 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Low-Resource Compositional Semantic Parsing with Concept Pretraining
Jan 30, 2023
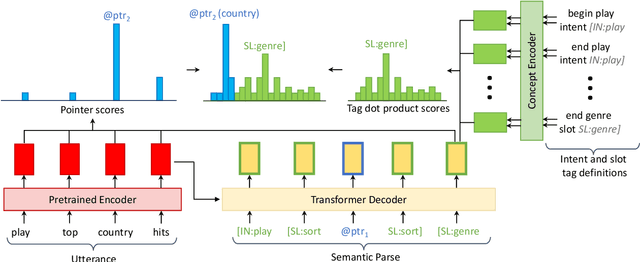


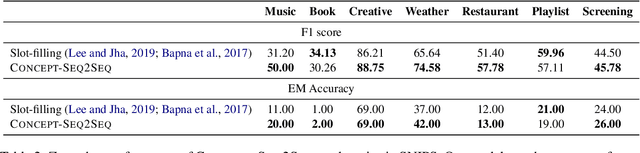
Semantic parsing plays a key role in digital voice assistants such as Alexa, Siri, and Google Assistant by mapping natural language to structured meaning representations. When we want to improve the capabilities of a voice assistant by adding a new domain, the underlying semantic parsing model needs to be retrained using thousands of annotated examples from the new domain, which is time-consuming and expensive. In this work, we present an architecture to perform such domain adaptation automatically, with only a small amount of metadata about the new domain and without any new training data (zero-shot) or with very few examples (few-shot). We use a base seq2seq (sequence-to-sequence) architecture and augment it with a concept encoder that encodes intent and slot tags from the new domain. We also introduce a novel decoder-focused approach to pretrain seq2seq models to be concept aware using Wikidata and use it to help our model learn important concepts and perform well in low-resource settings. We report few-shot and zero-shot results for compositional semantic parsing on the TOPv2 dataset and show that our model outperforms prior approaches in few-shot settings for the TOPv2 and SNIPS datasets.
Temporal Consistency Loss for Physics-Informed Neural Networks
Jan 30, 2023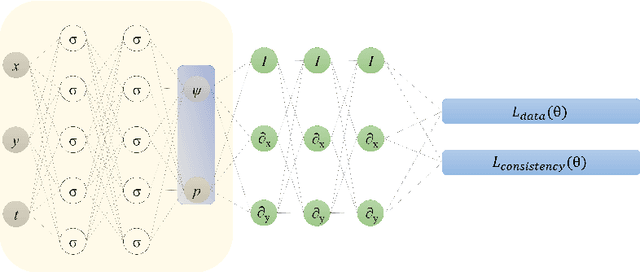
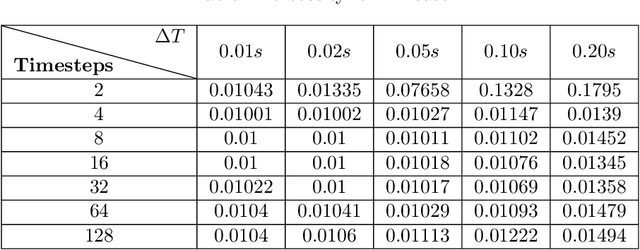
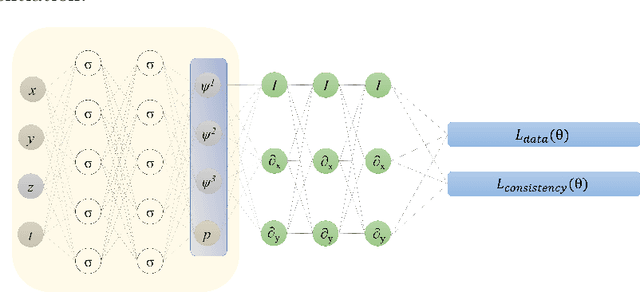
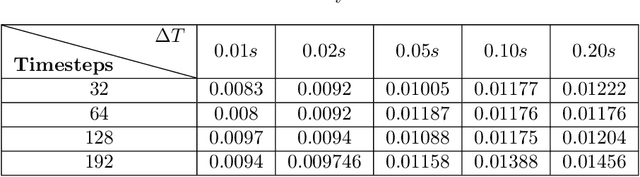
Physics-informed neural networks (PINNs) have been widely used to solve partial differential equations in a forward and inverse manner using deep neural networks. However, training these networks can be challenging for multiscale problems. While statistical methods can be employed to scale the regression loss on data, it is generally challenging to scale the loss terms for equations. This paper proposes a method for scaling the mean squared loss terms in the objective function used to train PINNs. Instead of using automatic differentiation to calculate the temporal derivative, we use backward Euler discretization. This provides us with a scaling term for the equations. In this work, we consider the two and three-dimensional Navier-Stokes equations and determine the kinematic viscosity using the spatio-temporal data on the velocity and pressure fields. We first consider numerical datasets to test our method. We test the sensitivity of our method to the time step size, the number of timesteps, noise in the data, and spatial resolution. Finally, we use the velocity field obtained using Particle Image Velocimetry (PIV) experiments to generate a reference pressure field. We then test our framework using the velocity and reference pressure field.
On the Interaction between Node Fairness and Edge Privacy in Graph Neural Networks
Jan 30, 2023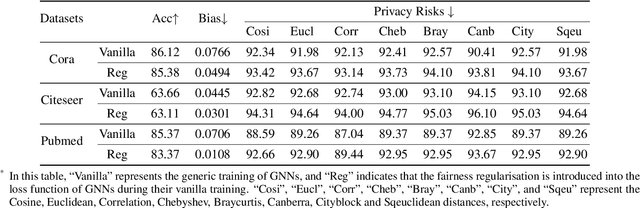
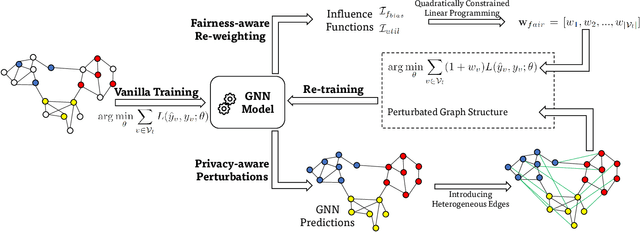
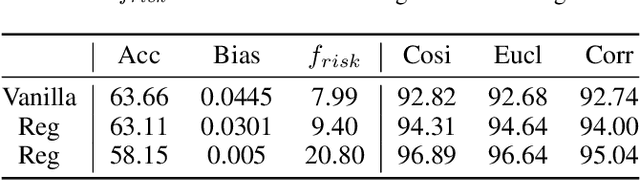
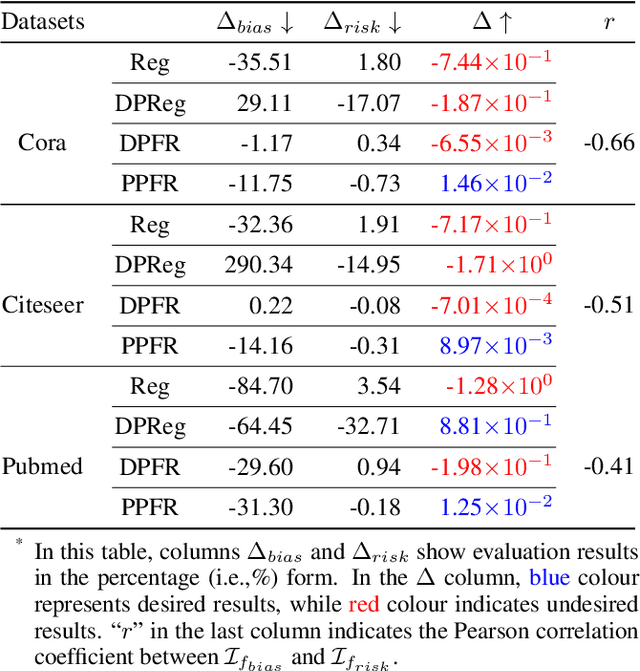
Due to the emergence of graph neural networks (GNNs) and their widespread implementation in real-world scenarios, the fairness and privacy of GNNs have attracted considerable interest since they are two essential social concerns in the era of building trustworthy GNNs. Existing studies have respectively explored the fairness and privacy of GNNs and exhibited that both fairness and privacy are at the cost of GNN performance. However, the interaction between them is yet to be explored and understood. In this paper, we investigate the interaction between the fairness of a GNN and its privacy for the first time. We empirically identify that edge privacy risks increase when the individual fairness of nodes is improved. Next, we present the intuition behind such a trade-off and employ the influence function and Pearson correlation to measure it theoretically. To take the performance, fairness, and privacy of GNNs into account simultaneously, we propose implementing fairness-aware reweighting and privacy-aware graph structure perturbation modules in a retraining mechanism. Experimental results demonstrate that our method is effective in implementing GNN fairness with limited performance cost and restricted privacy risks.
PACED-5G: Predictive Autonomous Control using Edge for Drones over 5G
Jan 30, 2023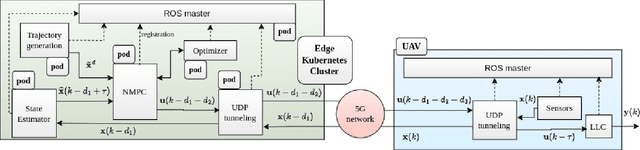
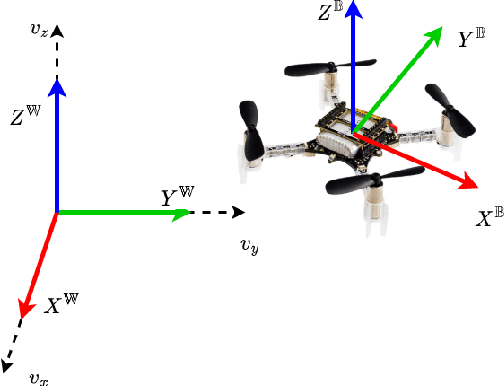
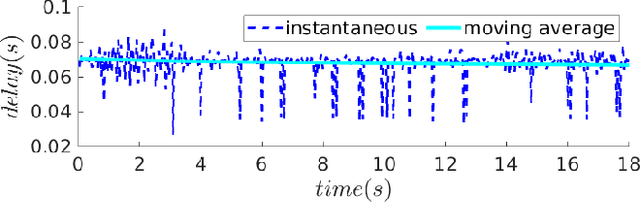
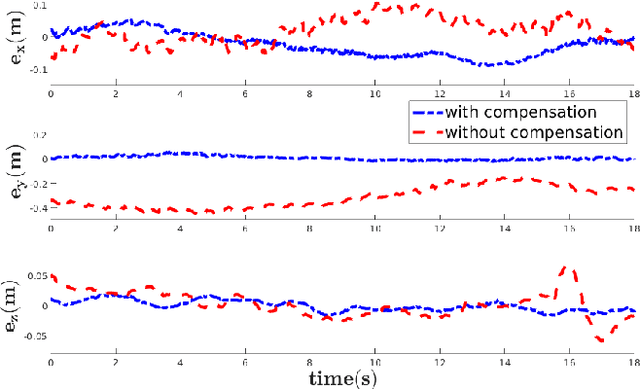
With the advent of technologies such as Edge computing, the horizons of remote computational applications have broadened multidimensionally. Autonomous Unmanned Aerial Vehicle (UAV) mission is a vital application to utilize remote computation to catalyze its performance. However, offloading computational complexity to a remote system increases the latency in the system. Though technologies such as 5G networking minimize communication latency, the effects of latency on the control of UAVs are inevitable and may destabilize the system. Hence, it is essential to consider the delays in the system and compensate for them in the control design. Therefore, we propose a novel Edge-based predictive control architecture enabled by 5G networking, PACED-5G (Predictive Autonomous Control using Edge for Drones over 5G). In the proposed control architecture, we have designed a state estimator for estimating the current states based on the available knowledge of the time-varying delays, devised a Model Predictive controller (MPC) for the UAV to track the reference trajectory while avoiding obstacles, and provided an interface to offload the high-level tasks over Edge systems. The proposed architecture is validated in two experimental test cases using a quadrotor UAV.
Structure Learning and Parameter Estimation for Graphical Models via Penalized Maximum Likelihood Methods
Jan 30, 2023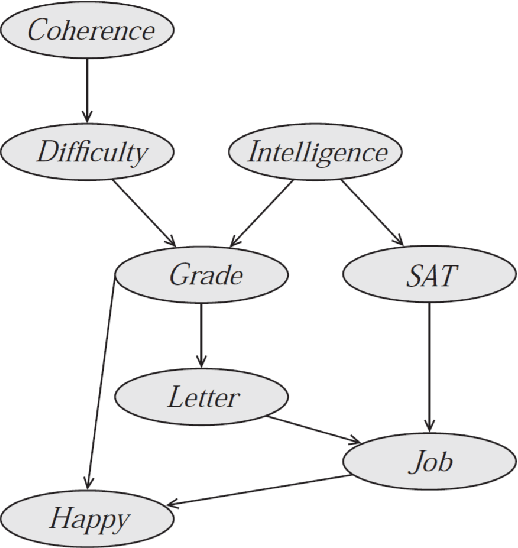
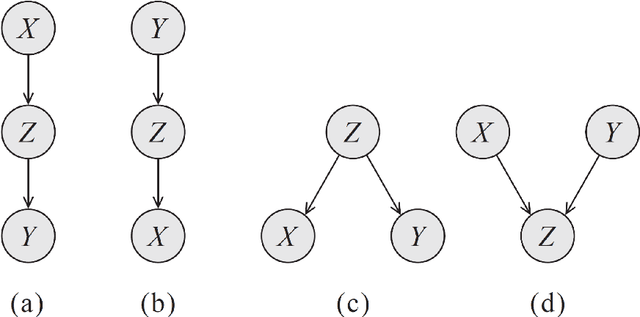
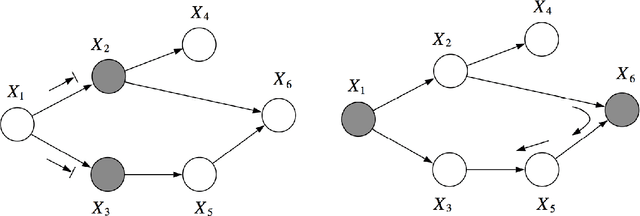
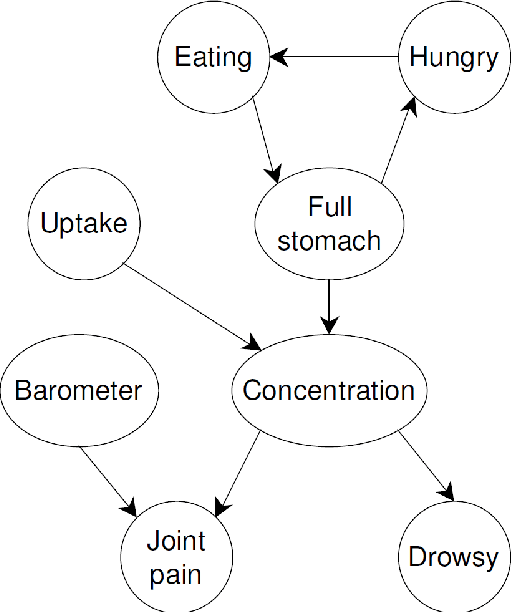
Probabilistic graphical models (PGMs) provide a compact and flexible framework to model very complex real-life phenomena. They combine the probability theory which deals with uncertainty and logical structure represented by a graph which allows one to cope with the computational complexity and also interpret and communicate the obtained knowledge. In the thesis, we consider two different types of PGMs: Bayesian networks (BNs) which are static, and continuous time Bayesian networks which, as the name suggests, have a temporal component. We are interested in recovering their true structure, which is the first step in learning any PGM. This is a challenging task, which is interesting in itself from the causal point of view, for the purposes of interpretation of the model and the decision-making process. All approaches for structure learning in the thesis are united by the same idea of maximum likelihood estimation with the LASSO penalty. The problem of structure learning is reduced to the problem of finding non-zero coefficients in the LASSO estimator for a generalized linear model. In the case of CTBNs, we consider the problem both for complete and incomplete data. We support the theoretical results with experiments.
ArchiSound: Audio Generation with Diffusion
Jan 30, 2023
The recent surge in popularity of diffusion models for image generation has brought new attention to the potential of these models in other areas of media generation. One area that has yet to be fully explored is the application of diffusion models to audio generation. Audio generation requires an understanding of multiple aspects, such as the temporal dimension, long term structure, multiple layers of overlapping sounds, and the nuances that only trained listeners can detect. In this work, we investigate the potential of diffusion models for audio generation. We propose a set of models to tackle multiple aspects, including a new method for text-conditional latent audio diffusion with stacked 1D U-Nets, that can generate multiple minutes of music from a textual description. For each model, we make an effort to maintain reasonable inference speed, targeting real-time on a single consumer GPU. In addition to trained models, we provide a collection of open source libraries with the hope of simplifying future work in the field. Samples can be found at https://bit.ly/audio-diffusion. Codes are at https://github.com/archinetai/audio-diffusion-pytorch.
SSR-TA: Sequence to Sequence based expert recurrent recommendation for ticket automation
Jan 30, 2023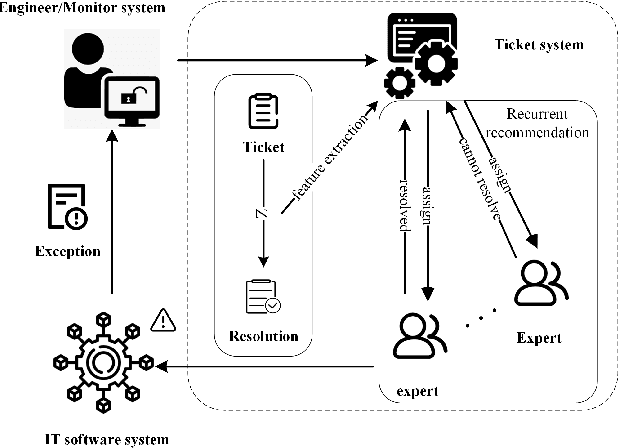
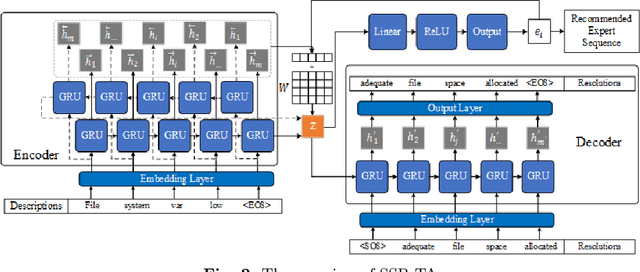

The ticket automation provides crucial support for the normal operation of IT software systems. An essential task of ticket automation is to assign experts to solve upcoming tickets. However, facing thousands of tickets, inappropriate assignments will make tickets transfer frequently among experts, which causes time delays and wasted resources. Effectively and efficiently finding an appropriate expert in fewer steps is vital to ticket automation. In this paper, we proposed a sequence to sequence based translation model combined with a recurrent recommendation network to recommend appropriate experts for tickets. The sequence to sequence model transforms the ticket description into the corresponding resolution for capturing the potential and useful features of representing tickets. The recurrent recommendation network recommends the appropriate expert based on the assumption that the previous expert in the recommendation sequence cannot solve the expert. To evaluate the performance, we conducted experiments to compare several baselines with SSR-TA on two real-world datasets, and the experimental results show that our proposed model outperforms the baselines. The comparative experiment results also show that SSR-TA has a better performance of expert recommendations for user-generated tickets.
Contextual Dynamic Prompting for Response Generation in Task-oriented Dialog Systems
Jan 30, 2023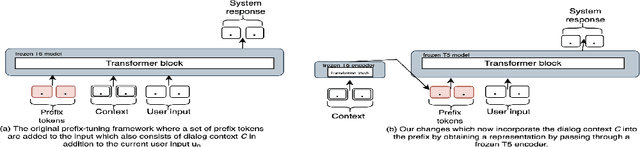


Response generation is one of the critical components in task-oriented dialog systems. Existing studies have shown that large pre-trained language models can be adapted to this task. The typical paradigm of adapting such extremely large language models would be by fine-tuning on the downstream tasks which is not only time-consuming but also involves significant resources and access to fine-tuning data. Prompting \citep{schick2020exploiting} has been an alternative to fine-tuning in many NLP tasks. In our work, we explore the idea of using prompting for response generation in task-oriented dialog systems. Specifically, we propose an approach that performs \textit{contextual dynamic prompting} where the prompts are learnt from dialog contexts. We aim to distill useful prompting signals from the dialog context. On experiments with MultiWOZ 2.2 dataset \cite{zang2020multiwoz}, we show that contextual dynamic prompts improve response generation in terms of \textit{combined score} \cite{mehri-etal-2019-structured} by 3 absolute points, and a massive 20 points when dialog states are incorporated. Furthermore, human annotation on these conversations found that agents which incorporate context were preferred over agents with vanilla prefix-tuning.
Reachability Analysis of Neural Network Control Systems
Jan 28, 2023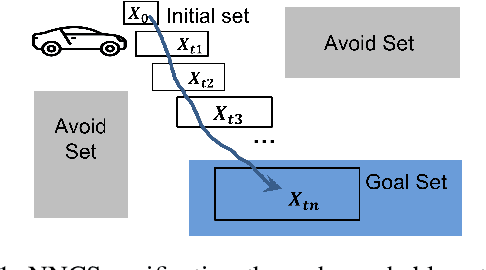

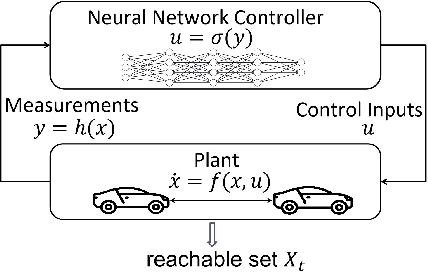
Neural network controllers (NNCs) have shown great promise in autonomous and cyber-physical systems. Despite the various verification approaches for neural networks, the safety analysis of NNCs remains an open problem. Existing verification approaches for neural network control systems (NNCSs) either can only work on a limited type of activation functions, or result in non-trivial over-approximation errors with time evolving. This paper proposes a verification framework for NNCS based on Lipschitzian optimisation, called DeepNNC. We first prove the Lipschitz continuity of closed-loop NNCSs by unrolling and eliminating the loops. We then reveal the working principles of applying Lipschitzian optimisation on NNCS verification and illustrate it by verifying an adaptive cruise control model. Compared to state-of-the-art verification approaches, DeepNNC shows superior performance in terms of efficiency and accuracy over a wide range of NNCs. We also provide a case study to demonstrate the capability of DeepNNC to handle a real-world, practical, and complex system. Our tool \textbf{DeepNNC} is available at \url{https://github.com/TrustAI/DeepNNC}.
Analyzing Robustness of the Deep Reinforcement Learning Algorithm in Ramp Metering Applications Considering False Data Injection Attack and Defense
Jan 28, 2023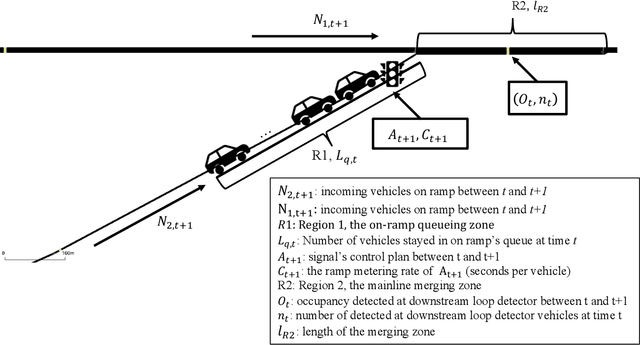
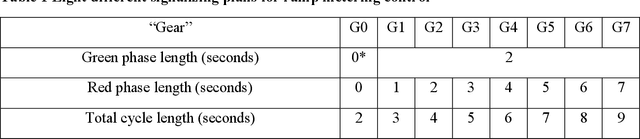
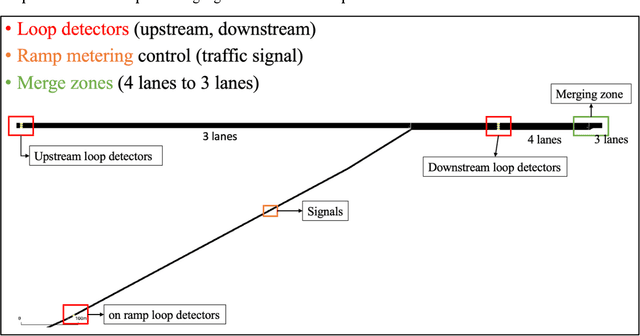
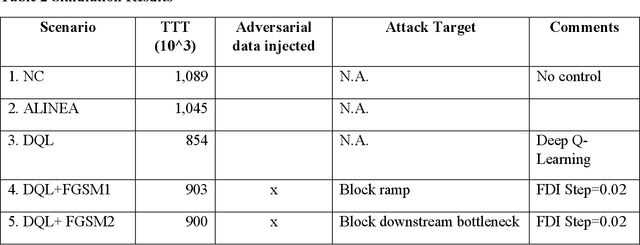
Decades of practices of ramp metering, by controlling downstream volume and smoothing the interweaving traffic, have proved that ramp metering can decrease total travel time, mitigate shockwaves, decrease rear-end collisions, reduce pollution, etc. Besides traditional methods like ALIENA algorithms, Deep Reinforcement Learning algorithms have been established recently to build finer control on ramp metering. However, those Deep Learning models may be venerable to adversarial attacks. Thus, it is important to investigate the robustness of those models under False Data Injection adversarial attack. Furthermore, algorithms capable of detecting anomaly data from clean data are the key to safeguard Deep Learning algorithm. In this study, an online algorithm that can distinguish adversarial data from clean data are tested. Results found that in most cases anomaly data can be distinguished from clean data, although their difference is too small to be manually distinguished by humans. In practice, whenever adversarial/hazardous data is detected, the system can fall back to a fixed control program, and experts should investigate the detectors status or security protocols afterwards before real damages happen.