 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Less, but Stronger: On the Value of Strong Heuristics in Semi-supervised Learning for Software Analytics
Feb 03, 2023

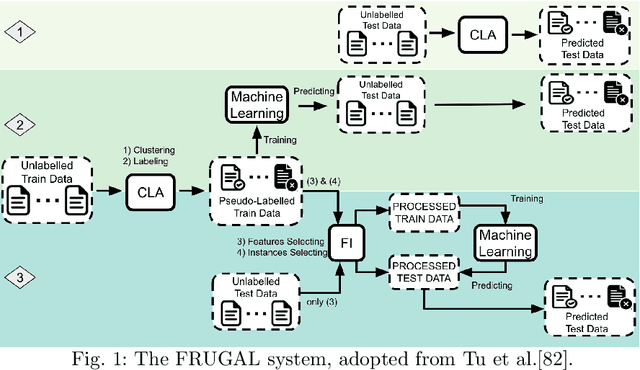
In many domains, there are many examples and far fewer labels for those examples; e.g. we may have access to millions of lines of source code, but access to only a handful of warnings about that code. In those domains, semi-supervised learners (SSL) can extrapolate labels from a small number of examples to the rest of the data. Standard SSL algorithms use ``weak'' knowledge (i.e. those not based on specific SE knowledge) such as (e.g.) co-train two learners and use good labels from one to train the other. Another approach of SSL in software analytics is potentially use ``strong'' knowledge that use SE knowledge. For example, an often-used heuristic in SE is that unusually large artifacts contain undesired properties (e.g. more bugs). This paper argues that such ``strong'' algorithms perform better than those standard, weaker, SSL algorithms. We show this by learning models from labels generated using weak SSL or our ``stronger'' FRUGAL algorithm. In four domains (distinguishing security-related bug reports; mitigating bias in decision-making; predicting issue close time; and (reducing false alarms in static code warnings), FRUGAL required only 2.5% of the data to be labeled yet out-performed standard semi-supervised learners that relied on (e.g.) some domain-independent graph theory concepts. Hence, for future work, we strongly recommend the use of strong heuristics for semi-supervised learning for SE applications. To better support other researchers, our scripts and data are on-line at https://github.com/HuyTu7/FRUGAL.
Faster DAN: Multi-target Queries with Document Positional Encoding for End-to-end Handwritten Document Recognition
Jan 25, 2023
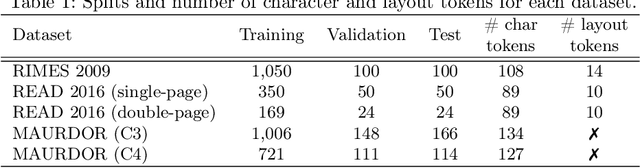
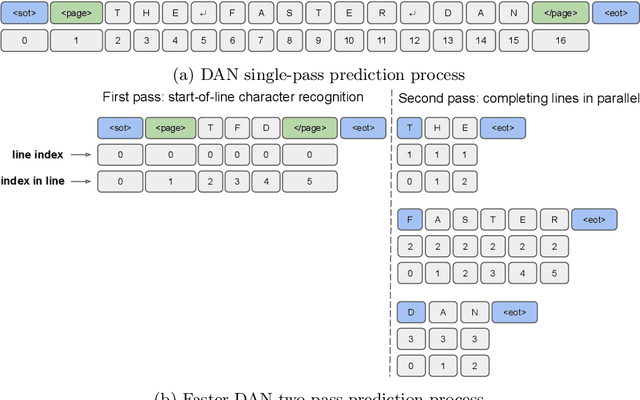
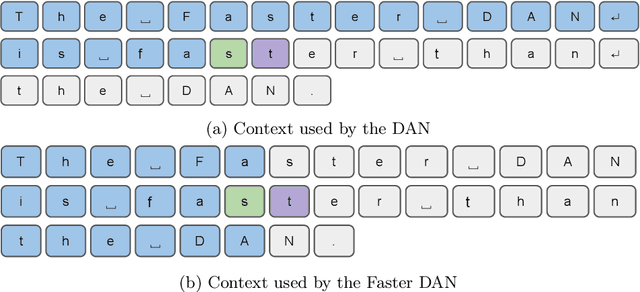
Recent advances in handwritten text recognition enabled to recognize whole documents in an end-to-end way: the Document Attention Network (DAN) recognizes the characters one after the other through an attention-based prediction process until reaching the end of the document. However, this autoregressive process leads to inference that cannot benefit from any parallelization optimization. In this paper, we propose Faster DAN, a two-step strategy to speed up the recognition process at prediction time: the model predicts the first character of each text line in the document, and then completes all the text lines in parallel through multi-target queries and a specific document positional encoding scheme. Faster DAN reaches competitive results compared to standard DAN, while being at least 4 times faster on whole single-page and double-page images of the RIMES 2009, READ 2016 and MAURDOR datasets. Source code and trained model weights are available at https://github.com/FactoDeepLearning/FasterDAN.
An Incremental Inverse Reinforcement Learning Approach for Motion Planning with Human Preferences
Jan 25, 2023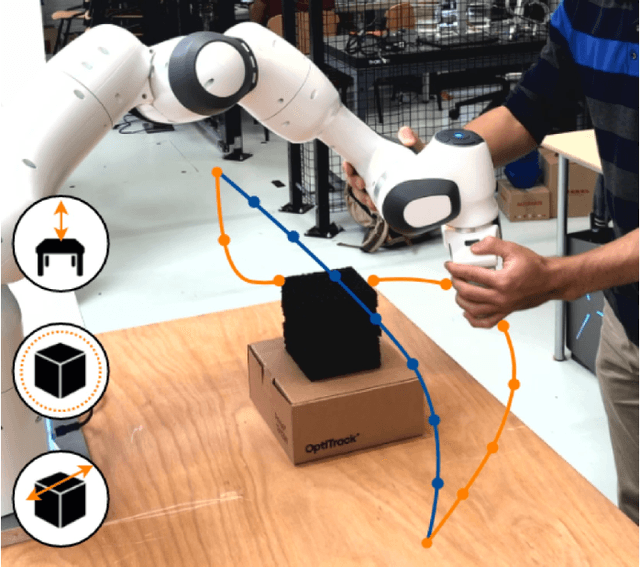
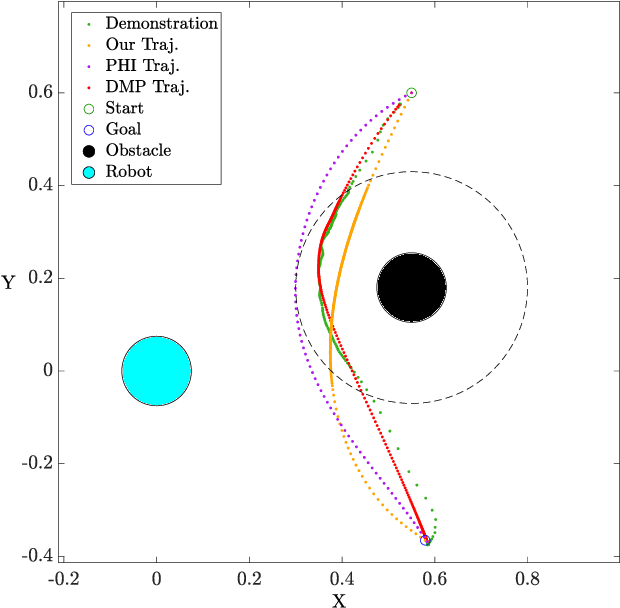
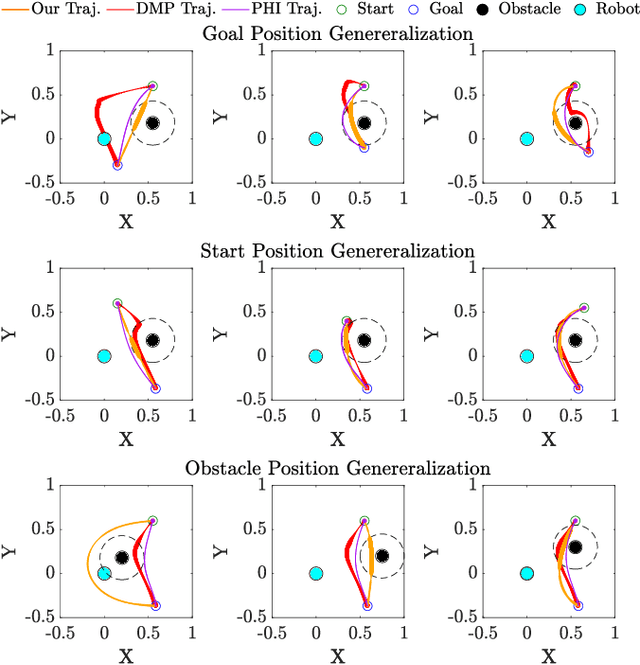
Humans often demonstrate diverse behaviors due to their personal preferences, for instance related to their individual execution style or personal margin for safety. In this paper, we consider the problem of integrating such preferences into trajectory planning for robotic manipulators. We first learn reward functions that represent the user path and motion preferences from kinesthetic demonstration. We then use a discrete-time trajectory optimization scheme to produce trajectories that adhere to both task requirements and user preferences. We go beyond the state of art by designing a feature set that captures the fundamental preferences in a manipulation task, such as timing of the motion. We further demonstrate that our method is capable of generalizing such preferences to new scenarios. We implement our algorithm on a Franka Emika 7-DoF robot arm, and validate the functionality and flexibility of our approach in a user study. The results show that non-expert users are able to teach the robot their preferences with just a few iterations of feedback.
Towards Arbitrary Text-driven Image Manipulation via Space Alignment
Jan 25, 2023
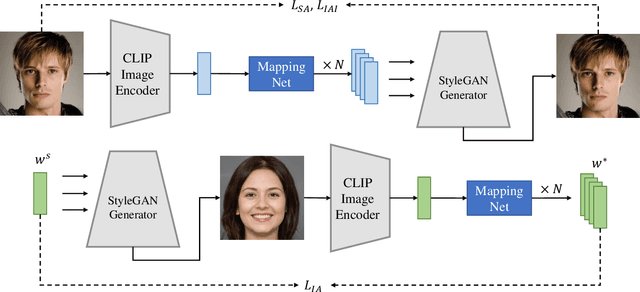
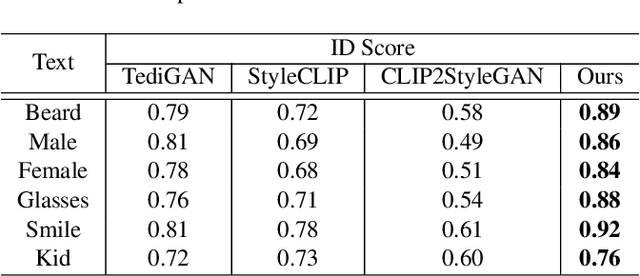
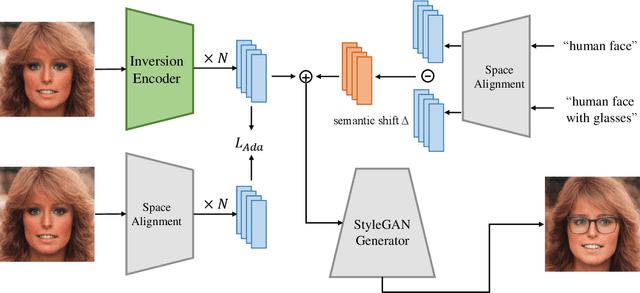
The recent GAN inversion methods have been able to successfully invert the real image input to the corresponding editable latent code in StyleGAN. By combining with the language-vision model (CLIP), some text-driven image manipulation methods are proposed. However, these methods require extra costs to perform optimization for a certain image or a new attribute editing mode. To achieve a more efficient editing method, we propose a new Text-driven image Manipulation framework via Space Alignment (TMSA). The Space Alignment module aims to align the same semantic regions in CLIP and StyleGAN spaces. Then, the text input can be directly accessed into the StyleGAN space and be used to find the semantic shift according to the text description. The framework can support arbitrary image editing mode without additional cost. Our work provides the user with an interface to control the attributes of a given image according to text input and get the result in real time. Ex tensive experiments demonstrate our superior performance over prior works.
Optimal and Robust Waveform Design for MIMO-OFDM Channel Sensing: A Cramér-Rao Bound Perspective
Jan 25, 2023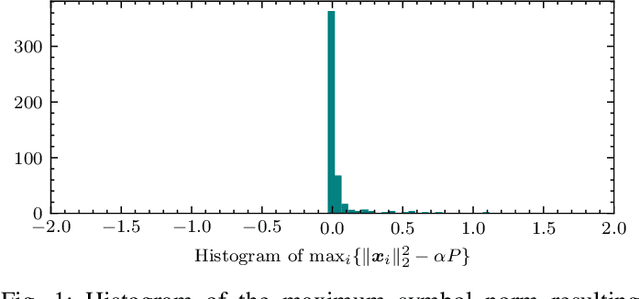
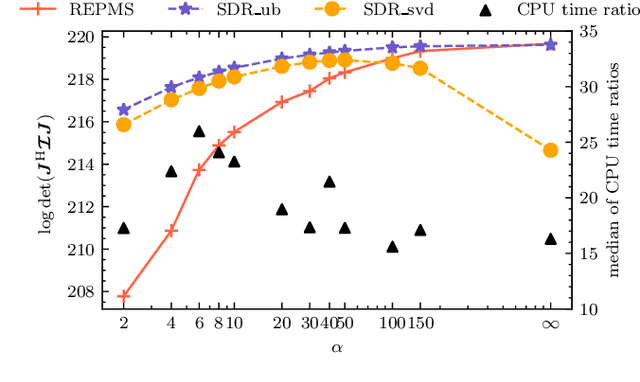
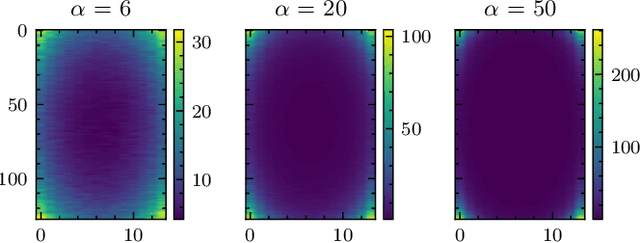
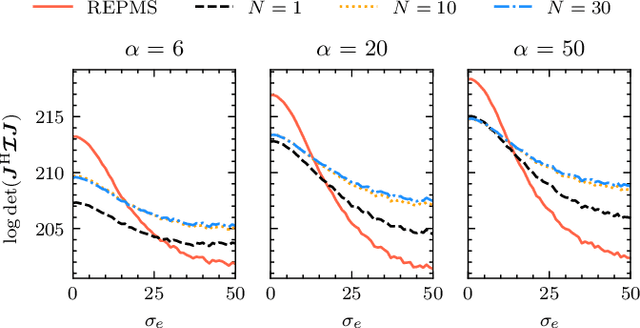
Wireless channel sensing is one of the key enablers for integrated sensing and communication (ISAC) which helps communication networks understand the surrounding environment. In this work, we consider MIMO-OFDM systems and aim to design optimal and robust waveforms for accurate channel parameter estimation given allocated OFDM resources. The Fisher information matrix (FIM) is derived first, and the waveform design problem is formulated by maximizing the log determinant of the FIM. We then consider the uncertainty in the parameters and state the stochastic optimization problem for a robust design. We propose the Riemannian Exact Penalty Method via Smoothing (REPMS) and its stochastic version SREPMS to solve the constrained non-convex problems. In simulations, we show that the REPMS yields comparable results to the semidefinite relaxation (SDR) but with a much shorter running time. Finally, the designed robust waveforms using SREMPS are investigated, and are shown to have a good performance under channel perturbations.
Data Consistent Deep Rigid MRI Motion Correction
Jan 25, 2023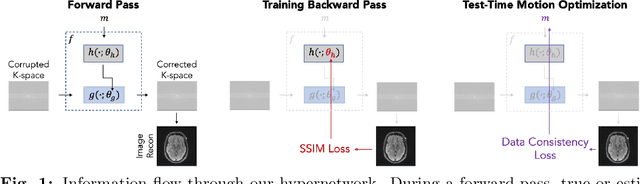
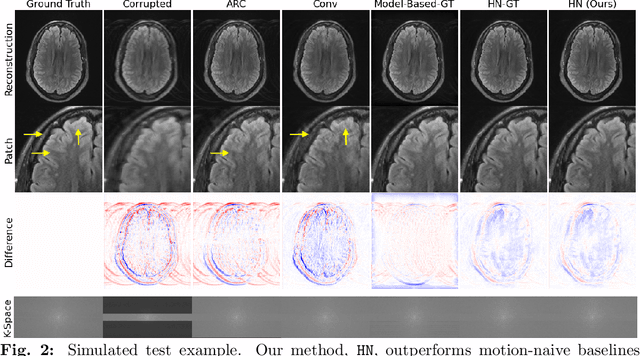
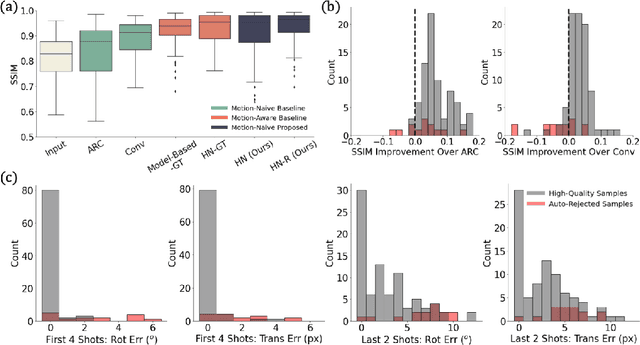
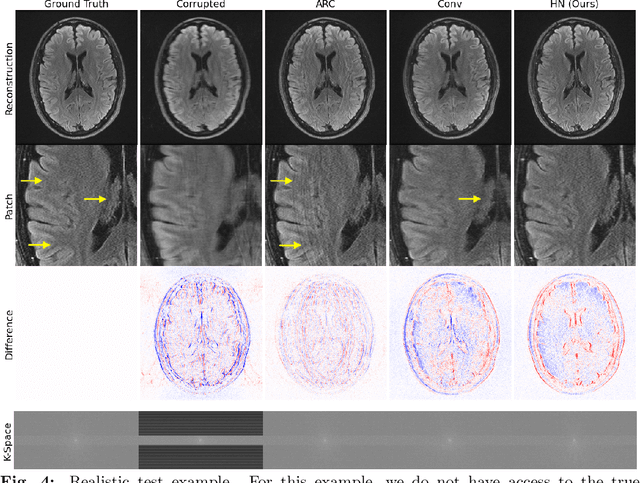
Motion artifacts are a pervasive problem in MRI, leading to misdiagnosis or mischaracterization in population-level imaging studies. Current retrospective rigid intra-slice motion correction techniques jointly optimize estimates of the image and the motion parameters. In this paper, we use a deep network to reduce the joint image-motion parameter search to a search over rigid motion parameters alone. Our network produces a reconstruction as a function of two inputs: corrupted k-space data and motion parameters. We train the network using simulated, motion-corrupted k-space data generated from known motion parameters. At test-time, we estimate unknown motion parameters by minimizing a data consistency loss between the motion parameters, the network-based image reconstruction given those parameters, and the acquired measurements. Intra-slice motion correction experiments on simulated and realistic 2D fast spin echo brain MRI achieve high reconstruction fidelity while retaining the benefits of explicit data consistency-based optimization. Our code is publicly available at https://www.github.com/nalinimsingh/neuroMoCo.
Scaling in Depth: Unlocking Robustness Certification on ImageNet
Jan 29, 2023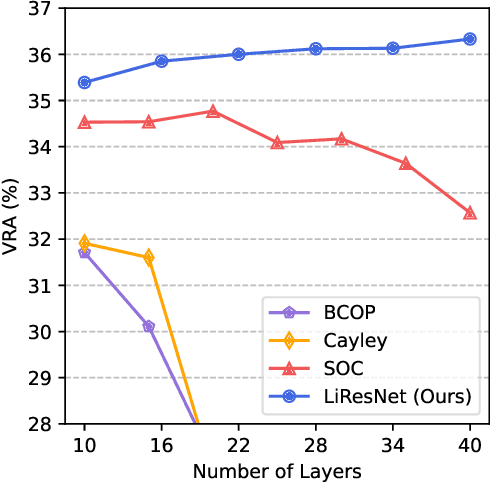
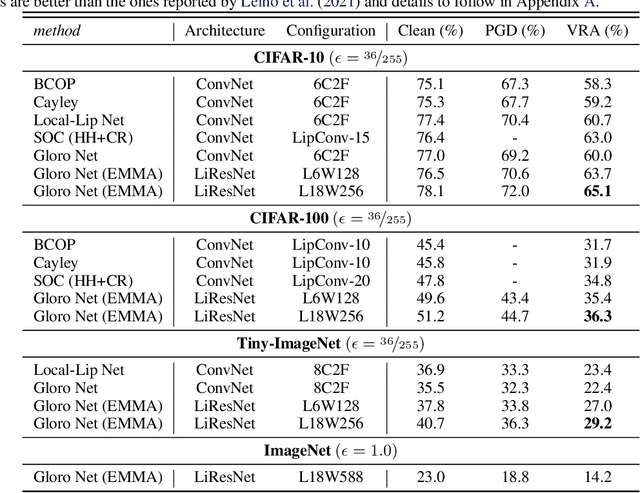
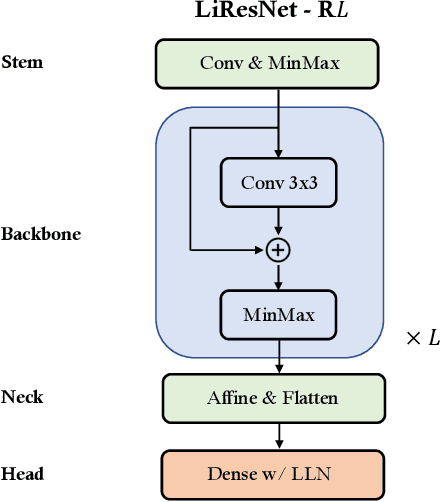
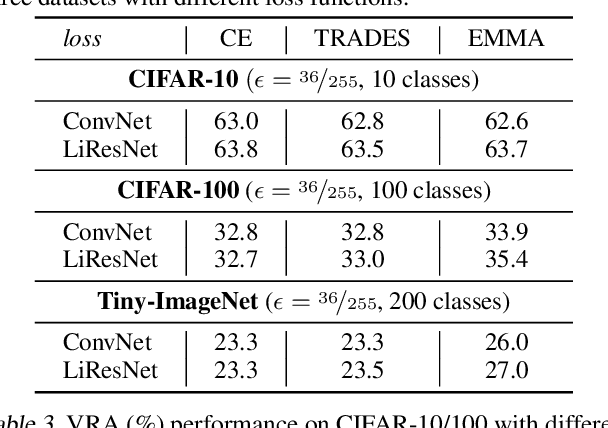
Notwithstanding the promise of Lipschitz-based approaches to \emph{deterministically} train and certify robust deep networks, the state-of-the-art results only make successful use of feed-forward Convolutional Networks (ConvNets) on low-dimensional data, e.g. CIFAR-10. Because ConvNets often suffer from vanishing gradients when going deep, large-scale datasets with many classes, e.g., ImageNet, have remained out of practical reach. This paper investigates ways to scale up certifiably robust training to Residual Networks (ResNets). First, we introduce the \emph{Linear ResNet} (LiResNet) architecture, which utilizes a new residual block designed to facilitate \emph{tighter} Lipschitz bounds compared to a conventional residual block. Second, we introduce Efficient Margin MAximization (EMMA), a loss function that stabilizes robust training by simultaneously penalizing worst-case adversarial examples from \emph{all} classes. Combining LiResNet and EMMA, we achieve new \emph{state-of-the-art} robust accuracy on CIFAR-10/100 and Tiny-ImageNet under $\ell_2$-norm-bounded perturbations. Moreover, for the first time, we are able to scale up deterministic robustness guarantees to ImageNet, bringing hope to the possibility of applying deterministic certification to real-world applications.
Continual Learning for Predictive Maintenance: Overview and Challenges
Jan 29, 2023
Machine learning techniques have become one of the main propellers for solving many engineering problems effectively and efficiently. In Predictive Maintenance, for instance, Data-Driven methods have been used to improve predictions of when maintenance is needed on different machines and operative contexts. However, one of the limitations of these methods is that they are trained on a fixed distribution that does not change over time, which seldom happens in real-world applications. When internal or external factors alter the data distribution, the model performance may decrease or even fail unpredictably, resulting in severe consequences for machine maintenance. Continual Learning methods propose ways of adapting prediction models and incorporating new knowledge after deployment. The main objective of these methods is to avoid the plasticity-stability dilemma by updating the parametric model while not forgetting previously learned tasks. In this work, we present the current state of the art in applying Continual Learning to Predictive Maintenance, with an extensive review of both disciplines. We first introduce the two research themes independently, then discuss the current intersection of Continual Learning and Predictive Maintenance. Finally, we discuss the main research directions and conclusions.
Latent Autoregressive Source Separation
Jan 09, 2023

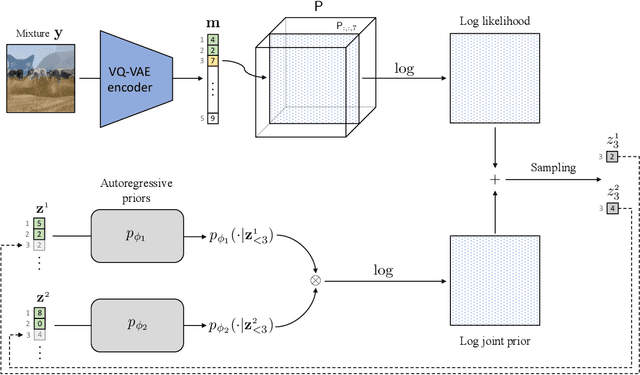
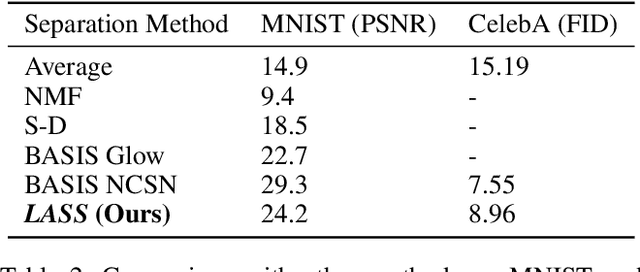
Autoregressive models have achieved impressive results over a wide range of domains in terms of generation quality and downstream task performance. In the continuous domain, a key factor behind this success is the usage of quantized latent spaces (e.g., obtained via VQ-VAE autoencoders), which allow for dimensionality reduction and faster inference times. However, using existing pre-trained models to perform new non-trivial tasks is difficult since it requires additional fine-tuning or extensive training to elicit prompting. This paper introduces LASS as a way to perform vector-quantized Latent Autoregressive Source Separation (i.e., de-mixing an input signal into its constituent sources) without requiring additional gradient-based optimization or modifications of existing models. Our separation method relies on the Bayesian formulation in which the autoregressive models are the priors, and a discrete (non-parametric) likelihood function is constructed by performing frequency counts over latent sums of addend tokens. We test our method on images and audio with several sampling strategies (e.g., ancestral, beam search) showing competitive results with existing approaches in terms of separation quality while offering at the same time significant speedups in terms of inference time and scalability to higher dimensional data.
Balance is Essence: Accelerating Sparse Training via Adaptive Gradient Correction
Jan 09, 2023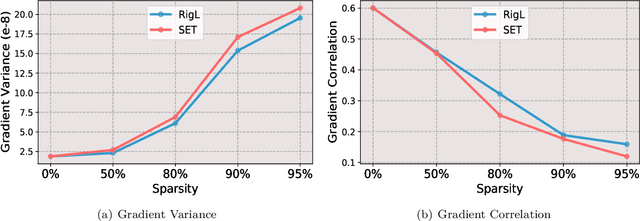
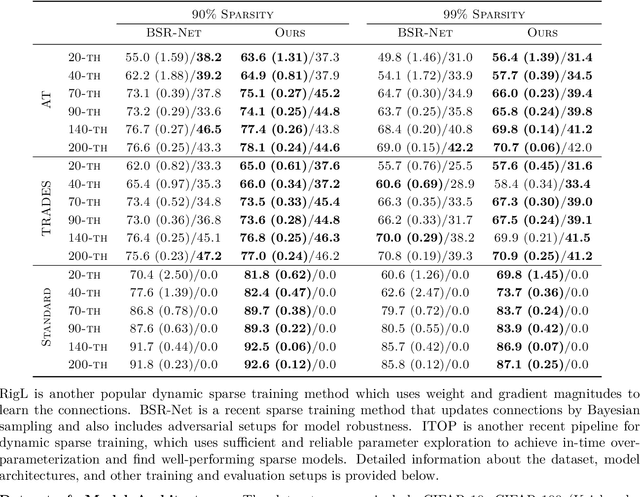
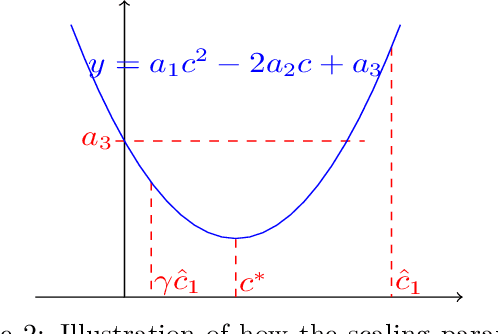
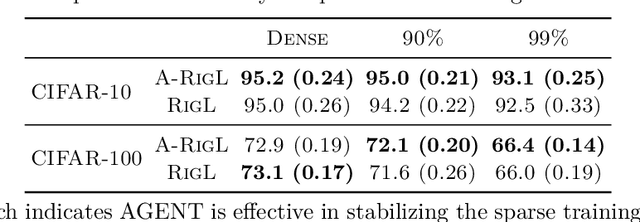
Despite impressive performance on a wide variety of tasks, deep neural networks require significant memory and computation costs, prohibiting their application in resource-constrained scenarios. Sparse training is one of the most common techniques to reduce these costs, however, the sparsity constraints add difficulty to the optimization, resulting in an increase in training time and instability. In this work, we aim to overcome this problem and achieve space-time co-efficiency. To accelerate and stabilize the convergence of sparse training, we analyze the gradient changes and develop an adaptive gradient correction method. Specifically, we approximate the correlation between the current and previous gradients, which is used to balance the two gradients to obtain a corrected gradient. Our method can be used with most popular sparse training pipelines under both standard and adversarial setups. Theoretically, we prove that our method can accelerate the convergence rate of sparse training. Extensive experiments on multiple datasets, model architectures, and sparsities demonstrate that our method outperforms leading sparse training methods by up to \textbf{5.0\%} in accuracy given the same number of training epochs, and reduces the number of training epochs by up to \textbf{52.1\%} to achieve the same accuracy.