 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SwinCross: Cross-modal Swin Transformer for Head-and-Neck Tumor Segmentation in PET/CT Images
Feb 08, 2023
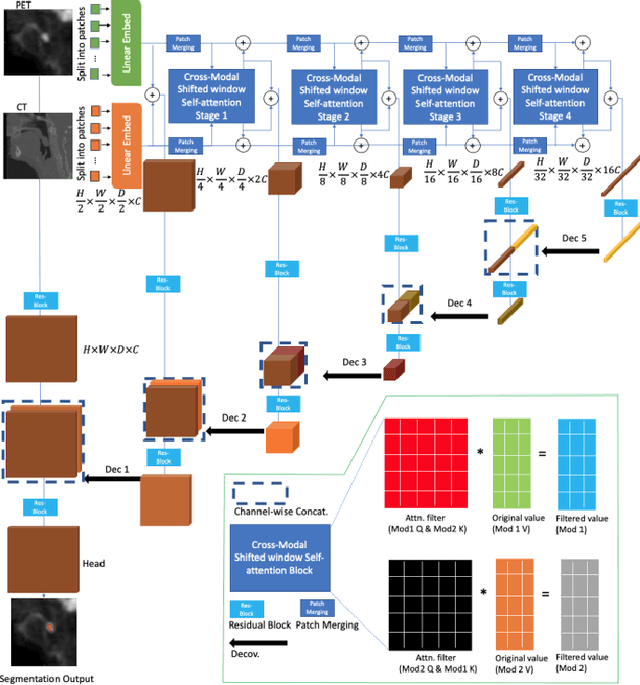
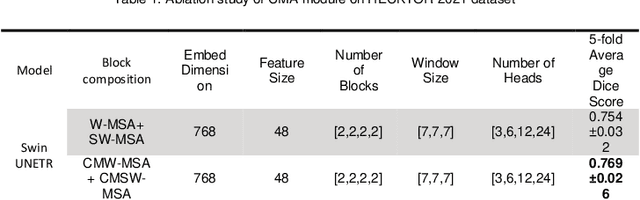
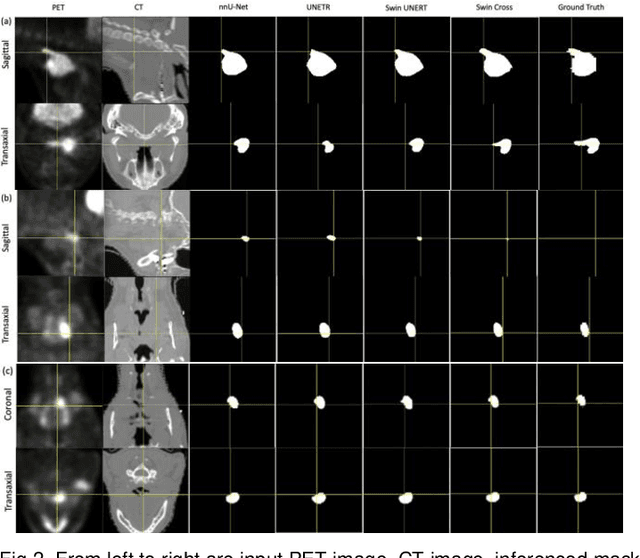
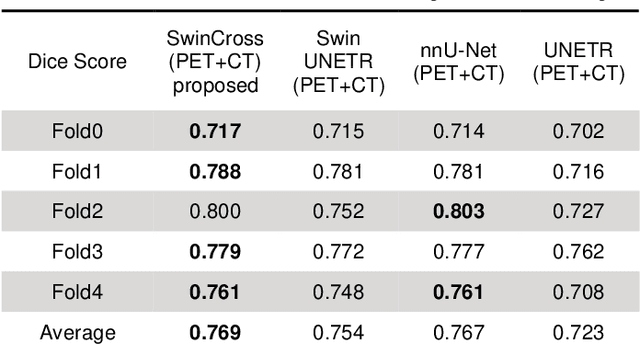
Radiotherapy (RT) combined with cetuximab is the standard treatment for patients with inoperable head and neck cancers. Segmentation of head and neck (H&N) tumors is a prerequisite for radiotherapy planning but a time-consuming process. In recent years, deep convolutional neural networks have become the de facto standard for automated image segmentation. However, due to the expensive computational cost associated with enlarging the field of view in DCNNs, their ability to model long-range dependency is still limited, and this can result in sub-optimal segmentation performance for objects with background context spanning over long distances. On the other hand, Transformer models have demonstrated excellent capabilities in capturing such long-range information in several semantic segmentation tasks performed on medical images. Inspired by the recent success of Vision Transformers and advances in multi-modal image analysis, we propose a novel segmentation model, debuted, Cross-Modal Swin Transformer (SwinCross), with cross-modal attention (CMA) module to incorporate cross-modal feature extraction at multiple resolutions.To validate the effectiveness of the proposed method, we performed experiments on the HECKTOR 2021 challenge dataset and compared it with the nnU-Net (the backbone of the top-5 methods in HECKTOR 2021) and other state-of-the-art transformer-based methods such as UNETR, and Swin UNETR. The proposed method is experimentally shown to outperform these comparing methods thanks to the ability of the CMA module to capture better inter-modality complimentary feature representations between PET and CT, for the task of head-and-neck tumor segmentation.
Relativistic Digital Twin: Bringing the IoT to the Future
Jan 18, 2023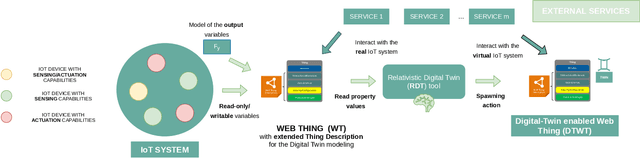
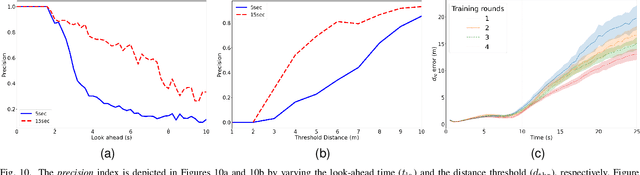
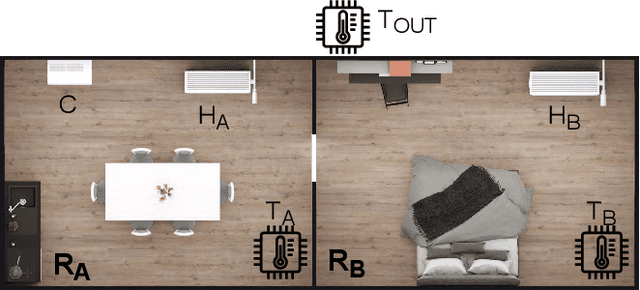
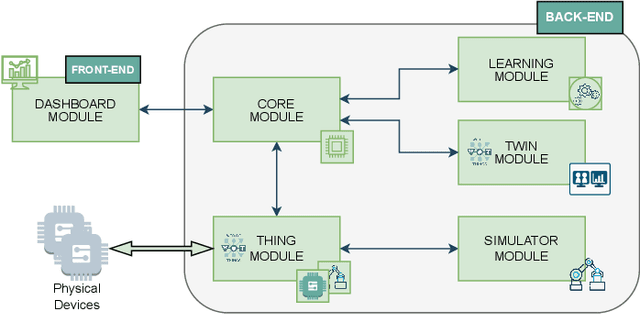
Complex IoT ecosystems often require the usage of Digital Twins (DTs) of their physical assets in order to perform predictive analytics and simulate what-if scenarios. DTs are able to replicate IoT devices and adapt over time to their behavioral changes. However, DTs in IoT are typically tailored to a specific use case, without the possibility to seamlessly adapt to different scenarios. Further, the fragmentation of IoT poses additional challenges on how to deploy DTs in heterogeneous scenarios characterized by the usage of multiple data formats and IoT network protocols. In this paper, we propose the Relativistic Digital Twin (RDT) framework, through which we automatically generate general purpose DTs of IoT entities and tune their behavioral models over time by constantly observing their real counterparts. The framework relies on the object representation via the Web of Things (WoT), to offer a standardized interface to each of the IoT devices as well as to their DTs. To this purpose, we extended the W3C WoT standard in order to encompass the concept of behavioral model and define it in the Thing Description (TD) through a new vocabulary. Finally, we evaluated the RDT framework over two disjoint use cases to assess its correctness and learning performance, i.e. the DT of a simulated smart home scenario with the capability of forecasting the indoor temperature, and the DT of a real-world drone with the capability of forecasting its trajectory in an outdoor scenario.
Spatio-Temporal Point Process for Multiple Object Tracking
Feb 05, 2023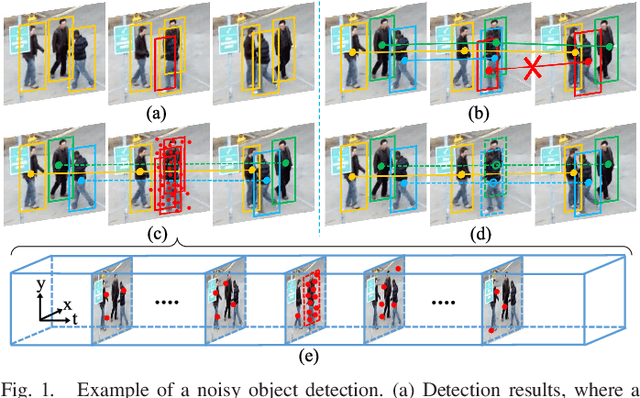
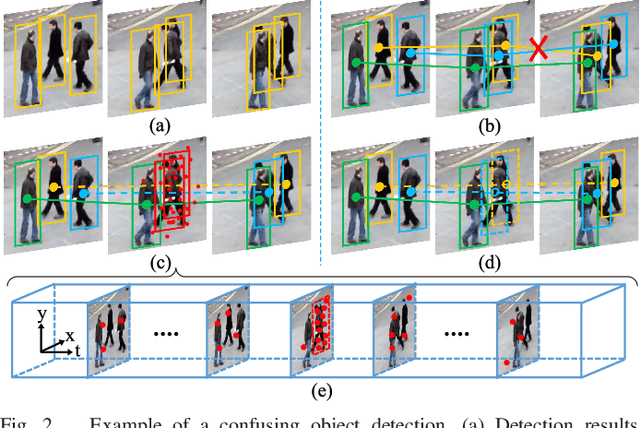
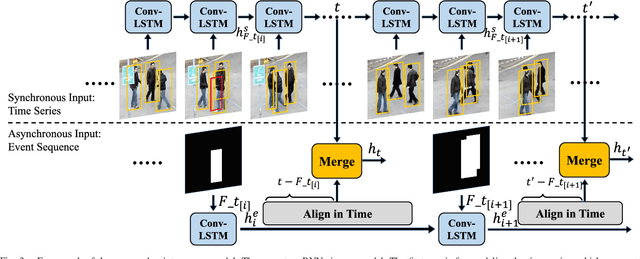
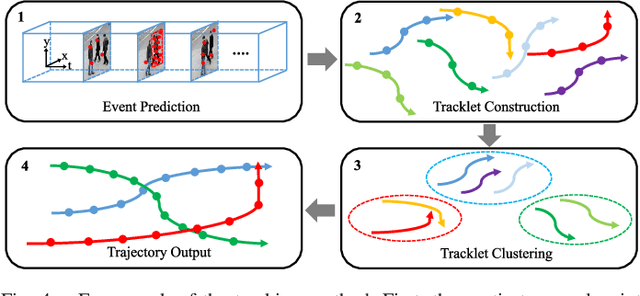
Multiple Object Tracking (MOT) focuses on modeling the relationship of detected objects among consecutive frames and merge them into different trajectories. MOT remains a challenging task as noisy and confusing detection results often hinder the final performance. Furthermore, most existing research are focusing on improving detection algorithms and association strategies. As such, we propose a novel framework that can effectively predict and mask-out the noisy and confusing detection results before associating the objects into trajectories. In particular, we formulate such "bad" detection results as a sequence of events and adopt the spatio-temporal point process}to model such events. Traditionally, the occurrence rate in a point process is characterized by an explicitly defined intensity function, which depends on the prior knowledge of some specific tasks. Thus, designing a proper model is expensive and time-consuming, with also limited ability to generalize well. To tackle this problem, we adopt the convolutional recurrent neural network (conv-RNN) to instantiate the point process, where its intensity function is automatically modeled by the training data. Furthermore, we show that our method captures both temporal and spatial evolution, which is essential in modeling events for MOT. Experimental results demonstrate notable improvements in addressing noisy and confusing detection results in MOT datasets. An improved state-of-the-art performance is achieved by incorporating our baseline MOT algorithm with the spatio-temporal point process model.
CIPER: Combining Invariant and Equivariant Representations Using Contrastive and Predictive Learning
Feb 05, 2023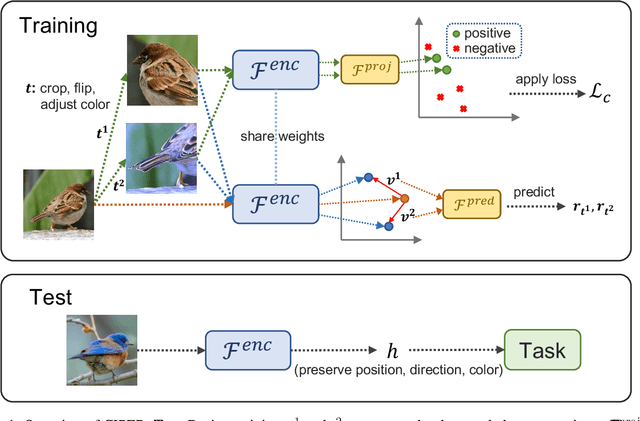


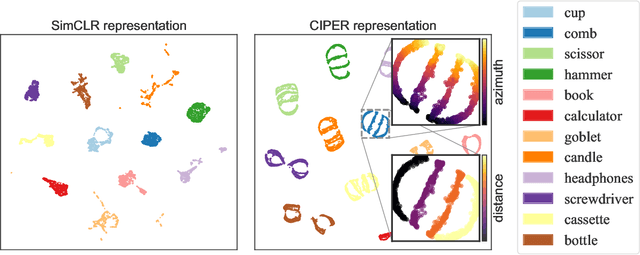
Self-supervised representation learning (SSRL) methods have shown great success in computer vision. In recent studies, augmentation-based contrastive learning methods have been proposed for learning representations that are invariant or equivariant to pre-defined data augmentation operations. However, invariant or equivariant features favor only specific downstream tasks depending on the augmentations chosen. They may result in poor performance when a downstream task requires the counterpart of those features (e.g., when the task is to recognize hand-written digits while the model learns to be invariant to in-plane image rotations rendering it incapable of distinguishing "9" from "6"). This work introduces Contrastive Invariant and Predictive Equivariant Representation learning (CIPER). CIPER comprises both invariant and equivariant learning objectives using one shared encoder and two different output heads on top of the encoder. One output head is a projection head with a state-of-the-art contrastive objective to encourage invariance to augmentations. The other is a prediction head estimating the augmentation parameters, capturing equivariant features. Both heads are discarded after training and only the encoder is used for downstream tasks. We evaluate our method on static image tasks and time-augmented image datasets. Our results show that CIPER outperforms a baseline contrastive method on various tasks, especially when the downstream task requires the encoding of augmentation-related information.
Using Intermediate Forward Iterates for Intermediate Generator Optimization
Feb 05, 2023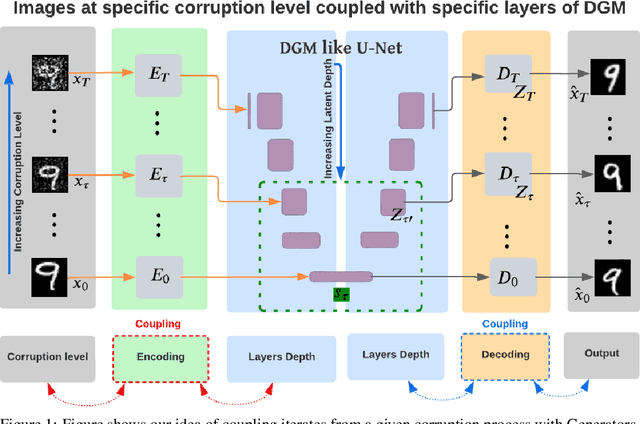
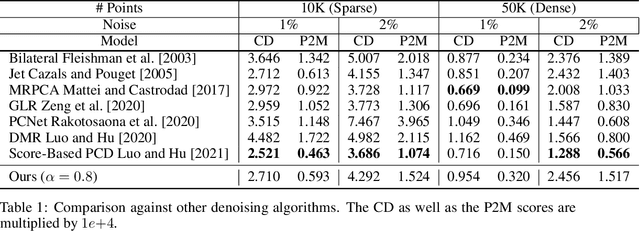
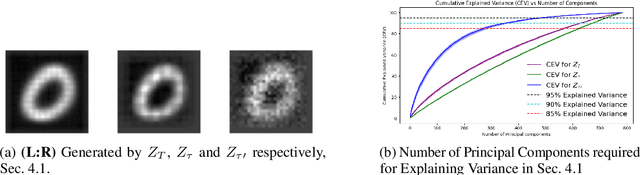

Score-based models have recently been introduced as a richer framework to model distributions in high dimensions and are generally more suitable for generative tasks. In score-based models, a generative task is formulated using a parametric model (such as a neural network) to directly learn the gradient of such high dimensional distributions, instead of the density functions themselves, as is done traditionally. From the mathematical point of view, such gradient information can be utilized in reverse by stochastic sampling to generate diverse samples. However, from a computational perspective, existing score-based models can be efficiently trained only if the forward or the corruption process can be computed in closed form. By using the relationship between the process and layers in a feed-forward network, we derive a backpropagation-based procedure which we call Intermediate Generator Optimization to utilize intermediate iterates of the process with negligible computational overhead. The main advantage of IGO is that it can be incorporated into any standard autoencoder pipeline for the generative task. We analyze the sample complexity properties of IGO to solve downstream tasks like Generative PCA. We show applications of the IGO on two dense predictive tasks viz., image extrapolation, and point cloud denoising. Our experiments indicate that obtaining an ensemble of generators for various time points is possible using first-order methods.
The Role of Time Delay in Sim2real Transfer of Reinforcement Learning for Cyber-Physical Systems
Sep 30, 2022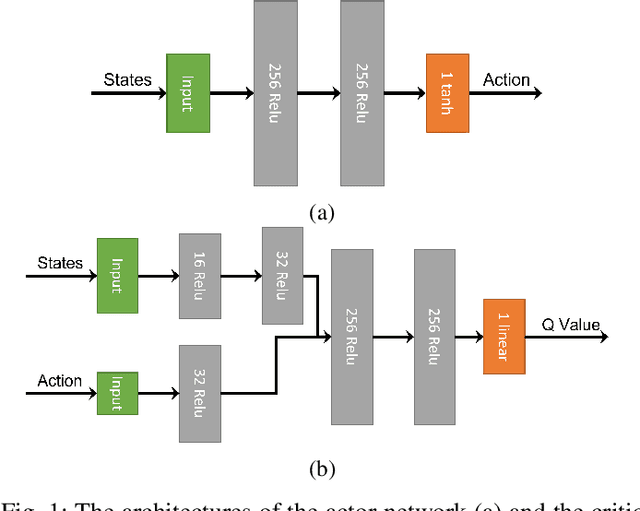
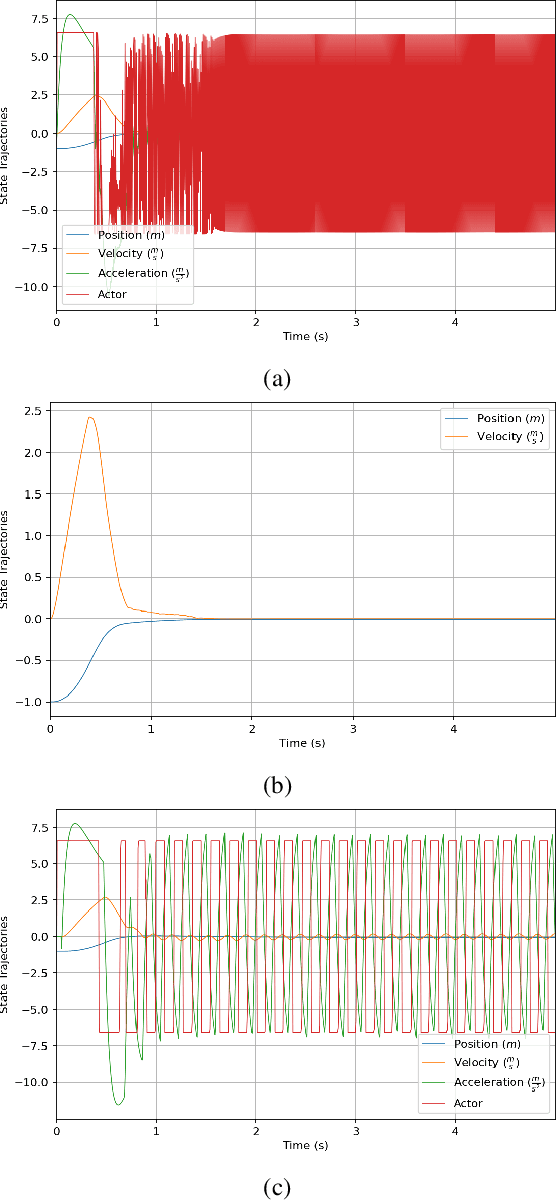
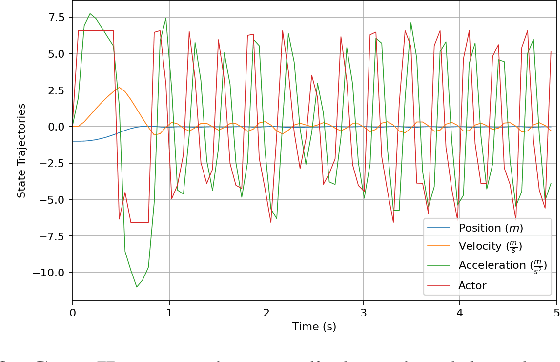
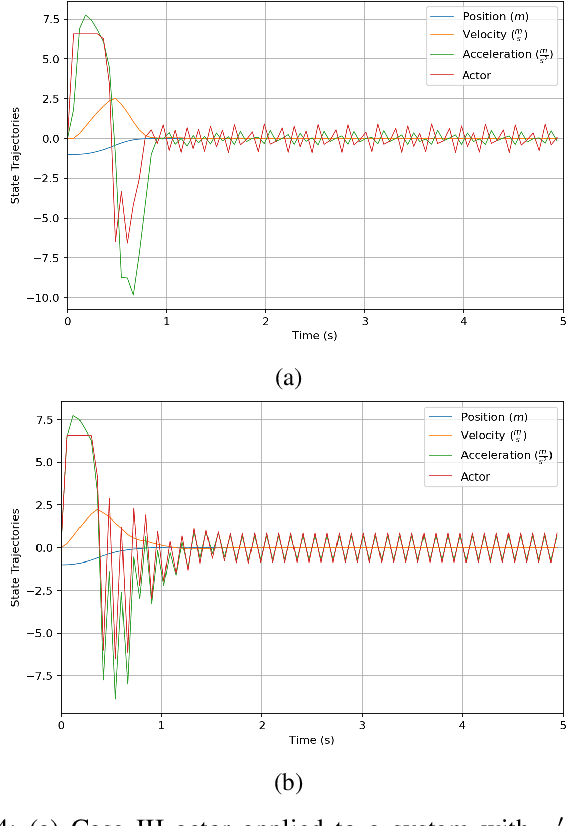
This paper analyzes the simulation to reality gap in reinforcement learning (RL) cyber-physical systems with fractional delays (i.e. delays that are non-integer multiple of the sampling period). The consideration of fractional delay has important implications on the nature of the cyber-physical system considered. Systems with delays are non-Markovian, and the system state vector needs to be extended to make the system Markovian. We show that this is not possible when the delay is in the output, and the problem would always be non-Markovian. Based on this analysis, a sampling scheme is proposed that results in efficient RL training and agents that perform well in realistic multirotor unmanned aerial vehicle simulations. We demonstrate that the resultant agents do not produce excessive oscillations, which is not the case with RL agents that do not consider time delay in the model.
Broad Learning System with Takagi-Sugeno Fuzzy Subsystem for Tobacco Origin Identification based on Near Infrared Spectroscopy
Dec 31, 2022Tobacco origin identification is significantly important in tobacco industry. Modeling analysis for sensor data with near infrared spectroscopy has become a popular method for rapid detection of internal features. However, for sensor data analysis using traditional artificial neural network or deep network models, the training process is extremely time-consuming. In this paper, a novel broad learning system with Takagi-Sugeno (TS) fuzzy subsystem is proposed for rapid identification of tobacco origin. Incremental learning is employed in the proposed method, which obtains the weight matrix of the network after a very small amount of computation, resulting in much shorter training time for the model, with only about 3 seconds for the extra step training. The experimental results show that the TS fuzzy subsystem can extract features from the near infrared data and effectively improve the recognition performance. The proposed method can achieve the highest prediction accuracy (95.59 %) in comparison to the traditional classification algorithms, artificial neural network, and deep convolutional neural network, and has a great advantage in the training time with only about 128 seconds.
TranSOP: Transformer-based Multimodal Classification for Stroke Treatment Outcome Prediction
Jan 25, 2023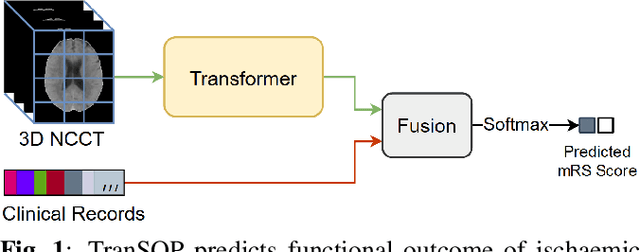
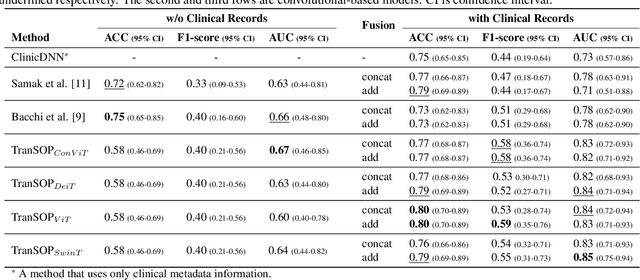
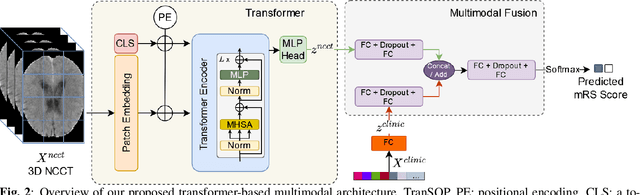
Acute ischaemic stroke, caused by an interruption in blood flow to brain tissue, is a leading cause of disability and mortality worldwide. The selection of patients for the most optimal ischaemic stroke treatment is a crucial step for a successful outcome, as the effect of treatment highly depends on the time to treatment. We propose a transformer-based multimodal network (TranSOP) for a classification approach that employs clinical metadata and imaging information, acquired on hospital admission, to predict the functional outcome of stroke treatment based on the modified Rankin Scale (mRS). This includes a fusion module to efficiently combine 3D non-contrast computed tomography (NCCT) features and clinical information. In comparative experiments using unimodal and multimodal data on the MRCLEAN dataset, we achieve a state-of-the-art AUC score of 0.85.
Offline Learning of Closed-Loop Deep Brain Stimulation Controllers for Parkinson Disease Treatment
Feb 09, 2023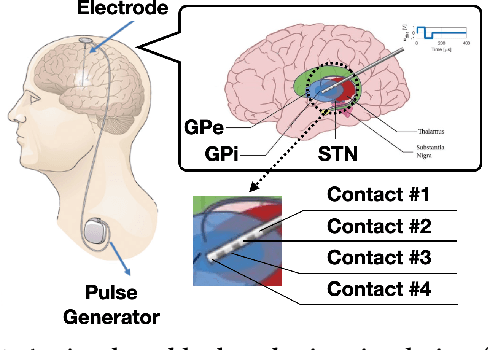
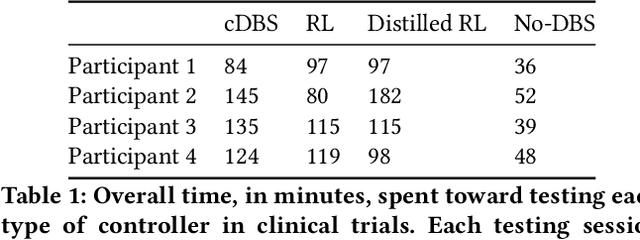
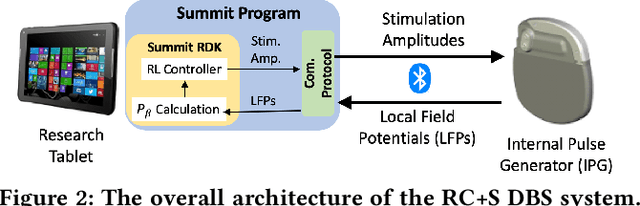

Deep brain stimulation (DBS) has shown great promise toward treating motor symptoms caused by Parkinson's disease (PD), by delivering electrical pulses to the Basal Ganglia (BG) region of the brain. However, DBS devices approved by the U.S. Food and Drug Administration (FDA) can only deliver continuous DBS (cDBS) stimuli at a fixed amplitude; this energy inefficient operation reduces battery lifetime of the device, cannot adapt treatment dynamically for activity, and may cause significant side-effects (e.g., gait impairment). In this work, we introduce an offline reinforcement learning (RL) framework, allowing the use of past clinical data to train an RL policy to adjust the stimulation amplitude in real time, with the goal of reducing energy use while maintaining the same level of treatment (i.e., control) efficacy as cDBS. Moreover, clinical protocols require the safety and performance of such RL controllers to be demonstrated ahead of deployments in patients. Thus, we also introduce an offline policy evaluation (OPE) method to estimate the performance of RL policies using historical data, before deploying them on patients. We evaluated our framework on four PD patients equipped with the RC+S DBS system, employing the RL controllers during monthly clinical visits, with the overall control efficacy evaluated by severity of symptoms (i.e., bradykinesia and tremor), changes in PD biomakers (i.e., local field potentials), and patient ratings. The results from clinical experiments show that our RL-based controller maintains the same level of control efficacy as cDBS, but with significantly reduced stimulation energy. Further, the OPE method is shown effective in accurately estimating and ranking the expected returns of RL controllers.
Bilevel Optimization for Just-in-Time Robotic Kitting and Delivery via Adaptive Task Segmentation and Scheduling
Sep 17, 2022
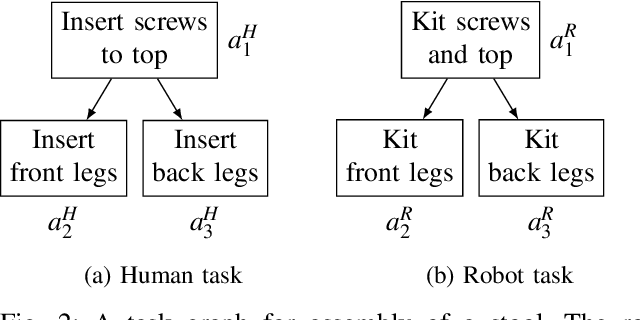
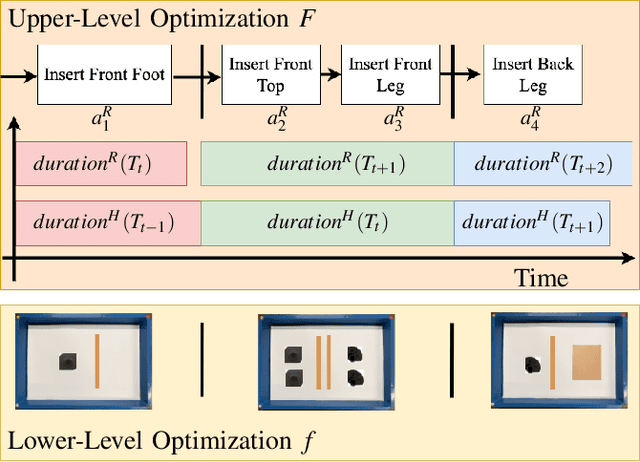

Kitting refers to the task of preparing and grouping necessary parts and tools (or "kits") for assembly in a manufacturing environment. Automating this process simplifies the assembly task for human workers and improves efficiency. Existing automated kitting systems adhere to scripted instructions and predefined heuristics. However, given variability in the availability of parts and logistic delays, the inflexibility of existing systems can limit the overall efficiency of an assembly line. In this paper, we propose a bilevel optimization framework to enable a robot to perform task segmentation-based part selection, kit arrangement, and delivery scheduling to provide custom-tailored kits just in time - i.e., right when they are needed. We evaluate the proposed approach both through a human subjects study (n=18) involving the construction of a flat-pack furniture table and shop-flow simulation based on the data from the study. Our results show that the just-in-time kitting system is objectively more efficient, resilient to upstream shop flow delays, and subjectively more preferable as compared to baseline approaches of using kits defined by rigid task segmentation boundaries defined by the task graph itself or a single kit that includes all parts necessary to assemble a single unit.