 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Big Little Transformer Decoder
Feb 15, 2023
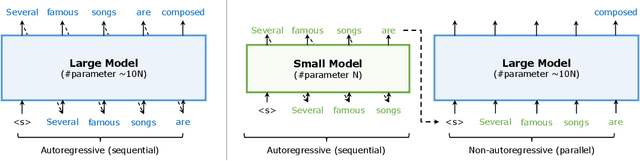
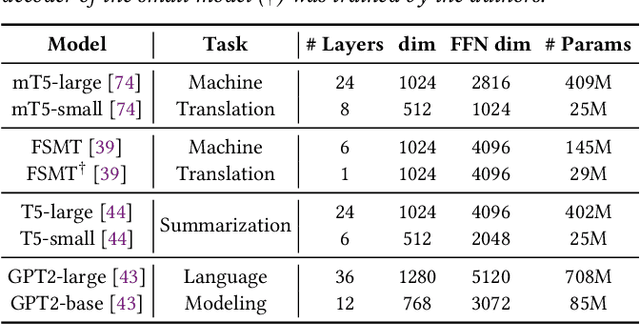
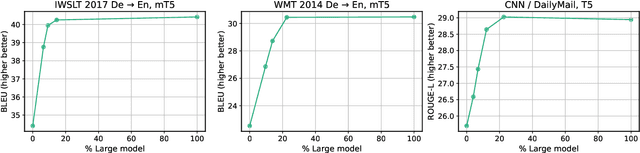
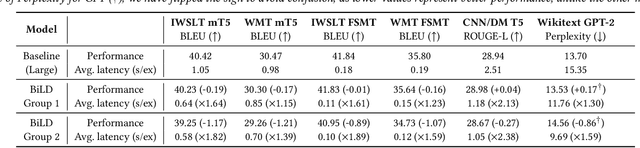
The recent emergence of Large Language Models based on the Transformer architecture has enabled dramatic advancements in the field of Natural Language Processing. However, these models have long inference latency, which limits their deployment, and which makes them prohibitively expensive for various real-time applications. The inference latency is further exacerbated by autoregressive generative tasks, as models need to run iteratively to generate tokens sequentially without leveraging token-level parallelization. To address this, we propose Big Little Decoder (BiLD), a framework that can improve inference efficiency and latency for a wide range of text generation applications. The BiLD framework contains two models with different sizes that collaboratively generate text. The small model runs autoregressively to generate text with a low inference cost, and the large model is only invoked occasionally to refine the small model's inaccurate predictions in a non-autoregressive manner. To coordinate the small and large models, BiLD introduces two simple yet effective policies: (1) the fallback policy that determines when to hand control over to the large model; and (2) the rollback policy that determines when the large model needs to review and correct the small model's inaccurate predictions. To evaluate our framework across different tasks and models, we apply BiLD to various text generation scenarios encompassing machine translation on IWSLT 2017 De-En and WMT 2014 De-En, summarization on CNN/DailyMail, and language modeling on WikiText-2. On an NVIDIA Titan Xp GPU, our framework achieves a speedup of up to 2.13x without any performance drop, and it achieves up to 2.38x speedup with only ~1 point degradation. Furthermore, our framework is fully plug-and-play as it does not require any training or modifications to model architectures. Our code will be open-sourced.
DONEX: Real-time occupancy grid based dynamic echo classification for 3D point cloud
Dec 08, 2022
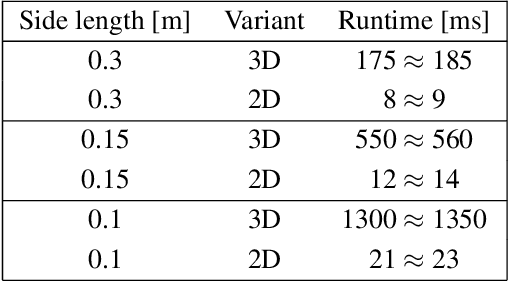
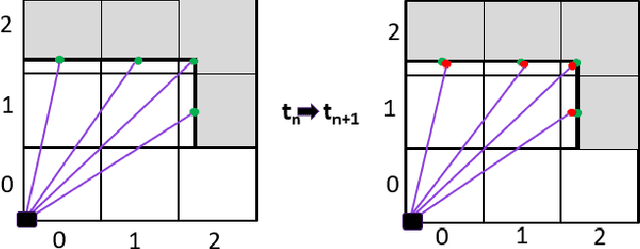
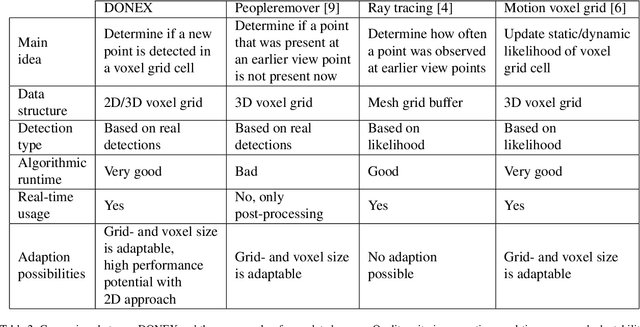
For driving assistance and autonomous driving systems, it is important to differentiate between dynamic objects such as moving vehicles and static objects such as guard rails. Among all the sensor modalities, RADAR and FMCW LiDAR can provide information regarding the motion state of the raw measurement data. On the other hand, perception pipelines using measurement data from ToF LiDAR typically can only differentiate between dynamic and static states on the object level. In this work, a new algorithm called DONEX was developed to classify the motion state of 3D LiDAR point cloud echoes using an occupancy grid approach. Through algorithmic improvements, e.g. 2D grid approach, it was possible to reduce the runtime. Scenarios, in which the measuring sensor is located in a moving vehicle, were also considered.
CILP: Co-simulation based Imitation Learner for Dynamic Resource Provisioning in Cloud Computing Environments
Feb 11, 2023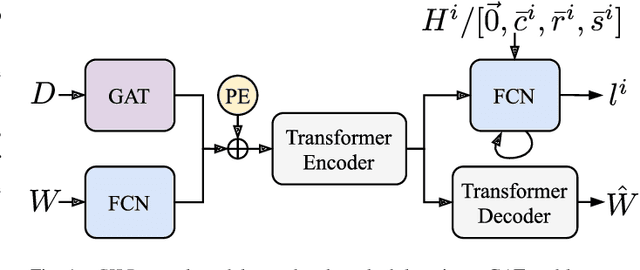
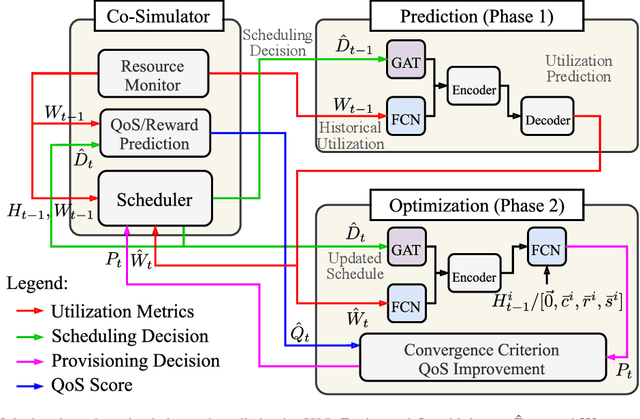
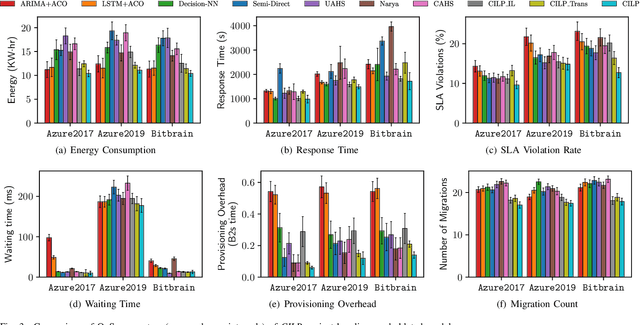

Intelligent Virtual Machine (VM) provisioning is central to cost and resource efficient computation in cloud computing environments. As bootstrapping VMs is time-consuming, a key challenge for latency-critical tasks is to predict future workload demands to provision VMs proactively. However, existing AI-based solutions \blue{tend to not holistically consider} all crucial aspects such as provisioning overheads, heterogeneous VM costs and Quality of Service (QoS) of the cloud system. To address this, we propose a novel method, called CILP, that formulates the VM provisioning problem as two sub-problems of prediction and optimization, where the provisioning plan is optimized based on predicted workload demands. CILP leverages a neural network as a surrogate model to predict future workload demands with a co-simulated digital-twin of the infrastructure to compute QoS scores. We extend the neural network to also act as an imitation learner that dynamically decides the optimal VM provisioning plan. A transformer based neural model reduces training and inference overheads while our novel two-phase decision making loop facilitates in making informed provisioning decisions. Crucially, we address limitations of prior work by including resource utilization, deployment costs and provisioning overheads to inform the provisioning decisions in our imitation learning framework. Experiments with three public benchmarks demonstrate that CILP gives up to 22% higher resource utilization, 14% higher QoS scores and 44% lower execution costs compared to the current online and offline optimization based state-of-the-art methods.
Consistency Regularisation in Varying Contexts and Feature Perturbations for Semi-Supervised Semantic Segmentation of Histology Images
Feb 11, 2023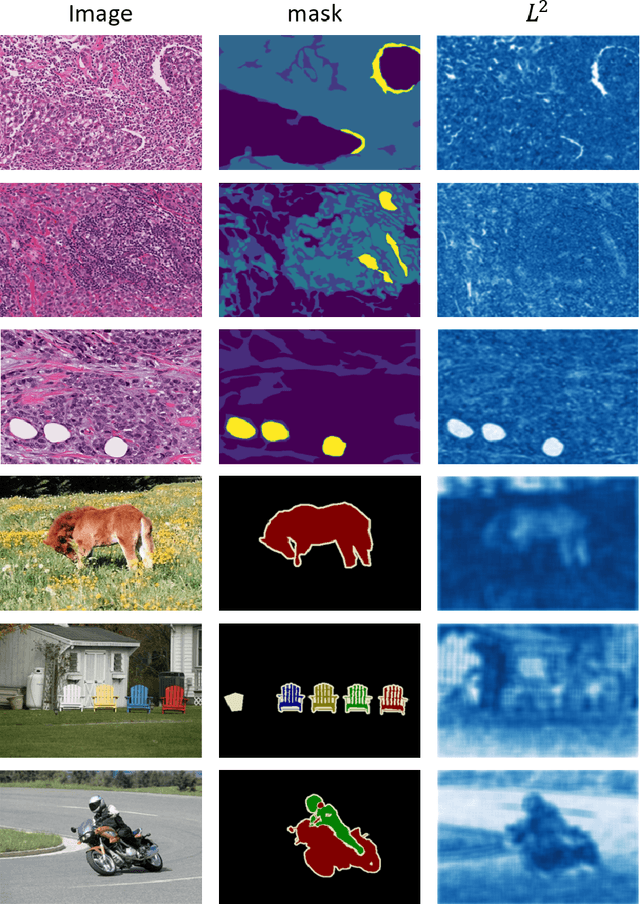
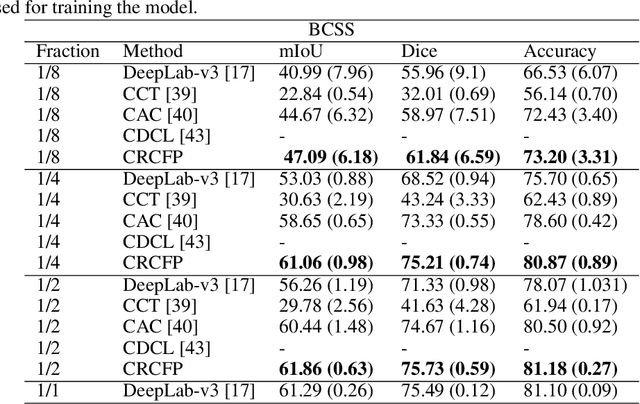
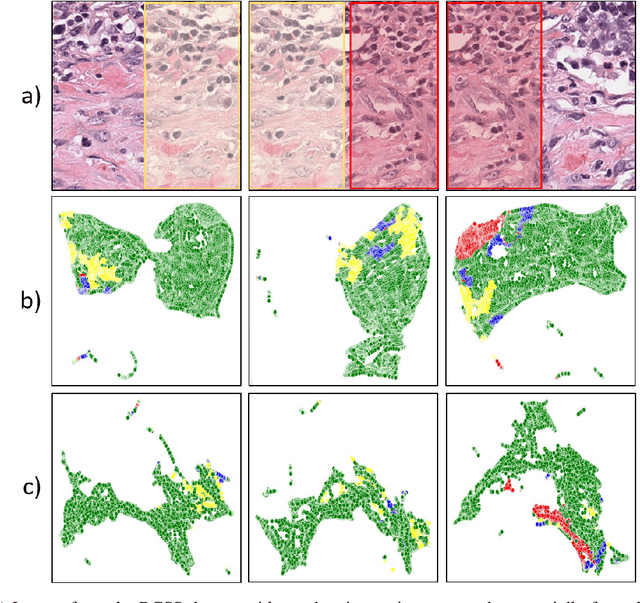
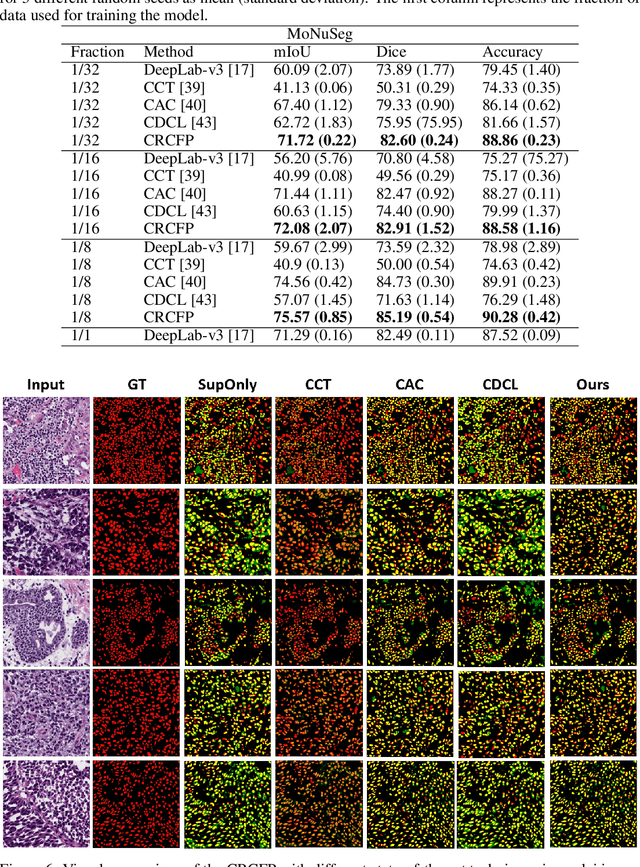
Semantic segmentation of various tissue and nuclei types in histology images is fundamental to many downstream tasks in the area of computational pathology (CPath). In recent years, Deep Learning (DL) methods have been shown to perform well on segmentation tasks but DL methods generally require a large amount of pixel-wise annotated data. Pixel-wise annotation sometimes requires expert's knowledge and time which is laborious and costly to obtain. In this paper, we present a consistency based semi-supervised learning (SSL) approach that can help mitigate this challenge by exploiting a large amount of unlabelled data for model training thus alleviating the need for a large annotated dataset. However, SSL models might also be susceptible to changing context and features perturbations exhibiting poor generalisation due to the limited training data. We propose an SSL method that learns robust features from both labelled and unlabelled images by enforcing consistency against varying contexts and feature perturbations. The proposed method incorporates context-aware consistency by contrasting pairs of overlapping images in a pixel-wise manner from changing contexts resulting in robust and context invariant features. We show that cross-consistency training makes the encoder features invariant to different perturbations and improves the prediction confidence. Finally, entropy minimisation is employed to further boost the confidence of the final prediction maps from unlabelled data. We conduct an extensive set of experiments on two publicly available large datasets (BCSS and MoNuSeg) and show superior performance compared to the state-of-the-art methods.
Deep Contrastive One-Class Time Series Anomaly Detection
Jul 04, 2022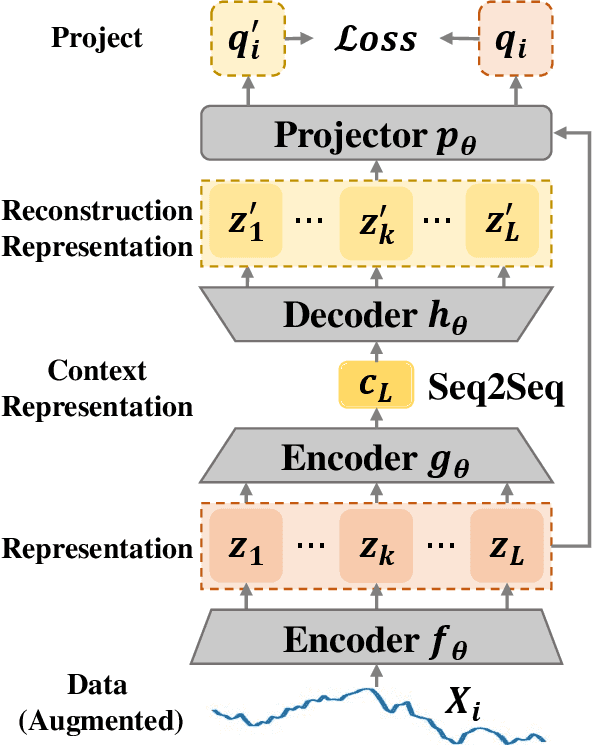
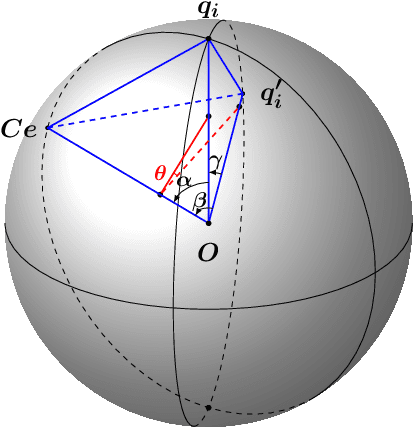
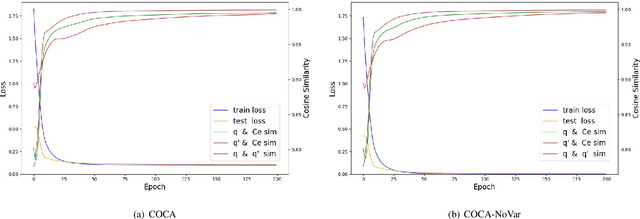
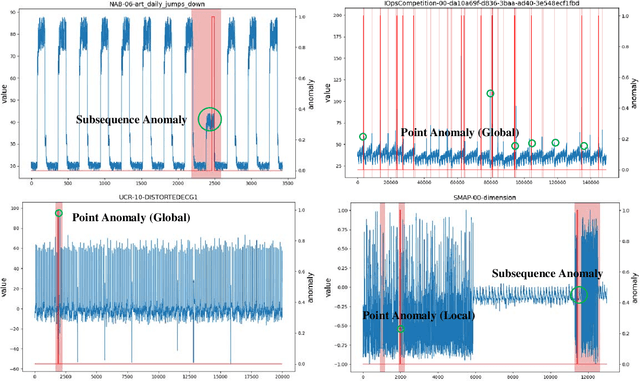
The accumulation of time series data and the absence of labels make time-series Anomaly Detection (AD) a self-supervised deep learning task. Single-assumption-based methods may only touch on a certain aspect of the whole normality, not sufficient to detect various anomalies. Among them, contrastive learning methods adopted for AD always choose negative pairs that are both normal to push away, which is objecting to AD tasks' purpose. Existing multi-assumption-based methods are usually two-staged, firstly applying a pre-training process whose target may differ from AD, so the performance is limited by the pre-trained representations. This paper proposes a deep Contrastive One-Class Anomaly detection method of time series (COCA), which combines the normality assumptions of contrastive learning and one-class classification. The key idea is to treat the representation and reconstructed representation as the positive pair of negative-samples-free contrastive learning, and we name it sequence contrast. Then we apply a contrastive one-class loss function composed of invariance and variance terms, the former optimizing loss of the two assumptions simultaneously, and the latter preventing hypersphere collapse. Extensive experiments conducted on four real-world time-series datasets show the superior performance of the proposed method achieves state-of-the-art. The code is publicly available at https://github.com/ruiking04/COCA.
Multi-Carrier Wideband OCDM-Based THz Automotive Radar
Feb 01, 2023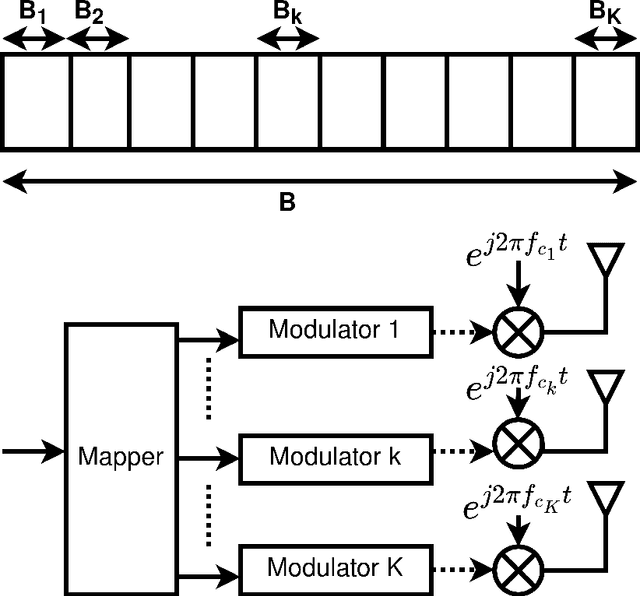
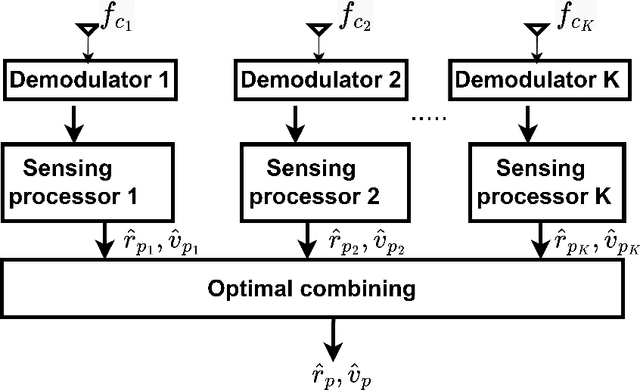
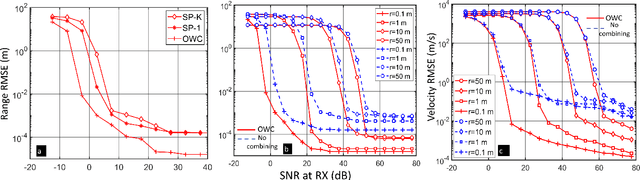
Automotive radars at the Terahertz (THz) frequency band have the potential to be compact and lightweight while providing high (nearly-optical) angular resolution. In this paper, we propose a bistatic THz automotive radar that employs the recently proposed orthogonal chirp division multiplexing (OCDM) multi-carrier waveform. As a stand-alone communications waveform, OCDM has been investigated for robustness against interference in time-frequency selective channels. The THz-band path loss, and, hence, radar signal bandwidth, are range-dependent. We address this unique feature through a multi-carrier wideband OCDM sensing transceiver that exploits the coherence bandwidth of the THz channel. We develop an optimal scheme to combine the returns at different range/bandwidths by assigning weights based on the Cramer-Rao lower bound on the range and velocity estimates. Numerical experiments demonstrate improved target estimates using our proposed combined estimation from multiple varied-attenuation THz frequencies.
Quickest Change Detection for Unnormalized Statistical Models
Feb 01, 2023
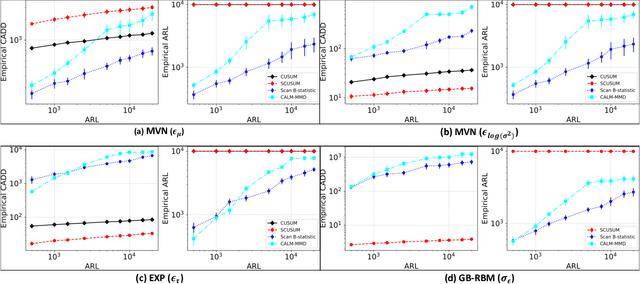
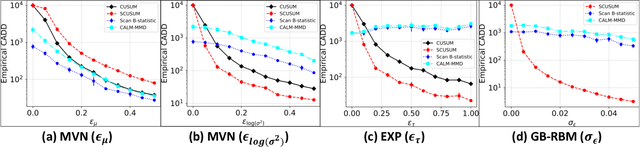

Classical quickest change detection algorithms require modeling pre-change and post-change distributions. Such an approach may not be feasible for various machine learning models because of the complexity of computing the explicit distributions. Additionally, these methods may suffer from a lack of robustness to model mismatch and noise. This paper develops a new variant of the classical Cumulative Sum (CUSUM) algorithm for the quickest change detection. This variant is based on Fisher divergence and the Hyv\"arinen score and is called the Score-based CUSUM (SCUSUM) algorithm. The SCUSUM algorithm allows the applications of change detection for unnormalized statistical models, i.e., models for which the probability density function contains an unknown normalization constant. The asymptotic optimality of the proposed algorithm is investigated by deriving expressions for average detection delay and the mean running time to a false alarm. Numerical results are provided to demonstrate the performance of the proposed algorithm.
Effectiveness of Moving Target Defenses for Adversarial Attacks in ML-based Malware Detection
Feb 01, 2023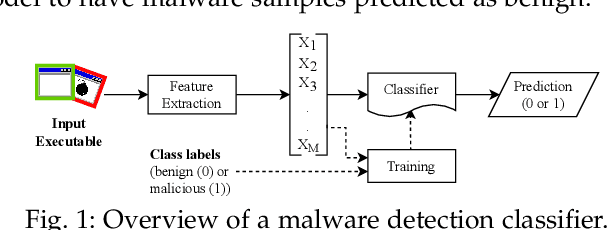
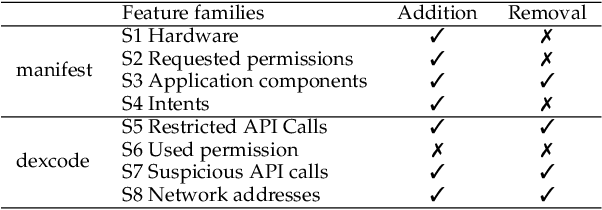
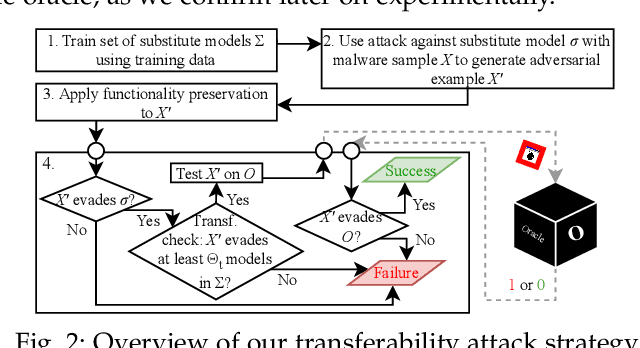
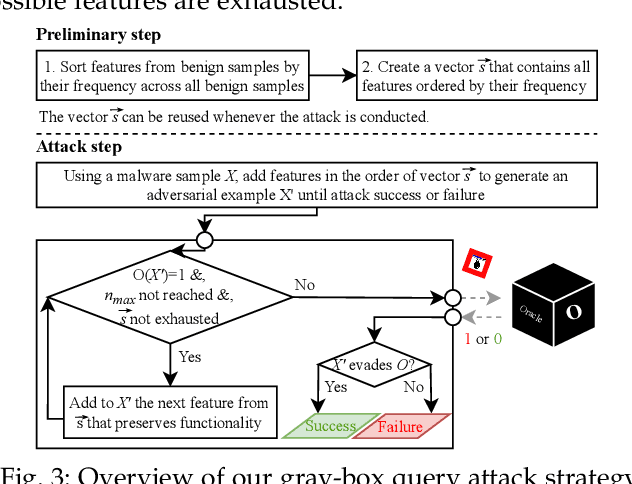
Several moving target defenses (MTDs) to counter adversarial ML attacks have been proposed in recent years. MTDs claim to increase the difficulty for the attacker in conducting attacks by regularly changing certain elements of the defense, such as cycling through configurations. To examine these claims, we study for the first time the effectiveness of several recent MTDs for adversarial ML attacks applied to the malware detection domain. Under different threat models, we show that transferability and query attack strategies can achieve high levels of evasion against these defenses through existing and novel attack strategies across Android and Windows. We also show that fingerprinting and reconnaissance are possible and demonstrate how attackers may obtain critical defense hyperparameters as well as information about how predictions are produced. Based on our findings, we present key recommendations for future work on the development of effective MTDs for adversarial attacks in ML-based malware detection.
A Log-Linear Non-Parametric Online Changepoint Detection Algorithm based on Functional Pruning
Feb 06, 2023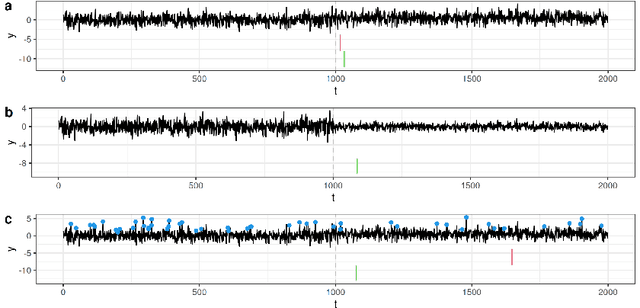
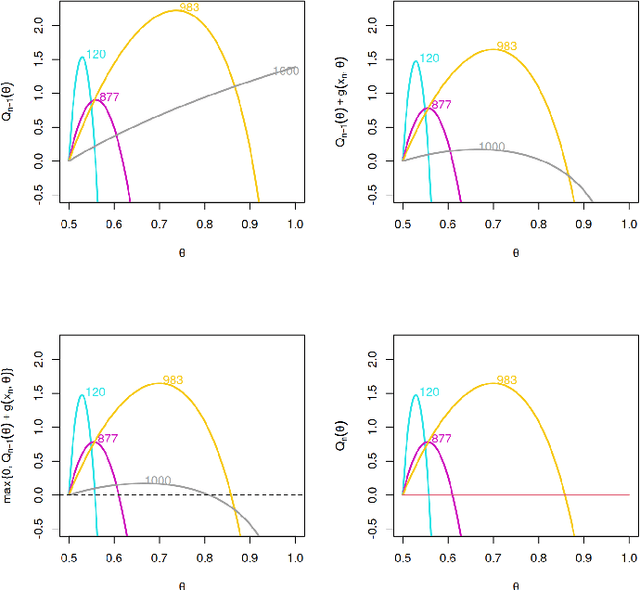
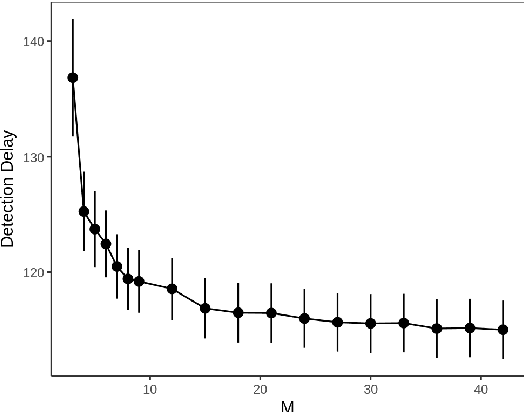
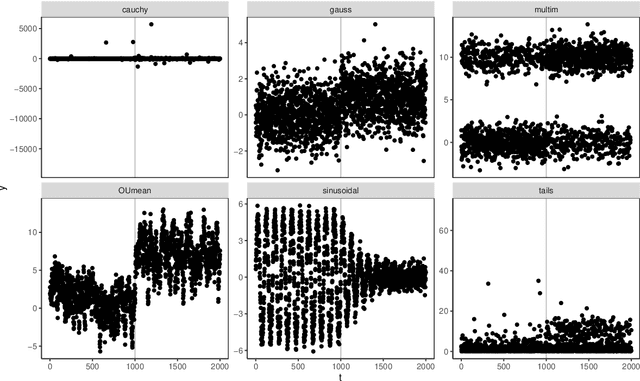
Online changepoint detection aims to detect anomalies and changes in real-time in high-frequency data streams, sometimes with limited available computational resources. This is an important task that is rooted in many real-world applications, including and not limited to cybersecurity, medicine and astrophysics. While fast and efficient online algorithms have been recently introduced, these rely on parametric assumptions which are often violated in practical applications. Motivated by data streams from the telecommunications sector, we build a flexible nonparametric approach to detect a change in the distribution of a sequence. Our procedure, NP-FOCuS, builds a sequential likelihood ratio test for a change in a set of points of the empirical cumulative density function of our data. This is achieved by keeping track of the number of observations above or below those points. Thanks to functional pruning ideas, NP-FOCuS has a computational cost that is log-linear in the number of observations and is suitable for high-frequency data streams. In terms of detection power, NP-FOCuS is seen to outperform current nonparametric online changepoint techniques in a variety of settings. We demonstrate the utility of the procedure on both simulated and real data.
Stochastic Gradient Descent-induced drift of representation in a two-layer neural network
Feb 06, 2023
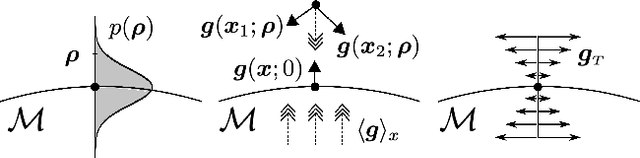
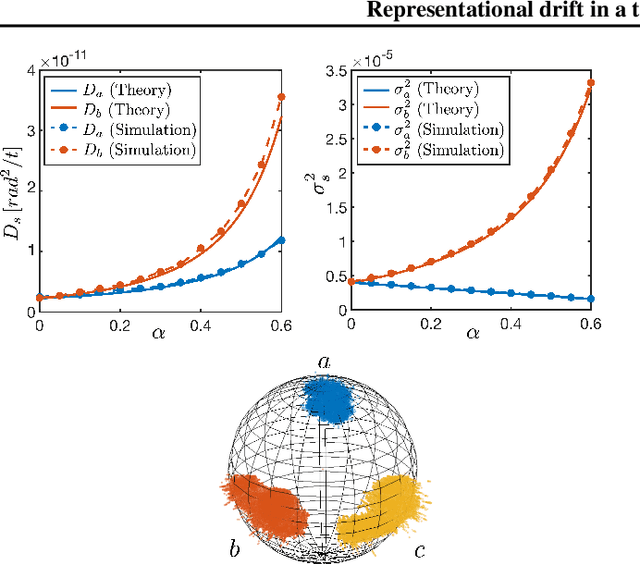
Representational drift refers to over-time changes in neural activation accompanied by a stable task performance. Despite being observed in the brain and in artificial networks, the mechanisms of drift and its implications are not fully understood. Motivated by recent experimental findings of stimulus-dependent drift in the piriform cortex, we use theory and simulations to study this phenomenon in a two-layer linear feedforward network. Specifically, in a continual learning scenario, we study the drift induced by the noise inherent in the Stochastic Gradient Descent (SGD). By decomposing the learning dynamics into the normal and tangent spaces of the minimum-loss manifold, we show the former correspond to a finite variance fluctuation, while the latter could be considered as an effective diffusion process on the manifold. We analytically compute the fluctuation and the diffusion coefficients for the stimuli representations in the hidden layer as a function of network parameters and input distribution. Further, consistent with experiments, we show that the drift rate is slower for a more frequently presented stimulus. Overall, our analysis yields a theoretical framework for better understanding of the drift phenomenon in biological and artificial neural networks.