 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Embedded digital phase noise analyzer for optical frequency metrology
Feb 03, 2023
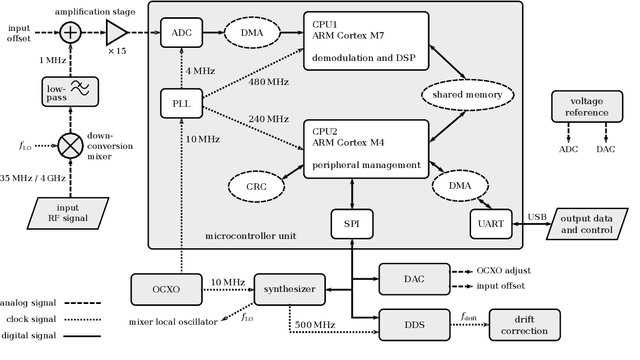
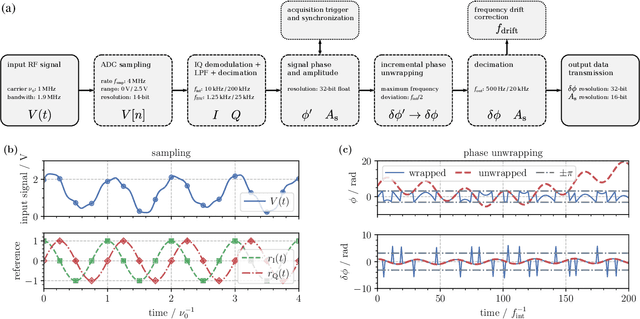
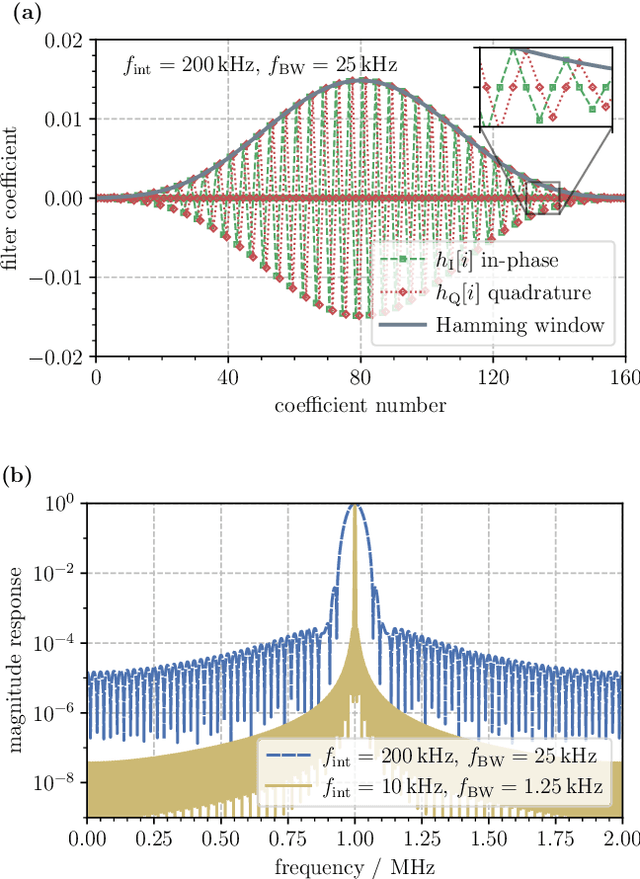
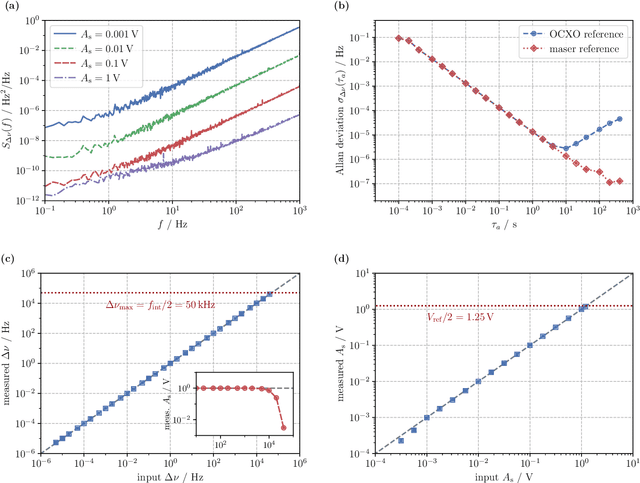
Digital signal processing is supporting novel in-field applications of optical interferometry, such as in laser ranging and distributed acoustic sensing. While the highest performances are achieved with field-programmable gated arrays, their complexity and cost are often too high for many tasks. Here, we describe an alternative solution for processing optical signals in real-time, based on a dual-core 32-bit microcontroller. We implemented in-phase and quadrature demodulation of optical beat-notes resulting from the interference of independent laser sources, phase noise analysis of deployed optical fibers covering intercity distances, and synchronization of remote acquisitions via optical trigger signals. The embedded architecture can efficiently accomplish a large variety of tasks in the context of optical signal processing, being also easily configurable, compact and upgradable. These features make it attractive for applications that require long-term, remotely-operated, and field-deployed instrumentation.
Laplacian ICP for Progressive Registration of 3D Human Head Meshes
Feb 04, 2023
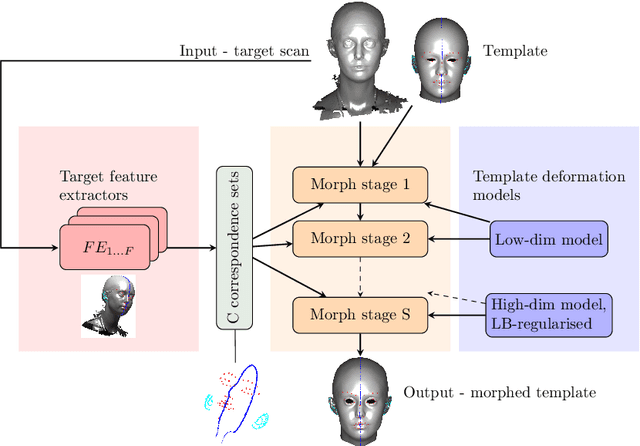

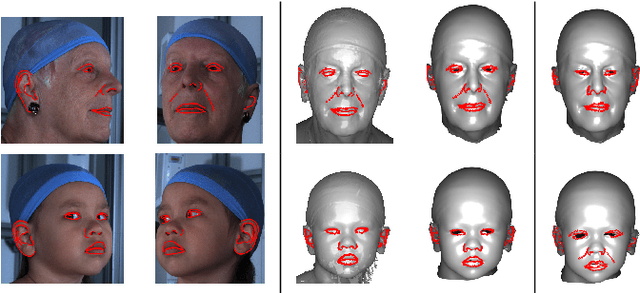
We present a progressive 3D registration framework that is a highly-efficient variant of classical non-rigid Iterative Closest Points (N-ICP). Since it uses the Laplace-Beltrami operator for deformation regularisation, we view the overall process as Laplacian ICP (L-ICP). This exploits a `small deformation per iteration' assumption and is progressively coarse-to-fine, employing an increasingly flexible deformation model, an increasing number of correspondence sets, and increasingly sophisticated correspondence estimation. Correspondence matching is only permitted within predefined vertex subsets derived from domain-specific feature extractors. Additionally, we present a new benchmark and a pair of evaluation metrics for 3D non-rigid registration, based on annotation transfer. We use this to evaluate our framework on a publicly-available dataset of 3D human head scans (Headspace). The method is robust and only requires a small fraction of the computation time compared to the most popular classical approach, yet has comparable registration performance.
* 7 pages, 6 figures
Detecting Security Patches via Behavioral Data in Code Repositories
Feb 04, 2023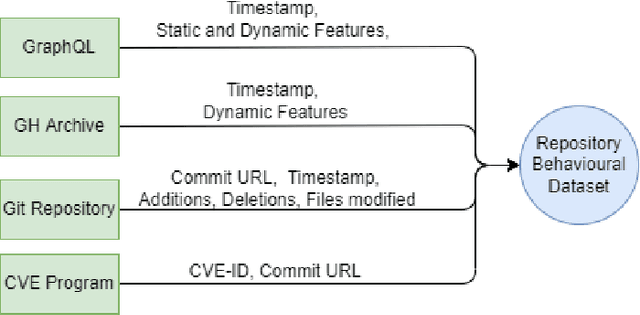
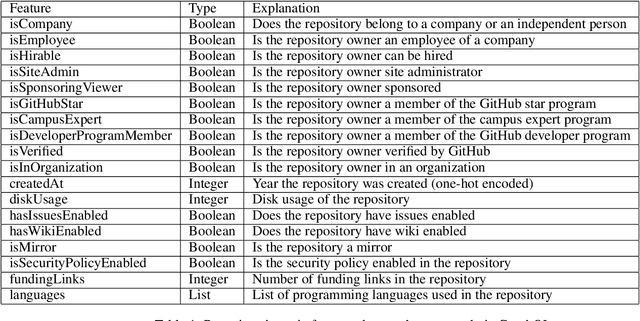
The absolute majority of software today is developed collaboratively using collaborative version control tools such as Git. It is a common practice that once a vulnerability is detected and fixed, the developers behind the software issue a Common Vulnerabilities and Exposures or CVE record to alert the user community of the security hazard and urge them to integrate the security patch. However, some companies might not disclose their vulnerabilities and just update their repository. As a result, users are unaware of the vulnerability and may remain exposed. In this paper, we present a system to automatically identify security patches using only the developer behavior in the Git repository without analyzing the code itself or the remarks that accompanied the fix (commit message). We showed we can reveal concealed security patches with an accuracy of 88.3% and F1 Score of 89.8%. This is the first time that a language-oblivious solution for this problem is presented.
Proactive and Reactive Engagement of Artificial Intelligence Methods for Education: A Review
Jan 23, 2023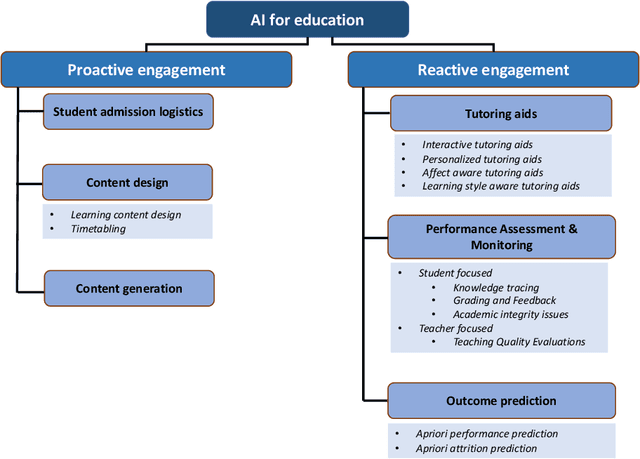
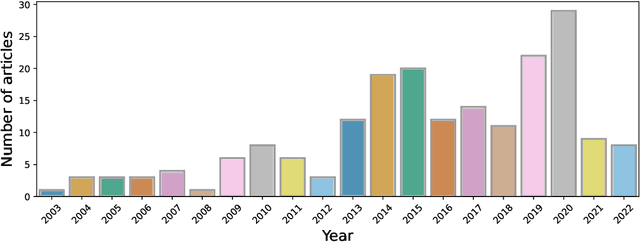
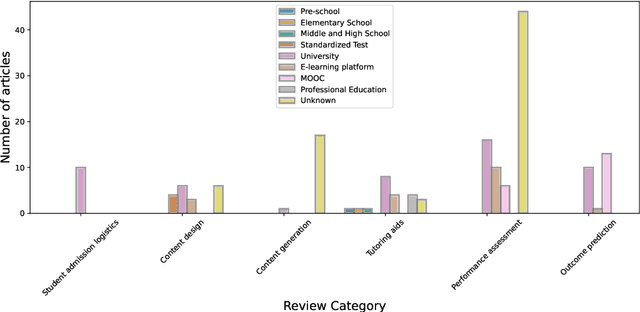
Quality education, one of the seventeen sustainable development goals (SDGs) identified by the United Nations General Assembly, stands to benefit enormously from the adoption of artificial intelligence (AI) driven tools and technologies. The concurrent boom of necessary infrastructure, digitized data and general social awareness has propelled massive research and development efforts in the artificial intelligence for education (AIEd) sector. In this review article, we investigate how artificial intelligence, machine learning and deep learning methods are being utilized to support students, educators and administrative staff. We do this through the lens of a novel categorization approach. We consider the involvement of AI-driven methods in the education process in its entirety - from students admissions, course scheduling etc. in the proactive planning phase to knowledge delivery, performance assessment etc. in the reactive execution phase. We outline and analyze the major research directions under proactive and reactive engagement of AI in education using a representative group of 194 original research articles published in the past two decades i.e., 2003 - 2022. We discuss the paradigm shifts in the solution approaches proposed, i.e., in the choice of data and algorithms used over this time. We further dive into how the COVID-19 pandemic challenged and reshaped the education landscape at the fag end of this time period. Finally, we pinpoint existing limitations in adopting artificial intelligence for education and reflect on the path forward.
Concrete Safety for ML Problems: System Safety for ML Development and Assessment
Feb 06, 2023
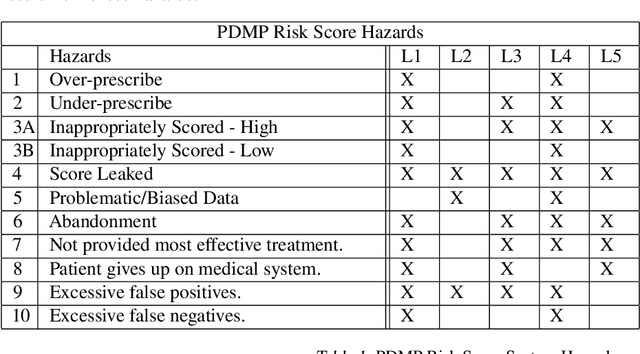
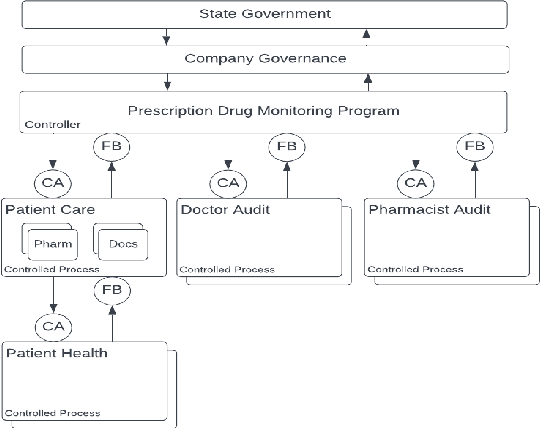
Many stakeholders struggle to make reliances on ML-driven systems due to the risk of harm these systems may cause. Concerns of trustworthiness, unintended social harms, and unacceptable social and ethical violations undermine the promise of ML advancements. Moreover, such risks in complex ML-driven systems present a special challenge as they are often difficult to foresee, arising over periods of time, across populations, and at scale. These risks often arise not from poor ML development decisions or low performance directly but rather emerge through the interactions amongst ML development choices, the context of model use, environmental factors, and the effects of a model on its target. Systems safety engineering is an established discipline with a proven track record of identifying and managing risks even in high-complexity sociotechnical systems. In this work, we apply a state-of-the-art systems safety approach to concrete applications of ML with notable social and ethical risks to demonstrate a systematic means for meeting the assurance requirements needed to argue for safe and trustworthy ML in sociotechnical systems.
On Exact Sampling in the Two-Variable Fragment of First-Order Logic
Feb 06, 2023
In this paper, we study the sampling problem for first-order logic proposed recently by Wang et al. -- how to efficiently sample a model of a given first-order sentence on a finite domain? We extend their result for the universally-quantified subfragment of two-variable logic $\mathbf{FO}^2$ ($\mathbf{UFO}^2$) to the entire fragment of $\mathbf{FO}^2$. Specifically, we prove the domain-liftability under sampling of $\mathbf{FO}^2$, meaning that there exists a sampling algorithm for $\mathbf{FO}^2$ that runs in time polynomial in the domain size. We then further show that this result continues to hold even in the presence of counting constraints, such as $\forall x\exists_{=k} y: \varphi(x,y)$ and $\exists_{=k} x\forall y: \varphi(x,y)$, for some quantifier-free formula $\varphi(x,y)$. Our proposed method is constructive, and the resulting sampling algorithms have potential applications in various areas, including the uniform generation of combinatorial structures and sampling in statistical-relational models such as Markov logic networks and probabilistic logic programs.
From CAD models to soft point cloud labels: An automatic annotation pipeline for cheaply supervised 3D semantic segmentation
Feb 06, 2023
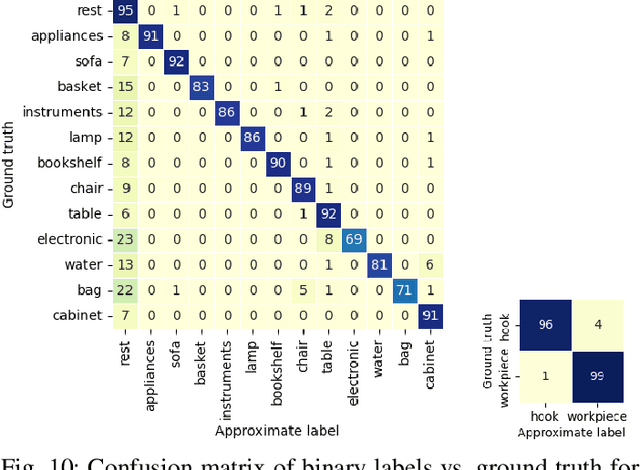
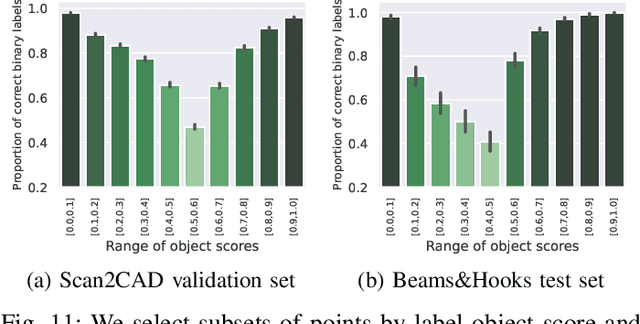
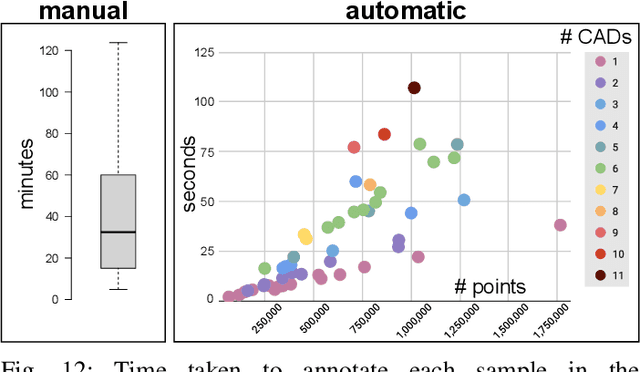
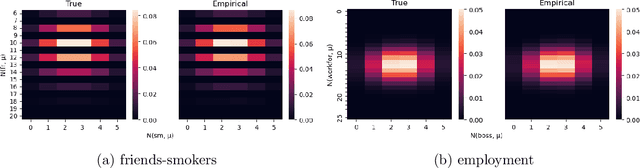
We propose a fully automatic annotation scheme which takes a raw 3D point cloud with a set of fitted CAD models as input, and outputs convincing point-wise labels which can be used as cheap training data for point cloud segmentation. Compared to manual annotations, we show that our automatic labels are accurate while drastically reducing the annotation time, and eliminating the need for manual intervention or dataset-specific parameters. Our labeling pipeline outputs semantic classes and soft point-wise object scores which can either be binarized into standard one-hot-encoded labels, thresholded into weak labels with ambiguous points left unlabeled, or used directly as soft labels during training. We evaluate the label quality and segmentation performance of PointNet++ on a dataset of real industrial point clouds and Scan2CAD, a public dataset of indoor scenes. Our results indicate that reducing supervision in areas which are more difficult to label automatically is beneficial, compared to the conventional approach of naively assigning a hard "best guess" label to every point.
Accelerated Dynamic Magnetic Resonance Imaging from Spatial-Subspace Reconstructions (SPARS)
Feb 06, 2023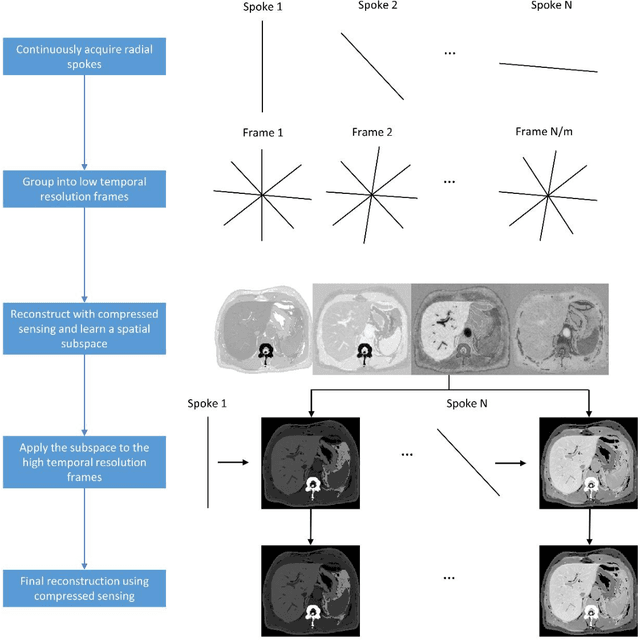
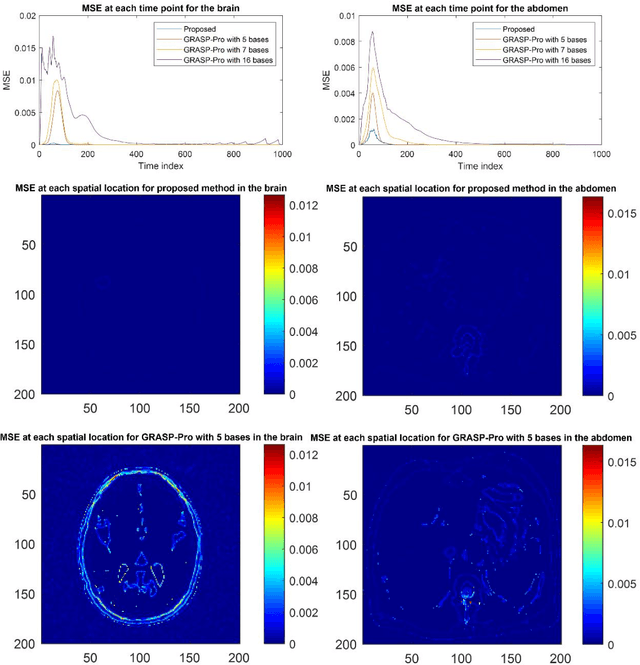
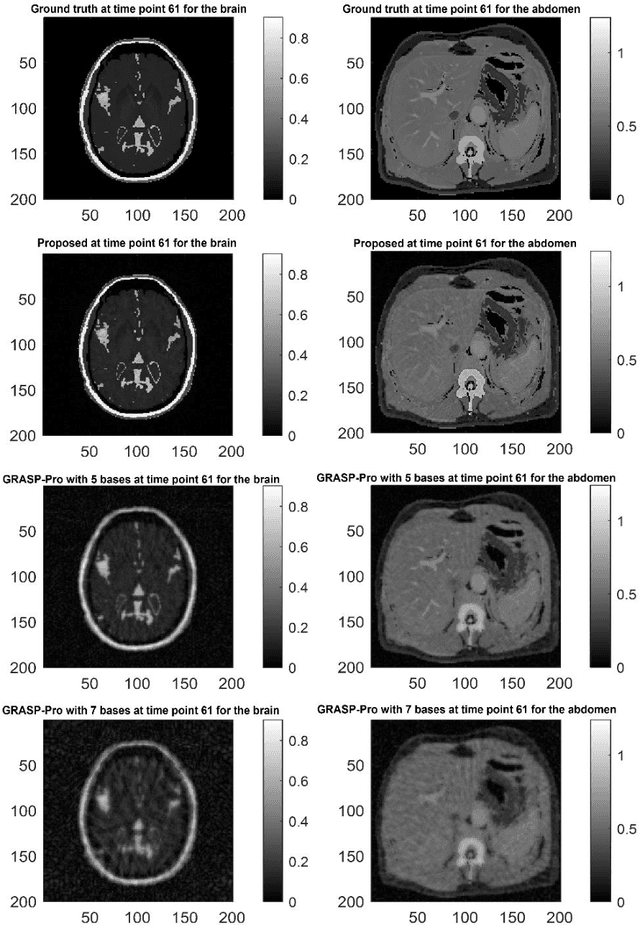
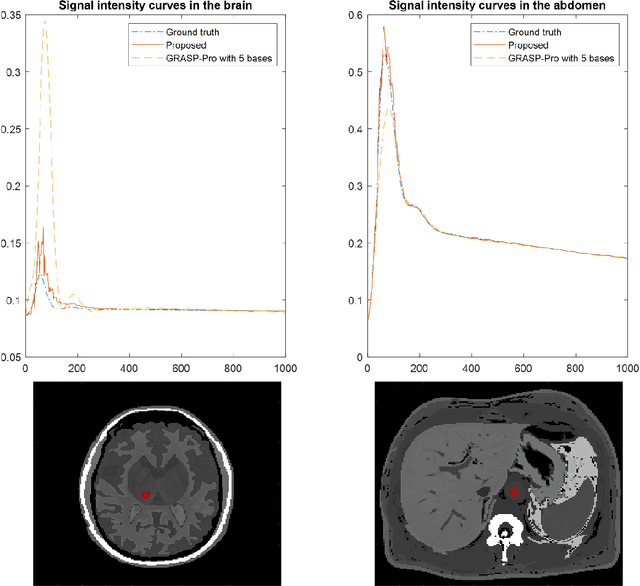
Dynamic contrast-enhanced (DCE) magnetic resonance imaging (MRI) ideally requires a high spatial and high temporal resolution, but hardware limitations prevent acquisitions from simultaneously achieving both. Existing image reconstruction techniques can artificially create spatial resolution at a given temporal resolution by estimating data that is not acquired, but, ultimately, spatial details are sacrificed at very high acceleration rates. The purpose of this paper is to introduce the concept of spatial subspace reconstructions (SPARS) and demonstrate its ability to reconstruct high spatial resolution dynamic images from as few as one acquired radial spoke per dynamic frame. Briefly, a low-temporal-high-spatial resolution organization of the acquired raw data is used to estimate a spatial subspace in which the high-temporal-high-spatial ground truth data resides. This subspace is then used to estimate entire images from single k-space spokes. In both simulated and human in-vivo data, the proposed SPARS reconstruction method outperformed standard GRASP and GRASP-Pro reconstruction, providing a shorter reconstruction time and yielding higher accuracy from both a spatial and temporal perspective.
Cooperative Task-Oriented Communication for Multi-Modal Data with Transmission Control
Feb 06, 2023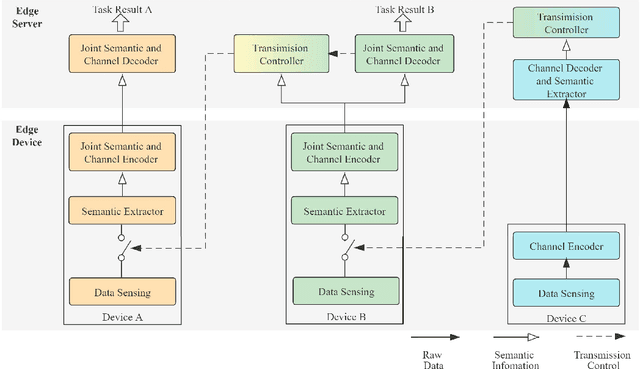
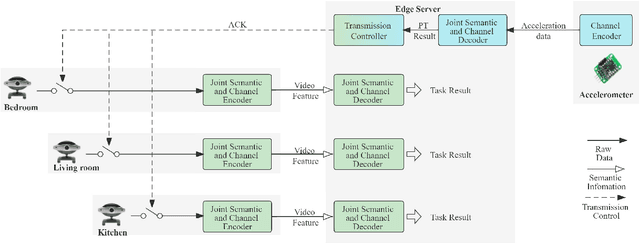


Real-time intelligence applications in Internet of Things (IoT) environment depend on timely data communication. However, it is challenging to transmit and analyse massive data of various modalities. Recently proposed task-oriented communication methods based on deep learning have showed its superiority in communication efficiency. In this paper, we propose a cooperative task-oriented communication method for the transmission of multi-modal data from multiple end devices to a central server. In particular, we use the transmission result of data of one modality, which is with lower rate, to control the transmission of other modalities with higher rate in order to reduce the amount of transmitted date. We take the human activity recognition (HAR) task in a smart home environment and design the semantic-oriented transceivers for the transmission of monitoring videos of different rooms and acceleration data of the monitored human. The numerical results demonstrate that by using the transmission control based on the obtained results of the received acceleration data, the transmission is reduced to 2% of that without transmission control while preserving the performance on the HAR task.
Fast-MC-PET: A Novel Deep Learning-aided Motion Correction and Reconstruction Framework for Accelerated PET
Feb 14, 2023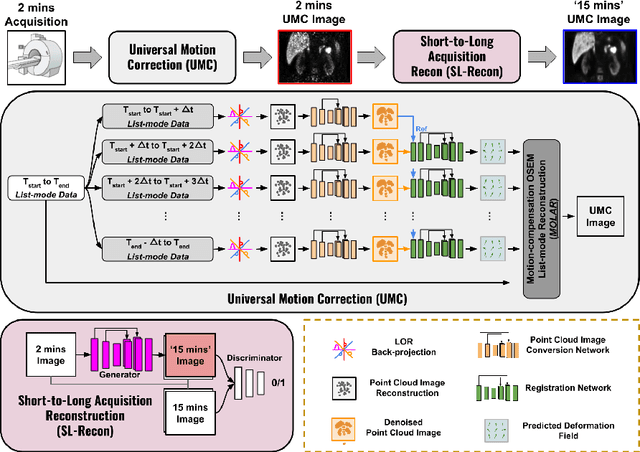
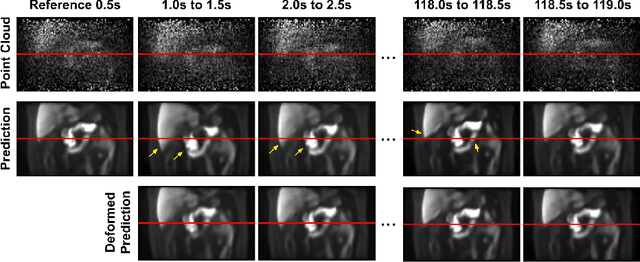

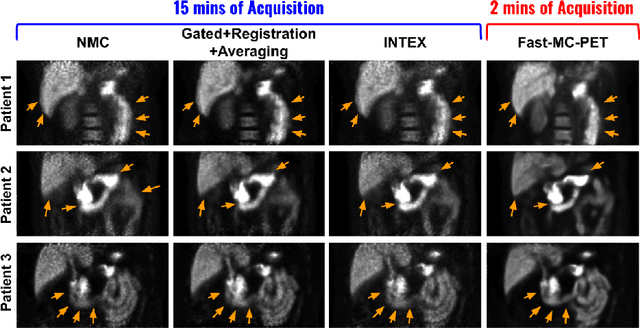
Patient motion during PET is inevitable. Its long acquisition time not only increases the motion and the associated artifacts but also the patient's discomfort, thus PET acceleration is desirable. However, accelerating PET acquisition will result in reconstructed images with low SNR, and the image quality will still be degraded by motion-induced artifacts. Most of the previous PET motion correction methods are motion type specific that require motion modeling, thus may fail when multiple types of motion present together. Also, those methods are customized for standard long acquisition and could not be directly applied to accelerated PET. To this end, modeling-free universal motion correction reconstruction for accelerated PET is still highly under-explored. In this work, we propose a novel deep learning-aided motion correction and reconstruction framework for accelerated PET, called Fast-MC-PET. Our framework consists of a universal motion correction (UMC) and a short-to-long acquisition reconstruction (SL-Reon) module. The UMC enables modeling-free motion correction by estimating quasi-continuous motion from ultra-short frame reconstructions and using this information for motion-compensated reconstruction. Then, the SL-Recon converts the accelerated UMC image with low counts to a high-quality image with high counts for our final reconstruction output. Our experimental results on human studies show that our Fast-MC-PET can enable 7-fold acceleration and use only 2 minutes acquisition to generate high-quality reconstruction images that outperform/match previous motion correction reconstruction methods using standard 15 minutes long acquisition data.