 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Confidence Score Based Speaker Adaptation of Conformer Speech Recognition Systems
Feb 15, 2023
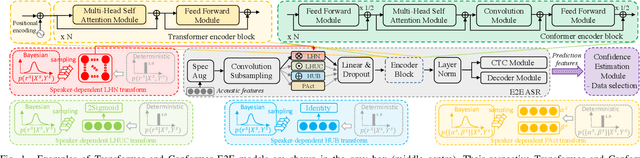
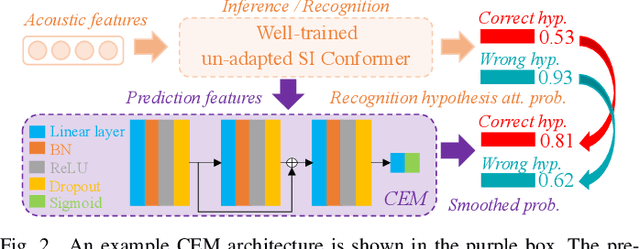
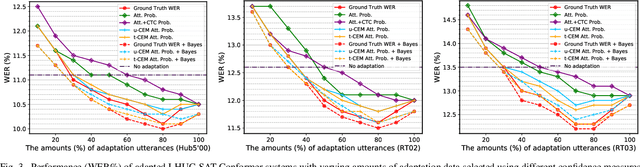
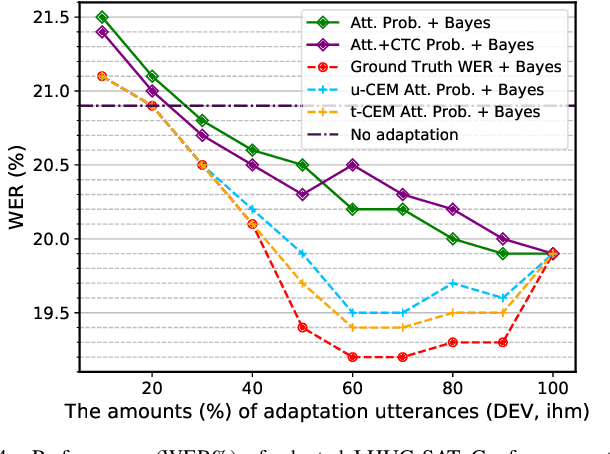
Speaker adaptation techniques provide a powerful solution to customise automatic speech recognition (ASR) systems for individual users. Practical application of unsupervised model-based speaker adaptation techniques to data intensive end-to-end ASR systems is hindered by the scarcity of speaker-level data and performance sensitivity to transcription errors. To address these issues, a set of compact and data efficient speaker-dependent (SD) parameter representations are used to facilitate both speaker adaptive training and test-time unsupervised speaker adaptation of state-of-the-art Conformer ASR systems. The sensitivity to supervision quality is reduced using a confidence score-based selection of the less erroneous subset of speaker-level adaptation data. Two lightweight confidence score estimation modules are proposed to produce more reliable confidence scores. The data sparsity issue, which is exacerbated by data selection, is addressed by modelling the SD parameter uncertainty using Bayesian learning. Experiments on the benchmark 300-hour Switchboard and the 233-hour AMI datasets suggest that the proposed confidence score-based adaptation schemes consistently outperformed the baseline speaker-independent (SI) Conformer model and conventional non-Bayesian, point estimate-based adaptation using no speaker data selection. Similar consistent performance improvements were retained after external Transformer and LSTM language model rescoring. In particular, on the 300-hour Switchboard corpus, statistically significant WER reductions of 1.0%, 1.3%, and 1.4% absolute (9.5%, 10.9%, and 11.3% relative) were obtained over the baseline SI Conformer on the NIST Hub5'00, RT02, and RT03 evaluation sets respectively. Similar WER reductions of 2.7% and 3.3% absolute (8.9% and 10.2% relative) were also obtained on the AMI development and evaluation sets.
Graph state-space models
Jan 04, 2023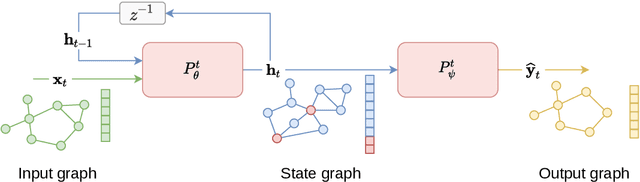

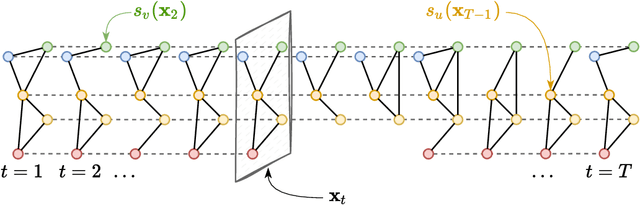
State-space models constitute an effective modeling tool to describe multivariate time series and operate by maintaining an updated representation of the system state from which predictions are made. Within this framework, relational inductive biases, e.g., associated with functional dependencies existing among signals, are not explicitly exploited leaving unattended great opportunities for effective modeling approaches. The manuscript aims, for the first time, at filling this gap by matching state-space modeling and spatio-temporal data where the relational information, say the functional graph capturing latent dependencies, is learned directly from data and is allowed to change over time. Within a probabilistic formulation that accounts for the uncertainty in the data-generating process, an encoder-decoder architecture is proposed to learn the state-space model end-to-end on a downstream task. The proposed methodological framework generalizes several state-of-the-art methods and demonstrates to be effective in extracting meaningful relational information while achieving optimal forecasting performance in controlled environments.
Local Differential Privacy for Sequential Decision Making in a Changing Environment
Jan 02, 2023We study the problem of preserving privacy while still providing high utility in sequential decision making scenarios in a changing environment. We consider abruptly changing environment: the environment remains constant during periods and it changes at unknown time instants. To formulate this problem, we propose a variant of multi-armed bandits called non-stationary stochastic corrupt bandits. We construct an algorithm called SW-KLUCB-CF and prove an upper bound on its utility using the performance measure of regret. The proven regret upper bound for SW-KLUCB-CF is near-optimal in the number of time steps and matches the best known bound for analogous problems in terms of the number of time steps and the number of changes. Moreover, we present a provably optimal mechanism which can guarantee the desired level of local differential privacy while providing high utility.
Deep Power Laws for Hyperparameter Optimization
Feb 01, 2023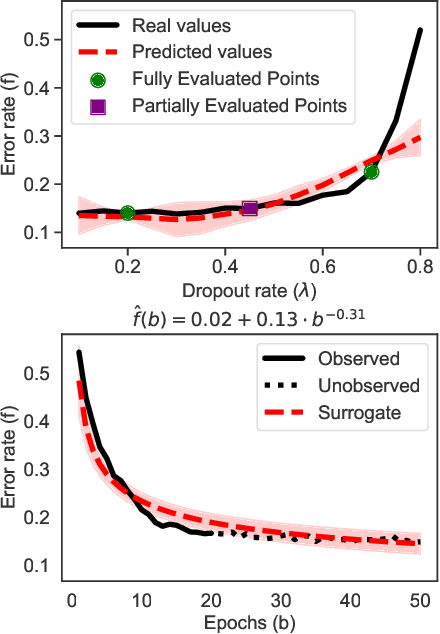



Hyperparameter optimization is an important subfield of machine learning that focuses on tuning the hyperparameters of a chosen algorithm to achieve peak performance. Recently, there has been a stream of methods that tackle the issue of hyperparameter optimization, however, most of the methods do not exploit the scaling law property of learning curves. In this work, we propose Deep Power Laws (DPL), an ensemble of neural network models conditioned to yield predictions that follow a power-law scaling pattern. Our method dynamically decides which configurations to pause and train incrementally by making use of gray-box evaluations. We compare our method against 7 state-of-the-art competitors on 3 benchmarks related to tabular, image, and NLP datasets covering 57 diverse tasks. Our method achieves the best results across all benchmarks by obtaining the best any-time results compared to all competitors.
DisDiff: Unsupervised Disentanglement of Diffusion Probabilistic Models
Feb 01, 2023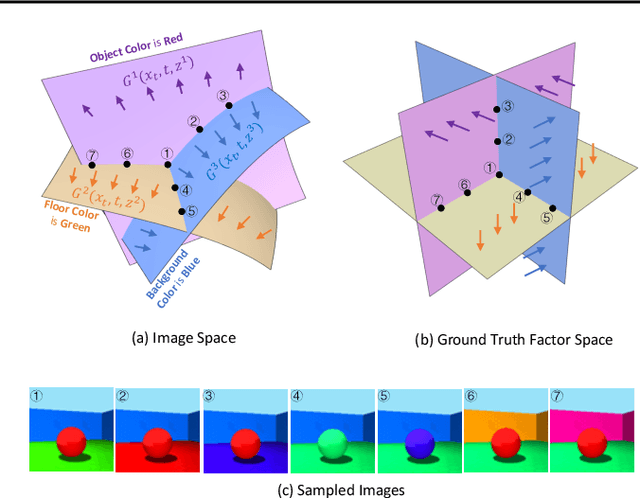
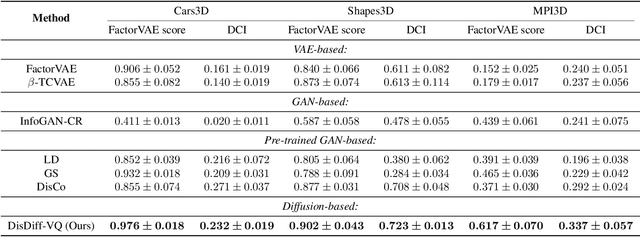
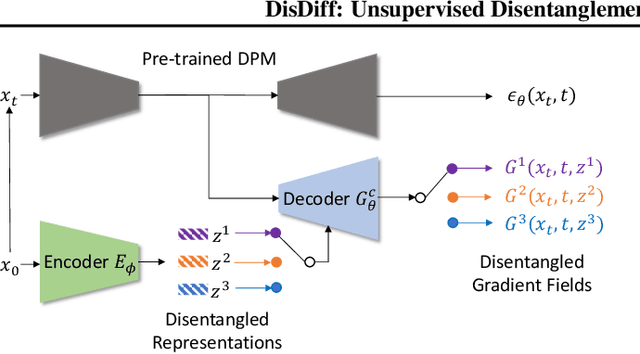
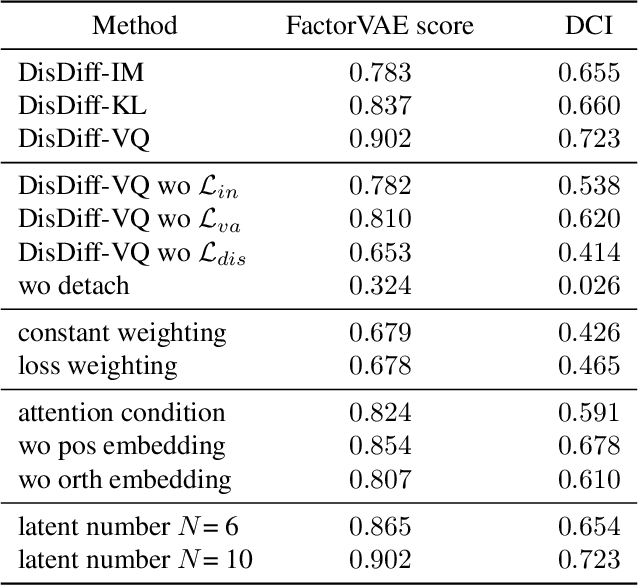
In this paper, targeting to understand the underlying explainable factors behind observations and modeling the conditional generation process on these factors, we propose a new task, disentanglement of diffusion probabilistic models (DPMs), to take advantage of the remarkable modeling ability of DPMs. To tackle this task, we further devise an unsupervised approach named DisDiff. For the first time, we achieve disentangled representation learning in the framework of diffusion probabilistic models. Given a pre-trained DPM, DisDiff can automatically discover the inherent factors behind the image data and disentangle the gradient fields of DPM into sub-gradient fields, each conditioned on the representation of each discovered factor. We propose a novel Disentangling Loss for DisDiff to facilitate the disentanglement of the representation and sub-gradients. The extensive experiments on synthetic and real-world datasets demonstrate the effectiveness of DisDiff.
The RW3D: A multi-modal panel dataset to understand the psychological impact of the pandemic
Feb 01, 2023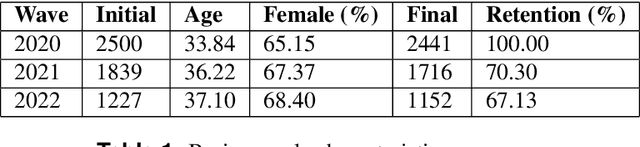
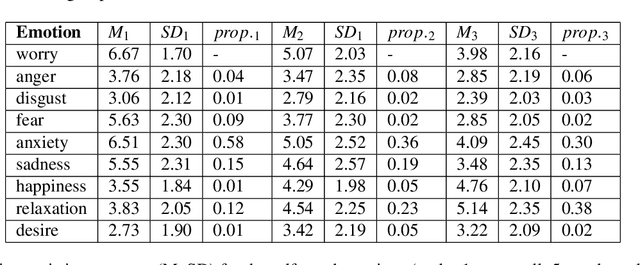

Besides far-reaching public health consequences, the COVID-19 pandemic had a significant psychological impact on people around the world. To gain further insight into this matter, we introduce the Real World Worry Waves Dataset (RW3D). The dataset combines rich open-ended free-text responses with survey data on emotions, significant life events, and psychological stressors in a repeated-measures design in the UK over three years (2020: n=2441, 2021: n=1716 and 2022: n=1152). This paper provides background information on the data collection procedure, the recorded variables, participants' demographics, and higher-order psychological and text-based derived variables that emerged from the data. The RW3D is a unique primary data resource that could inspire new research questions on the psychological impact of the pandemic, especially those that connect modalities (here: text data, psychological survey variables and demographics) over time.
Active Transfer Prototypical Network: An Efficient Labeling Algorithm for Time-Series Data
Sep 28, 2022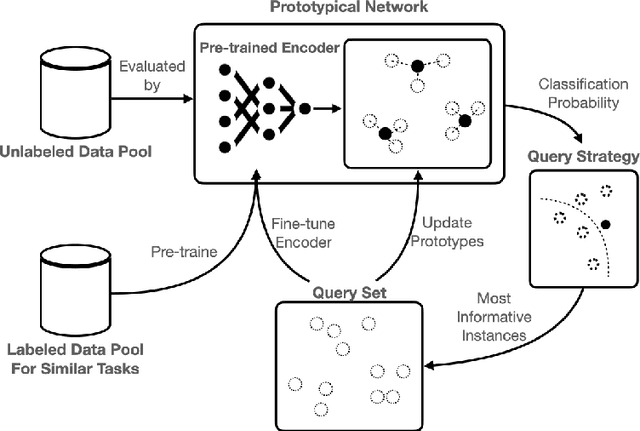
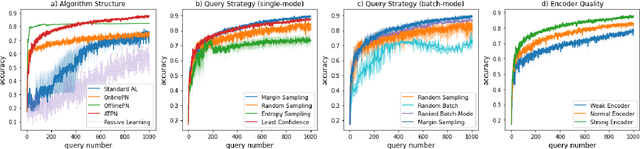
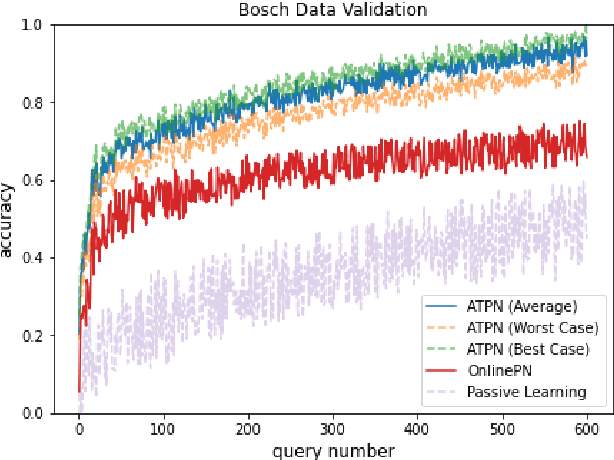
The paucity of labeled data is a typical challenge in the automotive industry. Annotating time-series measurements requires solid domain knowledge and in-depth exploratory data analysis, which implies a high labeling effort. Conventional Active Learning (AL) addresses this issue by actively querying the most informative instances based on the estimated classification probability and retraining the model iteratively. However, the learning efficiency strongly relies on the initial model, resulting in the trade-off between the size of the initial dataset and the query number. This paper proposes a novel Few-Shot Learning (FSL)-based AL framework, which addresses the trade-off problem by incorporating a Prototypical Network (ProtoNet) in the AL iterations. The results show an improvement, on the one hand, in the robustness to the initial model and, on the other hand, in the learning efficiency of the ProtoNet through the active selection of the support set in each iteration. This framework was validated on UCI HAR/HAPT dataset and a real-world braking maneuver dataset. The learning performance significantly surpasses traditional AL algorithms on both datasets, achieving 90% classification accuracy with 10% and 5% labeling effort, respectively.
Photonic Neural Networks: A Compact Review
Feb 16, 2023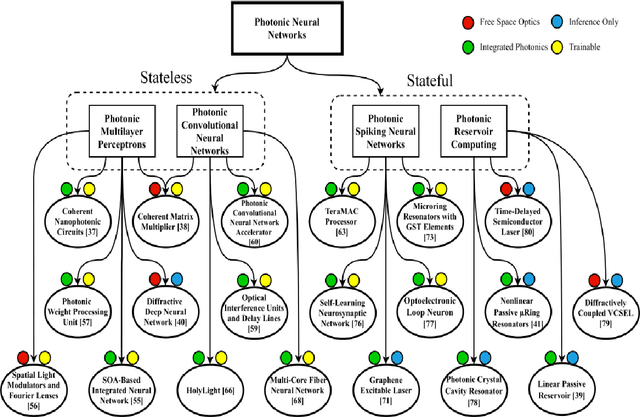
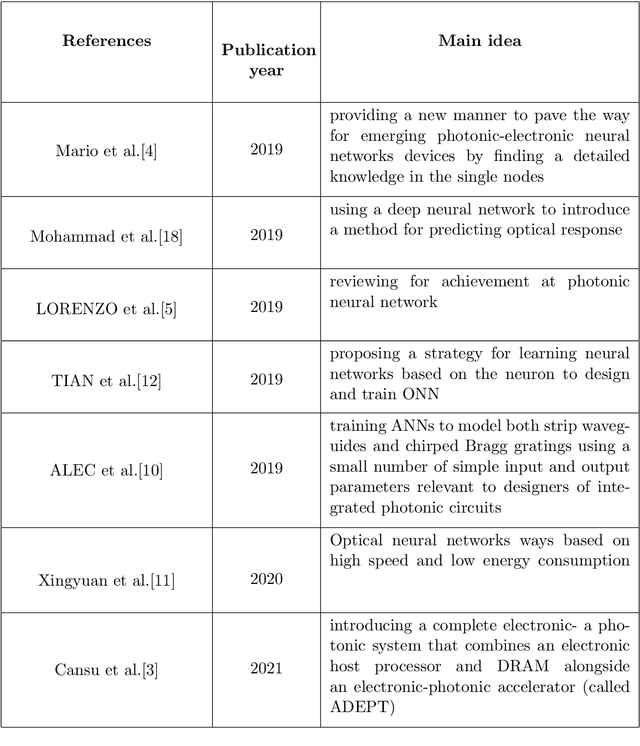
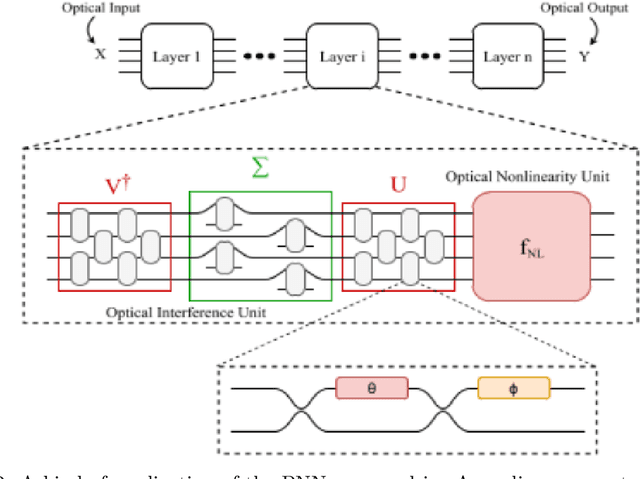
It has long been known that photonic science and especially photonic communications can raise the speed of technologies and producing manufacturing. More recently, photonic science has also been interested in its capabilities to implement low-precision linear operations, such as matrix multiplications, fast and effciently. For a long time most scientists taught that Electronics is the end of science but after many years and about 35 years ago had been understood that electronics do not answer alone and should have a new science. Today we face modern ways and instruments for doing tasks as soon as possible in proportion to many decays before. The velocity of progress in science is very fast. All our progress in science area is dependent on modern knowledge about new methods. In this research, we want to review the concept of a photonic neural network. For this research was selected 18 main articles were among the main 30 articles on this subject from 2015 to the 2022 year. These articles noticed three principles: 1- Experimental concepts, 2- Theoretical concepts, and, finally 3- Mathematic concepts. We should be careful with this research because mathematics has a very important and constructive role in our topics! One of the topics that are very valid and also new, is simulation. We used to work with simulation in some parts of this research. First, briefly, we start by introducing photonics and neural networks. In the second we explain the advantages and disadvantages of a combination of both in the science world and industries and technologies about them. Also, we are talking about the achievements of a thin modern science. Third, we try to introduce some important and valid parameters in neural networks. In this manner, we use many mathematic tools in some portions of this article.
Deterministic Nonsmooth Nonconvex Optimization
Feb 16, 2023We study the complexity of optimizing nonsmooth nonconvex Lipschitz functions by producing $(\delta,\epsilon)$-stationary points. Several recent works have presented randomized algorithms that produce such points using $\tilde O(\delta^{-1}\epsilon^{-3})$ first-order oracle calls, independent of the dimension $d$. It has been an open problem as to whether a similar result can be obtained via a deterministic algorithm. We resolve this open problem, showing that randomization is necessary to obtain a dimension-free rate. In particular, we prove a lower bound of $\Omega(d)$ for any deterministic algorithm. Moreover, we show that unlike smooth or convex optimization, access to function values is required for any deterministic algorithm to halt within any finite time. On the other hand, we prove that if the function is even slightly smooth, then the dimension-free rate of $\tilde O(\delta^{-1}\epsilon^{-3})$ can be obtained by a deterministic algorithm with merely a logarithmic dependence on the smoothness parameter. Motivated by these findings, we turn to study the complexity of deterministically smoothing Lipschitz functions. Though there are efficient black-box randomized smoothings, we start by showing that no such deterministic procedure can smooth functions in a meaningful manner, resolving an open question. We then bypass this impossibility result for the structured case of ReLU neural networks. To that end, in a practical white-box setting in which the optimizer is granted access to the network's architecture, we propose a simple, dimension-free, deterministic smoothing that provably preserves $(\delta,\epsilon)$-stationary points. Our method applies to a variety of architectures of arbitrary depth, including ResNets and ConvNets. Combined with our algorithm, this yields the first deterministic dimension-free algorithm for optimizing ReLU networks, circumventing our lower bound.
Quality vs. Quantity of Data in Contextual Decision-Making: Exact Analysis under Newsvendor Loss
Feb 16, 2023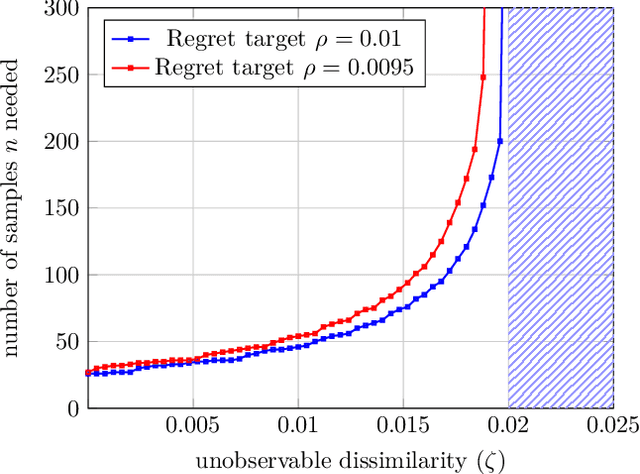
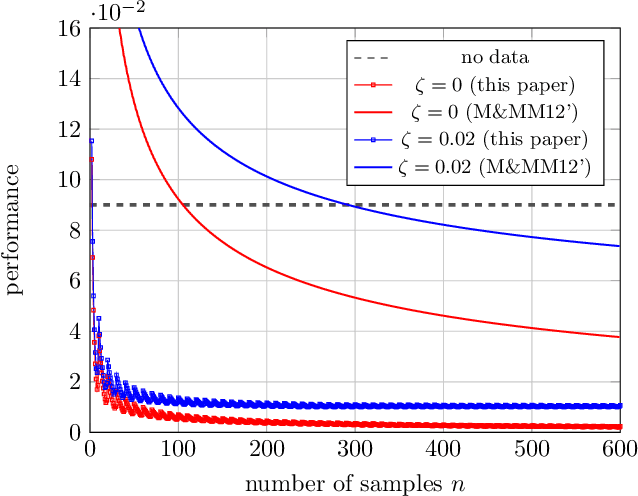
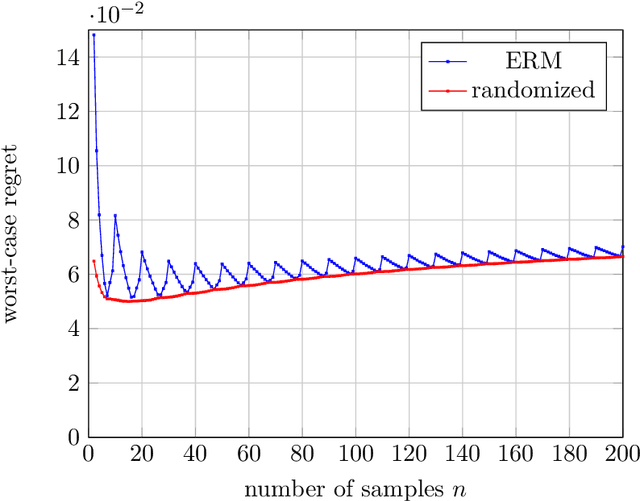
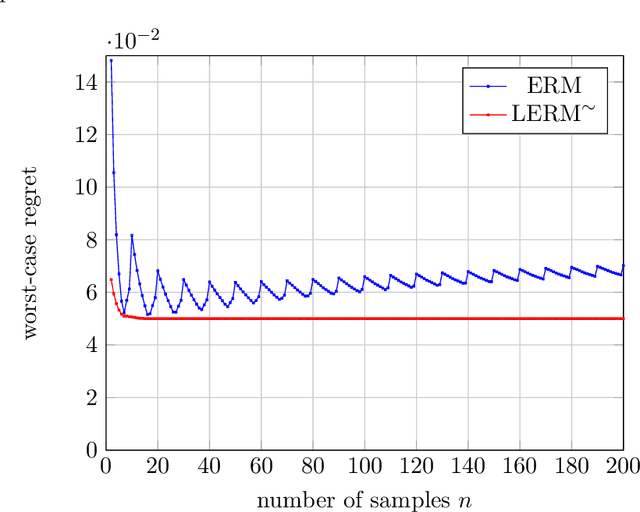
When building datasets, one needs to invest time, money and energy to either aggregate more data or to improve their quality. The most common practice favors quantity over quality without necessarily quantifying the trade-off that emerges. In this work, we study data-driven contextual decision-making and the performance implications of quality and quantity of data. We focus on contextual decision-making with a Newsvendor loss. This loss is that of a central capacity planning problem in Operations Research, but also that associated with quantile regression. We consider a model in which outcomes observed in similar contexts have similar distributions and analyze the performance of a classical class of kernel policies which weigh data according to their similarity in a contextual space. We develop a series of results that lead to an exact characterization of the worst-case expected regret of these policies. This exact characterization applies to any sample size and any observed contexts. The model we develop is flexible, and captures the case of partially observed contexts. This exact analysis enables to unveil new structural insights on the learning behavior of uniform kernel methods: i) the specialized analysis leads to very large improvements in quantification of performance compared to state of the art general purpose bounds. ii) we show an important non-monotonicity of the performance as a function of data size not captured by previous bounds; and iii) we show that in some regimes, a little increase in the quality of the data can dramatically reduce the amount of samples required to reach a performance target. All in all, our work demonstrates that it is possible to quantify in a precise fashion the interplay of data quality and quantity, and performance in a central problem class. It also highlights the need for problem specific bounds in order to understand the trade-offs at play.