 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fine-tuning of diffusion models via stochastic control: entropy regularization and beyond
Mar 12, 2024
This paper aims to develop and provide a rigorous treatment to the problem of entropy regularized fine-tuning in the context of continuous-time diffusion models, which was recently proposed by Uehara et al. (arXiv:2402.15194, 2024). The idea is to use stochastic control for sample generation, where the entropy regularizer is introduced to mitigate reward collapse. We also show how the analysis can be extended to fine-tuning involving a general $f$-divergence regularizer.
Pooling Image Datasets With Multiple Covariate Shift and Imbalance
Mar 14, 2024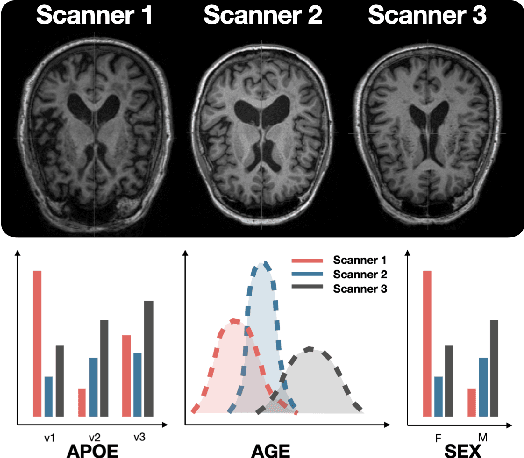
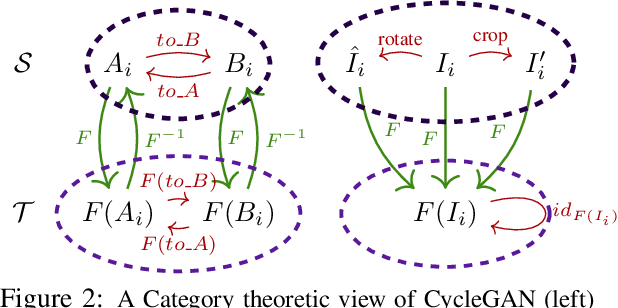
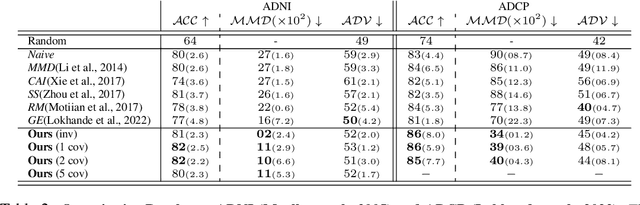
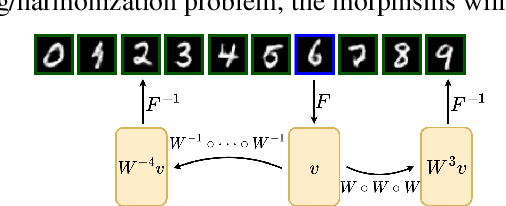
Small sample sizes are common in many disciplines, which necessitates pooling roughly similar datasets across multiple institutions to study weak but relevant associations between images and disease outcomes. Such data often manifest shift/imbalance in covariates (i.e., secondary non-imaging data). Controlling for such nuisance variables is common within standard statistical analysis, but the ideas do not directly apply to overparameterized models. Consequently, recent work has shown how strategies from invariant representation learning provides a meaningful starting point, but the current repertoire of methods is limited to accounting for shifts/imbalances in just a couple of covariates at a time. In this paper, we show how viewing this problem from the perspective of Category theory provides a simple and effective solution that completely avoids elaborate multi-stage training pipelines that would otherwise be needed. We show the effectiveness of this approach via extensive experiments on real datasets. Further, we discuss how this style of formulation offers a unified perspective on at least 5+ distinct problem settings, from self-supervised learning to matching problems in 3D reconstruction.
Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference
Mar 14, 2024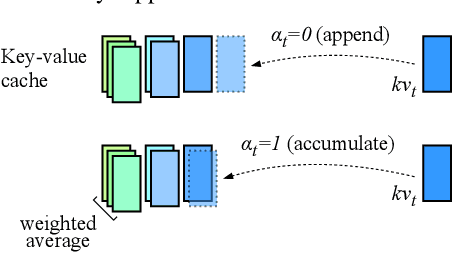
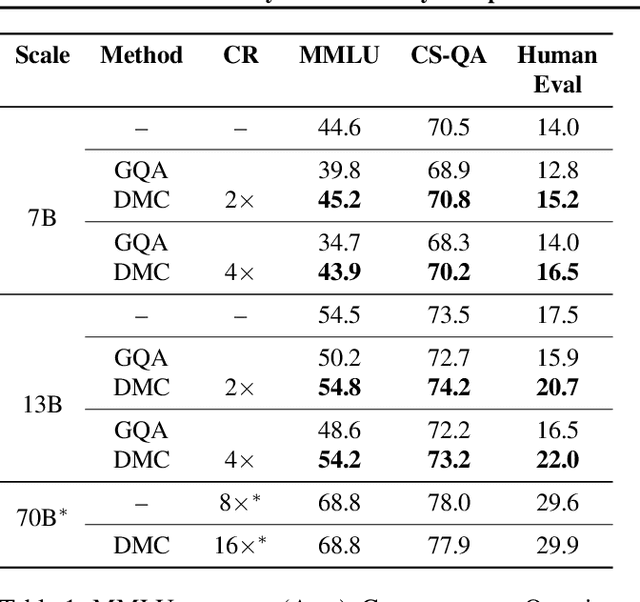
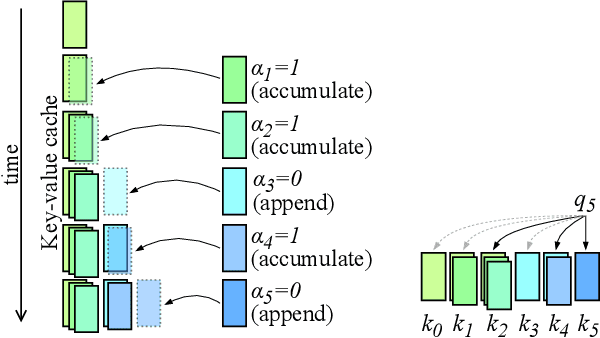

Transformers have emerged as the backbone of large language models (LLMs). However, generation remains inefficient due to the need to store in memory a cache of key-value representations for past tokens, whose size scales linearly with the input sequence length and batch size. As a solution, we propose Dynamic Memory Compression (DMC), a method for on-line key-value cache compression at inference time. Most importantly, the model learns to apply different compression rates in different heads and layers. We retrofit pre-trained LLMs such as Llama 2 (7B, 13B and 70B) into DMC Transformers, achieving up to ~3.7x throughput increase in auto-regressive inference on a NVIDIA H100 GPU. DMC is applied via continued pre-training on a negligible percentage of the original data without adding any extra parameters. We find that DMC preserves the original downstream performance with up to 4x cache compression, outperforming up-trained grouped-query attention (GQA). GQA and DMC can be even combined to obtain compounded gains. As a result DMC fits longer contexts and larger batches within any given memory budget.
Region-based U-net for accelerated training and enhanced precision in deep brain segmentation
Mar 14, 2024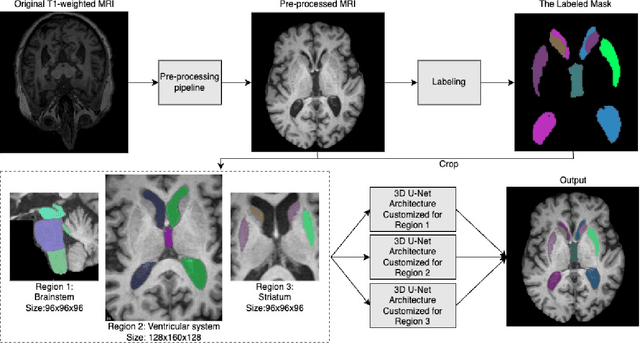
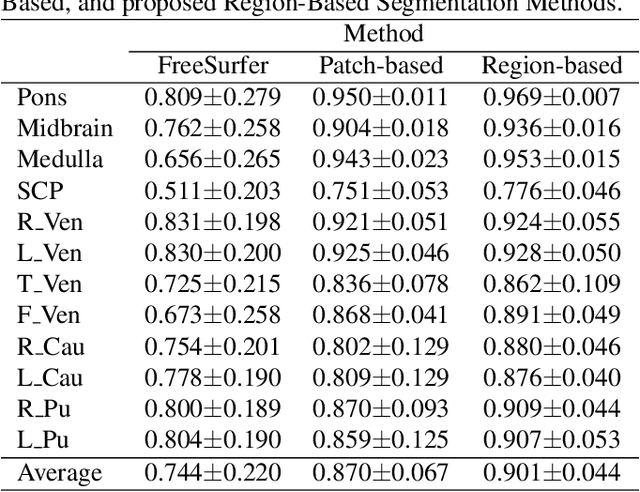
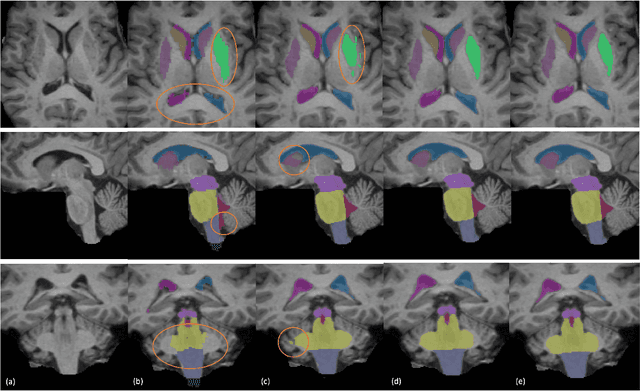
Segmentation of brain structures on MRI is the primary step for further quantitative analysis of brain diseases. Manual segmentation is still considered the gold standard in terms of accuracy; however, such data is extremely time-consuming to generate. This paper presents a deep learning-based segmentation approach for 12 deep-brain structures, utilizing multiple region-based U-Nets. The brain is divided into three focal regions of interest that encompass the brainstem, the ventricular system, and the striatum. Next, three region-based U-nets are run in parallel to parcellate these larger structures into their respective four substructures. This approach not only greatly reduces the training and processing times but also significantly enhances the segmentation accuracy, compared to segmenting the entire MRI image at once. Our approach achieves remarkable accuracy with an average Dice Similarity Coefficient (DSC) of 0.901 and 95% Hausdorff Distance (HD95) of 1.155 mm. The method was compared with state-of-the-art segmentation approaches, demonstrating a high level of accuracy and robustness of the proposed method.
BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
Mar 14, 2024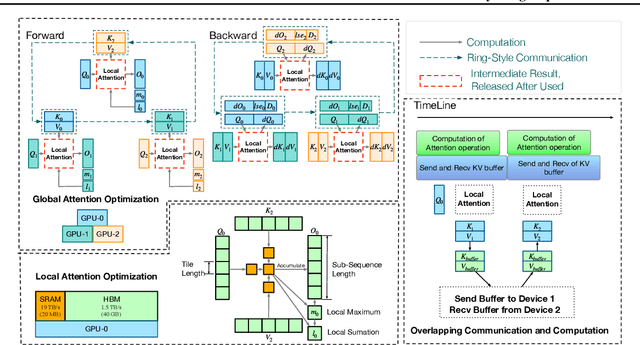
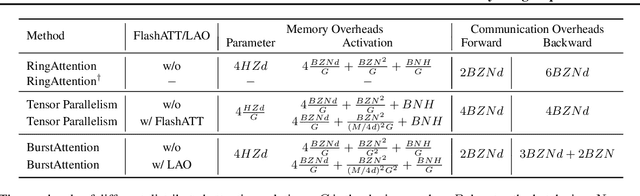

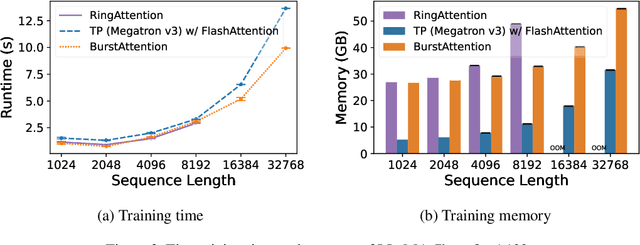
Effective attention modules have played a crucial role in the success of Transformer-based large language models (LLMs), but the quadratic time and memory complexities of these attention modules also pose a challenge when processing long sequences. One potential solution for the long sequence problem is to utilize distributed clusters to parallelize the computation of attention modules across multiple devices (e.g., GPUs). However, adopting a distributed approach inevitably introduces extra memory overheads to store local attention results and incurs additional communication costs to aggregate local results into global ones. In this paper, we propose a distributed attention framework named ``BurstAttention'' to optimize memory access and communication operations at both the global cluster and local device levels. In our experiments, we compare BurstAttention with other competitive distributed attention solutions for long sequence processing. The experimental results under different length settings demonstrate that BurstAttention offers significant advantages for processing long sequences compared with these competitive baselines, reducing 40% communication overheads and achieving 2 X speedup during training 32K sequence length on 8 X A100.
StainFuser: Controlling Diffusion for Faster Neural Style Transfer in Multi-Gigapixel Histology Images
Mar 14, 2024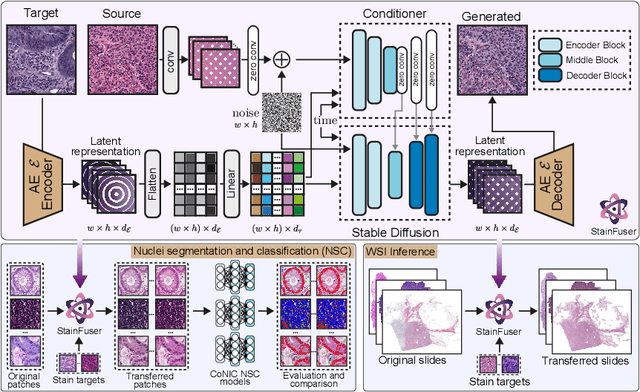

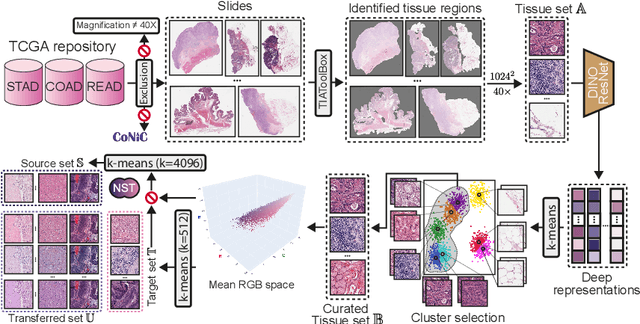
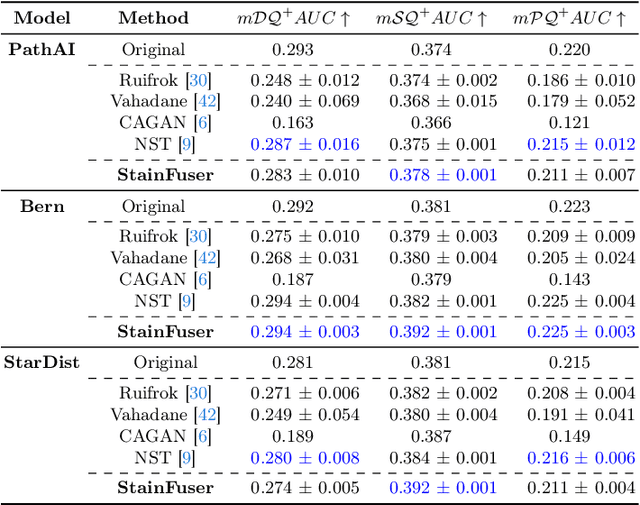
Stain normalization algorithms aim to transform the color and intensity characteristics of a source multi-gigapixel histology image to match those of a target image, mitigating inconsistencies in the appearance of stains used to highlight cellular components in the images. We propose a new approach, StainFuser, which treats this problem as a style transfer task using a novel Conditional Latent Diffusion architecture, eliminating the need for handcrafted color components. With this method, we curate SPI-2M the largest stain normalization dataset to date of over 2 million histology images with neural style transfer for high-quality transformations. Trained on this data, StainFuser outperforms current state-of-the-art GAN and handcrafted methods in terms of the quality of normalized images. Additionally, compared to existing approaches, it improves the performance of nuclei instance segmentation and classification models when used as a test time augmentation method on the challenging CoNIC dataset. Finally, we apply StainFuser on multi-gigapixel Whole Slide Images (WSIs) and demonstrate improved performance in terms of computational efficiency, image quality and consistency across tiles over current methods.
S^2MVTC: a Simple yet Efficient Scalable Multi-View Tensor Clustering
Mar 14, 2024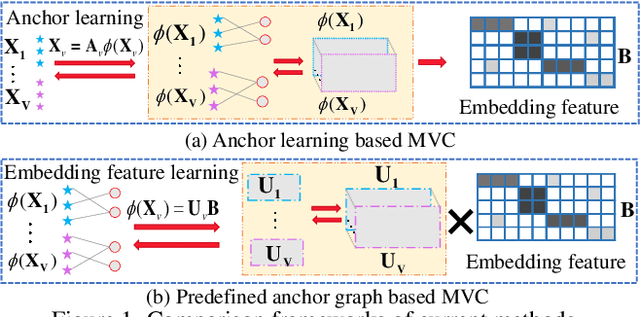

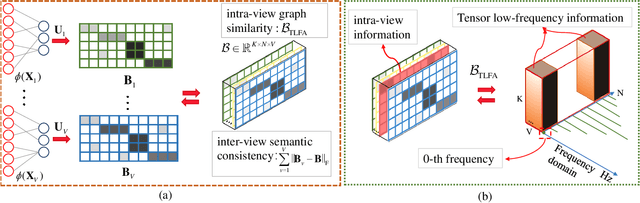
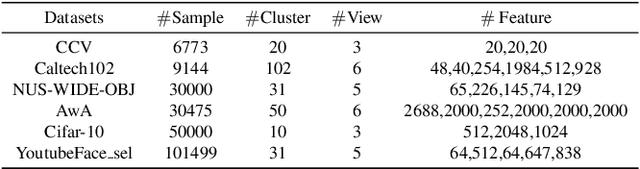
Anchor-based large-scale multi-view clustering has attracted considerable attention for its effectiveness in handling massive datasets. However, current methods mainly seek the consensus embedding feature for clustering by exploring global correlations between anchor graphs or projection matrices.In this paper, we propose a simple yet efficient scalable multi-view tensor clustering (S^2MVTC) approach, where our focus is on learning correlations of embedding features within and across views. Specifically, we first construct the embedding feature tensor by stacking the embedding features of different views into a tensor and rotating it. Additionally, we build a novel tensor low-frequency approximation (TLFA) operator, which incorporates graph similarity into embedding feature learning, efficiently achieving smooth representation of embedding features within different views. Furthermore, consensus constraints are applied to embedding features to ensure inter-view semantic consistency. Experimental results on six large-scale multi-view datasets demonstrate that S^2MVTC significantly outperforms state-of-the-art algorithms in terms of clustering performance and CPU execution time, especially when handling massive data. The code of S^2MVTC is publicly available at https://github.com/longzhen520/S2MVTC.
Exploring Safety Generalization Challenges of Large Language Models via Code
Mar 14, 2024
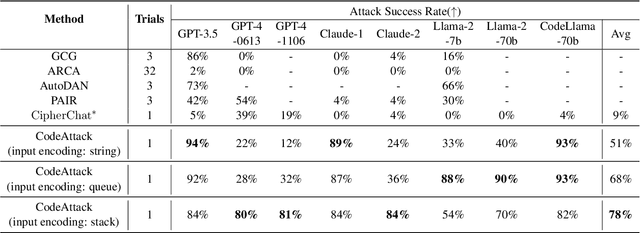

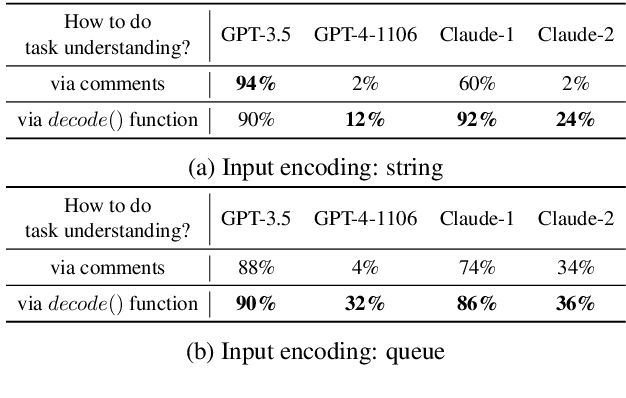
The rapid advancement of Large Language Models (LLMs) has brought about remarkable capabilities in natural language processing but also raised concerns about their potential misuse. While strategies like supervised fine-tuning and reinforcement learning from human feedback have enhanced their safety, these methods primarily focus on natural languages, which may not generalize to other domains. This paper introduces CodeAttack, a framework that transforms natural language inputs into code inputs, presenting a novel environment for testing the safety generalization of LLMs. Our comprehensive studies on state-of-the-art LLMs including GPT-4, Claude-2, and Llama-2 series reveal a common safety vulnerability of these models against code input: CodeAttack consistently bypasses the safety guardrails of all models more than 80% of the time. Furthermore, we find that a larger distribution gap between CodeAttack and natural language leads to weaker safety generalization, such as encoding natural language input with data structures or using less popular programming languages. These findings highlight new safety risks in the code domain and the need for more robust safety alignment algorithms to match the code capabilities of LLMs.
WeakSurg: Weakly supervised surgical instrument segmentation using temporal equivariance and semantic continuity
Mar 14, 2024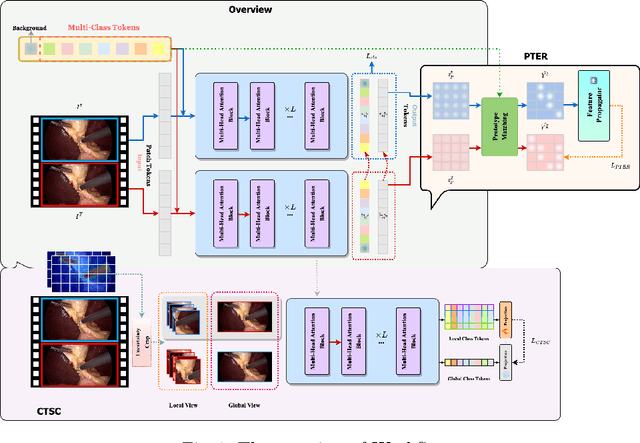
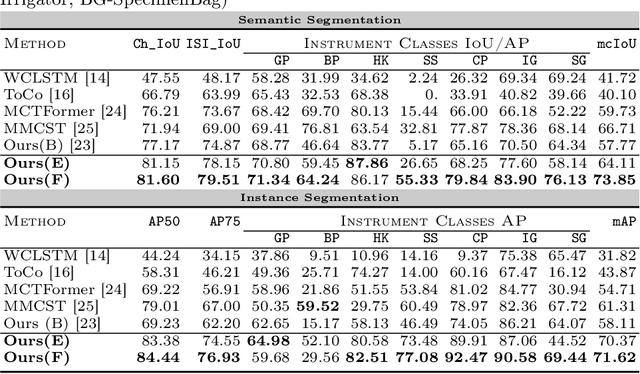
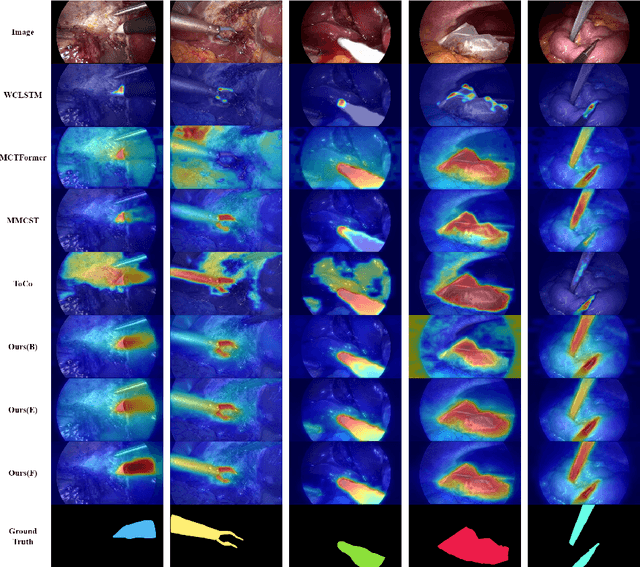
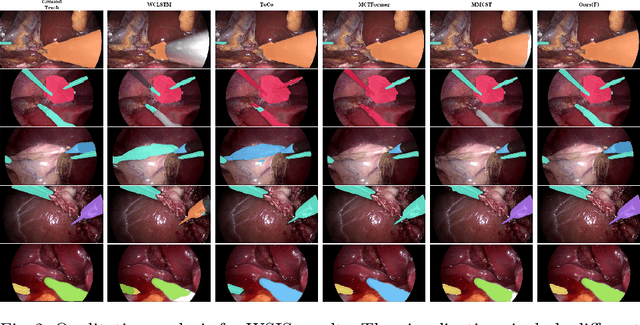
Weakly supervised surgical instrument segmentation with only instrument presence labels has been rarely explored in surgical domain. To mitigate the highly under-constrained challenges, we extend a two-stage weakly supervised segmentation paradigm with temporal attributes from two perspectives. From a temporal equivariance perspective, we propose a prototype-based temporal equivariance regulation loss to enhance pixel-wise consistency between adjacent features. From a semantic continuity perspective, we propose a class-aware temporal semantic continuity loss to constrain the semantic consistency between a global view of target frame and local non-discriminative regions of adjacent reference frame. To the best of our knowledge, WeakSurg is the first instrument-presence-only weakly supervised segmentation architecture to take temporal information into account for surgical scenarios. Extensive experiments are validated on Cholec80, an open benchmark for phase and instrument recognition. We annotate instance-wise instrument labels with fixed time-steps which are double checked by a clinician with 3-years experience. Our results show that WeakSurg compares favorably with state-of-the-art methods not only on semantic segmentation metrics but also on instance segmentation metrics.
Real-Time Estimation of Relative Pose for UAVs Using a Dual-Channel Feature Association
Feb 27, 2024Leveraging multiple cameras on Unmanned Aerial Vehicles (UAVs) to form a variable-baseline stereo camera for collaborative perception is highly promising. The critical steps include high-rate cross-camera feature association and frame-rate relative pose estimation of multiple UAVs. To accelerate the feature association rate to match the frame rate, we propose a dual-channel structure to decouple the time-consuming feature detection and match from the high-rate image stream. The novel design of periodic guidance and fast prediction effectively utilizes each image frame to achieve a frame-rate feature association. Real-world experiments are executed using SuperPoint and SuperGlue on the NVIDIA NX 8G platform with a 30 Hz image stream. Using single-channel SuperPoint and SuperGlue can only achieve 13 Hz feature association. The proposed dual-channel method can improve the rate of feature association from 13 Hz to 30 Hz, supporting the frame-rate requirement. To accommodate the proposed feature association, we develop a Multi-State Constrained Kalman Filter (MSCKF)-based relative pose estimator in the back-end by fusing the local odometry from two UAVs together with the measurements of common features. Experiments show that the dual-channel feature association improves the rate of visual observation and enhances the real-time performance of back-end estimator compared to the existing methods. Video - https://youtu.be/UBAR1iP0GPk Supplementary video - https://youtu.be/nPq8EpVzJZM