 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Comparing Ordering Strategies For Process Discovery Using Synthesis Rules
Jan 04, 2023
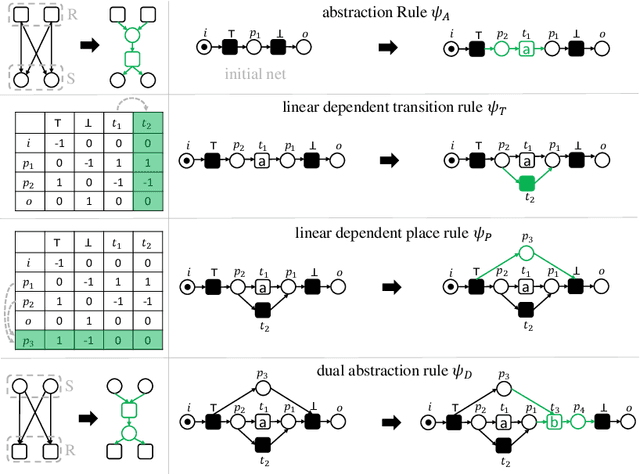
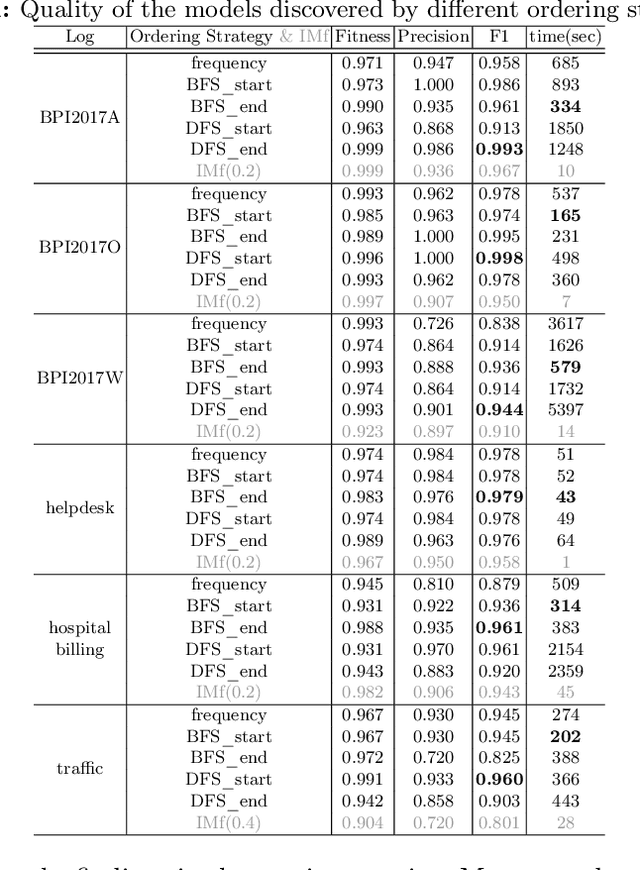

Process discovery aims to learn process models from observed behaviors, i.e., event logs, in the information systems.The discovered models serve as the starting point for process mining techniques that are used to address performance and compliance problems. Compared to the state-of-the-art Inductive Miner, the algorithm applying synthesis rules from the free-choice net theory discovers process models with more flexible (non-block) structures while ensuring the same desirable soundness and free-choiceness properties. Moreover, recent development in this line of work shows that the discovered models have compatible quality. Following the synthesis rules, the algorithm incrementally modifies an existing process model by adding the activities in the event log one at a time. As the applications of rules are highly dependent on the existing model structure, the model quality and computation time are significantly influenced by the order of adding activities. In this paper, we investigate the effect of different ordering strategies on the discovered models (w.r.t. fitness and precision) and the computation time using real-life event data. The results show that the proposed ordering strategy can improve the quality of the resulting process models while requiring less time compared to the ordering strategy solely based on the frequency of activities.
DANLIP: Deep Autoregressive Networks for Locally Interpretable Probabilistic Forecasting
Jan 05, 2023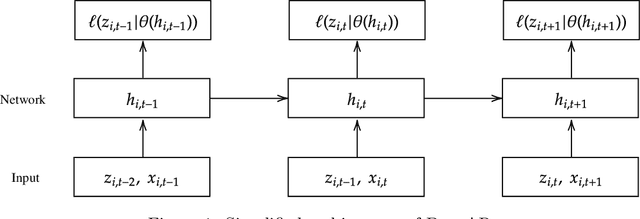
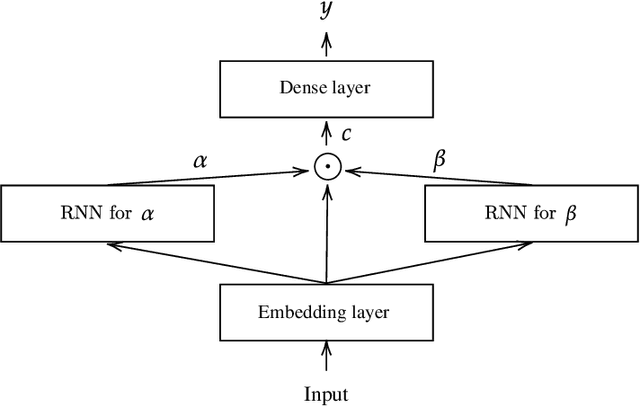
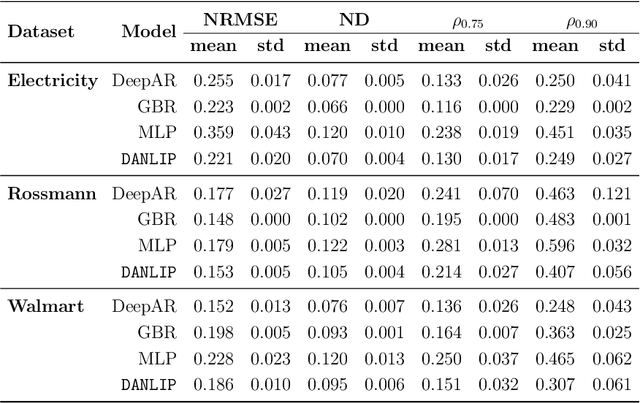
Despite the high performance of neural network-based time series forecasting methods, the inherent challenge in explaining their predictions has limited their applicability in certain application areas. Due to the difficulty in identifying causal relationships between the input and output of such black-box methods, they rarely have been adopted in domains such as legal and medical fields in which the reliability and interpretability of the results can be essential. In this paper, we propose \model, a novel deep learning-based probabilistic time series forecasting architecture that is intrinsically interpretable. We conduct experiments with multiple datasets and performance metrics and empirically show that our model is not only interpretable but also provides comparable performance to state-of-the-art probabilistic time series forecasting methods. Furthermore, we demonstrate that interpreting the parameters of the stochastic processes of interest can provide useful insights into several application areas.
Scalable Batch Acquisition for Deep Bayesian Active Learning
Jan 13, 2023
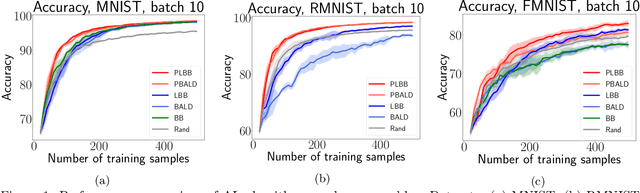
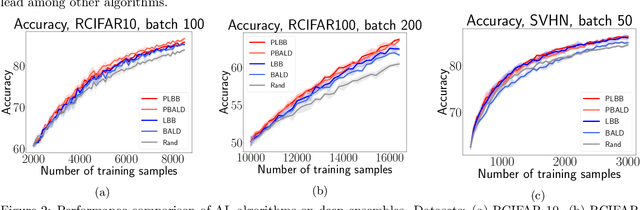

In deep active learning, it is especially important to choose multiple examples to markup at each step to work efficiently, especially on large datasets. At the same time, existing solutions to this problem in the Bayesian setup, such as BatchBALD, have significant limitations in selecting a large number of examples, associated with the exponential complexity of computing mutual information for joint random variables. We, therefore, present the Large BatchBALD algorithm, which gives a well-grounded approximation to the BatchBALD method that aims to achieve comparable quality while being more computationally efficient. We provide a complexity analysis of the algorithm, showing a reduction in computation time, especially for large batches. Furthermore, we present an extensive set of experimental results on image and text data, both on toy datasets and larger ones such as CIFAR-100.
Diffusion-based Time Series Imputation and Forecasting with Structured State Space Models
Aug 19, 2022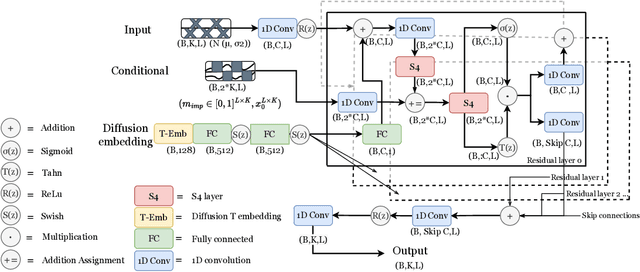
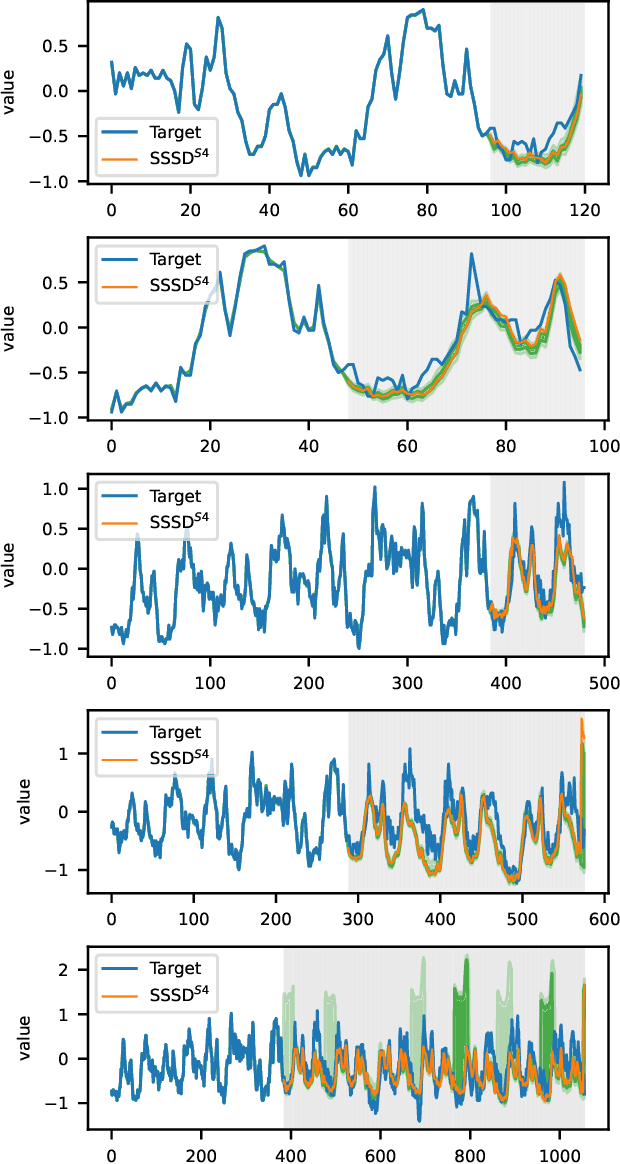
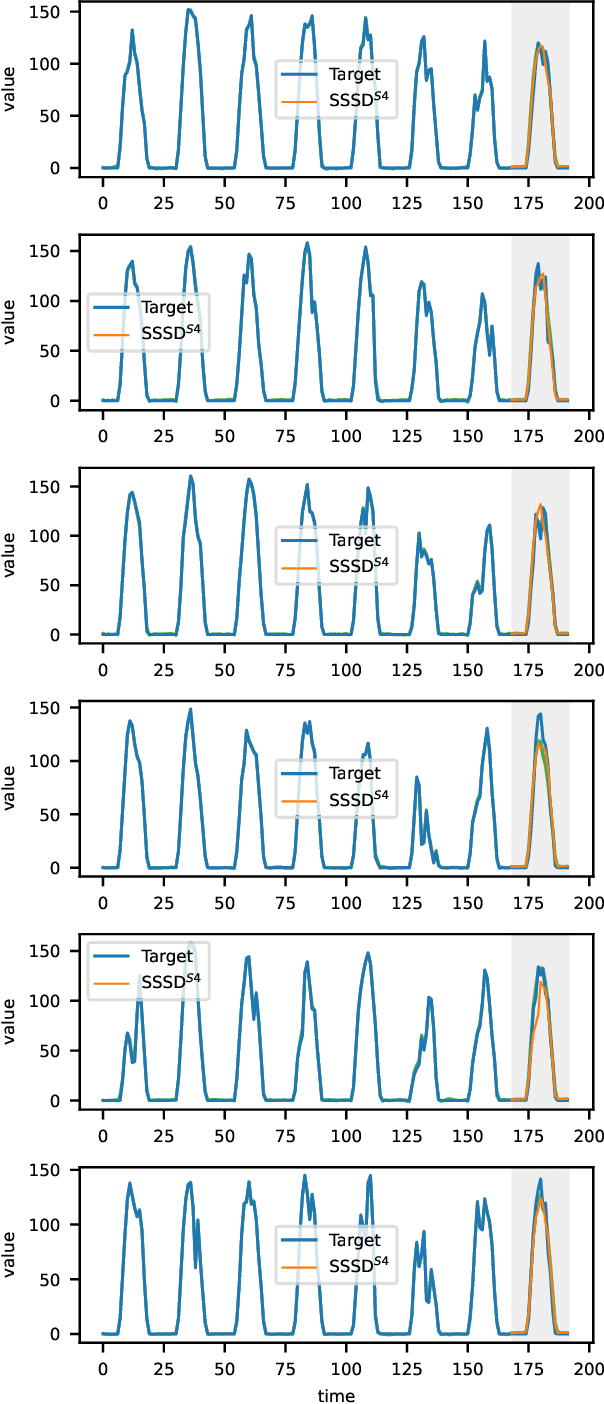
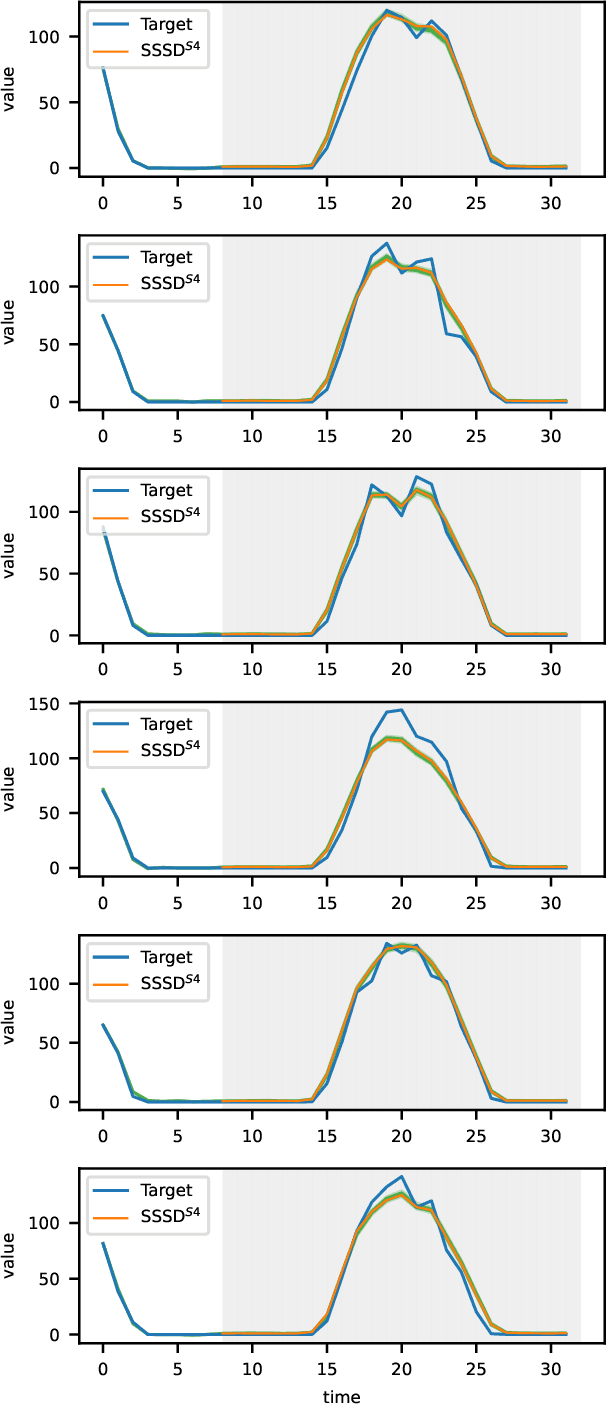
The imputation of missing values represents a significant obstacle for many real-world data analysis pipelines. Here, we focus on time series data and put forward SSSD, an imputation model that relies on two emerging technologies, (conditional) diffusion models as state-of-the-art generative models and structured state space models as internal model architecture, which are particularly suited to capture long-term dependencies in time series data. We demonstrate that SSSD matches or even exceeds state-of-the-art probabilistic imputation and forecasting performance on a broad range of data sets and different missingness scenarios, including the challenging blackout-missing scenarios, where prior approaches failed to provide meaningful results.
Deep Learning for scalp High Frequency Oscillations Identification
Jan 20, 2023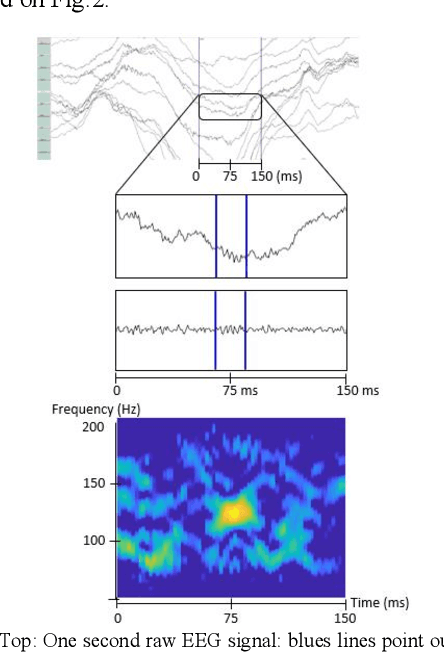
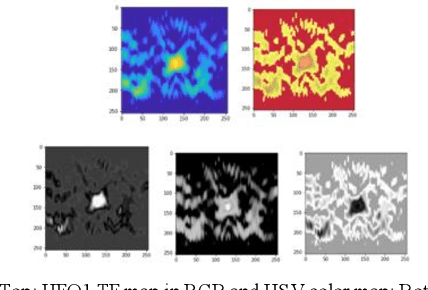
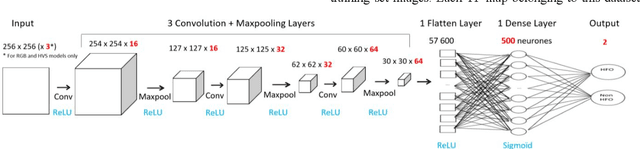
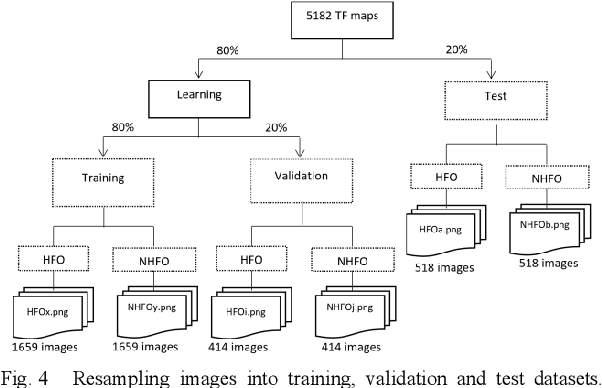
Since last 2 decades, High Frequency Oscillations (HFOs) are studied as a promising biomarker to localize the epileptogenic zone of patients with refractory focal epilepsy. As HFOs visual detection is time consuming and subjective, automatization of HFO detection is required. Most HFO detectors were developed on invasive electroencephalograms (iEEG) whereas scalp electroencephalograms (EEG) are used in clinical routine. In order HFO detection can benefit to more patients, scalp HFO detectors has to be developed. However, HFOs identification in scalp EEG is more challenging than in iEEG since scalp HFOs are of lower rate, lower amplitude and more likely to be corrupted by several sources of artifacts than iEEG HFOs. The main goal of this study is to explore the ability of deep learning architecture to identify scalp HFOs from the remaining EEG signal. Hence, a binary classification Convolutional Neural Network (CNN) is learned to analyze High Density Electroencephalograms (HD-EEG). EEG signals are first mapped into a 2D time-frequency image, several color definitions are then used as an input for the CNN. Experimental results show that deep learning allows simple end-to-end learning of preprocessing, feature extraction and classification modules while reaching competitive performance.
Development, Optimization, and Deployment of Thermal Forward Vision Systems for Advance Vehicular Applications on Edge Devices
Jan 18, 2023
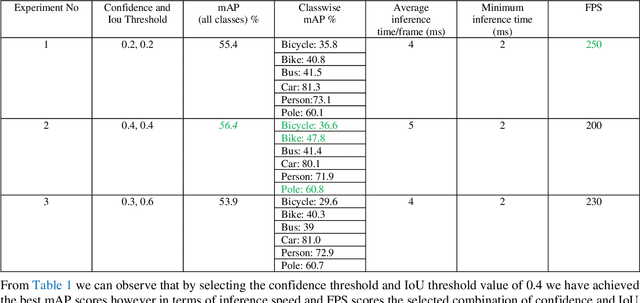
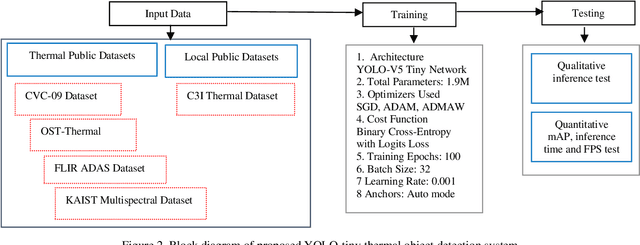
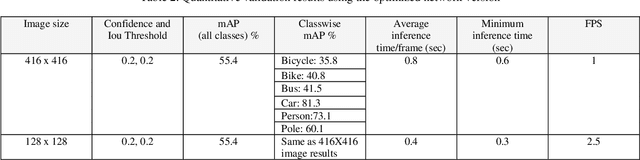
In this research work, we have proposed a thermal tiny-YOLO multi-class object detection (TTYMOD) system as a smart forward sensing system that should remain effective in all weather and harsh environmental conditions using an end-to-end YOLO deep learning framework. It provides enhanced safety and improved awareness features for driver assistance. The system is trained on large-scale thermal public datasets as well as newly gathered novel open-sourced dataset comprising of more than 35,000 distinct thermal frames. For optimal training and convergence of YOLO-v5 tiny network variant on thermal data, we have employed different optimizers which include stochastic decent gradient (SGD), Adam, and its variant AdamW which has an improved implementation of weight decay. The performance of thermally tuned tiny architecture is further evaluated on the public as well as locally gathered test data in diversified and challenging weather and environmental conditions. The efficacy of a thermally tuned nano network is quantified using various qualitative metrics which include mean average precision, frames per second rate, and average inference time. Experimental outcomes show that the network achieved the best mAP of 56.4% with an average inference time/ frame of 4 milliseconds. The study further incorporates optimization of tiny network variant using the TensorFlow Lite quantization tool this is beneficial for the deployment of deep learning architectures on the edge and mobile devices. For this study, we have used a raspberry pi 4 computing board for evaluating the real-time feasibility performance of an optimized version of the thermal object detection network for the automotive sensor suite. The source code, trained and optimized models and complete validation/ testing results are publicly available at https://github.com/MAli-Farooq/Thermal-YOLO-And-Model-Optimization-Using-TensorFlowLite.
Optimal decision making in robotic assembly and other trial-and-error tasks
Jan 25, 2023
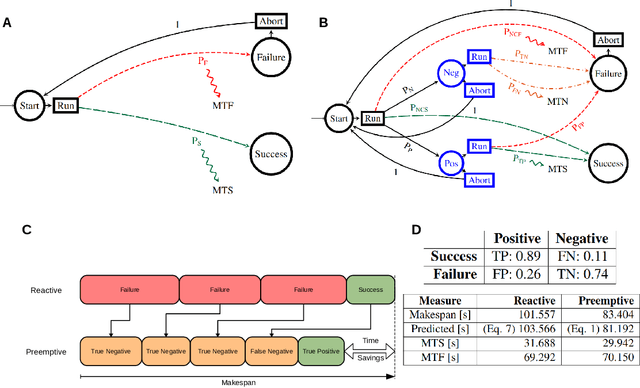
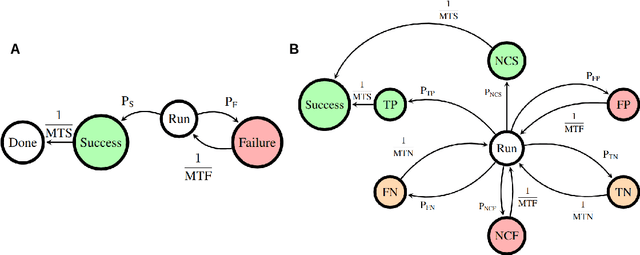
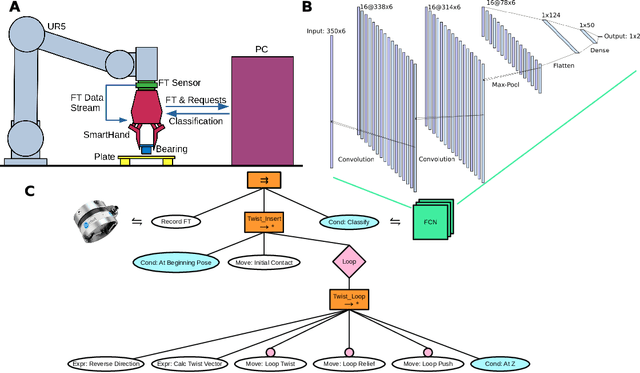
Uncertainty in perception, actuation, and the environment often require multiple attempts for a robotic task to be successful. We study a class of problems providing (1) low-entropy indicators of terminal success / failure, and (2) unreliable (high-entropy) data to predict the final outcome of an ongoing task. Examples include a robot trying to connect with a charging station, parallel parking, or assembling a tightly-fitting part. The ability to restart after predicting failure early, versus simply running to failure, can significantly decrease the makespan, that is, the total time to completion, with the drawback of potentially short-cutting an otherwise successful operation. Assuming task running times to be Poisson distributed, and using a Markov Jump process to capture the dynamics of the underlying Markov Decision Process, we derive a closed form solution that predicts makespan based on the confusion matrix of the failure predictor. This allows the robot to learn failure prediction in a production environment, and only adopt a preemptive policy when it actually saves time. We demonstrate this approach using a robotic peg-in-hole assembly problem using a real robotic system. Failures are predicted by a dilated convolutional network based on force-torque data, showing an average makespan reduction from 101s to 81s (N=120, p<0.05). We posit that the proposed algorithm generalizes to any robotic behavior with an unambiguous terminal reward, with wide ranging applications on how robots can learn and improve their behaviors in the wild.
Globally Optimized TDOA High Frequency Source Localization Based on Quasi-Parabolic Ionosphere Modeling and Collaborative Gradient Projection
Feb 10, 2023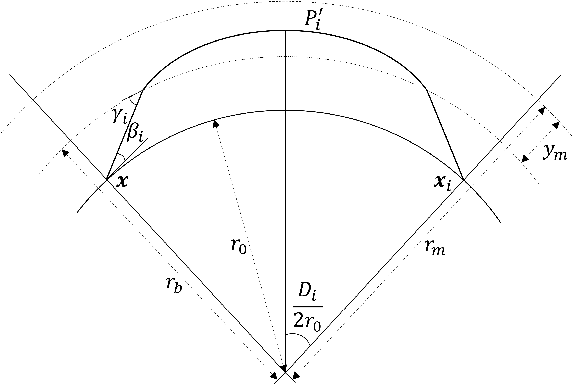
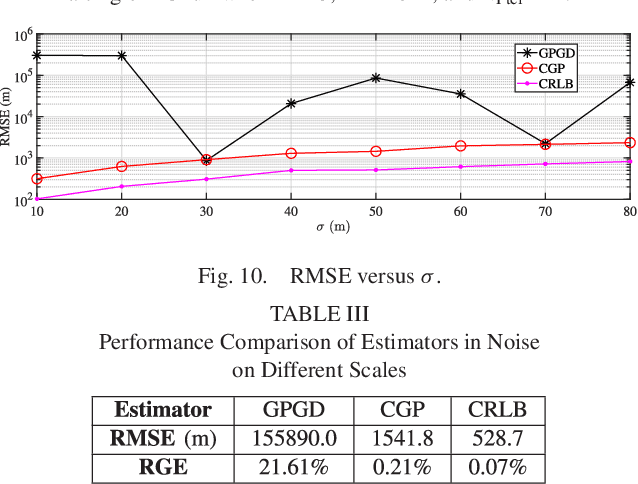
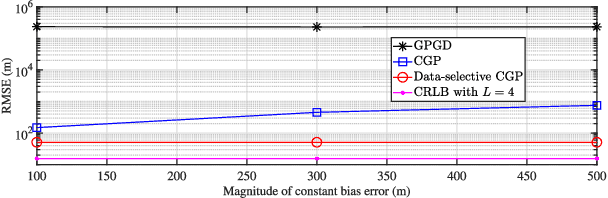
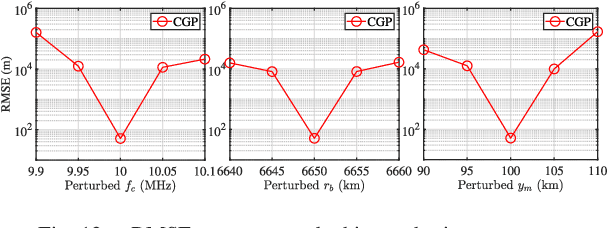
We investigate the problem of high frequency (HF) source localization using the time-difference-of-arrival (TDOA) observations of ionosphere-refracted radio rays based on quasi-parabolic (QP) modeling. An unresolved but pertinent issue in such a field is that the existing gradient-type scheme can easily get trapped in local optima for practical use. This will lead to the difficulty in initializing the algorithm and finally degraded positioning performance if the starting point is inappropriately selected. In this paper, we develop a collaborative gradient projection (GP) algorithm in order to globally solve the highly nonconvex QP-based TDOA HF localization problem. The metaheuristic of particle swarm optimization (PSO) is exploited for information sharing among multiple GP models, each of which is guaranteed to work out a critical point solution to the simplified maximum likelihood formulation. Random mutations are incorporated to avoid the early convergence of PSO. Rather than treating the geolocation of HF transmitter as a pure optimization problem, we further provide workarounds for addressing the possible impairments and challenges when the proposed technique is applied in practice. Numerical results demonstrate the effectiveness of our PSO-assisted re-initialization strategy in achieving the global optimality, and the superiority of our method over its competitor in terms of positioning accuracy.
* This is the accepted version. The final version of this paper has been published in the IEEE Transactions on Aerospace and Electronic Systems. The copyright is with IEEE. This version prevails, as there are unfortunately uncorrected editing mistakes in the final one
A SWAT-based Reinforcement Learning Framework for Crop Management
Feb 10, 2023
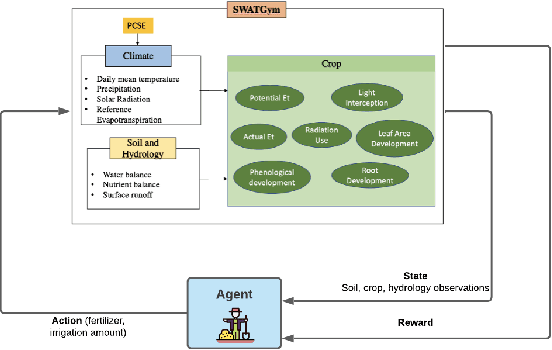
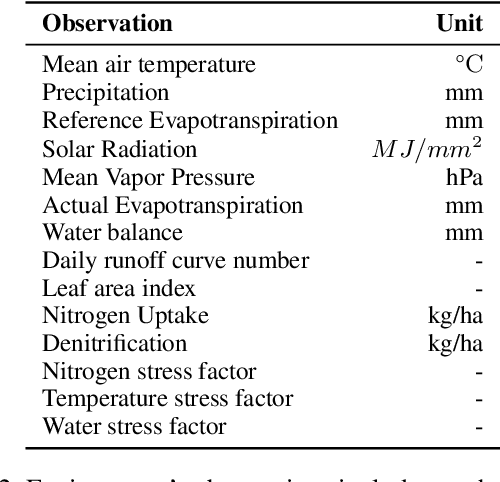
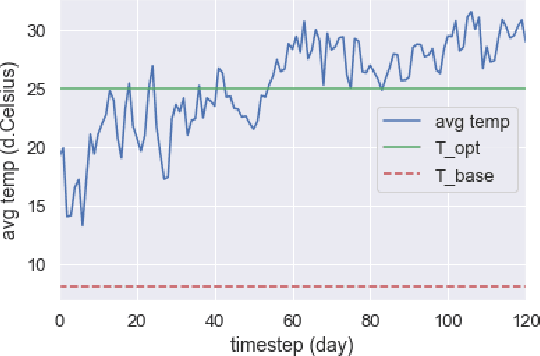
Crop management involves a series of critical, interdependent decisions or actions in a complex and highly uncertain environment, which exhibit distinct spatial and temporal variations. Managing resource inputs such as fertilizer and irrigation in the face of climate change, dwindling supply, and soaring prices is nothing short of a Herculean task. The ability of machine learning to efficiently interrogate complex, nonlinear, and high-dimensional datasets can revolutionize decision-making in agriculture. In this paper, we introduce a reinforcement learning (RL) environment that leverages the dynamics in the Soil and Water Assessment Tool (SWAT) and enables management practices to be assessed and evaluated on a watershed level. This drastically saves time and resources that would have been otherwise deployed during a full-growing season. We consider crop management as an optimization problem where the objective is to produce higher crop yield while minimizing the use of external farming inputs (specifically, fertilizer and irrigation amounts). The problem is naturally subject to environmental factors such as precipitation, solar radiation, temperature, and soil water content. We demonstrate the utility of our framework by developing and benchmarking various decision-making agents following management strategies informed by standard farming practices and state-of-the-art RL algorithms.
Fast Gumbel-Max Sketch and its Applications
Feb 10, 2023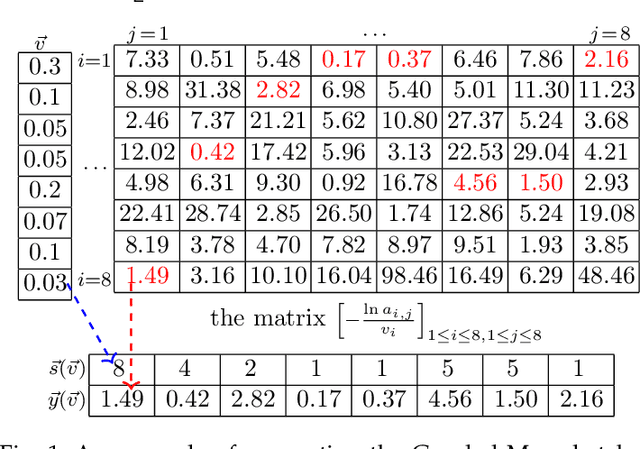
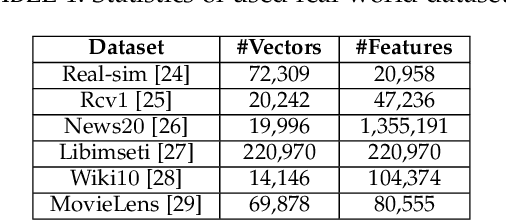
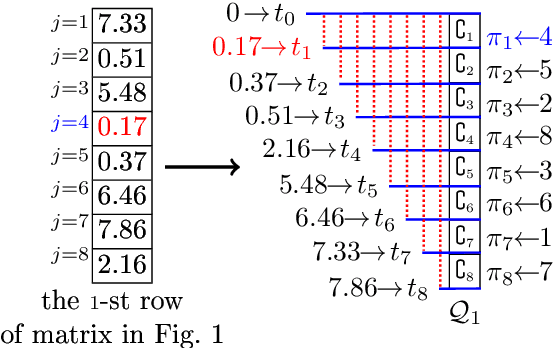
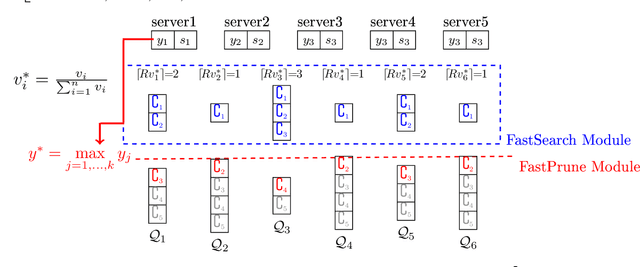
The well-known Gumbel-Max Trick for sampling elements from a categorical distribution (or more generally a non-negative vector) and its variants have been widely used in areas such as machine learning and information retrieval. To sample a random element $i$ in proportion to its positive weight $v_i$, the Gumbel-Max Trick first computes a Gumbel random variable $g_i$ for each positive weight element $i$, and then samples the element $i$ with the largest value of $g_i+\ln v_i$. Recently, applications including similarity estimation and weighted cardinality estimation require to generate $k$ independent Gumbel-Max variables from high dimensional vectors. However, it is computationally expensive for a large $k$ (e.g., hundreds or even thousands) when using the traditional Gumbel-Max Trick. To solve this problem, we propose a novel algorithm, FastGM, which reduces the time complexity from $O(kn^+)$ to $O(k \ln k + n^+)$, where $n^+$ is the number of positive elements in the vector of interest. FastGM stops the procedure of Gumbel random variables computing for many elements, especially for those with small weights. We perform experiments on a variety of real-world datasets and the experimental results demonstrate that FastGM is orders of magnitude faster than state-of-the-art methods without sacrificing accuracy or incurring additional expenses.