 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Review and a Taxonomy of Edge Machine Learning: Requirements, Paradigms, and Techniques
Feb 16, 2023
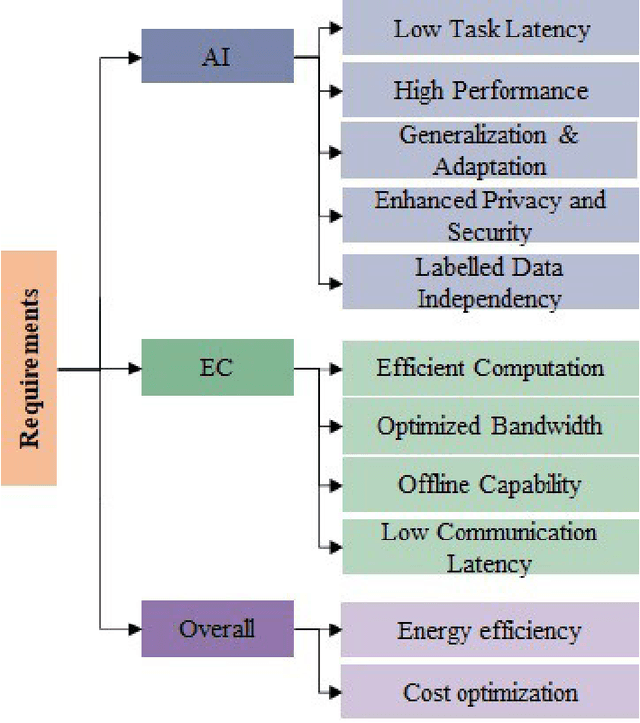
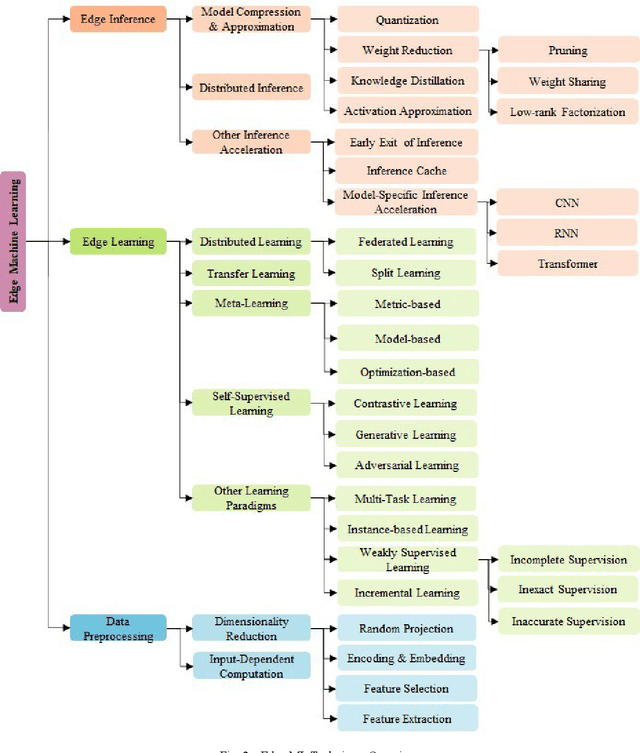
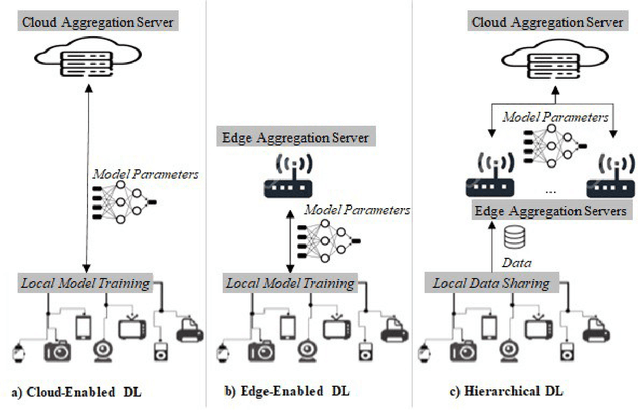
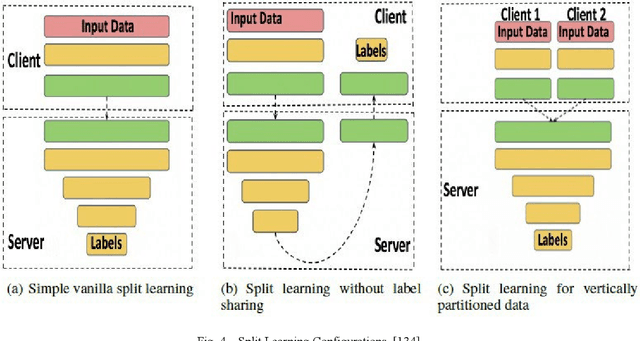
The union of Edge Computing (EC) and Artificial Intelligence (AI) has brought forward the Edge AI concept to provide intelligent solutions close to end-user environment, for privacy preservation, low latency to real-time performance, as well as resource optimization. Machine Learning (ML), as the most advanced branch of AI in the past few years, has shown encouraging results and applications in the edge environment. Nevertheless, edge powered ML solutions are more complex to realize due to the joint constraints from both edge computing and AI domains, and the corresponding solutions are expected to be efficient and adapted in technologies such as data processing, model compression, distributed inference, and advanced learning paradigms for Edge ML requirements. Despite that a great attention of Edge ML is gained in both academic and industrial communities, we noticed the lack of a complete survey on existing Edge ML technologies to provide a common understanding of this concept. To tackle this, this paper aims at providing a comprehensive taxonomy and a systematic review of Edge ML techniques: we start by identifying the Edge ML requirements driven by the joint constraints. We then survey more than twenty paradigms and techniques along with their representative work, covering two main parts: edge inference, and edge learning. In particular, we analyze how each technique fits into Edge ML by meeting a subset of the identified requirements. We also summarize Edge ML open issues to shed light on future directions for Edge ML.
Near Lossless Time Series Data Compression Methods using Statistics and Deviation
Sep 28, 2022
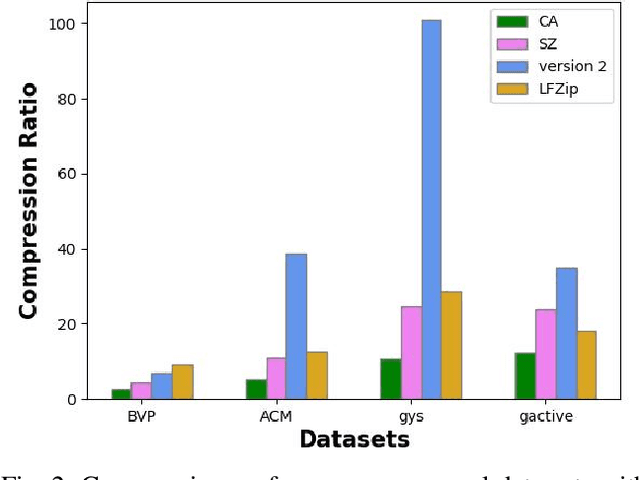

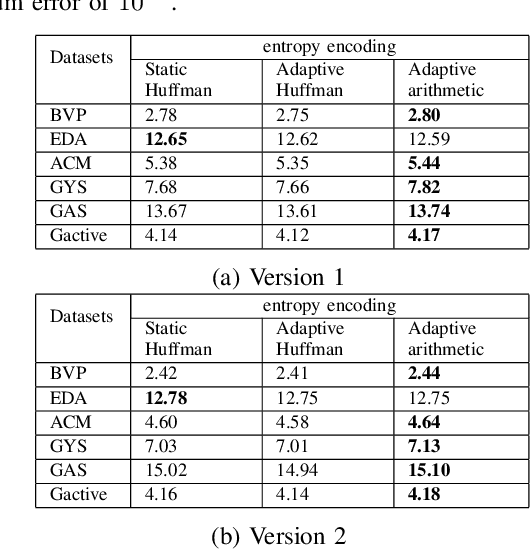
The last two decades have seen tremendous growth in data collections because of the realization of recent technologies, including the internet of things (IoT), E-Health, industrial IoT 4.0, autonomous vehicles, etc. The challenge of data transmission and storage can be handled by utilizing state-of-the-art data compression methods. Recent data compression methods are proposed using deep learning methods, which perform better than conventional methods. However, these methods require a lot of data and resources for training. Furthermore, it is difficult to materialize these deep learning-based solutions on IoT devices due to the resource-constrained nature of IoT devices. In this paper, we propose lightweight data compression methods based on data statistics and deviation. The proposed method performs better than the deep learning method in terms of compression ratio (CR). We simulate and compare the proposed data compression methods for various time series signals, e.g., accelerometer, gas sensor, gyroscope, electrical power consumption, etc. In particular, it is observed that the proposed method achieves 250.8\%, 94.3\%, and 205\% higher CR than the deep learning method for the GYS, Gactive, and ACM datasets, respectively. The code and data are available at https://github.com/vidhi0206/data-compression .
Autoencoder Based Iterative Modeling and Multivariate Time-Series Subsequence Clustering Algorithm
Sep 09, 2022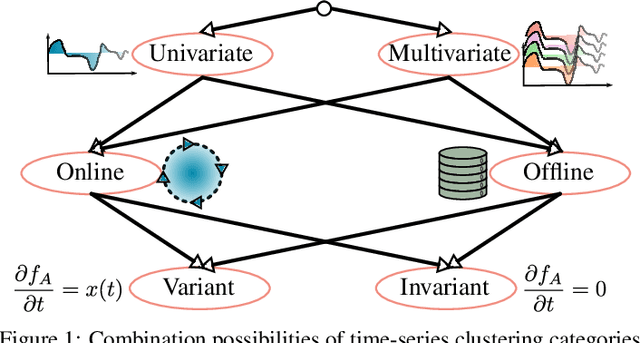


This paper introduces an algorithm for the detection of change-points and the identification of the corresponding subsequences in transient multivariate time-series data (MTSD). The analysis of such data has become more and more important due to the increase of availability in many industrial fields. Labeling, sorting or filtering highly transient measurement data for training condition based maintenance (CbM) models is cumbersome and error-prone. For some applications it can be sufficient to filter measurements by simple thresholds or finding change-points based on changes in mean value and variation. But a robust diagnosis of a component within a component group for example, which has a complex non-linear correlation between multiple sensor values, a simple approach would not be feasible. No meaningful and coherent measurement data which could be used for training a CbM model would emerge. Therefore, we introduce an algorithm which uses a recurrent neural network (RNN) based Autoencoder (AE) which is iteratively trained on incoming data. The scoring function uses the reconstruction error and latent space information. A model of the identified subsequence is saved and used for recognition of repeating subsequences as well as fast offline clustering. For evaluation, we propose a new similarity measure based on the curvature for a more intuitive time-series subsequence clustering metric. A comparison with seven other state-of-the-art algorithms and eight datasets shows the capability and the increased performance of our algorithm to cluster MTSD online and offline in conjunction with mechatronic systems.
On the Convergence of Federated Averaging with Cyclic Client Participation
Feb 06, 2023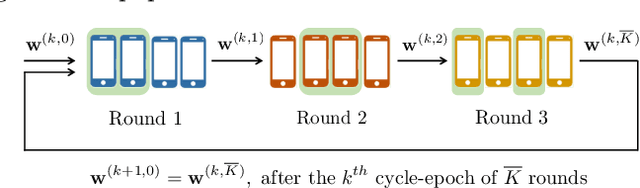
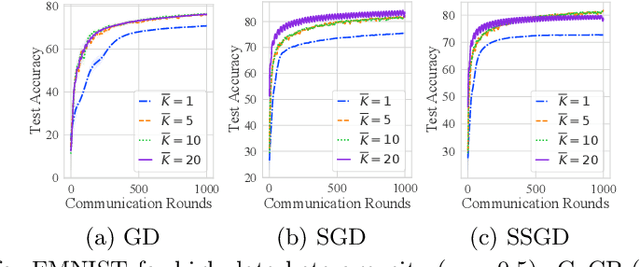
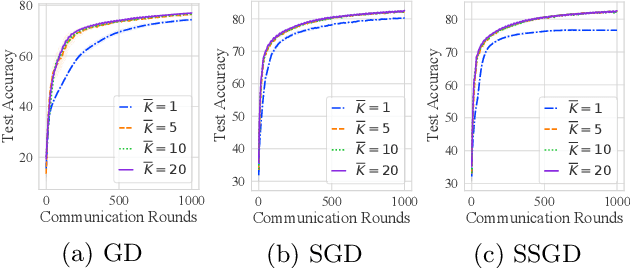
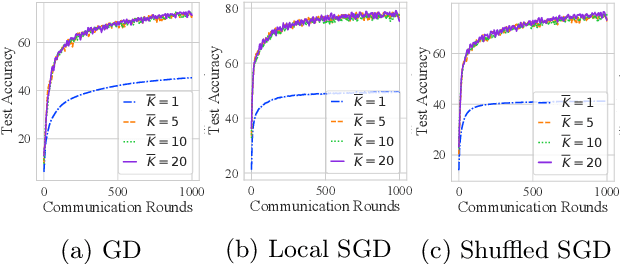
Federated Averaging (FedAvg) and its variants are the most popular optimization algorithms in federated learning (FL). Previous convergence analyses of FedAvg either assume full client participation or partial client participation where the clients can be uniformly sampled. However, in practical cross-device FL systems, only a subset of clients that satisfy local criteria such as battery status, network connectivity, and maximum participation frequency requirements (to ensure privacy) are available for training at a given time. As a result, client availability follows a natural cyclic pattern. We provide (to our knowledge) the first theoretical framework to analyze the convergence of FedAvg with cyclic client participation with several different client optimizers such as GD, SGD, and shuffled SGD. Our analysis discovers that cyclic client participation can achieve a faster asymptotic convergence rate than vanilla FedAvg with uniform client participation under suitable conditions, providing valuable insights into the design of client sampling protocols.
Robust Maximum Correntropy Kalman Filter
Feb 06, 2023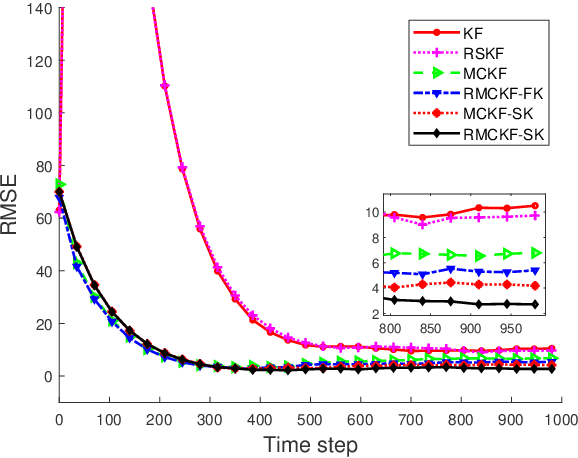
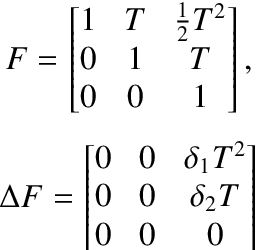
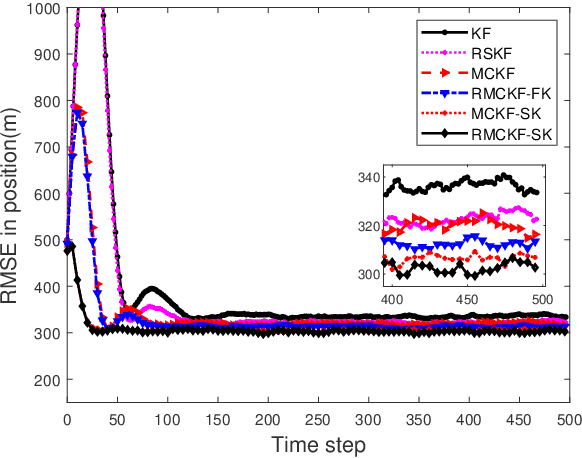
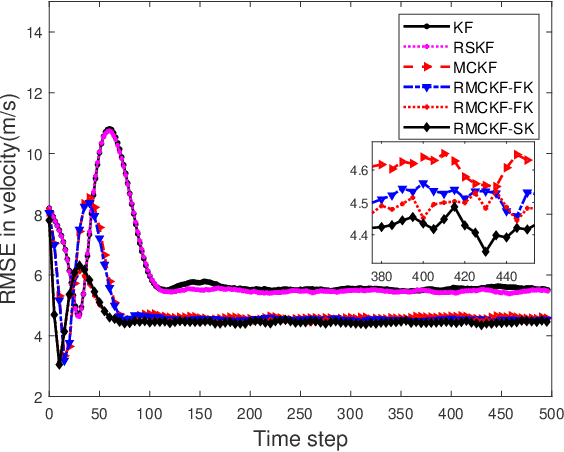
The Kalman filter provides an optimal estimation for a linear system with Gaussian noise. However when the noises are non-Gaussian in nature, its performance deteriorates rapidly. For non-Gaussian noises, maximum correntropy Kalman filter (MCKF) is developed which provides an improved result. But when the system model differs from nominal consideration, the performance of the MCKF degrades. For such cases, we have proposed a new robust filtering technique which maximize a cost function defined by exponential of weighted past and present errors along with the Gaussian kernel function. By solving this cost criteria we have developed prior and posterior mean and covariance matrix propagation equations. By maximizing the correntropy function of error matrix, we have selected the kernel bandwidth value at each time step. Further the conditions for convergence of the proposed algorithm is also derived. Two numerical examples are presented to show the usefulness of the new filtering technique.
Adaptive Coverage Path Planning for Efficient Exploration of Unknown Environments
Feb 06, 2023
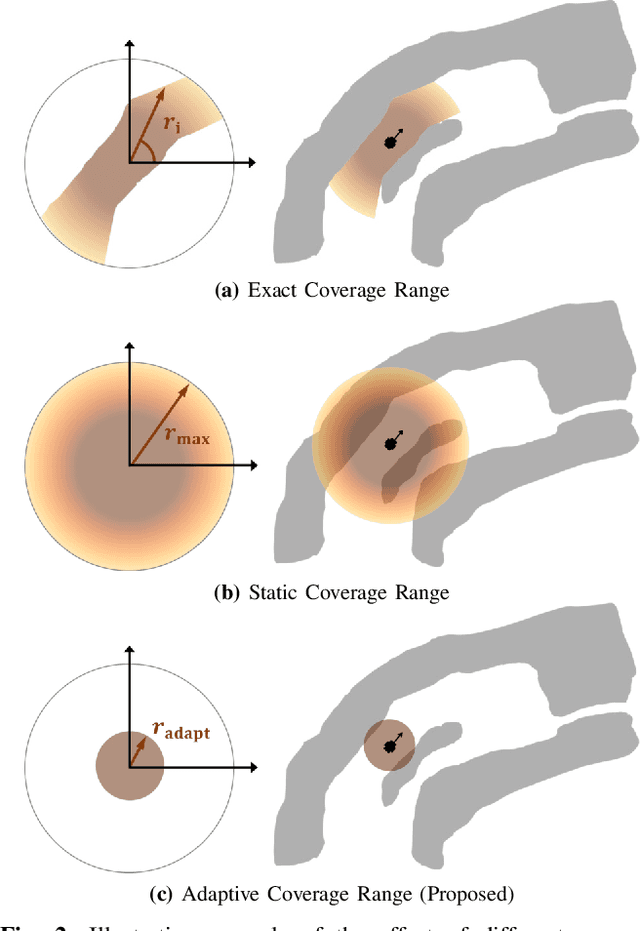
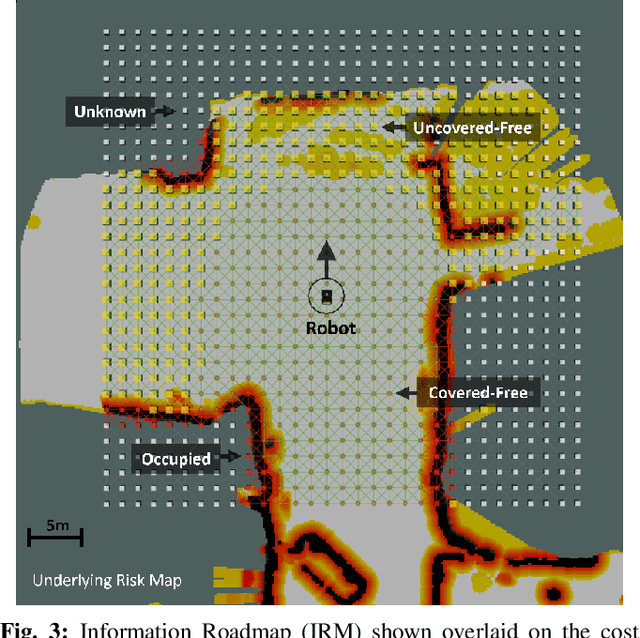
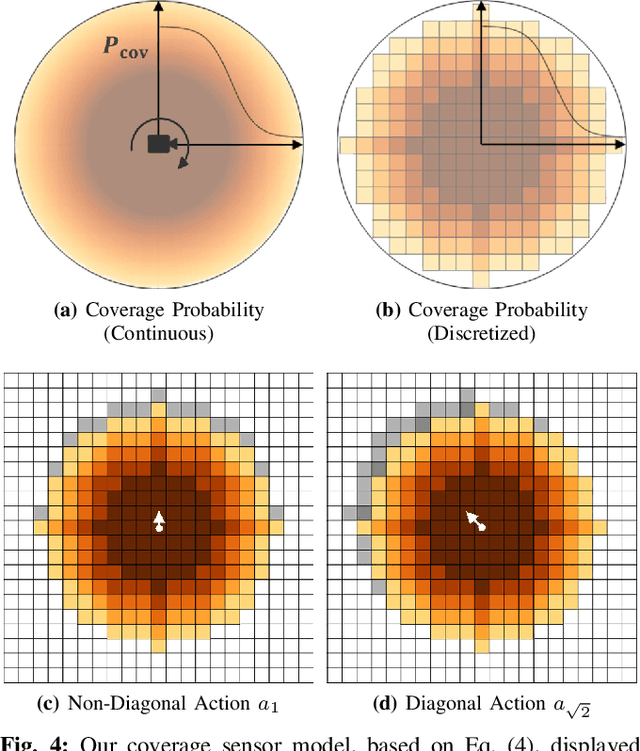
We present a method for solving the coverage problem with the objective of autonomously exploring an unknown environment under mission time constraints. Here, the robot is tasked with planning a path over a horizon such that the accumulated area swept out by its sensor footprint is maximized. Because this problem exhibits a diminishing returns property known as submodularity, we choose to formulate it as a tree-based sequential decision making process. This formulation allows us to evaluate the effects of the robot's actions on future world coverage states, while simultaneously accounting for traversability risk and the dynamic constraints of the robot. To quickly find near-optimal solutions, we propose an effective approximation to the coverage sensor model which adapts to the local environment. Our method was extensively tested across various complex environments and served as the local exploration algorithm for a competing entry in the DARPA Subterranean Challenge.
SparDA: Accelerating Dynamic Sparse Deep Neural Networks via Sparse-Dense Transformation
Jan 26, 2023

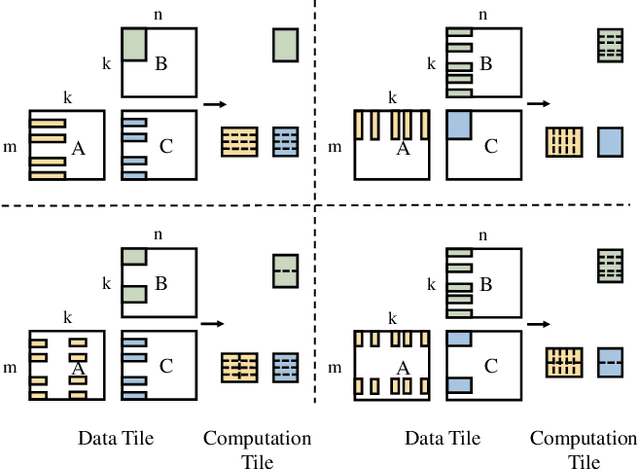
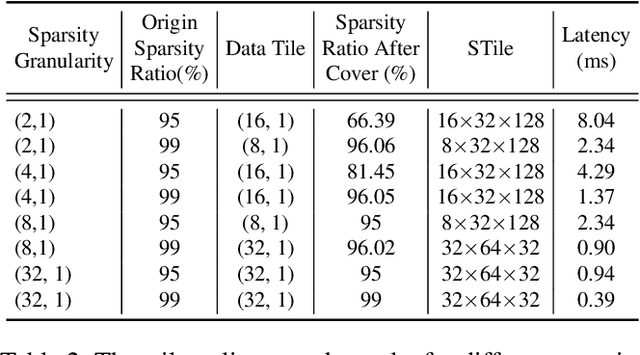
Due to its high cost-effectiveness, sparsity has become the most important approach for building efficient deep-learning models. However, commodity accelerators are built mainly for efficient dense computation, creating a huge gap for general sparse computation to leverage. Existing solutions have to use time-consuming compiling to improve the efficiency of sparse kernels in an ahead-of-time manner and thus are limited to static sparsity. A wide range of dynamic sparsity opportunities is missed because their sparsity patterns are only known at runtime. This limits the future of building more biological brain-like neural networks that should be dynamically and sparsely activated. In this paper, we bridge the gap between sparse computation and commodity accelerators by proposing a system, called Spider, for efficiently executing deep learning models with dynamic sparsity. We identify an important property called permutation invariant that applies to most deep-learning computations. The property enables Spider (1) to extract dynamic sparsity patterns of tensors that are only known at runtime with little overhead; and (2) to transform the dynamic sparse computation into an equivalent dense computation which has been extremely optimized on commodity accelerators. Extensive evaluation on diverse models shows Spider can extract and transform dynamic sparsity with negligible overhead but brings up to 9.4x speedup over state-of-art solutions.
ZiCo: Zero-shot NAS via Inverse Coefficient of Variation on Gradients
Jan 26, 2023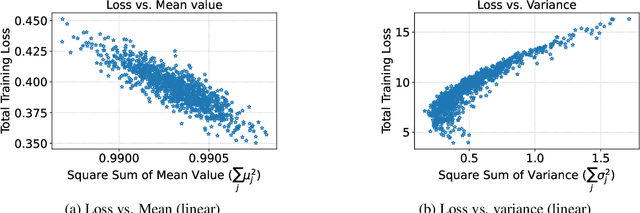
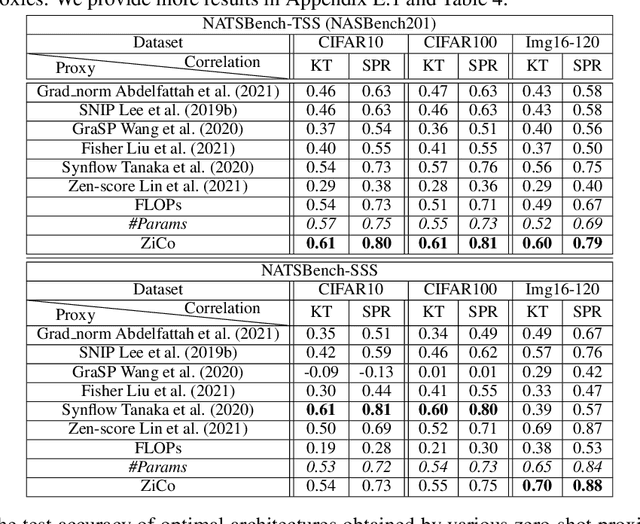

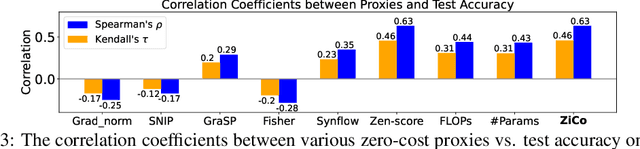
Neural Architecture Search (NAS) is widely used to automatically design the neural network with the best performance among a large number of candidate architectures. To reduce the search time, zero-shot NAS aims at designing training-free proxies that can predict the test performance of a given architecture. However, as shown recently, none of the zero-shot proxies proposed to date can actually work consistently better than a naive proxy, namely, the number of network parameters (#Params). To improve this state of affairs, as the main theoretical contribution, we first reveal how some specific gradient properties across different samples impact the convergence rate and generalization capacity of neural networks. Based on this theoretical analysis, we propose a new zero-shot proxy, ZiCo, the first proxy that works consistently better than #Params. We demonstrate that ZiCo works better than State-Of-The-Art (SOTA) proxies on several popular NAS-Benchmarks (NASBench101, NATSBench-SSS/TSS, TransNASBench-101) for multiple applications (e.g., image classification/reconstruction and pixel-level prediction). Finally, we demonstrate that the optimal architectures found via ZiCo are as competitive as the ones found by one-shot and multi-shot NAS methods, but with much less search time. For example, ZiCo-based NAS can find optimal architectures with 78.1%, 79.4%, and 80.4% test accuracy under inference budgets of 450M, 600M, and 1000M FLOPs on ImageNet within 0.4 GPU days.
Network-Assisted Full-Duplex Cell-Free mmWave Massive MIMO Systems with DAC Quantization and Fronthaul Compression
Feb 11, 2023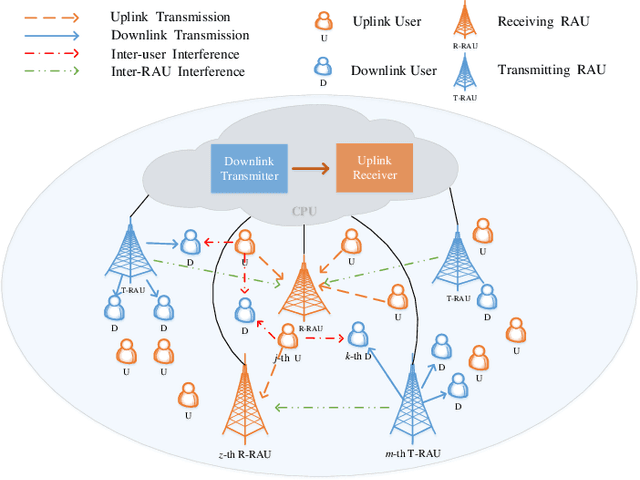
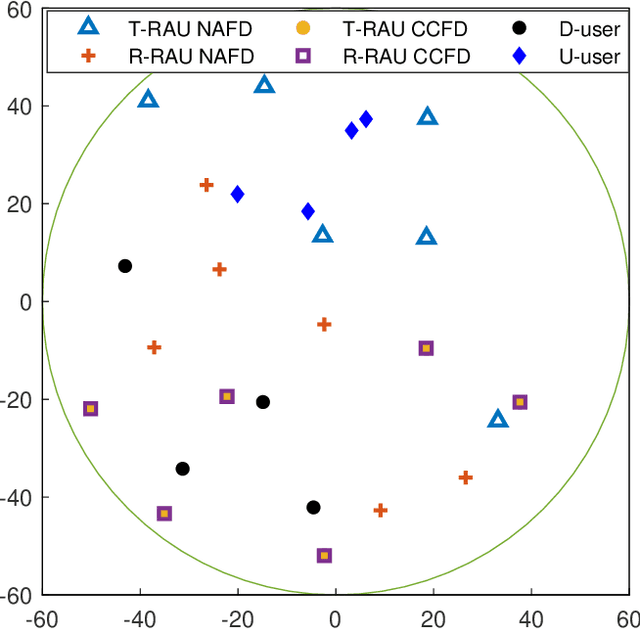
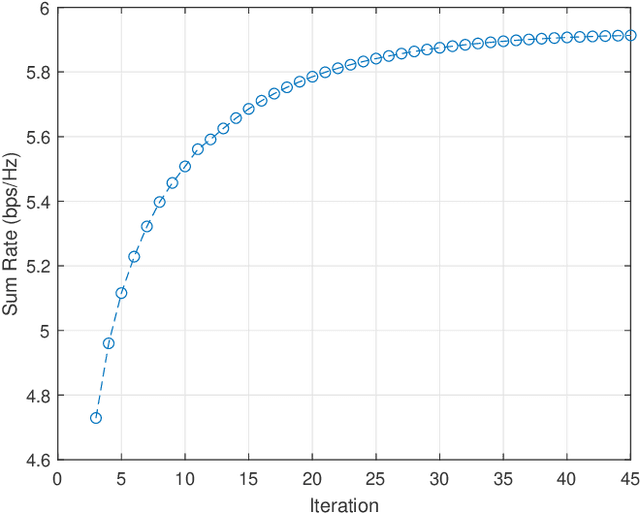
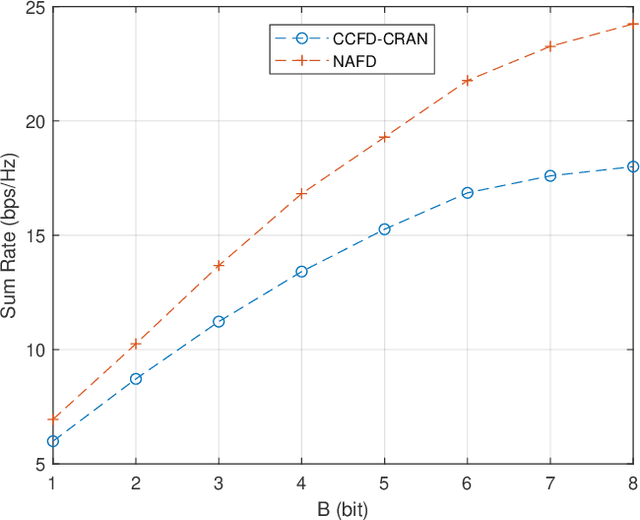
In this paper, we investigate network-assisted full-duplex (NAFD) cell-free millimeter-wave (mmWave) massive multiple-input multiple-output (MIMO) systems with digital-to-analog converter (DAC) quantization and fronthaul compression. We propose to maximize the weighted uplink and downlink sum rate by jointly optimizing the power allocation of both the transmitting remote antenna units (T-RAUs) and uplink users and the variances of the downlink and uplink fronthaul compression noises. To deal with this challenging problem, we further apply a successive convex approximation (SCA) method to handle the non-convex bidirectional limited-capacity fronthaul constraints. The simulation results verify the convergence of the proposed SCA-based algorithm and analyze the impact of fronthaul capacity and DAC quantization on the spectral efficiency of the NAFD cell-free mmWave massive MIMO systems. Moreover, some insightful conclusions are obtained through the comparisons of spectral efficiency, which shows that NAFD achieves better performance gains than co-time co-frequency full-duplex cloud radio access network (CCFD C-RAN) in the cases of practical limited-resolution DACs. Specifically, their performance gaps with 8-bit DAC quantization are larger than that with 1-bit DAC quantization, which attains a 5.5-fold improvement.
From ORAN to Cell-Free RAN: Architecture, Performance Analysis, Testbeds and Trials
Feb 07, 2023
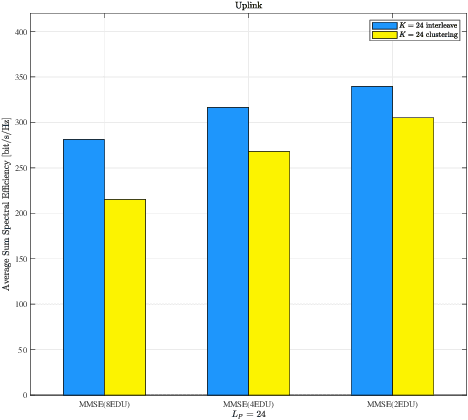
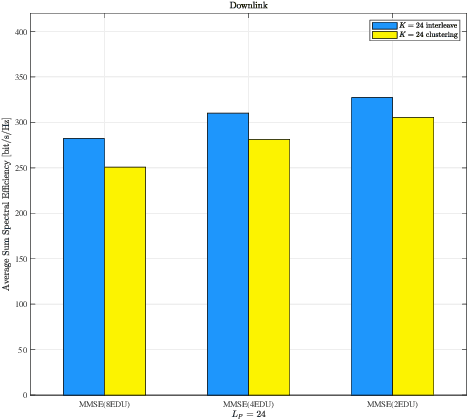

Open radio access network (ORAN) provides an open architecture to implement radio access network (RAN) of the fifth generation (5G) and beyond mobile communications. As a key technology for the evolution to the sixth generation (6G) systems, cell-free massive multiple-input multiple-output (CF-mMIMO) can effectively improve the spectrum efficiency, peak rate and reliability of wireless communication systems. Starting from scalable implementation of CF-mMIMO, we study a cell-free RAN (CF-RAN) under the ORAN architecture. Through theoretical analysis and numerical simulation, we investigate the uplink and downlink spectral efficiencies of CF-mMIMO with the new architecture. We then discuss the implementation issues of CF-RAN under ORAN architecture, including time-frequency synchronization and over-the-air reciprocity calibration, low layer splitting, deployment of ORAN radio units (O-RU), artificial intelligent based user associations. Finally, we present some representative experimental results for the uplink distributed reception and downlink coherent joint transmission of CF-RAN with commercial off-the-shelf O-RUs.