 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models
Jan 31, 2023
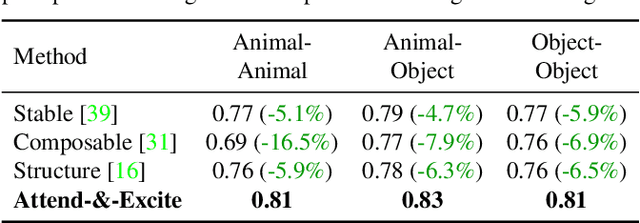

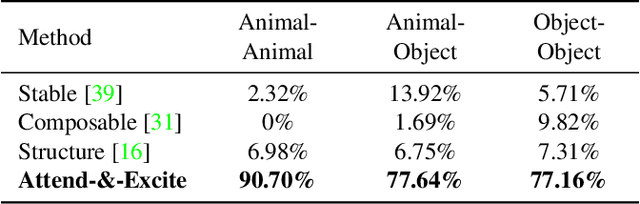
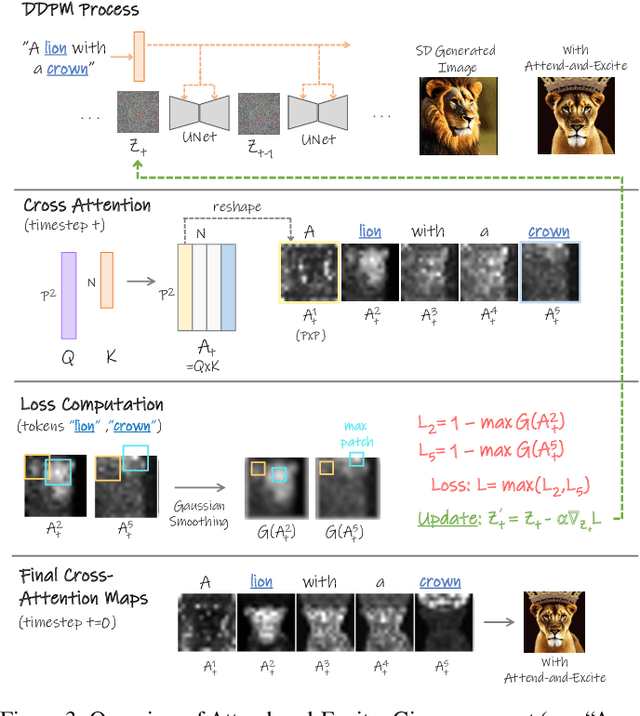
Recent text-to-image generative models have demonstrated an unparalleled ability to generate diverse and creative imagery guided by a target text prompt. While revolutionary, current state-of-the-art diffusion models may still fail in generating images that fully convey the semantics in the given text prompt. We analyze the publicly available Stable Diffusion model and assess the existence of catastrophic neglect, where the model fails to generate one or more of the subjects from the input prompt. Moreover, we find that in some cases the model also fails to correctly bind attributes (e.g., colors) to their corresponding subjects. To help mitigate these failure cases, we introduce the concept of Generative Semantic Nursing (GSN), where we seek to intervene in the generative process on the fly during inference time to improve the faithfulness of the generated images. Using an attention-based formulation of GSN, dubbed Attend-and-Excite, we guide the model to refine the cross-attention units to attend to all subject tokens in the text prompt and strengthen - or excite - their activations, encouraging the model to generate all subjects described in the text prompt. We compare our approach to alternative approaches and demonstrate that it conveys the desired concepts more faithfully across a range of text prompts.
Evaluating Temporal Observation-Based Causal Discovery Techniques Applied to Road Driver Behaviour
Jan 31, 2023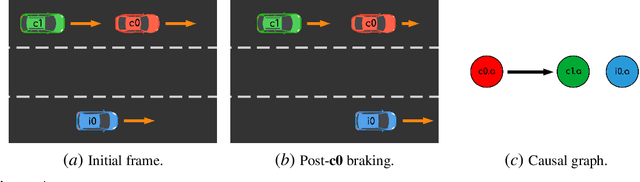
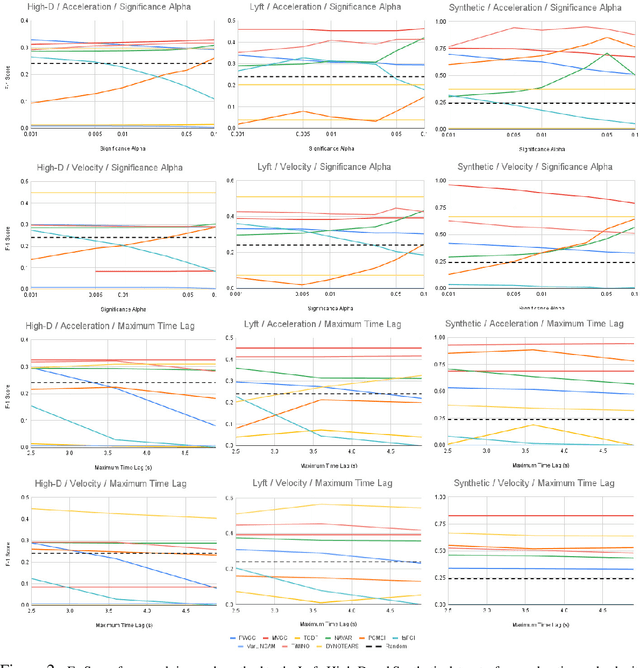
Autonomous robots are required to reason about the behaviour of dynamic agents in their environment. To this end, many approaches assume that causal models describing the interactions of agents are given a priori. However, in many application domains such models do not exist or cannot be engineered. Hence, the learning (or discovery) of high-level causal structures from low-level, temporal observations is a key problem in AI and robotics. However, the application of causal discovery methods to scenarios involving autonomous agents remains in the early stages of research. While a number of methods exist for performing causal discovery on time series data, these usually rely upon assumptions such as sufficiency and stationarity which cannot be guaranteed in interagent behavioural interactions in the real world. In this paper we are applying contemporary observation-based temporal causal discovery techniques to real world and synthetic driving scenarios from multiple datasets. Our evaluation demonstrates and highlights the limitations of state of the art approaches by comparing and contrasting the performance between real and synthetically generated data. Finally, based on our analysis, we discuss open issues related to causal discovery on autonomous robotics scenarios and propose future research directions for overcoming current limitations in the field.
Physics-informed Reduced-Order Learning from the First Principles for Simulation of Quantum Nanostructures
Jan 31, 2023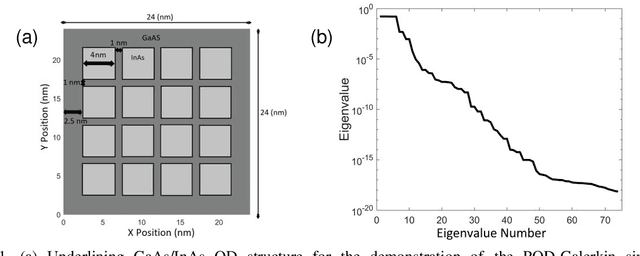
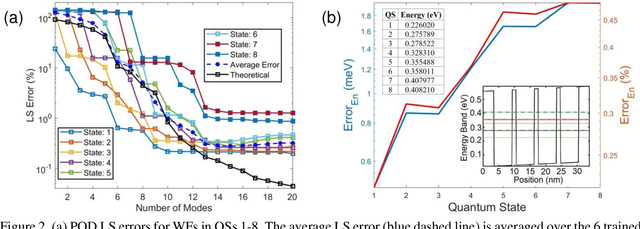
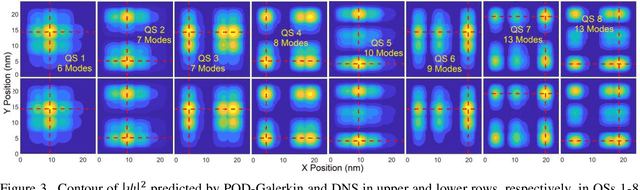
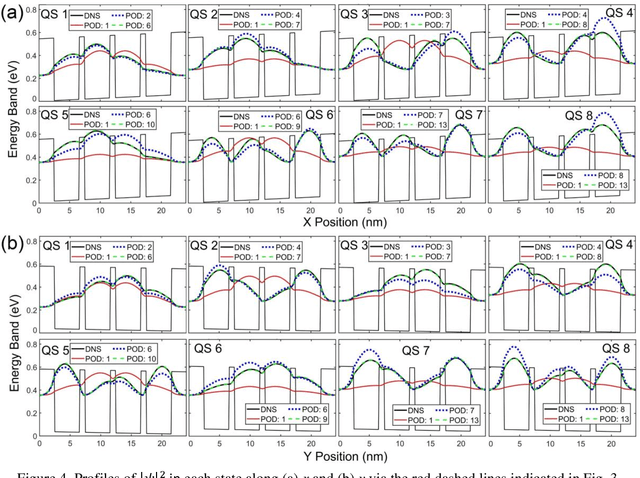
Multi-dimensional direct numerical simulation (DNS) of the Schr\"odinger equation is needed for design and analysis of quantum nanostructures that offer numerous applications in biology, medicine, materials, electronic/photonic devices, etc. In large-scale nanostructures, extensive computational effort needed in DNS may become prohibitive due to the high degrees of freedom (DoF). This study employs a reduced-order learning algorithm, enabled by the first principles, for simulation of the Schr\"odinger equation to achieve high accuracy and efficiency. The proposed simulation methodology is applied to investigate two quantum-dot structures; one operates under external electric field, and the other is influenced by internal potential variation with periodic boundary conditions. The former is similar to typical operations of nanoelectronic devices, and the latter is of interest to simulation and design of nanostructures and materials, such as applications of density functional theory. Using the proposed methodology, a very accurate prediction can be realized with a reduction in the DoF by more than 3 orders of magnitude and in the computational time by 2 orders, compared to DNS. The proposed physics-informed learning methodology is also able to offer an accurate prediction beyond the training conditions, including higher external field and larger internal potential in untrained quantum states.
Hitting time for Markov decision process
May 10, 2022We define the hitting time for a Markov decision process (MDP). We do not use the hitting time of the Markov process induced by the MDP because the induced chain may not have a stationary distribution. Even it has a stationary distribution, the stationary distribution may not coincide with the (normalized) occupancy measure of the MDP. We observe a relationship between the MDP and the PageRank. Using this observation, we construct an MP whose stationary distribution coincides with the normalized occupancy measure of the MDP and we define the hitting time of the MDP as the hitting time of the associated MP.
Frequency-Domain Detection for Molecular Communications
Jan 03, 2023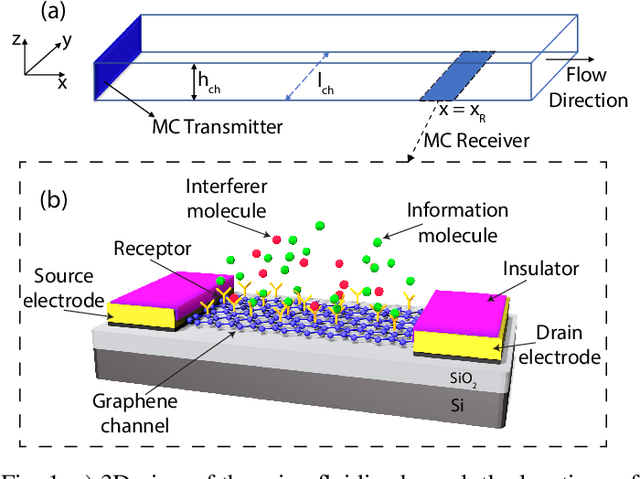
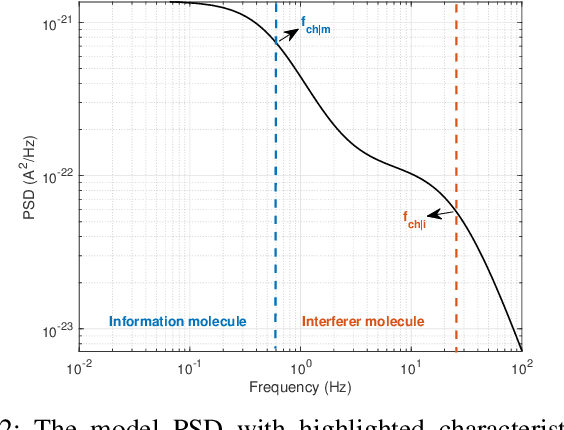
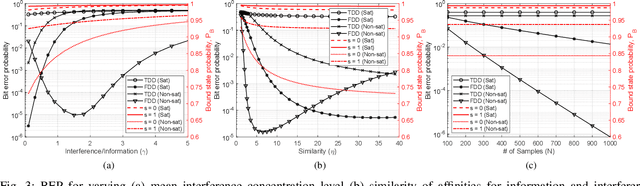
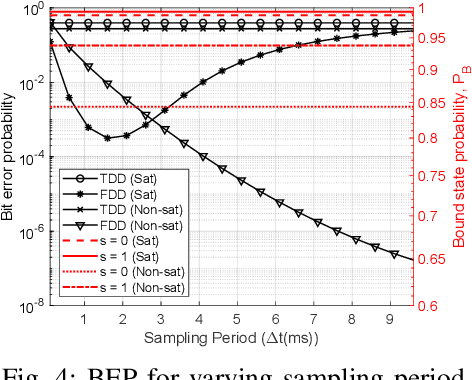
Molecular Communications (MC) is a bio-inspired communication paradigm which uses molecules as information carriers, thereby requiring unconventional transmitter/receiver architectures and modulation/detection techniques. Practical MC receivers (MC-Rxs) can be implemented based on field-effect transistor biosensor (bioFET) architectures, where surface receptors reversibly react with ligands, whose concentration encodes the information. The time-varying concentration of ligand-bound receptors is then translated into electrical signals via field-effect, which is used to decode the transmitted information. However, ligand-receptor interactions do not provide an ideal molecular selectivity, as similar types of ligands, i.e., interferers, co-existing in the MC channel can interact with the same type of receptors, resulting in cross-talk. Overcoming this molecular cross-talk with time-domain samples of the Rx's electrical output is not always attainable, especially when Rx has no knowledge of the interferer statistics or it operates near saturation. In this study, we propose a frequency-domain detection (FDD) technique for bioFET-based MC-Rxs, which exploits the difference in binding reaction rates of different types of ligands, reflected to the noise spectrum of the ligand-receptor binding fluctuations. We analytically derive the bit error probability (BEP) of the FDD technique, and demonstrate its effectiveness in decoding transmitted concentration signals under stochastic molecular interference, in comparison to a widely-used time-domain detection (TDD) technique. The proposed FDD method can be applied to any biosensor-based MC-Rxs, which employ receptor molecules as the channel-Rx interface.
Efficient Computation of Map-scale Continuous Mutual Information on Chip in Real Time
Oct 07, 2022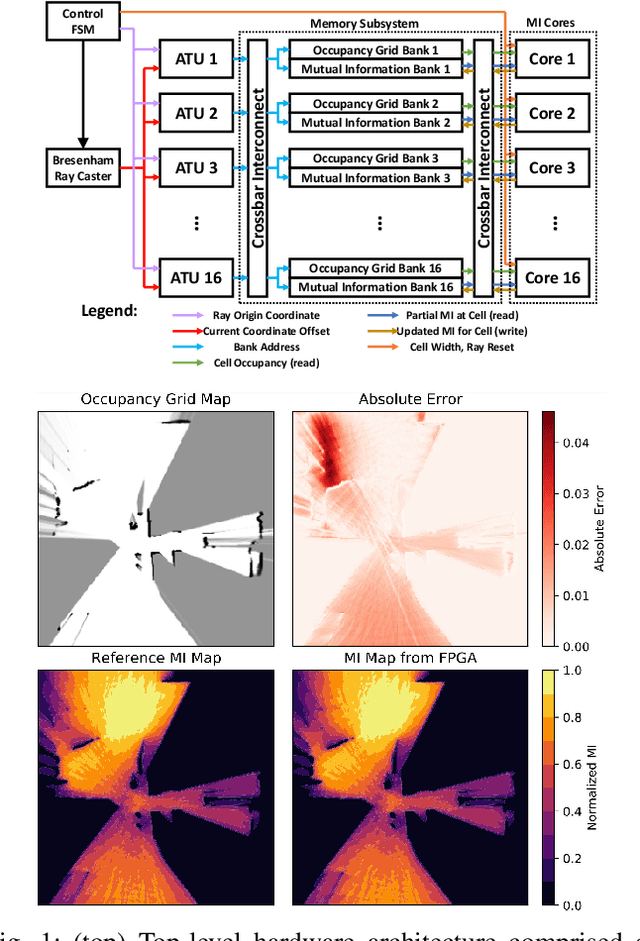
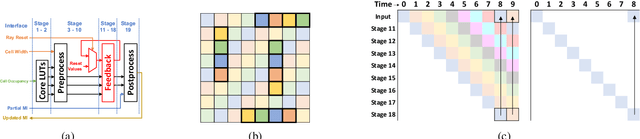
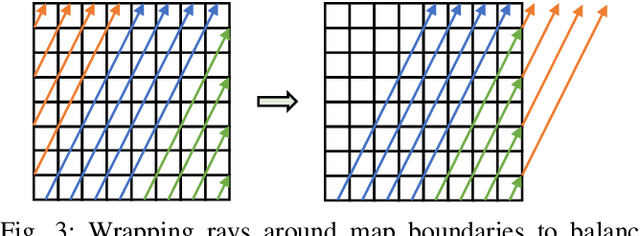
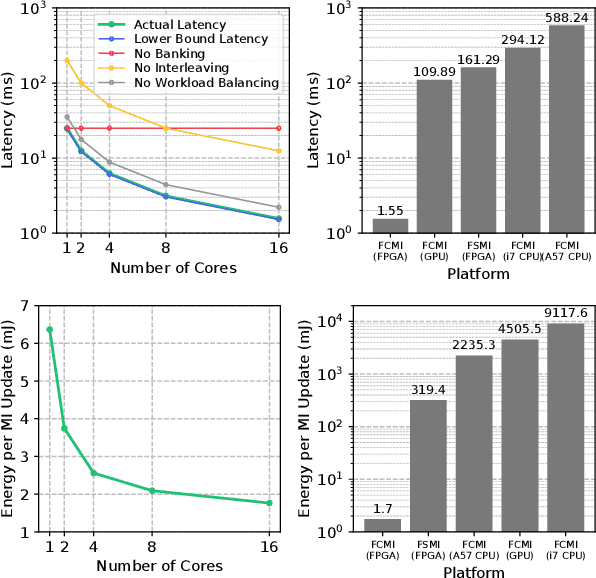
Exploration tasks are essential to many emerging robotics applications, ranging from search and rescue to space exploration. The planning problem for exploration requires determining the best locations for future measurements that will enhance the fidelity of the map, for example, by reducing its total entropy. A widely-studied technique involves computing the Mutual Information (MI) between the current map and future measurements, and utilizing this MI metric to decide the locations for future measurements. However, computing MI for reasonably-sized maps is slow and power hungry, which has been a bottleneck towards fast and efficient robotic exploration. In this paper, we introduce a new hardware accelerator architecture for MI computation that features a low-latency, energy-efficient MI compute core and an optimized memory subsystem that provides sufficient bandwidth to keep the cores fully utilized. The core employs interleaving to counter the recursive algorithm, and workload balancing and numerical approximations to reduce latency and energy consumption. We demonstrate this optimized architecture with a Field-Programmable Gate Array (FPGA) implementation, which can compute MI for all cells in an entire 201-by-201 occupancy grid ({\em e.g.}, representing a 20.1m-by-20.1m map at 0.1m resolution) in 1.55 ms while consuming 1.7 mJ of energy, thus finally rendering MI computation for the whole map real time and at a fraction of the energy cost of traditional compute platforms. For comparison, this particular FPGA implementation running on the Xilinx Zynq-7000 platform is two orders of magnitude faster and consumes three orders of magnitude less energy per MI map compute, when compared to a baseline GPU implementation running on an NVIDIA GeForce GTX 980 platform. The improvements are more pronounced when compared to CPU implementations of equivalent algorithms.
FRAME: Fast and Robust Autonomous 3D point cloud Map-merging for Egocentric multi-robot exploration
Jan 24, 2023
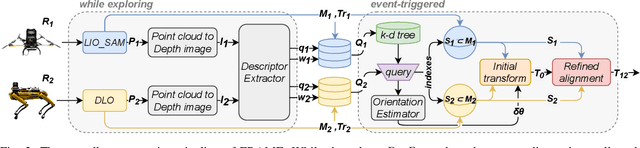
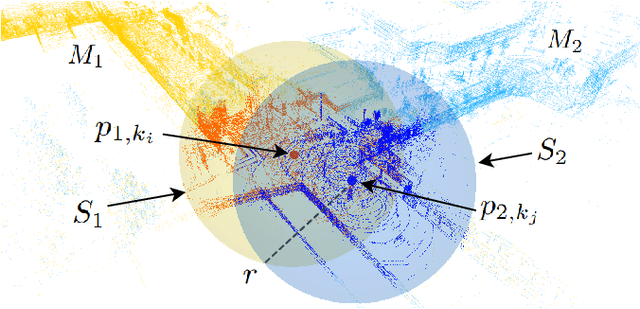
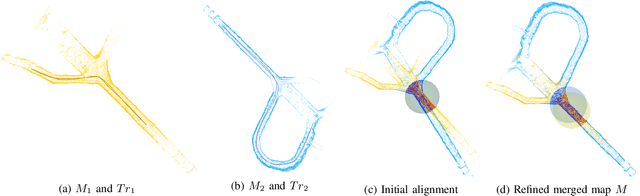
This article presents a 3D point cloud map-merging framework for egocentric heterogeneous multi-robot exploration, based on overlap detection and alignment, that is independent of a manual initial guess or prior knowledge of the robots' poses. The novel proposed solution utilizes state-of-the-art place recognition learned descriptors, that through the framework's main pipeline, offer a fast and robust region overlap estimation, hence eliminating the need for the time-consuming global feature extraction and feature matching process that is typically used in 3D map integration. The region overlap estimation provides a homogeneous rigid transform that is applied as an initial condition in the point cloud registration algorithm Fast-GICP, which provides the final and refined alignment. The efficacy of the proposed framework is experimentally evaluated based on multiple field multi-robot exploration missions in underground environments, where both ground and aerial robots are deployed, with different sensor configurations.
Semi-Automated Construction of Food Composition Knowledge Base
Jan 24, 2023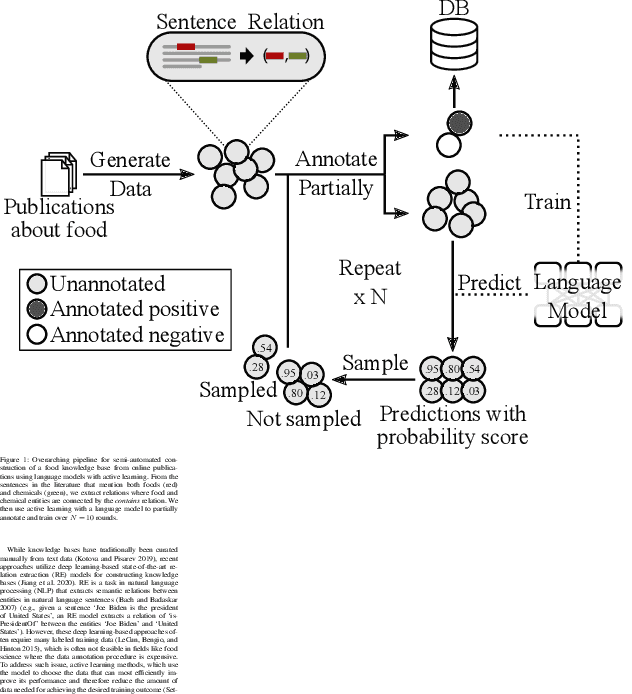
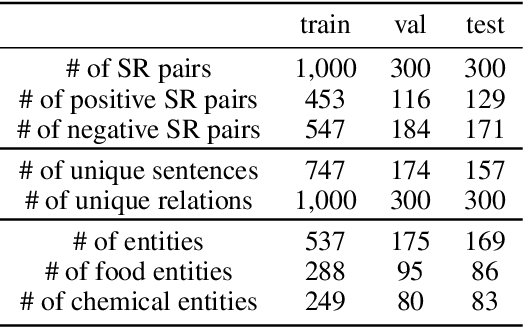
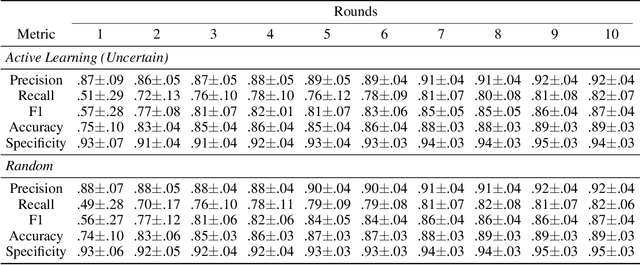
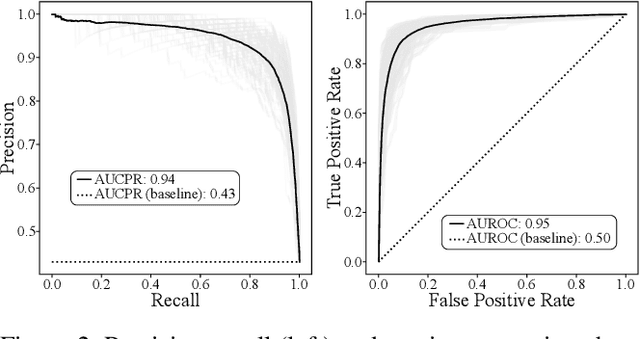
A food composition knowledge base, which stores the essential phyto-, micro-, and macro-nutrients of foods is useful for both research and industrial applications. Although many existing knowledge bases attempt to curate such information, they are often limited by time-consuming manual curation processes. Outside of the food science domain, natural language processing methods that utilize pre-trained language models have recently shown promising results for extracting knowledge from unstructured text. In this work, we propose a semi-automated framework for constructing a knowledge base of food composition from the scientific literature available online. To this end, we utilize a pre-trained BioBERT language model in an active learning setup that allows the optimal use of limited training data. Our work demonstrates how human-in-the-loop models are a step toward AI-assisted food systems that scale well to the ever-increasing big data.
Rethinking Attention Mechanism in Time Series Classification
Jul 14, 2022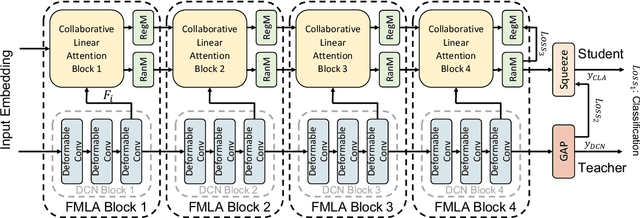
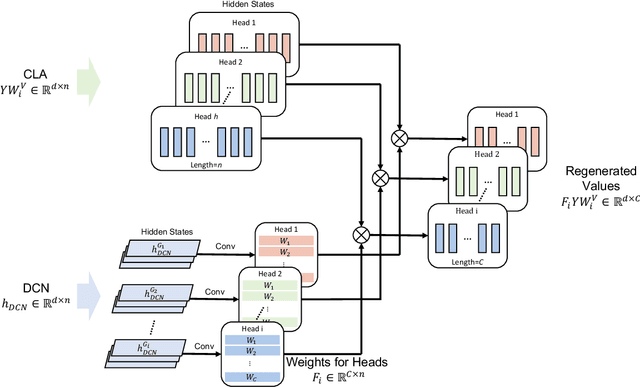
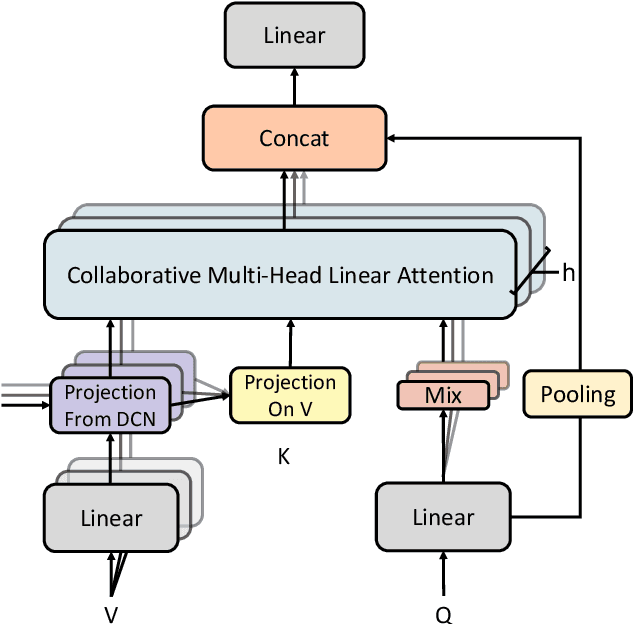
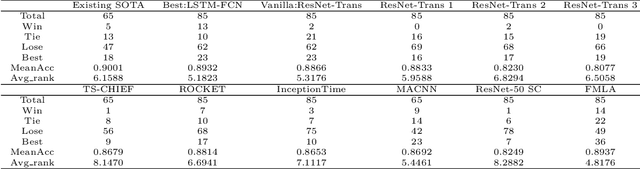
Attention-based models have been widely used in many areas, such as computer vision and natural language processing. However, relevant applications in time series classification (TSC) have not been explored deeply yet, causing a significant number of TSC algorithms still suffer from general problems of attention mechanism, like quadratic complexity. In this paper, we promote the efficiency and performance of the attention mechanism by proposing our flexible multi-head linear attention (FMLA), which enhances locality awareness by layer-wise interactions with deformable convolutional blocks and online knowledge distillation. What's more, we propose a simple but effective mask mechanism that helps reduce the noise influence in time series and decrease the redundancy of the proposed FMLA by masking some positions of each given series proportionally. To stabilize this mechanism, samples are forwarded through the model with random mask layers several times and their outputs are aggregated to teach the same model with regular mask layers. We conduct extensive experiments on 85 UCR2018 datasets to compare our algorithm with 11 well-known ones and the results show that our algorithm has comparable performance in terms of top-1 accuracy. We also compare our model with three Transformer-based models with respect to the floating-point operations per second and number of parameters and find that our algorithm achieves significantly better efficiency with lower complexity.
CMOS-based area-and-power-efficient neuron and synapse circuits for time-domain analog spiking neural networks
Aug 25, 2022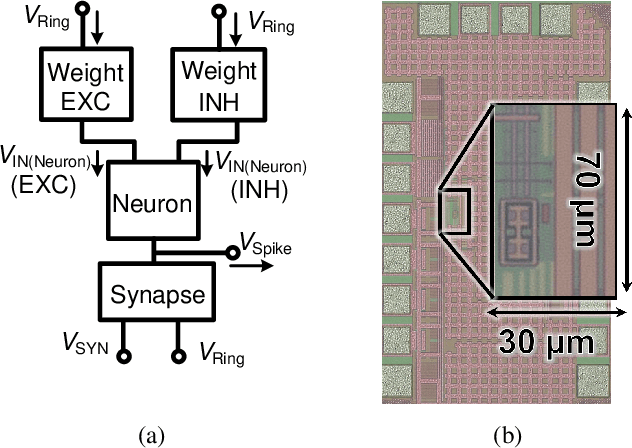
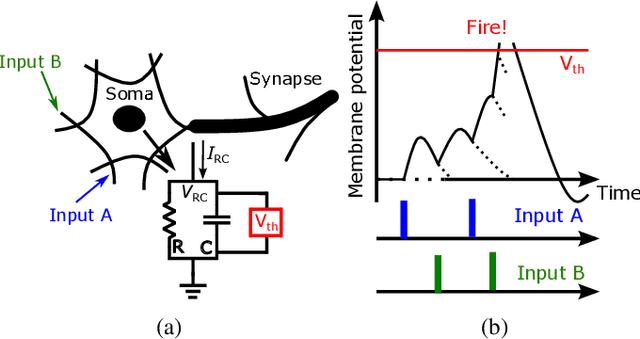
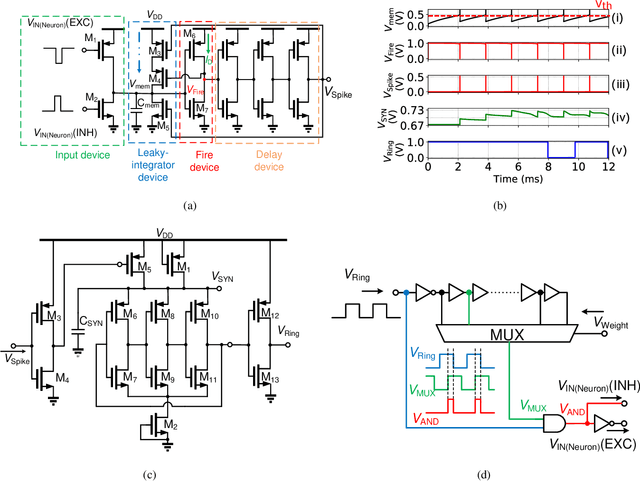
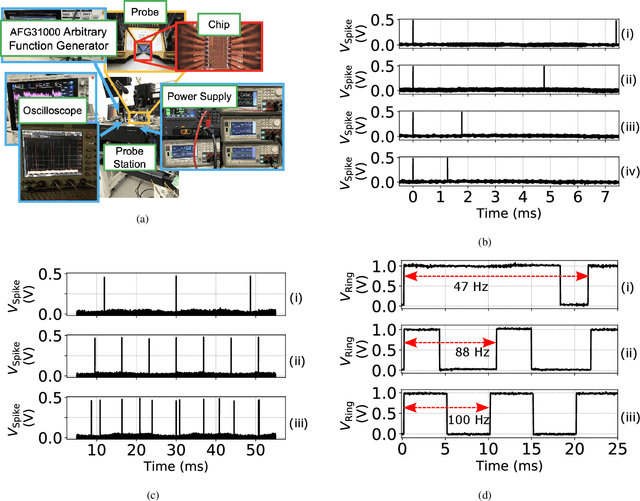
Conventional neural structures tend to communicate through analog quantities such as currents or voltages, however, as CMOS devices shrink and supply voltages decrease, the dynamic range of voltage/current-domain analog circuits becomes narrower, the available margin becomes smaller, and noise immunity decreases. More than that, the use of operational amplifiers (op-amps) and clocked or asynchronous comparators in conventional designs leads to high energy consumption and large chip area, which would be detrimental to building spiking neural networks. In view of this, we propose a neural structure for generating and transmitting time-domain signals, including a neuron module, a synapse module, and two weight modules. The proposed neural structure is driven by leakage currents in the transistor triode region and does not use op-amps and comparators, thus providing higher energy and area efficiency compared to conventional designs. In addition, the structure provides greater noise immunity due to internal communication via time-domain signals, which simplifies the wiring between the modules. The proposed neural structure is fabricated using TSMC 65 nm CMOS technology. The proposed neuron and synapse occupy an area of 127 um2 and 231 um2, respectively, while achieving millisecond time constants. Actual chip measurements show that the proposed structure successfully implements the temporal signal communication function with millisecond time constants, which is a critical step toward hardware reservoir computing for human-computer interaction.