 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Power Laws for Hyperparameter Optimization
Feb 01, 2023
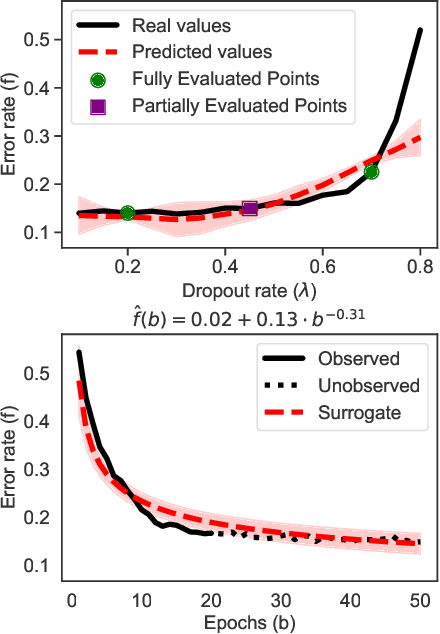



Hyperparameter optimization is an important subfield of machine learning that focuses on tuning the hyperparameters of a chosen algorithm to achieve peak performance. Recently, there has been a stream of methods that tackle the issue of hyperparameter optimization, however, most of the methods do not exploit the scaling law property of learning curves. In this work, we propose Deep Power Laws (DPL), an ensemble of neural network models conditioned to yield predictions that follow a power-law scaling pattern. Our method dynamically decides which configurations to pause and train incrementally by making use of gray-box evaluations. We compare our method against 7 state-of-the-art competitors on 3 benchmarks related to tabular, image, and NLP datasets covering 57 diverse tasks. Our method achieves the best results across all benchmarks by obtaining the best any-time results compared to all competitors.
DisDiff: Unsupervised Disentanglement of Diffusion Probabilistic Models
Feb 01, 2023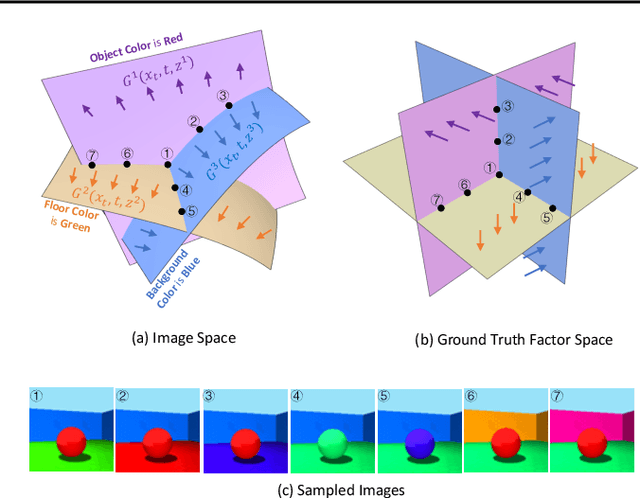
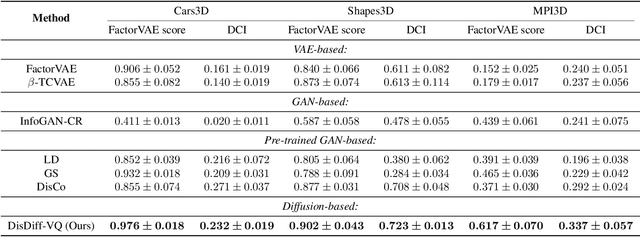
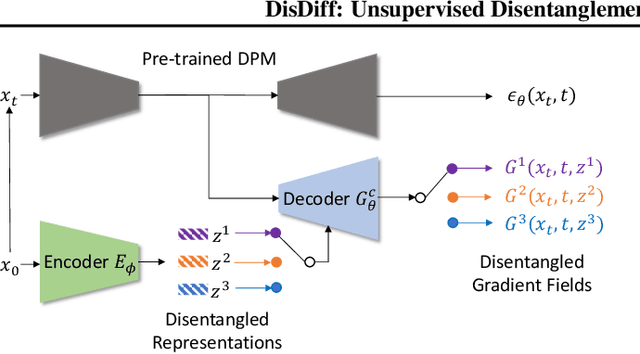
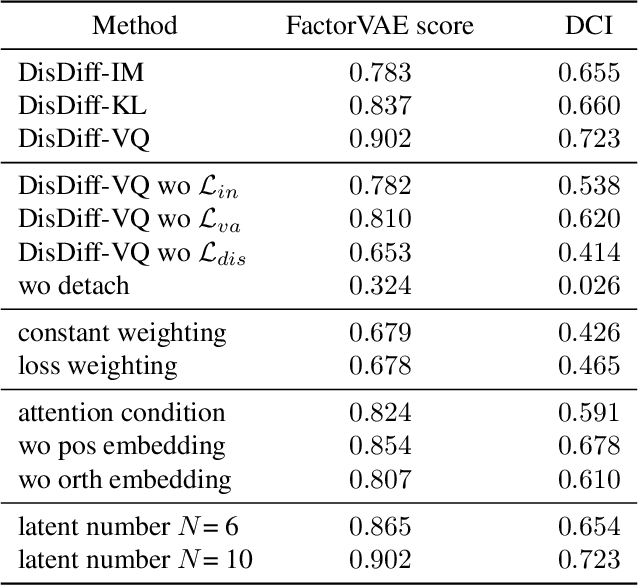
In this paper, targeting to understand the underlying explainable factors behind observations and modeling the conditional generation process on these factors, we propose a new task, disentanglement of diffusion probabilistic models (DPMs), to take advantage of the remarkable modeling ability of DPMs. To tackle this task, we further devise an unsupervised approach named DisDiff. For the first time, we achieve disentangled representation learning in the framework of diffusion probabilistic models. Given a pre-trained DPM, DisDiff can automatically discover the inherent factors behind the image data and disentangle the gradient fields of DPM into sub-gradient fields, each conditioned on the representation of each discovered factor. We propose a novel Disentangling Loss for DisDiff to facilitate the disentanglement of the representation and sub-gradients. The extensive experiments on synthetic and real-world datasets demonstrate the effectiveness of DisDiff.
The RW3D: A multi-modal panel dataset to understand the psychological impact of the pandemic
Feb 01, 2023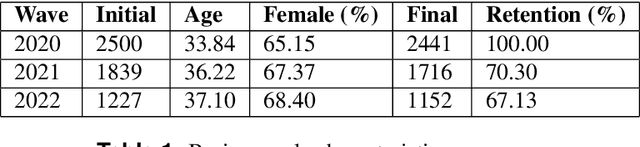
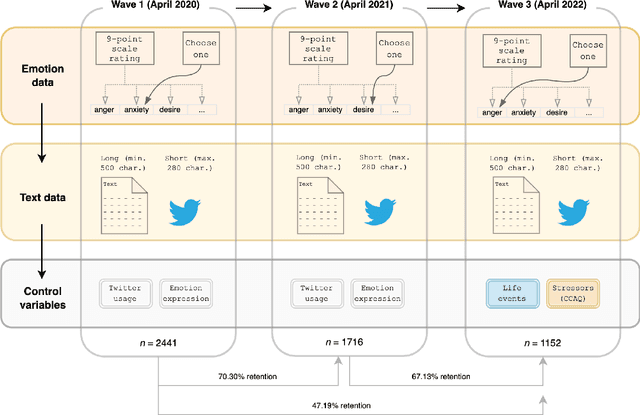
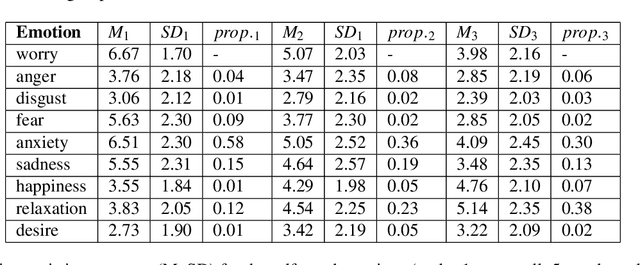

Besides far-reaching public health consequences, the COVID-19 pandemic had a significant psychological impact on people around the world. To gain further insight into this matter, we introduce the Real World Worry Waves Dataset (RW3D). The dataset combines rich open-ended free-text responses with survey data on emotions, significant life events, and psychological stressors in a repeated-measures design in the UK over three years (2020: n=2441, 2021: n=1716 and 2022: n=1152). This paper provides background information on the data collection procedure, the recorded variables, participants' demographics, and higher-order psychological and text-based derived variables that emerged from the data. The RW3D is a unique primary data resource that could inspire new research questions on the psychological impact of the pandemic, especially those that connect modalities (here: text data, psychological survey variables and demographics) over time.
EgPDE-Net: Building Continuous Neural Networks for Time Series Prediction with Exogenous Variables
Aug 03, 2022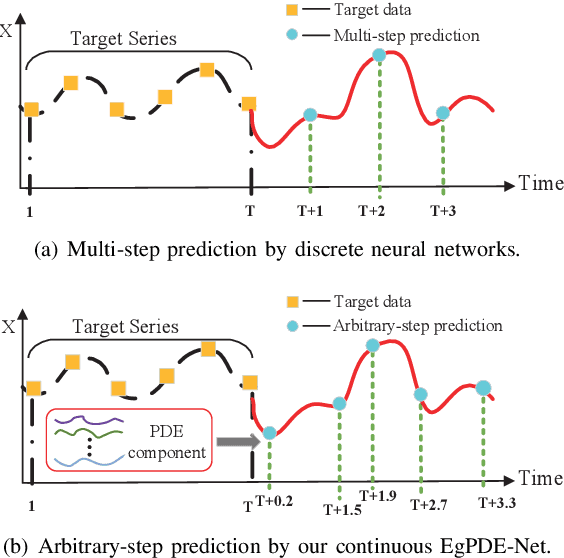
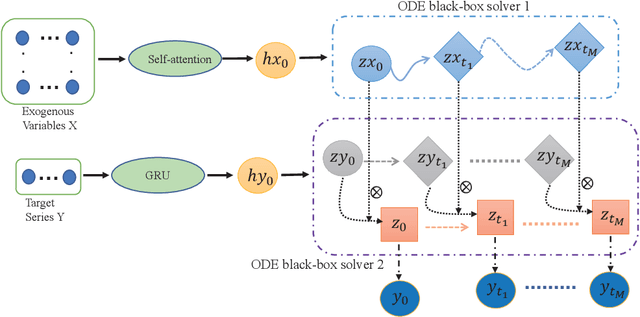
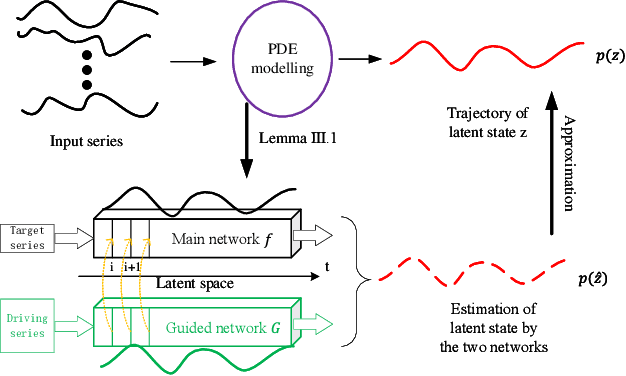
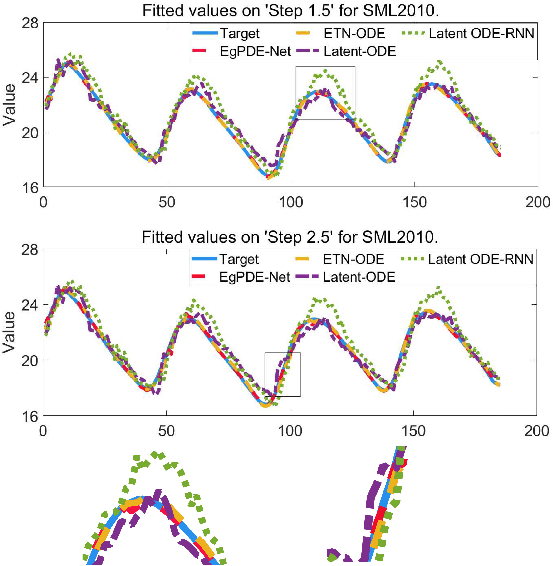
While exogenous variables have a major impact on performance improvement in time series analysis, inter-series correlation and time dependence among them are rarely considered in the present continuous methods. The dynamical systems of multivariate time series could be modelled with complex unknown partial differential equations (PDEs) which play a prominent role in many disciplines of science and engineering. In this paper, we propose a continuous-time model for arbitrary-step prediction to learn an unknown PDE system in multivariate time series whose governing equations are parameterised by self-attention and gated recurrent neural networks. The proposed model, \underline{E}xogenous-\underline{g}uided \underline{P}artial \underline{D}ifferential \underline{E}quation Network (EgPDE-Net), takes account of the relationships among the exogenous variables and their effects on the target series. Importantly, the model can be reduced into a regularised ordinary differential equation (ODE) problem with special designed regularisation guidance, which makes the PDE problem tractable to obtain numerical solutions and feasible to predict multiple future values of the target series at arbitrary time points. Extensive experiments demonstrate that our proposed model could achieve competitive accuracy over strong baselines: on average, it outperforms the best baseline by reducing $9.85\%$ on RMSE and $13.98\%$ on MAE for arbitrary-step prediction.
FasterX: Real-Time Object Detection Based on Edge GPUs for UAV Applications
Sep 07, 2022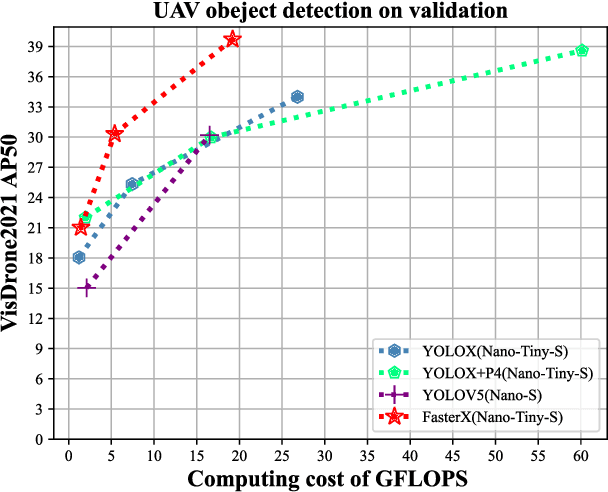

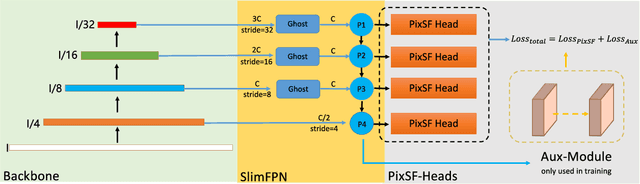
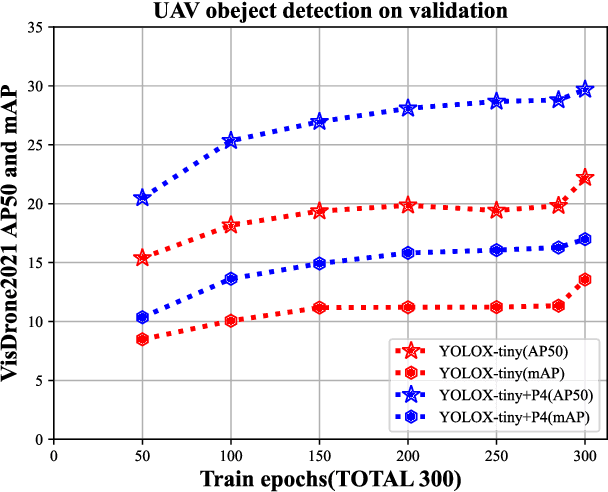
Real-time object detection on Unmanned Aerial Vehicles (UAVs) is a challenging issue due to the limited computing resources of edge GPU devices as Internet of Things (IoT) nodes. To solve this problem, in this paper, we propose a novel lightweight deep learning architectures named FasterX based on YOLOX model for real-time object detection on edge GPU. First, we design an effective and lightweight PixSF head to replace the original head of YOLOX to better detect small objects, which can be further embedded in the depthwise separable convolution (DS Conv) to achieve a lighter head. Then, a slimmer structure in the Neck layer termed as SlimFPN is developed to reduce parameters of the network, which is a trade-off between accuracy and speed. Furthermore, we embed attention module in the Head layer to improve the feature extraction effect of the prediction head. Meanwhile, we also improve the label assignment strategy and loss function to alleviate category imbalance and box optimization problems of the UAV dataset. Finally, auxiliary heads are presented for online distillation to improve the ability of position embedding and feature extraction in PixSF head. The performance of our lightweight models are validated experimentally on the NVIDIA Jetson NX and Jetson Nano GPU embedded platforms.Extensive experiments show that FasterX models achieve better trade-off between accuracy and latency on VisDrone2021 dataset compared to state-of-the-art models.
Test-Time Adaptation via Conjugate Pseudo-labels
Jul 20, 2022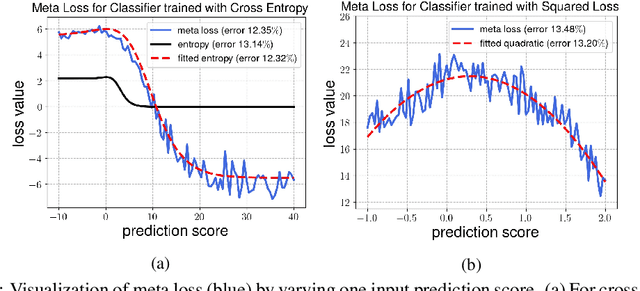
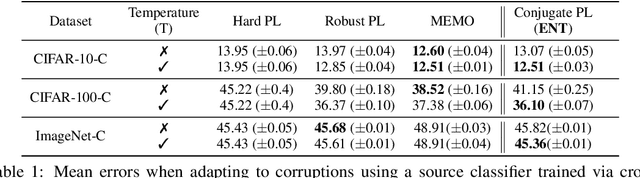
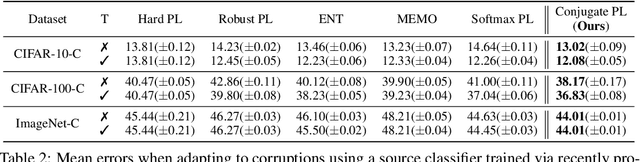
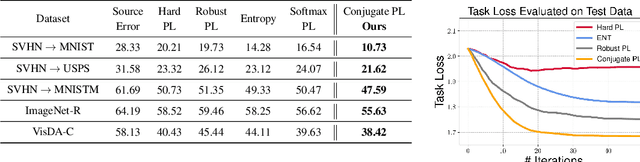
Test-time adaptation (TTA) refers to adapting neural networks to distribution shifts, with access to only the unlabeled test samples from the new domain at test-time. Prior TTA methods optimize over unsupervised objectives such as the entropy of model predictions in TENT [Wang et al., 2021], but it is unclear what exactly makes a good TTA loss. In this paper, we start by presenting a surprising phenomenon: if we attempt to meta-learn the best possible TTA loss over a wide class of functions, then we recover a function that is remarkably similar to (a temperature-scaled version of) the softmax-entropy employed by TENT. This only holds, however, if the classifier we are adapting is trained via cross-entropy; if trained via squared loss, a different best TTA loss emerges. To explain this phenomenon, we analyze TTA through the lens of the training losses's convex conjugate. We show that under natural conditions, this (unsupervised) conjugate function can be viewed as a good local approximation to the original supervised loss and indeed, it recovers the best losses found by meta-learning. This leads to a generic recipe that can be used to find a good TTA loss for any given supervised training loss function of a general class. Empirically, our approach consistently dominates other baselines over a wide range of benchmarks. Our approach is particularly of interest when applied to classifiers trained with novel loss functions, e.g., the recently-proposed PolyLoss, where it differs substantially from (and outperforms) an entropy-based loss. Further, we show that our approach can also be interpreted as a kind of self-training using a very specific soft label, which we refer to as the conjugate pseudolabel. Overall, our method provides a broad framework for better understanding and improving test-time adaptation. Code is available at https://github.com/locuslab/tta_conjugate.
Domain Re-Modulation for Few-Shot Generative Domain Adaptation
Feb 07, 2023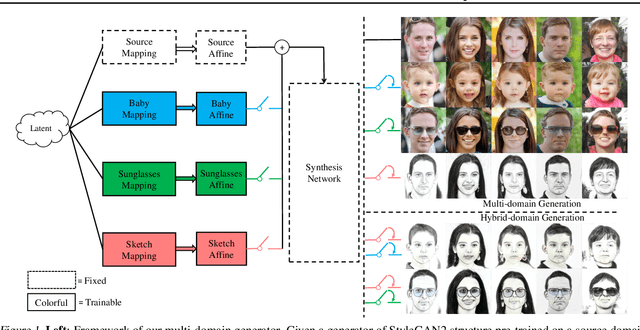
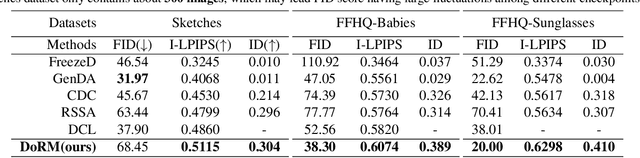
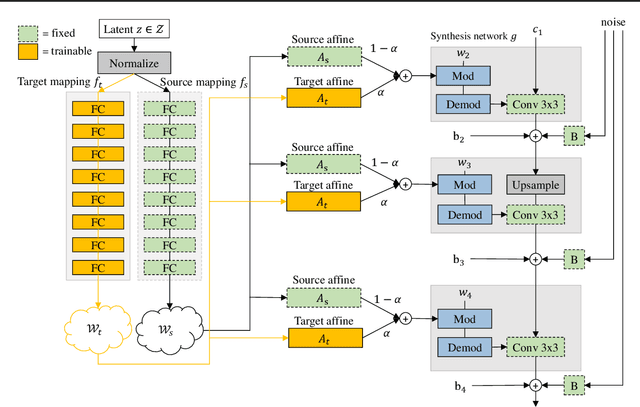
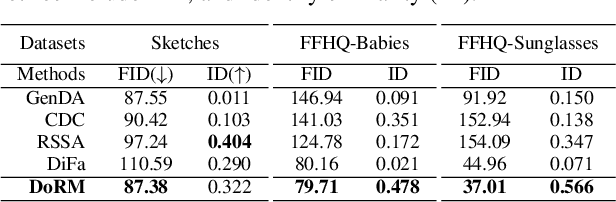
In this study, we investigate the task of few-shot Generative Domain Adaptation (GDA), which involves transferring a pre-trained generator from one domain to a new domain using one or a few reference images. Building upon previous research that has focused on Target-domain Consistency, Large Diversity, and Cross-domain Consistency, we conclude two additional desired properties for GDA: Memory and Domain Association. To meet these properties, we proposed a novel method Domain Re-Modulation (DoRM). Specifically, DoRM freezes the source generator and employs additional mapping and affine modules (M&A module) to capture the attributes of the target domain, resulting in a linearly combinable domain shift in style space. This allows for high-fidelity multi-domain and hybrid-domain generation by integrating multiple M&A modules in a single generator. DoRM is lightweight and easy to implement. Extensive experiments demonstrated the superior performance of DoRM on both one-shot and 10-shot GDA, both quantitatively and qualitatively. Additionally, for the first time, multi-domain and hybrid-domain generation can be achieved with a minimal storage cost by using a single model. The code will be available at https://github.com/wuyi2020/DoRM.
SimCon Loss with Multiple Views for Text Supervised Semantic Segmentation
Feb 07, 2023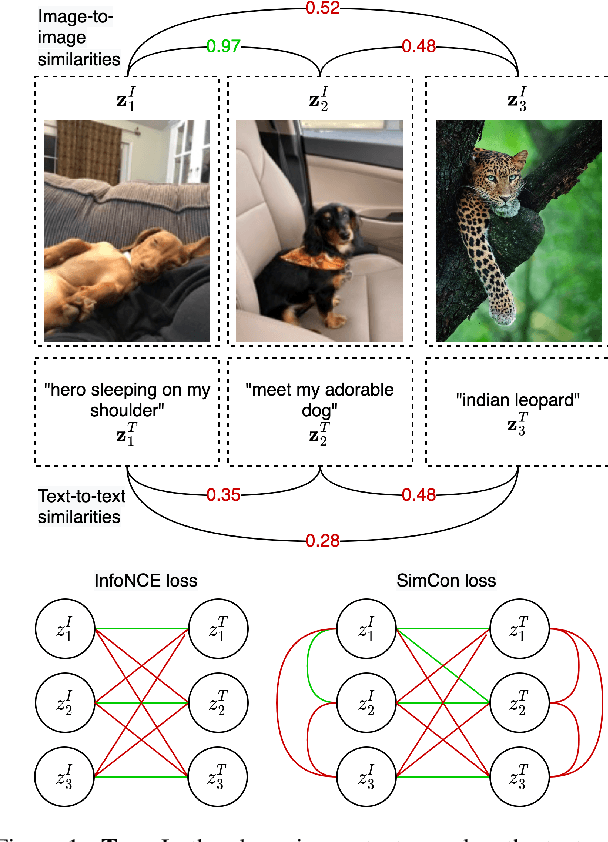
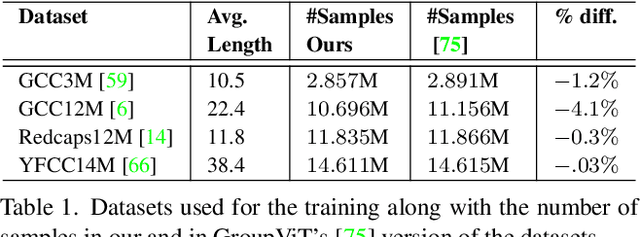
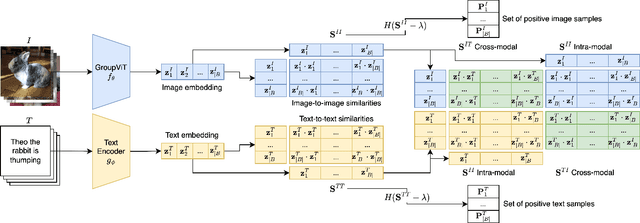
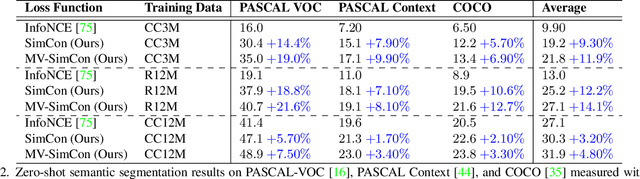
Learning to segment images purely by relying on the image-text alignment from web data can lead to sub-optimal performance due to noise in the data. The noise comes from the samples where the associated text does not correlate with the image's visual content. Instead of purely relying on the alignment from the noisy data, this paper proposes a novel loss function termed SimCon, which accounts for intra-modal similarities to determine the appropriate set of positive samples to align. Further, using multiple views of the image (created synthetically) for training and combining the SimCon loss with it makes the training more robust. This version of the loss is termed MV-SimCon. The empirical results demonstrate that using the proposed loss function leads to consistent improvements on zero-shot, text supervised semantic segmentation and outperforms state-of-the-art by $+3.0\%$, $+3.3\%$ and $+6.9\%$ on PASCAL VOC, PASCAL Context and MSCOCO, respectively. With test time augmentations, we set a new record by improving these results further to $58.7\%$, $26.6\%$, and $33.3\%$ on PASCAL VOC, PASCAL Context, and MSCOCO, respectively. In addition, using the proposed loss function leads to robust training and faster convergence.
OpenSpike: An OpenRAM SNN Accelerator
Feb 02, 2023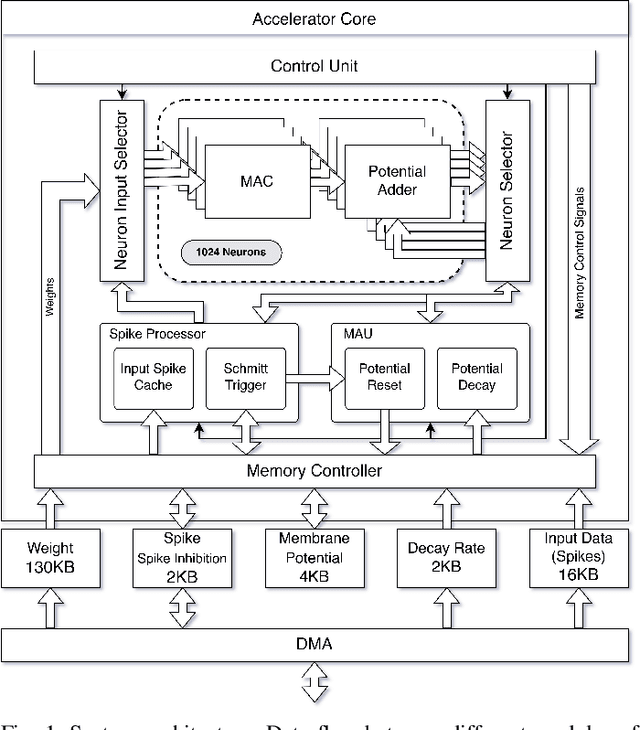
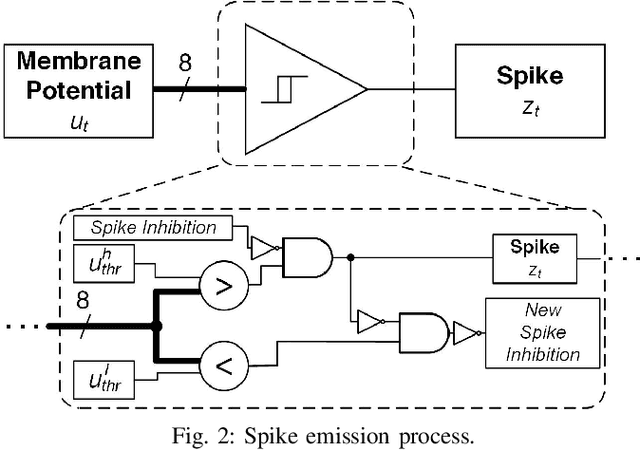
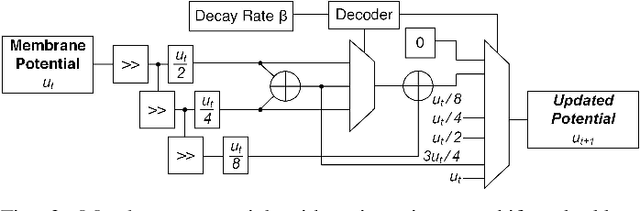
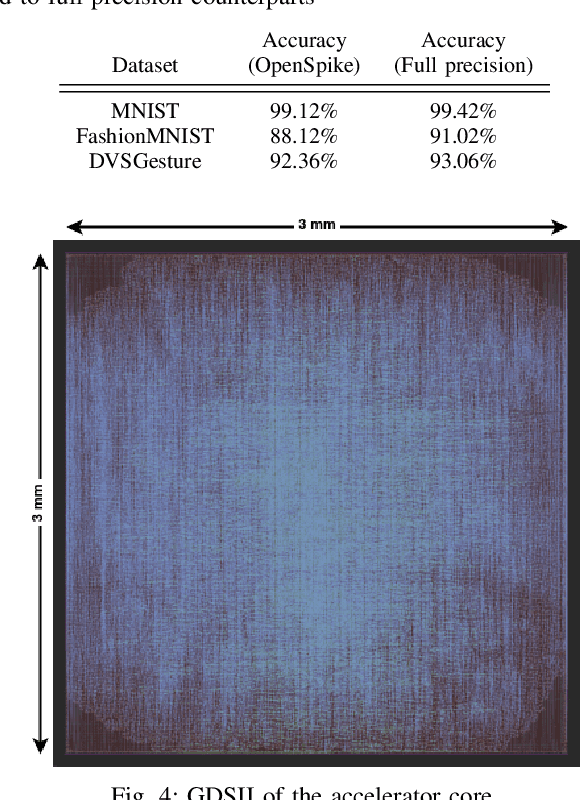
This paper presents a spiking neural network (SNN) accelerator made using fully open-source EDA tools, process design kit (PDK), and memory macros synthesized using OpenRAM. The chip is taped out in the 130 nm SkyWater process and integrates over 1 million synaptic weights, and offers a reprogrammable architecture. It operates at a clock speed of 40 MHz, a supply of 1.8 V, uses a PicoRV32 core for control, and occupies an area of 33.3 mm^2. The throughput of the accelerator is 48,262 images per second with a wallclock time of 20.72 us, at 56.8 GOPS/W. The spiking neurons use hysteresis to provide an adaptive threshold (i.e., a Schmitt trigger) which can reduce state instability. This results in high performing SNNs across a range of benchmarks that remain competitive with state-of-the-art, full precision SNNs. The design is open sourced and available online: https://github.com/sfmth/OpenSpike
Mnemosyne: Learning to Train Transformers with Transformers
Feb 02, 2023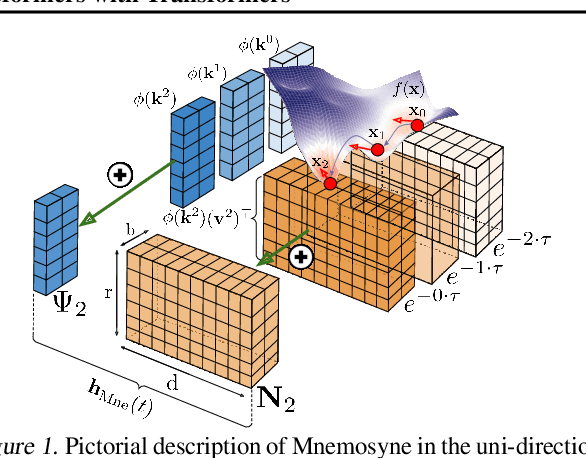

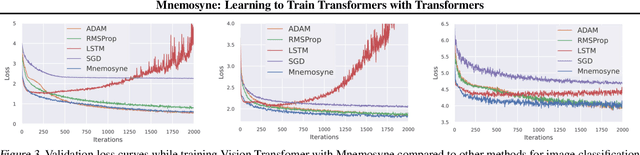
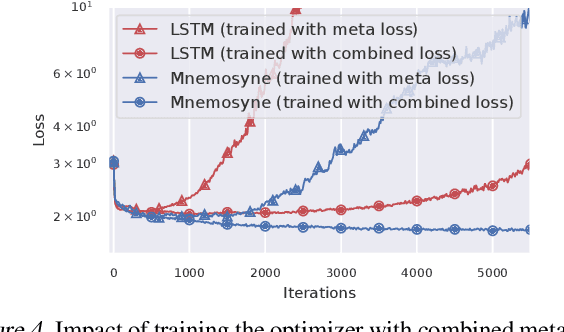
Training complex machine learning (ML) architectures requires a compute and time consuming process of selecting the right optimizer and tuning its hyper-parameters. A new paradigm of learning optimizers from data has emerged as a better alternative to hand-designed ML optimizers. We propose Mnemosyne optimizer, that uses Performers: implicit low-rank attention Transformers. It can learn to train entire neural network architectures including other Transformers without any task-specific optimizer tuning. We show that Mnemosyne: (a) generalizes better than popular LSTM optimizer, (b) in particular can successfully train Vision Transformers (ViTs) while meta--trained on standard MLPs and (c) can initialize optimizers for faster convergence in Robotics applications. We believe that these results open the possibility of using Transformers to build foundational optimization models that can address the challenges of regular Transformer training. We complement our results with an extensive theoretical analysis of the compact associative memory used by Mnemosyne.