 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Better by you, better than me, chatgpt3 as writing assistance in students essays
Feb 09, 2023
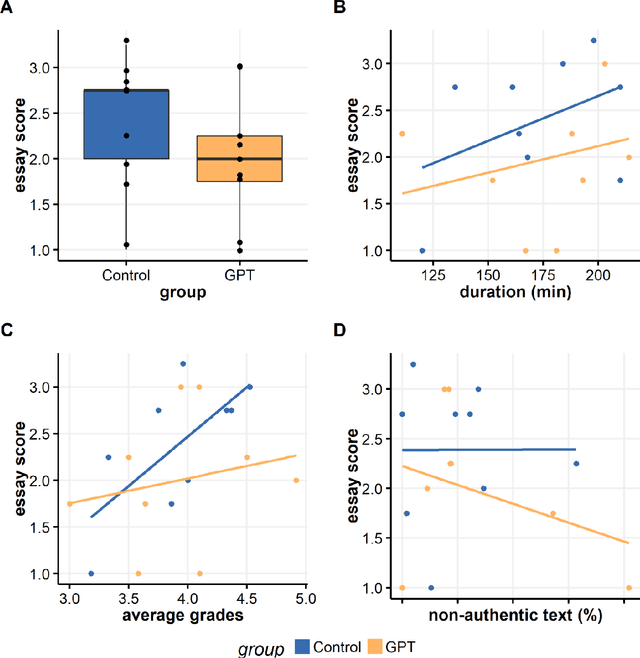
Aim: To compare students' essay writing performance with or without employing ChatGPT-3 as a writing assistant tool. Materials and methods: Eighteen students participated in the study (nine in control and nine in the experimental group that used ChatGPT-3). We scored essay elements with grades (A-D) and corresponding numerical values (4-1). We compared essay scores to students' GPTs, writing time, authenticity, and content similarity. Results: Average grade was C for both groups; for control (2.39, SD=0.71) and for experimental (2.00, SD=0.73). None of the predictors affected essay scores: group (P=0.184), writing duration (P=0.669), module (P=0.388), and GPA (P=0.532). The text unauthenticity was slightly higher in the experimental group (11.87%, SD=13.45 to 9.96%, SD=9.81%), but the similarity among essays was generally low in the overall sample (the Jaccard similarity index ranging from 0 to 0.054). In the experimental group, AI classifier recognized more potential AI-generated texts. Conclusions: This study found no evidence that using GPT as a writing tool improves essay quality since the control group outperformed the experimental group in most parameters.
Representation biases in sentence transformers
Jan 30, 2023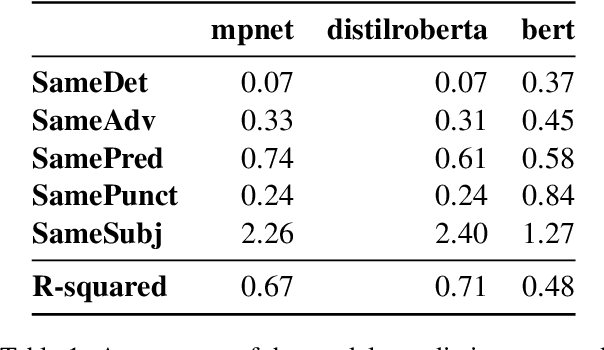
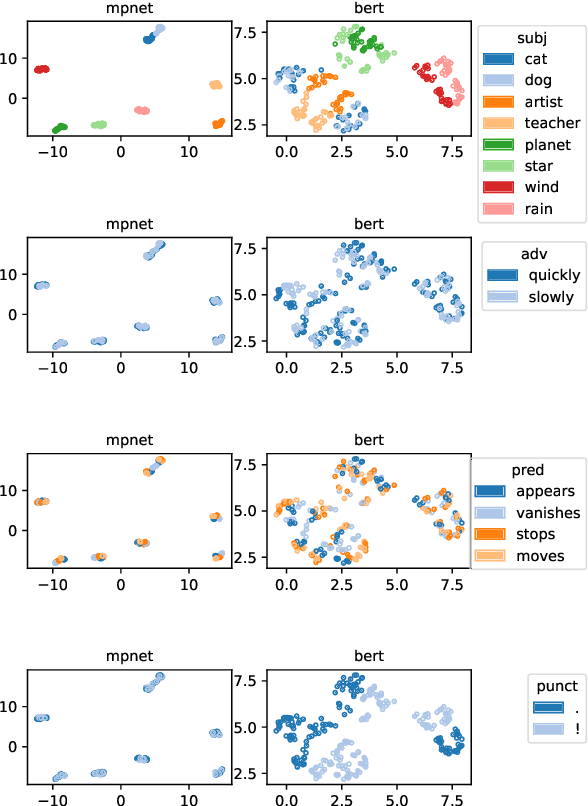
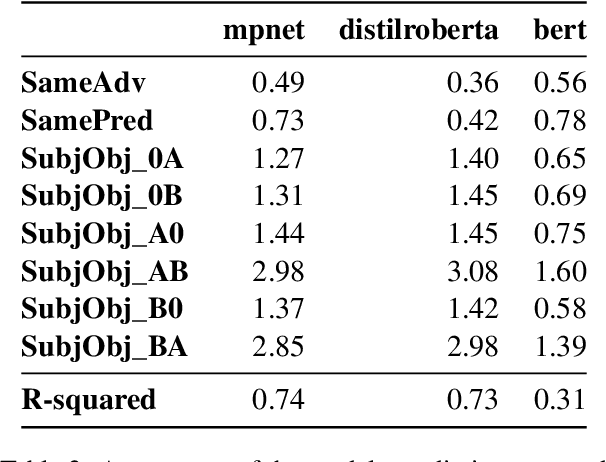
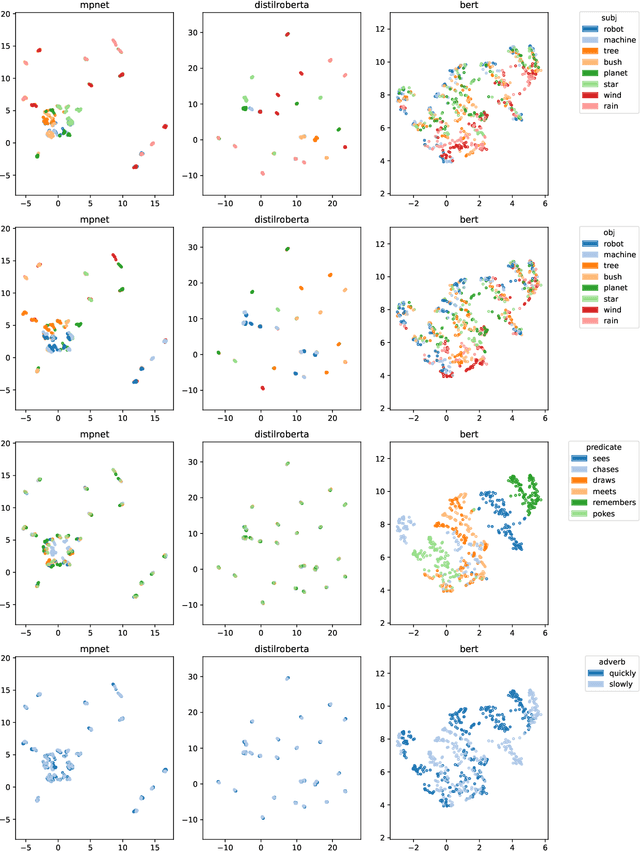
Variants of the BERT architecture specialised for producing full-sentence representations often achieve better performance on downstream tasks than sentence embeddings extracted from vanilla BERT. However, there is still little understanding of what properties of inputs determine the properties of such representations. In this study, we construct several sets of sentences with pre-defined lexical and syntactic structures and show that SOTA sentence transformers have a strong nominal-participant-set bias: cosine similarities between pairs of sentences are more strongly determined by the overlap in the set of their noun participants than by having the same predicates, lengthy nominal modifiers, or adjuncts. At the same time, the precise syntactic-thematic functions of the participants are largely irrelevant.
Learning the Kalman Filter with Fine-Grained Sample Complexity
Jan 30, 2023
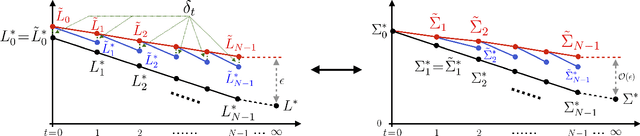
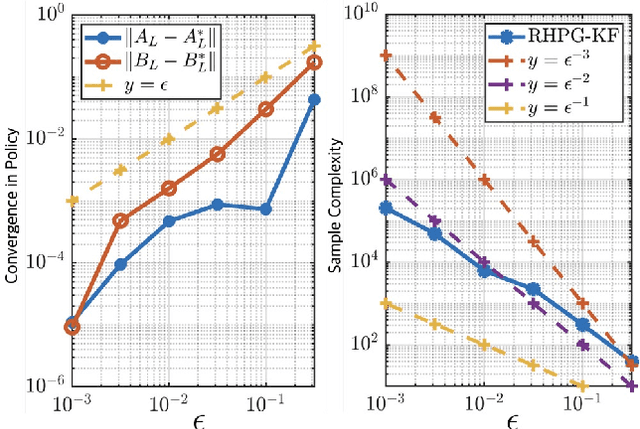
We develop the first end-to-end sample complexity of model-free policy gradient (PG) methods in discrete-time infinite-horizon Kalman filtering. Specifically, we introduce the receding-horizon policy gradient (RHPG-KF) framework and demonstrate $\tilde{\mathcal{O}}(\epsilon^{-2})$ sample complexity for RHPG-KF in learning a stabilizing filter that is $\epsilon$-close to the optimal Kalman filter. Notably, the proposed RHPG-KF framework does not require the system to be open-loop stable nor assume any prior knowledge of a stabilizing filter. Our results shed light on applying model-free PG methods to control a linear dynamical system where the state measurements could be corrupted by statistical noises and other (possibly adversarial) disturbances.
BSA-OMP: Beam-Split-Aware Orthogonal Matching Pursuit for THz Channel Estimation
Feb 05, 2023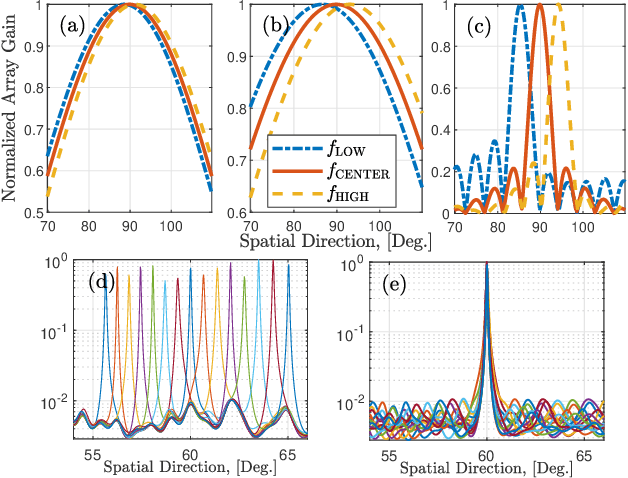
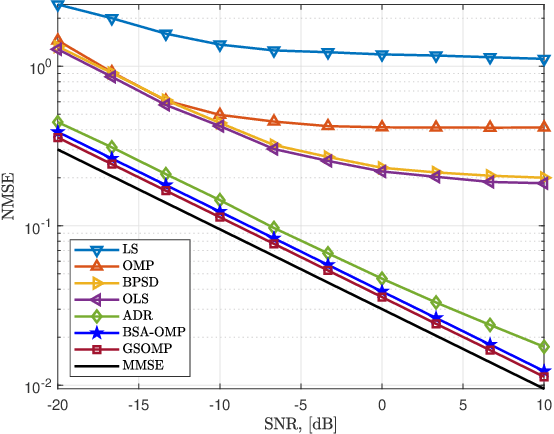
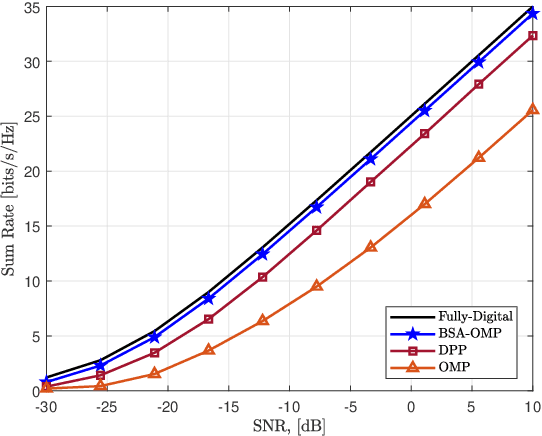
Terahertz (THz)-band has been envisioned for the sixth generation wireless networks thanks to its ultra-wide bandwidth and very narrow beamwidth. Nevertheless, THz-band transmission faces several unique challenges, one of which is beam-split which occurs due to the usage of subcarrier-independent analog beamformers and causes the generated beams at different subcarriers split, and point to different directions. Unlike the prior works dealing with beam-split by employing additional complex hardware components, e.g., time-delayer networks, a beam-split-aware orthogonal matching pursuit (BSA-OMP) approach is introduced to efficiently estimate the THz channel and beamformer design without any additional hardware. Specifically, we design a BSA dictionary comprised of beam-split-corrected steering vectors which inherently include the effect of beam-split so that the proposed BSA-OMP solution automatically yields the beam-split-corrected physical channel directions. Numerical results demonstrate the superior performance of BSA-OMP approach against the existing state-of-the-art techniques.
Machine Learning Methods for Evaluating Public Crisis: Meta-Analysis
Feb 05, 2023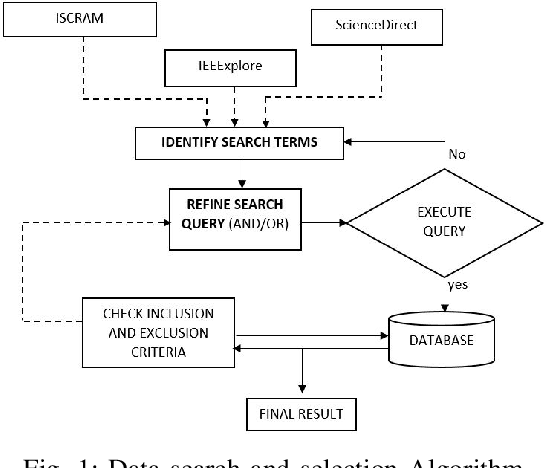
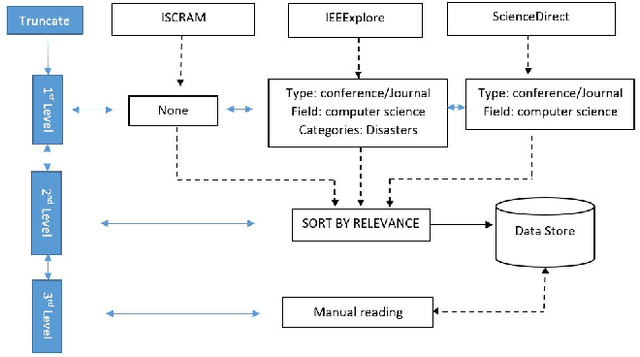
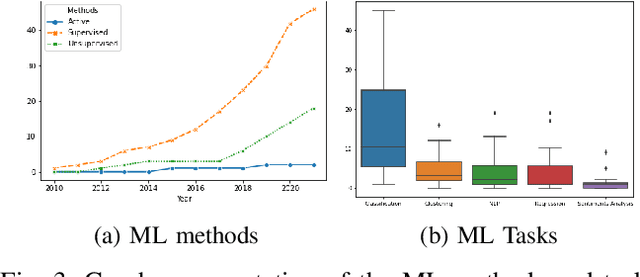
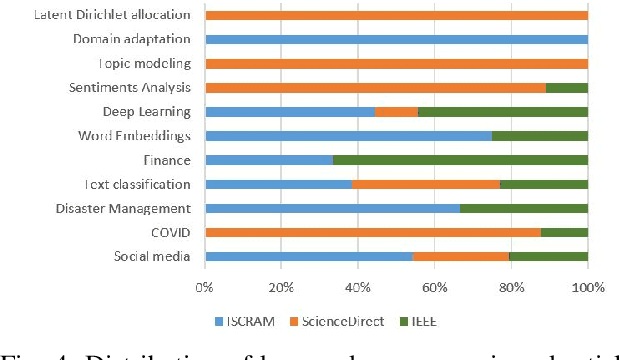
This study examines machine learning methods used in crisis management. Analyzing detected patterns from a crisis involves the collection and evaluation of historical or near-real-time datasets through automated means. This paper utilized the meta-review method to analyze scientific literature that utilized machine learning techniques to evaluate human actions during crises. Selected studies were condensed into themes and emerging trends using a systematic literature evaluation of published works accessed from three scholarly databases. Results show that data from social media was prominent in the evaluated articles with 27% usage, followed by disaster management, health (COVID) and crisis informatics, amongst many other themes. Additionally, the supervised machine learning method, with an application of 69% across the board, was predominant. The classification technique stood out among other machine learning tasks with 41% usage. The algorithms that played major roles were the Support Vector Machine, Neural Networks, Naive Bayes, and Random Forest, with 23%, 16%, 15%, and 12% contributions, respectively.
Improved High-Probability Regret for Adversarial Bandits with Time-Varying Feedback Graphs
Oct 04, 2022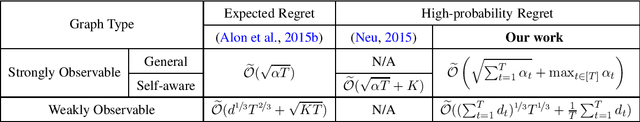
We study high-probability regret bounds for adversarial $K$-armed bandits with time-varying feedback graphs over $T$ rounds. For general strongly observable graphs, we develop an algorithm that achieves the optimal regret $\widetilde{\mathcal{O}}((\sum_{t=1}^T\alpha_t)^{1/2}+\max_{t\in[T]}\alpha_t)$ with high probability, where $\alpha_t$ is the independence number of the feedback graph at round $t$. Compared to the best existing result [Neu, 2015] which only considers graphs with self-loops for all nodes, our result not only holds more generally, but importantly also removes any $\text{poly}(K)$ dependence that can be prohibitively large for applications such as contextual bandits. Furthermore, we also develop the first algorithm that achieves the optimal high-probability regret bound for weakly observable graphs, which even improves the best expected regret bound of [Alon et al., 2015] by removing the $\mathcal{O}(\sqrt{KT})$ term with a refined analysis. Our algorithms are based on the online mirror descent framework, but importantly with an innovative combination of several techniques. Notably, while earlier works use optimistic biased loss estimators for achieving high-probability bounds, we find it important to use a pessimistic one for nodes without self-loop in a strongly observable graph.
Standing Between Past and Future: Spatio-Temporal Modeling for Multi-Camera 3D Multi-Object Tracking
Feb 07, 2023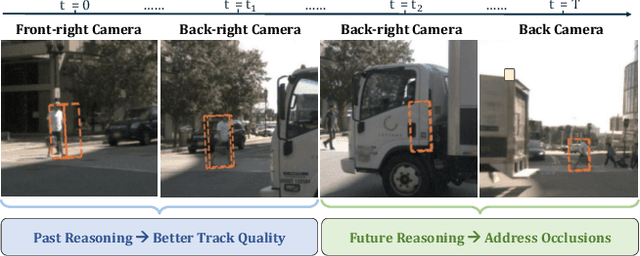
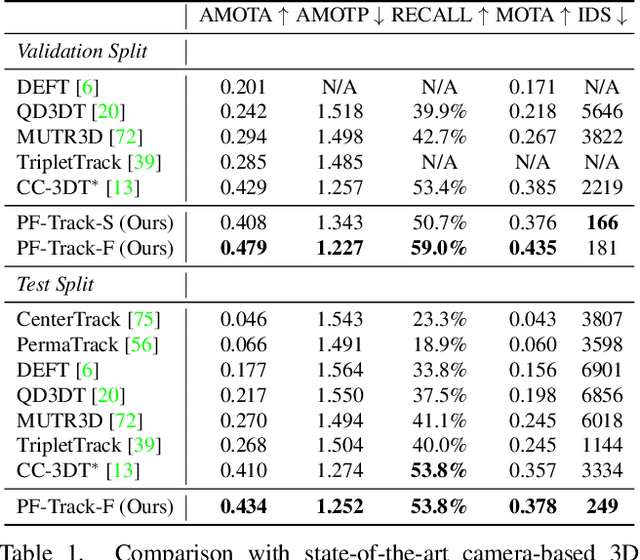
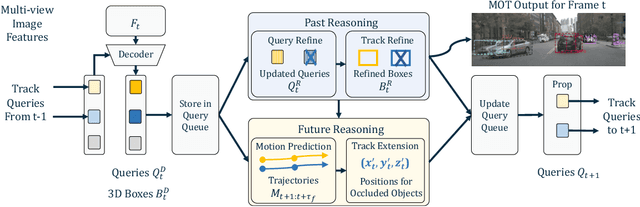
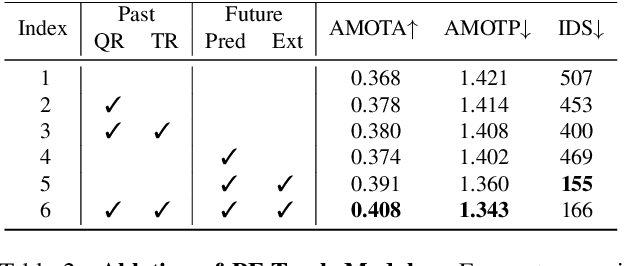
This work proposes an end-to-end multi-camera 3D multi-object tracking (MOT) framework. It emphasizes spatio-temporal continuity and integrates both past and future reasoning for tracked objects. Thus, we name it "Past-and-Future reasoning for Tracking" (PF-Track). Specifically, our method adapts the "tracking by attention" framework and represents tracked instances coherently over time with object queries. To explicitly use historical cues, our "Past Reasoning" module learns to refine the tracks and enhance the object features by cross-attending to queries from previous frames and other objects. The "Future Reasoning" module digests historical information and predicts robust future trajectories. In the case of long-term occlusions, our method maintains the object positions and enables re-association by integrating motion predictions. On the nuScenes dataset, our method improves AMOTA by a large margin and remarkably reduces ID-Switches by 90% compared to prior approaches, which is an order of magnitude less. The code and models are made available at https://github.com/TRI-ML/PF-Track.
NeSe: Near-Sensor Event-Driven Scheme for Low Power Energy Harvesting Sensors
Feb 07, 2023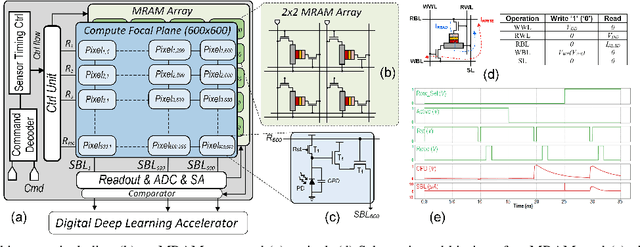
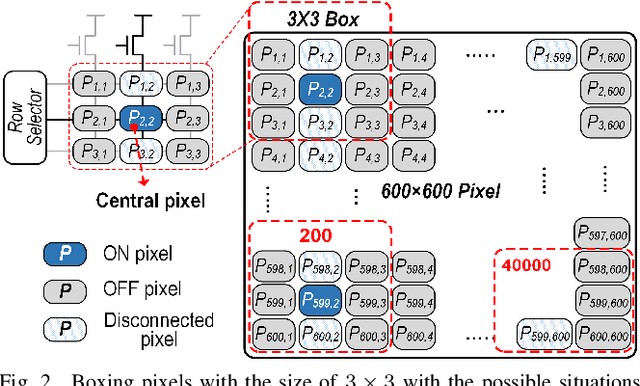


Digital technologies have made it possible to deploy visual sensor nodes capable of detecting motion events in the coverage area cost-effectively. However, background subtraction, as a widely used approach, remains an intractable task due to its inability to achieve competitive accuracy and reduced computation cost simultaneously. In this paper, an effective background subtraction approach, namely NeSe, for tiny energy-harvested sensors is proposed leveraging non-volatile memory (NVM). Using the developed software/hardware method, the accuracy and efficiency of event detection can be adjusted at runtime by changing the precision depending on the application's needs. Due to the near-sensor implementation of background subtraction and NVM usage, the proposed design reduces the data movement overhead while ensuring intermittent resiliency. The background is stored for a specific time interval within NVMs and compared with the next frame. If the power is cut, the background remains unchanged and is updated after the interval passes. Once the moving object is detected, the device switches to the high-powered sensor mode to capture the image.
Identification of Power System Oscillation Modes using Blind Source Separation based on Copula Statistic
Feb 07, 2023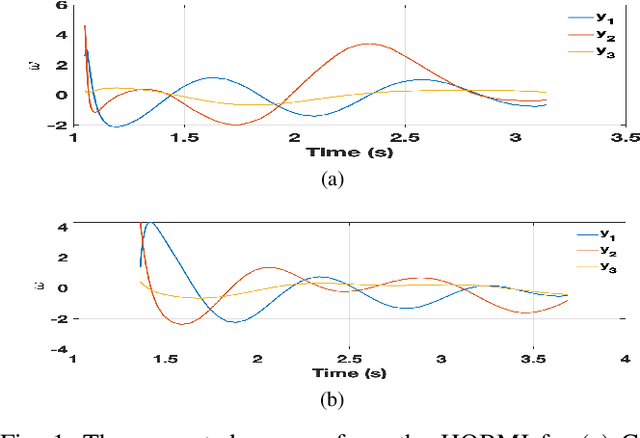
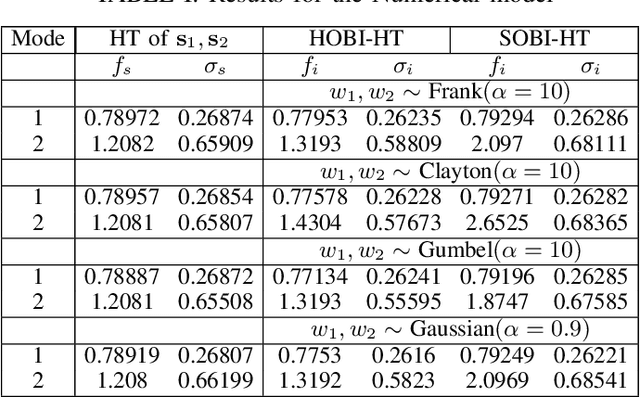
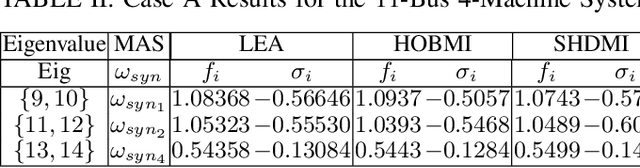
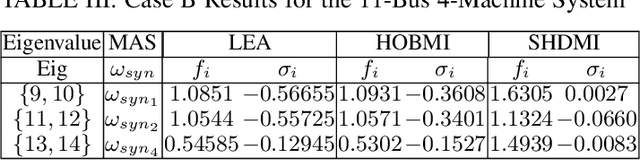
The dynamics of a power system with large penetration of renewable energy resources are becoming more nonlinear due to the intermittence of these resources and the switching of their power electronic devices. Therefore, it is crucial to accurately identify the dynamical modes of oscillation of such a power system when it is subject to disturbances to initiate appropriate preventive or corrective control actions. In this paper, we propose a high-order blind source identification (HOBI) algorithm based on the copula statistic to address these non-linear dynamics in modal analysis. The method combined with Hilbert transform (HOBI-HT) and iteration procedure (HOBMI) can identify all the modes as well as the model order from the observation signals obtained from the number of channels as low as one. We access the performance of the proposed method on numerical simulation signals and recorded data from a simulation of time domain analysis on the classical 11-Bus 4-Machine test system. Our simulation results outperform the state-of-the-art method in accuracy and effectiveness.
Open Set Wireless Signal Classification: Augmenting Deep Learning with Expert Feature Classifiers
Feb 07, 2023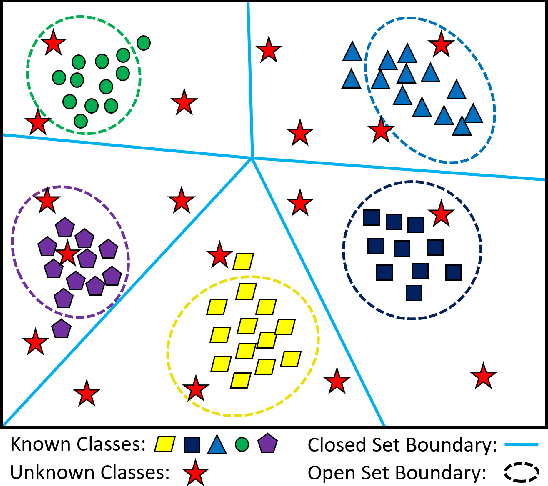
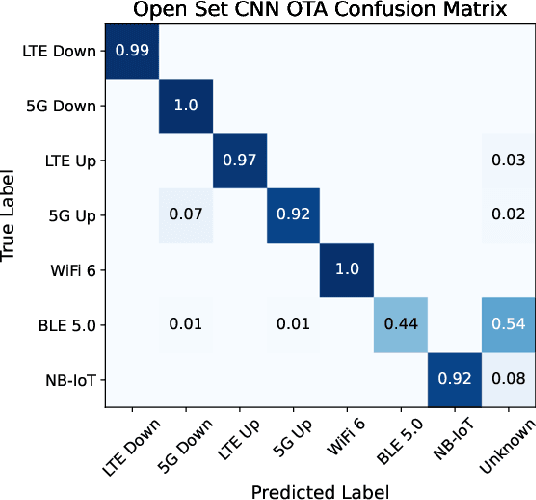
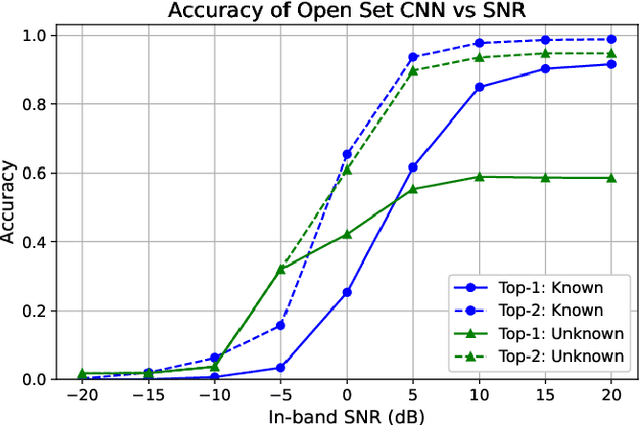
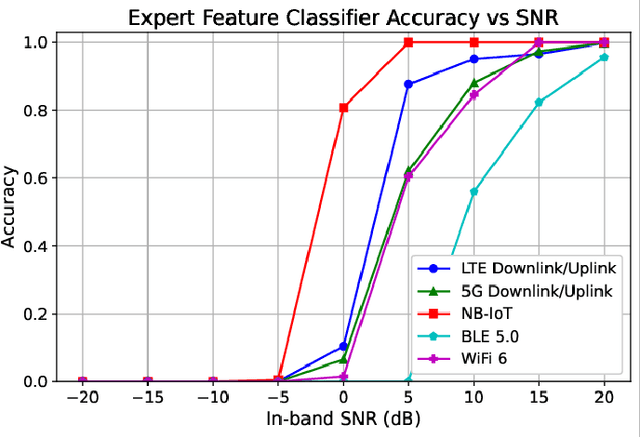
In shared spectrum with multiple radio access technologies, wireless standard classification is vital for applications such as dynamic spectrum access (DSA) and wideband spectrum monitoring. However, interfering signals and the presence of unknown classes of signals can diminish classification accuracy. To reduce interference, signals can be isolated in time, frequency, and space, but the isolation process adds distortion that reduces the accuracy of deep learning classifiers. We find that the distortion can be partially mitigated by augmenting the classifier training data with the signal isolation steps. To address unknown signals, we propose an open set hybrid classifier, which combines deep learning and expert feature classifiers to leverage the reliability and explainability of expert feature classifiers and the lower computational complexity of deep learning classifiers. The hybrid classifier reduces the computational complexity by 2 to 7 times on average compared to the expert feature classifiers, while achieving an accuracy of 95% at 15 dB SNR for known signal classes. The hybrid classifier manages to detect unknown classes at nearly 100% accuracy, due to the robustness of the expert feature classifiers.