 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Computation of Map-scale Continuous Mutual Information on Chip in Real Time
Oct 07, 2022
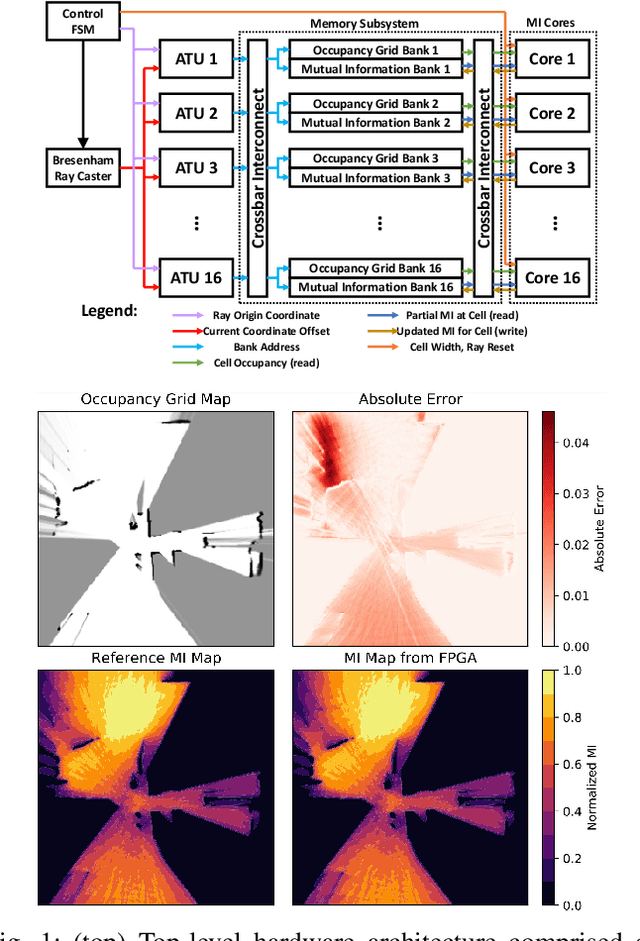
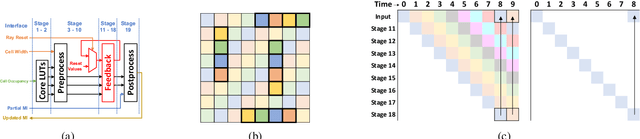
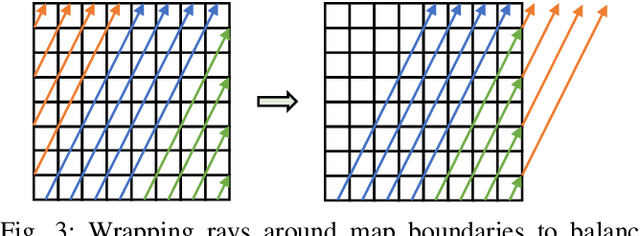
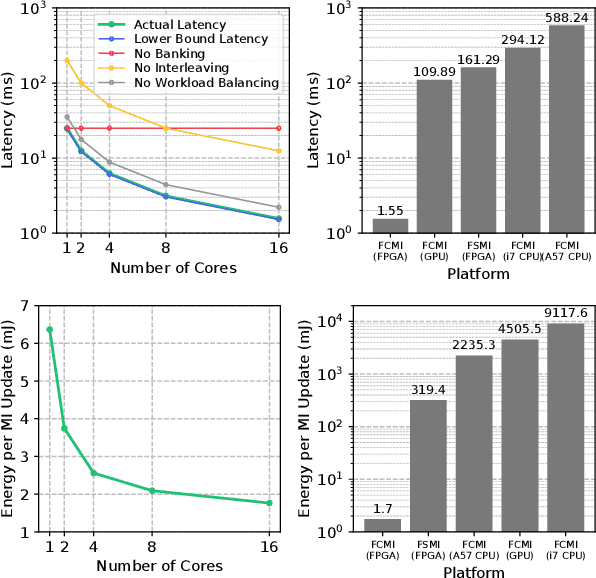
Exploration tasks are essential to many emerging robotics applications, ranging from search and rescue to space exploration. The planning problem for exploration requires determining the best locations for future measurements that will enhance the fidelity of the map, for example, by reducing its total entropy. A widely-studied technique involves computing the Mutual Information (MI) between the current map and future measurements, and utilizing this MI metric to decide the locations for future measurements. However, computing MI for reasonably-sized maps is slow and power hungry, which has been a bottleneck towards fast and efficient robotic exploration. In this paper, we introduce a new hardware accelerator architecture for MI computation that features a low-latency, energy-efficient MI compute core and an optimized memory subsystem that provides sufficient bandwidth to keep the cores fully utilized. The core employs interleaving to counter the recursive algorithm, and workload balancing and numerical approximations to reduce latency and energy consumption. We demonstrate this optimized architecture with a Field-Programmable Gate Array (FPGA) implementation, which can compute MI for all cells in an entire 201-by-201 occupancy grid ({\em e.g.}, representing a 20.1m-by-20.1m map at 0.1m resolution) in 1.55 ms while consuming 1.7 mJ of energy, thus finally rendering MI computation for the whole map real time and at a fraction of the energy cost of traditional compute platforms. For comparison, this particular FPGA implementation running on the Xilinx Zynq-7000 platform is two orders of magnitude faster and consumes three orders of magnitude less energy per MI map compute, when compared to a baseline GPU implementation running on an NVIDIA GeForce GTX 980 platform. The improvements are more pronounced when compared to CPU implementations of equivalent algorithms.
Generalizable Memory-driven Transformer for Multivariate Long Sequence Time-series Forecasting
Jul 16, 2022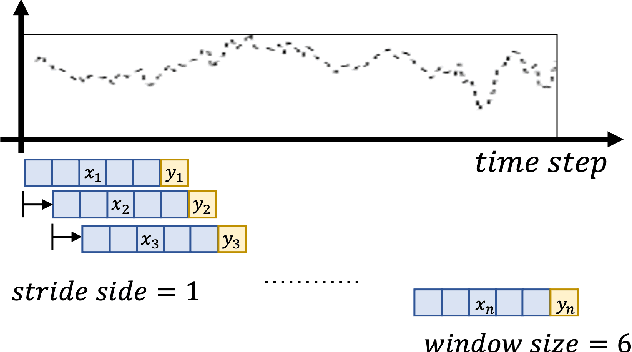
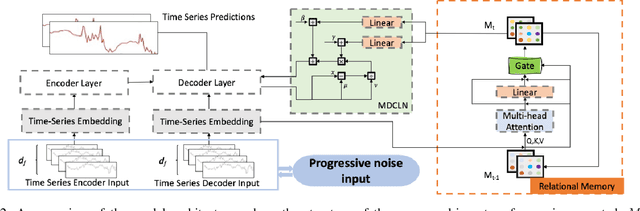
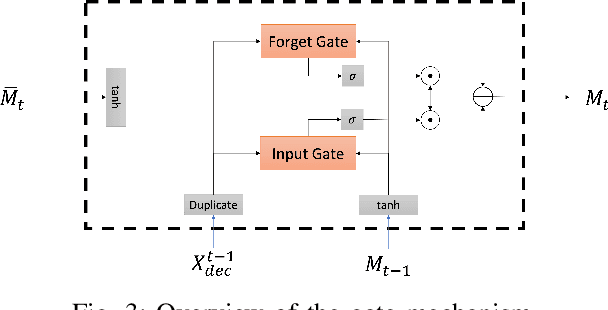
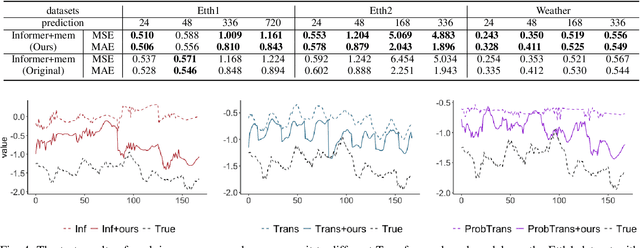
Multivariate long sequence time-series forecasting (M-LSTF) is a practical but challenging problem. Unlike traditional timer-series forecasting tasks, M-LSTF tasks are more challenging from two aspects: 1) M-LSTF models need to learn time-series patterns both within and between multiple time features; 2) Under the rolling forecasting setting, the similarity between two consecutive training samples increases with the increasing prediction length, which makes models more prone to overfitting. In this paper, we propose a generalizable memory-driven Transformer to target M-LSTF problems. Specifically, we first propose a global-level memory component to drive the forecasting procedure by integrating multiple time-series features. In addition, we adopt a progressive fashion to train our model to increase its generalizability, in which we gradually introduce Bernoulli noises to training samples. Extensive experiments have been performed on five different datasets across multiple fields. Experimental results demonstrate that our approach can be seamlessly plugged into varying Transformer-based models to improve their performances up to roughly 30%. Particularly, this is the first work to specifically focus on the M-LSTF tasks to the best of our knowledge.
Counterfactual Explanations for Land Cover Mapping in a Multi-class Setting
Jan 04, 2023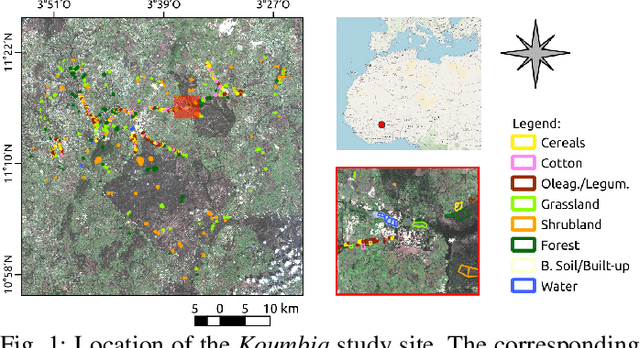
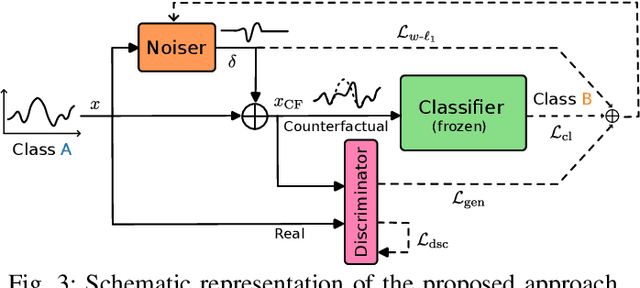
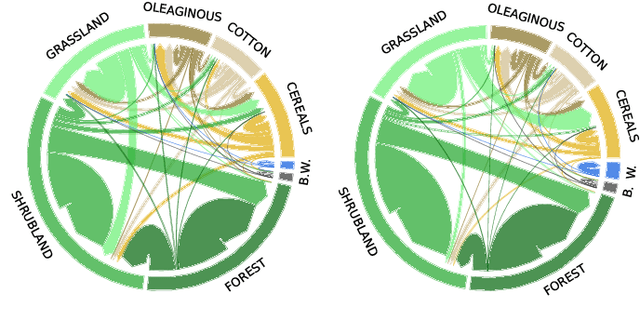
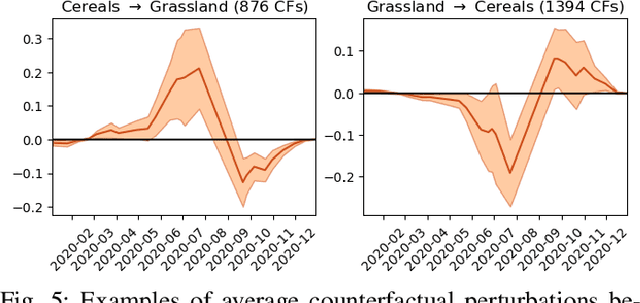
Counterfactual explanations are an emerging tool to enhance interpretability of deep learning models. Given a sample, these methods seek to find and display to the user similar samples across the decision boundary. In this paper, we propose a generative adversarial counterfactual approach for satellite image time series in a multi-class setting for the land cover classification task. One of the distinctive features of the proposed approach is the lack of prior assumption on the targeted class for a given counterfactual explanation. This inherent flexibility allows for the discovery of interesting information on the relationship between land cover classes. The other feature consists of encouraging the counterfactual to differ from the original sample only in a small and compact temporal segment. These time-contiguous perturbations allow for a much sparser and, thus, interpretable solution. Furthermore, plausibility/realism of the generated counterfactual explanations is enforced via the proposed adversarial learning strategy.
Learning Decorrelated Representations Efficiently Using Fast Fourier Transform
Jan 04, 2023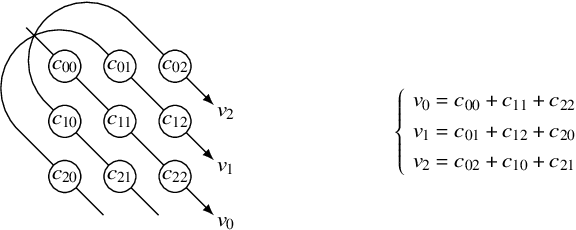
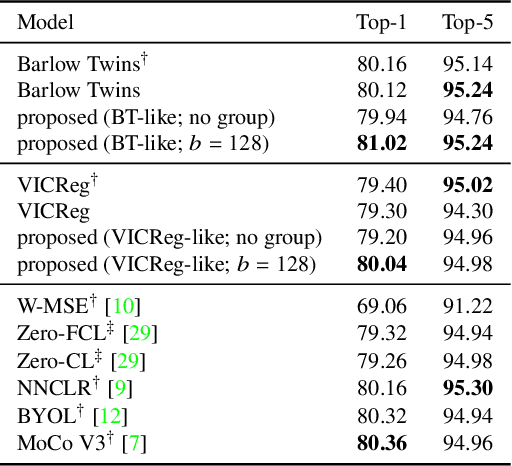
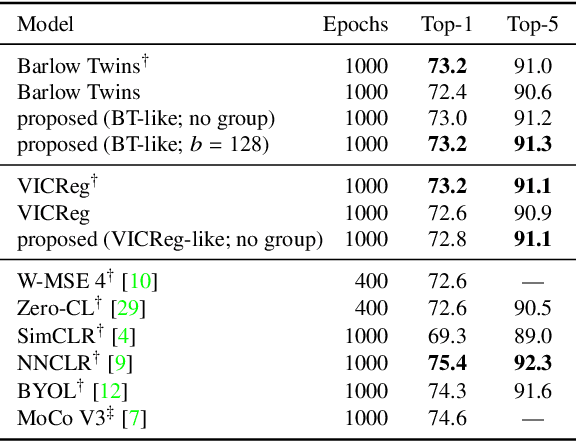
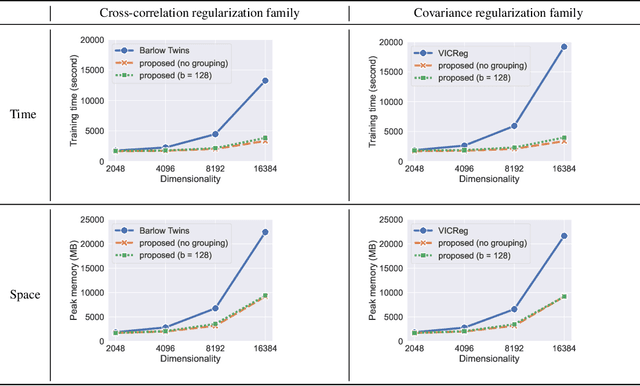
Barlow Twins and VICReg are self-supervised representation learning models that use regularizers to decorrelate features. Although they work as well as conventional representation learning models, their training can be computationally demanding if the dimension of projected representations is high; as these regularizers are defined in terms of individual elements of a cross-correlation or covariance matrix, computing the loss for $d$-dimensional projected representations of $n$ samples takes $O(n d^2)$ time. In this paper, we propose a relaxed version of decorrelating regularizers that can be computed in $O(n d\log d)$ time by the fast Fourier transform. We also propose an inexpensive trick to mitigate the undesirable local minima that develop with the relaxation. Models learning representations using the proposed regularizers show comparable accuracy to existing models in downstream tasks, whereas the training requires less memory and is faster when $d$ is large.
Less, but Stronger: On the Value of Strong Heuristics in Semi-supervised Learning for Software Analytics
Feb 03, 2023
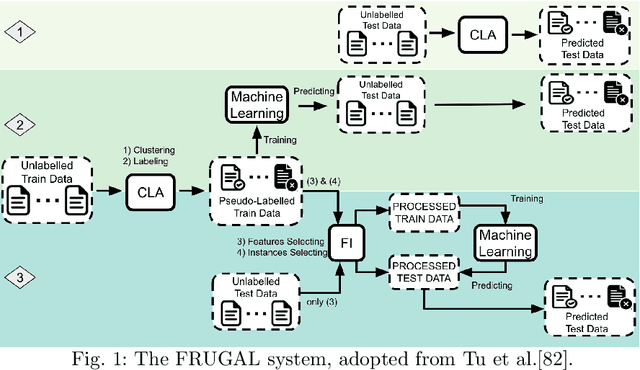
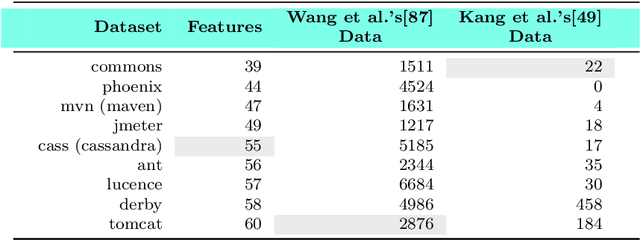
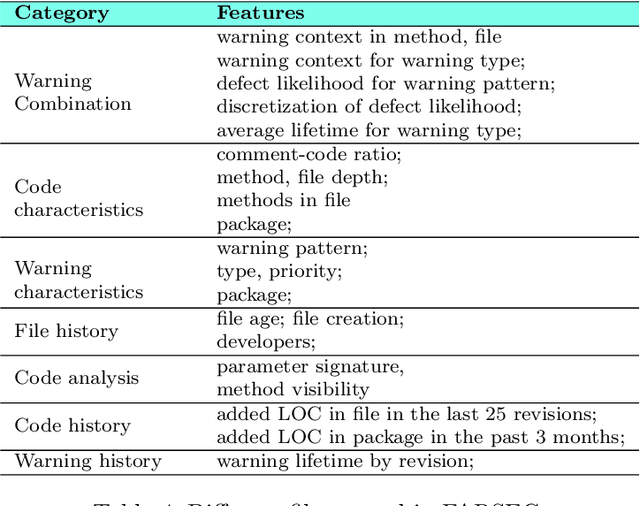
In many domains, there are many examples and far fewer labels for those examples; e.g. we may have access to millions of lines of source code, but access to only a handful of warnings about that code. In those domains, semi-supervised learners (SSL) can extrapolate labels from a small number of examples to the rest of the data. Standard SSL algorithms use ``weak'' knowledge (i.e. those not based on specific SE knowledge) such as (e.g.) co-train two learners and use good labels from one to train the other. Another approach of SSL in software analytics is potentially use ``strong'' knowledge that use SE knowledge. For example, an often-used heuristic in SE is that unusually large artifacts contain undesired properties (e.g. more bugs). This paper argues that such ``strong'' algorithms perform better than those standard, weaker, SSL algorithms. We show this by learning models from labels generated using weak SSL or our ``stronger'' FRUGAL algorithm. In four domains (distinguishing security-related bug reports; mitigating bias in decision-making; predicting issue close time; and (reducing false alarms in static code warnings), FRUGAL required only 2.5% of the data to be labeled yet out-performed standard semi-supervised learners that relied on (e.g.) some domain-independent graph theory concepts. Hence, for future work, we strongly recommend the use of strong heuristics for semi-supervised learning for SE applications. To better support other researchers, our scripts and data are on-line at https://github.com/HuyTu7/FRUGAL.
From slides (through tiles) to pixels: an explainability framework for weakly supervised models in pre-clinical pathology
Feb 03, 2023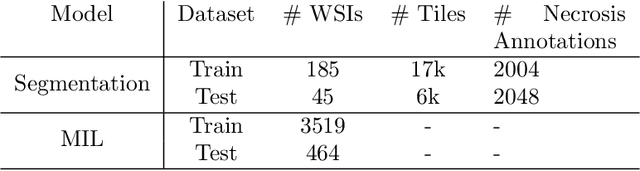
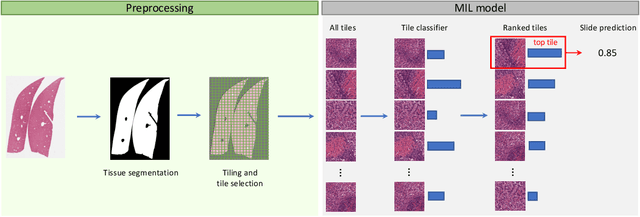

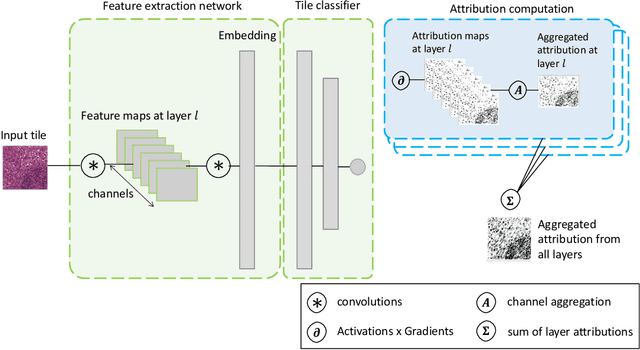
In pre-clinical pathology, there is a paradox between the abundance of raw data (whole slide images from many organs of many individual animals) and the lack of pixel-level slide annotations done by pathologists. Due to time constraints and requirements from regulatory authorities, diagnoses are instead stored as slide labels. Weakly supervised training is designed to take advantage of those data, and the trained models can be used by pathologists to rank slides by their probability of containing a given lesion of interest. In this work, we propose a novel contextualized eXplainable AI (XAI) framework and its application to deep learning models trained on Whole Slide Images (WSIs) in Digital Pathology. Specifically, we apply our methods to a multi-instance-learning (MIL) model, which is trained solely on slide-level labels, without the need for pixel-level annotations. We validate quantitatively our methods by quantifying the agreements of our explanations' heatmaps with pathologists' annotations, as well as with predictions from a segmentation model trained on such annotations. We demonstrate the stability of the explanations with respect to input shifts, and the fidelity with respect to increased model performance. We quantitatively evaluate the correlation between available pixel-wise annotations and explainability heatmaps. We show that the explanations on important tiles of the whole slide correlate with tissue changes between healthy regions and lesions, but do not exactly behave like a human annotator. This result is coherent with the model training strategy.
Domain Adaptation via Alignment of Operation Profile for Remaining Useful Lifetime Prediction
Feb 03, 2023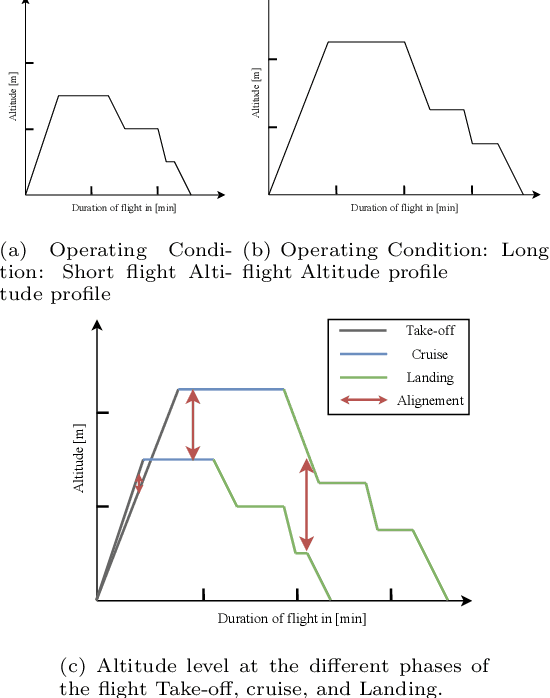
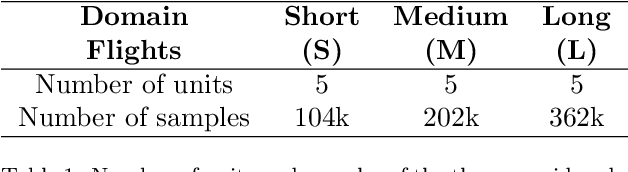
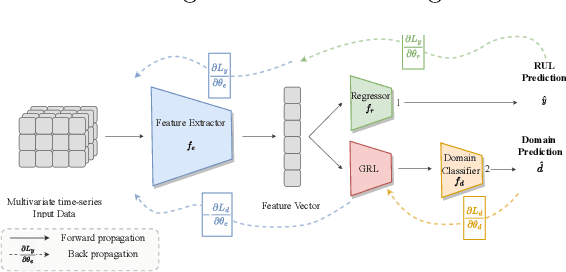
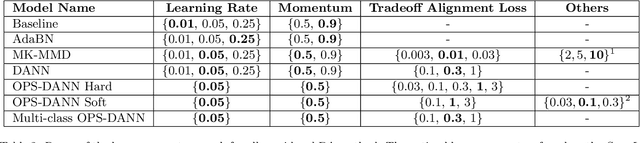
Effective Prognostics and Health Management (PHM) relies on accurate prediction of the Remaining Useful Life (RUL). Data-driven RUL prediction techniques rely heavily on the representativeness of the available time-to-failure trajectories. Therefore, these methods may not perform well when applied to data from new units of a fleet that follow different operating conditions than those they were trained on. This is also known as domain shifts. Domain adaptation (DA) methods aim to address the domain shift problem by extracting domain invariant features. However, DA methods do not distinguish between the different phases of operation, such as steady states or transient phases. This can result in misalignment due to under- or over-representation of different operation phases. This paper proposes two novel DA approaches for RUL prediction based on an adversarial domain adaptation framework that considers the different phases of the operation profiles separately. The proposed methodologies align the marginal distributions of each phase of the operation profile in the source domain with its counterpart in the target domain. The effectiveness of the proposed methods is evaluated using the New Commercial Modular Aero-Propulsion System (N-CMAPSS) dataset, where sub-fleets of turbofan engines operating in one of the three different flight classes (short, medium, and long) are treated as separate domains. The experimental results show that the proposed methods improve the accuracy of RUL predictions compared to current state-of-the-art DA methods.
Faster DAN: Multi-target Queries with Document Positional Encoding for End-to-end Handwritten Document Recognition
Jan 25, 2023
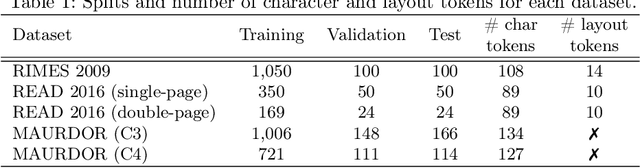
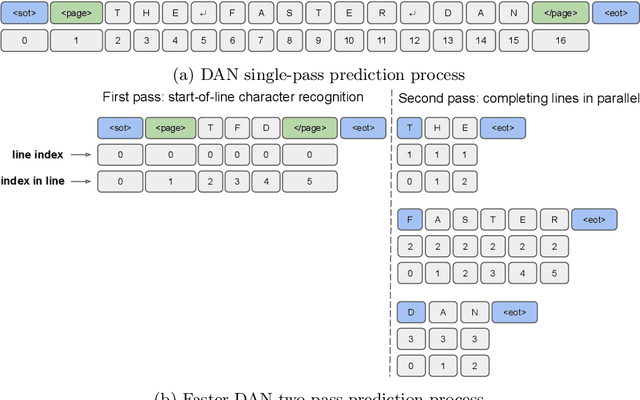
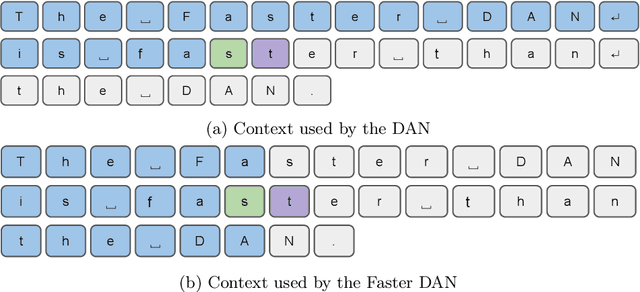
Recent advances in handwritten text recognition enabled to recognize whole documents in an end-to-end way: the Document Attention Network (DAN) recognizes the characters one after the other through an attention-based prediction process until reaching the end of the document. However, this autoregressive process leads to inference that cannot benefit from any parallelization optimization. In this paper, we propose Faster DAN, a two-step strategy to speed up the recognition process at prediction time: the model predicts the first character of each text line in the document, and then completes all the text lines in parallel through multi-target queries and a specific document positional encoding scheme. Faster DAN reaches competitive results compared to standard DAN, while being at least 4 times faster on whole single-page and double-page images of the RIMES 2009, READ 2016 and MAURDOR datasets. Source code and trained model weights are available at https://github.com/FactoDeepLearning/FasterDAN.
Optimal and Robust Waveform Design for MIMO-OFDM Channel Sensing: A Cramér-Rao Bound Perspective
Jan 25, 2023
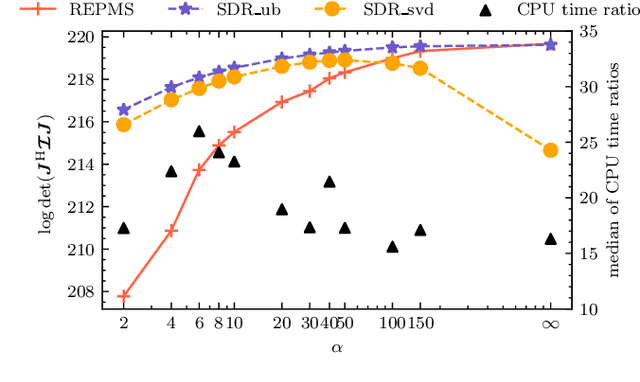
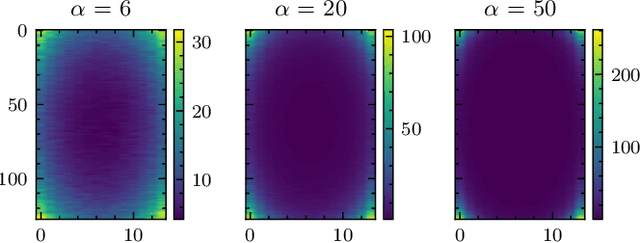
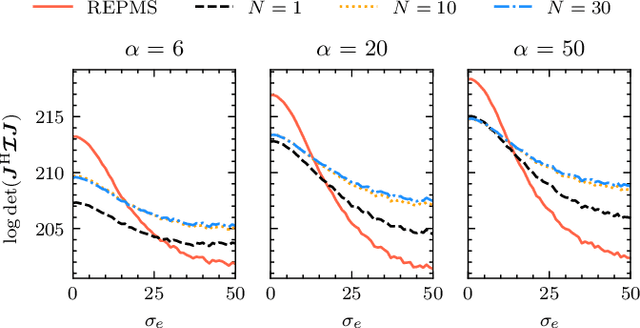
Wireless channel sensing is one of the key enablers for integrated sensing and communication (ISAC) which helps communication networks understand the surrounding environment. In this work, we consider MIMO-OFDM systems and aim to design optimal and robust waveforms for accurate channel parameter estimation given allocated OFDM resources. The Fisher information matrix (FIM) is derived first, and the waveform design problem is formulated by maximizing the log determinant of the FIM. We then consider the uncertainty in the parameters and state the stochastic optimization problem for a robust design. We propose the Riemannian Exact Penalty Method via Smoothing (REPMS) and its stochastic version SREPMS to solve the constrained non-convex problems. In simulations, we show that the REPMS yields comparable results to the semidefinite relaxation (SDR) but with a much shorter running time. Finally, the designed robust waveforms using SREMPS are investigated, and are shown to have a good performance under channel perturbations.
Towards Arbitrary Text-driven Image Manipulation via Space Alignment
Jan 25, 2023
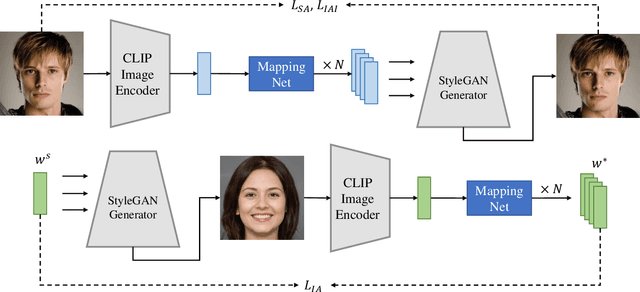
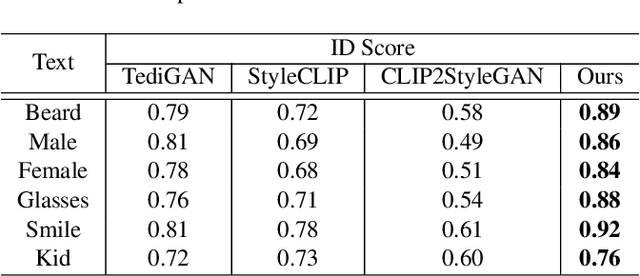
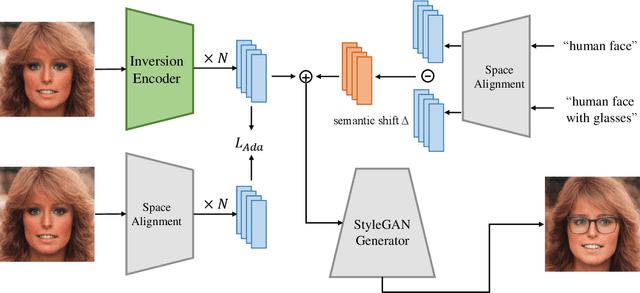
The recent GAN inversion methods have been able to successfully invert the real image input to the corresponding editable latent code in StyleGAN. By combining with the language-vision model (CLIP), some text-driven image manipulation methods are proposed. However, these methods require extra costs to perform optimization for a certain image or a new attribute editing mode. To achieve a more efficient editing method, we propose a new Text-driven image Manipulation framework via Space Alignment (TMSA). The Space Alignment module aims to align the same semantic regions in CLIP and StyleGAN spaces. Then, the text input can be directly accessed into the StyleGAN space and be used to find the semantic shift according to the text description. The framework can support arbitrary image editing mode without additional cost. Our work provides the user with an interface to control the attributes of a given image according to text input and get the result in real time. Ex tensive experiments demonstrate our superior performance over prior works.