 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optical Flow estimation with Event-based Cameras and Spiking Neural Networks
Feb 13, 2023
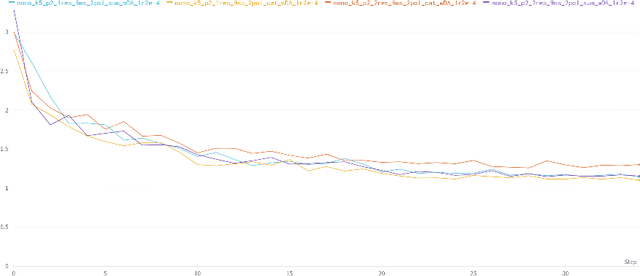
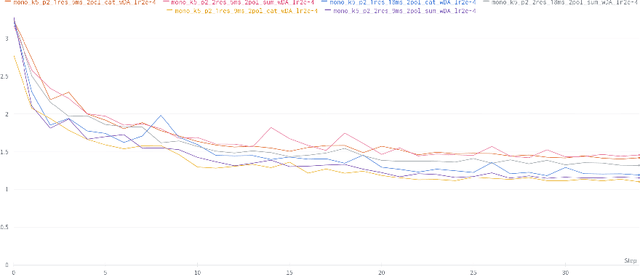
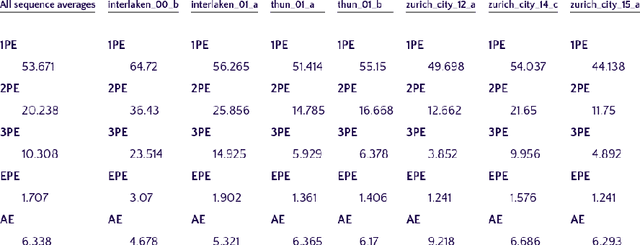
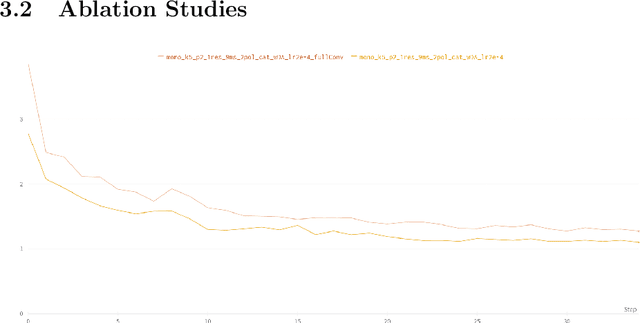
Event-based cameras are raising interest within the computer vision community. These sensors operate with asynchronous pixels, emitting events, or "spikes", when the luminance change at a given pixel since the last event surpasses a certain threshold. Thanks to their inherent qualities, such as their low power consumption, low latency and high dynamic range, they seem particularly tailored to applications with challenging temporal constraints and safety requirements. Event-based sensors are an excellent fit for Spiking Neural Networks (SNNs), since the coupling of an asynchronous sensor with neuromorphic hardware can yield real-time systems with minimal power requirements. In this work, we seek to develop one such system, using both event sensor data from the DSEC dataset and spiking neural networks to estimate optical flow for driving scenarios. We propose a U-Net-like SNN which, after supervised training, is able to make dense optical flow estimations. To do so, we encourage both minimal norm for the error vector and minimal angle between ground-truth and predicted flow, training our model with back-propagation using a surrogate gradient. In addition, the use of 3d convolutions allows us to capture the dynamic nature of the data by increasing the temporal receptive fields. Upsampling after each decoding stage ensures that each decoder's output contributes to the final estimation. Thanks to separable convolutions, we have been able to develop a light model (when compared to competitors) that can nonetheless yield reasonably accurate optical flow estimates.
Persistence Initialization: A novel adaptation of the Transformer architecture for Time Series Forecasting
Aug 30, 2022
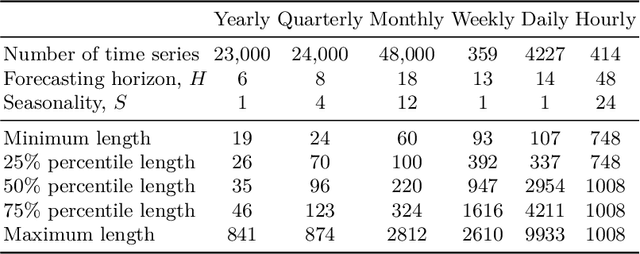
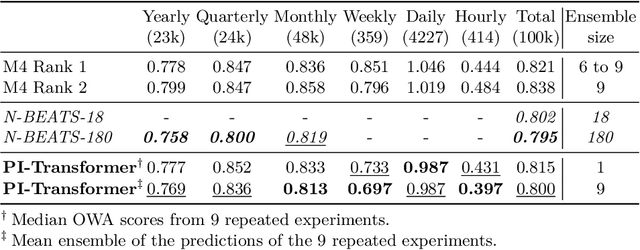
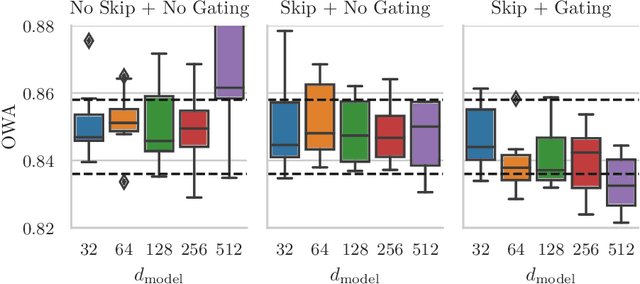
Time series forecasting is an important problem, with many real world applications. Ensembles of deep neural networks have recently achieved impressive forecasting accuracy, but such large ensembles are impractical in many real world settings. Transformer models been successfully applied to a diverse set of challenging problems. We propose a novel adaptation of the original Transformer architecture focusing on the task of time series forecasting, called Persistence Initialization. The model is initialized as a naive persistence model by using a multiplicative gating mechanism combined with a residual skip connection. We use a decoder Transformer with ReZero normalization and Rotary positional encodings, but the adaptation is applicable to any auto-regressive neural network model. We evaluate our proposed architecture on the challenging M4 dataset, achieving competitive performance compared to ensemble based methods. We also compare against existing recently proposed Transformer models for time series forecasting, showing superior performance on the M4 dataset. Extensive ablation studies show that Persistence Initialization leads to better performance and faster convergence. As the size of the model increases, only the models with our proposed adaptation gain in performance. We also perform an additional ablation study to determine the importance of the choice of normalization and positional encoding, and find both the use of Rotary encodings and ReZero normalization to be essential for good forecasting performance.
How to choose "Good" Samples for Text Data Augmentation
Feb 02, 2023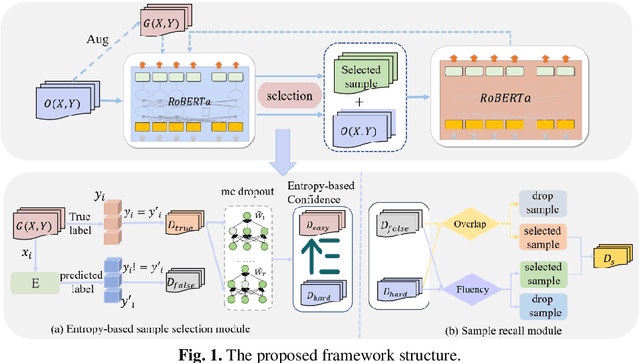
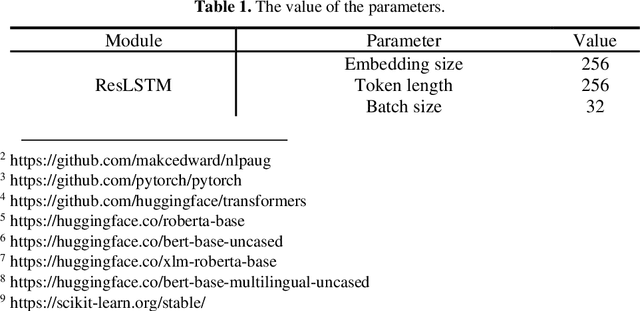
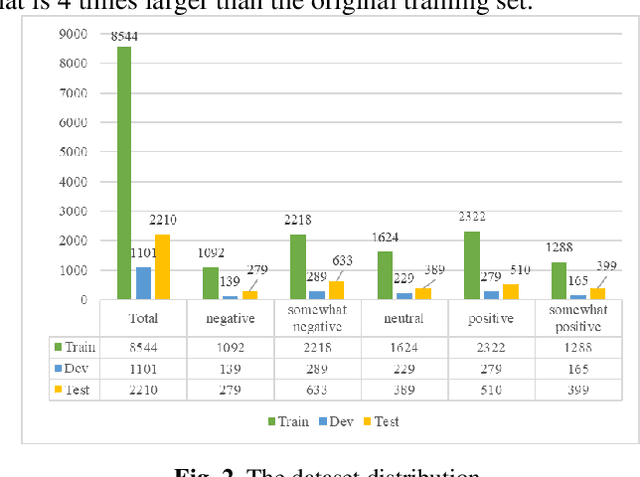

Deep learning-based text classification models need abundant labeled data to obtain competitive performance. Unfortunately, annotating large-size corpus is time-consuming and laborious. To tackle this, multiple researches try to use data augmentation to expand the corpus size. However, data augmentation may potentially produce some noisy augmented samples. There are currently no works exploring sample selection for augmented samples in nature language processing field. In this paper, we propose a novel self-training selection framework with two selectors to select the high-quality samples from data augmentation. Specifically, we firstly use an entropy-based strategy and the model prediction to select augmented samples. Considering some samples with high quality at the above step may be wrongly filtered, we propose to recall them from two perspectives of word overlap and semantic similarity. Experimental results show the effectiveness and simplicity of our framework.
Diffusion-based Time Series Imputation and Forecasting with Structured State Space Models
Aug 19, 2022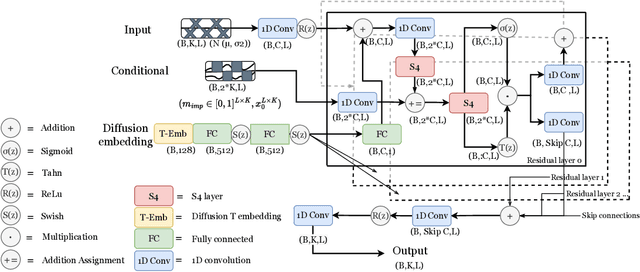
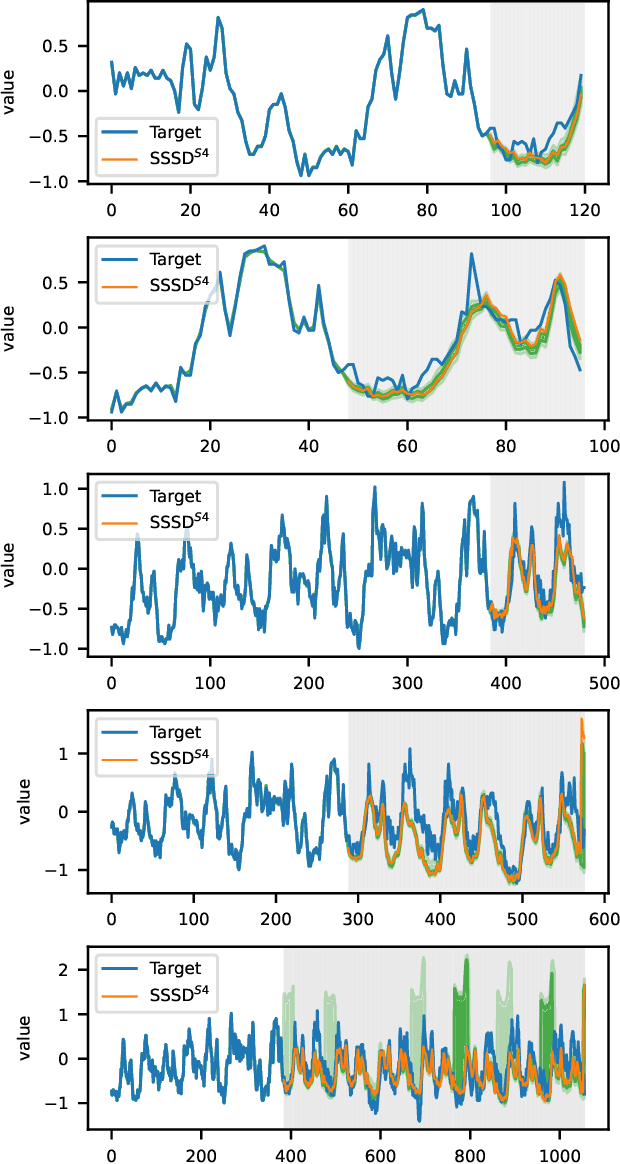
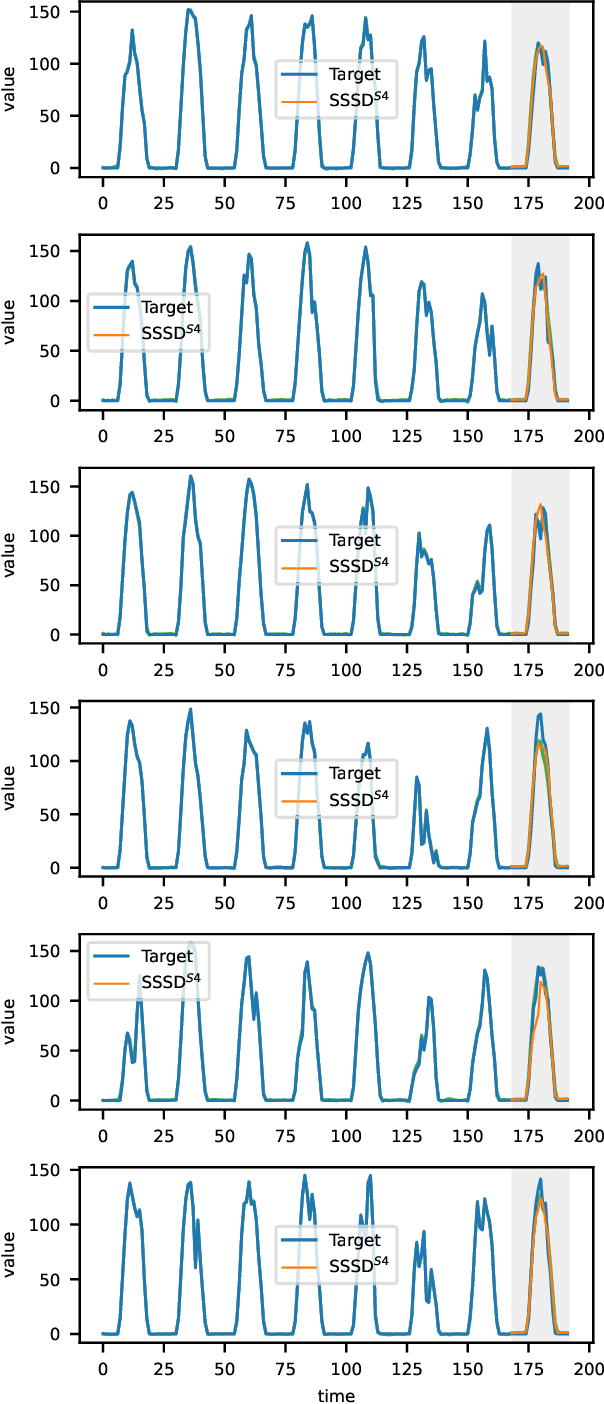
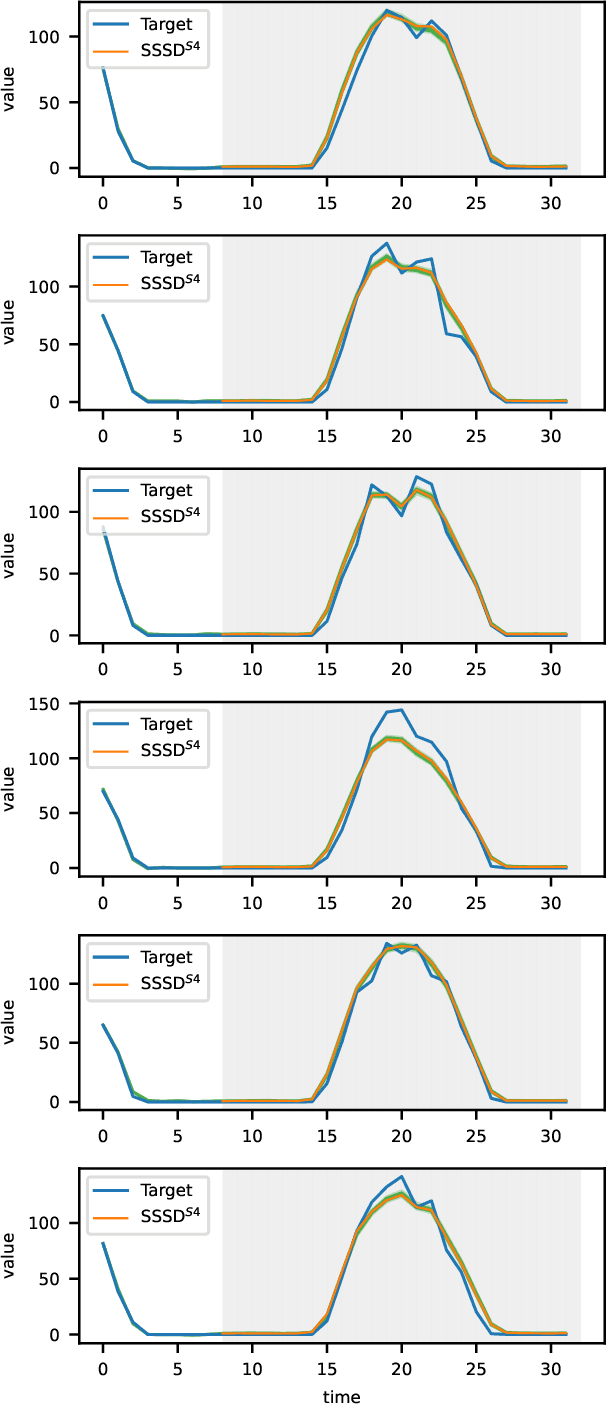
The imputation of missing values represents a significant obstacle for many real-world data analysis pipelines. Here, we focus on time series data and put forward SSSD, an imputation model that relies on two emerging technologies, (conditional) diffusion models as state-of-the-art generative models and structured state space models as internal model architecture, which are particularly suited to capture long-term dependencies in time series data. We demonstrate that SSSD matches or even exceeds state-of-the-art probabilistic imputation and forecasting performance on a broad range of data sets and different missingness scenarios, including the challenging blackout-missing scenarios, where prior approaches failed to provide meaningful results.
Efficient Adversarial Contrastive Learning via Robustness-Aware Coreset Selection
Feb 08, 2023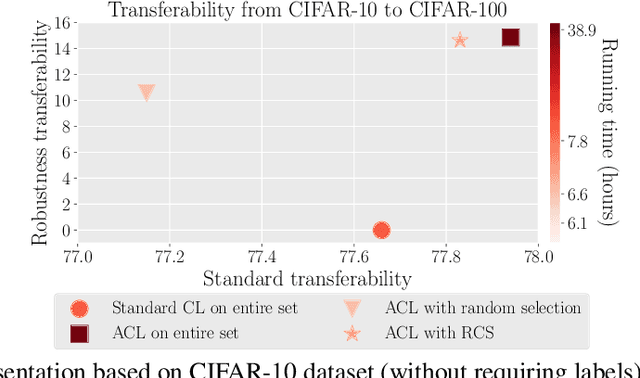

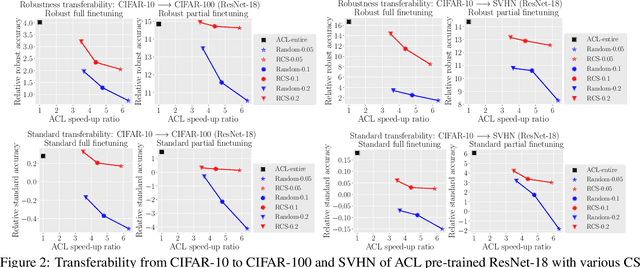

Adversarial contrastive learning (ACL) does not require expensive data annotations but outputs a robust representation that withstands adversarial attacks and also generalizes to a wide range of downstream tasks. However, ACL needs tremendous running time to generate the adversarial variants of all training data, which limits its scalability to large datasets. To speed up ACL, this paper proposes a robustness-aware coreset selection (RCS) method. RCS does not require label information and searches for an informative subset that minimizes a representational divergence, which is the distance of the representation between natural data and their virtual adversarial variants. The vanilla solution of RCS via traversing all possible subsets is computationally prohibitive. Therefore, we theoretically transform RCS into a surrogate problem of submodular maximization, of which the greedy search is an efficient solution with an optimality guarantee for the original problem. Empirically, our comprehensive results corroborate that RCS can speed up ACL by a large margin without significantly hurting the robustness and standard transferability. Notably, to the best of our knowledge, we are the first to conduct ACL efficiently on the large-scale ImageNet-1K dataset to obtain an effective robust representation via RCS.
FastPillars: A Deployment-friendly Pillar-based 3D Detector
Feb 08, 2023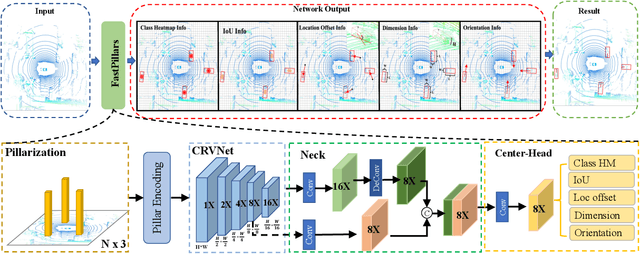
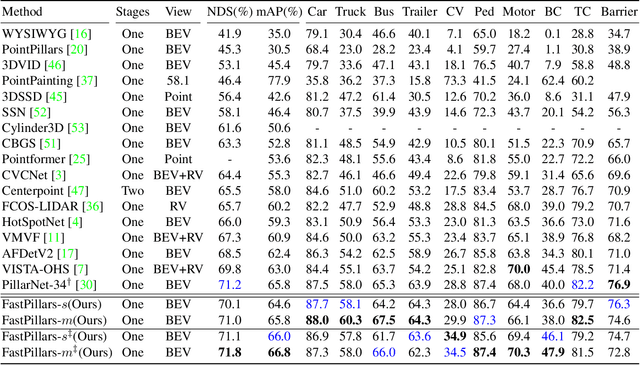
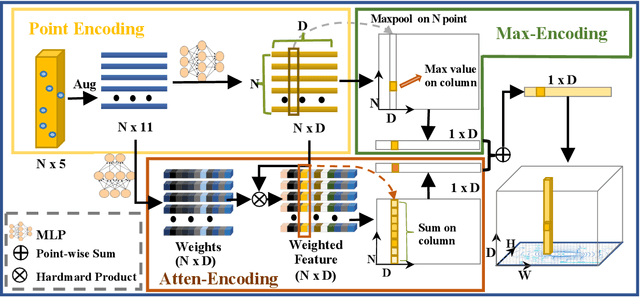
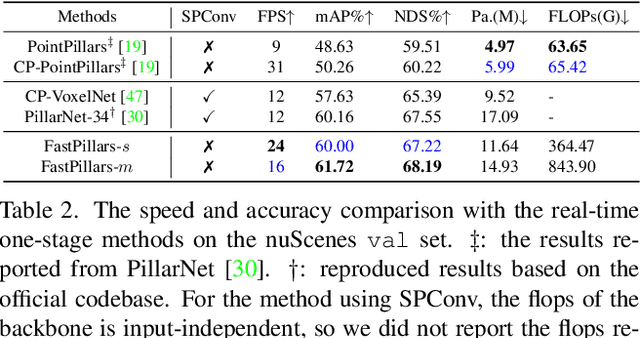
The deployment of 3D detectors strikes one of the major challenges in real-world self-driving scenarios. Existing BEV-based (i.e., Bird Eye View) detectors favor sparse convolution (known as SPConv) to speed up training and inference, which puts a hard barrier for deployment especially for on-device applications. In this paper, we tackle the problem of efficient 3D object detection from LiDAR point clouds with deployment in mind. To reduce computational burden, we propose a pillar-based 3D detector with high performance from an industry perspective, termed FastPillars. Compared with previous methods, we introduce a more effective Max-and-Attention pillar encoding (MAPE) module, and redesigning a powerful and lightweight backbone CRVNet imbued with Cross Stage Partial network (CSP) in a reparameterization style, forming a compact feature representation framework. Extensive experiments demonstrate that our FastPillars surpasses the state-of-the-art 3D detectors regarding both on-device speed and performance. Specifically, FastPillars can be effectively deployed through TensorRT, obtaining real-time performance (24FPS) on a single RTX3070Ti GPU with 64.6 mAP on the nuScenes test set. Our code is publicly available at: https://github.com/StiphyJay/FastPillars.
Gas Leak detection using airborne US Sensors
Feb 08, 2023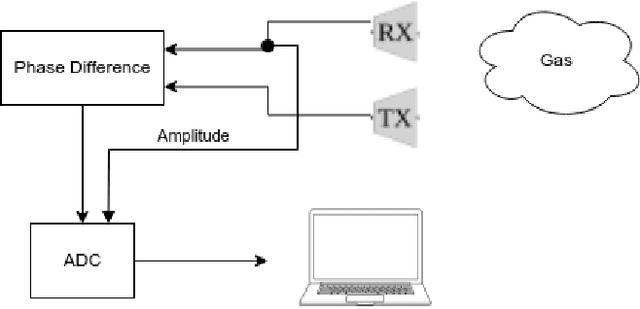
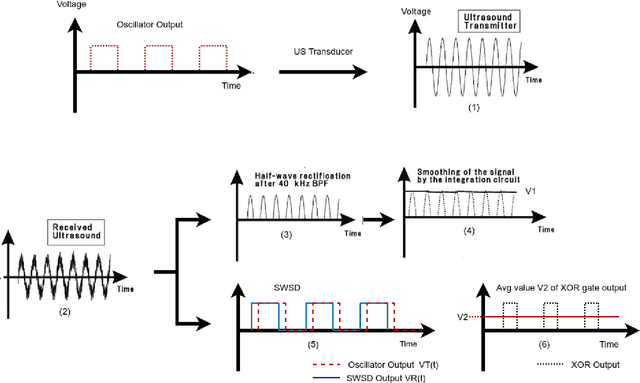
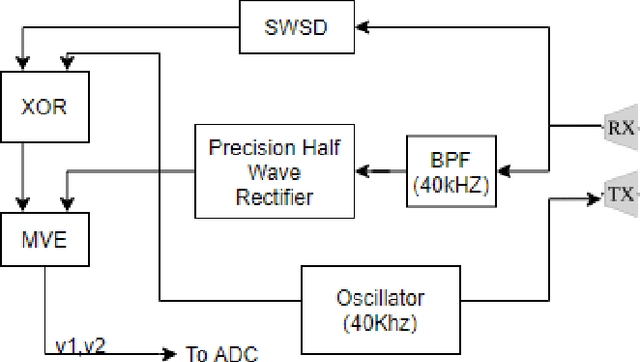

Gas leakage is a critical problem in the industrial sector, residential structures, and gas-powered vehicles; installing gas leakage detection systems is one of the preventative strategies for reducing hazards caused by gas leakage. Conventional gas sensors, such as electrochemical, infrared point, and MOS sensors, have traditionally been used to detect leaks. The challenge with these sensors is their versatility in settings involving many gases, as well as their exorbitant cost and scalability. As a result, several gas detection approaches were explored. Our approach utilizes 40 KHz ultrasound signal for gas detection. Here, the reflected signal has been analyzed to detect gas leaks and identify gas in real-time, providing a quick, reliable solution for gas leak detection in industrial environments. The electronics and sensors used are both low-cost and easily scalable. The system incorporates commonly accessible materials and off-the-shelf components, making it suitable for use in a variety of contexts. They are also more effective at detecting numerous gas leaks and has a longer lifetime. Butane was used to test our system. The breaches were identified in 0.01 seconds after permitting gas to flow from a broken pipe, whereas identifying the gas took 0.8 seconds
WAT: Improve the Worst-class Robustness in Adversarial Training
Feb 08, 2023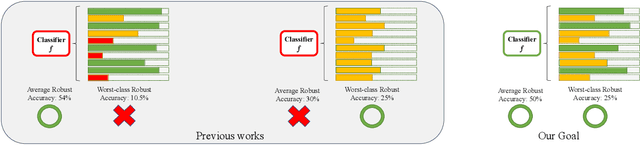
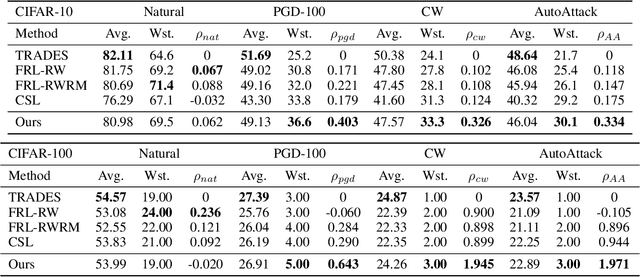
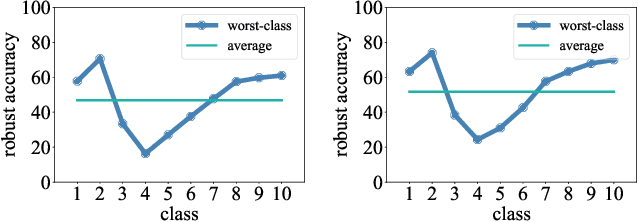
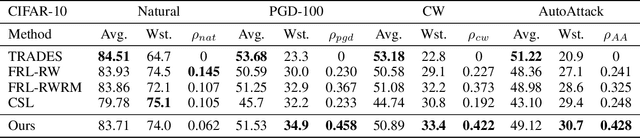
Deep Neural Networks (DNN) have been shown to be vulnerable to adversarial examples. Adversarial training (AT) is a popular and effective strategy to defend against adversarial attacks. Recent works (Benz et al., 2020; Xu et al., 2021; Tian et al., 2021) have shown that a robust model well-trained by AT exhibits a remarkable robustness disparity among classes, and propose various methods to obtain consistent robust accuracy across classes. Unfortunately, these methods sacrifice a good deal of the average robust accuracy. Accordingly, this paper proposes a novel framework of worst-class adversarial training and leverages no-regret dynamics to solve this problem. Our goal is to obtain a classifier with great performance on worst-class and sacrifice just a little average robust accuracy at the same time. We then rigorously analyze the theoretical properties of our proposed algorithm, and the generalization error bound in terms of the worst-class robust risk. Furthermore, we propose a measurement to evaluate the proposed method in terms of both the average and worst-class accuracies. Experiments on various datasets and networks show that our proposed method outperforms the state-of-the-art approaches.
Alamouti-Like Transmission Schemes in Distributed MIMO Networks
Feb 08, 2023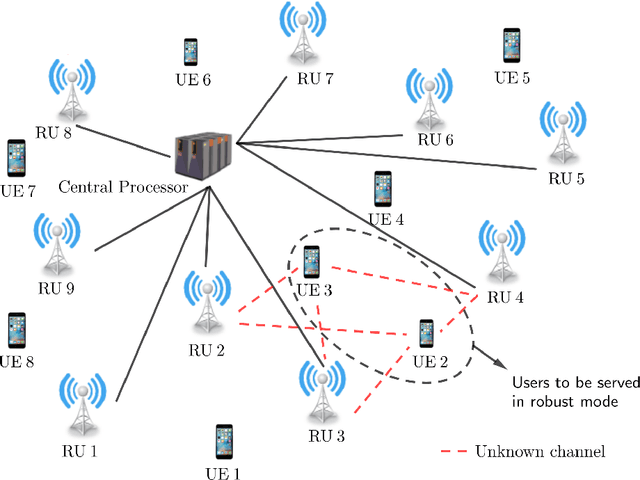
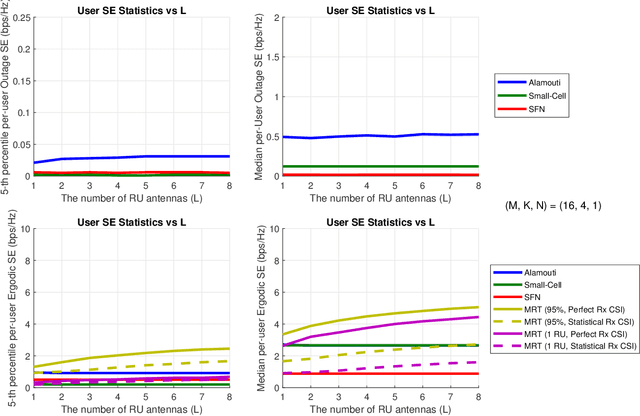
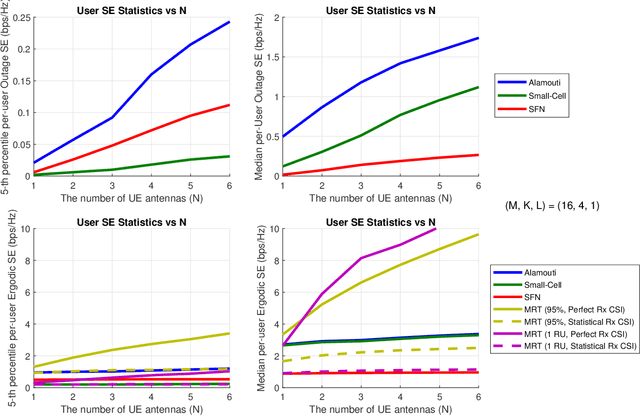
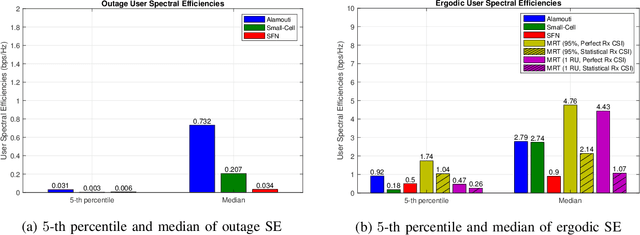
The purpose of the study is to investigate potential benefits of using Alamouti-like orthogonal space-time-frequency block codes (STFBC) in distributed multiple-input multiple-output (D-MIMO) systems to increase the diversity at the UE side when instantaneous channel state information (CSI) is not available at radio units (RUs). Most of the existing transmission techniques require instantaneous CSI to form precoders which can only be realized together with accurate and up-to-date channel knowledge. STFBC can increase the diversity at UE side without estimating the downlink channel. Under challenging channel conditions, the network can switch to a robust mode where a certain data rate is maintained for users even without knowing the channel coefficients by means of STFBC. In this study, it will be mainly focused on clustering of RUs and user equipment, where each cluster adopts a possibly different orthogonal code, so that overall spectral efficiency is optimized. Potential performance gains over known techniques that can be used when the channel is not known will be shown and performance gaps to sophisticated precoders making use of channel estimates will be identified.
Predicting the performance of hybrid ventilation in buildings using a multivariate attention-based biLSTM Encoder-Decoder neural network
Feb 08, 2023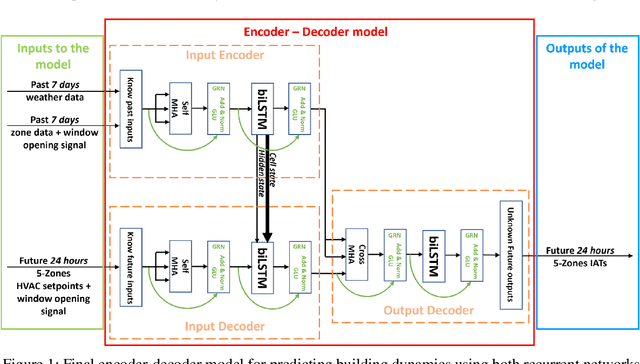
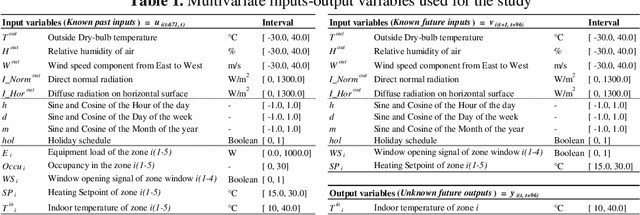

Hybrid ventilation (coupling natural and mechanical ventilation) is an energy-efficient solution to provide fresh air for most climates, given that it has a reliable control system. To operate such systems optimally, a high-fidelity control-oriented model is required. It should enable near-real time forecast of the indoor air temperature and humidity based on operational conditions such as window opening and HVAC schedules. However, widely used physics-based simulation models (i.e., white-box models) are labour-intensive and computationally expensive. Alternatively, black-box models based on artificial neural networks can be trained to be good estimators for building dynamics. This paper investigates the capabilities of a multivariate multi-head attention-based long short-term memory (LSTM) encoder-decoder neural network to predict indoor air conditions of a building equipped with hybrid ventilation. The deep neural network used for this study aims to predict indoor air temperature dynamics when a window is opened and closed, respectively. Training and test data were generated from detailed multi-zone office building model (EnergyPlus). The deep neural network is able to accurately predict indoor air temperature of five zones whenever a window was opened and closed.