 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Quickest Change Detection for Unnormalized Statistical Models
Feb 01, 2023

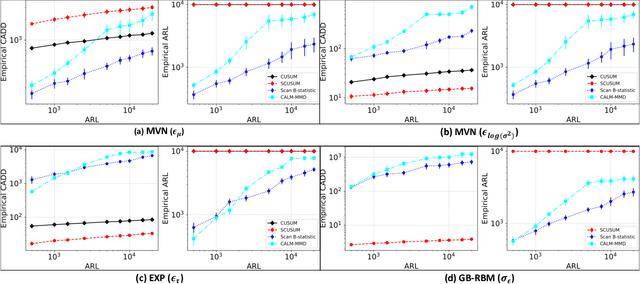
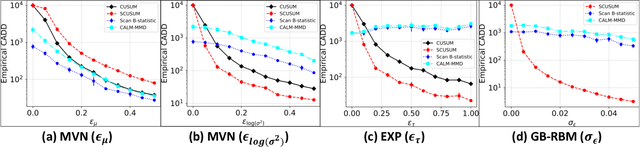

Classical quickest change detection algorithms require modeling pre-change and post-change distributions. Such an approach may not be feasible for various machine learning models because of the complexity of computing the explicit distributions. Additionally, these methods may suffer from a lack of robustness to model mismatch and noise. This paper develops a new variant of the classical Cumulative Sum (CUSUM) algorithm for the quickest change detection. This variant is based on Fisher divergence and the Hyv\"arinen score and is called the Score-based CUSUM (SCUSUM) algorithm. The SCUSUM algorithm allows the applications of change detection for unnormalized statistical models, i.e., models for which the probability density function contains an unknown normalization constant. The asymptotic optimality of the proposed algorithm is investigated by deriving expressions for average detection delay and the mean running time to a false alarm. Numerical results are provided to demonstrate the performance of the proposed algorithm.
Multi-Carrier Wideband OCDM-Based THz Automotive Radar
Feb 01, 2023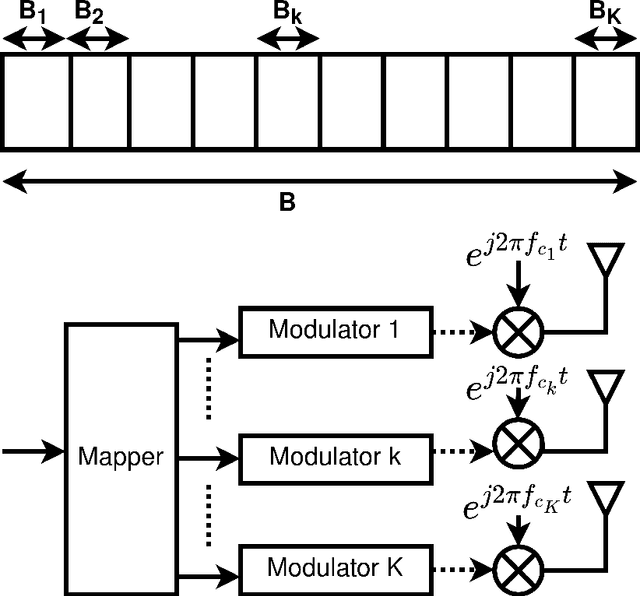
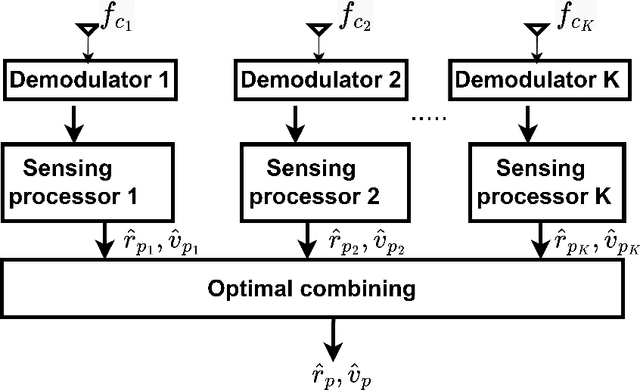
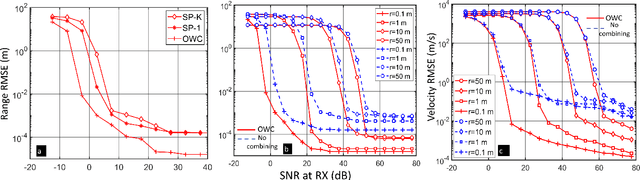
Automotive radars at the Terahertz (THz) frequency band have the potential to be compact and lightweight while providing high (nearly-optical) angular resolution. In this paper, we propose a bistatic THz automotive radar that employs the recently proposed orthogonal chirp division multiplexing (OCDM) multi-carrier waveform. As a stand-alone communications waveform, OCDM has been investigated for robustness against interference in time-frequency selective channels. The THz-band path loss, and, hence, radar signal bandwidth, are range-dependent. We address this unique feature through a multi-carrier wideband OCDM sensing transceiver that exploits the coherence bandwidth of the THz channel. We develop an optimal scheme to combine the returns at different range/bandwidths by assigning weights based on the Cramer-Rao lower bound on the range and velocity estimates. Numerical experiments demonstrate improved target estimates using our proposed combined estimation from multiple varied-attenuation THz frequencies.
Time Series Forecasting Models Copy the Past: How to Mitigate
Jul 27, 2022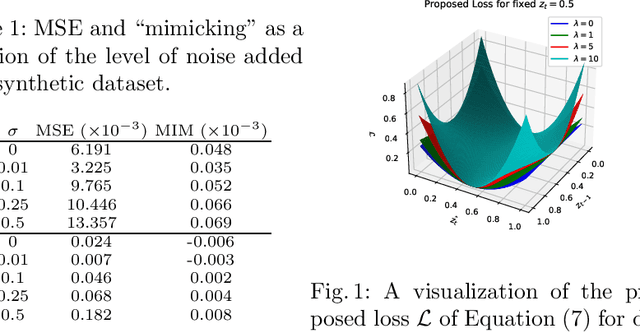
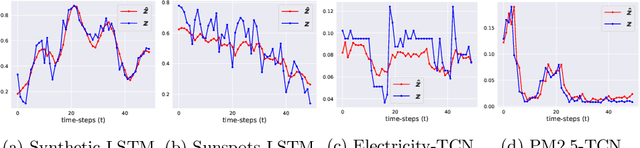
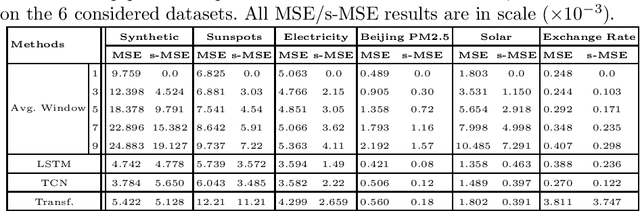
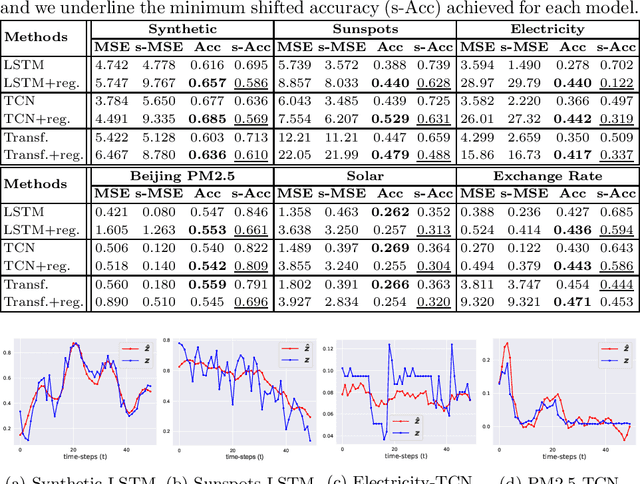
Time series forecasting is at the core of important application domains posing significant challenges to machine learning algorithms. Recently neural network architectures have been widely applied to the problem of time series forecasting. Most of these models are trained by minimizing a loss function that measures predictions' deviation from the real values. Typical loss functions include mean squared error (MSE) and mean absolute error (MAE). In the presence of noise and uncertainty, neural network models tend to replicate the last observed value of the time series, thus limiting their applicability to real-world data. In this paper, we provide a formal definition of the above problem and we also give some examples of forecasts where the problem is observed. We also propose a regularization term penalizing the replication of previously seen values. We evaluate the proposed regularization term both on synthetic and real-world datasets. Our results indicate that the regularization term mitigates to some extent the aforementioned problem and gives rise to more robust models.
$IC^3$: Image Captioning by Committee Consensus
Feb 02, 2023
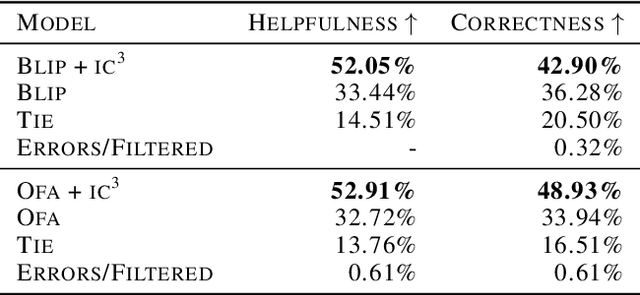
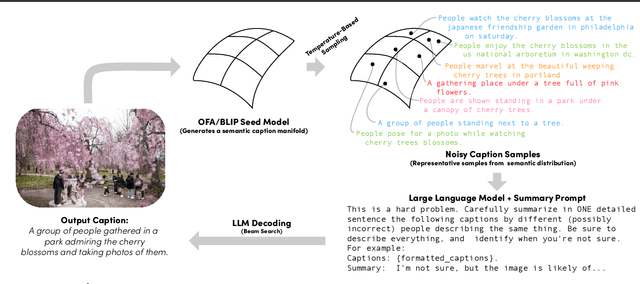
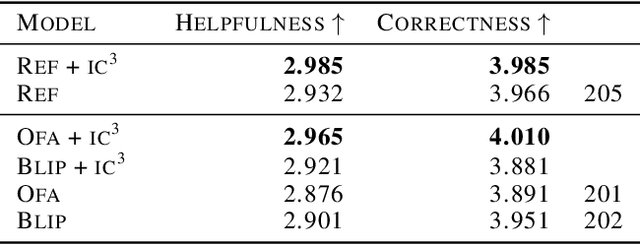
If you ask a human to describe an image, they might do so in a thousand different ways. Traditionally, image captioning models are trained to approximate the reference distribution of image captions, however, doing so encourages captions that are viewpoint-impoverished. Such captions often focus on only a subset of the possible details, while ignoring potentially useful information in the scene. In this work, we introduce a simple, yet novel, method: "Image Captioning by Committee Consensus" ($IC^3$), designed to generate a single caption that captures high-level details from several viewpoints. Notably, humans rate captions produced by $IC^3$ at least as helpful as baseline SOTA models more than two thirds of the time, and $IC^3$ captions can improve the performance of SOTA automated recall systems by up to 84%, indicating significant material improvements over existing SOTA approaches for visual description. Our code is publicly available at https://github.com/DavidMChan/caption-by-committee
SceneScape: Text-Driven Consistent Scene Generation
Feb 02, 2023
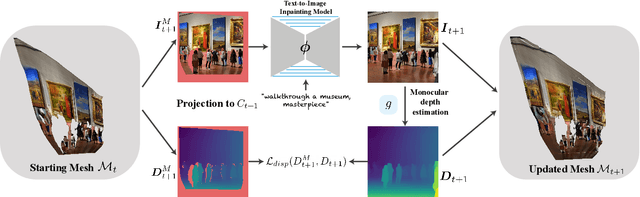
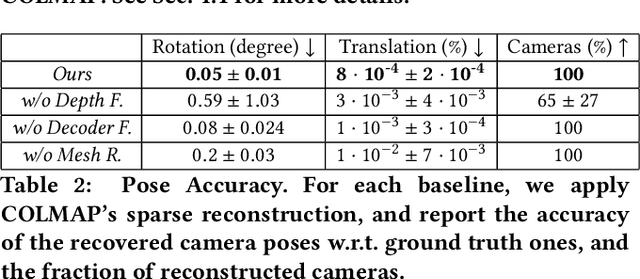

We propose a method for text-driven perpetual view generation -- synthesizing long videos of arbitrary scenes solely from an input text describing the scene and camera poses. We introduce a novel framework that generates such videos in an online fashion by combining the generative power of a pre-trained text-to-image model with the geometric priors learned by a pre-trained monocular depth prediction model. To achieve 3D consistency, i.e., generating videos that depict geometrically-plausible scenes, we deploy an online test-time training to encourage the predicted depth map of the current frame to be geometrically consistent with the synthesized scene; the depth maps are used to construct a unified mesh representation of the scene, which is updated throughout the generation and is used for rendering. In contrast to previous works, which are applicable only for limited domains (e.g., landscapes), our framework generates diverse scenes, such as walkthroughs in spaceships, caves, or ice castles. Project page: https://scenescape.github.io/
Scene2BIR: Material-aware learning-based binaural impulse response generator for reconstructed real-world 3D scenes
Feb 02, 2023
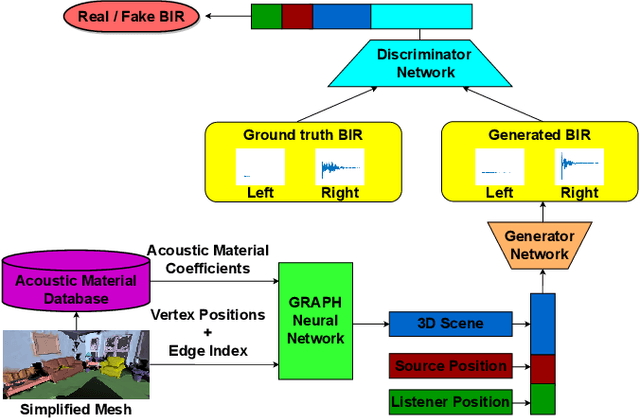
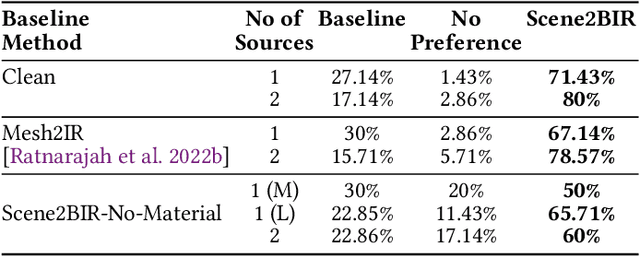
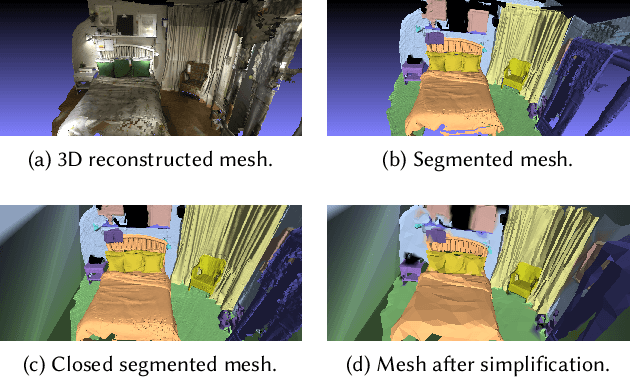
We present an end-to-end binaural impulse response generator (BIR) to generate plausible sounds in real-time for real-world models. Our approach uses a novel neural-network-based BIR generator (Scene2BIR) for the reconstructed 3D model. We propose a graph neural network that uses both the material and the topology information of the 3D scenes and generates a scene latent vector. Moreover, we use a conditional generative adversarial network (CGAN) to generate BIRs from the scene latent vector. Our network is able to handle holes or other artifacts in the reconstructed 3D mesh model. We present an efficient cost function to the generator network to incorporate spatial audio effects. Given the source and the listener position, our approach can generate a BIR in 0.1 milliseconds on an NVIDIA GeForce RTX 2080 Ti GPU and can easily handle multiple sources. We have evaluated the accuracy of our approach with real-world captured BIRs and an interactive geometric sound propagation algorithm.
A Light-weight CNN Model for Efficient Parkinson's Disease Diagnostics
Feb 02, 2023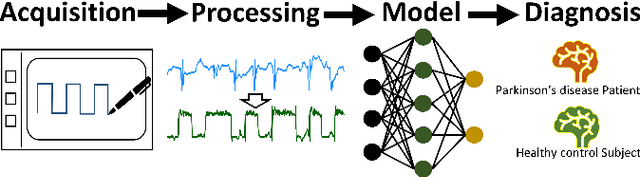

In recent years, deep learning methods have achieved great success in various fields due to their strong performance in practical applications. In this paper, we present a light-weight neural network for Parkinson's disease diagnostics, in which a series of hand-drawn data are collected to distinguish Parkinson's disease patients from healthy control subjects. The proposed model consists of a convolution neural network (CNN) cascading to long-short-term memory (LSTM) to adapt the characteristics of collected time-series signals. To make full use of their advantages, a multilayered LSTM model is firstly used to enrich features which are then concatenated with raw data and fed into a shallow one-dimensional (1D) CNN model for efficient classification. Experimental results show that the proposed model achieves a high-quality diagnostic result over multiple evaluation metrics with much fewer parameters and operations, outperforming conventional methods such as support vector machine (SVM), random forest (RF), lightgbm (LGB) and CNN-based methods.
Locally Constrained Policy Optimization for Online Reinforcement Learning in Non-Stationary Input-Driven Environments
Feb 04, 2023
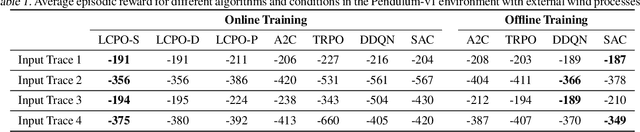
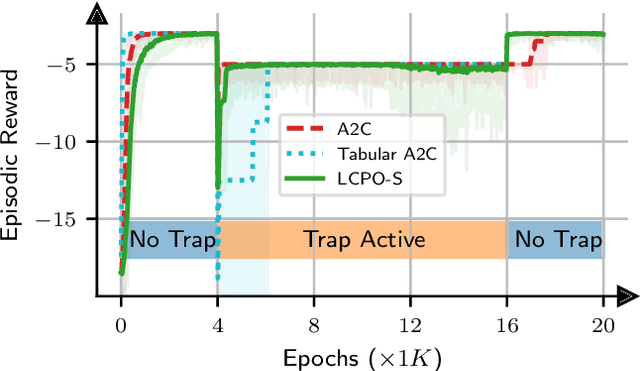

We study online Reinforcement Learning (RL) in non-stationary input-driven environments, where a time-varying exogenous input process affects the environment dynamics. Online RL is challenging in such environments due to catastrophic forgetting (CF). The agent tends to forget prior knowledge as it trains on new experiences. Prior approaches to mitigate this issue assume task labels (which are often not available in practice) or use off-policy methods that can suffer from instability and poor performance. We present Locally Constrained Policy Optimization (LCPO), an on-policy RL approach that combats CF by anchoring policy outputs on old experiences while optimizing the return on current experiences. To perform this anchoring, LCPO locally constrains policy optimization using samples from experiences that lie outside of the current input distribution. We evaluate LCPO in two gym and computer systems environments with a variety of synthetic and real input traces, and find that it outperforms state-of-the-art on-policy and off-policy RL methods in the online setting, while achieving results on-par with an offline agent pre-trained on the whole input trace.
Machine Learning-based Signal Quality Assessment for Cardiac Volume Monitoring in Electrical Impedance Tomography
Jan 04, 2023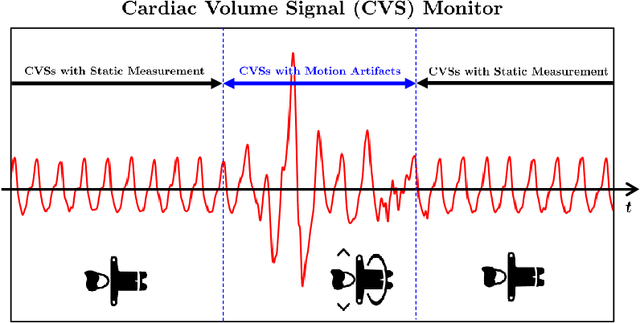
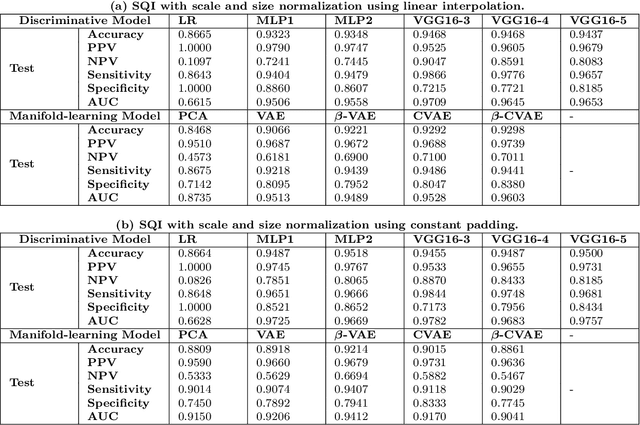
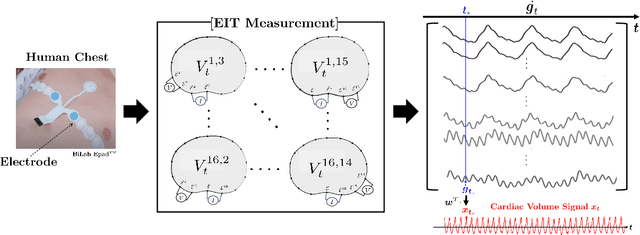
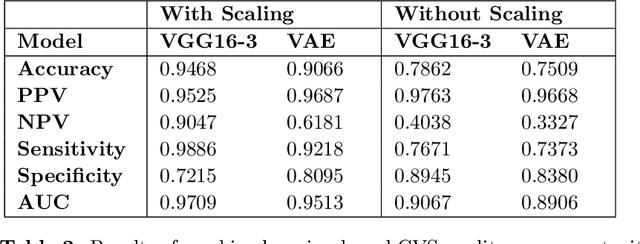
Owing to recent advances in thoracic electrical impedance tomography, a patient's hemodynamic function can be noninvasively and continuously estimated in real-time by surveilling a cardiac volume signal associated with stroke volume and cardiac output. In clinical applications, however, a cardiac volume signal is often of low quality, mainly because of the patient's deliberate movements or inevitable motions during clinical interventions. This study aims to develop a signal quality indexing method that assesses the influence of motion artifacts on transient cardiac volume signals. The assessment is performed on each cardiac cycle to take advantage of the periodicity and regularity in cardiac volume changes. Time intervals are identified using the synchronized electrocardiography system. We apply divergent machine-learning methods, which can be sorted into discriminative-model and manifold-learning approaches. The use of machine-learning could be suitable for our real-time monitoring application that requires fast inference and automation as well as high accuracy. In the clinical environment, the proposed method can be utilized to provide immediate warnings so that clinicians can minimize confusion regarding patients' conditions, reduce clinical resource utilization, and improve the confidence level of the monitoring system. Numerous experiments using actual EIT data validate the capability of cardiac volume signals degraded by motion artifacts to be accurately and automatically assessed in real-time by machine learning. The best model achieved an accuracy of 0.95, positive and negative predictive values of 0.96 and 0.86, sensitivity of 0.98, specificity of 0.77, and AUC of 0.96.
Transfer learning for time series classification using synthetic data generation
Jul 16, 2022In this paper, we propose an innovative Transfer learning for Time series classification method. Instead of using an existing dataset from the UCR archive as the source dataset, we generated a 15,000,000 synthetic univariate time series dataset that was created using our unique synthetic time series generator algorithm which can generate data with diverse patterns and angles and different sequence lengths. Furthermore, instead of using classification tasks provided by the UCR archive as the source task as previous studies did,we used our own 55 regression tasks as the source tasks, which produced better results than selecting classification tasks from the UCR archive