 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Insights for Digital Marketing Content Design
Feb 02, 2023
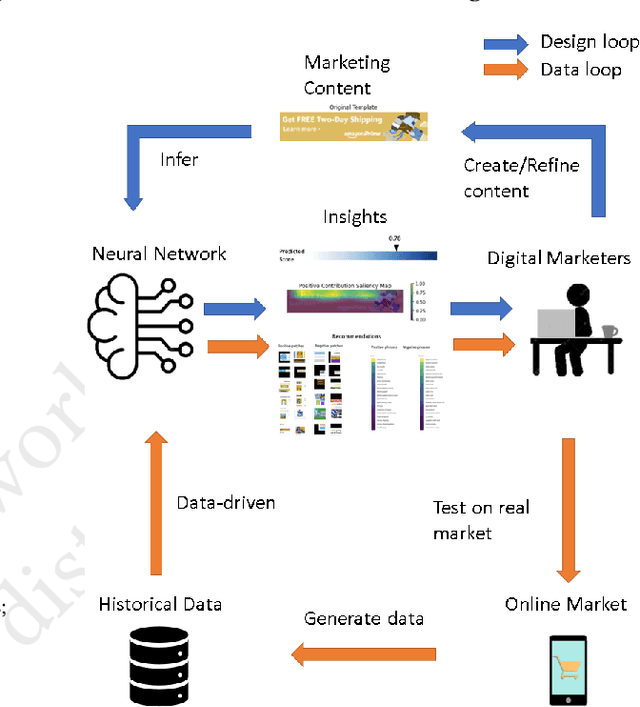
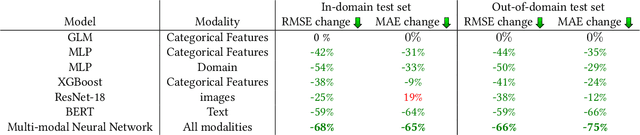
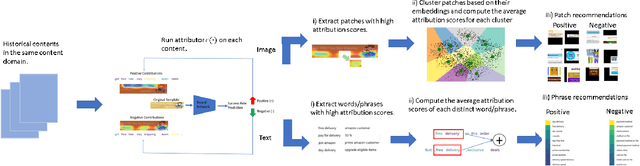

In digital marketing, experimenting with new website content is one of the key levers to improve customer engagement. However, creating successful marketing content is a manual and time-consuming process that lacks clear guiding principles. This paper seeks to close the loop between content creation and online experimentation by offering marketers AI-driven actionable insights based on historical data to improve their creative process. We present a neural-network-based system that scores and extracts insights from a marketing content design, namely, a multimodal neural network predicts the attractiveness of marketing contents, and a post-hoc attribution method generates actionable insights for marketers to improve their content in specific marketing locations. Our insights not only point out the advantages and drawbacks of a given current content, but also provide design recommendations based on historical data. We show that our scoring model and insights work well both quantitatively and qualitatively.
Neural Network Architecture for Database Augmentation Using Shared Features
Feb 02, 2023

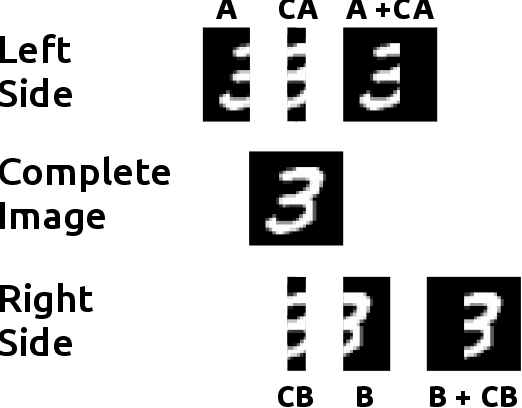
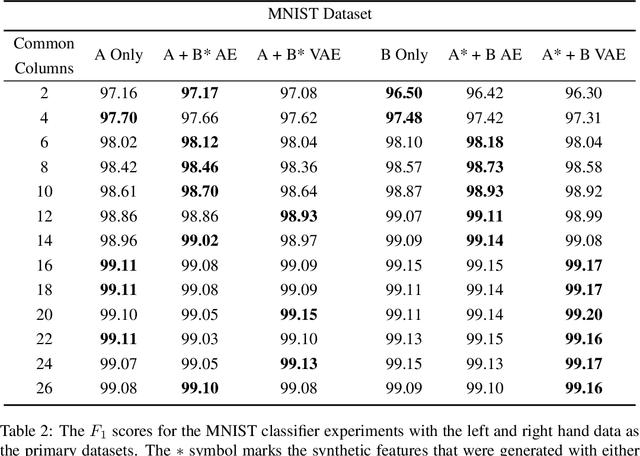
The popularity of learning from data with machine learning and neural networks has lead to the creation of many new datasets for almost every problem domain. However, even within a single domain, these datasets are often collected with disparate features, sampled from different sub-populations, and recorded at different time points. Even with the plethora of individual datasets, large data science projects can be difficult as it is often not trivial to merge these smaller datasets. Inherent challenges in some domains such as medicine also makes it very difficult to create large single source datasets or multi-source datasets with identical features. Instead of trying to merge these non-matching datasets directly, we propose a neural network architecture that can provide data augmentation using features common between these datasets. Our results show that this style of data augmentation can work for both image and tabular data.
Dynamic Atomic Column Detection in Transmission Electron Microscopy Videos via Ridge Estimation
Feb 02, 2023
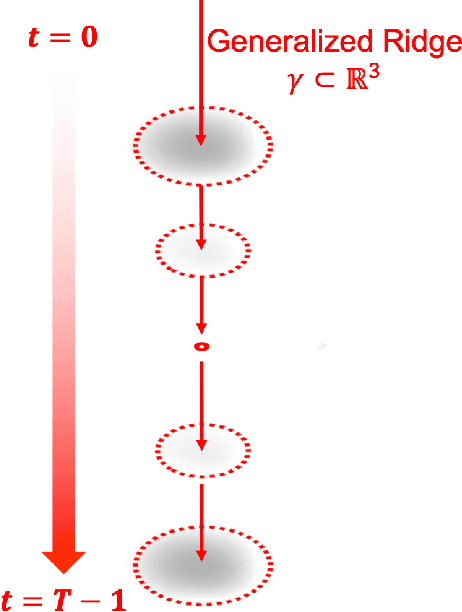
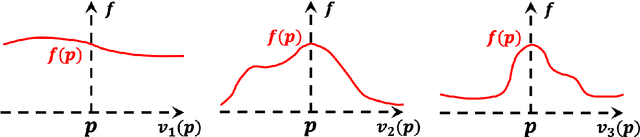
Ridge detection is a classical tool to extract curvilinear features in image processing. As such, it has great promise in applications to material science problems; specifically, for trend filtering relatively stable atom-shaped objects in image sequences, such as Transmission Electron Microscopy (TEM) videos. Standard analysis of TEM videos is limited to frame-by-frame object recognition. We instead harness temporal correlation across frames through simultaneous analysis of long image sequences, specified as a spatio-temporal image tensor. We define new ridge detection algorithms to non-parametrically estimate explicit trajectories of atomic-level object locations as a continuous function of time. Our approach is specially tailored to handle temporal analysis of objects that seemingly stochastically disappear and subsequently reappear throughout a sequence. We demonstrate that the proposed method is highly effective and efficient in simulation scenarios, and delivers notable performance improvements in TEM experiments compared to other material science benchmarks.
Resolving Left-Right Ambiguity During Bearing Only Tracking of an Underwater Target Using Towed Array
Feb 03, 2023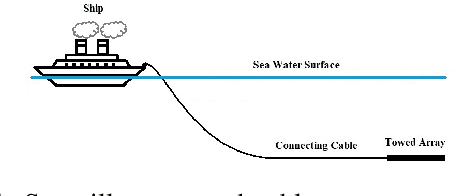
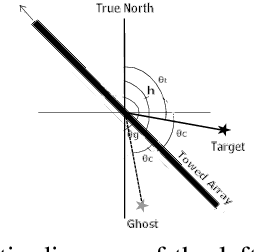
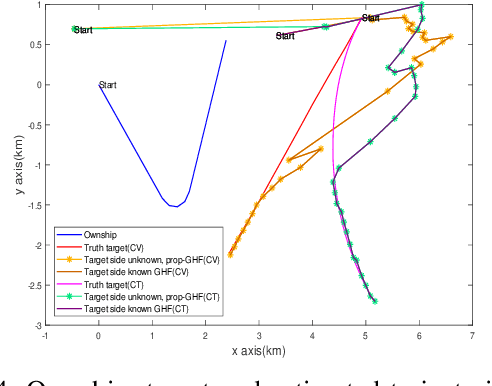
In bearing only tracking using a towed array, the array can sense the bearing angle of the target but is unable to differentiate whether the target is on the left or the right side of the array. Thus, the traditional tracking algorithm generates tracks in both the sides of the array which create difficulties when interception is required. In this paper, we propose a method based on likelihood of measurement which along with the estimators can resolve left-right ambiguity and track the target. A case study has been presented where the target moves (a) in a straight line with a near constant velocity, (b) maneuvers with a turn, and observer takes a `U'-like maneuver. The method along with the various estimators has been applied which successfully resolves the ambiguity and tracks the target. Further, the tracking results are compared in terms of the root mean square error in position and velocity, bias norm, \% of track loss and the relative execution time.
LiSnowNet: Real-time Snow Removal for LiDAR Point Cloud
Nov 18, 2022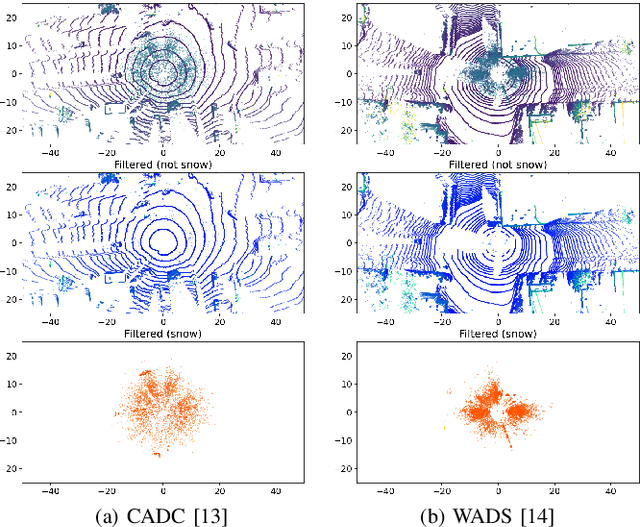

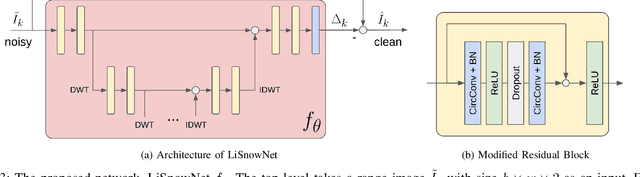
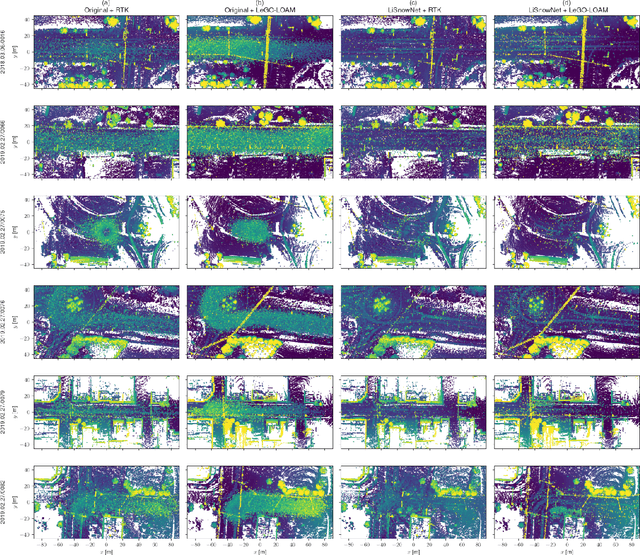
LiDARs have been widely adopted to modern self-driving vehicles, providing 3D information of the scene and surrounding objects. However, adverser weather conditions still pose significant challenges to LiDARs since point clouds captured during snowfall can easily be corrupted. The resulting noisy point clouds degrade downstream tasks such as mapping. Existing works in de-noising point clouds corrupted by snow are based on nearest-neighbor search, and thus do not scale well with modern LiDARs which usually capture $100k$ or more points at 10Hz. In this paper, we introduce an unsupervised de-noising algorithm, LiSnowNet, running 52$\times$ faster than the state-of-the-art methods while achieving superior performance in de-noising. Unlike previous methods, the proposed algorithm is based on a deep convolutional neural network and can be easily deployed to hardware accelerators such as GPUs. In addition, we demonstrate how to use the proposed method for mapping even with corrupted point clouds.
Ancilia: Scalable Intelligent Video Surveillance for the Artificial Intelligence of Things
Jan 09, 2023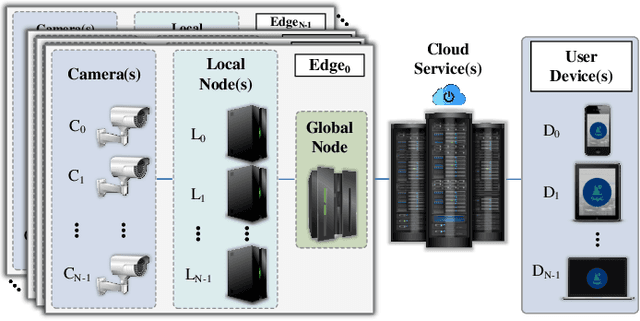
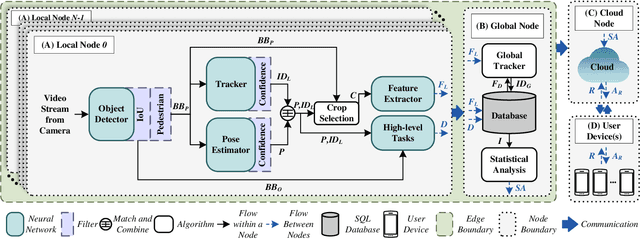
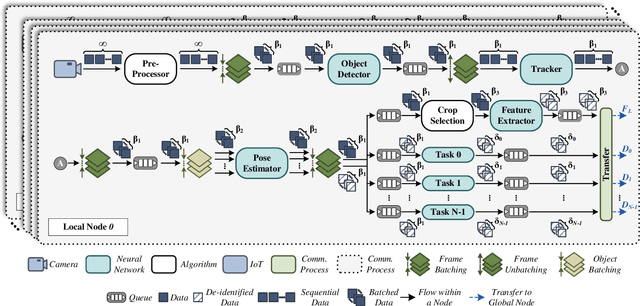
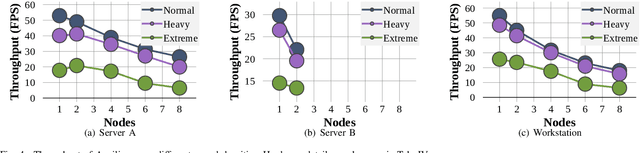
With the advancement of vision-based artificial intelligence, the proliferation of the Internet of Things connected cameras, and the increasing societal need for rapid and equitable security, the demand for accurate real-time intelligent surveillance has never been higher. This article presents Ancilia, an end-to-end scalable, intelligent video surveillance system for the Artificial Intelligence of Things. Ancilia brings state-of-the-art artificial intelligence to real-world surveillance applications while respecting ethical concerns and performing high-level cognitive tasks in real-time. Ancilia aims to revolutionize the surveillance landscape, to bring more effective, intelligent, and equitable security to the field, resulting in safer and more secure communities without requiring people to compromise their right to privacy.
ShiftDDPMs: Exploring Conditional Diffusion Models by Shifting Diffusion Trajectories
Feb 05, 2023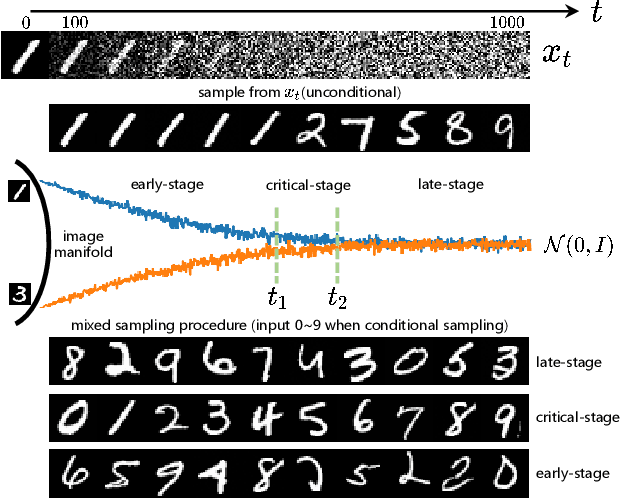
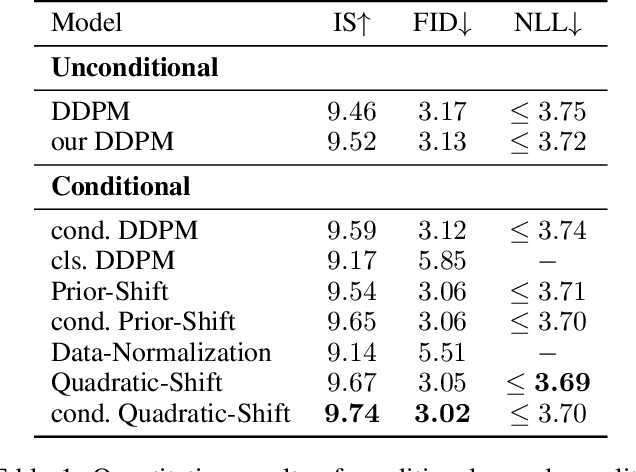
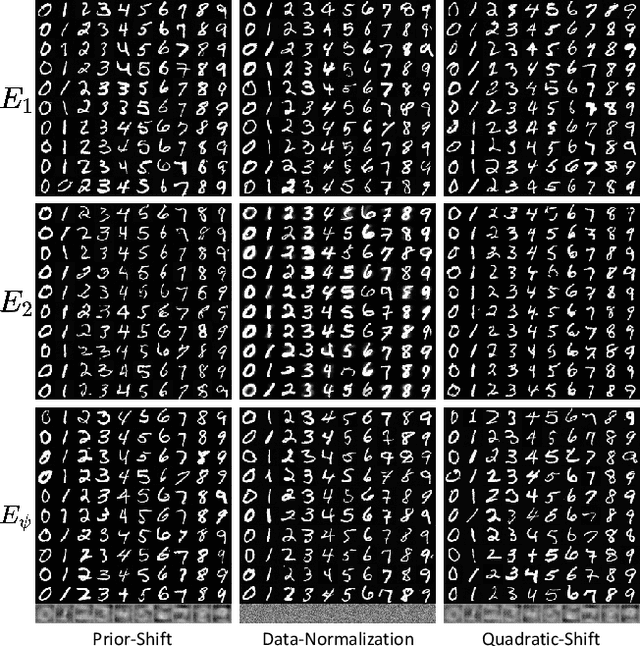
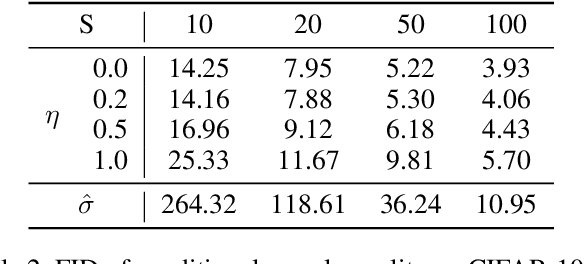
Diffusion models have recently exhibited remarkable abilities to synthesize striking image samples since the introduction of denoising diffusion probabilistic models (DDPMs). Their key idea is to disrupt images into noise through a fixed forward process and learn its reverse process to generate samples from noise in a denoising way. For conditional DDPMs, most existing practices relate conditions only to the reverse process and fit it to the reversal of unconditional forward process. We find this will limit the condition modeling and generation in a small time window. In this paper, we propose a novel and flexible conditional diffusion model by introducing conditions into the forward process. We utilize extra latent space to allocate an exclusive diffusion trajectory for each condition based on some shifting rules, which will disperse condition modeling to all timesteps and improve the learning capacity of model. We formulate our method, which we call \textbf{ShiftDDPMs}, and provide a unified point of view on existing related methods. Extensive qualitative and quantitative experiments on image synthesis demonstrate the feasibility and effectiveness of ShiftDDPMs.
MILO: Model-Agnostic Subset Selection Framework for Efficient Model Training and Tuning
Feb 05, 2023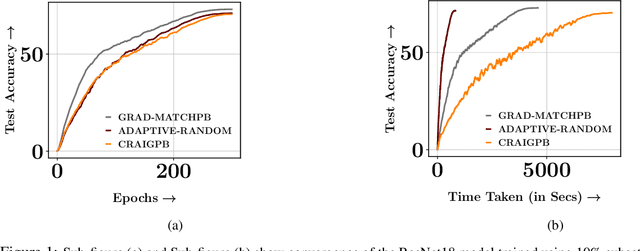
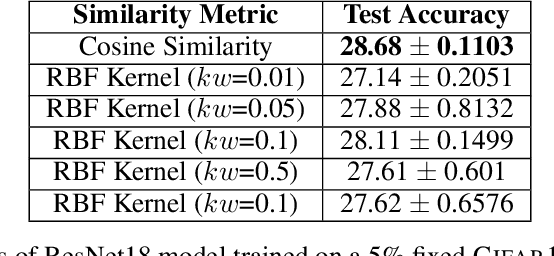
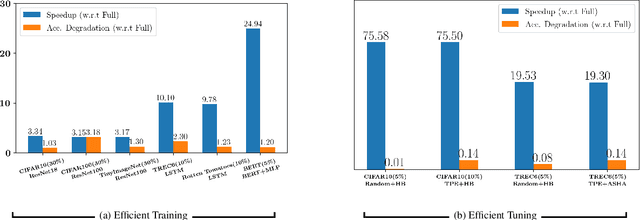
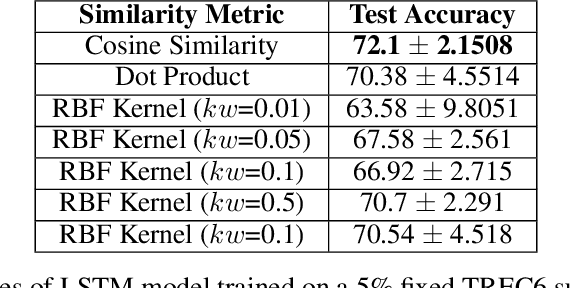
Training deep networks and tuning hyperparameters on large datasets is computationally intensive. One of the primary research directions for efficient training is to reduce training costs by selecting well-generalizable subsets of training data. Compared to simple adaptive random subset selection baselines, existing intelligent subset selection approaches are not competitive due to the time-consuming subset selection step, which involves computing model-dependent gradients and feature embeddings and applies greedy maximization of submodular objectives. Our key insight is that removing the reliance on downstream model parameters enables subset selection as a pre-processing step and enables one to train multiple models at no additional cost. In this work, we propose MILO, a model-agnostic subset selection framework that decouples the subset selection from model training while enabling superior model convergence and performance by using an easy-to-hard curriculum. Our empirical results indicate that MILO can train models $3\times - 10 \times$ faster and tune hyperparameters $20\times - 75 \times$ faster than full-dataset training or tuning without compromising performance.
FastPillars: A Deployment-friendly Pillar-based 3D Detector
Feb 05, 2023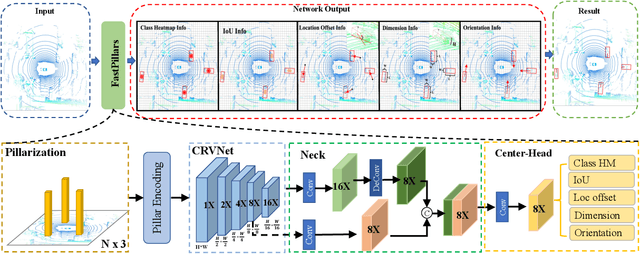
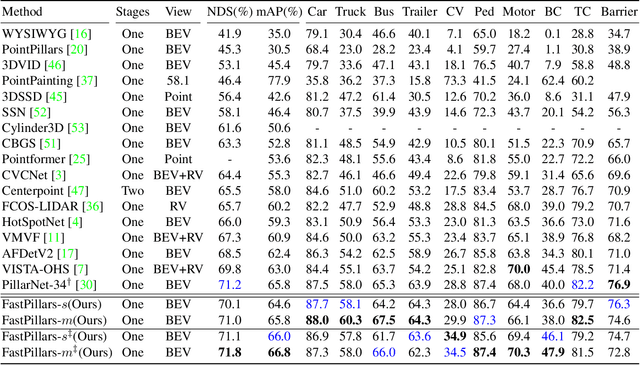
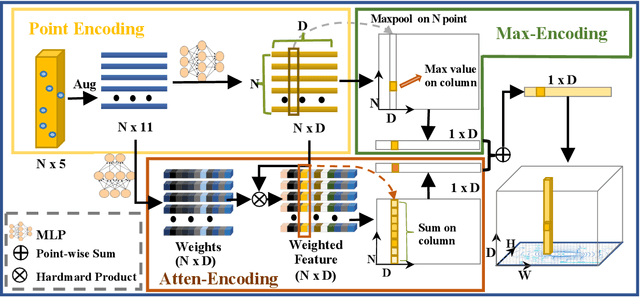
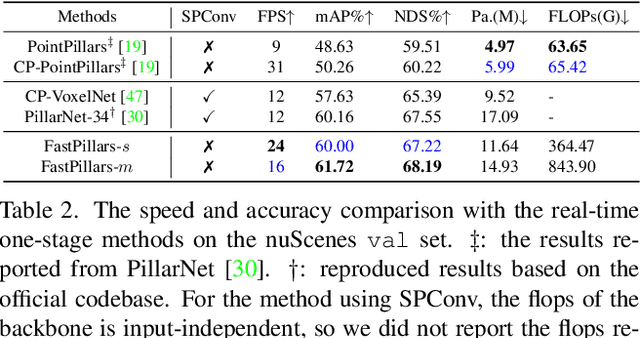
The deployment of 3D detectors strikes one of the major challenges in real-world self-driving scenarios. Existing BEV-based (i.e., Bird Eye View) detectors favor sparse convolution (known as SPConv) to speed up training and inference, which puts a hard barrier for deployment especially for on-device applications. In this paper, we tackle the problem of efficient 3D object detection from LiDAR point clouds with deployment in mind. To reduce computational burden, we propose a pillar-based 3D detector with high performance from an industry perspective, termed FastPillars. Compared with previous methods, we introduce a more effective Max-and-Attention pillar encoding (MAPE) module, and redesigning a powerful and lightweight backbone CRVNet imbued with Cross Stage Partial network (CSP) in a reparameterization style, forming a compact feature representation framework. Extensive experiments demonstrate that our FastPillars surpasses the state-of-the-art 3D detectors regarding both on-device speed and performance. Specifically, FastPillars can be effectively deployed through TensorRT, obtaining real-time performance (24FPS) on a single RTX3070Ti GPU with 64.6 mAP on the nuScenes test set. Our code will be released.
Wireless Picosecond Time Synchronization for Distributed Antenna Arrays
Jun 16, 2022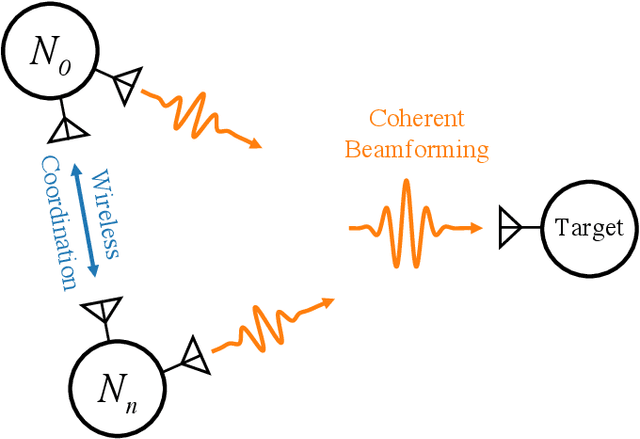
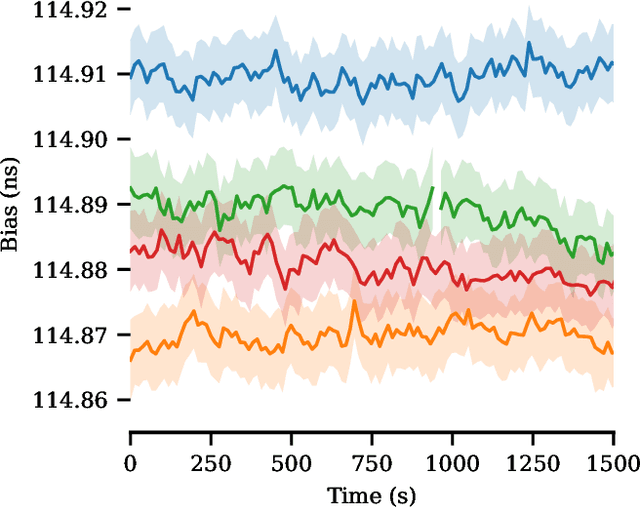
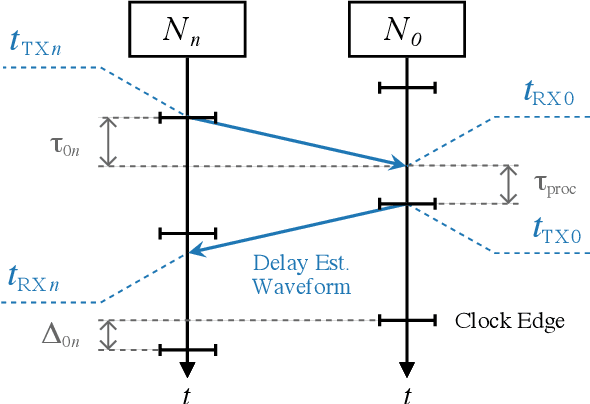
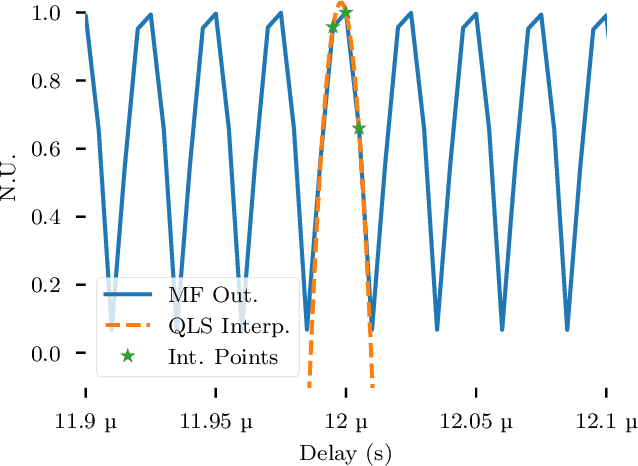
Distributed antenna arrays have been proposed for many applications ranging from space-based observatories to automated vehicles. Achieving good performance in distributed antenna systems requires stringent synchronization at the wavelength and information level to ensure that the transmitted signals arrive coherently at the target, or that scattered and received signals can be appropriately processed via distributed algorithms. In this paper we address the challenge of high precision time synchronization to align the operations of elements in a distributed antenna array and to overcome time-varying bias between platforms due to oscillator drift. We use a spectrally sparse two-tone waveform, which obtains approximately optimal time estimation accuracy, in a two-way time transfer process. We also describe a technique for determining the true time delay using the ambiguous two-tone matched filter output, and we compare the time synchronization precision of the two-tone waveform with the more common linear frequency modulation (LFM) waveform. We experimentally demonstrate wireless time synchronization using a single pulse 40$\,$MHz two-tone waveform over a 90$\,$cm 5.8$\,$GHz wireless link in a laboratory setting, obtaining a timing precision of 2.26$\,$ps.