 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
E-commerce users' preferences for delivery options
Dec 30, 2022
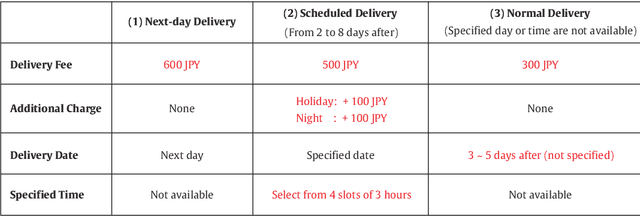

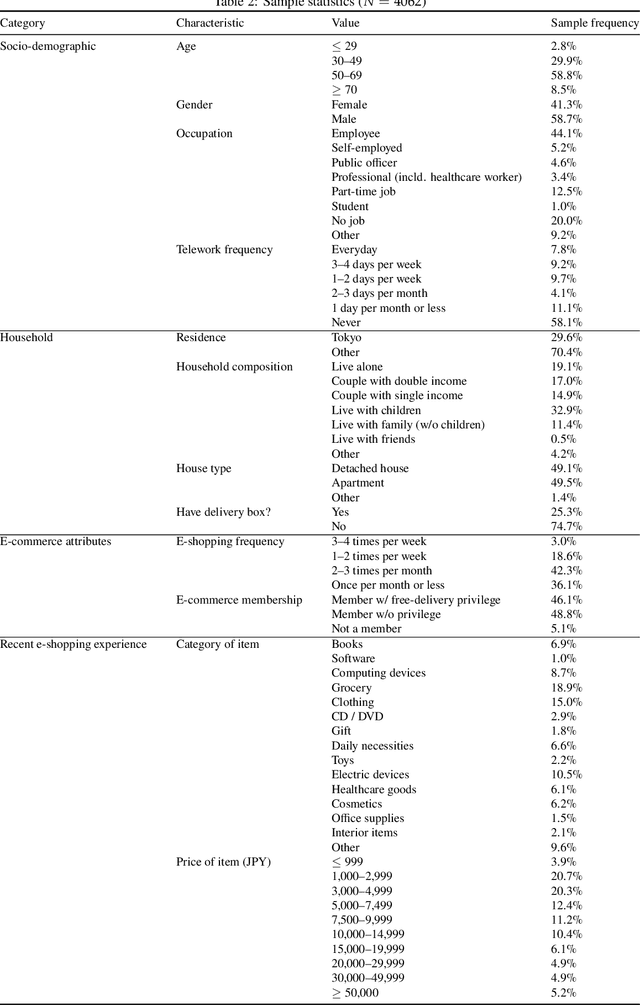
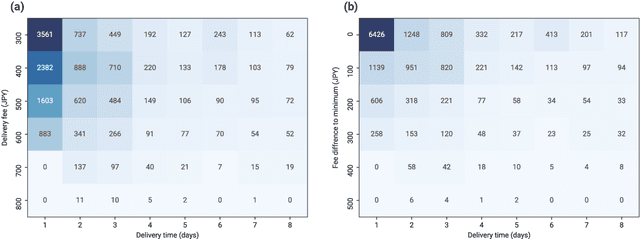
Many e-commerce marketplaces offer their users fast delivery options for free to meet the increasing needs of users, imposing an excessive burden on city logistics. Therefore, understanding e-commerce users' preference for delivery options is a key to designing logistics policies. To this end, this study designs a stated choice survey in which respondents are faced with choice tasks among different delivery options and time slots, which was completed by 4,062 users from the three major metropolitan areas in Japan. To analyze the data, mixed logit models capturing taste heterogeneity as well as flexible substitution patterns have been estimated. The model estimation results indicate that delivery attributes including fee, time, and time slot size are significant determinants of the delivery option choices. Associations between users' preferences and socio-demographic characteristics, such as age, gender, teleworking frequency and the presence of a delivery box, were also suggested. Moreover, we analyzed two willingness-to-pay measures for delivery, namely, the value of delivery time savings (VODT) and the value of time slot shortening (VOTS), and applied a non-semiparametric approach to estimate their distributions in a data-oriented manner. Although VODT has a large heterogeneity among respondents, the estimated median VODT is 25.6 JPY/day, implying that more than half of the respondents would wait an additional day if the delivery fee were increased by only 26 JPY, that is, they do not necessarily need a fast delivery option but often request it when cheap or almost free. Moreover, VOTS was found to be low, distributed with the median of 5.0 JPY/hour; that is, users do not highly value the reduction in time slot size in monetary terms. These findings on e-commerce users' preferences can help in designing levels of service for last-mile delivery to significantly improve its efficiency.
EgPDE-Net: Building Continuous Neural Networks for Time Series Prediction with Exogenous Variables
Aug 03, 2022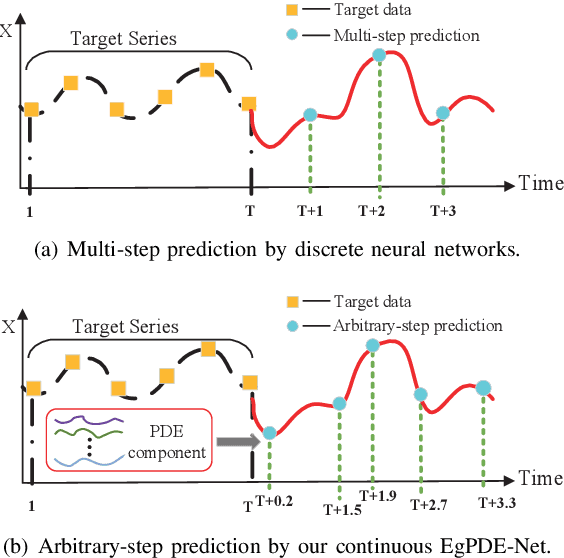
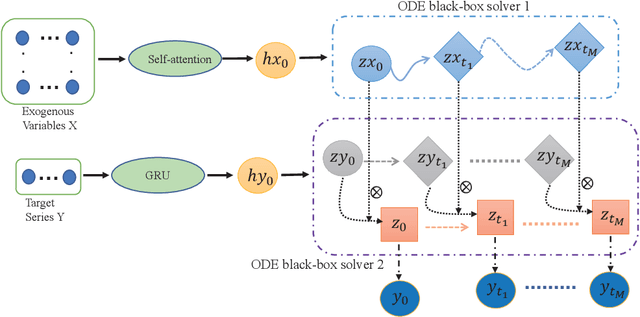
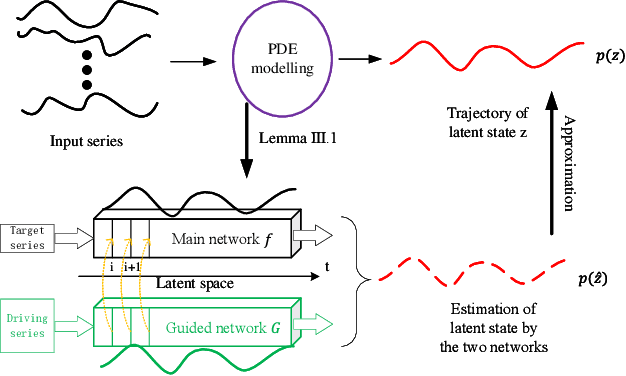
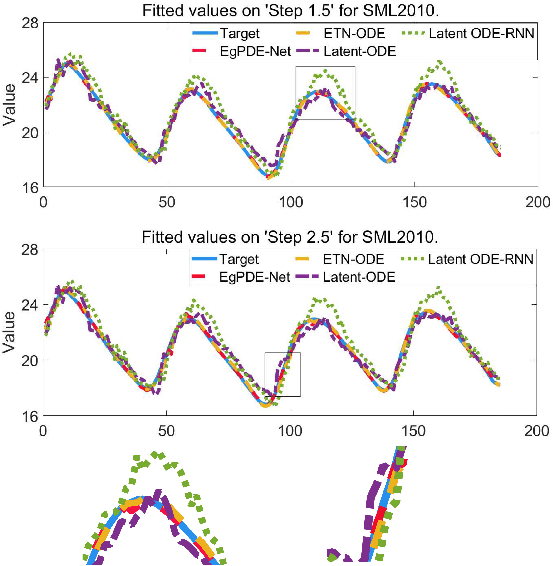
While exogenous variables have a major impact on performance improvement in time series analysis, inter-series correlation and time dependence among them are rarely considered in the present continuous methods. The dynamical systems of multivariate time series could be modelled with complex unknown partial differential equations (PDEs) which play a prominent role in many disciplines of science and engineering. In this paper, we propose a continuous-time model for arbitrary-step prediction to learn an unknown PDE system in multivariate time series whose governing equations are parameterised by self-attention and gated recurrent neural networks. The proposed model, \underline{E}xogenous-\underline{g}uided \underline{P}artial \underline{D}ifferential \underline{E}quation Network (EgPDE-Net), takes account of the relationships among the exogenous variables and their effects on the target series. Importantly, the model can be reduced into a regularised ordinary differential equation (ODE) problem with special designed regularisation guidance, which makes the PDE problem tractable to obtain numerical solutions and feasible to predict multiple future values of the target series at arbitrary time points. Extensive experiments demonstrate that our proposed model could achieve competitive accuracy over strong baselines: on average, it outperforms the best baseline by reducing $9.85\%$ on RMSE and $13.98\%$ on MAE for arbitrary-step prediction.
Local Differential Privacy for Sequential Decision Making in a Changing Environment
Jan 02, 2023We study the problem of preserving privacy while still providing high utility in sequential decision making scenarios in a changing environment. We consider abruptly changing environment: the environment remains constant during periods and it changes at unknown time instants. To formulate this problem, we propose a variant of multi-armed bandits called non-stationary stochastic corrupt bandits. We construct an algorithm called SW-KLUCB-CF and prove an upper bound on its utility using the performance measure of regret. The proven regret upper bound for SW-KLUCB-CF is near-optimal in the number of time steps and matches the best known bound for analogous problems in terms of the number of time steps and the number of changes. Moreover, we present a provably optimal mechanism which can guarantee the desired level of local differential privacy while providing high utility.
Test-Time Adaptation via Conjugate Pseudo-labels
Jul 20, 2022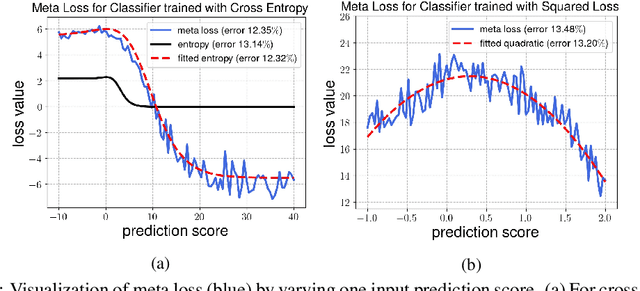
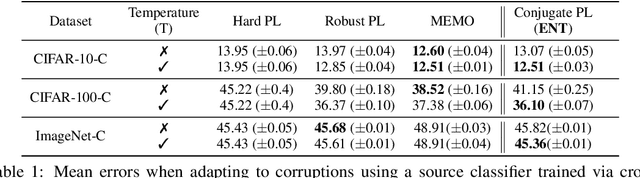
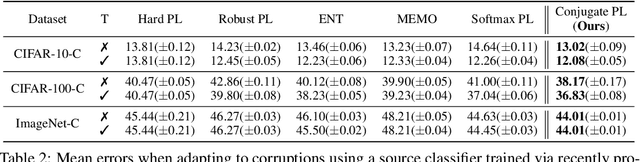
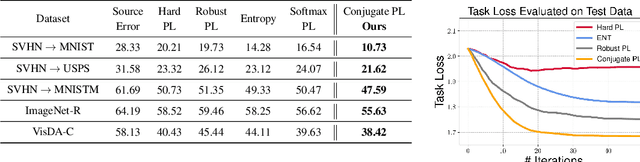
Test-time adaptation (TTA) refers to adapting neural networks to distribution shifts, with access to only the unlabeled test samples from the new domain at test-time. Prior TTA methods optimize over unsupervised objectives such as the entropy of model predictions in TENT [Wang et al., 2021], but it is unclear what exactly makes a good TTA loss. In this paper, we start by presenting a surprising phenomenon: if we attempt to meta-learn the best possible TTA loss over a wide class of functions, then we recover a function that is remarkably similar to (a temperature-scaled version of) the softmax-entropy employed by TENT. This only holds, however, if the classifier we are adapting is trained via cross-entropy; if trained via squared loss, a different best TTA loss emerges. To explain this phenomenon, we analyze TTA through the lens of the training losses's convex conjugate. We show that under natural conditions, this (unsupervised) conjugate function can be viewed as a good local approximation to the original supervised loss and indeed, it recovers the best losses found by meta-learning. This leads to a generic recipe that can be used to find a good TTA loss for any given supervised training loss function of a general class. Empirically, our approach consistently dominates other baselines over a wide range of benchmarks. Our approach is particularly of interest when applied to classifiers trained with novel loss functions, e.g., the recently-proposed PolyLoss, where it differs substantially from (and outperforms) an entropy-based loss. Further, we show that our approach can also be interpreted as a kind of self-training using a very specific soft label, which we refer to as the conjugate pseudolabel. Overall, our method provides a broad framework for better understanding and improving test-time adaptation. Code is available at https://github.com/locuslab/tta_conjugate.
A novel dataset and a two-stage mitosis nuclei detection method based on hybrid anchor branch
Jan 18, 2023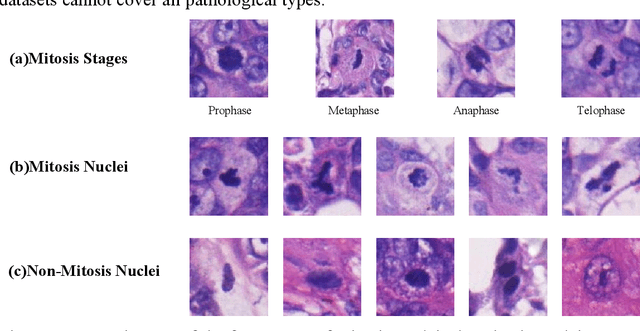

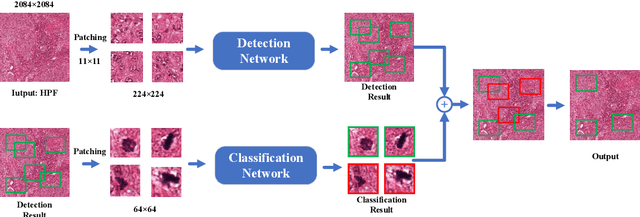
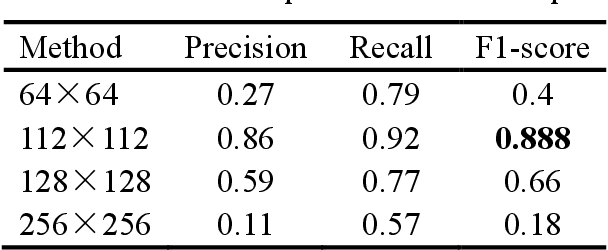
Mitosis detection is one of the challenging problems in computational pathology, and mitotic count is an important index of cancer grading for pathologists. However, current counts of mitotic nuclei rely on pathologists looking microscopically at the number of mitotic nuclei in hot spots, which is subjective and time-consuming. In this paper, we propose a two-stage cascaded network, named FoCasNet, for mitosis detection. In the first stage, a detection network named M_det is proposed to detect as many mitoses as possible. In the second stage, a classification network M_class is proposed to refine the results of the first stage. In addition, the attention mechanism, normalization method, and hybrid anchor branch classification subnet are introduced to improve the overall detection performance. Our method achieves the current highest F1-score of 0.888 on the public dataset ICPR 2012. We also evaluated our method on the GZMH dataset released by our research team for the first time and reached the highest F1-score of 0.563, which is also better than multiple classic detection networks widely used at present. It confirmed the effectiveness and generalization of our method. The code will be available at: https://github.com/antifen/mitosis-nuclei-detection.
Dereverberation in Acoustic Sensor Networks Using Weighted Prediction Error With Microphone-dependent Prediction Delays
Jan 18, 2023
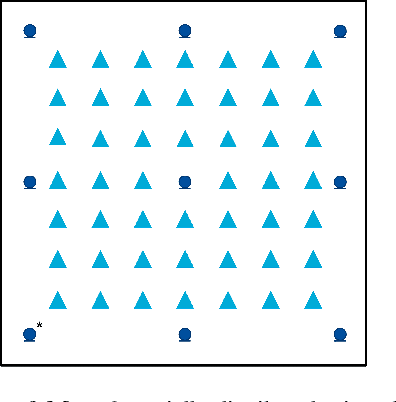
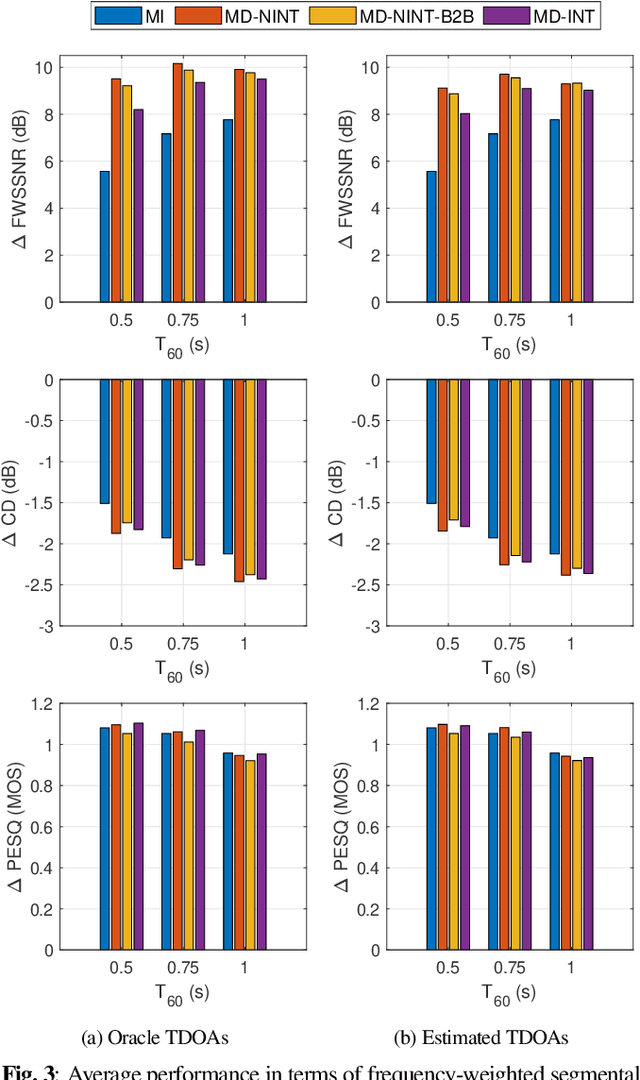
In the last decades several multi-microphone speech dereverberation algorithms have been proposed, among which the weighted prediction error (WPE) algorithm. In the WPE algorithm, a prediction delay is required to reduce the correlation between the prediction signals and the direct component in the reference microphone signal. In compact arrays with closely-spaced microphones, the prediction delay is often chosen microphone-independent. In acoustic sensor networks with spatially distributed microphones, large time-differences-of-arrival (TDOAs) of the speech source between the reference microphone and other microphones typically occur. Hence, when using a microphone-independent prediction delay the reference and prediction signals may still be significantly correlated, leading to distortion in the dereverberated output signal. In order to decorrelate the signals, in this paper we propose to apply TDOA compensation with respect to the reference microphone, resulting in microphone-dependent prediction delays for the WPE algorithm. We consider both optimal TDOA compensation using crossband filtering in the short-time Fourier transform domain as well as band-to-band and integer delay approximations. Simulation results for different reverberation times using oracle as well as estimated TDOAs clearly show the benefit of using microphone-dependent prediction delays.
Deep learning enhanced noise spectroscopy of a spin qubit environment
Jan 12, 2023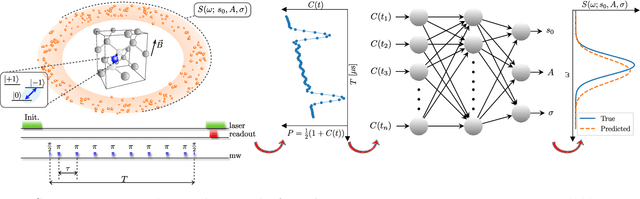
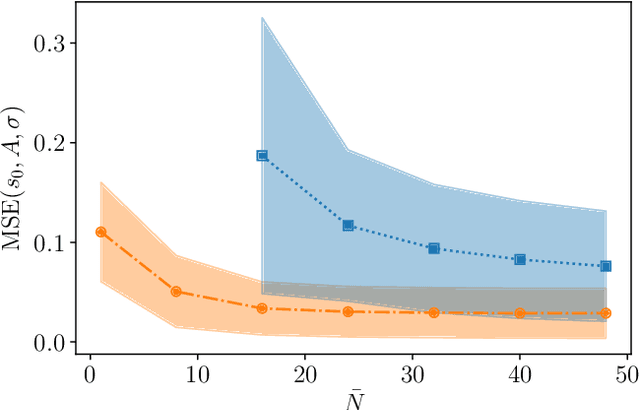
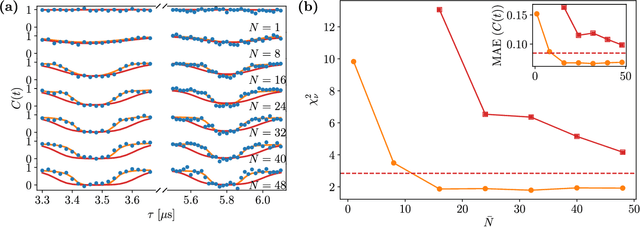
The undesired interaction of a quantum system with its environment generally leads to a coherence decay of superposition states in time. A precise knowledge of the spectral content of the noise induced by the environment is crucial to protect qubit coherence and optimize its employment in quantum device applications. We experimentally show that the use of neural networks can highly increase the accuracy of noise spectroscopy, by reconstructing the power spectral density that characterizes an ensemble of carbon impurities around a nitrogen-vacancy (NV) center in diamond. Neural networks are trained over spin coherence functions of the NV center subjected to different Carr-Purcell sequences, typically used for dynamical decoupling (DD). As a result, we determine that deep learning models can be more accurate than standard DD noise-spectroscopy techniques, by requiring at the same time a much smaller number of DD sequences.
Learning Reservoir Dynamics with Temporal Self-Modulation
Jan 23, 2023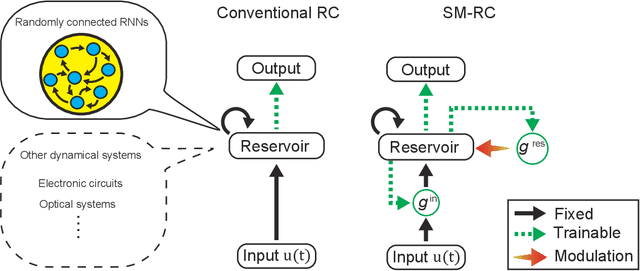
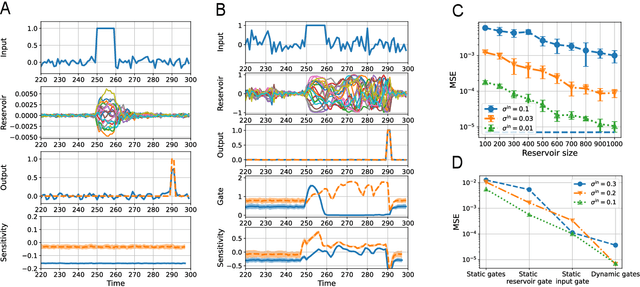
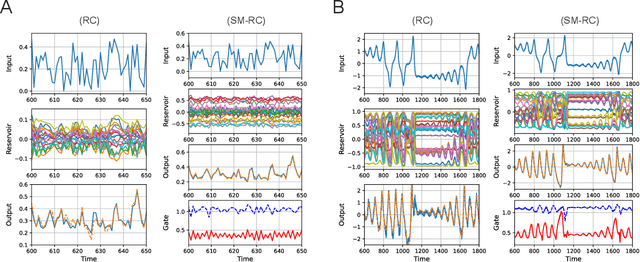
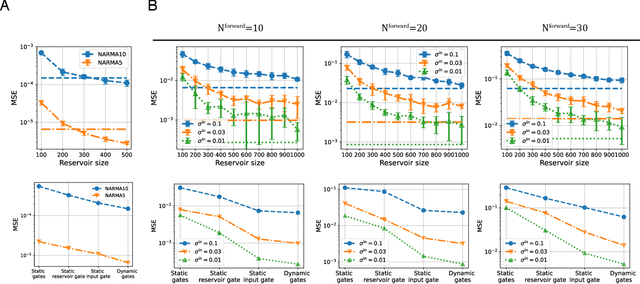
Reservoir computing (RC) can efficiently process time-series data by transferring the input signal to randomly connected recurrent neural networks (RNNs), which are referred to as a reservoir. The high-dimensional representation of time-series data in the reservoir significantly simplifies subsequent learning tasks. Although this simple architecture allows fast learning and facile physical implementation, the learning performance is inferior to that of other state-of-the-art RNN models. In this paper, to improve the learning ability of RC, we propose self-modulated RC (SM-RC), which extends RC by adding a self-modulation mechanism. The self-modulation mechanism is realized with two gating variables: an input gate and a reservoir gate. The input gate modulates the input signal, and the reservoir gate modulates the dynamical properties of the reservoir. We demonstrated that SM-RC can perform attention tasks where input information is retained or discarded depending on the input signal. We also found that a chaotic state emerged as a result of learning in SM-RC. This indicates that self-modulation mechanisms provide RC with qualitatively different information-processing capabilities. Furthermore, SM-RC outperformed RC in NARMA and Lorentz model tasks. In particular, SM-RC achieved a higher prediction accuracy than RC with a reservoir 10 times larger in the Lorentz model tasks. Because the SM-RC architecture only requires two additional gates, it is physically implementable as RC, providing a new direction for realizing edge AI.
Earthquake Magnitude and b value prediction model using Extreme Learning Machine
Jan 23, 2023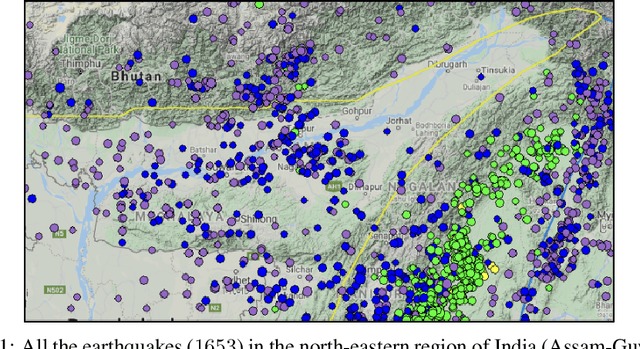
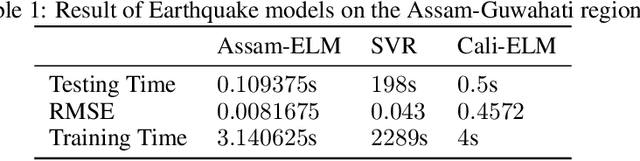
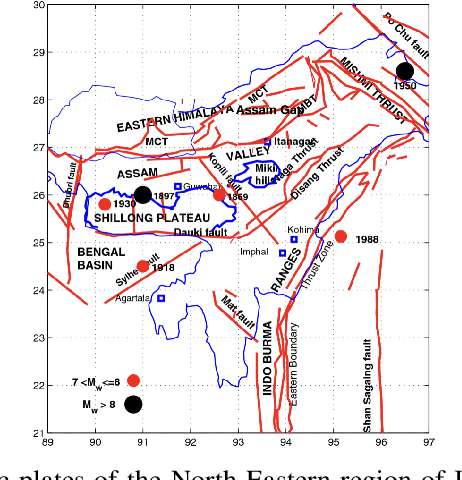

Earthquake prediction has been a challenging research area for many decades, where the future occurrence of this highly uncertain calamity is predicted. In this paper, several parametric and non-parametric features were calculated, where the non-parametric features were calculated using the parametric features. $8$ seismic features were calculated using Gutenberg-Richter law, the total recurrence, and the seismic energy release. Additionally, criterions such as Maximum Relevance and Maximum Redundancy were applied to choose the pertinent features. These features along with others were used as input for an Extreme Learning Machine (ELM) Regression Model. Magnitude and time data of $5$ decades from the Assam-Guwahati region were used to create this model for magnitude prediction. The Testing Accuracy and Testing Speed were computed taking the Root Mean Squared Error (RMSE) as the parameter for evaluating the mode. As confirmed by the results, ELM shows better scalability with much faster training and testing speed (up to a thousand times faster) than traditional Support Vector Machines. The testing RMSE came out to be around $0.097$. To further test the model's robustness -- magnitude-time data from California was used to calculate the seismic indicators which were then fed into an ELM and then tested on the Assam-Guwahati region. The model proves to be robust and can be implemented in early warning systems as it continues to be a major part of Disaster Response and management.
Toward Foundation Models for Earth Monitoring: Generalizable Deep Learning Models for Natural Hazard Segmentation
Jan 23, 2023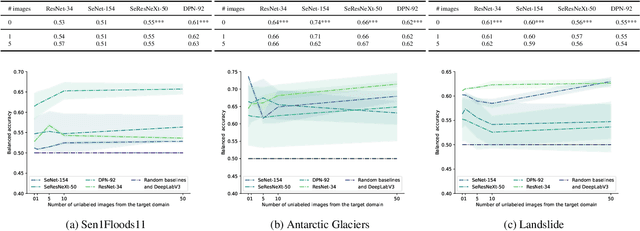
Climate change results in an increased probability of extreme weather events that put societies and businesses at risk on a global scale. Therefore, near real-time mapping of natural hazards is an emerging priority for the support of natural disaster relief, risk management, and informing governmental policy decisions. Recent methods to achieve near real-time mapping increasingly leverage deep learning (DL). However, DL-based approaches are designed for one specific task in a single geographic region based on specific frequency bands of satellite data. Therefore, DL models used to map specific natural hazards struggle with their generalization to other types of natural hazards in unseen regions. In this work, we propose a methodology to significantly improve the generalizability of DL natural hazards mappers based on pre-training on a suitable pre-task. Without access to any data from the target domain, we demonstrate this improved generalizability across four U-Net architectures for the segmentation of unseen natural hazards. Importantly, our method is invariant to geographic differences and differences in the type of frequency bands of satellite data. By leveraging characteristics of unlabeled images from the target domain that are publicly available, our approach is able to further improve the generalization behavior without fine-tuning. Thereby, our approach supports the development of foundation models for earth monitoring with the objective of directly segmenting unseen natural hazards across novel geographic regions given different sources of satellite imagery.