 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Domain Re-Modulation for Few-Shot Generative Domain Adaptation
Feb 07, 2023
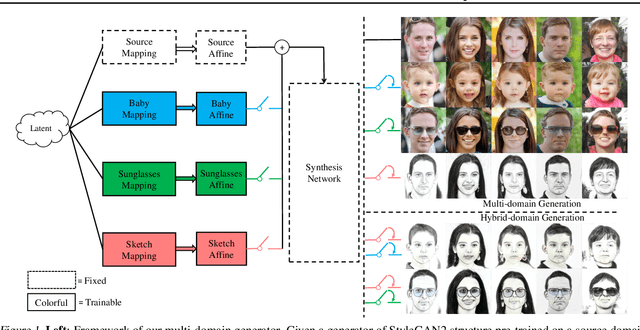
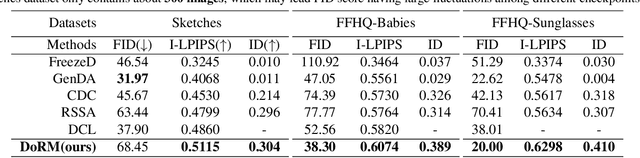
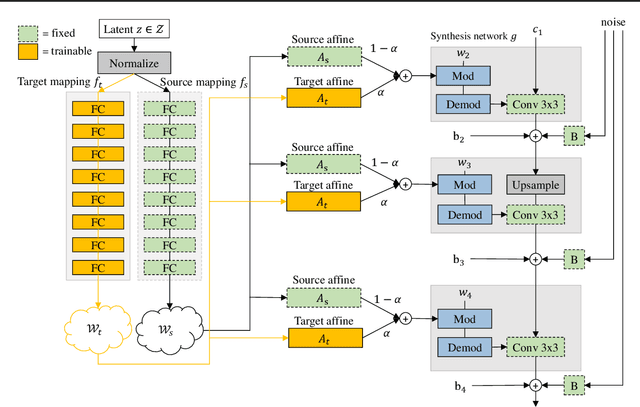
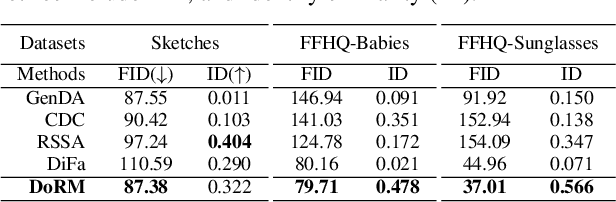
In this study, we investigate the task of few-shot Generative Domain Adaptation (GDA), which involves transferring a pre-trained generator from one domain to a new domain using one or a few reference images. Building upon previous research that has focused on Target-domain Consistency, Large Diversity, and Cross-domain Consistency, we conclude two additional desired properties for GDA: Memory and Domain Association. To meet these properties, we proposed a novel method Domain Re-Modulation (DoRM). Specifically, DoRM freezes the source generator and employs additional mapping and affine modules (M&A module) to capture the attributes of the target domain, resulting in a linearly combinable domain shift in style space. This allows for high-fidelity multi-domain and hybrid-domain generation by integrating multiple M&A modules in a single generator. DoRM is lightweight and easy to implement. Extensive experiments demonstrated the superior performance of DoRM on both one-shot and 10-shot GDA, both quantitatively and qualitatively. Additionally, for the first time, multi-domain and hybrid-domain generation can be achieved with a minimal storage cost by using a single model. The code will be available at https://github.com/wuyi2020/DoRM.
Resolving Left-Right Ambiguity During Bearing Only Tracking of an Underwater Target Using Towed Array
Feb 03, 2023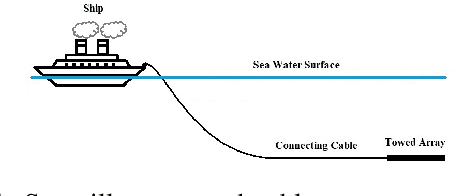
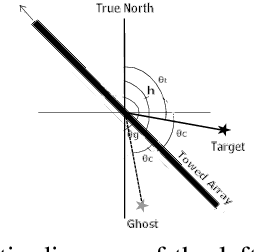
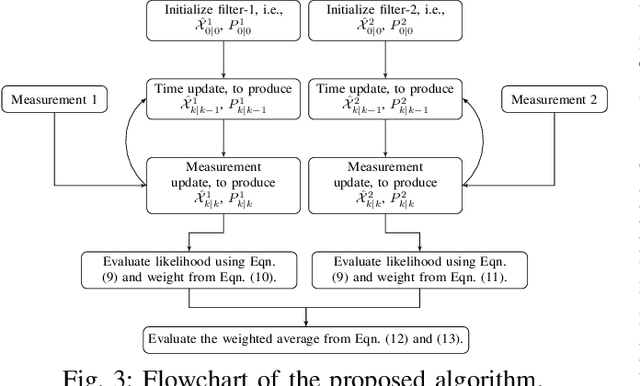
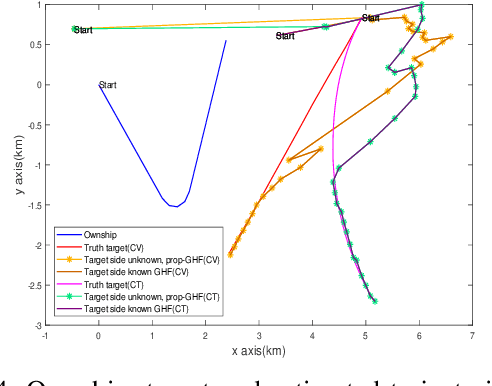
In bearing only tracking using a towed array, the array can sense the bearing angle of the target but is unable to differentiate whether the target is on the left or the right side of the array. Thus, the traditional tracking algorithm generates tracks in both the sides of the array which create difficulties when interception is required. In this paper, we propose a method based on likelihood of measurement which along with the estimators can resolve left-right ambiguity and track the target. A case study has been presented where the target moves (a) in a straight line with a near constant velocity, (b) maneuvers with a turn, and observer takes a `U'-like maneuver. The method along with the various estimators has been applied which successfully resolves the ambiguity and tracks the target. Further, the tracking results are compared in terms of the root mean square error in position and velocity, bias norm, \% of track loss and the relative execution time.
Baechi: Fast Device Placement of Machine Learning Graphs
Jan 20, 2023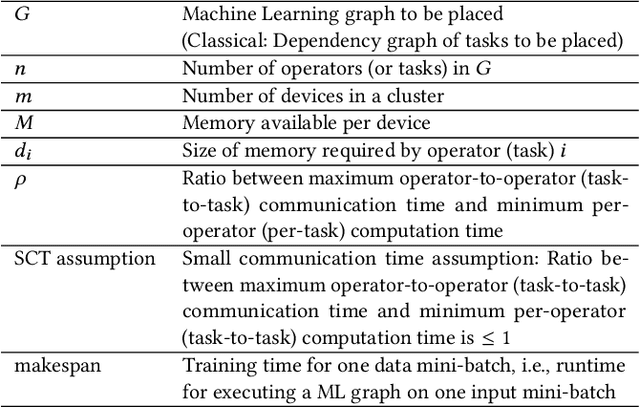
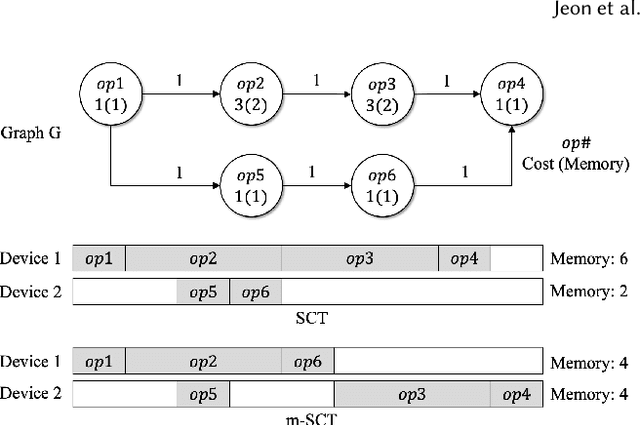
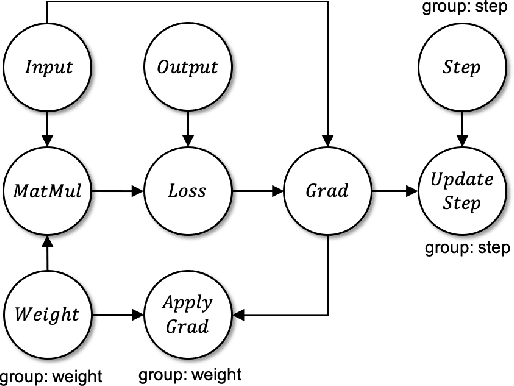

Machine Learning graphs (or models) can be challenging or impossible to train when either devices have limited memory, or models are large. To split the model across devices, learning-based approaches are still popular. While these result in model placements that train fast on data (i.e., low step times), learning-based model-parallelism is time-consuming, taking many hours or days to create a placement plan of operators on devices. We present the Baechi system, the first to adopt an algorithmic approach to the placement problem for running machine learning training graphs on small clusters of memory-constrained devices. We integrate our implementation of Baechi into two popular open-source learning frameworks: TensorFlow and PyTorch. Our experimental results using GPUs show that: (i) Baechi generates placement plans 654 X - 206K X faster than state-of-the-art learning-based approaches, and (ii) Baechi-placed model's step (training) time is comparable to expert placements in PyTorch, and only up to 6.2% worse than expert placements in TensorFlow. We prove mathematically that our two algorithms are within a constant factor of the optimal. Our work shows that compared to learning-based approaches, algorithmic approaches can face different challenges for adaptation to Machine learning systems, but also they offer proven bounds, and significant performance benefits.
AI enabled RPM for Mental Health Facility
Jan 20, 2023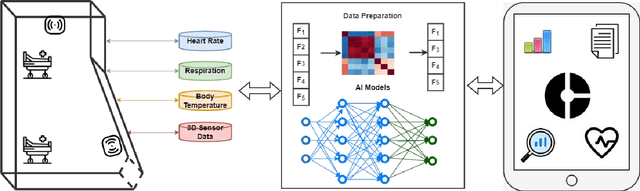

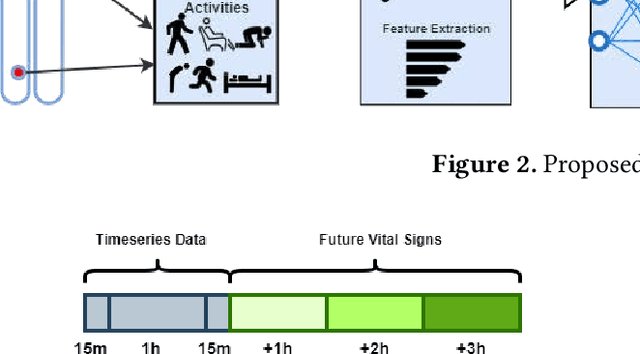
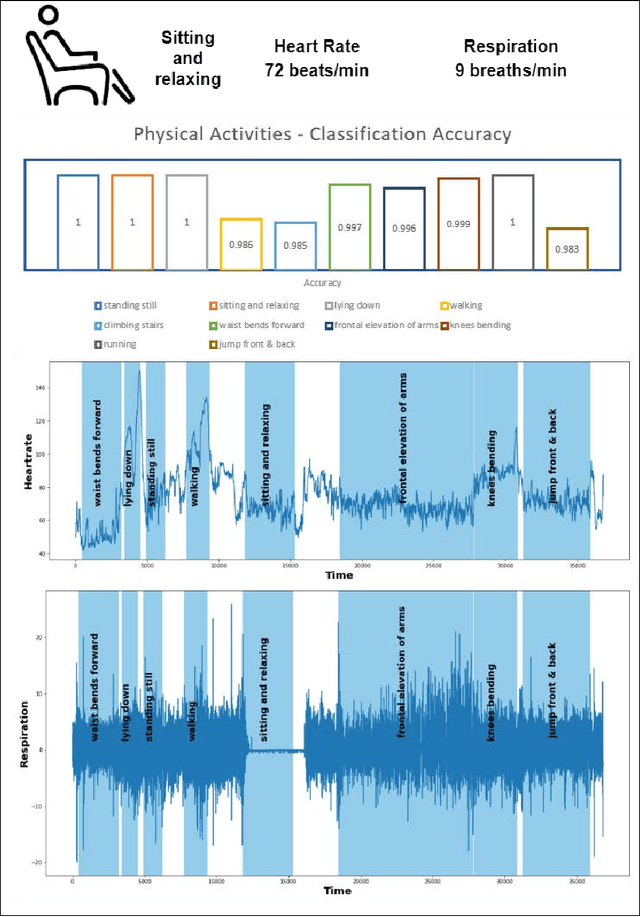
Mental healthcare is one of the prominent parts of the healthcare industry with alarming concerns related to patients depression, stress leading to self-harm and threat to fellow patients and medical staff. To provide a therapeutic environment for both patients and staff, aggressive or agitated patients need to be monitored remotely and track their vital signs and physical activities continuously. Remote patient monitoring (RPM) using non-invasive technology could enable contactless monitoring of acutely ill patients in a mental health facility. Enabling the RPM system with AI unlocks a predictive environment in which future vital signs of the patients can be forecasted. This paper discusses an AI-enabled RPM system framework with a non-invasive digital technology RFID using its in-built NCS mechanism to retrieve vital signs and physical actions of patients. Based on the retrieved time series data, future vital signs of patients for the upcoming 3 hours and classify their physical actions into 10 labelled physical activities. This framework assists to avoid any unforeseen clinical disasters and take precautionary measures with medical intervention at right time. A case study of a middle-aged PTSD patient treated with the AI-enabled RPM system is demonstrated in this study.
STORM-GAN: Spatio-Temporal Meta-GAN for Cross-City Estimation of Human Mobility Responses to COVID-19
Jan 20, 2023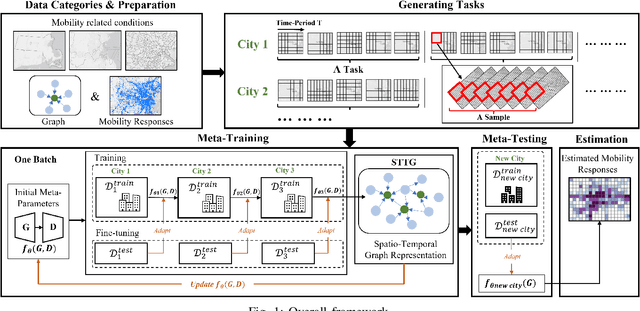
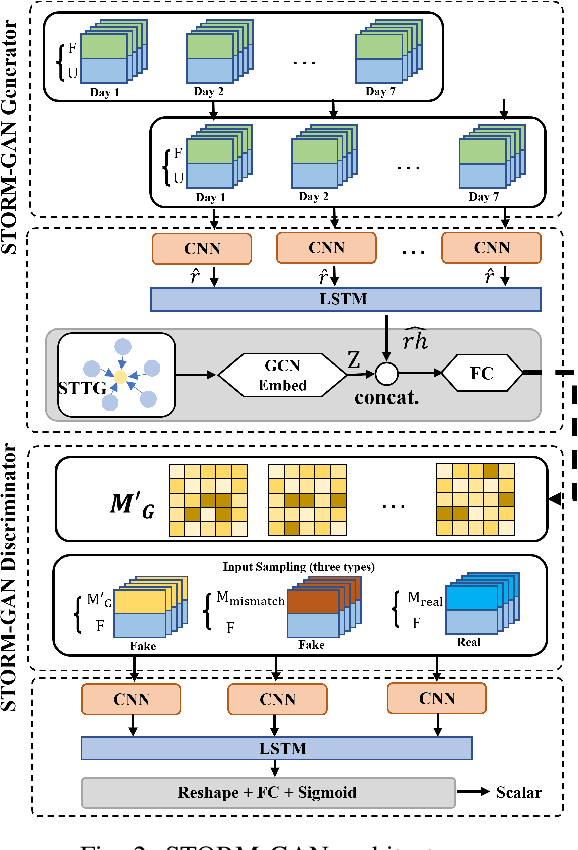
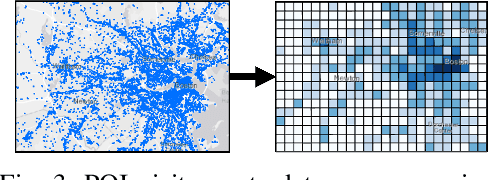
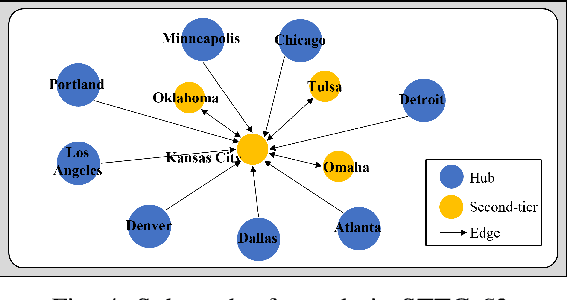
Human mobility estimation is crucial during the COVID-19 pandemic due to its significant guidance for policymakers to make non-pharmaceutical interventions. While deep learning approaches outperform conventional estimation techniques on tasks with abundant training data, the continuously evolving pandemic poses a significant challenge to solving this problem due to data nonstationarity, limited observations, and complex social contexts. Prior works on mobility estimation either focus on a single city or lack the ability to model the spatio-temporal dependencies across cities and time periods. To address these issues, we make the first attempt to tackle the cross-city human mobility estimation problem through a deep meta-generative framework. We propose a Spatio-Temporal Meta-Generative Adversarial Network (STORM-GAN) model that estimates dynamic human mobility responses under a set of social and policy conditions related to COVID-19. Facilitated by a novel spatio-temporal task-based graph (STTG) embedding, STORM-GAN is capable of learning shared knowledge from a spatio-temporal distribution of estimation tasks and quickly adapting to new cities and time periods with limited training samples. The STTG embedding component is designed to capture the similarities among cities to mitigate cross-task heterogeneity. Experimental results on real-world data show that the proposed approach can greatly improve estimation performance and out-perform baselines.
DAMO-YOLO : A Report on Real-Time Object Detection Design
Nov 23, 2022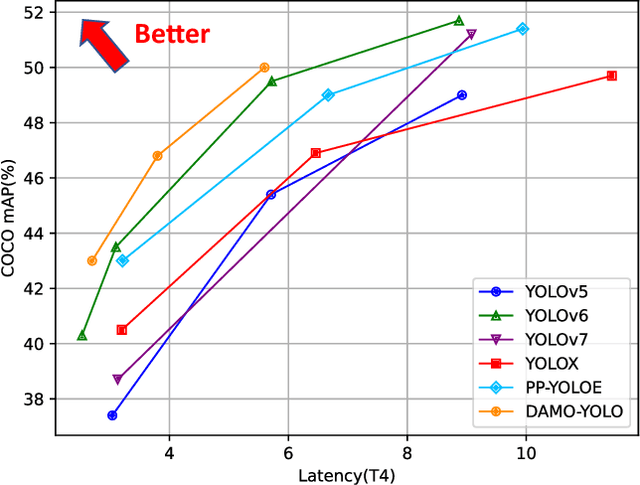
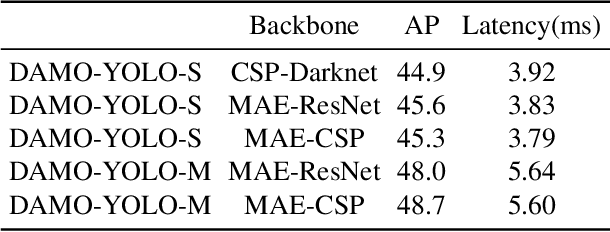
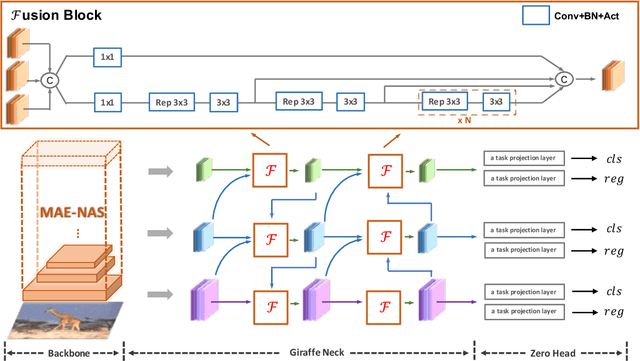
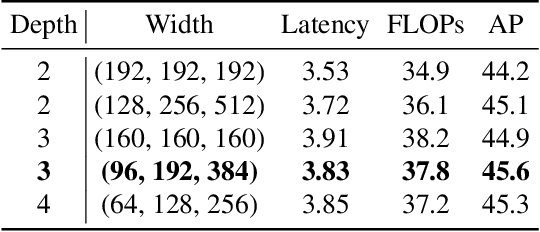
In this report, we present a fast and accurate object detection method dubbed DAMO-YOLO, which achieves higher performance than the state-of-the-art YOLO series. DAMO-YOLO is extended from YOLO with some new technologies, including Neural Architecture Search (NAS), efficient Reparameterized Generalized-FPN (RepGFPN), a lightweight head with AlignedOTA label assignment, and distillation enhancement. In particular, we use MAE-NAS, a method guided by the principle of maximum entropy, to search our detection backbone under the constraints of low latency and high performance, producing ResNet-like / CSP-like structures with spatial pyramid pooling and focus modules. In the design of necks and heads, we follow the rule of "large neck, small head". We import Generalized-FPN with accelerated queen-fusion to build the detector neck and upgrade its CSPNet with efficient layer aggregation networks (ELAN) and reparameterization. Then we investigate how detector head size affects detection performance and find that a heavy neck with only one task projection layer would yield better results. In addition, AlignedOTA is proposed to solve the misalignment problem in label assignment. And a distillation schema is introduced to improve performance to a higher level. Based on these new techs, we build a suite of models at various scales to meet the needs of different scenarios, i.e., DAMO-YOLO-Tiny/Small/Medium. They can achieve 43.0/46.8/50.0 mAPs on COCO with the latency of 2.78/3.83/5.62 ms on T4 GPUs respectively. The code is available at https://github.com/tinyvision/damo-yolo.
Efficient Semantic Segmentation on Edge Devices
Dec 28, 2022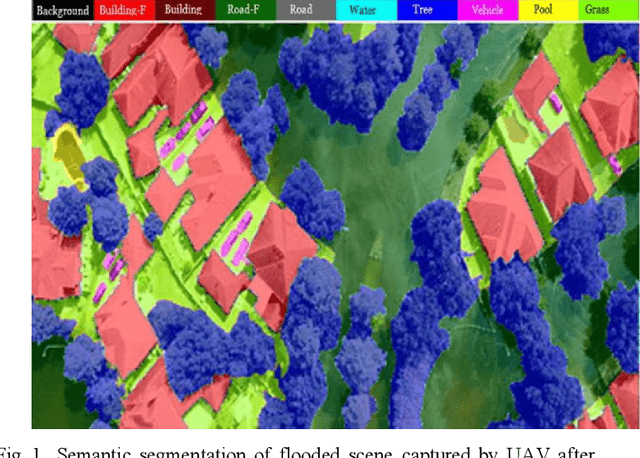
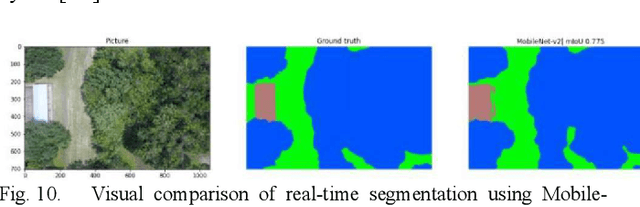

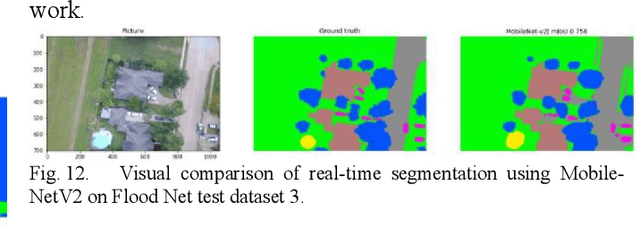
Semantic segmentation works on the computer vision algorithm for assigning each pixel of an image into a class. The task of semantic segmentation should be performed with both accuracy and efficiency. Most of the existing deep FCNs yield to heavy computations and these networks are very power hungry, unsuitable for real-time applications on portable devices. This project analyzes current semantic segmentation models to explore the feasibility of applying these models for emergency response during catastrophic events. We compare the performance of real-time semantic segmentation models with non-real-time counterparts constrained by aerial images under oppositional settings. Furthermore, we train several models on the Flood-Net dataset, containing UAV images captured after Hurricane Harvey, and benchmark their execution on special classes such as flooded buildings vs. non-flooded buildings or flooded roads vs. non-flooded roads. In this project, we developed a real-time UNet based model and deployed that network on Jetson AGX Xavier module.
Deep learning enhanced noise spectroscopy of a spin qubit environment
Jan 12, 2023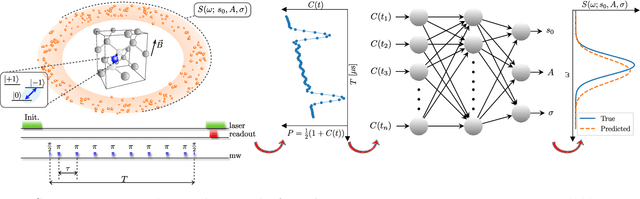
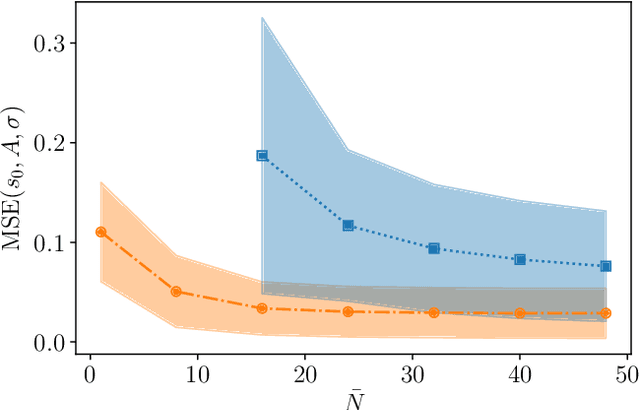
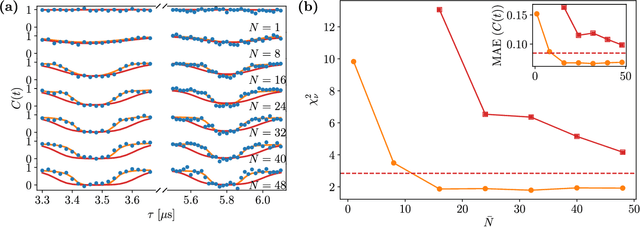
The undesired interaction of a quantum system with its environment generally leads to a coherence decay of superposition states in time. A precise knowledge of the spectral content of the noise induced by the environment is crucial to protect qubit coherence and optimize its employment in quantum device applications. We experimentally show that the use of neural networks can highly increase the accuracy of noise spectroscopy, by reconstructing the power spectral density that characterizes an ensemble of carbon impurities around a nitrogen-vacancy (NV) center in diamond. Neural networks are trained over spin coherence functions of the NV center subjected to different Carr-Purcell sequences, typically used for dynamical decoupling (DD). As a result, we determine that deep learning models can be more accurate than standard DD noise-spectroscopy techniques, by requiring at the same time a much smaller number of DD sequences.
ShiftDDPMs: Exploring Conditional Diffusion Models by Shifting Diffusion Trajectories
Feb 05, 2023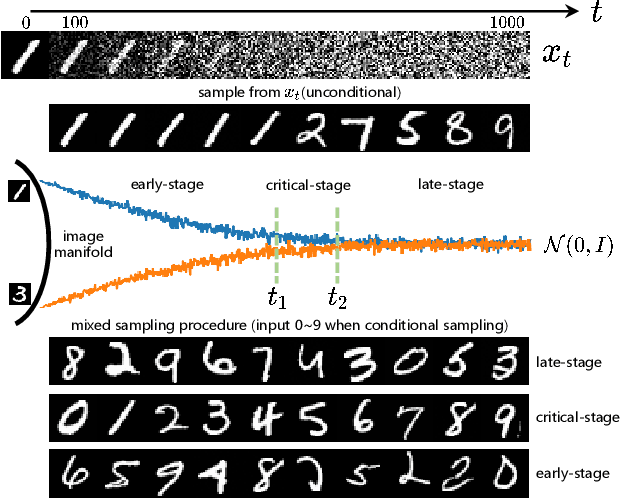
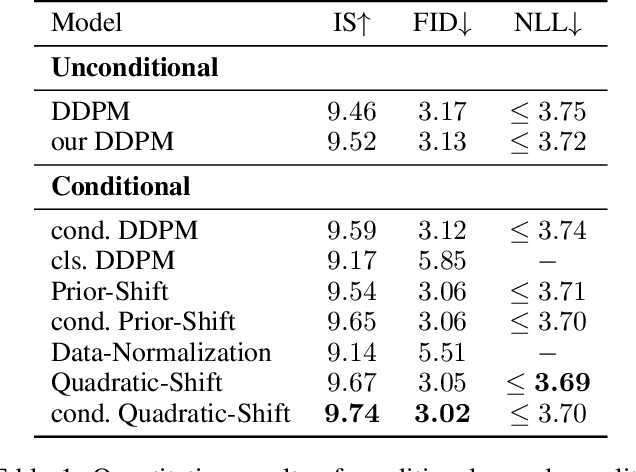
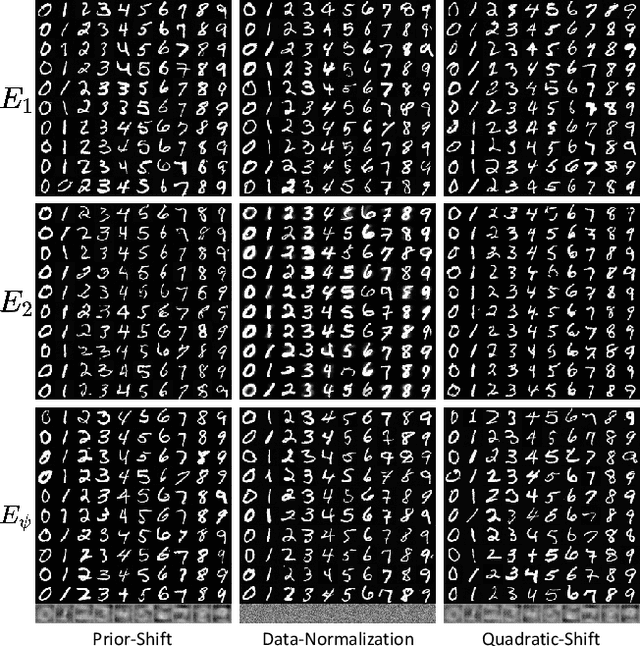
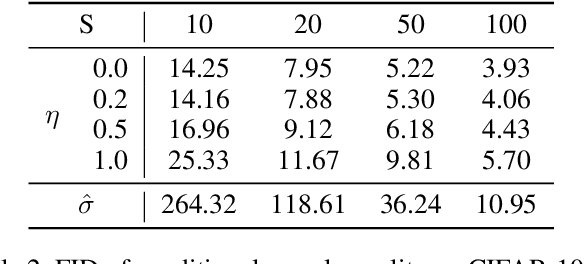
Diffusion models have recently exhibited remarkable abilities to synthesize striking image samples since the introduction of denoising diffusion probabilistic models (DDPMs). Their key idea is to disrupt images into noise through a fixed forward process and learn its reverse process to generate samples from noise in a denoising way. For conditional DDPMs, most existing practices relate conditions only to the reverse process and fit it to the reversal of unconditional forward process. We find this will limit the condition modeling and generation in a small time window. In this paper, we propose a novel and flexible conditional diffusion model by introducing conditions into the forward process. We utilize extra latent space to allocate an exclusive diffusion trajectory for each condition based on some shifting rules, which will disperse condition modeling to all timesteps and improve the learning capacity of model. We formulate our method, which we call \textbf{ShiftDDPMs}, and provide a unified point of view on existing related methods. Extensive qualitative and quantitative experiments on image synthesis demonstrate the feasibility and effectiveness of ShiftDDPMs.
MILO: Model-Agnostic Subset Selection Framework for Efficient Model Training and Tuning
Feb 05, 2023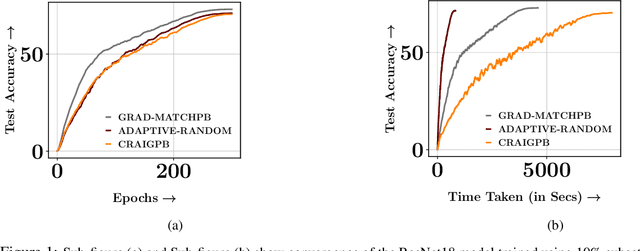
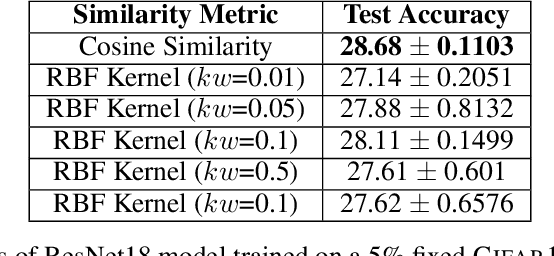
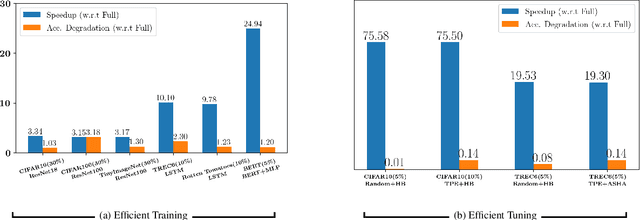
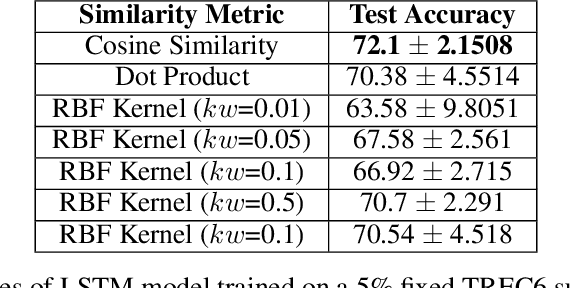
Training deep networks and tuning hyperparameters on large datasets is computationally intensive. One of the primary research directions for efficient training is to reduce training costs by selecting well-generalizable subsets of training data. Compared to simple adaptive random subset selection baselines, existing intelligent subset selection approaches are not competitive due to the time-consuming subset selection step, which involves computing model-dependent gradients and feature embeddings and applies greedy maximization of submodular objectives. Our key insight is that removing the reliance on downstream model parameters enables subset selection as a pre-processing step and enables one to train multiple models at no additional cost. In this work, we propose MILO, a model-agnostic subset selection framework that decouples the subset selection from model training while enabling superior model convergence and performance by using an easy-to-hard curriculum. Our empirical results indicate that MILO can train models $3\times - 10 \times$ faster and tune hyperparameters $20\times - 75 \times$ faster than full-dataset training or tuning without compromising performance.