 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sequential Fair Resource Allocation under a Markov Decision Process Framework
Jan 10, 2023
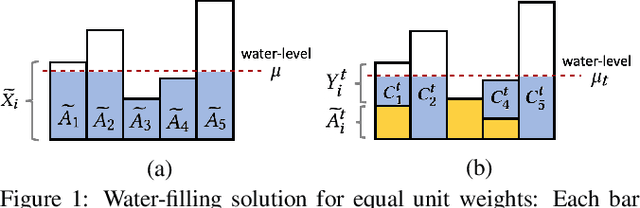
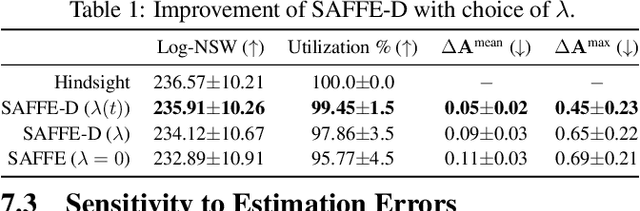
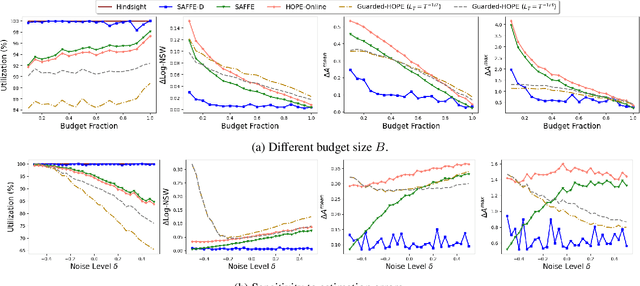

We study the sequential decision-making problem of allocating a limited resource to agents that reveal their stochastic demands on arrival over a finite horizon. Our goal is to design fair allocation algorithms that exhaust the available resource budget. This is challenging in sequential settings where information on future demands is not available at the time of decision-making. We formulate the problem as a discrete time Markov decision process (MDP). We propose a new algorithm, SAFFE, that makes fair allocations with respect to the entire demands revealed over the horizon by accounting for expected future demands at each arrival time. The algorithm introduces regularization which enables the prioritization of current revealed demands over future potential demands depending on the uncertainty in agents' future demands. Using the MDP formulation, we show that SAFFE optimizes allocations based on an upper bound on the Nash Social Welfare fairness objective, and we bound its gap to optimality with the use of concentration bounds on total future demands. Using synthetic and real data, we compare the performance of SAFFE against existing approaches and a reinforcement learning policy trained on the MDP. We show that SAFFE leads to more fair and efficient allocations and achieves close-to-optimal performance in settings with dense arrivals.
ConceptFusion: Open-set Multimodal 3D Mapping
Feb 15, 2023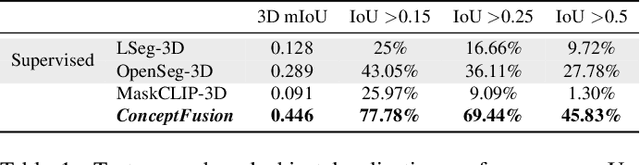



Building 3D maps of the environment is central to robot navigation, planning, and interaction with objects in a scene. Most existing approaches that integrate semantic concepts with 3D maps largely remain confined to the closed-set setting: they can only reason about a finite set of concepts, pre-defined at training time. Further, these maps can only be queried using class labels, or in recent work, using text prompts. We address both these issues with ConceptFusion, a scene representation that is (1) fundamentally open-set, enabling reasoning beyond a closed set of concepts and (ii) inherently multimodal, enabling a diverse range of possible queries to the 3D map, from language, to images, to audio, to 3D geometry, all working in concert. ConceptFusion leverages the open-set capabilities of today's foundation models pre-trained on internet-scale data to reason about concepts across modalities such as natural language, images, and audio. We demonstrate that pixel-aligned open-set features can be fused into 3D maps via traditional SLAM and multi-view fusion approaches. This enables effective zero-shot spatial reasoning, not needing any additional training or finetuning, and retains long-tailed concepts better than supervised approaches, outperforming them by more than 40% margin on 3D IoU. We extensively evaluate ConceptFusion on a number of real-world datasets, simulated home environments, a real-world tabletop manipulation task, and an autonomous driving platform. We showcase new avenues for blending foundation models with 3D open-set multimodal mapping. For more information, visit our project page https://concept-fusion.github.io or watch our 5-minute explainer video https://www.youtube.com/watch?v=rkXgws8fiDs
Confidence Score Based Speaker Adaptation of Conformer Speech Recognition Systems
Feb 15, 2023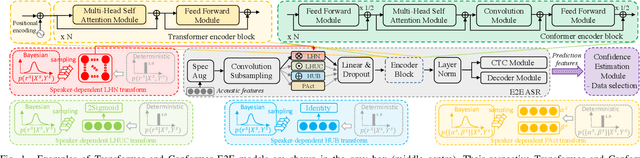
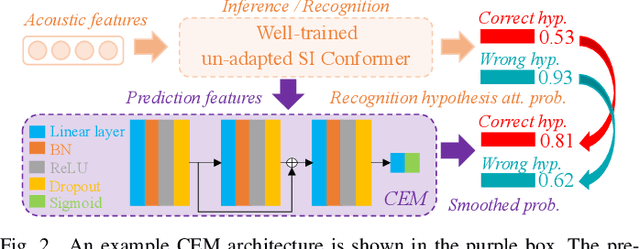
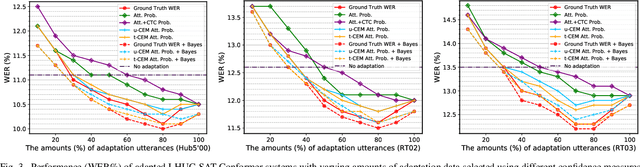
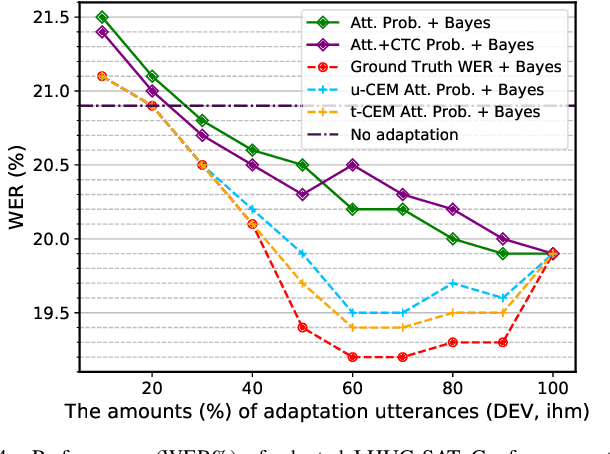
Speaker adaptation techniques provide a powerful solution to customise automatic speech recognition (ASR) systems for individual users. Practical application of unsupervised model-based speaker adaptation techniques to data intensive end-to-end ASR systems is hindered by the scarcity of speaker-level data and performance sensitivity to transcription errors. To address these issues, a set of compact and data efficient speaker-dependent (SD) parameter representations are used to facilitate both speaker adaptive training and test-time unsupervised speaker adaptation of state-of-the-art Conformer ASR systems. The sensitivity to supervision quality is reduced using a confidence score-based selection of the less erroneous subset of speaker-level adaptation data. Two lightweight confidence score estimation modules are proposed to produce more reliable confidence scores. The data sparsity issue, which is exacerbated by data selection, is addressed by modelling the SD parameter uncertainty using Bayesian learning. Experiments on the benchmark 300-hour Switchboard and the 233-hour AMI datasets suggest that the proposed confidence score-based adaptation schemes consistently outperformed the baseline speaker-independent (SI) Conformer model and conventional non-Bayesian, point estimate-based adaptation using no speaker data selection. Similar consistent performance improvements were retained after external Transformer and LSTM language model rescoring. In particular, on the 300-hour Switchboard corpus, statistically significant WER reductions of 1.0%, 1.3%, and 1.4% absolute (9.5%, 10.9%, and 11.3% relative) were obtained over the baseline SI Conformer on the NIST Hub5'00, RT02, and RT03 evaluation sets respectively. Similar WER reductions of 2.7% and 3.3% absolute (8.9% and 10.2% relative) were also obtained on the AMI development and evaluation sets.
Bayesian Decision Trees via Tractable Priors and Probabilistic Context-Free Grammars
Feb 15, 2023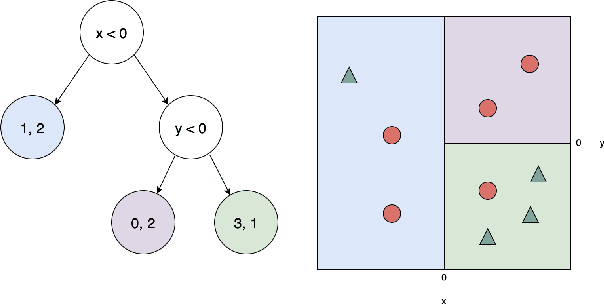
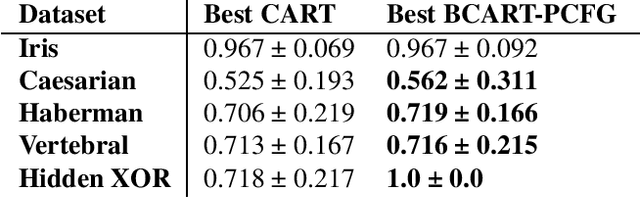

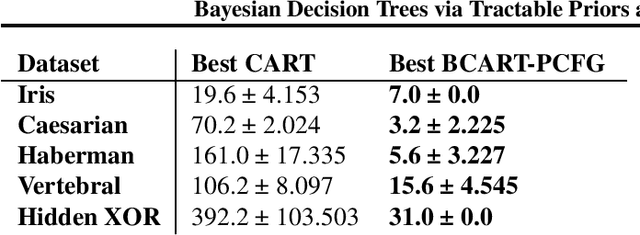
Decision Trees are some of the most popular machine learning models today due to their out-of-the-box performance and interpretability. Often, Decision Trees models are constructed greedily in a top-down fashion via heuristic search criteria, such as Gini impurity or entropy. However, trees constructed in this manner are sensitive to minor fluctuations in training data and are prone to overfitting. In contrast, Bayesian approaches to tree construction formulate the selection process as a posterior inference problem; such approaches are more stable and provide greater theoretical guarantees. However, generating Bayesian Decision Trees usually requires sampling from complex, multimodal posterior distributions. Current Markov Chain Monte Carlo-based approaches for sampling Bayesian Decision Trees are prone to mode collapse and long mixing times, which makes them impractical. In this paper, we propose a new criterion for training Bayesian Decision Trees. Our criterion gives rise to BCART-PCFG, which can efficiently sample decision trees from a posterior distribution across trees given the data and find the maximum a posteriori (MAP) tree. Learning the posterior and training the sampler can be done in time that is polynomial in the dataset size. Once the posterior has been learned, trees can be sampled efficiently (linearly in the number of nodes). At the core of our method is a reduction of sampling the posterior to sampling a derivation from a probabilistic context-free grammar. We find that trees sampled via BCART-PCFG perform comparable to or better than greedily-constructed Decision Trees in classification accuracy on several datasets. Additionally, the trees sampled via BCART-PCFG are significantly smaller -- sometimes by as much as 20x.
Benchmark time series data sets for PyTorch -- the torchtime package
Aug 01, 2022The development of models for Electronic Health Record data is an area of active research featuring a small number of public benchmark data sets. Researchers typically write custom data processing code but this hinders reproducibility and can introduce errors. The Python package torchtime provides reproducible implementations of commonly used PhysioNet and UEA & UCR time series classification repository data sets for PyTorch. Features are provided for working with irregularly sampled and partially observed time series of unequal length. It aims to simplify access to PhysioNet data and enable fair comparisons of models in this exciting area of research.
Improved High-Probability Regret for Adversarial Bandits with Time-Varying Feedback Graphs
Oct 04, 2022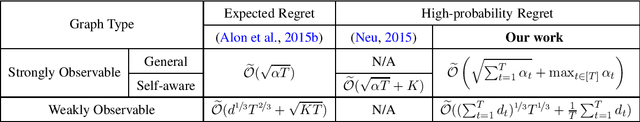
We study high-probability regret bounds for adversarial $K$-armed bandits with time-varying feedback graphs over $T$ rounds. For general strongly observable graphs, we develop an algorithm that achieves the optimal regret $\widetilde{\mathcal{O}}((\sum_{t=1}^T\alpha_t)^{1/2}+\max_{t\in[T]}\alpha_t)$ with high probability, where $\alpha_t$ is the independence number of the feedback graph at round $t$. Compared to the best existing result [Neu, 2015] which only considers graphs with self-loops for all nodes, our result not only holds more generally, but importantly also removes any $\text{poly}(K)$ dependence that can be prohibitively large for applications such as contextual bandits. Furthermore, we also develop the first algorithm that achieves the optimal high-probability regret bound for weakly observable graphs, which even improves the best expected regret bound of [Alon et al., 2015] by removing the $\mathcal{O}(\sqrt{KT})$ term with a refined analysis. Our algorithms are based on the online mirror descent framework, but importantly with an innovative combination of several techniques. Notably, while earlier works use optimistic biased loss estimators for achieving high-probability bounds, we find it important to use a pessimistic one for nodes without self-loop in a strongly observable graph.
Generative AI-empowered Effective Physical-Virtual Synchronization in the Vehicular Metaverse
Jan 19, 2023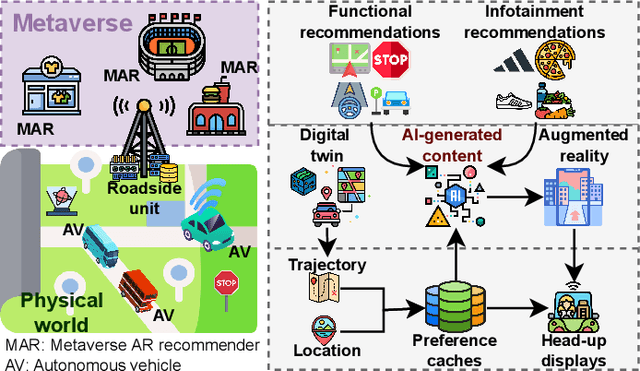
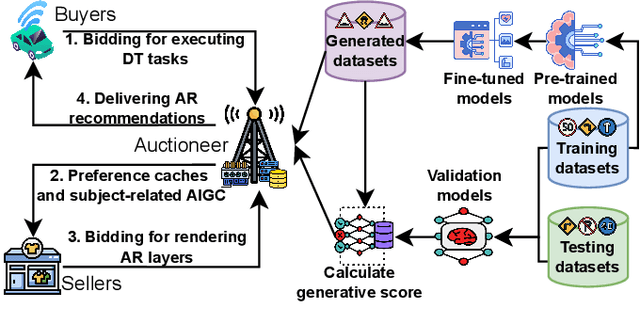

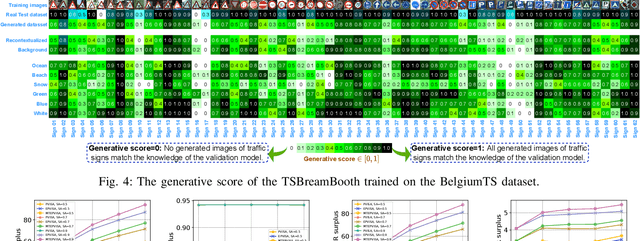
Metaverse seamlessly blends the physical world and virtual space via ubiquitous communication and computing infrastructure. In transportation systems, the vehicular Metaverse can provide a fully-immersive and hyperreal traveling experience (e.g., via augmented reality head-up displays, AR-HUDs) to drivers and users in autonomous vehicles (AVs) via roadside units (RSUs). However, provisioning real-time and immersive services necessitates effective physical-virtual synchronization between physical and virtual entities, i.e., AVs and Metaverse AR recommenders (MARs). In this paper, we propose a generative AI-empowered physical-virtual synchronization framework for the vehicular Metaverse. In physical-to-virtual synchronization, digital twin (DT) tasks generated by AVs are offloaded for execution in RSU with future route generation. In virtual-to-physical synchronization, MARs customize diverse and personal AR recommendations via generative AI models based on user preferences. Furthermore, we propose a multi-task enhanced auction-based mechanism to match and price AVs and MARs for RSUs to provision real-time and effective services. Finally, property analysis and experimental results demonstrate that the proposed mechanism is strategy-proof and adverse-selection free while increasing social surplus by 50%.
Synthetic Wavelength Imaging -- Utilizing Spectral Correlations for High-Precision Time-of-Flight Sensing
Sep 11, 2022
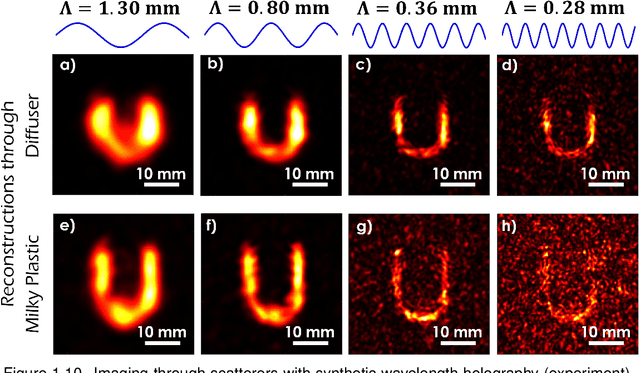
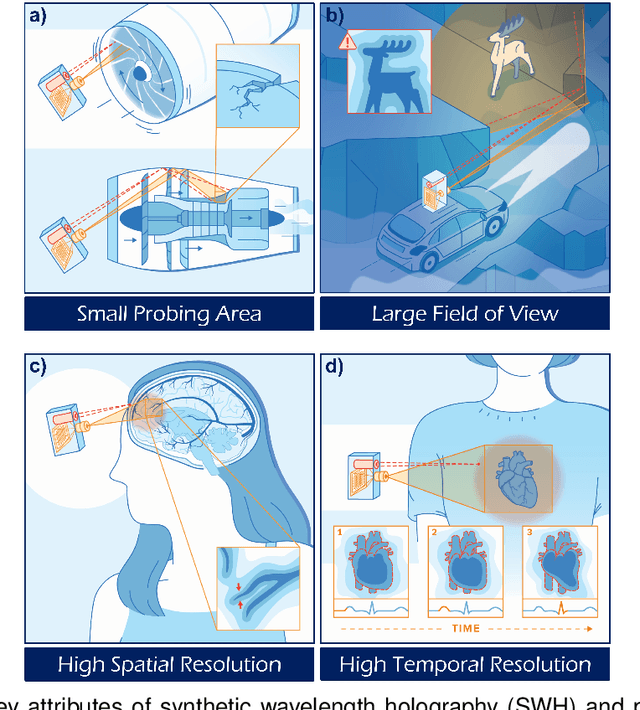
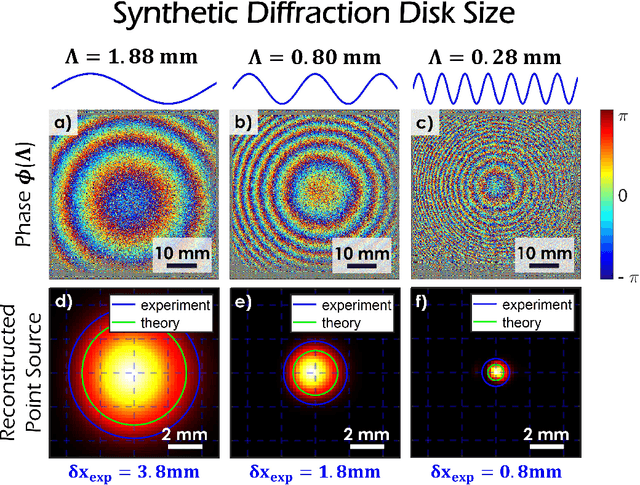
This book chapter describes how spectral correlations in scattered light fields can be utilized for high-precision time-of-flight sensing. The chapter should serve as a gentle introduction and is intended for computational imaging scientists and students new to the fascinating topic of synthetic wavelength imaging. Technical details (such as detector or light source specifications) will be largely omitted. Instead, the similarities between different methods will be emphasized to "draw the bigger picture."
Diffusion Denoising for Low-Dose-CT Model
Jan 31, 2023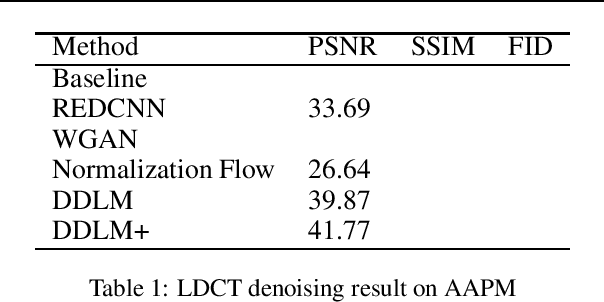

Low-dose Computed Tomography (LDCT) reconstruction is an important task in medical image analysis. Recent years have seen many deep learning based methods, proved to be effective in this area. However, these methods mostly follow a supervised architecture, which needs paired CT image of full dose and quarter dose, and the solution is highly dependent on specific measurements. In this work, we introduce Denoising Diffusion LDCT Model, dubbed as DDLM, generating noise-free CT image using conditioned sampling. DDLM uses pretrained model, and need no training nor tuning process, thus our proposal is in unsupervised manner. Experiments on LDCT images have shown comparable performance of DDLM using less inference time, surpassing other state-of-the-art methods, proving both accurate and efficient. Implementation code will be set to public soon.
Zero3D: Semantic-Driven Multi-Category 3D Shape Generation
Jan 31, 2023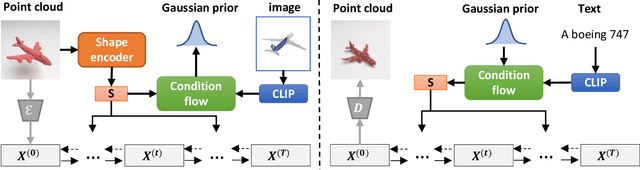
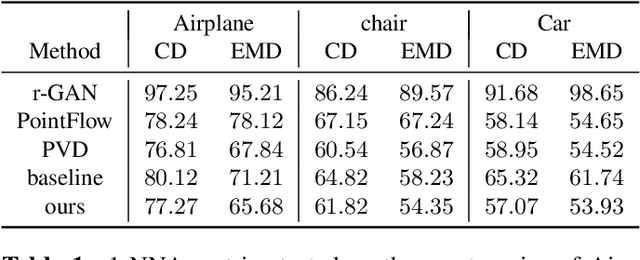
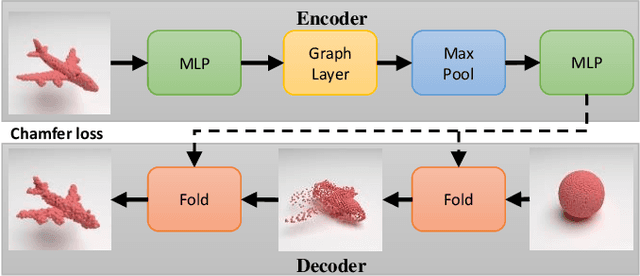
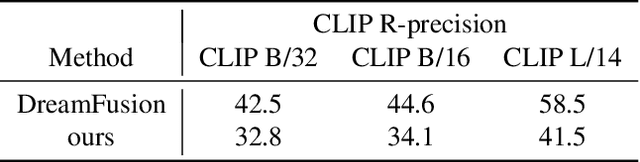
Semantic-driven 3D shape generation aims to generate 3D objects conditioned on text. Previous works face problems with single-category generation, low-frequency 3D details, and requiring a large number of paired datasets for training. To tackle these challenges, we propose a multi-category conditional diffusion model. Specifically, 1) to alleviate the problem of lack of large-scale paired data, we bridge the text, 2D image and 3D shape based on the pre-trained CLIP model, and 2) to obtain the multi-category 3D shape feature, we apply the conditional flow model to generate 3D shape vector conditioned on CLIP embedding. 3) to generate multi-category 3D shape, we employ the hidden-layer diffusion model conditioned on the multi-category shape vector, which greatly reduces the training time and memory consumption.