 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning For Classification Of Chest X-Ray Images (Covid 19)
Jan 06, 2023
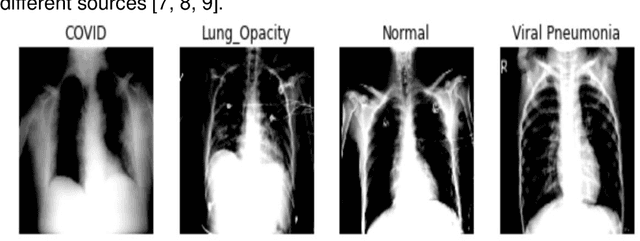
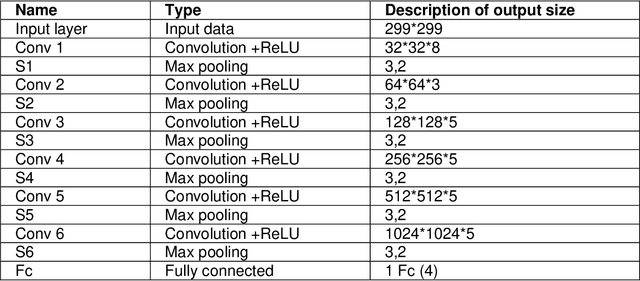
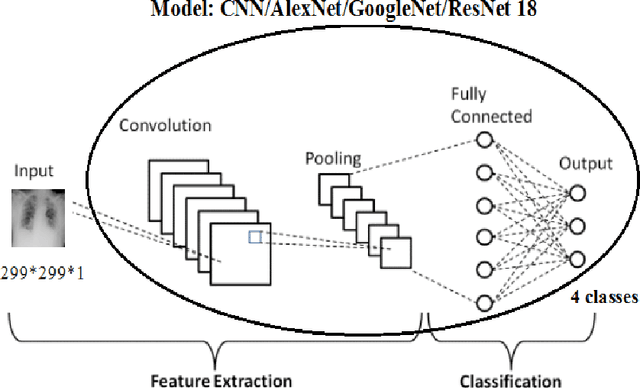
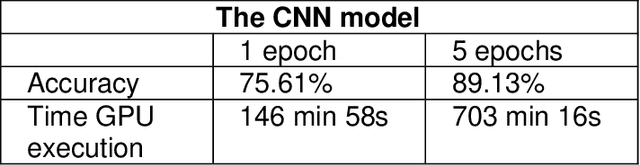
In medical practice, the contribution of information technology can be considerable. Most of these practices include the images that medical assistance uses to identify different pathologies of the human body. One of them is X-ray images which cover much of our work in this paper. Chest x-rays have played an important role in Covid 19 identification and diagnosis. The Covid 19 virus has been declared a global pandemic since 2020 after the first case found in Wuhan China in December 2019. Our goal in this project is to be able to classify different chest X-ray images containing Covid 19, viral pneumonia, lung opacity and normal images. We used CNN architecture and different pre-trained models. The best result is obtained by the use of the ResNet 18 architecture with 94.1% accuracy. We also note that The GPU execution time is optimal in the case of AlexNet but what requires our attention is that the pretrained models converge much faster than the CNN. The time saving is very considerable. With these results not only will solve the diagnosis time for patients, but will provide an interesting tool for practitioners, thus helping them in times of strong pandemic in particular.
Statistical Analysis of Time-Frequency Features Based On Multivariate Synchrosqueezing Transform for Hand Gesture Classification
Sep 24, 2022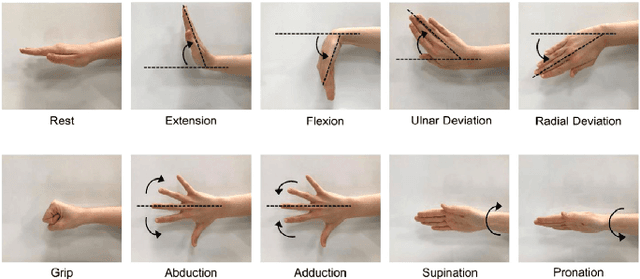
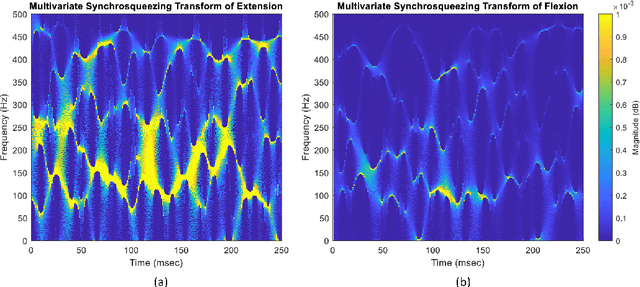
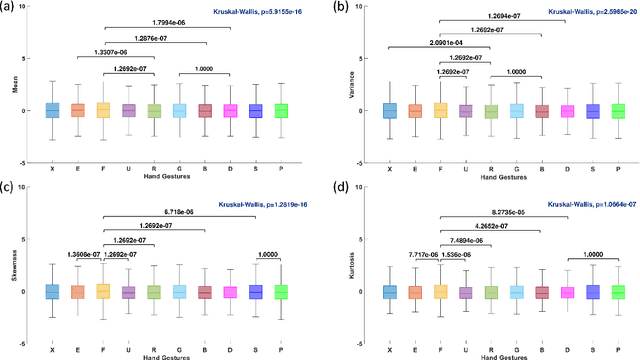
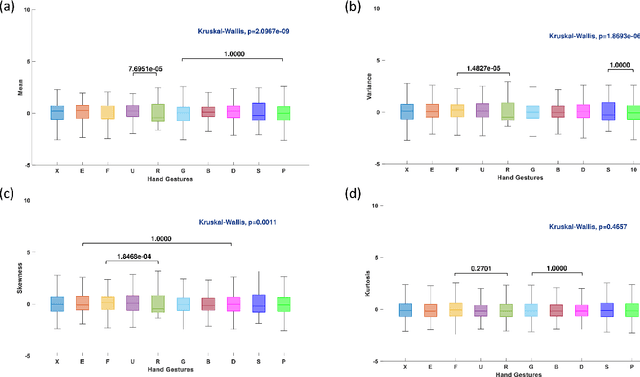
In this study, the four joint time-frequency (TF) moments; mean, variance, skewness, and kurtosis of TF matrix obtained from Multivariate Synchrosqueezing Transform (MSST) are proposed as features for hand gesture recognition. A publicly available dataset containing surface EMG (sEMG) signals of 40 subjects performing 10 hand gestures, was used. The distinguishing power of the feature variables for the tested gestures was evaluated according to their p values obtained from the Kruskal-Wallis (KW) test. It is concluded that the mean, variance, skewness, and kurtosis of TF matrices can be candidate feature sets for the recognition of hand gestures.
* Conference Paper, 5 pages, Translated Title (TR): El Hareketi Siniflandirmasi icin Cok-Degiskenli Senkrosikistirma Donusumune Dayali Zaman-Frekans Ozniteliklerinin Istatistiksel Analizi Proceedings: https://www.tipcih.com/books/ICMD2022_Proceedings-DRAFT.pdf Website: https://www.tipcih.com/
Geometry of contact: contact planning for multi-legged robots via spin models duality
Feb 07, 2023
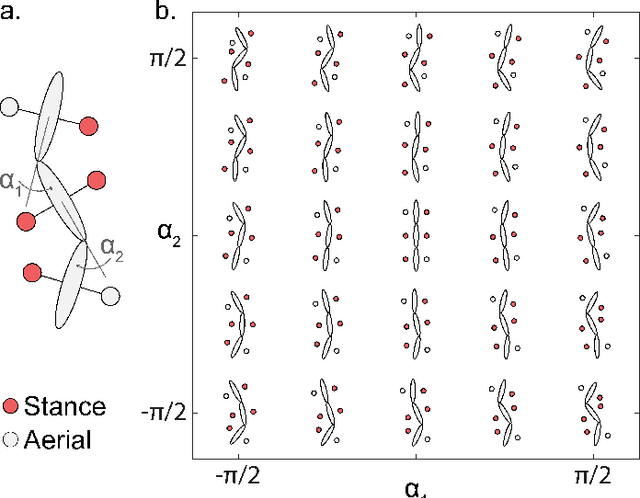
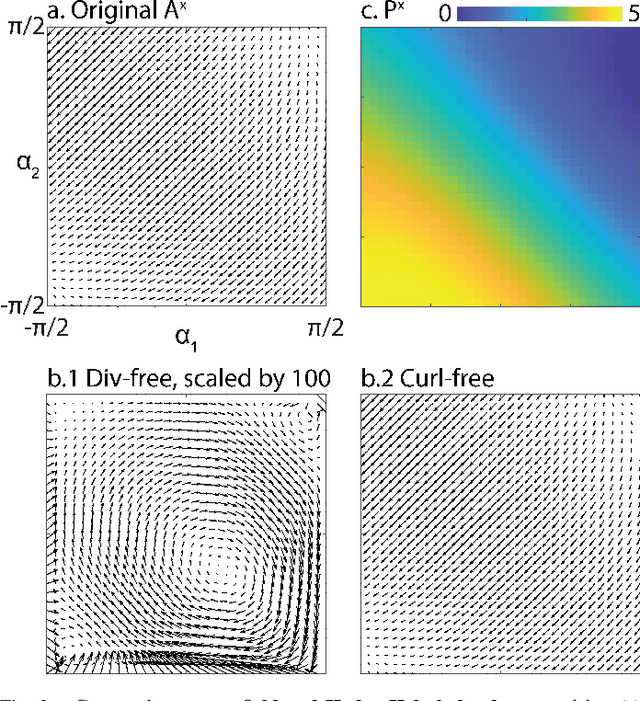
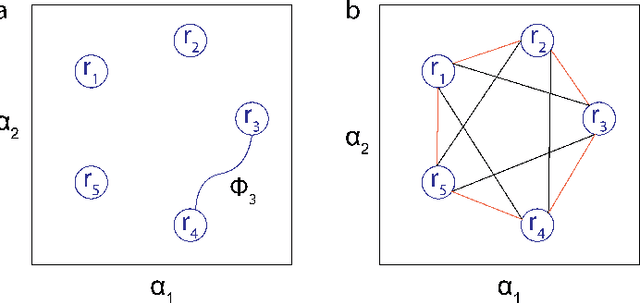
Contact planning is crucial in locomoting systems.Specifically, appropriate contact planning can enable versatile behaviors (e.g., sidewinding in limbless locomotors) and facilitate speed-dependent gait transitions (e.g., walk-trot-gallop in quadrupedal locomotors). The challenges of contact planning include determining not only the sequence by which contact is made and broken between the locomotor and the environments, but also the sequence of internal shape changes (e.g., body bending and limb shoulder joint oscillation). Most state-of-art contact planning algorithms focused on conventional robots (e.g.biped and quadruped) and conventional tasks (e.g. forward locomotion), and there is a lack of study on general contact planning in multi-legged robots. In this paper, we show that using geometric mechanics framework, we can obtain the global optimal contact sequence given the internal shape changes sequence. Therefore, we simplify the contact planning problem to a graph optimization problem to identify the internal shape changes. Taking advantages of the spatio-temporal symmetry in locomotion, we map the graph optimization problem to special cases of spin models, which allows us to obtain the global optima in polynomial time. We apply our approach to develop new forward and sidewinding behaviors in a hexapod and a 12-legged centipede. We verify our predictions using numerical and robophysical models, and obtain novel and effective locomotion behaviors.
Layered State Discovery for Incremental Autonomous Exploration
Feb 07, 2023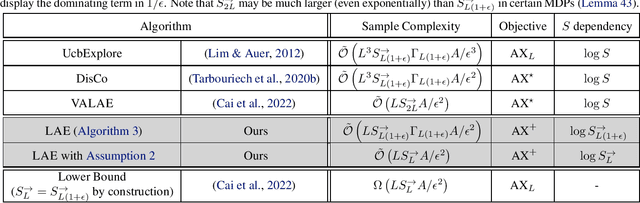

We study the autonomous exploration (AX) problem proposed by Lim & Auer (2012). In this setting, the objective is to discover a set of $\epsilon$-optimal policies reaching a set $\mathcal{S}_L^{\rightarrow}$ of incrementally $L$-controllable states. We introduce a novel layered decomposition of the set of incrementally $L$-controllable states that is based on the iterative application of a state-expansion operator. We leverage these results to design Layered Autonomous Exploration (LAE), a novel algorithm for AX that attains a sample complexity of $\tilde{\mathcal{O}}(LS^{\rightarrow}_{L(1+\epsilon)}\Gamma_{L(1+\epsilon)} A \ln^{12}(S^{\rightarrow}_{L(1+\epsilon)})/\epsilon^2)$, where $S^{\rightarrow}_{L(1+\epsilon)}$ is the number of states that are incrementally $L(1+\epsilon)$-controllable, $A$ is the number of actions, and $\Gamma_{L(1+\epsilon)}$ is the branching factor of the transitions over such states. LAE improves over the algorithm of Tarbouriech et al. (2020a) by a factor of $L^2$ and it is the first algorithm for AX that works in a countably-infinite state space. Moreover, we show that, under a certain identifiability assumption, LAE achieves minimax-optimal sample complexity of $\tilde{\mathcal{O}}(LS^{\rightarrow}_{L}A\ln^{12}(S^{\rightarrow}_{L})/\epsilon^2)$, outperforming existing algorithms and matching for the first time the lower bound proved by Cai et al. (2022) up to logarithmic factors.
Transfer learning for process design with reinforcement learning
Feb 07, 2023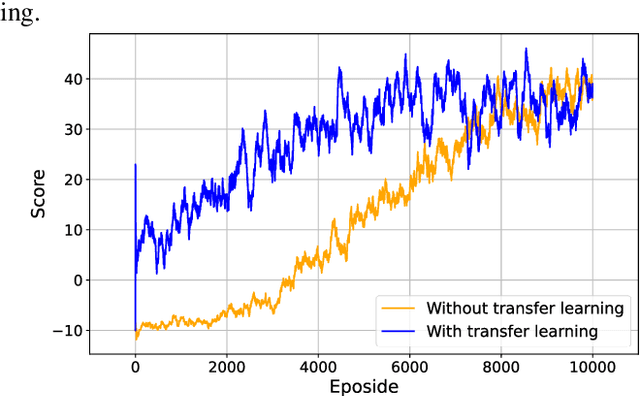

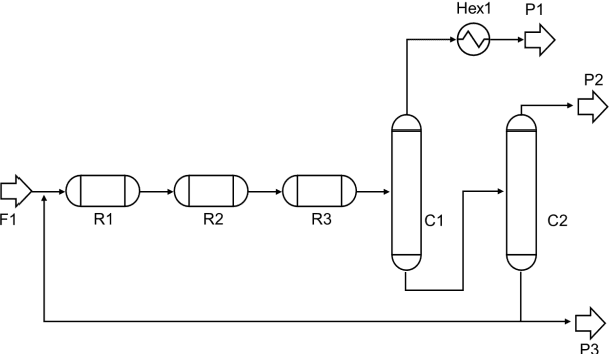
Process design is a creative task that is currently performed manually by engineers. Artificial intelligence provides new potential to facilitate process design. Specifically, reinforcement learning (RL) has shown some success in automating process design by integrating data-driven models that learn to build process flowsheets with process simulation in an iterative design process. However, one major challenge in the learning process is that the RL agent demands numerous process simulations in rigorous process simulators, thereby requiring long simulation times and expensive computational power. Therefore, typically short-cut simulation methods are employed to accelerate the learning process. Short-cut methods can, however, lead to inaccurate results. We thus propose to utilize transfer learning for process design with RL in combination with rigorous simulation methods. Transfer learning is an established approach from machine learning that stores knowledge gained while solving one problem and reuses this information on a different target domain. We integrate transfer learning in our RL framework for process design and apply it to an illustrative case study comprising equilibrium reactions, azeotropic separation, and recycles, our method can design economically feasible flowsheets with stable interaction with DWSIM. Our results show that transfer learning enables RL to economically design feasible flowsheets with DWSIM, resulting in a flowsheet with an 8% higher revenue. And the learning time can be reduced by a factor of 2.
Scalable Gaussian process regression enables accurate prediction of protein and small molecule properties with uncertainty quantitation
Feb 07, 2023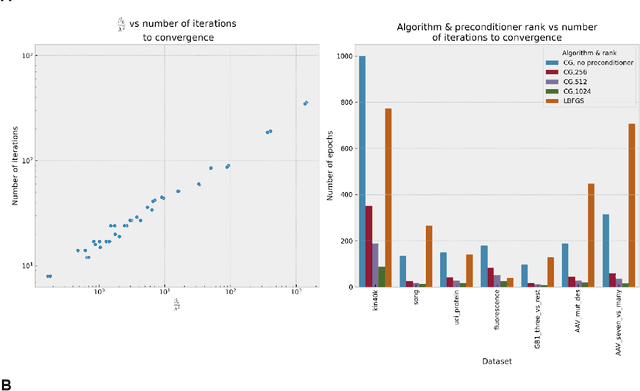
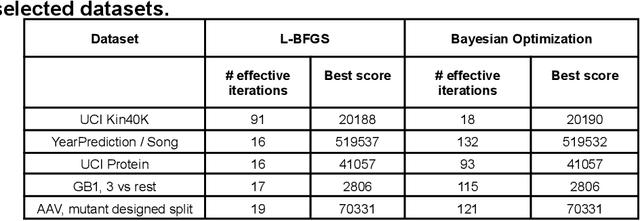
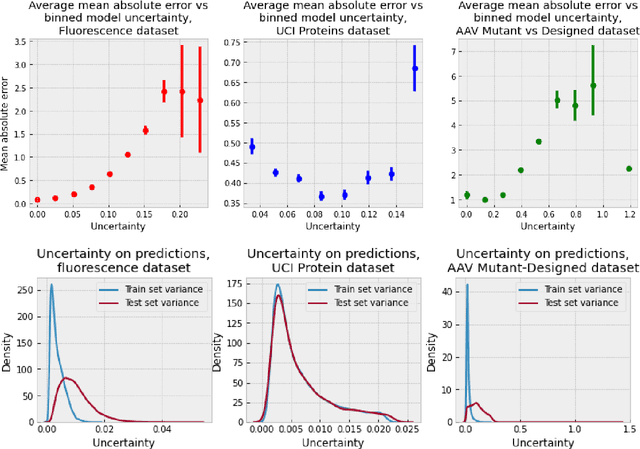
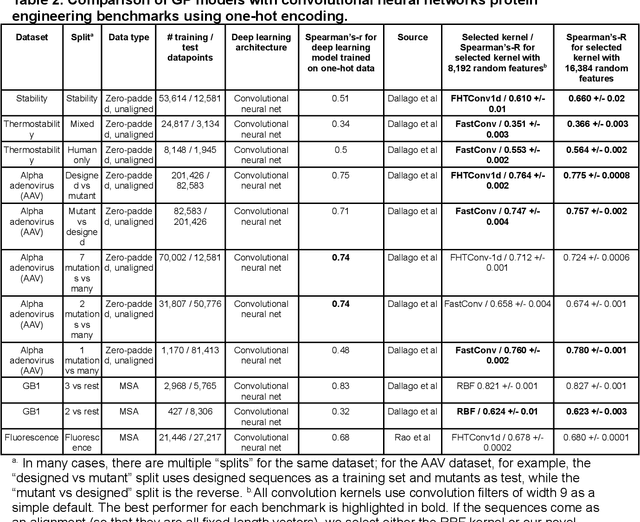
Gaussian process (GP) is a Bayesian model which provides several advantages for regression tasks in machine learning such as reliable quantitation of uncertainty and improved interpretability. Their adoption has been precluded by their excessive computational cost and by the difficulty in adapting them for analyzing sequences (e.g. amino acid and nucleotide sequences) and graphs (e.g. ones representing small molecules). In this study, we develop efficient and scalable approaches for fitting GP models as well as fast convolution kernels which scale linearly with graph or sequence size. We implement these improvements by building an open-source Python library called xGPR. We compare the performance of xGPR with the reported performance of various deep learning models on 20 benchmarks, including small molecule, protein sequence and tabular data. We show that xGRP achieves highly competitive performance with much shorter training time. Furthermore, we also develop new kernels for sequence and graph data and show that xGPR generally outperforms convolutional neural networks on predicting key properties of proteins and small molecules. Importantly, xGPR provides uncertainty information not available from typical deep learning models. Additionally, xGPR provides a representation of the input data that can be used for clustering and data visualization. These results demonstrate that xGPR provides a powerful and generic tool that can be broadly useful in protein engineering and drug discovery.
Two-step interpretable modeling of Intensive Care Acquired Infections
Jan 26, 2023
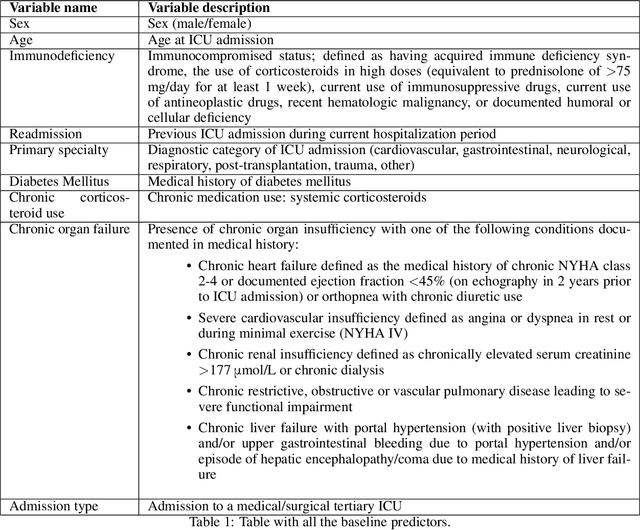
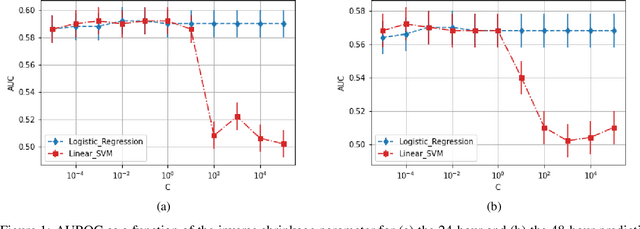
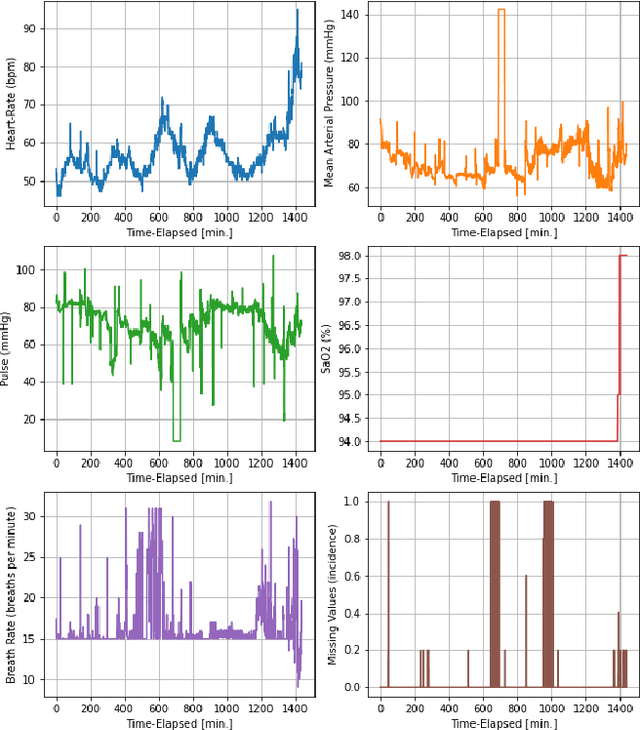
We present a novel methodology for integrating high resolution longitudinal data with the dynamic prediction capabilities of survival models. The aim is two-fold: to improve the predictive power while maintaining interpretability of the models. To go beyond the black box paradigm of artificial neural networks, we propose a parsimonious and robust semi-parametric approach (i.e., a landmarking competing risks model) that combines routinely collected low-resolution data with predictive features extracted from a convolutional neural network, that was trained on high resolution time-dependent information. We then use saliency maps to analyze and explain the extra predictive power of this model. To illustrate our methodology, we focus on healthcare-associated infections in patients admitted to an intensive care unit.
On the challenges to learn from Natural Data Streams
Jan 09, 2023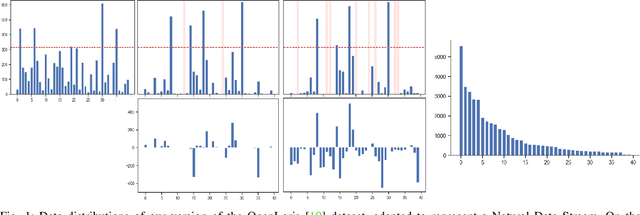
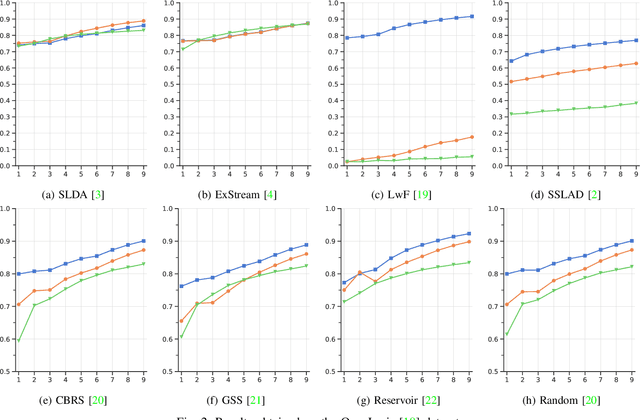
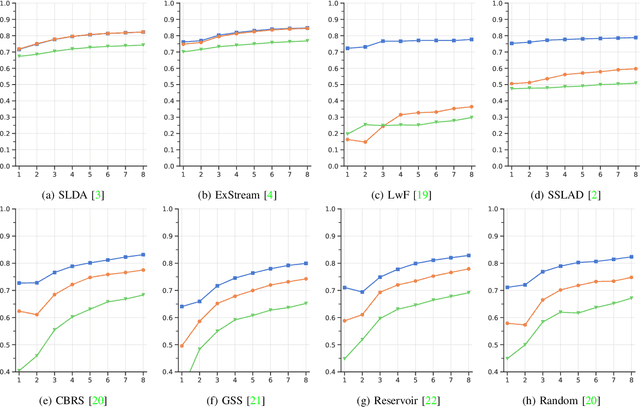
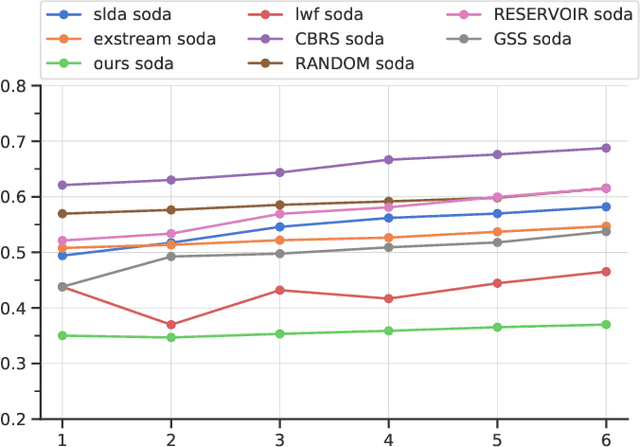
In real-world contexts, sometimes data are available in form of Natural Data Streams, i.e. data characterized by a streaming nature, unbalanced distribution, data drift over a long time frame and strong correlation of samples in short time ranges. Moreover, a clear separation between the traditional training and deployment phases is usually lacking. This data organization and fruition represents an interesting and challenging scenario for both traditional Machine and Deep Learning algorithms and incremental learning agents, i.e. agents that have the ability to incrementally improve their knowledge through the past experience. In this paper, we investigate the classification performance of a variety of algorithms that belong to various research field, i.e. Continual, Streaming and Online Learning, that receives as training input Natural Data Streams. The experimental validation is carried out on three different datasets, expressly organized to replicate this challenging setting.
Deep Contrastive One-Class Time Series Anomaly Detection
Jul 04, 2022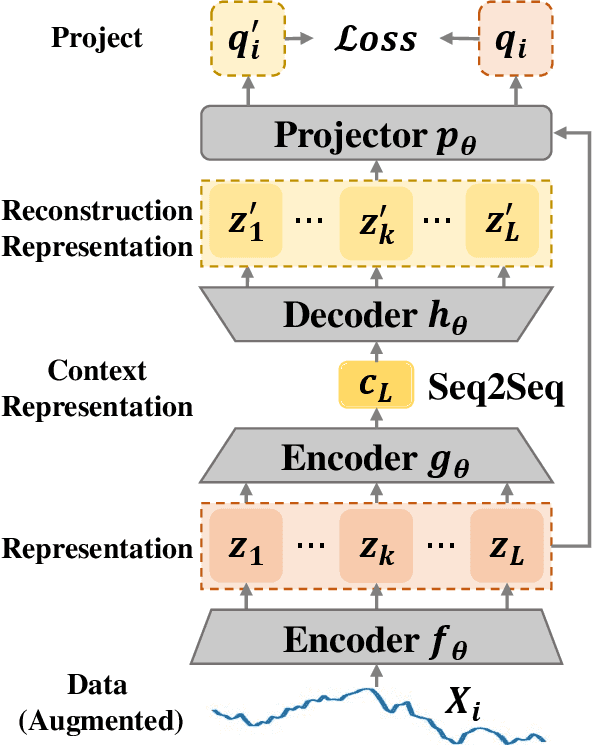
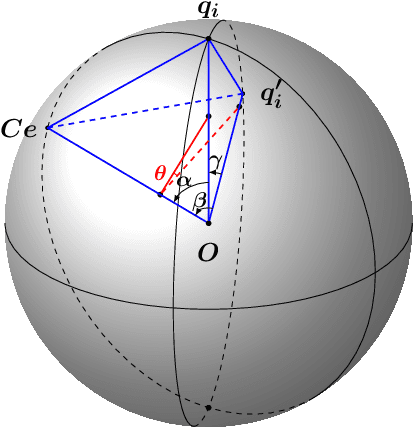
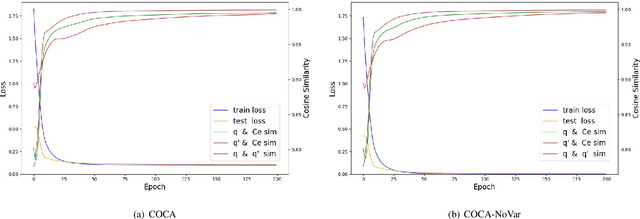
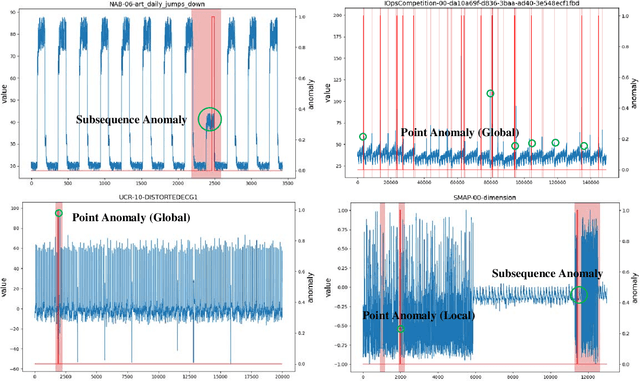
The accumulation of time series data and the absence of labels make time-series Anomaly Detection (AD) a self-supervised deep learning task. Single-assumption-based methods may only touch on a certain aspect of the whole normality, not sufficient to detect various anomalies. Among them, contrastive learning methods adopted for AD always choose negative pairs that are both normal to push away, which is objecting to AD tasks' purpose. Existing multi-assumption-based methods are usually two-staged, firstly applying a pre-training process whose target may differ from AD, so the performance is limited by the pre-trained representations. This paper proposes a deep Contrastive One-Class Anomaly detection method of time series (COCA), which combines the normality assumptions of contrastive learning and one-class classification. The key idea is to treat the representation and reconstructed representation as the positive pair of negative-samples-free contrastive learning, and we name it sequence contrast. Then we apply a contrastive one-class loss function composed of invariance and variance terms, the former optimizing loss of the two assumptions simultaneously, and the latter preventing hypersphere collapse. Extensive experiments conducted on four real-world time-series datasets show the superior performance of the proposed method achieves state-of-the-art. The code is publicly available at https://github.com/ruiking04/COCA.
NarrowBERT: Accelerating Masked Language Model Pretraining and Inference
Jan 11, 2023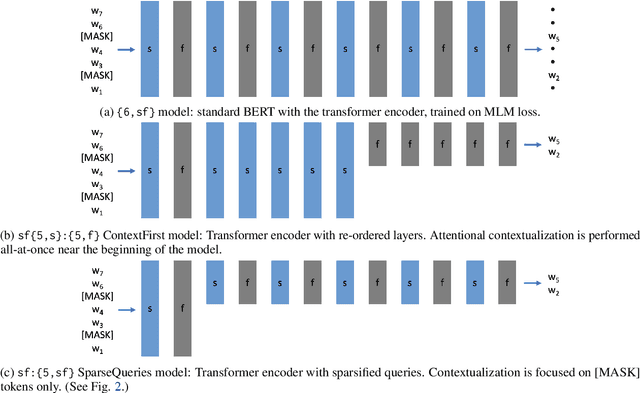
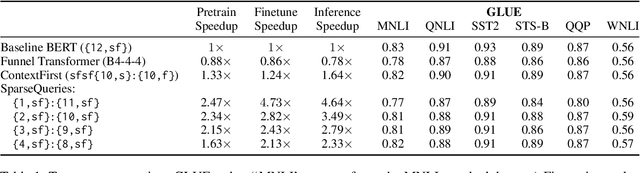
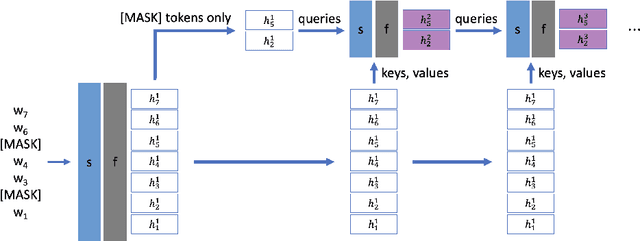
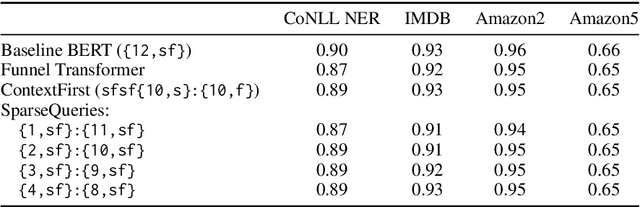
Large-scale language model pretraining is a very successful form of self-supervised learning in natural language processing, but it is increasingly expensive to perform as the models and pretraining corpora have become larger over time. We propose NarrowBERT, a modified transformer encoder that increases the throughput for masked language model pretraining by more than $2\times$. NarrowBERT sparsifies the transformer model such that the self-attention queries and feedforward layers only operate on the masked tokens of each sentence during pretraining, rather than all of the tokens as with the usual transformer encoder. We also show that NarrowBERT increases the throughput at inference time by as much as $3.5\times$ with minimal (or no) performance degradation on sentence encoding tasks like MNLI. Finally, we examine the performance of NarrowBERT on the IMDB and Amazon reviews classification and CoNLL NER tasks and show that it is also comparable to standard BERT performance.