 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time motion amplification on mobile devices
Jun 16, 2022
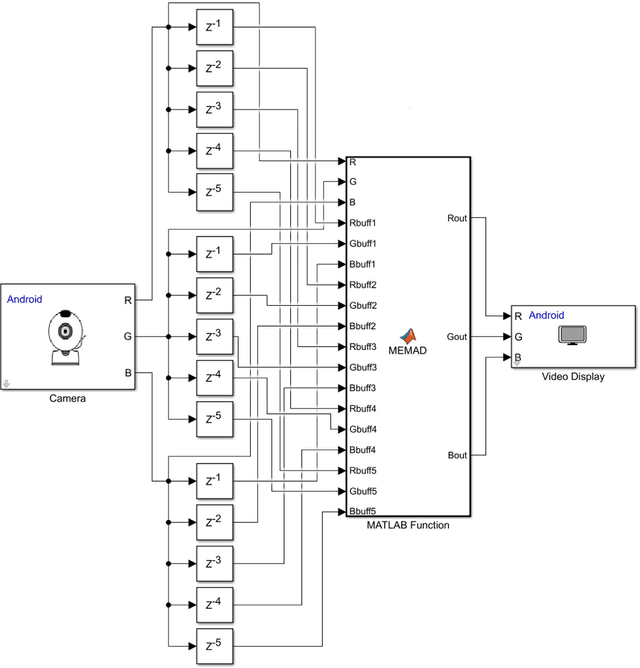


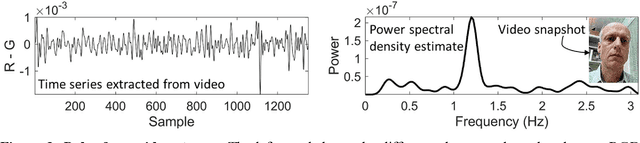
A simple motion amplification algorithm suitable for real-time applications on mobile devices is presented. It is based on motion enhancement by moving average differencing (MEMAD), a temporal high-pass filter for video streams. MEMAD can amplify small moving objects or subtle motion in larger objects. It is computationally sufficiently simple to be implemented in real time on smartphones. In the specific implementation as an Android phone app, MEMAD is demonstrated on examples chosen such as to motivate applications in the engineering, biological, and medical sciences.
Reactmine: a search algorithm for inferring chemical reaction networks from time series data
Sep 07, 2022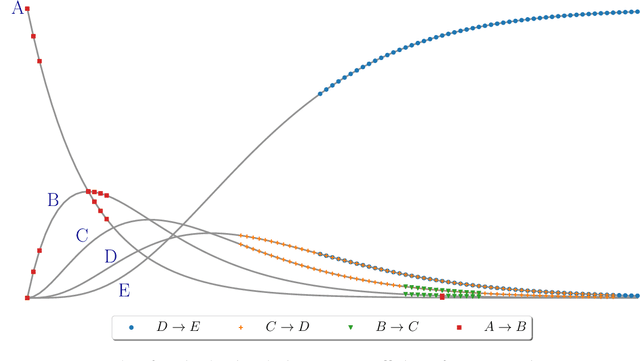
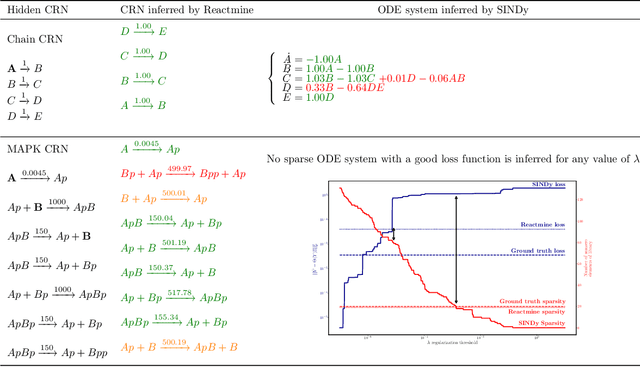
Inferring chemical reaction networks (CRN) from time series data is a challenge encouraged by the growing availability of quantitative temporal data at the cellular level. This motivates the design of algorithms to infer the preponderant reactions between the molecular species observed in a given biochemical process, and help to build CRN model structure and kinetics. Existing ODE-based inference methods such as SINDy resort to least square regression combined with sparsity-enforcing penalization, such as Lasso. However, when the input time series are only available in wild type conditions in which all reactions are present, we observe that current methods fail to learn sparse models. Results: We present Reactmine, a CRN learning algorithm which enforces sparsity by inferring reactions in a sequential fashion within a search tree of bounded depth, ranking the inferred reaction candidates according to the variance of their kinetics, and re-optimizing the CRN kinetic parameters on the whole trace in a final pass to rank the inferred CRN candidates. We first evaluate its performance on simulation data from a benchmark of hidden CRNs, together with algorithmic hyperparameter sensitivity analyses, and then on two sets of real experimental data: one from protein fluorescence videomicroscopy of cell cycle and circadian clock markers, and one from biomedical measurements of systemic circadian biomarkers possibly acting on clock gene expression in peripheral organs. We show that Reactmine succeeds both on simulation data by retrieving hidden CRNs where SINDy fails, and on the two real datasets by inferring reactions in agreement with previous studies.
Offline Learning of Closed-Loop Deep Brain Stimulation Controllers for Parkinson Disease Treatment
Feb 09, 2023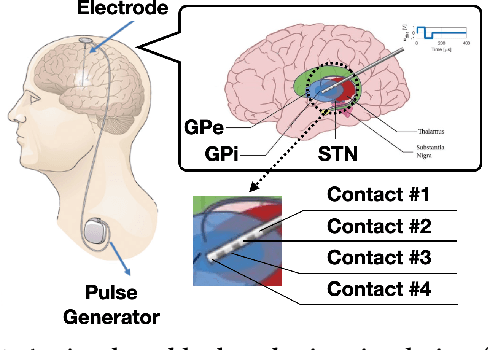
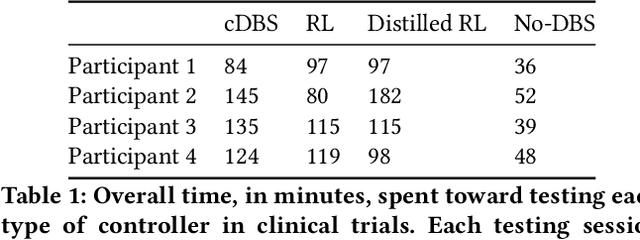
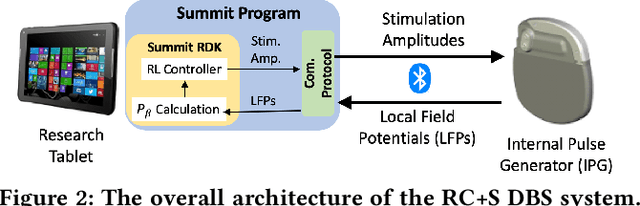

Deep brain stimulation (DBS) has shown great promise toward treating motor symptoms caused by Parkinson's disease (PD), by delivering electrical pulses to the Basal Ganglia (BG) region of the brain. However, DBS devices approved by the U.S. Food and Drug Administration (FDA) can only deliver continuous DBS (cDBS) stimuli at a fixed amplitude; this energy inefficient operation reduces battery lifetime of the device, cannot adapt treatment dynamically for activity, and may cause significant side-effects (e.g., gait impairment). In this work, we introduce an offline reinforcement learning (RL) framework, allowing the use of past clinical data to train an RL policy to adjust the stimulation amplitude in real time, with the goal of reducing energy use while maintaining the same level of treatment (i.e., control) efficacy as cDBS. Moreover, clinical protocols require the safety and performance of such RL controllers to be demonstrated ahead of deployments in patients. Thus, we also introduce an offline policy evaluation (OPE) method to estimate the performance of RL policies using historical data, before deploying them on patients. We evaluated our framework on four PD patients equipped with the RC+S DBS system, employing the RL controllers during monthly clinical visits, with the overall control efficacy evaluated by severity of symptoms (i.e., bradykinesia and tremor), changes in PD biomakers (i.e., local field potentials), and patient ratings. The results from clinical experiments show that our RL-based controller maintains the same level of control efficacy as cDBS, but with significantly reduced stimulation energy. Further, the OPE method is shown effective in accurately estimating and ranking the expected returns of RL controllers.
PDFormer: Propagation Delay-aware Dynamic Long-range Transformer for Traffic Flow Prediction
Jan 19, 2023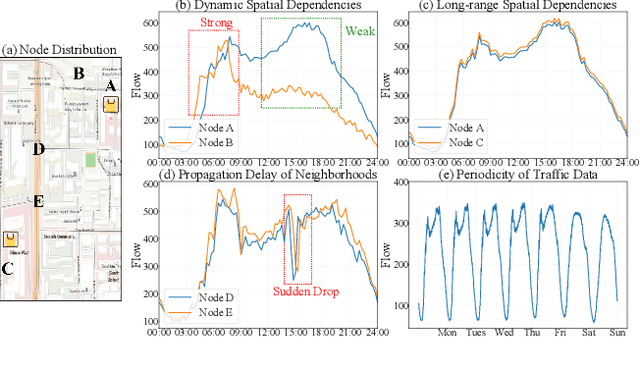
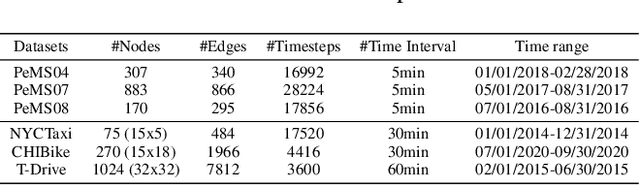
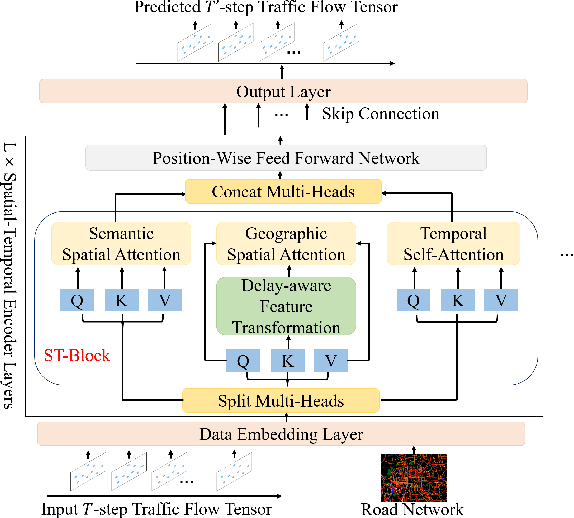
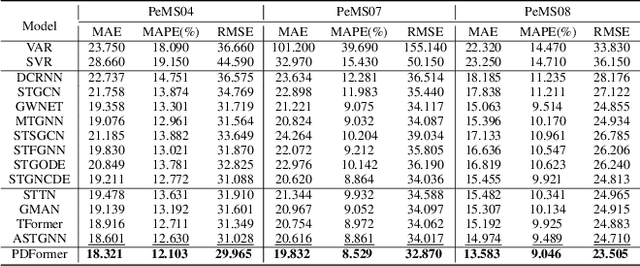
As a core technology of Intelligent Transportation System, traffic flow prediction has a wide range of applications. The fundamental challenge in traffic flow prediction is to effectively model the complex spatial-temporal dependencies in traffic data. Spatial-temporal Graph Neural Network (GNN) models have emerged as one of the most promising methods to solve this problem. However, GNN-based models have three major limitations for traffic prediction: i) Most methods model spatial dependencies in a static manner, which limits the ability to learn dynamic urban traffic patterns; ii) Most methods only consider short-range spatial information and are unable to capture long-range spatial dependencies; iii) These methods ignore the fact that the propagation of traffic conditions between locations has a time delay in traffic systems. To this end, we propose a novel Propagation Delay-aware dynamic long-range transFormer, namely PDFormer, for accurate traffic flow prediction. Specifically, we design a spatial self-attention module to capture the dynamic spatial dependencies. Then, two graph masking matrices are introduced to highlight spatial dependencies from short- and long-range views. Moreover, a traffic delay-aware feature transformation module is proposed to empower PDFormer with the capability of explicitly modeling the time delay of spatial information propagation. Extensive experimental results on six real-world public traffic datasets show that our method can not only achieve state-of-the-art performance but also exhibit competitive computational efficiency. Moreover, we visualize the learned spatial-temporal attention map to make our model highly interpretable.
PyGlove: Efficiently Exchanging ML Ideas as Code
Feb 03, 2023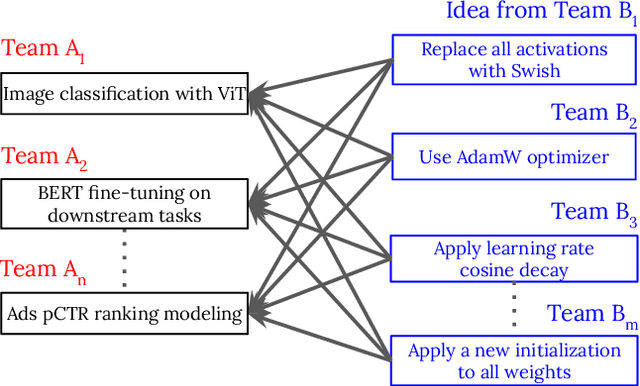



The increasing complexity and scale of machine learning (ML) has led to the need for more efficient collaboration among multiple teams. For example, when a research team invents a new architecture like "ResNet," it is desirable for multiple engineering teams to adopt it. However, the effort required for each team to study and understand the invention does not scale well with the number of teams or inventions. In this paper, we present an extension of our PyGlove library to easily and scalably share ML ideas. PyGlove represents ideas as symbolic rule-based patches, enabling researchers to write down the rules for models they have not seen. For example, an inventor can write rules that will "add skip-connections." This permits a network effect among teams: at once, any team can issue patches to all other teams. Such a network effect allows users to quickly surmount the cost of adopting PyGlove by writing less code quicker, providing a benefit that scales with time. We describe the new paradigm of organizing ML through symbolic patches and compare it to existing approaches. We also perform a case study of a large codebase where PyGlove led to an 80% reduction in the number of lines of code.
SCCAM: Supervised Contrastive Convolutional Attention Mechanism for Ante-hoc Interpretable Fault Diagnosis with Limited Fault Samples
Feb 03, 2023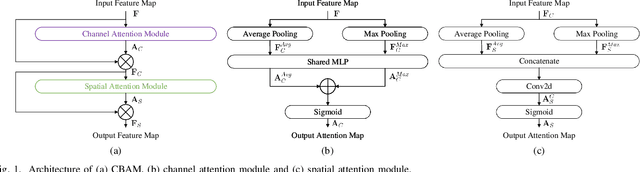

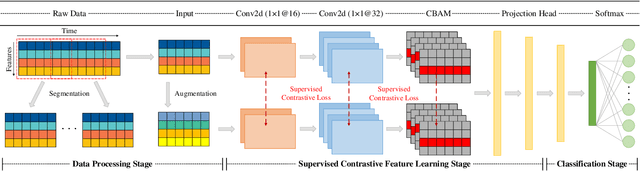
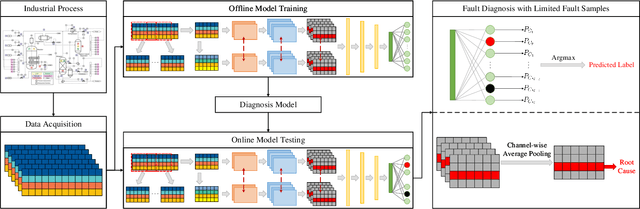
In real industrial processes, fault diagnosis methods are required to learn from limited fault samples since the procedures are mainly under normal conditions and the faults rarely occur. Although attention mechanisms have become popular in the field of fault diagnosis, the existing attention-based methods are still unsatisfying for the above practical applications. First, pure attention-based architectures like transformers need a large number of fault samples to offset the lack of inductive biases thus performing poorly under limited fault samples. Moreover, the poor fault classification dilemma further leads to the failure of the existing attention-based methods to identify the root causes. To address the aforementioned issues, we innovatively propose a supervised contrastive convolutional attention mechanism (SCCAM) with ante-hoc interpretability, which solves the root cause analysis problem under limited fault samples for the first time. The proposed SCCAM method is tested on a continuous stirred tank heater and the Tennessee Eastman industrial process benchmark. Three common fault diagnosis scenarios are covered, including a balanced scenario for additional verification and two scenarios with limited fault samples (i.e., imbalanced scenario and long-tail scenario). The comprehensive results demonstrate that the proposed SCCAM method can achieve better performance compared with the state-of-the-art methods on fault classification and root cause analysis.
Large Language Models Are Implicitly Topic Models: Explaining and Finding Good Demonstrations for In-Context Learning
Jan 27, 2023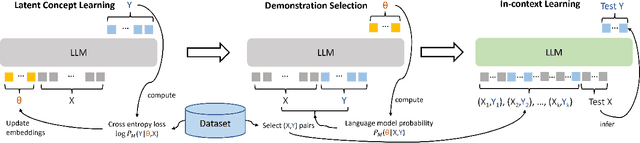
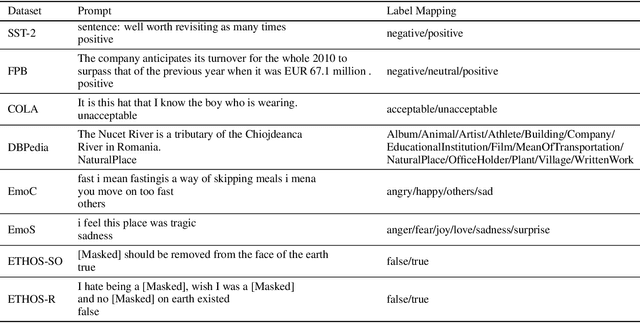
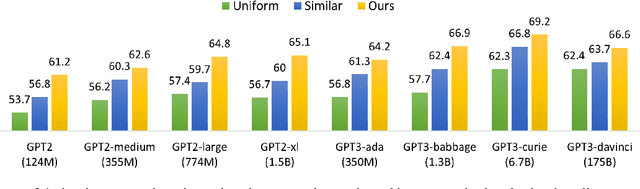
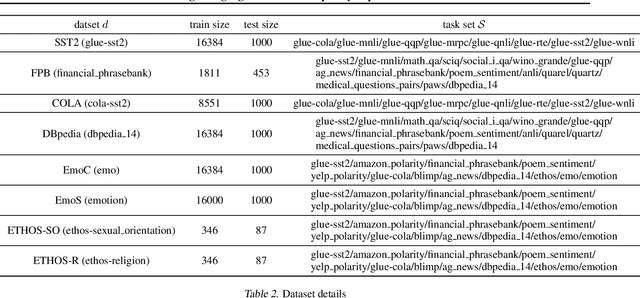
In recent years, pre-trained large language models have demonstrated remarkable efficiency in achieving an inference-time few-shot learning capability known as in-context learning. However, existing literature has highlighted the sensitivity of this capability to the selection of few-shot demonstrations. The underlying mechanisms by which this capability arises from regular language model pretraining objectives remain poorly understood. In this study, we aim to examine the in-context learning phenomenon through a Bayesian lens, viewing large language models as topic models that implicitly infer task-related information from demonstrations. On this premise, we propose an algorithm for selecting optimal demonstrations from a set of annotated data and demonstrate a significant 12.5% improvement relative to the random selection baseline, averaged over eight GPT2 and GPT3 models on eight different real-world text classification datasets. Our empirical findings support our hypothesis that large language models implicitly infer a latent concept variable.
Byte Pair Encoding for Symbolic Music
Jan 27, 2023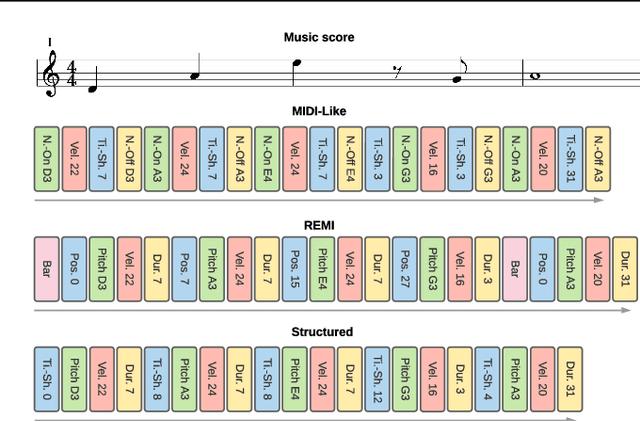
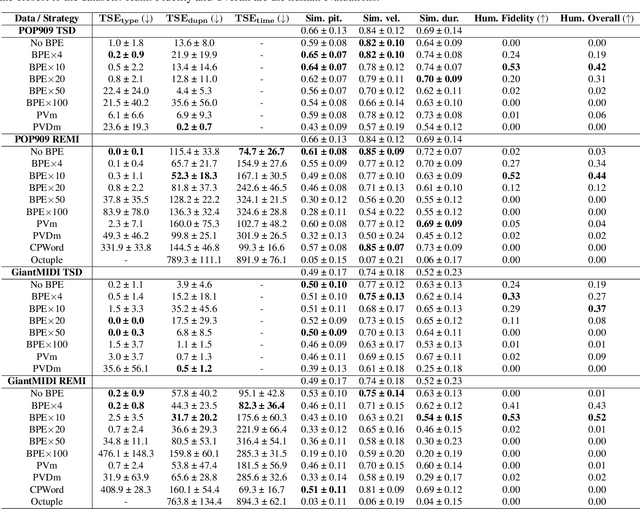
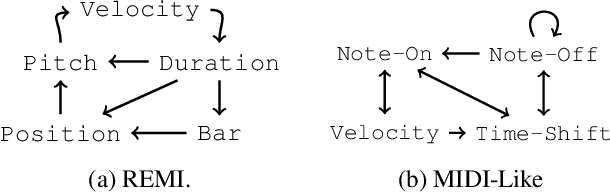
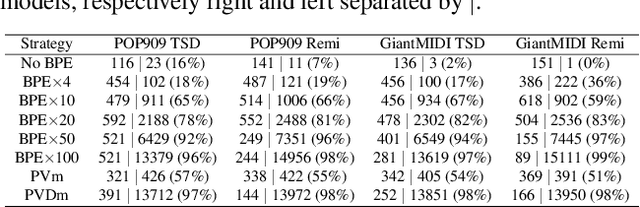
The symbolic music modality is nowadays mostly represented as discrete and used with sequential models such as Transformers, for deep learning tasks. Recent research put efforts on the tokenization, i.e. the conversion of data into sequences of integers intelligible to such models. This can be achieved by many ways as music can be composed of simultaneous tracks, of simultaneous notes with several attributes. Until now, the proposed tokenizations are based on small vocabularies describing the note attributes and time events, resulting in fairly long token sequences. In this paper, we show how Byte Pair Encoding (BPE) can improve the results of deep learning models while improving its performances. We experiment on music generation and composer classification, and study the impact of BPE on how models learn the embeddings, and show that it can help to increase their isotropy, i.e., the uniformity of the variance of their positions in the space.
Sequential Graph Attention Learning for Predicting Dynamic Stock Trends (Student Abstract)
Jan 15, 2023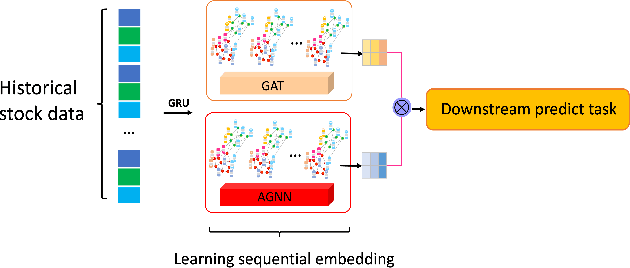
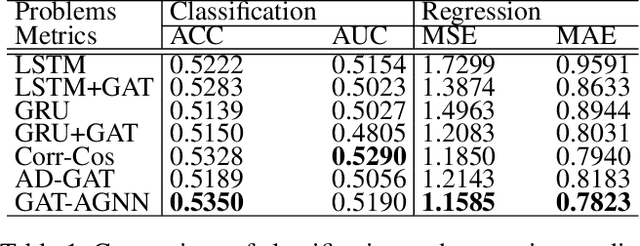

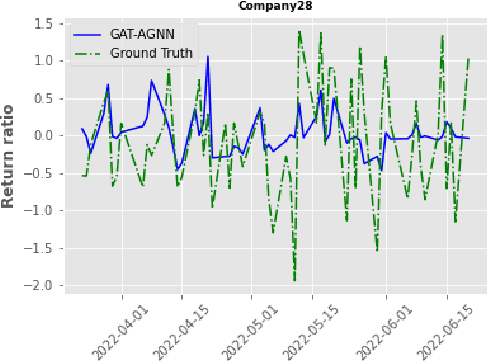
The stock market is characterized by a complex relationship between companies and the market. This study combines a sequential graph structure with attention mechanisms to learn global and local information within temporal time. Specifically, our proposed "GAT-AGNN" module compares model performance across multiple industries as well as within single industries. The results show that the proposed framework outperforms the state-of-the-art methods in predicting stock trends across multiple industries on Taiwan Stock datasets.
Discovering and Explaining Driver Behaviour under HoS Regulations
Jan 12, 2023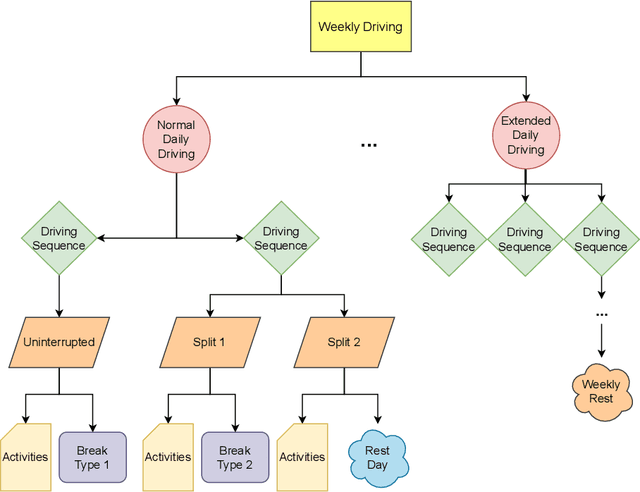
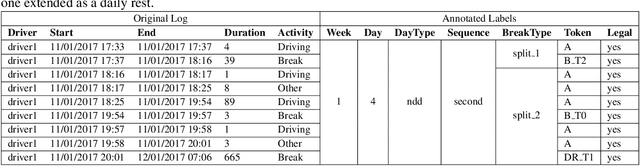


World wide transport authorities are imposing complex Hours of Service regulations to drivers, which constraint the amount of working, driving and resting time when delivering a service. As a consequence, transport companies are responsible not only of scheduling driving plans aligned with laws that define the legal behaviour of a driver, but also of monitoring and identifying as soon as possible problematic patterns that can incur in costs due to sanctions. Transport experts are frequently in charge of many drivers and lack time to analyse the vast amount of data recorded by the onboard sensors, and companies have grown accustomed to pay sanctions rather than predict and forestall wrongdoings. This paper exposes an application for summarising raw driver activity logs according to these regulations and for explaining driver behaviour in a human readable format. The system employs planning, constraint, and clustering techniques to extract and describe what the driver has been doing while identifying infractions and the activities that originate them. Furthermore, it groups drivers based on similar driving patterns. An experimentation in real world data indicates that recurring driving patterns can be clustered from short basic driving sequences to whole drivers working days.