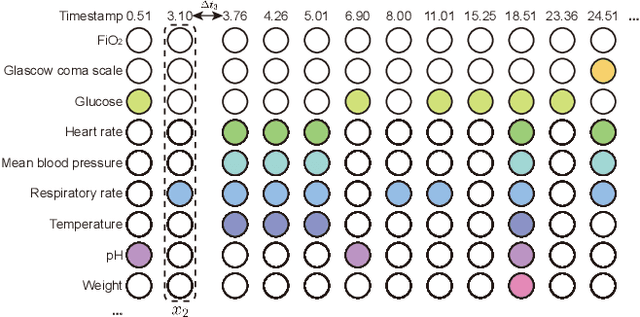
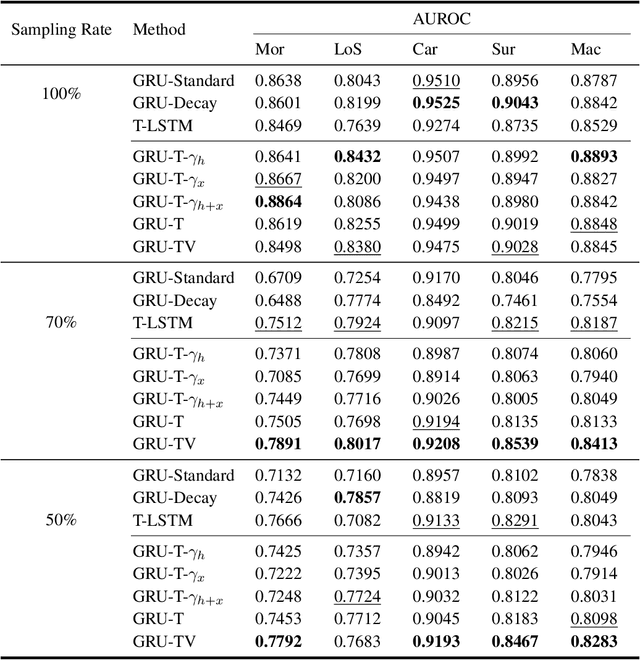
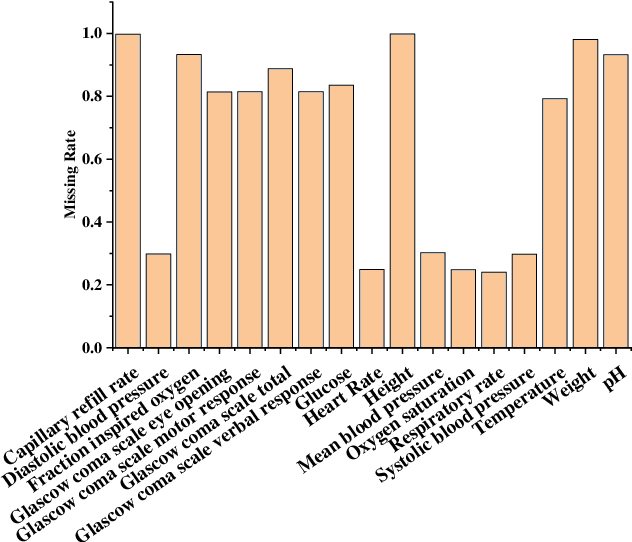
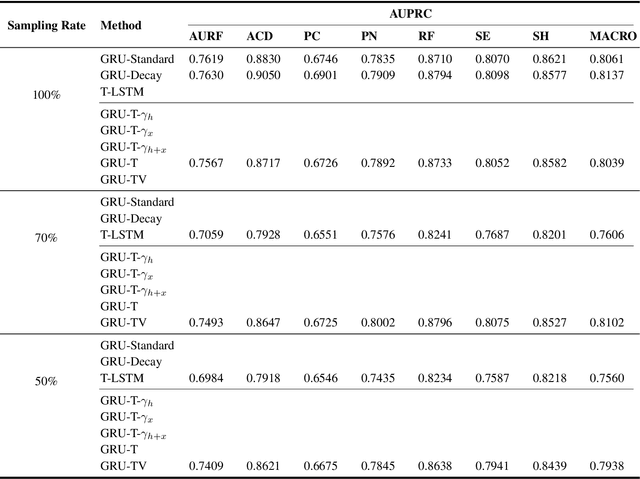
Electronic health records (EHRs) provide a rich repository to track a patient's health status. EHRs seek to fully document the patient's physiological status, and include data that is is high dimensional, heterogeneous, and multimodal. The significant differences in the sampling frequency of clinical variables can result in high missing rates and uneven time intervals between adjacent records in the multivariate clinical time-series data extracted from EHRs. Current studies using clinical time-series data for patient characterization view the patient's physiological status as a discrete process described by sporadically collected values, while the dynamics in patient's physiological status are time-continuous. In addition, recurrent neural networks (RNNs) models widely used for patient representation learning lack the perception of time intervals and velocity, which limits the ability of the model to represent the physiological status of the patient. In this paper, we propose an improved gated recurrent unit (GRU), namely time- and velocity-aware GRU (GRU-TV), for patient representation learning of clinical multivariate time-series data in a time-continuous manner. In proposed GRU-TV, the neural ordinary differential equations (ODEs) and velocity perception mechanism are used to perceive the time interval between records in the time-series data and changing rate of the patient's physiological status, respectively. Experimental results on two real-world clinical EHR datasets(PhysioNet2012, MIMIC-III) show that GRU-TV achieve state-of-the-art performance in computer aided diagnosis (CAD) tasks, and is more advantageous in processing sampled data.
NP-Match: Towards a New Probabilistic Model for Semi-Supervised Learning
Jan 31, 2023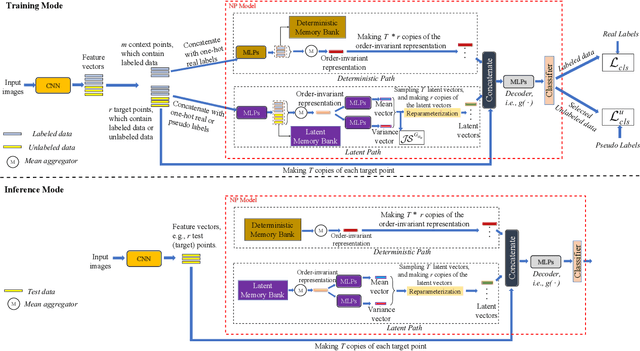
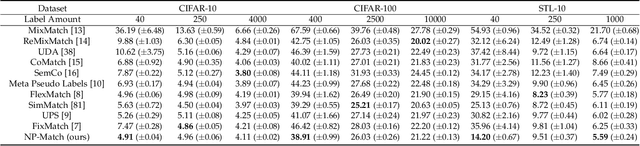
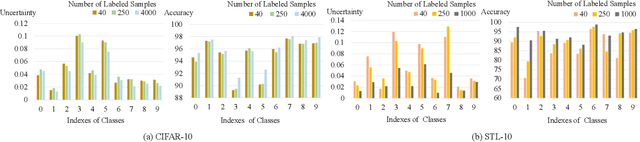
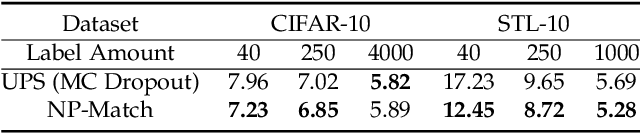
Semi-supervised learning (SSL) has been widely explored in recent years, and it is an effective way of leveraging unlabeled data to reduce the reliance on labeled data. In this work, we adjust neural processes (NPs) to the semi-supervised image classification task, resulting in a new method named NP-Match. NP-Match is suited to this task for two reasons. Firstly, NP-Match implicitly compares data points when making predictions, and as a result, the prediction of each unlabeled data point is affected by the labeled data points that are similar to it, which improves the quality of pseudo-labels. Secondly, NP-Match is able to estimate uncertainty that can be used as a tool for selecting unlabeled samples with reliable pseudo-labels. Compared with uncertainty-based SSL methods implemented with Monte-Carlo (MC) dropout, NP-Match estimates uncertainty with much less computational overhead, which can save time at both the training and the testing phases. We conducted extensive experiments on five public datasets under three semi-supervised image classification settings, namely, the standard semi-supervised image classification, the imbalanced semi-supervised image classification, and the multi-label semi-supervised image classification, and NP-Match outperforms state-of-the-art (SOTA) approaches or achieves competitive results on them, which shows the effectiveness of NP-Match and its potential for SSL. The codes are at https://github.com/Jianf-Wang/NP-Match
Partitioning Distributed Compute Jobs with Reinforcement Learning and Graph Neural Networks
Jan 31, 2023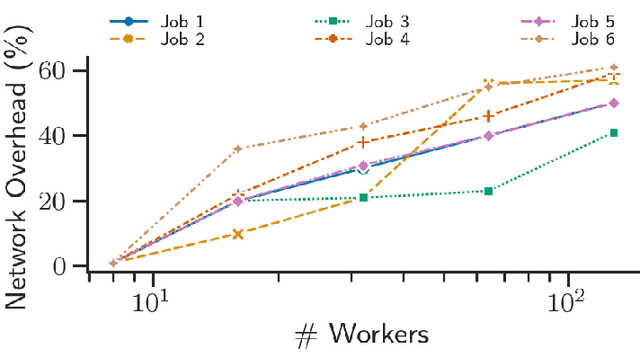
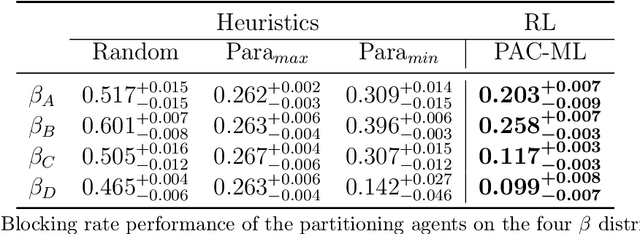
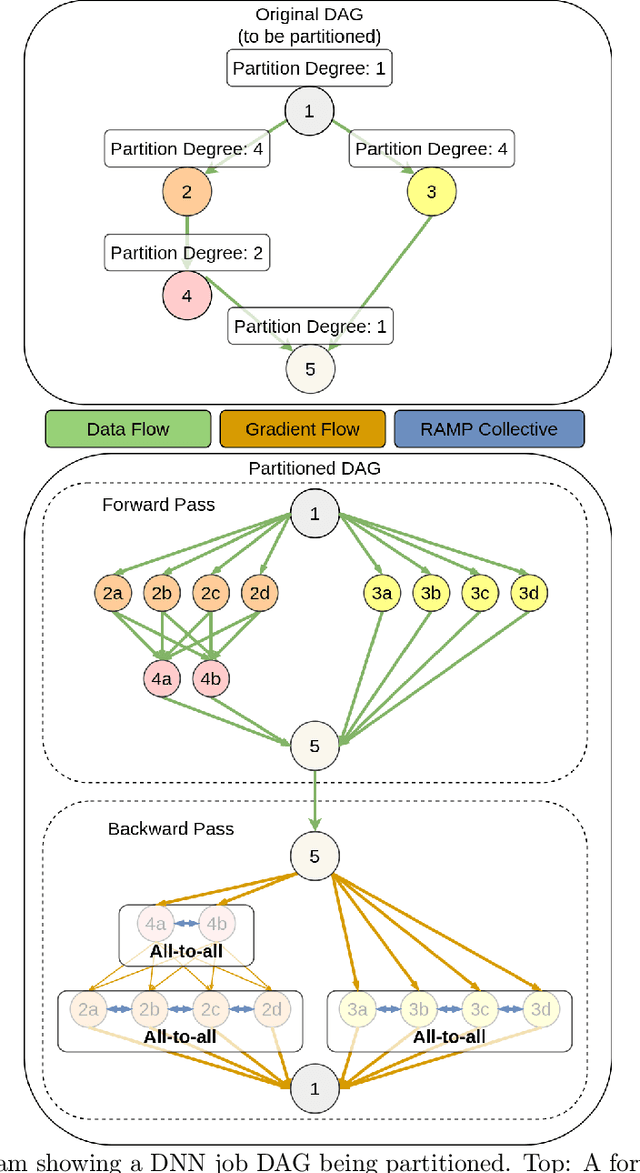
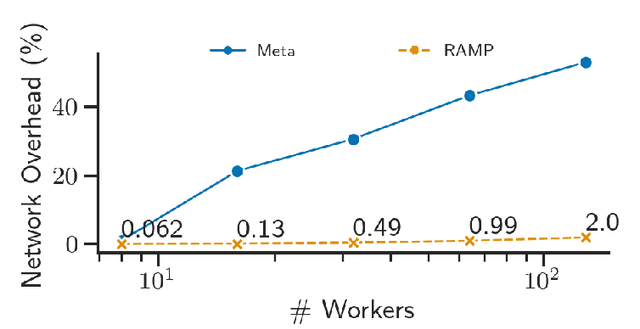
From natural language processing to genome sequencing, large-scale machine learning models are bringing advances to a broad range of fields. Many of these models are too large to be trained on a single machine, and instead must be distributed across multiple devices. This has motivated the research of new compute and network systems capable of handling such tasks. In particular, recent work has focused on developing management schemes which decide how to allocate distributed resources such that some overall objective, such as minimising the job completion time (JCT), is optimised. However, such studies omit explicit consideration of how much a job should be distributed, usually assuming that maximum distribution is desirable. In this work, we show that maximum parallelisation is sub-optimal in relation to user-critical metrics such as throughput and blocking rate. To address this, we propose PAC-ML (partitioning for asynchronous computing with machine learning). PAC-ML leverages a graph neural network and reinforcement learning to learn how much to partition computation graphs such that the number of jobs which meet arbitrary user-defined JCT requirements is maximised. In experiments with five real deep learning computation graphs on a recently proposed optical architecture across four user-defined JCT requirement distributions, we demonstrate PAC-ML achieving up to 56.2% lower blocking rates in dynamic job arrival settings than the canonical maximum parallelisation strategy used by most prior works.
Large Language Models are Versatile Decomposers: Decompose Evidence and Questions for Table-based Reasoning
Jan 31, 2023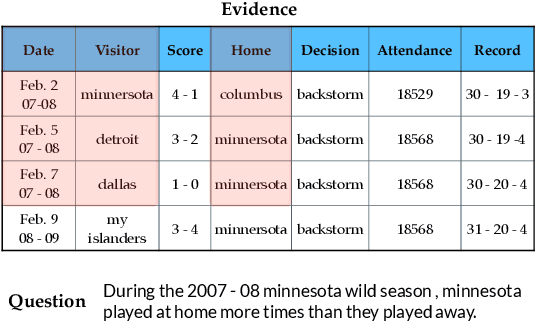

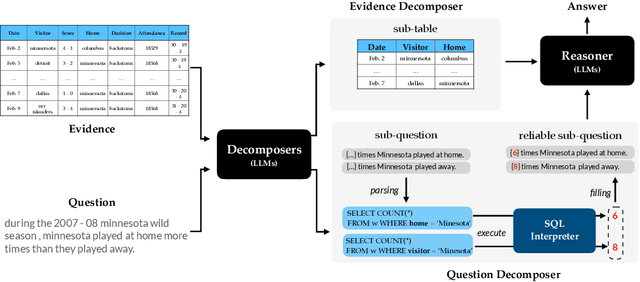
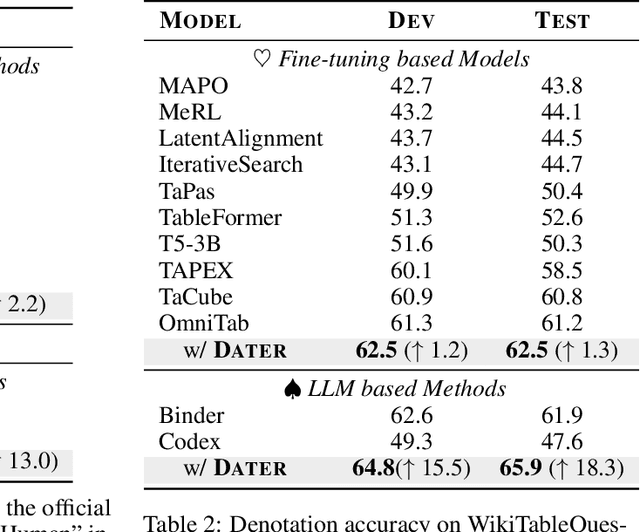
Table-based reasoning has shown remarkable progress in combining deep models with discrete reasoning, which requires reasoning over both free-form natural language (NL) questions and structured tabular data. However, previous table-based reasoning solutions usually suffer from significant performance degradation on huge evidence (tables). In addition, most existing methods struggle to reason over complex questions since the required information is scattered in different places. To alleviate the above challenges, we exploit large language models (LLMs) as decomposers for effective table-based reasoning, which (i) decompose huge evidence (a huge table) into sub-evidence (a small table) to mitigate the interference of useless information for table reasoning; and (ii) decompose complex questions into simpler sub-questions for text reasoning. Specifically, we first use the LLMs to break down the evidence (tables) involved in the current question, retaining the relevant evidence and excluding the remaining irrelevant evidence from the huge table. In addition, we propose a "parsing-execution-filling" strategy to alleviate the hallucination dilemma of the chain of thought by decoupling logic and numerical computation in each step. Extensive experiments show that our method can effectively leverage decomposed evidence and questions and outperforms the strong baselines on TabFact, WikiTableQuestion, and FetaQA datasets. Notably, our model outperforms human performance for the first time on the TabFact dataset.
Sublinear-Time Clustering Oracle for Signed Graphs
Jun 28, 2022
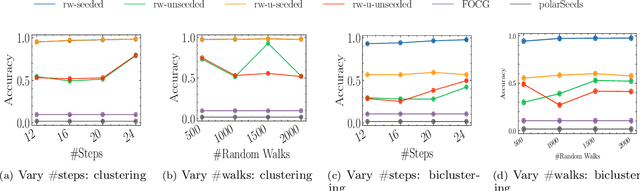
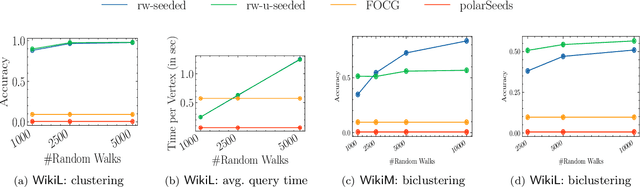
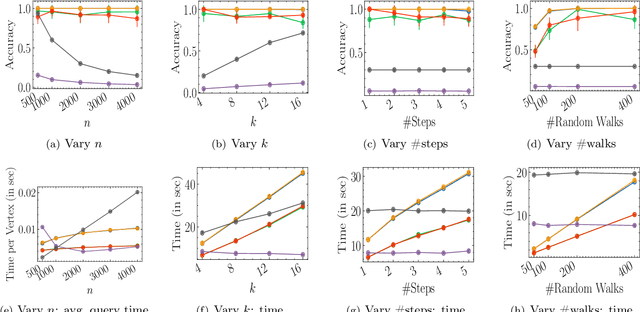
Social networks are often modeled using signed graphs, where vertices correspond to users and edges have a sign that indicates whether an interaction between users was positive or negative. The arising signed graphs typically contain a clear community structure in the sense that the graph can be partitioned into a small number of polarized communities, each defining a sparse cut and indivisible into smaller polarized sub-communities. We provide a local clustering oracle for signed graphs with such a clear community structure, that can answer membership queries, i.e., "Given a vertex $v$, which community does $v$ belong to?", in sublinear time by reading only a small portion of the graph. Formally, when the graph has bounded maximum degree and the number of communities is at most $O(\log n)$, then with $\tilde{O}(\sqrt{n}\operatorname{poly}(1/\varepsilon))$ preprocessing time, our oracle can answer each membership query in $\tilde{O}(\sqrt{n}\operatorname{poly}(1/\varepsilon))$ time, and it correctly classifies a $(1-\varepsilon)$-fraction of vertices w.r.t. a set of hidden planted ground-truth communities. Our oracle is desirable in applications where the clustering information is needed for only a small number of vertices. Previously, such local clustering oracles were only known for unsigned graphs; our generalization to signed graphs requires a number of new ideas and gives a novel spectral analysis of the behavior of random walks with signs. We evaluate our algorithm for constructing such an oracle and answering membership queries on both synthetic and real-world datasets, validating its performance in practice.
LSDM: Long-Short Diffeomorphic Motion for Weakly-Supervised Ultrasound Landmark Tracking
Jan 11, 2023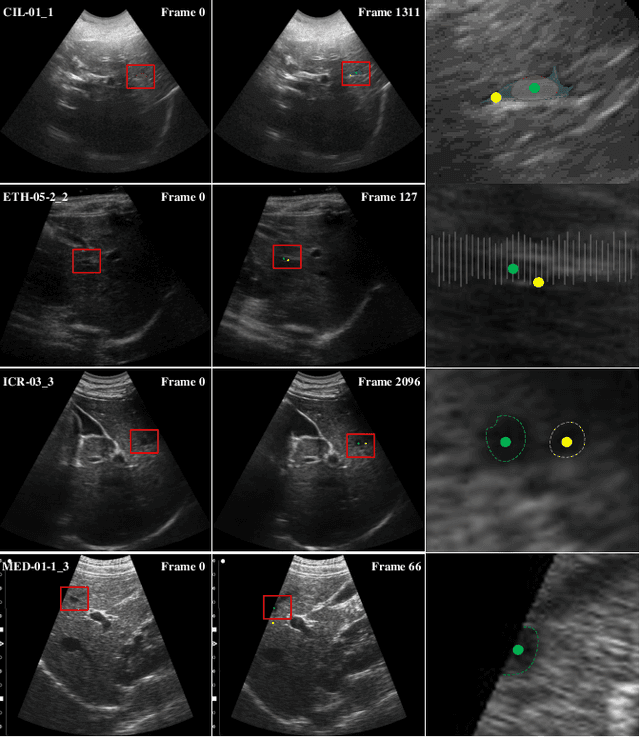
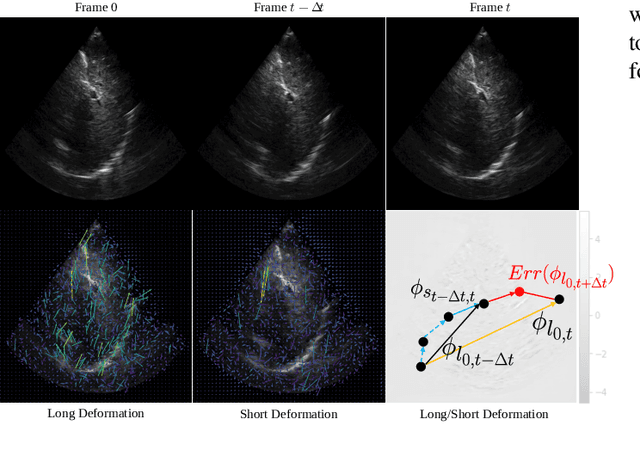
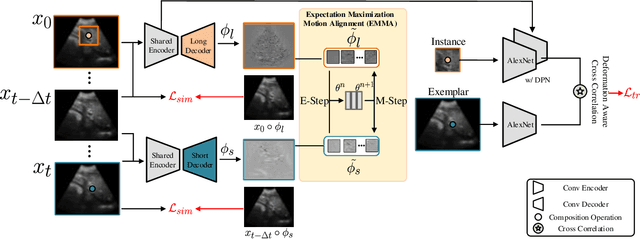
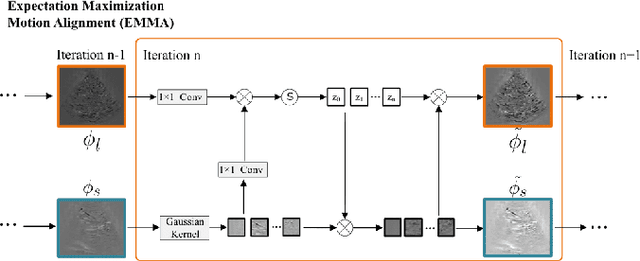
Accurate tracking of an anatomical landmark over time has been of high interests for disease assessment such as minimally invasive surgery and tumor radiation therapy. Ultrasound imaging is a promising modality benefiting from low-cost and real-time acquisition. However, generating a precise landmark tracklet is very challenging, as attempts can be easily distorted by different interference such as landmark deformation, visual ambiguity and partial observation. In this paper, we propose a long-short diffeomorphic motion network, which is a multi-task framework with a learnable deformation prior to search for the plausible deformation of landmark. Specifically, we design a novel diffeomorphism representation in both long and short temporal domains for delineating motion margins and reducing long-term cumulative tracking errors. To further mitigate local anatomical ambiguity, we propose an expectation maximisation motion alignment module to iteratively optimize both long and short deformation, aligning to the same directional and spatial representation. The proposed multi-task system can be trained in a weakly-supervised manner, which only requires few landmark annotations for tracking and zero annotation for long-short deformation learning. We conduct extensive experiments on two ultrasound landmark tracking datasets. Experimental results show that our proposed method can achieve better or competitive landmark tracking performance compared with other state-of-the-art tracking methods, with a strong generalization capability across different scanner types and different ultrasound modalities.
HUSP-SP: Faster Utility Mining on Sequence Data
Dec 29, 2022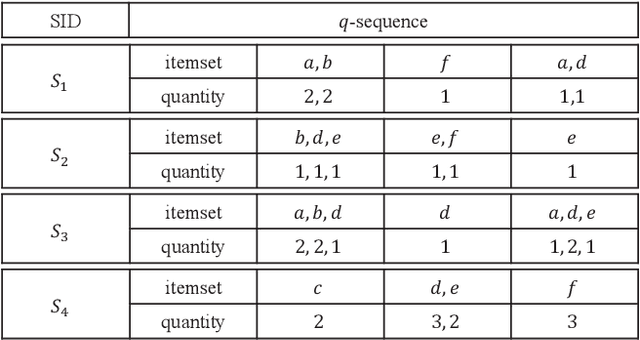
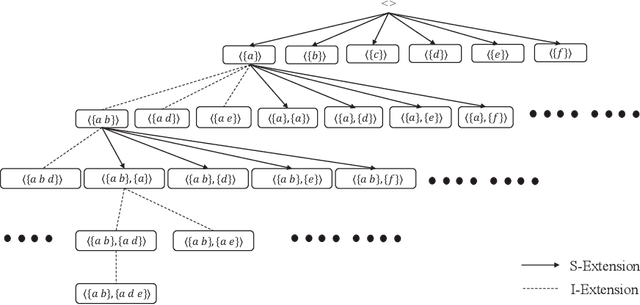
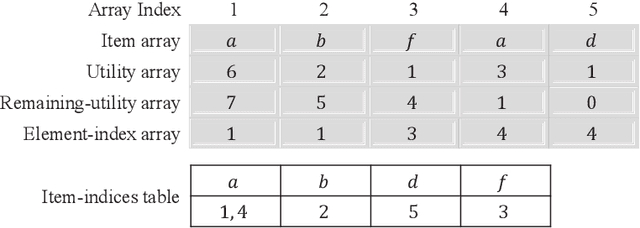
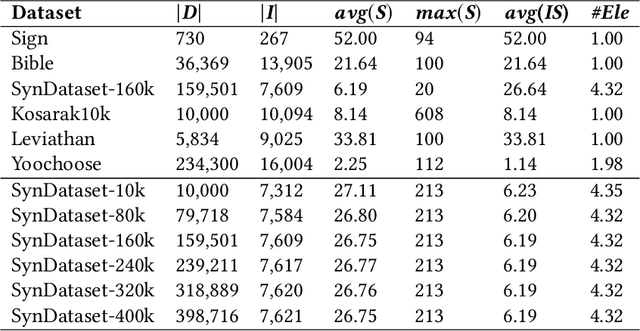
High-utility sequential pattern mining (HUSPM) has emerged as an important topic due to its wide application and considerable popularity. However, due to the combinatorial explosion of the search space when the HUSPM problem encounters a low utility threshold or large-scale data, it may be time-consuming and memory-costly to address the HUSPM problem. Several algorithms have been proposed for addressing this problem, but they still cost a lot in terms of running time and memory usage. In this paper, to further solve this problem efficiently, we design a compact structure called sequence projection (seqPro) and propose an efficient algorithm, namely discovering high-utility sequential patterns with the seqPro structure (HUSP-SP). HUSP-SP utilizes the compact seq-array to store the necessary information in a sequence database. The seqPro structure is designed to efficiently calculate candidate patterns' utilities and upper bound values. Furthermore, a new upper bound on utility, namely tighter reduced sequence utility (TRSU) and two pruning strategies in search space, are utilized to improve the mining performance of HUSP-SP. Experimental results on both synthetic and real-life datasets show that HUSP-SP can significantly outperform the state-of-the-art algorithms in terms of running time, memory usage, search space pruning efficiency, and scalability.