 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A simple model for pink noise from amplitude modulations
Jan 26, 2023
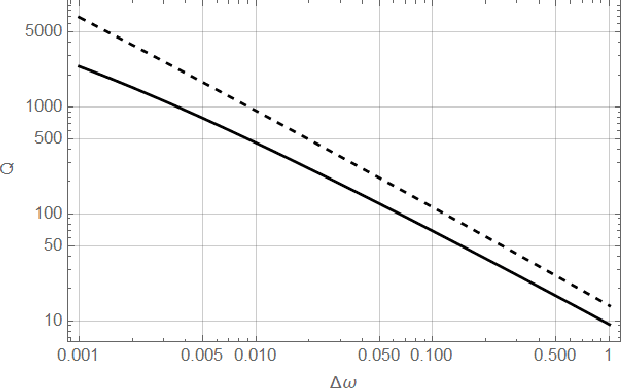
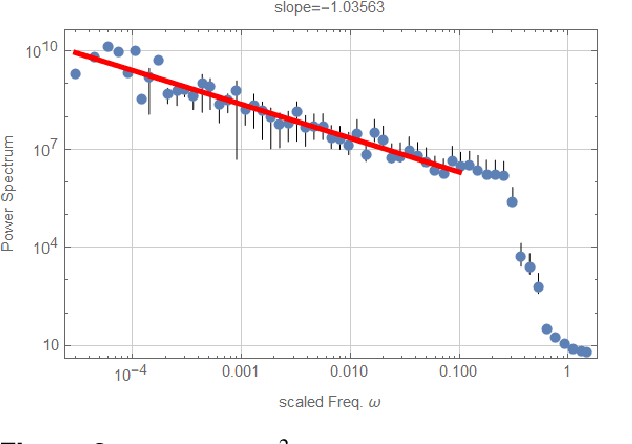
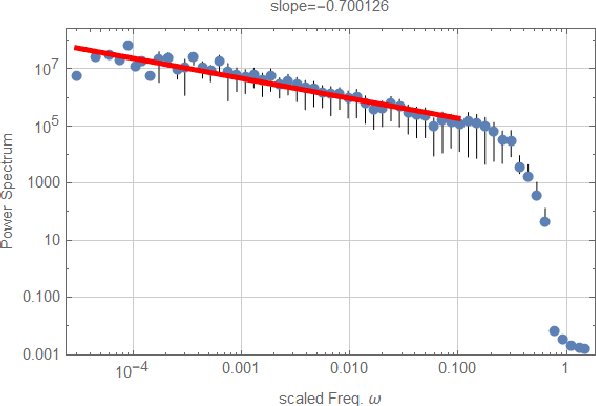
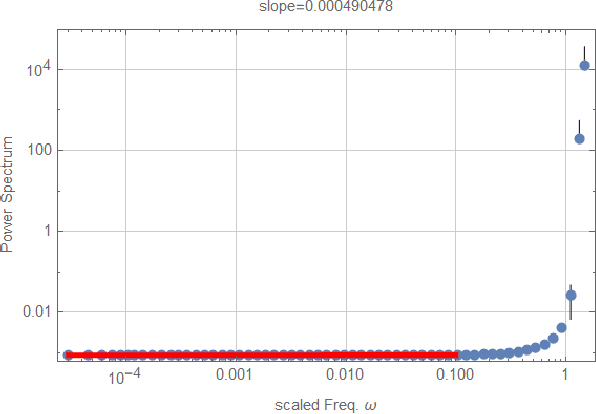
We propose a simple model for the origin of pink noise (or 1/f fluctuation) based on the beat of cooperative waves. These cooperative waves arise spontaneously in a system with synchronization, resonance, and infrared divergence. Many cooperative waves with close frequencies can produce signals of arbitrary small frequencies from a system of small size. This beat mechanism can be understood as amplitude modulation. The pink noise can appear after the demodulation process, which produces a variety of pink noise in many fields. The pink noise thus formed from the beat has nothing to do with dissipation or long-time memory. We also suggest new ways of looking at pink noise in shallow earthquakes, solar flares, and stellar activities.
Are Labels Needed for Incremental Instance Learning?
Jan 26, 2023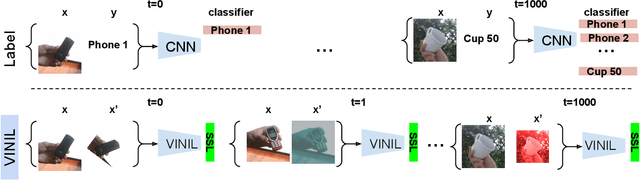
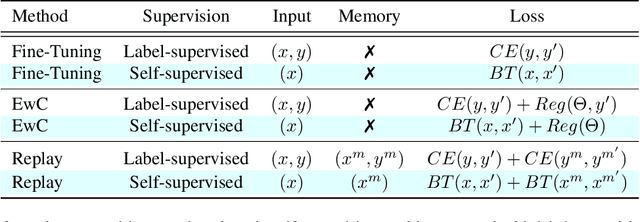
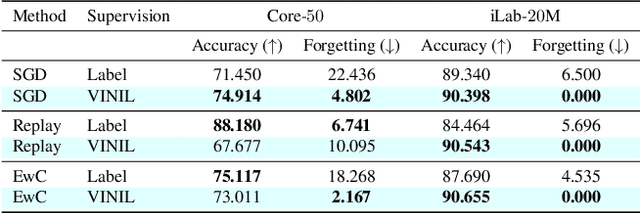
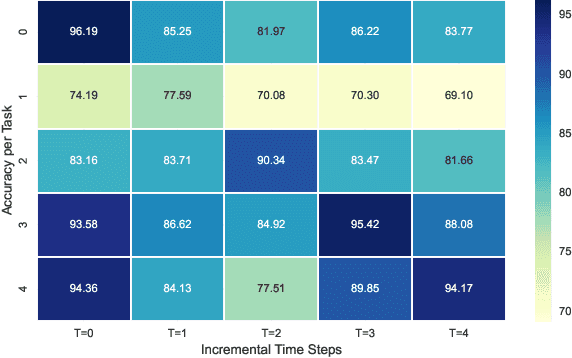
In this paper, we learn to classify visual object instances, incrementally and via self-supervision (self-incremental). Our learner observes a single instance at a time, which is then discarded from the dataset. Incremental instance learning is challenging, since longer learning sessions exacerbate forgetfulness, and labeling instances is cumbersome. We overcome these challenges via three contributions: \textit{i).} We propose VINIL, a self-incremental learner that can learn object instances sequentially, \textit{ii).} We equip VINIL with self-supervision to by-pass the need for instance labelling, \textit{iii).} We compare VINIL to label-supervised variants on two large-scale benchmarks~\cite{core50,ilab20m}, and show that VINIL significantly improves accuracy while reducing forgetfulness.
Open Problem: Properly learning decision trees in polynomial time?
Jun 29, 2022
The authors recently gave an $n^{O(\log\log n)}$ time membership query algorithm for properly learning decision trees under the uniform distribution (Blanc et al., 2021). The previous fastest algorithm for this problem ran in $n^{O(\log n)}$ time, a consequence of Ehrenfeucht and Haussler (1989)'s classic algorithm for the distribution-free setting. In this article we highlight the natural open problem of obtaining a polynomial-time algorithm, discuss possible avenues towards obtaining it, and state intermediate milestones that we believe are of independent interest.
Representing Noisy Image Without Denoising
Jan 18, 2023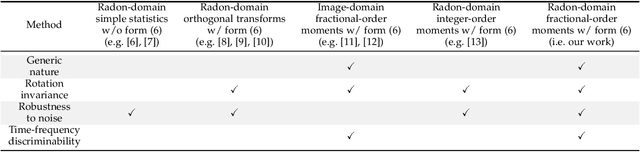
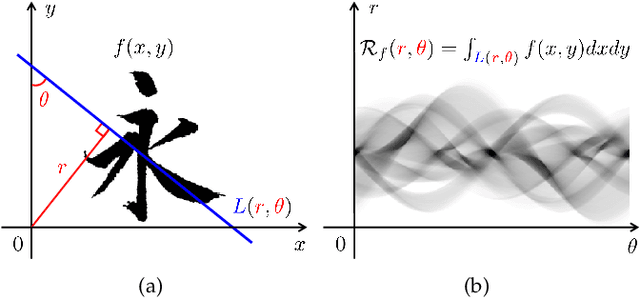
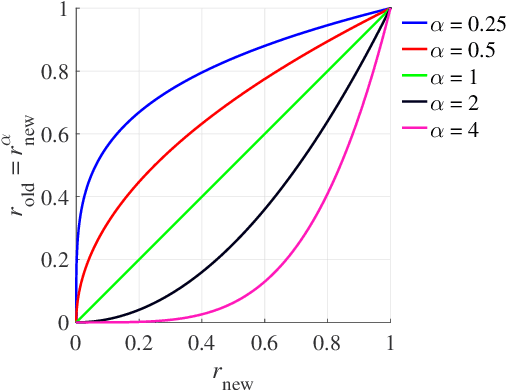
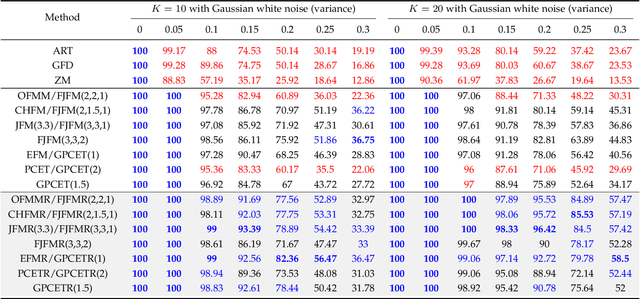
A long-standing topic in artificial intelligence is the effective recognition of patterns from noisy images. In this regard, the recent data-driven paradigm considers 1) improving the representation robustness by adding noisy samples in training phase (i.e., data augmentation) or 2) pre-processing the noisy image by learning to solve the inverse problem (i.e., image denoising). However, such methods generally exhibit inefficient process and unstable result, limiting their practical applications. In this paper, we explore a non-learning paradigm that aims to derive robust representation directly from noisy images, without the denoising as pre-processing. Here, the noise-robust representation is designed as Fractional-order Moments in Radon space (FMR), with also beneficial properties of orthogonality and rotation invariance. Unlike earlier integer-order methods, our work is a more generic design taking such classical methods as special cases, and the introduced fractional-order parameter offers time-frequency analysis capability that is not available in classical methods. Formally, both implicit and explicit paths for constructing the FMR are discussed in detail. Extensive simulation experiments and an image security application are provided to demonstrate the uniqueness and usefulness of our FMR, especially for noise robustness, rotation invariance, and time-frequency discriminability.
Detecting and Ranking Causal Anomalies in End-to-End Complex System
Jan 18, 2023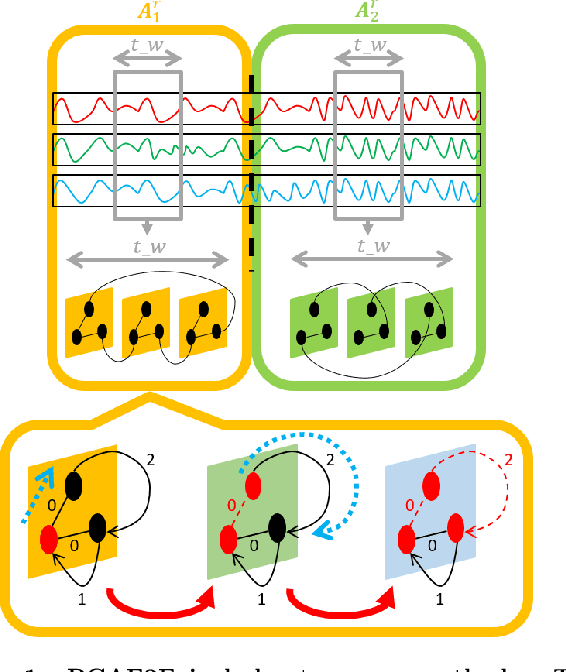

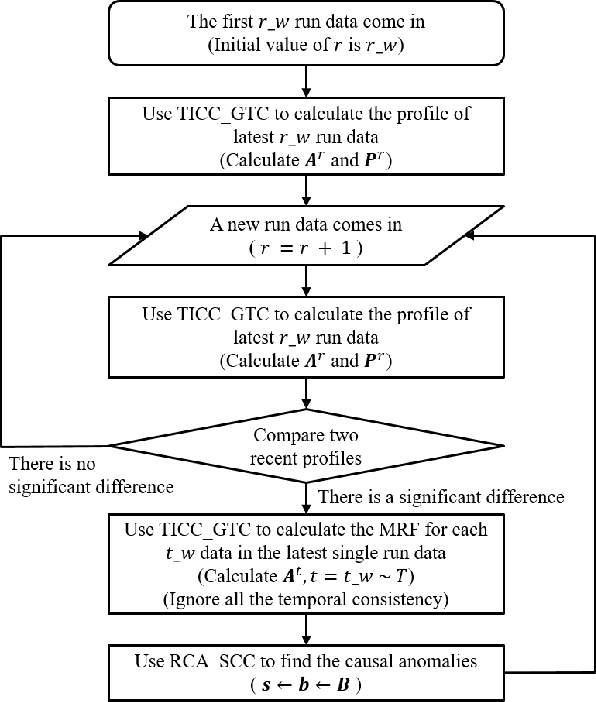
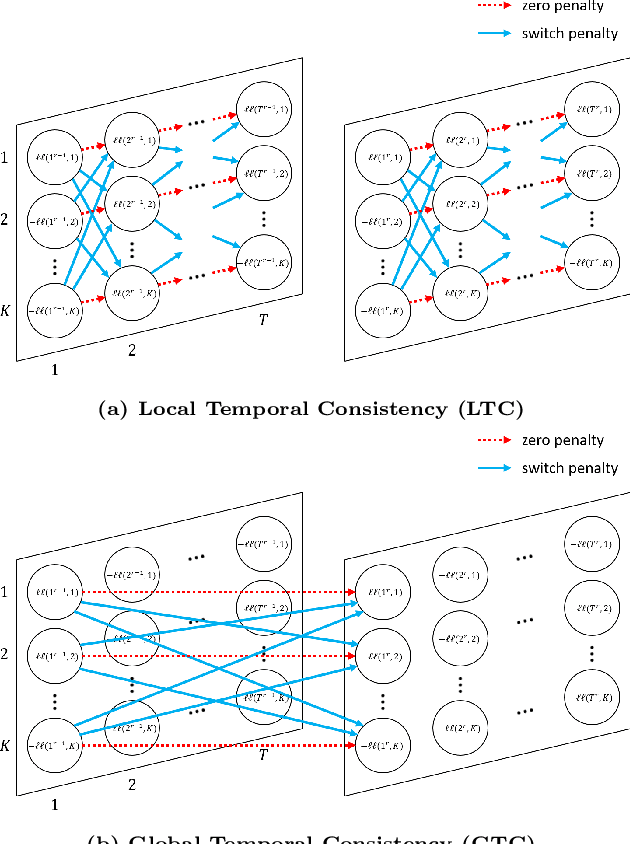
With the rapid development of technology, the automated monitoring systems of large-scale factories are becoming more and more important. By collecting a large amount of machine sensor data, we can have many ways to find anomalies. We believe that the real core value of an automated monitoring system is to identify and track the cause of the problem. The most famous method for finding causal anomalies is RCA, but there are many problems that cannot be ignored. They used the AutoRegressive eXogenous (ARX) model to create a time-invariant correlation network as a machine profile, and then use this profile to track the causal anomalies by means of a method called fault propagation. There are two major problems in describing the behavior of a machine by using the correlation network established by ARX: (1) It does not take into account the diversity of states (2) It does not separately consider the correlations with different time-lag. Based on these problems, we propose a framework called Ranking Causal Anomalies in End-to-End System (RCAE2E), which completely solves the problems mentioned above. In the experimental part, we use synthetic data and real-world large-scale photoelectric factory data to verify the correctness and existence of our method hypothesis.
simpleKT: A Simple But Tough-to-Beat Baseline for Knowledge Tracing
Feb 14, 2023
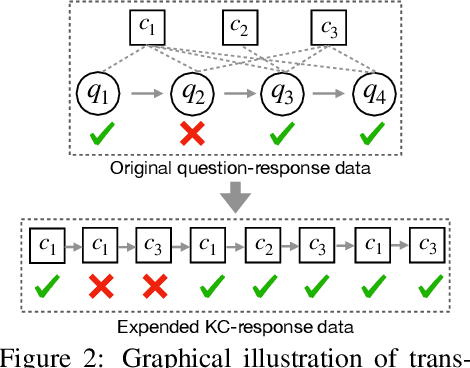
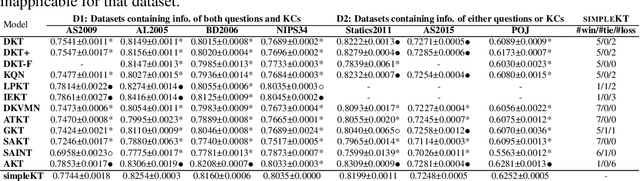
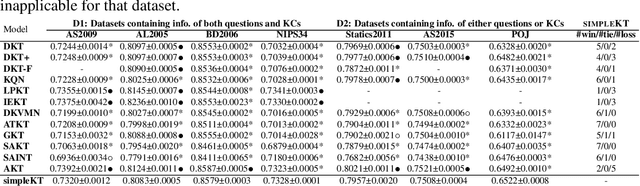
Knowledge tracing (KT) is the problem of predicting students' future performance based on their historical interactions with intelligent tutoring systems. Recently, many works present lots of special methods for applying deep neural networks to KT from different perspectives like model architecture, adversarial augmentation and etc., which make the overall algorithm and system become more and more complex. Furthermore, due to the lack of standardized evaluation protocol \citep{liu2022pykt}, there is no widely agreed KT baselines and published experimental comparisons become inconsistent and self-contradictory, i.e., the reported AUC scores of DKT on ASSISTments2009 range from 0.721 to 0.821 \citep{minn2018deep,yeung2018addressing}. Therefore, in this paper, we provide a strong but simple baseline method to deal with the KT task named \textsc{simpleKT}. Inspired by the Rasch model in psychometrics, we explicitly model question-specific variations to capture the individual differences among questions covering the same set of knowledge components that are a generalization of terms of concepts or skills needed for learners to accomplish steps in a task or a problem. Furthermore, instead of using sophisticated representations to capture student forgetting behaviors, we use the ordinary dot-product attention function to extract the time-aware information embedded in the student learning interactions. Extensive experiments show that such a simple baseline is able to always rank top 3 in terms of AUC scores and achieve 57 wins, 3 ties and 16 loss against 12 DLKT baseline methods on 7 public datasets of different domains. We believe this work serves as a strong baseline for future KT research. Code is available at \url{https://github.com/pykt-team/pykt-toolkit}\footnote{We merged our model to the \textsc{pyKT} benchmark at \url{https://pykt.org/}.}.
SCONNA: A Stochastic Computing Based Optical Accelerator for Ultra-Fast, Energy-Efficient Inference of Integer-Quantized CNNs
Feb 14, 2023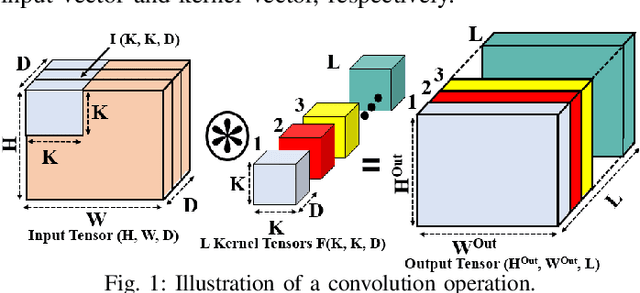
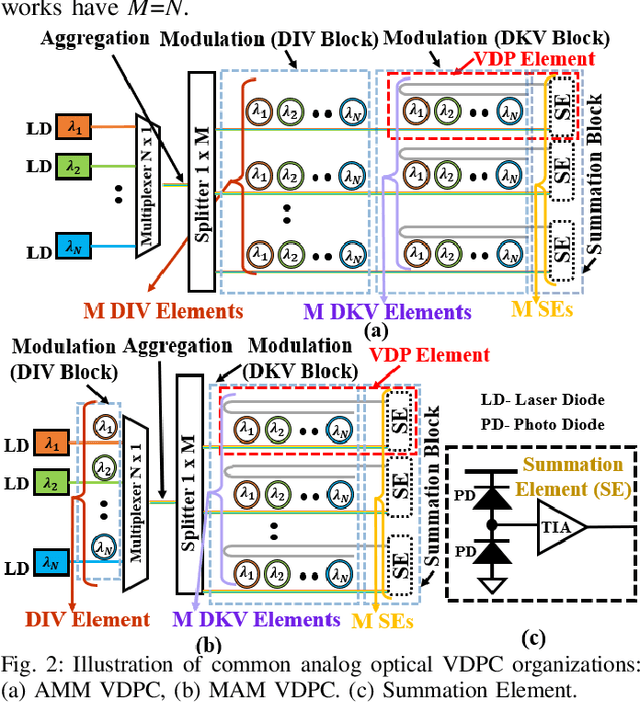
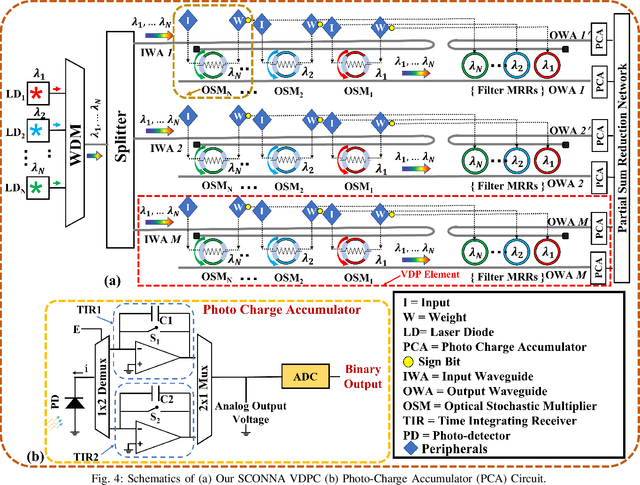
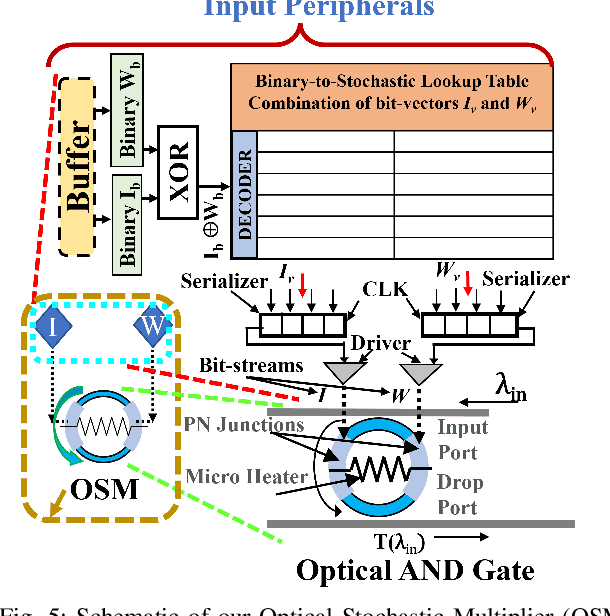
The acceleration of a CNN inference task uses convolution operations that are typically transformed into vector-dot-product (VDP) operations. Several photonic microring resonators (MRRs) based hardware architectures have been proposed to accelerate integer-quantized CNNs with remarkably higher throughput and energy efficiency compared to their electronic counterparts. However, the existing photonic MRR-based analog accelerators exhibit a very strong trade-off between the achievable input/weight precision and VDP operation size, which severely restricts their achievable VDP operation size for the quantized input/weight precision of 4 bits and higher. The restricted VDP operation size ultimately suppresses computing throughput to severely diminish the achievable performance benefits. To address this shortcoming, we for the first time present a merger of stochastic computing and MRR-based CNN accelerators. To leverage the innate precision flexibility of stochastic computing, we invent an MRR-based optical stochastic multiplier (OSM). We employ multiple OSMs in a cascaded manner using dense wavelength division multiplexing, to forge a novel Stochastic Computing based Optical Neural Network Accelerator (SCONNA). SCONNA achieves significantly high throughput and energy efficiency for accelerating inferences of high-precision quantized CNNs. Our evaluation for the inference of four modern CNNs at 8-bit input/weight precision indicates that SCONNA provides improvements of up to 66.5x, 90x, and 91x in frames-per-second (FPS), FPS/W and FPS/W/mm2, respectively, on average over two photonic MRR-based analog CNN accelerators from prior work, with Top-1 accuracy drop of only up to 0.4% for large CNNs and up to 1.5% for small CNNs. We developed a transaction-level, event-driven python-based simulator for the evaluation of SCONNA and other accelerators (https://github.com/uky-UCAT/SC_ONN_SIM.git).
Deep Seam Prediction for Image Stitching Based on Selection Consistency Loss
Feb 10, 2023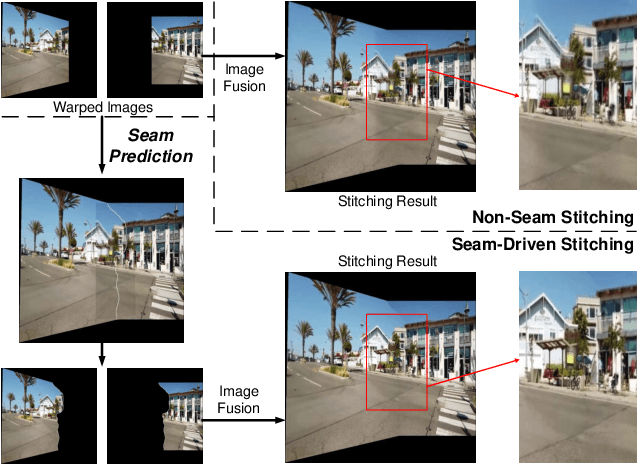
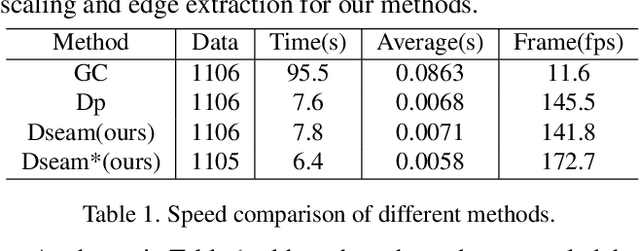
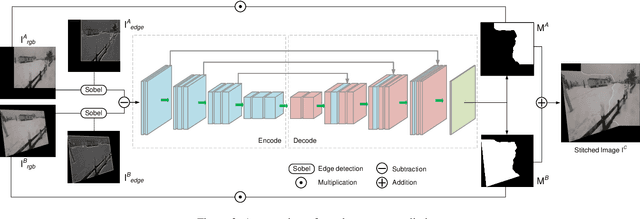
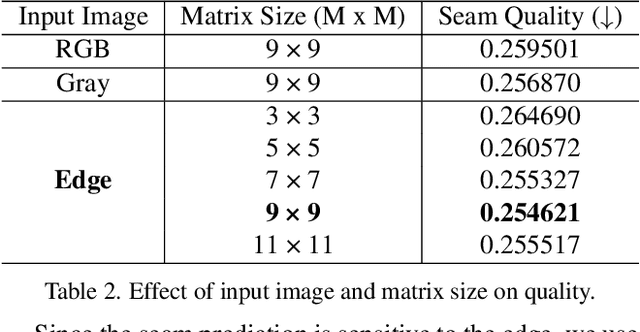
Image stitching is to construct panoramic images with wider field of vision (FOV) from some images captured from different viewing positions. To solve the problem of fusion ghosting in the stitched image, seam-driven methods avoid the misalignment area to fuse images by predicting the best seam. Currently, as standard tools of the OpenCV library, dynamic programming (DP) and GraphCut (GC) are still the only commonly used seam prediction methods despite the fact that they were both proposed two decades ago. However, GC can get excellent seam quality but poor real-time performance while DP method has good efficiency but poor seam quality. In this paper, we propose a deep learning based seam prediction method (DSeam) for the sake of high seam quality with high efficiency. To overcome the difficulty of the seam description in network and no GroundTruth for training we design a selective consistency loss combining the seam shape constraint and seam quality constraint to supervise the network learning. By the constraint of the selection of consistency loss, we implicitly defined the mask boundaries as seams and transform seam prediction into mask prediction. To our knowledge, the proposed DSeam is the first deep learning based seam prediction method for image stitching. Extensive experimental results well demonstrate the superior performance of our proposed Dseam method which is 15 times faster than the classic GC seam prediction method in OpenCV 2.4.9 with similar seam quality.
Learning from Stochastic Labels
Feb 01, 2023
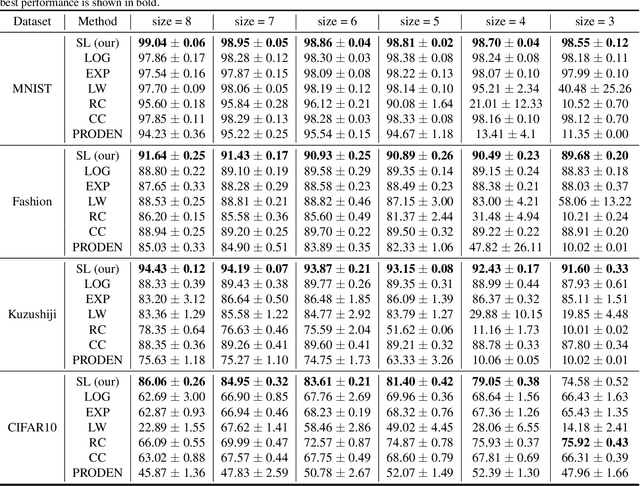
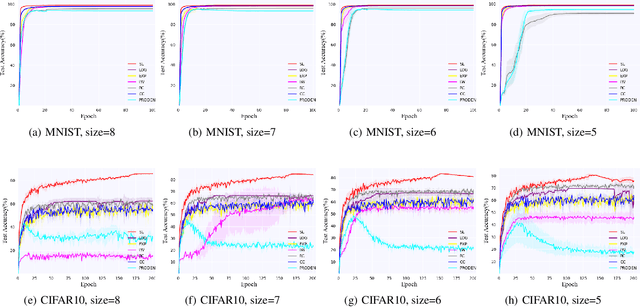
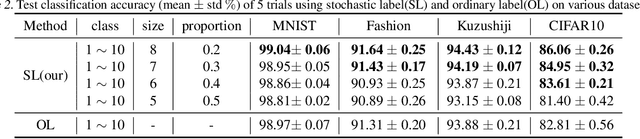
Annotating multi-class instances is a crucial task in the field of machine learning. Unfortunately, identifying the correct class label from a long sequence of candidate labels is time-consuming and laborious. To alleviate this problem, we design a novel labeling mechanism called stochastic label. In this setting, stochastic label includes two cases: 1) identify a correct class label from a small number of randomly given labels; 2) annotate the instance with None label when given labels do not contain correct class label. In this paper, we propose a novel suitable approach to learn from these stochastic labels. We obtain an unbiased estimator that utilizes less supervised information in stochastic labels to train a multi-class classifier. Additionally, it is theoretically justifiable by deriving the estimation error bound of the proposed method. Finally, we conduct extensive experiments on widely-used benchmark datasets to validate the superiority of our method by comparing it with existing state-of-the-art methods.
Energy Efficient Training of SNN using Local Zeroth Order Method
Feb 05, 2023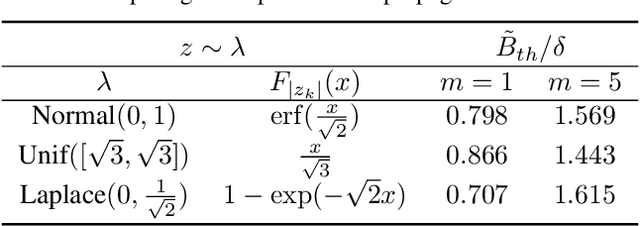
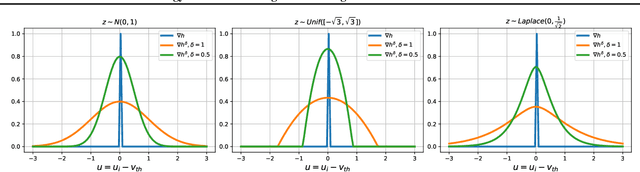
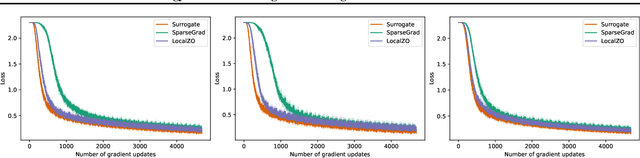
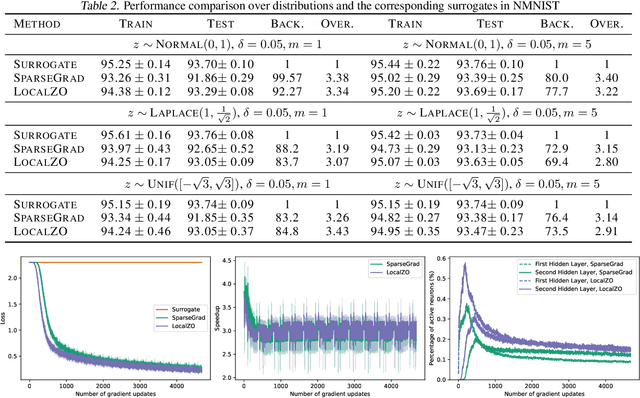
Spiking neural networks are becoming increasingly popular for their low energy requirement in real-world tasks with accuracy comparable to the traditional ANNs. SNN training algorithms face the loss of gradient information and non-differentiability due to the Heaviside function in minimizing the model loss over model parameters. To circumvent the problem surrogate method uses a differentiable approximation of the Heaviside in the backward pass, while the forward pass uses the Heaviside as the spiking function. We propose to use the zeroth order technique at the neuron level to resolve this dichotomy and use it within the automatic differentiation tool. As a result, we establish a theoretical connection between the proposed local zeroth-order technique and the existing surrogate methods and vice-versa. The proposed method naturally lends itself to energy-efficient training of SNNs on GPUs. Experimental results with neuromorphic datasets show that such implementation requires less than 1 percent neurons to be active in the backward pass, resulting in a 100x speed-up in the backward computation time. Our method offers better generalization compared to the state-of-the-art energy-efficient technique while maintaining similar efficiency.