 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Backpropagation-Based Analytical Derivatives of EKF Covariance for Active Sensing
Mar 08, 2024
To enhance accuracy of robot state estimation, active sensing (or perception-aware) methods seek trajectories that maximize the information gathered by the sensors. To this aim, one possibility is to seek trajectories that minimize the (estimation error) covariance matrix output by an extended Kalman filter (EKF), w.r.t. its control inputs over a given horizon. However, this is computationally demanding. In this article, we derive novel backpropagation analytical formulas for the derivatives of the covariance matrices of an EKF w.r.t. all its inputs. We then leverage the obtained analytical gradients as an enabling technology to derive perception-aware optimal motion plans. Simulations validate the approach, showcasing improvements in execution time, notably over PyTorch's automatic differentiation. Experimental results on a real vehicle also support the method.
DyRoNet: A Low-Rank Adapter Enhanced Dynamic Routing Network for Streaming Perception
Mar 08, 2024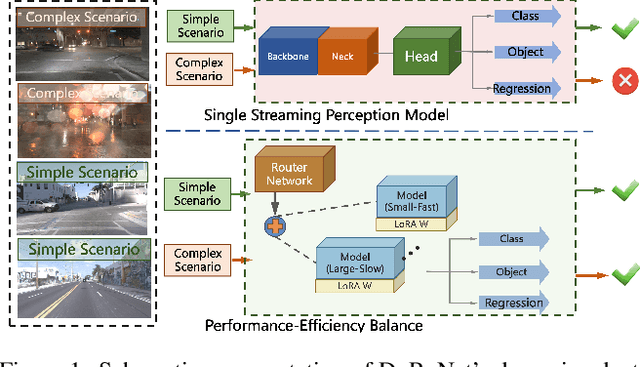
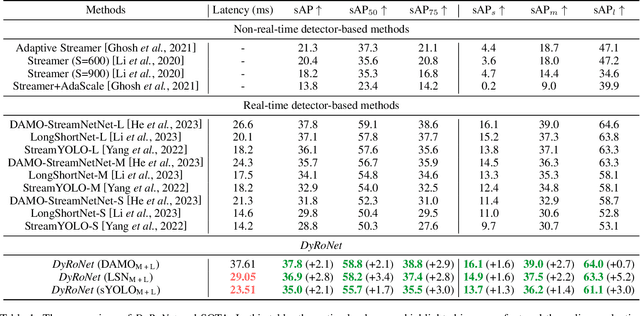
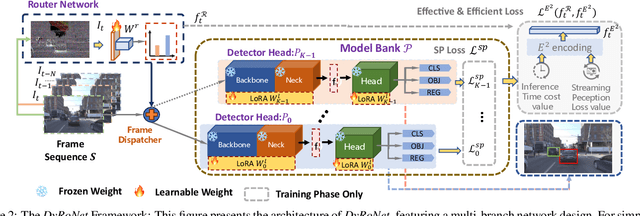
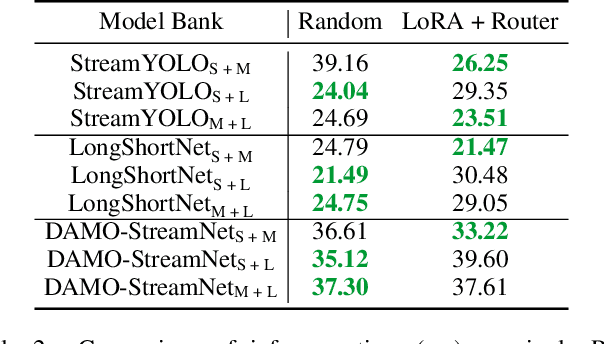
Autonomous driving systems demand real-time, accurate perception to navigate complex environments. Addressing this, we introduce the Dynamic Router Network (DyRoNet), a framework that innovates with low-rank dynamic routing for enhanced streaming perception. By integrating specialized pre-trained branch networks, fine-tuned for various environmental conditions, DyRoNet achieves a balance between latency and precision. Its core feature, the speed router module, intelligently directs input data to the best-suited branch network, optimizing performance. The extensive evaluations reveal that DyRoNet adapts effectively to multiple branch selection strategies, setting a new benchmark in performance across a range of scenarios. DyRoNet not only establishes a new benchmark for streaming perception but also provides valuable engineering insights for future work. More project information is available at https://tastevision.github.io/DyRoNet/
SAFFIRA: a Framework for Assessing the Reliability of Systolic-Array-Based DNN Accelerators
Mar 05, 2024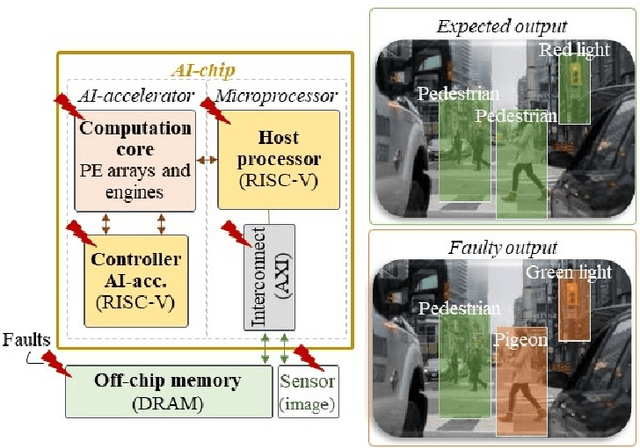
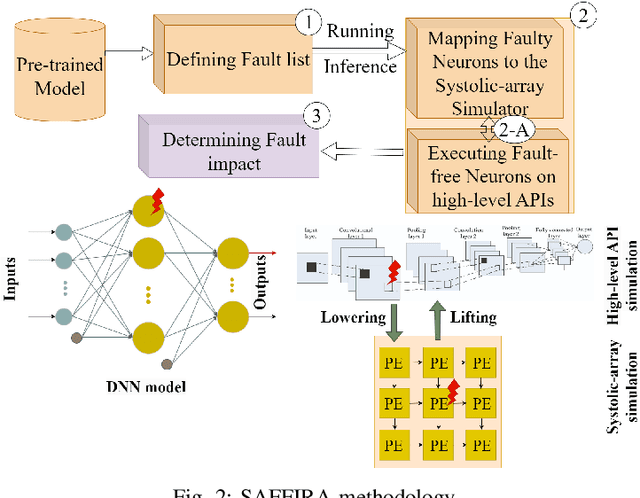
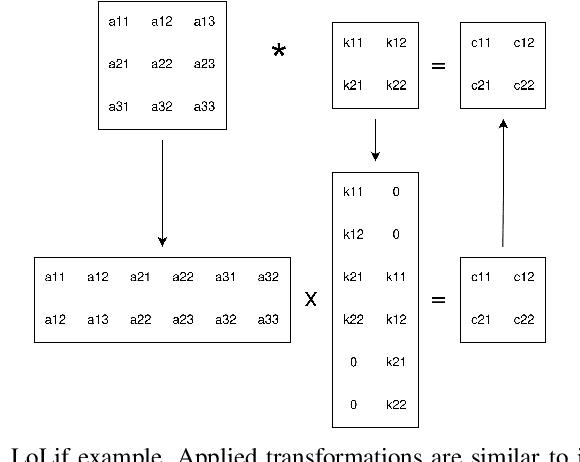
Systolic array has emerged as a prominent architecture for Deep Neural Network (DNN) hardware accelerators, providing high-throughput and low-latency performance essential for deploying DNNs across diverse applications. However, when used in safety-critical applications, reliability assessment is mandatory to guarantee the correct behavior of DNN accelerators. While fault injection stands out as a well-established practical and robust method for reliability assessment, it is still a very time-consuming process. This paper addresses the time efficiency issue by introducing a novel hierarchical software-based hardware-aware fault injection strategy tailored for systolic array-based DNN accelerators.
Online Adaptation of Language Models with a Memory of Amortized Contexts
Mar 07, 2024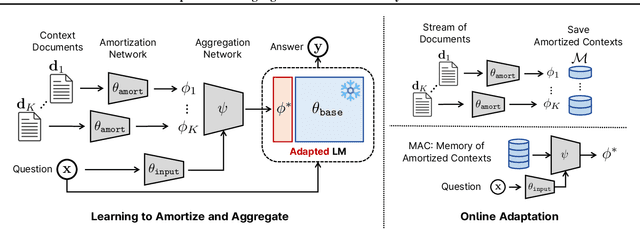
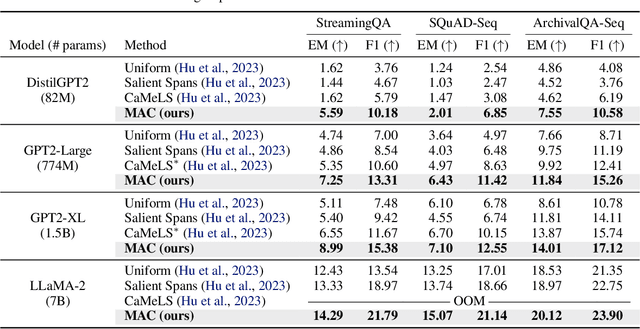

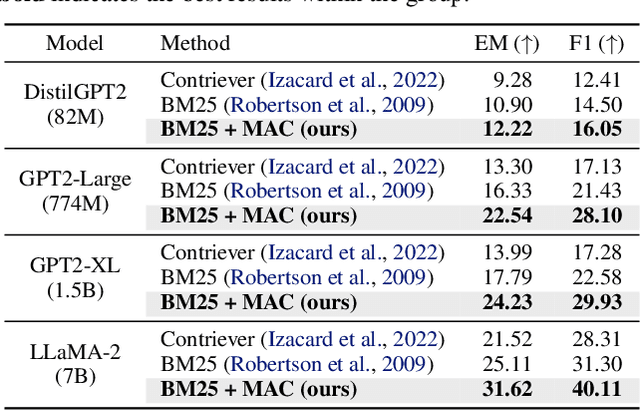
Due to the rapid generation and dissemination of information, large language models (LLMs) quickly run out of date despite enormous development costs. Due to this crucial need to keep models updated, online learning has emerged as a critical necessity when utilizing LLMs for real-world applications. However, given the ever-expanding corpus of unseen documents and the large parameter space of modern LLMs, efficient adaptation is essential. To address these challenges, we propose Memory of Amortized Contexts (MAC), an efficient and effective online adaptation framework for LLMs with strong knowledge retention. We propose an amortized feature extraction and memory-augmentation approach to compress and extract information from new documents into compact modulations stored in a memory bank. When answering questions, our model attends to and extracts relevant knowledge from this memory bank. To learn informative modulations in an efficient manner, we utilize amortization-based meta-learning, which substitutes the optimization process with a single forward pass of the encoder. Subsequently, we learn to choose from and aggregate selected documents into a single modulation by conditioning on the question, allowing us to adapt a frozen language model during test time without requiring further gradient updates. Our experiment demonstrates the superiority of MAC in multiple aspects, including online adaptation performance, time, and memory efficiency. Code is available at: https://github.com/jihoontack/MAC.
Speech Emotion Recognition Via CNN-Transforemr and Multidimensional Attention Mechanism
Mar 07, 2024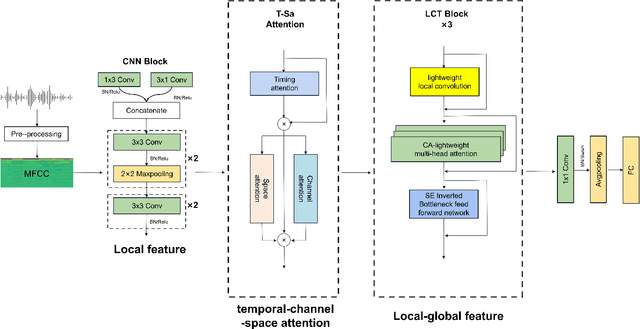
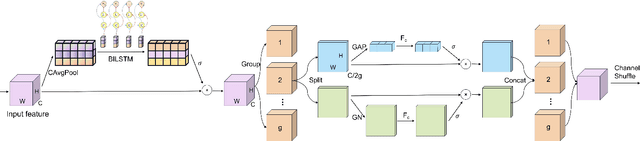
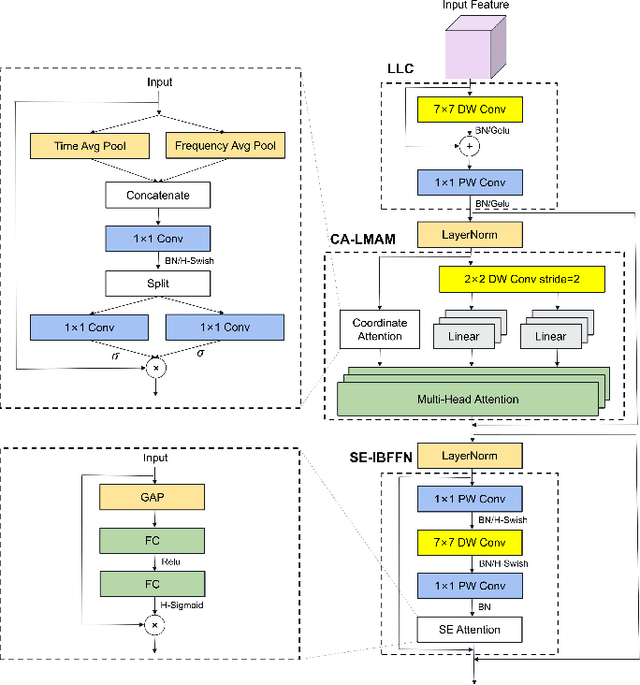
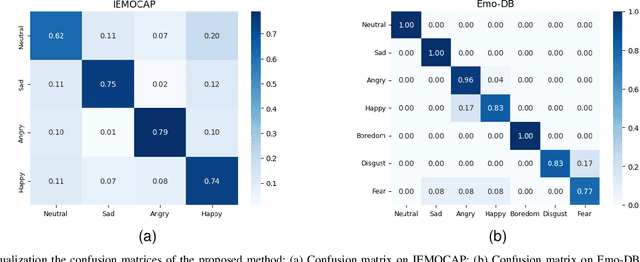
Speech Emotion Recognition (SER) is crucial in human-machine interactions. Mainstream approaches utilize Convolutional Neural Networks or Recurrent Neural Networks to learn local energy feature representations of speech segments from speech information, but struggle with capturing global information such as the duration of energy in speech. Some use Transformers to capture global information, but there is room for improvement in terms of parameter count and performance. Furthermore, existing attention mechanisms focus on spatial or channel dimensions, hindering learning of important temporal information in speech. In this paper, to model local and global information at different levels of granularity in speech and capture temporal, spatial and channel dependencies in speech signals, we propose a Speech Emotion Recognition network based on CNN-Transformer and multi-dimensional attention mechanisms. Specifically, a stack of CNN blocks is dedicated to capturing local information in speech from a time-frequency perspective. In addition, a time-channel-space attention mechanism is used to enhance features across three dimensions. Moreover, we model local and global dependencies of feature sequences using large convolutional kernels with depthwise separable convolutions and lightweight Transformer modules. We evaluate the proposed method on IEMOCAP and Emo-DB datasets and show our approach significantly improves the performance over the state-of-the-art methods. Our code is available on https://github.com/SCNU-RISLAB/CNN-Transforemr-and-Multidimensional-Attention-Mechanism
Radiative Gaussian Splatting for Efficient X-ray Novel View Synthesis
Mar 07, 2024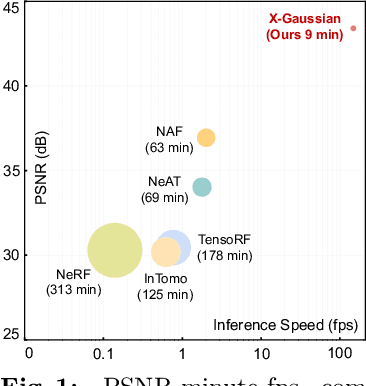
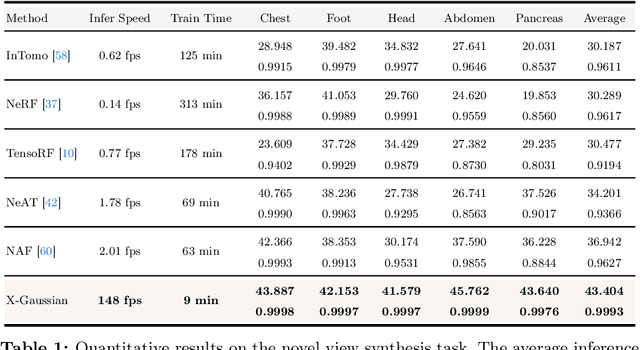

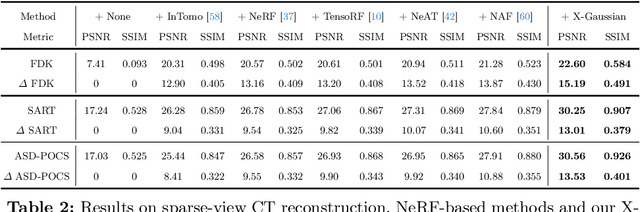
X-ray is widely applied for transmission imaging due to its stronger penetration than natural light. When rendering novel view X-ray projections, existing methods mainly based on NeRF suffer from long training time and slow inference speed. In this paper, we propose a 3D Gaussian splatting-based framework, namely X-Gaussian, for X-ray novel view synthesis. Firstly, we redesign a radiative Gaussian point cloud model inspired by the isotropic nature of X-ray imaging. Our model excludes the influence of view direction when learning to predict the radiation intensity of 3D points. Based on this model, we develop a Differentiable Radiative Rasterization (DRR) with CUDA implementation. Secondly, we customize an Angle-pose Cuboid Uniform Initialization (ACUI) strategy that directly uses the parameters of the X-ray scanner to compute the camera information and then uniformly samples point positions within a cuboid enclosing the scanned object. Experiments show that our X-Gaussian outperforms state-of-the-art methods by 6.5 dB while enjoying less than 15% training time and over 73x inference speed. The application on sparse-view CT reconstruction also reveals the practical values of our method. Code and models will be publicly available at https://github.com/caiyuanhao1998/X-Gaussian . A video demo of the training process visualization is at https://www.youtube.com/watch?v=gDVf_Ngeghg .
Understanding the PULSAR Effect in Combined Radiotherapy and Immunotherapy through Attention Mechanisms with a Transformer Model
Mar 07, 2024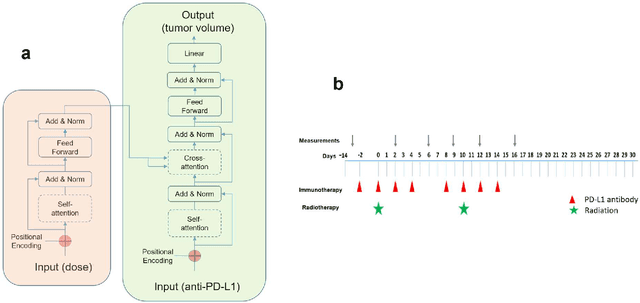
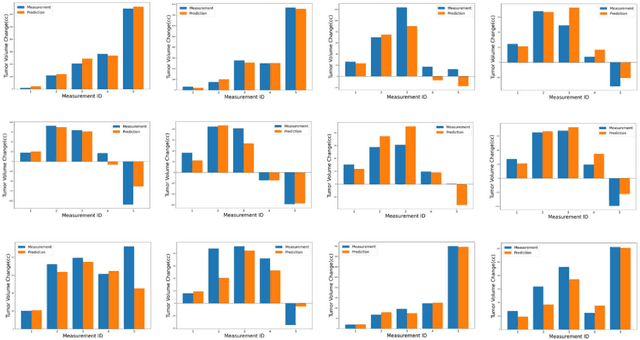
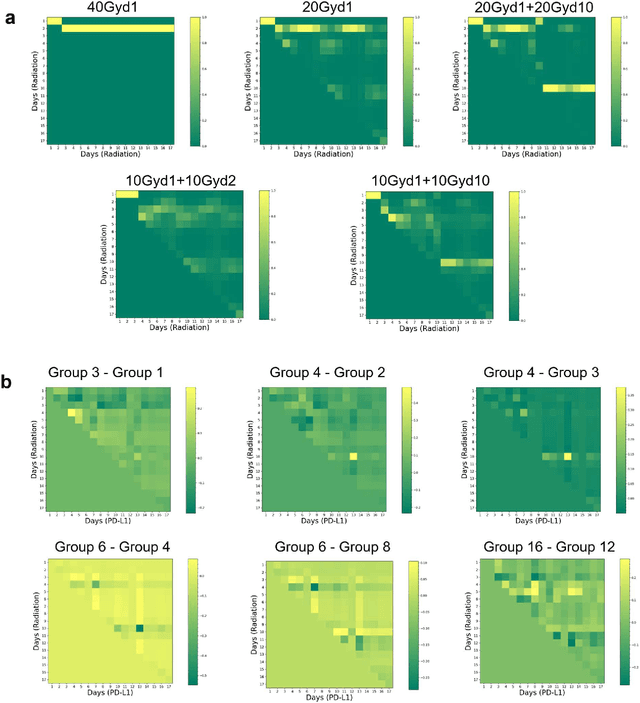
PULSAR (personalized, ultra-fractionated stereotactic adaptive radiotherapy) is the adaptation of stereotactic ablative radiotherapy towards personalized cancer management. For the first time, we applied a transformer-based attention mechanism to investigate the underlying interactions between combined PULSAR and PD-L1 blockade immunotherapy based on a murine cancer model (Lewis Lung Carcinoma, LLC). The proposed approach is able to predict the trend of tumor volume change semi-quantitatively, and excels in identifying the potential causal relationships through both self-attention and cross-attention scores.
Revitalizing Multivariate Time Series Forecasting: Learnable Decomposition with Inter-Series Dependencies and Intra-Series Variations Modeling
Feb 20, 2024Predicting multivariate time series is crucial, demanding precise modeling of intricate patterns, including inter-series dependencies and intra-series variations. Distinctive trend characteristics in each time series pose challenges, and existing methods, relying on basic moving average kernels, may struggle with the non-linear structure and complex trends in real-world data. Given that, we introduce a learnable decomposition strategy to capture dynamic trend information more reasonably. Additionally, we propose a dual attention module tailored to capture inter-series dependencies and intra-series variations simultaneously for better time series forecasting, which is implemented by channel-wise self-attention and autoregressive self-attention. To evaluate the effectiveness of our method, we conducted experiments across eight open-source datasets and compared it with the state-of-the-art methods. Through the comparison results, our Leddam (LEarnable Decomposition and Dual Attention Module) not only demonstrates significant advancements in predictive performance, but also the proposed decomposition strategy can be plugged into other methods with a large performance-boosting, from 11.87% to 48.56% MSE error degradation.
Weighted Monte Carlo augmented spherical Fourier-Bessel convolutional layers for 3D abdominal organ segmentation
Mar 09, 2024Filter-decomposition-based group equivariant convolutional neural networks show promising stability and data efficiency for 3D image feature extraction. However, the existing filter-decomposition-based 3D group equivariant neural networks rely on parameter-sharing designs and are mostly limited to rotation transformation groups, where the chosen spherical harmonic filter bases consider only angular orthogonality. These limitations hamper its application to deep neural network architectures for medical image segmentation. To address these issues, this paper describes a non-parameter-sharing affine group equivariant neural network for 3D medical image segmentation based on an adaptive aggregation of Monte Carlo augmented spherical Fourier Bessel filter bases. The efficiency and flexibility of the adopted non-parameter-sharing strategy enable for the first time an efficient implementation of 3D affine group equivariant convolutional neural networks for volumetric data. The introduced spherical Bessel Fourier filter basis combines both angular and radial orthogonality for better feature extraction. The 3D image segmentation experiments on two abdominal medical image sets, BTCV and the NIH Pancreas datasets, show that the proposed methods excel the state-of-the-art 3D neural networks with high training stability and data efficiency. The code will be available at https://github.com/ZhaoWenzhao/WMCSFB.
Electromagnetic Hybrid Beamforming for Holographic Communications
Mar 09, 2024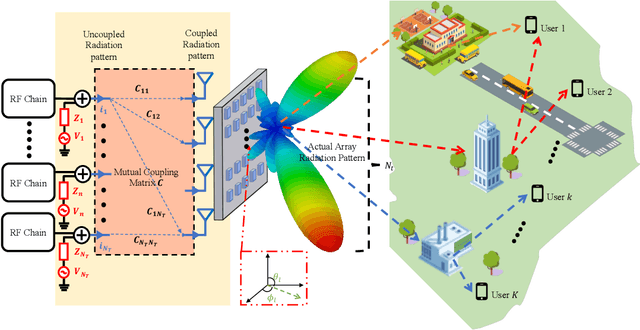
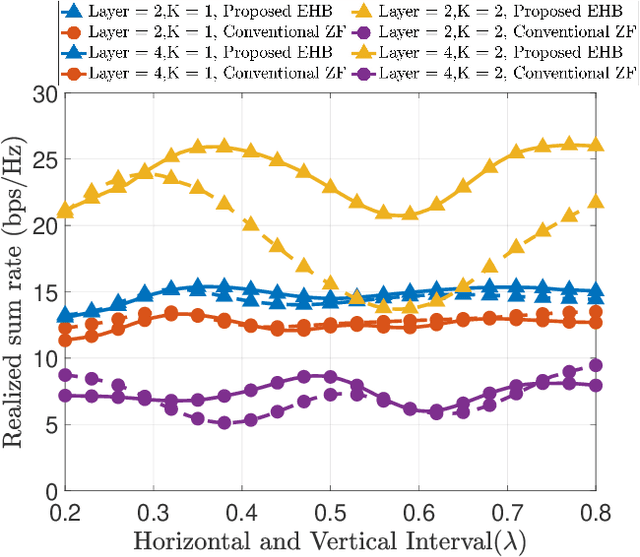
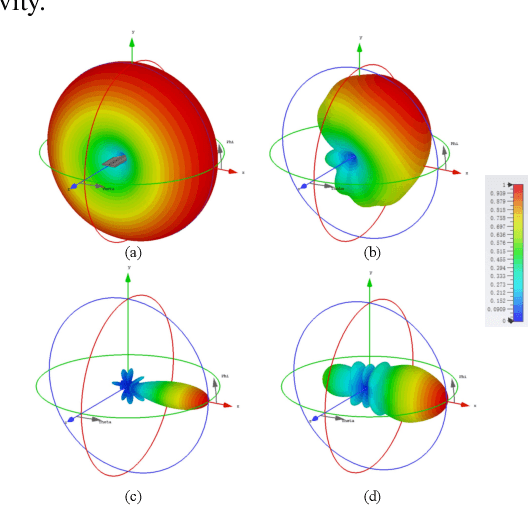
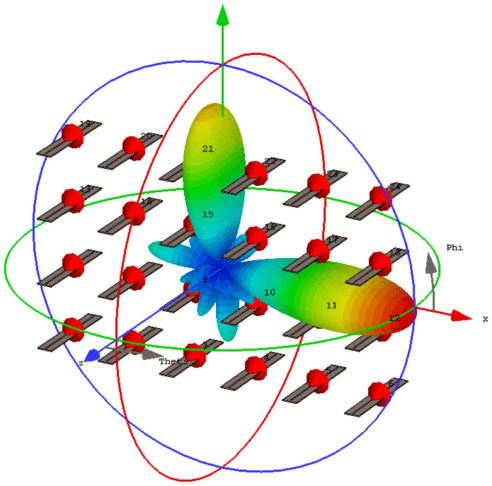
It is well known that there is inherent radiation pattern distortion for the commercial base station antenna array, which usually needs three antenna sectors to cover the whole space. To eliminate pattern distortion and further enhance beamforming performance, we propose an electromagnetic hybrid beamforming (EHB) scheme based on a three-dimensional (3D) superdirective holographic antenna array. Specifically, EHB consists of antenna excitation current vectors (analog beamforming) and digital precoding matrices, where the implementation of analog beamforming involves the real-time adjustment of the radiation pattern to adapt it to the dynamic wireless environment. Meanwhile, the digital beamforming is optimized based on the channel characteristics of analog beamforming to further improve the achievable rate of communication systems. An electromagnetic channel model incorporating array radiation patterns and the mutual coupling effect is also developed to evaluate the benefits of our proposed scheme. Simulation results demonstrate that our proposed EHB scheme with a 3D holographic array achieves a relatively flat superdirective beamforming gain and allows for programmable focusing directions throughout the entire spatial domain. Furthermore, they also verify that the proposed scheme achieves a sum rate gain of over 150% compared to traditional beamforming algorithms.