 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Autonomous Exploration Method for Fast Unknown Environment Mapping by Using UAV Equipped with Limited FOV Sensor
Feb 05, 2023
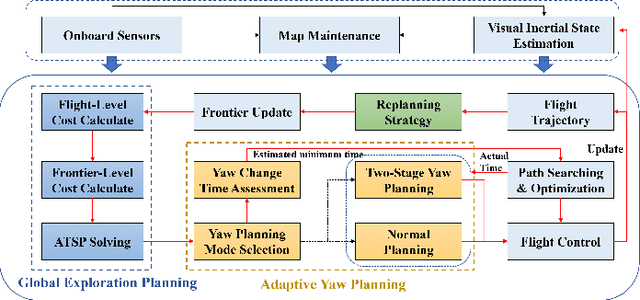

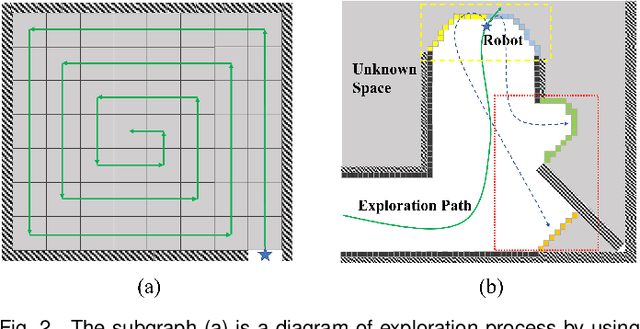
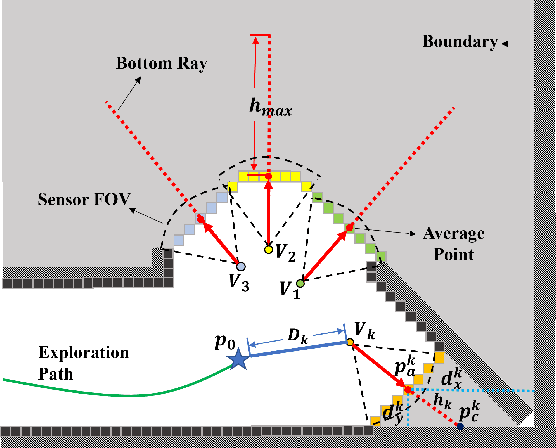
Autonomous exploration is one of the important parts to achieve the fast autonomous mapping and target search. However, most of the existing methods are facing low-efficiency problems caused by low-quality trajectory or back-and-forth maneuvers. To improve the exploration efficiency in unknown environments, a fast autonomous exploration planner (FAEP) is proposed in this paper. Different from existing methods, we firstly design a novel frontiers exploration sequence generation method to obtain a more reasonable exploration path, which considers not only the flight-level but frontier-level factors in the asymmetric traveling salesman problem (ATSP). Then, according to the exploration sequence and the distribution of frontiers, an adaptive yaw planning method is proposed to cover more frontiers by yaw change during an exploration journey. In addition, to increase the speed and fluency of flight, a dynamic replanning strategy is also adopted. We present sufficient comparison and evaluation experiments in simulation environments. Experimental results show the proposed exploration planner has better performance in terms of flight time and flight distance compared to typical and state-of-the-art methods. Moreover, the effectiveness of the proposed method is further evaluated in real-world environments.
Control-Tree Optimization: an approach to MPC under discrete Partial Observability
Jan 31, 2023
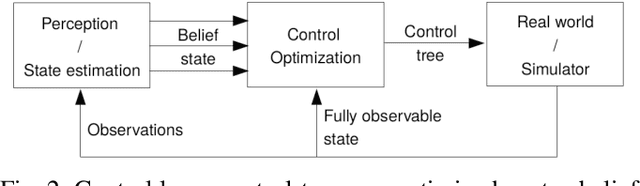
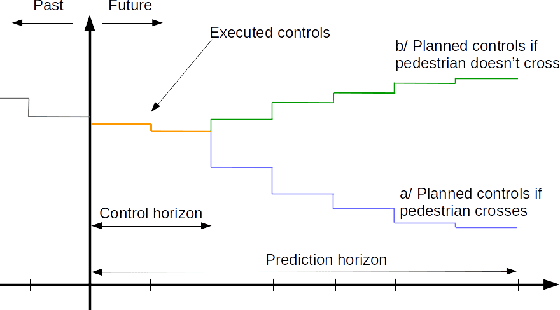
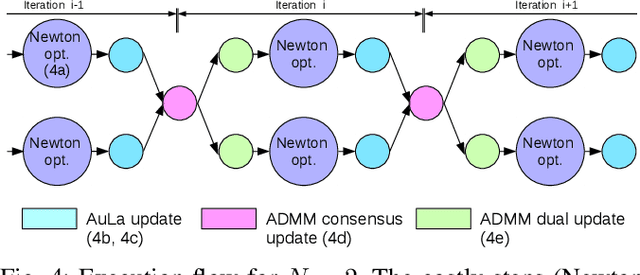
This paper presents a new approach to Model Predictive Control for environments where essential, discrete variables are partially observed. Under this assumption, the belief state is a probability distribution over a finite number of states. We optimize a \textit{control-tree} where each branch assumes a given state-hypothesis. The control-tree optimization uses the probabilistic belief state information. This leads to policies more optimized with respect to likely states than unlikely ones, while still guaranteeing robust constraint satisfaction at all times. We apply the method to both linear and non-linear MPC with constraints. The optimization of the \textit{control-tree} is decomposed into optimization subproblems that are solved in parallel leading to good scalability for high number of state-hypotheses. We demonstrate the real-time feasibility of the algorithm on two examples and show the benefits compared to a classical MPC scheme optimizing w.r.t. one single hypothesis.
* 6 pages, 10 figures
Active Transfer Prototypical Network: An Efficient Labeling Algorithm for Time-Series Data
Sep 28, 2022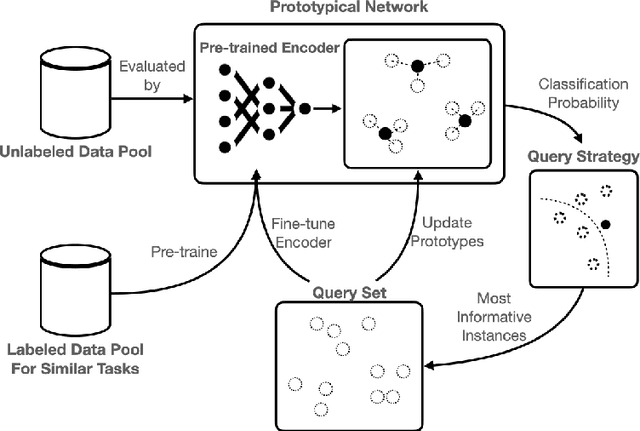
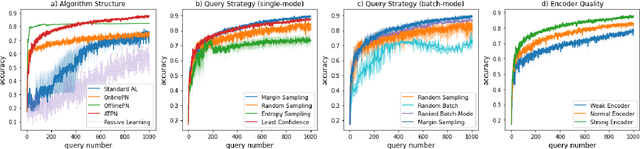
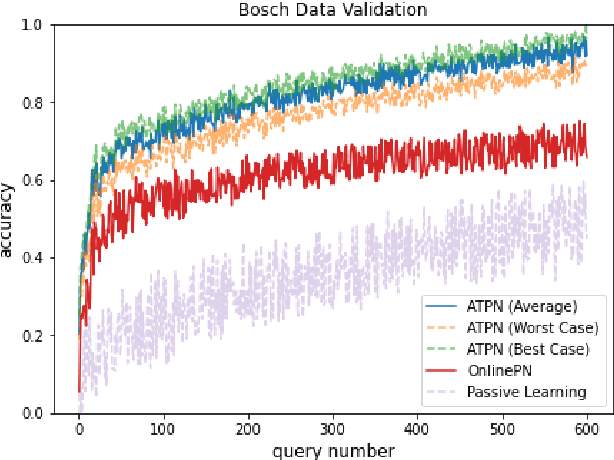
The paucity of labeled data is a typical challenge in the automotive industry. Annotating time-series measurements requires solid domain knowledge and in-depth exploratory data analysis, which implies a high labeling effort. Conventional Active Learning (AL) addresses this issue by actively querying the most informative instances based on the estimated classification probability and retraining the model iteratively. However, the learning efficiency strongly relies on the initial model, resulting in the trade-off between the size of the initial dataset and the query number. This paper proposes a novel Few-Shot Learning (FSL)-based AL framework, which addresses the trade-off problem by incorporating a Prototypical Network (ProtoNet) in the AL iterations. The results show an improvement, on the one hand, in the robustness to the initial model and, on the other hand, in the learning efficiency of the ProtoNet through the active selection of the support set in each iteration. This framework was validated on UCI HAR/HAPT dataset and a real-world braking maneuver dataset. The learning performance significantly surpasses traditional AL algorithms on both datasets, achieving 90% classification accuracy with 10% and 5% labeling effort, respectively.
Learning from Stochastic Labels
Feb 01, 2023
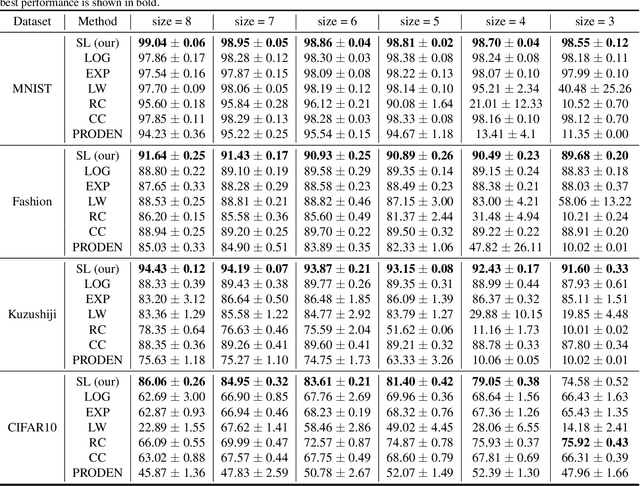
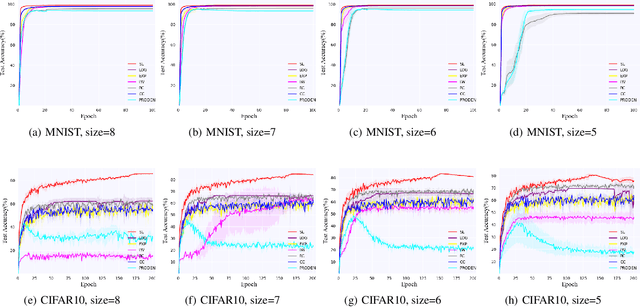
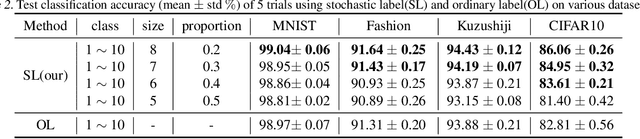
Annotating multi-class instances is a crucial task in the field of machine learning. Unfortunately, identifying the correct class label from a long sequence of candidate labels is time-consuming and laborious. To alleviate this problem, we design a novel labeling mechanism called stochastic label. In this setting, stochastic label includes two cases: 1) identify a correct class label from a small number of randomly given labels; 2) annotate the instance with None label when given labels do not contain correct class label. In this paper, we propose a novel suitable approach to learn from these stochastic labels. We obtain an unbiased estimator that utilizes less supervised information in stochastic labels to train a multi-class classifier. Additionally, it is theoretically justifiable by deriving the estimation error bound of the proposed method. Finally, we conduct extensive experiments on widely-used benchmark datasets to validate the superiority of our method by comparing it with existing state-of-the-art methods.
Learning Players' Objectives in Continuous Dynamic Games from Partial State Observations
Feb 03, 2023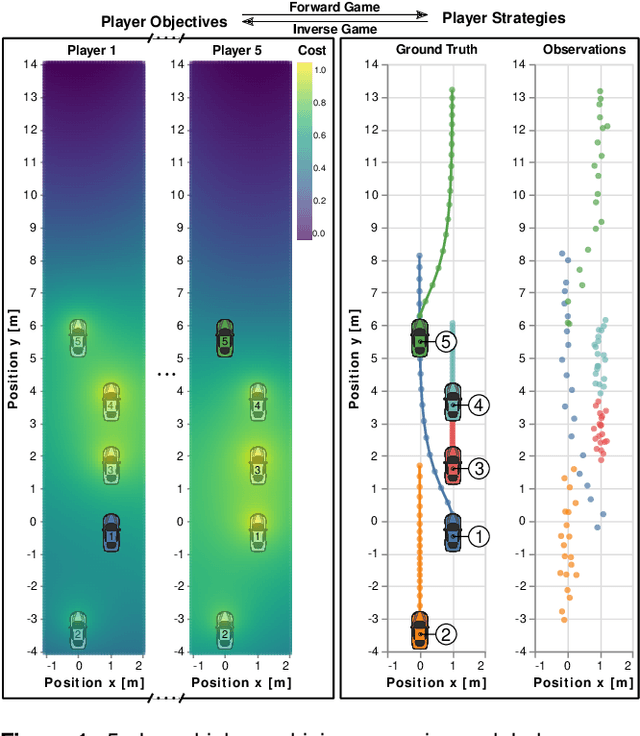
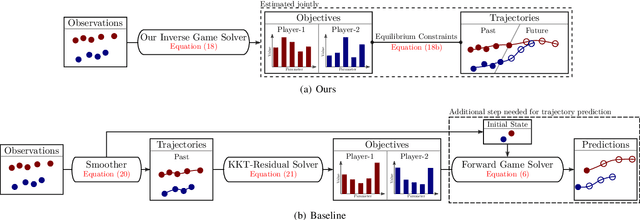
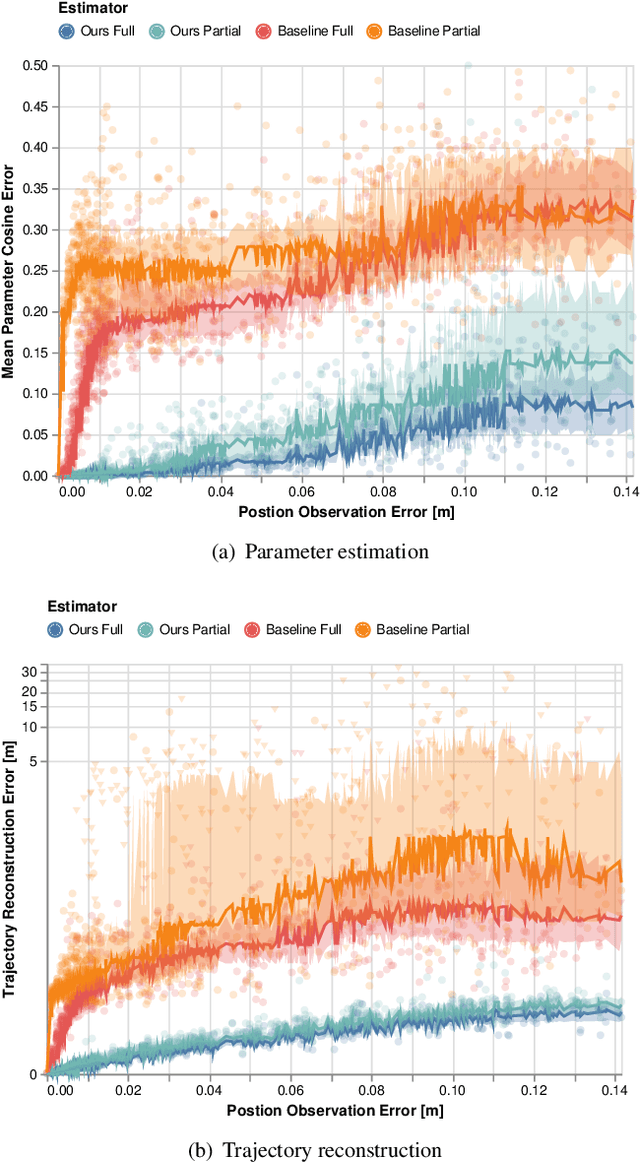
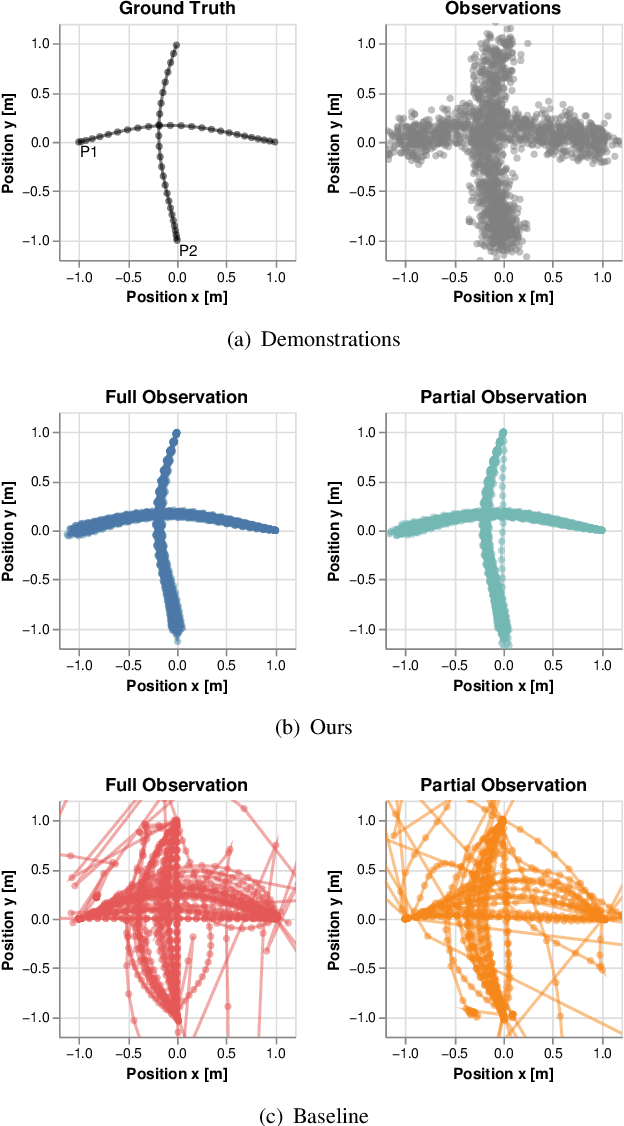
Robots deployed to the real world must be able to interact with other agents in their environment. Dynamic game theory provides a powerful mathematical framework for modeling scenarios in which agents have individual objectives and interactions evolve over time. However, a key limitation of such techniques is that they require a-priori knowledge of all players' objectives. In this work, we address this issue by proposing a novel method for learning players' objectives in continuous dynamic games from noise-corrupted, partial state observations. Our approach learns objectives by coupling the estimation of unknown cost parameters of each player with inference of unobserved states and inputs through Nash equilibrium constraints. By coupling past state estimates with future state predictions, our approach is amenable to simultaneous online learning and prediction in receding horizon fashion. We demonstrate our method in several simulated traffic scenarios in which we recover players' preferences for, e.g., desired travel speed and collision-avoidance behavior. Results show that our method reliably estimates game-theoretic models from noise-corrupted data that closely matches ground-truth objectives, consistently outperforming state-of-the-art approaches.
Self-Supervised Transformer Architecture for Change Detection in Radio Access Networks
Feb 03, 2023
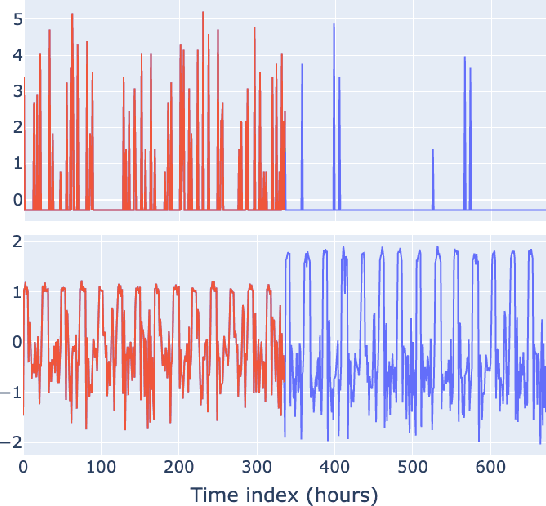
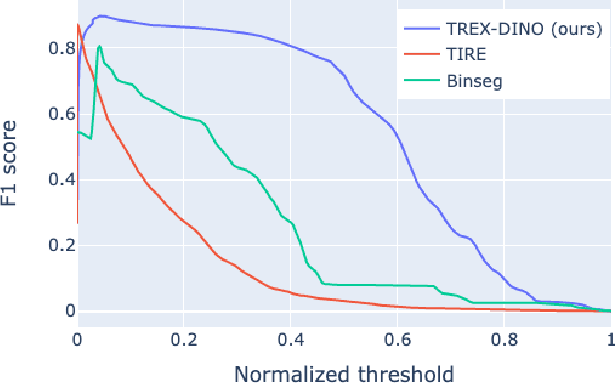

Radio Access Networks (RANs) for telecommunications represent large agglomerations of interconnected hardware consisting of hundreds of thousands of transmitting devices (cells). Such networks undergo frequent and often heterogeneous changes caused by network operators, who are seeking to tune their system parameters for optimal performance. The effects of such changes are challenging to predict and will become even more so with the adoption of 5G/6G networks. Therefore, RAN monitoring is vital for network operators. We propose a self-supervised learning framework that leverages self-attention and self-distillation for this task. It works by detecting changes in Performance Measurement data, a collection of time-varying metrics which reflect a set of diverse measurements of the network performance at the cell level. Experimental results show that our approach outperforms the state of the art by 4% on a real-world based dataset consisting of about hundred thousands timeseries. It also has the merits of being scalable and generalizable. This allows it to provide deep insight into the specifics of mode of operation changes while relying minimally on expert knowledge.
Accelerating exploration of Marine Cloud Brightening impacts on tipping points Using an AI Implementation of Fluctuation-Dissipation Theorem
Feb 03, 2023

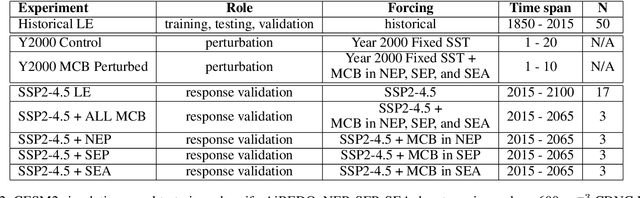
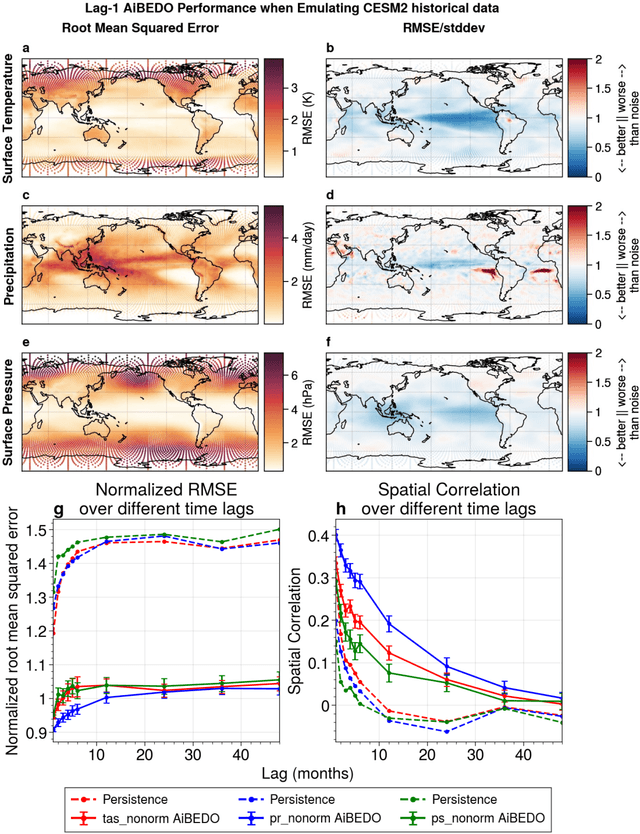
Marine cloud brightening (MCB) is a proposed climate intervention technology to partially offset greenhouse gas warming and possibly avoid crossing climate tipping points. The impacts of MCB on regional climate are typically estimated using computationally expensive Earth System Model (ESM) simulations, preventing a thorough assessment of the large possibility space of potential MCB interventions. Here, we describe an AI model, named AiBEDO, that can be used to rapidly projects climate responses to forcings via a novel application of the Fluctuation-Dissipation Theorem (FDT). AiBEDO is a Multilayer Perceptron (MLP) model that uses maps monthly-mean radiation anomalies to surface climate anomalies at a range of time lags. By leveraging a large existing dataset of ESM simulations containing internal climate noise, we use AiBEDO to construct an FDT operator that successfully projects climate responses to MCB forcing, when evaluated against ESM simulations. We propose that AiBEDO-FDT can be used to optimize MCB forcing patterns to reduce tipping point risks while minimizing negative side effects in other parts of the climate.
Towards Practical Preferential Bayesian Optimization with Skew Gaussian Processes
Feb 03, 2023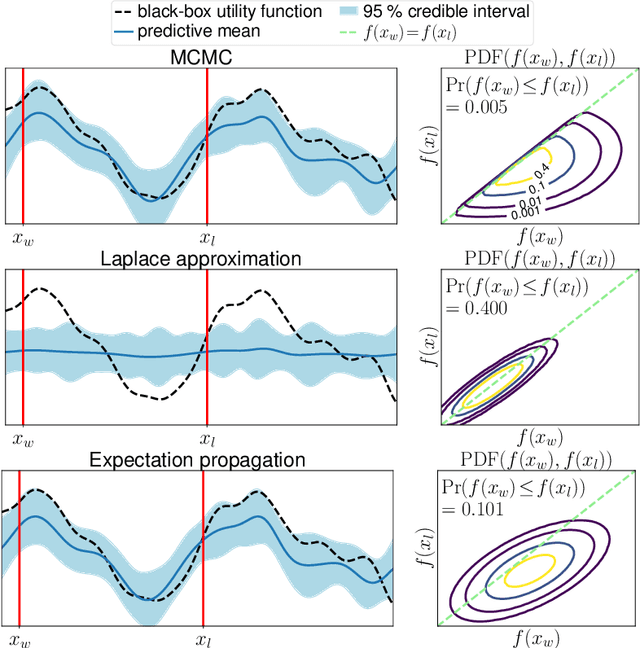
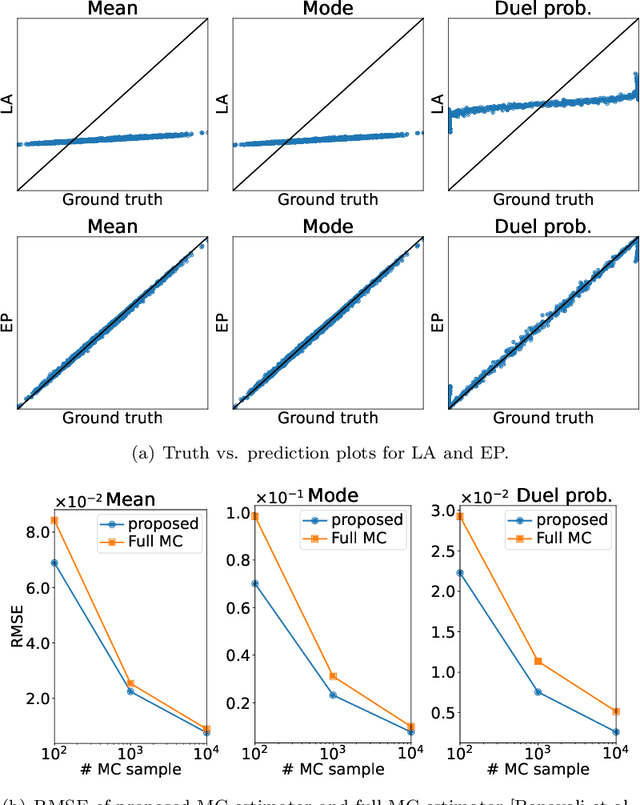
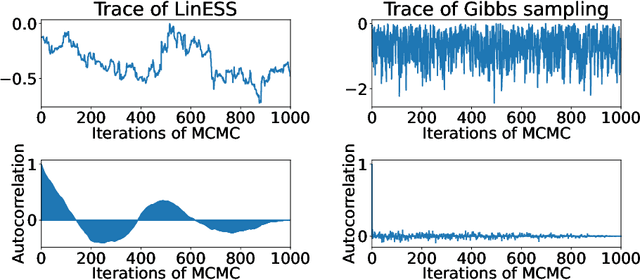
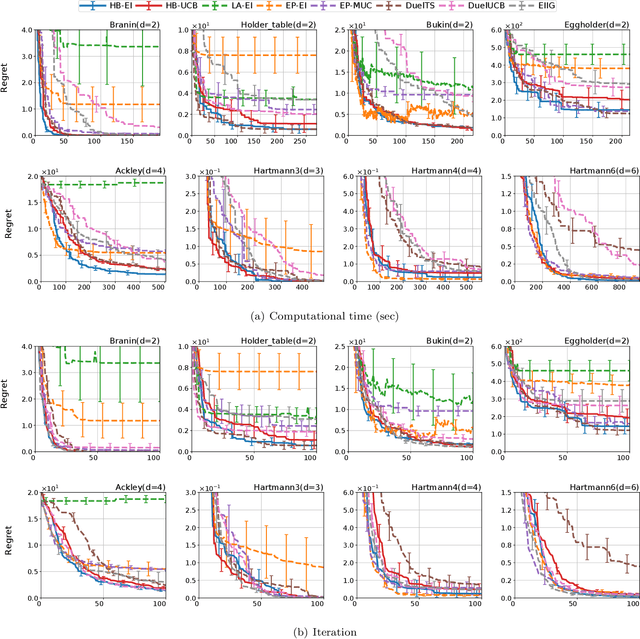
We study preferential Bayesian optimization (BO) where reliable feedback is limited to pairwise comparison called duels. An important challenge in preferential BO, which uses the preferential Gaussian process (GP) model to represent flexible preference structure, is that the posterior distribution is a computationally intractable skew GP. The most widely used approach for preferential BO is Gaussian approximation, which ignores the skewness of the true posterior. Alternatively, Markov chain Monte Carlo (MCMC) based preferential BO is also proposed. In this work, we first verify the accuracy of Gaussian approximation, from which we reveal the critical problem that the predictive probability of duels can be inaccurate. This observation motivates us to improve the MCMC-based estimation for skew GP, for which we show the practical efficiency of Gibbs sampling and derive the low variance MC estimator. However, the computational time of MCMC can still be a bottleneck in practice. Towards building a more practical preferential BO, we develop a new method that achieves both high computational efficiency and low sample complexity, and then demonstrate its effectiveness through extensive numerical experiments.
Coinductive guide to inductive transformer heads
Feb 03, 2023We argue that all building blocks of transformer models can be expressed with a single concept: combinatorial Hopf algebra. Transformer learning emerges as a result of the subtle interplay between the algebraic and coalgebraic operations of the combinatorial Hopf algebra. Viewed through this lens, the transformer model becomes a linear time-invariant system where the attention mechanism computes a generalized convolution transform and the residual stream serves as a unit impulse. Attention-only transformers then learn by enforcing an invariant between these two paths. We call this invariant Hopf coherence. Due to this, with a degree of poetic license, one could call combinatorial Hopf algebras "tensors with a built-in loss function gradient". This loss function gradient occurs within the single layers and no backward pass is needed. This is in contrast to automatic differentiation which happens across the whole graph and needs a explicit backward pass. This property is the result of the fact that combinatorial Hopf algebras have the surprising property of calculating eigenvalues by repeated squaring.
Are Labels Needed for Incremental Instance Learning?
Jan 26, 2023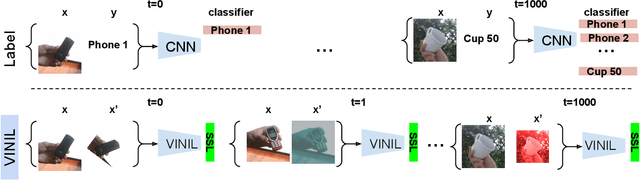
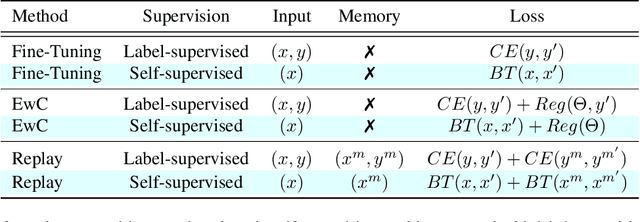
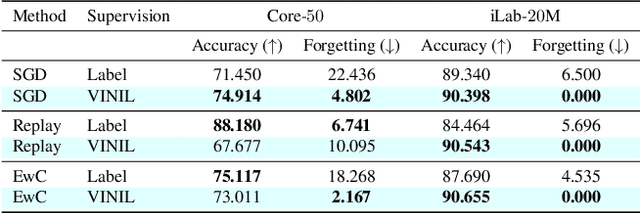
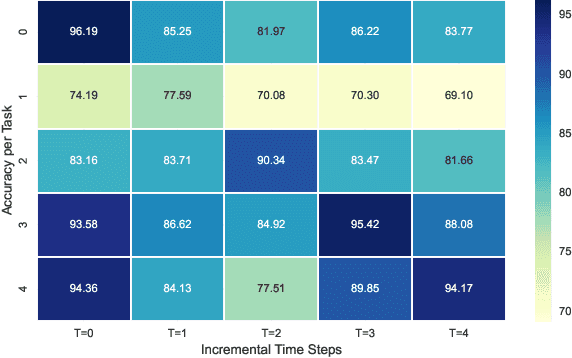
In this paper, we learn to classify visual object instances, incrementally and via self-supervision (self-incremental). Our learner observes a single instance at a time, which is then discarded from the dataset. Incremental instance learning is challenging, since longer learning sessions exacerbate forgetfulness, and labeling instances is cumbersome. We overcome these challenges via three contributions: \textit{i).} We propose VINIL, a self-incremental learner that can learn object instances sequentially, \textit{ii).} We equip VINIL with self-supervision to by-pass the need for instance labelling, \textit{iii).} We compare VINIL to label-supervised variants on two large-scale benchmarks~\cite{core50,ilab20m}, and show that VINIL significantly improves accuracy while reducing forgetfulness.